首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,061 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,065 阅读
3
【高数】形心计算公式讲解大全
8,735 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,423 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,766 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
编程&脚本笔记(共15篇)
找到
15
篇与
编程&脚本笔记
相关的结果
2024-03-12
C语言编译的四个步骤
编译一个C语言程序是一个多阶段的过程。从总体上看,这个过程可以分成四个独立的阶段。预处理、编译、汇编和连接。 在这篇文章中,我将逐一介绍编译下列C程序的四个阶段。 /* * "Hello, World!": A classic. */ #include <stdio.h> int main(void) { puts("Hello, World!"); return 0; }预处理 编译的第一个阶段称为预处理。在这个阶段,以#字符开头的行被预处理器解释为预处理器命令。这些命令形成一种简单的宏语言,有自己的语法和语义。这种语言通过提供内联文件、定义宏和有条件地省略代码的功能,来减少源代码的重复性。 在解释命令之前,预处理器会做一些初始处理。这包括连接续行(以 \ 结尾的行)和剥离注释。 要打印预处理阶段的结果,请向gcc传递-E选项。 gcc -E hello_world.c 考虑到上面的 "Hello, World!"的例子,预处理器将产生stdio.h头文件的内容和hello_world.c文件的内容,并将其前面的注释剥离出来。 编译 编译的第二个阶段被称为编译,令人困惑。在这个阶段,预处理过的代码被翻译成目标处理器架构特有的汇编指令。这些形成了一种中间的人类可读语言。 这一步骤的存在允许C代码包含内联汇编指令,并允许使用不同的汇编器。 一些编译器也支持使用集成汇编器,在这种情况下,编译阶段直接生成机器代码,避免了生成中间汇编指令和调用汇编器的开销。 要保存编译阶段的结果,可以向gcc传递-S选项。 gcc -S hello_world.c 这将创建一个名为hello_world.s的文件,包含生成的汇编指令。 汇编 在这个阶段,汇编器被用来将汇编指令翻译成目标代码。输出包括目标处理器要运行的实际指令。 要保存汇编阶段的结果,请向gcc传递-c选项。 gcc -c hello_world.c 运行上述命令将创建一个名为hello_world.o的文件,包含程序的目标代码。这个文件的内容是二进制格式,可以用运行命令hexdump或od来检查。 hexdump hello_world.o od -c hello_world.oLinux中的od(octal dump)命令用于转换输入内容为八进制。 Hexdump是一个命令行工具,用于以各种方式显示文件的原始内容,包括十六进制,可用于Linux、FreeBDS、OS X和其他平台。Hexdump不是传统Unix系统或GNU命令的一部分。 链接 汇编阶段产生的目标代码是由处理器能够理解的机器指令组成的,但程序的某些部分是不符合顺序的或缺失的。为了产生一个可执行的程序,现有的部分必须被重新排列,并把缺失的部分补上。这个过程被称为链接。 链接器将安排目标代码的各个部分,使某些部分的功能能够成功地调用其他部分的功能。它还将添加包含程序所使用的库函数指令的片段。在 "Hello,world!"程序的例子中,链接器将添加puts函数的对象代码。 这一阶段的结果是最终的可执行程序。当不使用选项运行时,gcc 将把这个文件命名为 a.out。如果要给文件命名,请向 gcc 传递 -o 选项。 gcc -o hello_world hello_world.c
编程&脚本笔记
# C/C++
刘航宇
2年前
0
540
0
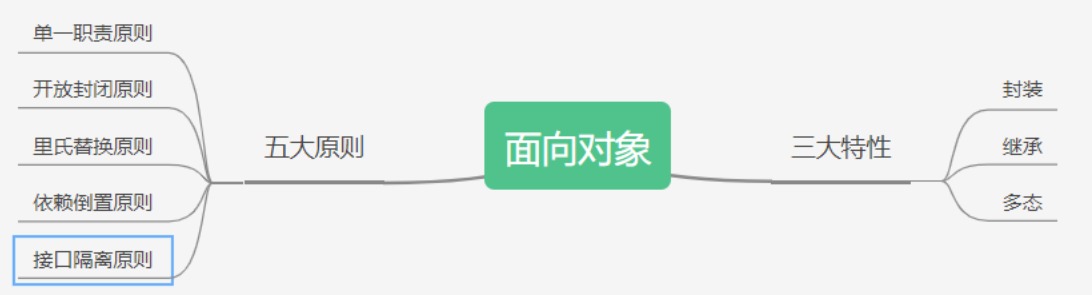
面向对象在编程中的概念
前言 那么究竟什么是面向对象呢?面向过程 面向对象 面向对象的三大特性封装 继承 多态 面向对象的五大基本原则单一职责原则(Single-Responsibility Principle) 开放封闭原则(Open-Closed principle) 里氏替换原则(Liskov-Substitution Principle) 依赖倒置原则(Dependecy-Inversion Principle) 接口隔离原则(Interface-Segregation Principle) 面向对象编程的用途 面向对象编程的应用领域 前言 在刚接触java、C++、Python语言的时候,就知道这是一门面向对象的语言。学不好java的原因找到了,面向对象的语言,没有对象怎么学 ::(狗头) 图片 那么究竟什么是面向对象呢? 面向对象,Object Oriented Programming,简称为OOP。说到面向对象,不得不提一嘴面向过程。 面向过程 面向过程是一种自顶而下的编程模式。 把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。 举个生活中的例子,假如你想吃红烧肉,你需要买肉,买调料,洗肉,切肉,烧肉,装盘。 需要我们具体每一步去实现,每个步骤相互协调,最终盛出来的才是正宗好吃的红烧肉。 面向对象 面向对象就是将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。 还是你想吃红烧肉这个例子,不过这次不同的是你发现了一家餐馆里有红烧肉这道菜,你要做的只是去点菜,就可以吃到红烧肉。 针不戳,针不戳,面向对象针不戳,你不用再去关心红烧肉繁琐的制作流程,就能吃到美味的红烧肉。 我们接着往下看 图片 面向对象的三大特性 封装 封装就是把客观的事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类进行信息的隐藏。简单的说就是:封装使对象的设计者与对象的使用者分开,使用者只要知道对象可以做什么就可以了,不需要知道具体是怎么实现的。封装可以有助于提高类和系统的安全性 这里有点像FPGA的IP了,电子人懂! 继承 当多个类中存在相同属性和行为时,将这些内容就可以抽取到一个单独的类中,使得多个类无需再定义这些属性和行为,只需继承那个类即可。通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类” 多态 多态同一个行为具有多个不同表现形式或形态的能力。是指一个类实例(对象)的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。 菜鸟教程中的例子就很形象 现实中,比如我们按下 F1 键这个动作: 如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档; 如果当前在 Word 下弹出的就是 Word 帮助; 在 Windows 下弹出的就是 Windows 帮助和支持。 同一个事件发生在不同的对象上会产生不同的结果。 面向对象的五大基本原则 单一职责原则(Single-Responsibility Principle) 简而言之,就是一个类最好只有一个能引起变化的原因,只做一件事,单一职责原则可以看做是低耦合高内聚思想的延伸,提高高内聚来减少引起变化的原因。 开放封闭原则(Open-Closed principle) 简而言之,就是软件实体应该是可扩展的,但是不可修改。因为修改程序有可能会对原来的程序造成错误。即对扩展开放,对修改封闭 里氏替换原则(Liskov-Substitution Principle) 简而言之,就是子类一定可以替换父类,子类包含其基类(父类)的功能 依赖倒置原则(Dependecy-Inversion Principle) 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。依赖于抽象即对接口编程,不要对实现编程 接口隔离原则(Interface-Segregation Principle) 图片 简而言之,就是使用多个小的专门的接口,而不要使用一个大的总接口。例如将一个房子再分割成卧室,厨房,厕所等等,而不是将所有功能放在一起 面向对象编程的用途 使用封装(信息隐藏)可以对外部隐藏数据 使用继承可以重用代码 使用多态可以重载操作符/方法/函数,即相同的函数名或操作符名称可用于多种任务 数据抽象可以用抽象实现 项目易于迁移(可以从小项目转换成大项目) 同一项目分工 软件复杂性可控 面向对象编程的应用领域 人工智能与专家系统 企业级应用 神经网络与并行编程 办公自动化系统
编程&脚本笔记
# 软件算法
# C/C++
刘航宇
3年前
0
424
3
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
497
0
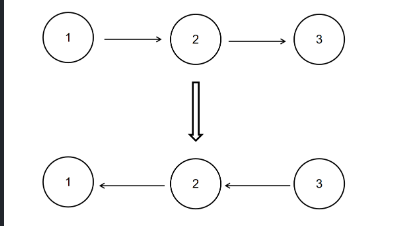
算法-反转链表C&Python实现
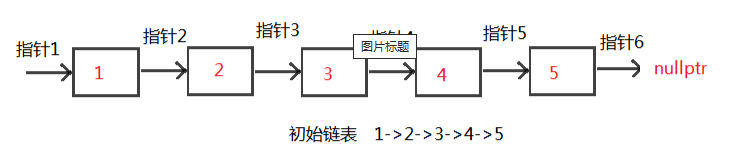
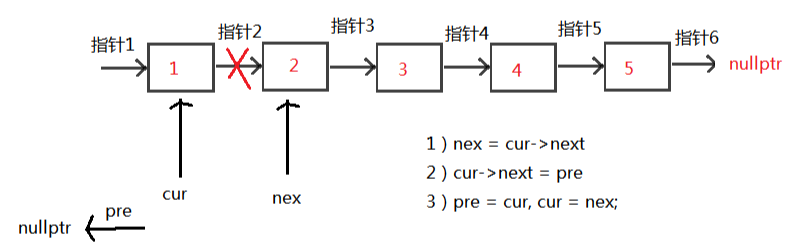
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
312
1
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
332
0
2023-07-19
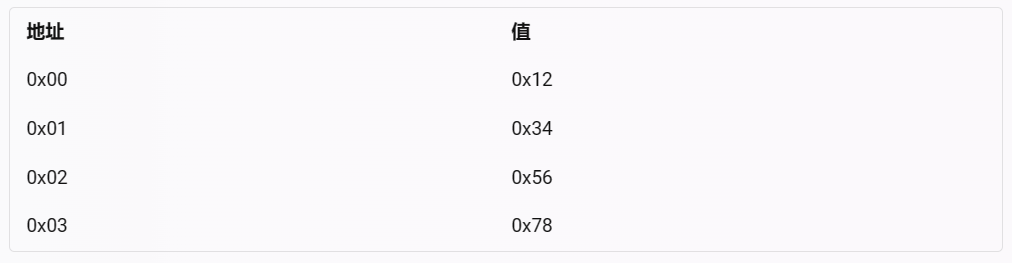
嵌入式软件-基于C语言小端转大端
意义 题目 示例 解答1.char指针,按字节替换 2.利用union联合体共用内存空间特性,使用char数组来改变 3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 4. 使用预定义好的宏函数 意义 大端小端转化对嵌入式系统有意义,因为不同的处理器或者通信协议可能采用不同的字节序来存储或者传输数据。字节序是指一个多字节数据在内存中的存放顺序,它有两种主要的形式: 大端:最高有效位(MSB)存放在最低的内存地址,最低有效位(LSB)存放在最高的内存地址。 小端:最低有效位(LSB)存放在最低的内存地址,最高有效位(MSB)存放在最高的内存地址。 例如,一个32位的整数0x12345678,在大端系统中,它的内存布局是: pC703EF.png图片 而在小端系统中,它的内存布局是: pC70G4J.png图片 如果一个嵌入式系统需要和不同字节序的设备或者网络进行交互,就需要进行字节序的转换,否则会导致数据错误或者通信失败。例如,TCP/IP协议族中的所有层都采用大端字节序来表示数据包头中的16位或32位的值,如IP地址、包长、校验和等。如果一个嵌入式系统使用小端字节序的处理器,并且想要建立一个TCP连接,就需要将IP地址等信息从小端转换为大端再发送出去,否则对方无法正确解析。 题目 输入一个数字n,假设它是以小端模式保存在机器的,请将其转换为大端方式保存时的值。 示例 输入:1 返回值:16777216 解答 1.char指针,按字节替换 /* * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here int tmp = 0x00000000; //开辟新的int空间用于接收转化结果 unsigned char *p = &tmp, *q = &n; p[0] = q[3]; p[1] = q[2]; p[2] = q[1]; p[3] = q[0]; return tmp; }2.利用union联合体共用内存空间特性,使用char数组来改变 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ typedef union { int i; unsigned char c[4] } inc_u; int convert(int n ) { // write code here inc_u x; //这里也可以用新开辟空间进行置换 x.i = n; //利用按位异或运算可叠加、可还原性 x.c[0] ^= x.c[3], x.c[3] ^= x.c[0], x.c[0] ^= x.c[3]; //首尾两字节对调 x.c[1] ^= x.c[2], x.c[2] ^= x.c[1], x.c[1] ^= x.c[2]; //中间两字节对调 return x.i; /* 按位<<到正确位置,并用|拼装 return (x.c[0]<<24)|(x.c[1]<<16)|(x.c[2]<<8)|x.c[3]; */ }3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return (((n & 0xff000000)>>24) | ((n & 0x00ff0000)>>8 ) | ((n & 0x0000ff00)<<8 ) | ((n & 0x000000ff)<<24); //按位与时,遇0清零,遇1保留 ); }4. 使用预定义好的宏函数 本条方法参考 https://www.codeproject.com/Articles/4804/Basic-concepts-on-Endianness 文中提到网络上常用的套接字接口(socket API)指定了一种称为网络字节顺序的标准字节顺序,这个顺序其实就是大端模式;而当时,同时代的 x86 系列主机反而是小端模式。所以就促使产生了如: ntohs() convert Network order TO Host order in Short (16 bit 大转小); ntohl() convert Network order TO Host order in Long (32 bit 大转小); htons() convert Host order TO Network order in Short (16 bit 小转大); htonl() convert Host order TO Network order in Long (32 bit 小转大). 所以我们这里使用 32 bit 小转大的 htonl() 宏函数来解决这个问题。 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return htonl(n); ); }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
504
1
2023-03-13
Verilog-位宽计算的系统函数$clog2
一、什么是$clog2 clog2 这是一个系统函数,第一次出现于Verilog-2005版本中,在IEEE中处在17.11.1节的math functions中,因为log2是2进制的对数,所以这个系统函数在电路设计的计算位宽时体现出了自身的方便性,需要注意的是,这里的$clog2是向上取整的一个系统函数,比如 $clog2(5) 虽然真实的值为2.3,但经过向上取整后,最后的输出为3 二、$clog2的优势和案例 在老的IEEE verilog版本中,假如不用clog2去计算位宽,我们可能需要如下的function函数来进行位宽计算,这个函数本身很好理解,即通过移位去检测depth的位宽,之后我们需要再将计算得到的数字使用在端口定义的过程中。 function integer clog2( input integer depth ); begin if(depth == 0) clog2 = 1; else if(depth != 0) for(clog2 = 0; depth > 0;clog2 = clog2 + 1) depth = depth >> 1; end endfunction但是引入$clog2后,原function可以简化为如下的过程,很显然,通过对系统函数 $clog2的使用,我们大大减少了设计时端口宽度定义时需要code的量。 module clog2(a,b); parameter depth = 2034; input [$clog2(depth)-1:0] a; output [$clog2(depth)-1:0]b; //details about the design endmodule 三、额外补充 在Xlinix的官网的“44586 - 13.2 Verilog $clog2 function implemented improperly”中,作者发现了13.2版本的Xlinix的ISE对clog2系统函数的错误计算,按照文章中所言:“The $clog2 function returns the ceiling of the logarithm to the base e (natural logarithm) rather than the ceiling of the logarithm to the base 2.”意味着13.2版本的ISE以e为底计算clog2,而非以2为底,官方的回复是ISE 13.2 仅支持Verilog-2001,这个问题在ISE 14.1中进行了修复,所以读者假如使用的开发套件是老版本的,或者不支持Verilog-2005,都有可能因为使用clog2产生问题,需注意。具体额外补充参考如下。 44586 - 13.2 Verilog $clog2 function implemented improperly
编程&脚本笔记
# Verilog
刘航宇
3年前
0
3,048
1
2023-02-09
VCS、Verdi与Makefile使用简介
前期工作 1、.fsdb文件 在使用Makefile文件前,先在测试文件中加入这样一句。 initial begin $fsdbDumpfile("tb.fsdb");//这个是产生名为tb.fsdb的文件 $fsdbDumpvars; end需要注意:对于用于仿真的testbench,需要额外建立一个 initial 块,调用产生有关 fsdb 格式的波形文件: 首先调用 fsdbDumpfile 函数,产生一个叫 .fsdb 的波形文件 然后调用 fsdbDumpvars 函数,声明需要保存那些信号的波形,括号内不加任何参数,则默认全部保存。 2、 filelist.f文件 filelist.f里存放所有需要仿真的.v文件。 创建filelist.f的方法: find -name "*.v" >filelist.f 1. Makefile作用? 编写makefile文件本质上是帮组make如何一键编译,进行批处理,makefile文件包含的规则命令使我们不需要繁琐的操作,提高了开发效率。 Makefile可以根据指定的依赖规则和文件是否有修改来执行命令。常用来编译软件源代码,只需要重新编译修改过的文件,使得编译速度大大加快。 2. Makefile应用 利用Makefile 实现简单的前端设计流程,包括VCS编译,Verdi仿真,DC综合,后续流程待补充。 目录结构 图片 #use "make" for help help: @echo "make help" @echo "make com to compile" @echo "make sim to run simulation" @echo "make clean to delete temporary files" #need to midify design name design_name = div_top fsdb_name = $(design_name).fsdb # use command "make com" to run vsc and product fsdb file com: cd RTL && vcs \ -full64 \ -f flist.f \ -debug_all \ -l com.log \ +v2k \ -P ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/novas.tab ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/pli.a # cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) #simulation:product fsdb file and sim log sim: ./RTL/simv cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) # use verdi to observe the waveform verdi: cd RTL && verdi \ +v2k \ -f flist.f \ -ssf $(fsdb_name) & #use fsdb file # run dc for synthesize syn: cd dc_script && dc_shell -64bit -topographical -f top_syn.tcl | tee -i syn.log #delete all files except .v and makefile clean: #rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v" | grep -v "dc_script"` make -C RTL clean make -C dc_script clean/RTL目录下MakeFile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v"` dc_script目录下Makefile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "script" | grep -v ".*.tcl"` make com :调用vcs编译 make sim:调用vcs仿真 make verdi 波形,shifrt+l可刷新重新编译结果 make clean 删除所有子目录下的临时生成文件 详细命令 执行“make vcs” 编译仿真 执行“make verdi” 打开波形 verdi常用快捷键 ctrl+w: 添加信号到波形图 h: 在波形窗口显示详细的信号名(路径) File>save signal,命名*.rc,下次直接打开rc文件就行 c/t: 修改信号的颜色(t可以直接切换颜色) 在波形窗口显示状态机的名字: 在rtl窗口,tools>Extract internative FSM ,可选first stage(仅展开目前所指定的FSM state),all stage (展开所有的FSM state) 改变颜色填充波形: Tools>waveform>view options>waveformpane> paint waveform with specified color/pattern 在rtl窗口按x: 标注出信号的值 z: 缩小波形窗口 Z: 放大波形窗口 f: 全屏 l: 上一个视图 L: 重新加载设计波形或文件 n: 向前查找 N: 向后查找 ctrl+→: 向右移动半屏 ctrl+←: 向左移动半屏 双击信号波形: 跳转到rtl中信号位置,并高亮新号 b: 跳到波形图开头 e: 跳到波形图尾部 2.不使用Makefile直接执行 vcs -R -f flist.f -full64 -fsdb -l name.log verdi -f flist.f -ssf name.fsdb 图片
编程&脚本笔记
EDA&虚拟机
# EDA&虚拟机
# Makefile
刘航宇
3年前
0
1,495
2
TCL脚本语言用法简介
前言(TCL综述) TCL(Tool Command Language)是一种解释执行的脚本语言(Scripting Language)。 它提供了 通用的编程能力:支持变量、过程和控制结构;同时 TCL还拥有一个功能强大的固有的核心命令集。 由于TCL的解释器是用一个C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作一个C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,可以很容易就在C\C++应用程序中嵌入TCL,而且每个应用程序都可以根据自己的需要对TCL语言进行扩展。我们可以针对某一特定应用领域对TCL语言的核心命令集进行扩展,加入适合于自己的应用领域的扩展命令,如果需要,甚至可以加入新的控制结构,TCL解释器将把扩展命令和扩展控制结构与固有命令和固有控制结构同等看待。扩展后的TCL语言将可以继承TCL 核心部分的所有功能,包括核心命令、控制结构、数据类型、对过程的支持等。根据需要,我们甚至可以屏蔽掉TCL的某些固有命令和固有控制结构。通过对TCL的扩展、继承或屏蔽,用户用不着象平时定义一种计算机语言那样对词法、语法、语义、语用等各方面加以定义,就可以方便的为自己的应用领域提供一种功能完备的脚本语言。 TCL良好的可扩展性使得它能很好地适应产品测试的需要,测试任务常常会由于设计和需求的改变而迅速改变,往往让测试人员疲于应付。利用TCL的可扩展性,测试人员就可以迅速继承多种新技术,并针对产品新特点迅速推出扩展TCL命令集,以用于产品的测试中,可以较容易跟上设计需求的变化。 另外,因为TCL是一种比C\C++ 语言有着更高抽象层次的语言,使用TCL可以在一种更高的层次上编写程序,它屏蔽掉了编写C\C++程序时必须涉及到的一些较为烦琐的细节,可以大大地提高开发测试例的速度。而且, 使用TCL语言写的测试例脚本,即使作了修改,也用不着重新编译就可以调用TCL解释器直接执行。可以省却不少时间。TCL 目前已成为自动测试中事实上的标准。 目录 前言(TCL综述) 语法脚本,命令和单词符号 置换(substitution) 变量置换variable subtitution 命令置换command substitution反斜杠置换backslash substitution 双引号和花括号 变量简单变量 数组 append和incr expr List concat lindex llength linsert lreplace lrange lappend lsearch 控制流 if 循环命令:while 、for 、 foreach while for break和continue命令 switch source 过程(procedure) 附录(Tcl的安装) 直接打开终端(terminal),输入 sudo apt install tcl即可进行安装,这里的截图是笔者安装成功后的实例。 图片 之后输入tclsh即可 语法 脚本,命令和单词符号 一个TCL脚本可以包含一个或多个命令。命令之间必须用换行符或分号隔开,下面的两个脚本都是合法的: set a 1 set b 2 或使用分号隔开 set a 1;set b 2TCL解释器对一个命令的求值过程分为两部分:分析和执行。在分析阶段,TCL 解释器运用规则把命令分成一个个独立的单词,同时进行必要的置换(substitution); 在执行阶段,TCL 解释器会把第一个单词当作命令名,并查看这个命令是否有定义,如果有定义就激活这个命令对应的C/C++过程,并把所有的单词作为参数传递给该命令过程,让命令过程进行处理。 置换(substitution) TCL解释器在分析命令时,把所有的命令参数都当作字符串看待,例如: %set x 10 //定义变量x,并把x的值赋为10 10 %set y x+100 //y的值是x+100,而不是我们期望的110 x+100上例的第二个命令中,x被看作字符串x+100的一部分,如果我们想使用x的值’10’ ,就必须告诉 TCL解释器:我们在这里期望的是变量x的值,而非字符’x’。怎么告诉TCL解释器呢,这就要用到TCL语言中提供的置换功能。置换功能分为三种.TCL提供三种形式的置换:变量置换、命令置换和反斜杠置换。每种置换都会导致一个或多个单词本身被其他的值所代替。置换可以发生在包括命令名在内的每一个单词中,而且置换可以嵌套。 变量置换variable subtitution 变量置换由一个$符号标记,变量置换会导致变量的值插入一个单词中。例如之前的一个例子 %set x 10 //定义变量x,并把x的值赋为10 10 %set y x+100 //y的值是x+100,而不是我们期望的110 x+100 %set y $x+100 //y的值是我们期望的110 110命令置换command substitution 命令置换是由[]括起来的TCL命令及其参数,命令置换会导致某一个命令的所有或部分单词被另一个命令的结果所代替。例如: %set y [expr $x+100] 110这里当TCL解释器遇到字符’[‘时,它就会把随后的expr作为一个命令名,从而激活与expr对应的C/C++过程,并把expr和变量置换后得到的10+100传递给该命令过程进行处理。 反斜杠置换backslash substitution TCL语言中的反斜杠置换类似于C语言中反斜杠的用法,主要用于在单词符号中插入诸如换行符、空格、[、$等被TCL解释器当作特殊符号对待的字符。 %set msg money\ \$3333\ \nArray\ a\[2] //这个命令的执行结果为: money $3333 Array a[2]双引号和花括号 除了使用反斜杠外,TCL提供另外两种方法来使得解释器把分隔符和置换符等特殊字符当作普通字符,而不作特殊处理,这就要使用双引号和花括号({})。 TCL解释器对双引号中的各种分隔符将不作处理,但是对换行符 及$和[]两种置换符会照常处理。而在花括号中,所有特殊字符都将成为普通字符,失去其特殊意义,TCL解释器不会对其作特殊处理。 %set y "$x ddd" 100 ddd %set y {/n$x [expr 10+100]} /n$x [expr 10+100]注释 TCL中的注释符是#,#和直到所在行结尾的所有字符都被TCL看作注释,TCL解释器对注释将不作任何处理。不过,要注意的是,#必须出现在TCL解释器期望命令的第一个字符出现的地方,才被当作注释。 %set a 100 # Not a comment wrong # args: should be "set varName ?newValue?" %set b 101 ; # this is a comment 101变量 变量分为简单变量和数组 简单变量 一个 TCL 的简单变量包含两个部分:名字和值。名字和值都可以是任意字符串。 % set a 2 2 set a.1 4 4 % set b $a.1 2.1在最后一个命令行,我们希望把变量a.1的值付给b,但是TCL解释器在分析时只把$符号之后直到第一个不是字母、数字或下划线的字符(这里是’.’)之间的单词符号(这里是’a’)当作要被置换的变量的名字,所以TCL解释器把a置换成2,然后把字符串“2.1”付给变量b。这显然与我们的初衷不同。 当然,如果变量名中有不是字母、数字或下划线的字符,又要用置换,可以用花括号把变量名括起来。例如: %set b ${a.1} 4数组 数组是一些元素的集合。TCL的数组和普通计算机语言中的数组有很大的区别。在TCL中,不能单独声明一个数组,数组只能和数组元素一起声明。数组中,数组元素的名字包含两部分:数组名和数组中元素的名字,TCL中数组元素的名字(下标〕可以为任何字符串。 例如: set day(monday) 1 set day(tuesday) 2 set a monday set day(monday) 1 set b $day(monday) //b 的值为 1 ,即 day(monday) 的值。 set c $day($a) //c 的值为 1 ,即 day(monday) 的值。其他命令 unset % unset a b day(monday)上面的语句中删除了变量a、b和数组元素day(monday),但是数组day并没有删除,其他元素还存在,要删除整个数组,只需给出数组的名字。 append和incr 这两个命令提供了改变变量的值的简单手段。 append命令把文本加到一个变量的后面,例如: % set txt hello hello % append txt "! How are you" hello! How are youincr命令把一个变量值加上一个整数。incr要求变量原来的值和新加的值都必须是整数。 expr 可以进行基本的数学函数计算 %expr 1 + 2*3 7List list这个概念在TCL中是用来表示集合的。TCL中list是由一堆元素组成的有序集合,list可以嵌套定 义,list每个元素可以是任意字符串,也可以是list。下面都是TCL中的合法的list: {} //空list {a b c d} {a {b c} d} //list可以嵌套list是TCL中比较重要的一种数据结构,对于编写复杂的脚本有很大的帮助 list 语法: list ? value value…? 这个命令生成一个list,list的元素就是所有的value。例: % list 1 2 {3 4} 1 2 {3 4}使用置换将其相结合 % set a {1 2 3 4 {1 2}} 1 2 3 4 {1 2} % puts $a 1 2 3 4 {1 2}concat 语法:concat list ?list…? 这个命令把多个list合成一个list,每个list变成新list的一个元素。 % set a {1 2 3} 1 2 3 % set b {4 5 6} 4 5 6 % concat $a $b 1 2 3 4 5 6lindex 语法:lindex list index 返回list的第index个(0-based)元素。例: % lindex {1 2 {3 4}} 2 3 4llength 语法:llength list 返回list的元素个数。例 % llength {1 2 {3 4}} 3 % set a {1 2 3} 1 2 3 % llength $a 3linsert 语法:linsert list index value ?value…? 返回一个新串,新串是把所有的value参数值插入list的第index个(0-based)元素之前得到。例: % linsert {1 2 {3 4}} 1 7 8 {9 10} 1 7 8 {9 10} 2 {3 4} % linsert {1 2 {3 4}} 1 {1 2 3 {4 5}} 1 {1 2 3 {4 5}} 2 {3 4} % set a {1 2 3} 1 2 3 % linsert $a 1 {2 3 4} 1 {2 3 4} 2 3lreplace 语法:lreplace list first last ?value value …? 返回一个新串,新串是把list的第firs (0-based)t到第last 个(0-based)元素用所有的value参数替换得到的。如果没有value参数,就表示删除第first到第last个元素。例: % lreplace {1 7 8 {9 10} 2 {3 4}} 3 3 1 7 8 2 {3 4} % lreplace {1 7 8 2 {3 4}} 4 4 4 5 6 1 7 8 2 4 5 6 % set a {1 2 3} 1 2 3 % lreplace $a 1 2 4 5 6 7 1 4 5 6 7 % lreplace $a 1 end 1lrange 语法:lrange list first last 返回list的第first (0-based)到第last (0-based)元素组成的串,如果last的值是end。就是从第first个直到串的最后。 例: % lrange {1 7 8 2 4 5 6} 3 end 2 4 5 6 % set a {1 2 3} 1 2 3 % lrange $a 0 end 1 2 3lappend 语法:lappend varname value ?value…? 把每个value的值作为一个元素附加到变量varname后面,并返回变量的新值,如果varname不存在,就生成这个变量。例: % set a {1 2 3} 1 2 3 % lappend a 4 5 6 1 2 3 4 5 6lsearch 语法:lsearch ?-exact? ?-glob? ?-regexp? list pattern 返回list中第一个匹配模式pattern的元素的索引,如果找不到匹配就返回-1。-exact、-glob、 -regexp是三种模式匹配的技术。-exact表示精确匹配;-glob的匹配方式和string match命令的匹配方式相同;-regexp表示正规表达式匹配。缺省时使用-glob匹配。例: % set a { how are you } how are you % lsearch $a y* 2 % lsearch $a y? -1-all 返回一个列表,返回的列表中的数值就是字符在列表中的位置 默认全局匹配,返回第一个字符在列表中的位置,其位缺省状态 % lsearch {a b c d e} c 2 % lsearch -all {a b c a b c} c 2 5 % lsearch {a b c d c} c 2匹配不到返回-1 % lsearch {a b c d e} g -1控制流 主要是对于所有的控制流,包括 if、while、for、foreach、switch、break、continue 等以及过程, if 语法: if test1 body1 ?elseif test2 body2 elseif…. ? ?else bodyn? TCL先把test1当作一个表达式求值,如果值非0,则把body1当作一个脚本执行并返回所得值,否则把test2当作一个表达式求值,如果值非0,则把body2当作一个脚本执行并返回所得值……。例如: if { $x>0 } { ..... }elseif{ $x==1 } { ..... }elseif { $x==2 } { .... }else{ ..... }if { $x<0 } { puts "x is smaller than zero" } elseif {$x==1} { puts "x is equal 1" } elseif {$x==2} { puts "x is equal 2" } else { puts "x is other" } 这里需要注意的是, if 和{之间应该有一个空格,否则TCL解释器会把’if{‘作为一个整体当作一个命令名,从而导致错误。 ‘{‘一定要写在上一行,因为如果不这样,TCL 解释器会认为if命令在换行符处已结 束,下一行会被当成新的命令,从而导致错误的结果需要将}{ 分开写, 否则会报错extra characters after close-brace 循环命令:while 、for 、 foreach while 语法为: while test body 参数test是一个表达式,body是一个脚本,如果表达式的值非0,就运行脚本,直到表达式为0才停止循环,此时while命令中断并返回一个空字符串。 例如:假设变量 a 是一个链表,下面的脚本把a 的值复制到b: % #首先生成一个集合 % set a {1 2 3 4} 1 2 3 4 % set b " " % #计算生成集合的长度(从0开始这里需要减去1例如:0-3一共有四个数) % set i [expr [llength $a] -1] 3 #接下来进行判断,将集合a中的元素全部按顺序写入b中 % while {$i>=0} { #思考执行该行代码替换会有怎样的结果打印出来 #lappend b [lindex $a $i] lappend b [lindex $a [expr [llength $a] - 1 - $i]] incr i -1 } #打印观察结果 % puts $b 1 2 3 4对代码进行分析 set 变量a为一个list,b为一个空list 然后计算列表里有几个元素,将其减一后的值赋值给i,这里减一的目的是从零开始计数会多一个 开始进行循环,首先i的值是4大于0,表达式为真,开始执行脚本。 脚本为将数组a的第i个位置的元素添加到b list 里,然后给i减一同时进行下一次判断即可。 最后输出b的值 for 语法为: for init test reinit body 参数init是一个初始化脚本,第二个参数test是一个表达式,用来决定循环什么时候中断,第三个参数reinit是一个重新初始化的脚本,第四个参数body也是脚本,代表循环体。下例与上例作用相同:(注意这里复制打印顺序的不同) % set a {1 2 3 4} 1 2 3 4 % set b " " % for {set i [expr [llength $a] -1]} {$i>=0} {incr i -1} { lappend b [lindex $a $i] } % puts $b 4 3 2 1例 % for {set i 0} {$i<4} {incr i} { puts "I is: $i " } I is: 0 I is: 1 I is: 2 I is: 3 foreach 这个命令有两种语法形式 1, foreach varName list body 第一个参数varName是一个变量,第二个参数list 是一个表(有序集合),第三个参数body是循环体。每次取得链表的一个元素,都会执行循环体一次。 下例与上例作用相同: % set a {1 2 3 4} 1 2 3 4 % set b " " % foreach i $a { set b [linsert $b 0 $i] } % puts $b 4 3 2 1% foreach var {a b c d e f} { puts $var } a b c d e f2, foreach varlist1 list1 ?varlist2 list2 ...? Body 这种形式包含了第一种形式。第一个参数varlist1是一个循环变量列表,第二个参数是一个列表list1,varlist1中的变量会分别取list1中的值。body参数是循环体。 ?varlist2 list2 …?表示可以有多个变量列表和列表对出现。例如: set x {} foreach {i j} {a b c d e f} { lappend x $j $i }这时总共有三次循环,x的值为”b a d c f e”。 % foreach i {a b c} j {d e f g} { puts $i puts $j } a d b e c f gset x {} foreach i {a b c} j {d e f g} { lappend x $i $j }这时总共有四次循环, x的值为”a d b e c f {} g set x {} foreach i {a b c} {j k} {d e f g} { lappend x $i $j $k }这时总共有三次循环,x的值为”a d e b f g c {} {}”。 例子: 图片 break和continue命令 在循环体中,可以用break和continue命令中断循环。其中break命令结束整个循环过程,并从循环中跳出,continue只是结束本次循环 这里有一个特别好的例子 说明:这里首先进行给一个list,然后使用foreach循环进行写入数据当遇见break时候直接退出了循环,而continue仅仅只是跳出此次循环继续向b里写入数 % set b {} % set a {1 2 3 4 5} 1 2 3 4 5 % foreach i $a { if {$i == 4} break set b [linsert $b 0 $i] } % puts $b 3 2 1% set b {} % set a {1 2 3 4 5} 1 2 3 4 5 % foreach i $a { if {$i == 4} continue set b [linsert $b 0 $i] } % puts $b 5 3 2 1switch 和 C 语言中 switch 语句一样,TCL 中的 switch 命令也可以由 if 命令实现。只是书写起来较为烦琐。 switch 命令的语法为: switch ? options? string { pattern body ? pattern body …?} 注意这里进行的是字符匹配 图片 set x a; set t1 0;set t2 0;set t3 0; switch $x { a - b {incr t1} c {incr t2} default {incr t3} } puts "t1=$t1,t2=$t2,t3=$t3"x=a时执行的是t1加2 其中 a 的后面跟一个’-’表示使用和下一个模式相同的脚本。default 表示匹配任意值。一旦switch 命令 找到一个模式匹配,就执行相应的脚本,并返回脚本的值,作为 switch 命令的返回值。 source source 命令读一个文件并把这个文件的内容作为一个脚本进行求值 以上边的switch第一段代码为例 使用VIM新建一个文件,写入文件后保存退出 vim switch1.tcl键入wish然后输入source switch1.tcl 图片 过程(procedure) TCL 支持过程的定义和调用,在 TCL 中,过程可以看作是用 TCL 脚本实现的命令,效果与 TCL的固有命令相似。我们可以在任何时候使用 proc 命令定义自己的过程,TCL 中的过程类似于 C中的函数。 TCL 中过程是由 proc 命令产生的: 例如: % proc add {x y } {expr $x+$y} roc 命令的第一个参数是你要定义的过程的名字,第二个参数是过程的参数列表,参数之间用空格隔开,第三个参数是一个 TCL 脚本,代表过程体。 proc 生成一个新的命令,可以象固有命令一样调用: % add 1 2 3
编程&脚本笔记
# TCL脚本
刘航宇
3年前
0
1,671
0
2021-07-06
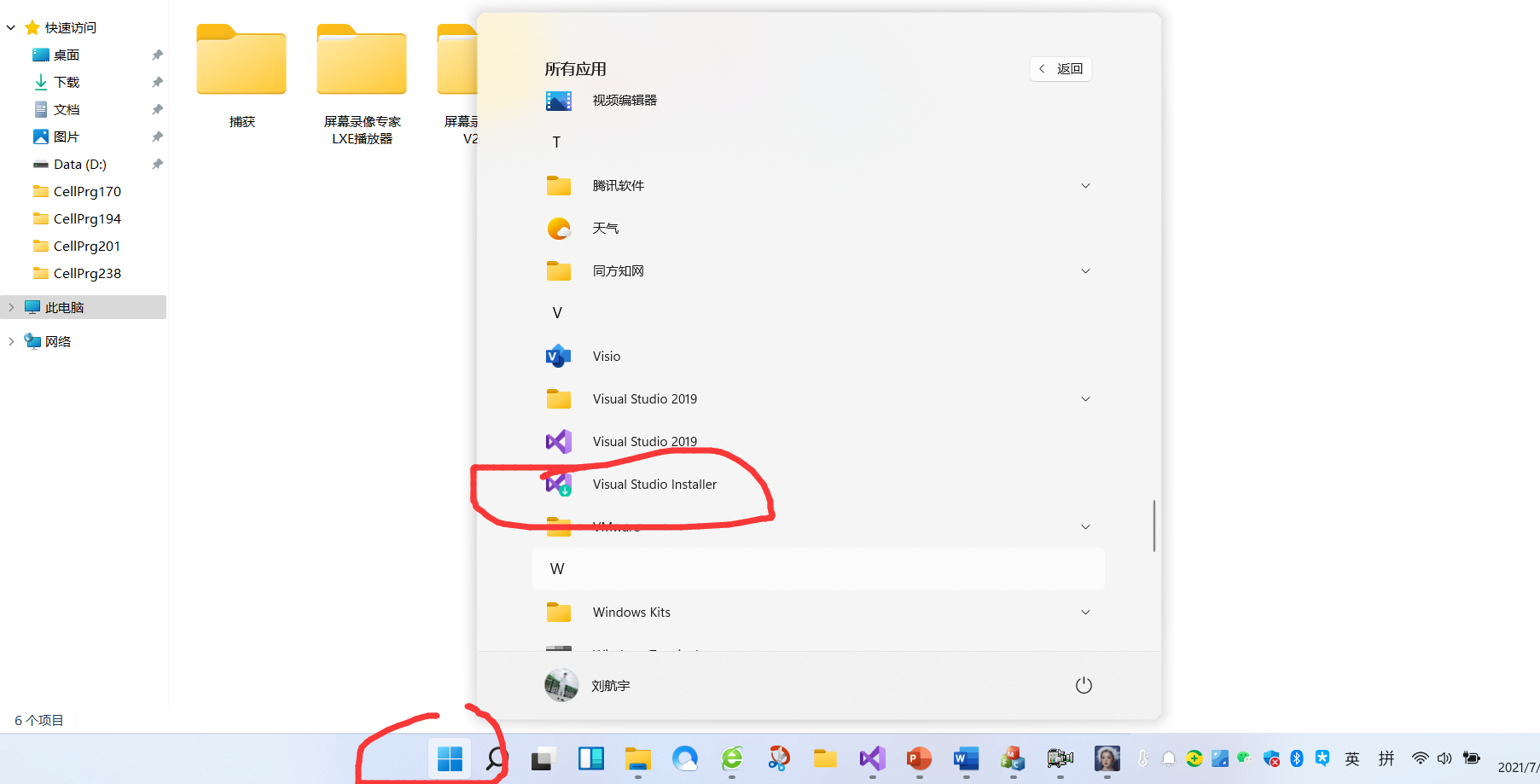
图像处理中VS2019下载及其MFC环境配置
安装环境配置 按照教程下载vs软件 https://mp.weixin.qq.com/s/dsqCMhO7r8zZ83Fc74gWbQ 完成后找到 图片 图片 图片 点击下载必须的mfc环境 图片 等待下载完毕即可
通信&信息处理
编程&脚本笔记
刘航宇
5年前
0
640
5
2021-07-02
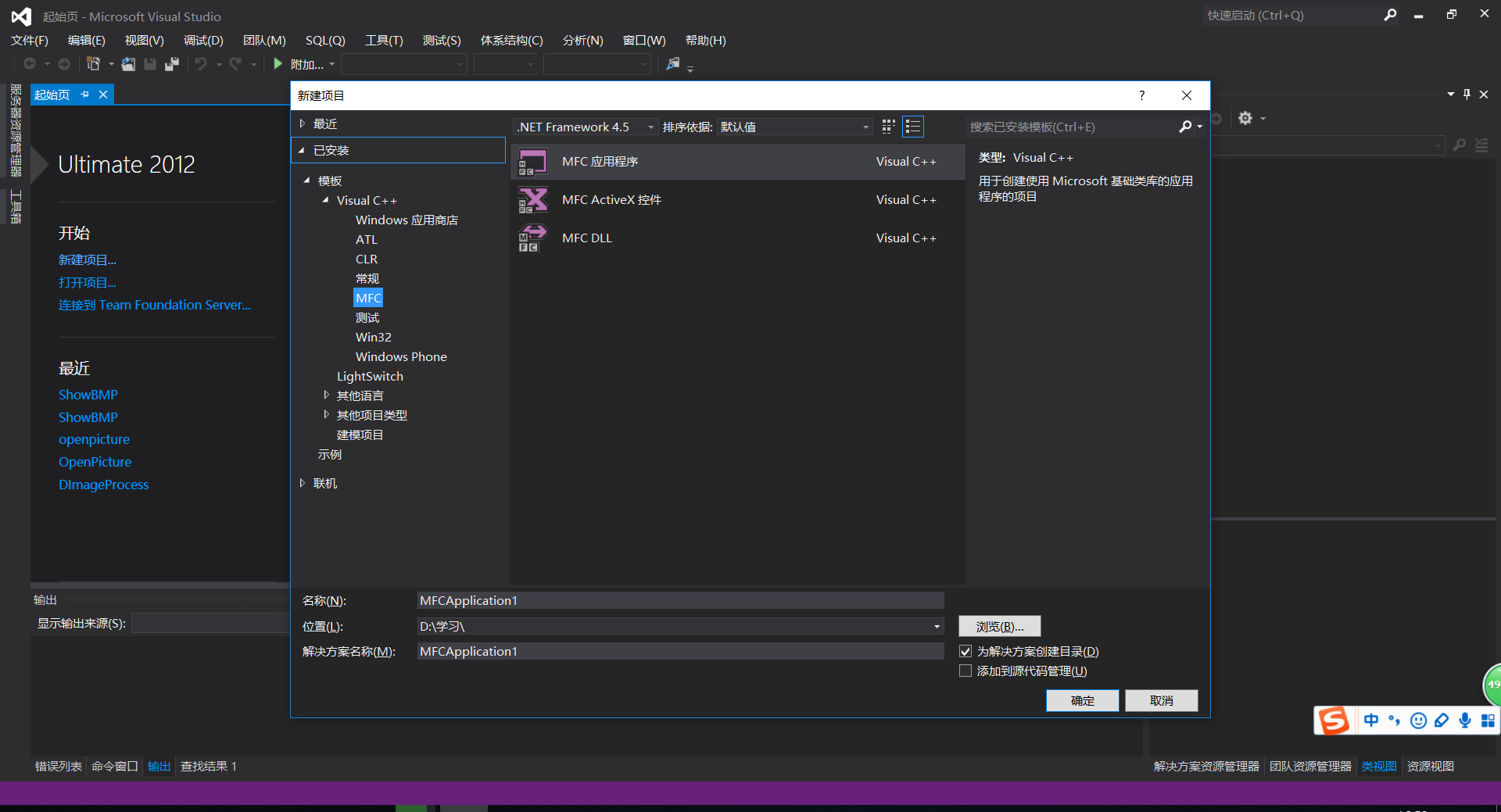
图像处理入门-MFC打开BMP图片
第一步:新建项目"MFC应用程序",项目名为ShowBMP,在应用程序类型中选择"单个文档",点击"确定" 图片 图片 第二步:向CShowBMPView类添加成员变量和成员函数.在右栏的"类视图"右键CShowBMPView添加函数或直接在ShowBMPView.h中直接添加public成员变量和成员函数.添加代码如下: public: //成员变量 CString BmpName; //保存图像文件文件名 CString EntName; //保存图像文件扩展名 CBitmap m_bitmap; //创建位图对象 //成员函数 void ShowBitmap(CDC* pDC, CString BmpName); //用来显示指定位图bmp的函数 第三步:设置打开BMP图片函数.“项目”->“类向导”->选择"类名"CShowBMPView->在命令对象ID中双击"ID_FILE_OPEN"->自动生成默认成员函数OnFileOpen,消息为COMMAND.双击成员函数(Member Functions)进入函数编辑. 图片 //**************文件打开****************// void CShowBMPView::OnFileOpen() { //四种格式的文件:bmp gif jpg tiff CString filter; filter = "所有文件(*.bmp,*.jpg,*.gif,*tiff)|*.bmp;*.jpg;*.gif;*.tiff| BMP(*.bmp)|*.bmp| JPG(*.jpg)|*.jpg| GIF(*.gif)|*.gif| TIFF(*.tiff)|*.tiff||"; CFileDialog dlg(TRUE, NULL, NULL, OFN_HIDEREADONLY, filter, NULL); //按下确定按钮 dlg.DoModal() 函数显示对话框 if (dlg.DoModal() == IDOK) { BmpName = dlg.GetPathName(); //获取文件路径名 如D:\pic\abc.bmp EntName = dlg.GetFileExt(); //获取文件扩展名 EntName.MakeLower(); //将文件扩展名转换为一个小写字符 Invalidate(); //调用该函数就会调用OnDraw重绘画图 } } 第四步:在ShowBMPView.cpp中编写void CShowBMPView::ShowBitmap(CDC *pDC, CString BmpName)函数,即“二.显示BMP图片基本步骤”.同时通过OnDraw()函数调用ShowBitmap()函数显示图片.代码如下: void CShowBMPView::OnDraw(CDC* pDC) { CShowBMPDoc* pDoc = GetDocument(); ASSERT_VALID(pDoc); if (!pDoc) return; // TODO: 在此处为本机数据添加绘制代码 if (EntName.Compare(_T("bmp")) == 0) //bmp格式 { ShowBitmap(pDC, BmpName); //显示图片 } } 第五步:添加“显示BMP格式图片”函数。 void CShowBMPView::ShowBitmap(CDC *pDC, CString BmpName) { //定义bitmap指针 调用函数LoadImage装载位图 HBITMAP m_hBitmap; m_hBitmap = (HBITMAP)LoadImage(NULL, BmpName, IMAGE_BITMAP, 0, 0, LR_LOADFROMFILE | LR_DEFAULTSIZE | LR_CREATEDIBSECTION); /*************************************************************************/ /* 1.要装载OEM图像,则设此参数值为0 OBM_ OEM位图 OIC_OEM图标 OCR_OEM光标 /* 2.BmpName要装载图片的文件名 /* 3.装载图像类型: /* IMAGE_BITMAP-装载位图 IMAGE_CURSOR-装载光标 IMAGE_ICON-装载图标 /* 4.指定图标或光标的像素宽度和长度 以像素为单位 /* 5.加载选项: /* IR_LOADFROMFILE-指明由lpszName指定文件中加载图像 /* IR_DEFAULTSIZE-指明使用图像默认大小 /* LR_CREATEDIBSECTION-当uType参数为IMAGE_BITMAP时,创建一个DIB项 /**************************************************************************/ if (m_bitmap.m_hObject) { m_bitmap.Detach(); //切断CWnd和窗口联系 } m_bitmap.Attach(m_hBitmap); //将句柄HBITMAP m_hBitmap与CBitmap m_bitmap关联 //边界 CRect rect; GetClientRect(&rect); //图片显示(x,y)起始坐标 int m_showX = 0; int m_showY = 0; int m_nWindowWidth = rect.right - rect.left; //计算客户区宽度 int m_nWindowHeight = rect.bottom - rect.top; //计算客户区高度 //定义并创建一个内存设备环境DC CDC dcBmp; if (!dcBmp.CreateCompatibleDC(pDC)) //创建兼容性的DC return; BITMAP m_bmp; //临时bmp图片变量 m_bitmap.GetBitmap(&m_bmp); //将图片载入位图中 CBitmap *pbmpOld = NULL; dcBmp.SelectObject(&m_bitmap); //将位图选入临时内存设备环境 //图片显示调用函数stretchBlt pDC->StretchBlt(0, 0, m_bmp.bmWidth, m_bmp.bmHeight, &dcBmp, 0, 0, m_bmp.bmWidth, m_bmp.bmHeight, SRCCOPY); /*******************************************************************************/ /* BOOL StretchBlt(int x,int y,int nWidth,int nHeight,CDC* pSrcDC, /* int xSrc,int ySrc,int nSrcWidth,int nSrcHeight,DWORD dwRop ); /* 1.参数x、y位图目标矩形左上角x、y的坐标值 /* 2.nWidth、nHeigth位图目标矩形的逻辑宽度和高度 /* 3.pSrcDC表示源设备CDC指针 /* 4.xSrc、ySrc表示位图源矩形的左上角的x、y逻辑坐标值 /* 5.dwRop表示显示位图的光栅操作方式 SRCCOPY用于直接将位图复制到目标环境中 /*******************************************************************************/ dcBmp.SelectObject(pbmpOld); //恢复临时DC的位图 DeleteObject(&m_bitmap); //删除内存中的位图 dcBmp.DeleteDC(); //删除CreateCompatibleDC得到的图片DC }图片
通信&信息处理
编程&脚本笔记
# 图像处理
刘航宇
5年前
0
663
4
2021-06-30
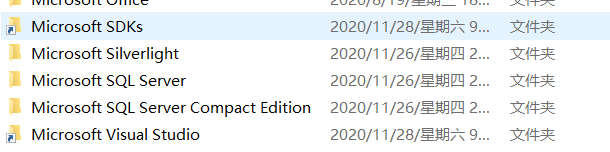
vs2019等版本完全安装到D盘方案-安装前必备
由于VS占用C盘内存过大,现提出一种完全安装到D盘方案,其实这个方案最早(20年11月)我发在了科学网上,也可以在这里观看 http://blog.sciencenet.cn/blog-3432403-1260218.html 第一步 从微软官网下载 Visual Studio Community 2019(其他版本类似) 运行下载的安装程序,到选择安装的组件时退出程序 第二步:使用 mklink 创建链接 原理:这一步的目的是欺骗 VS 安装程序,把它(将要或已经)放在系统盘的内容转移到其他盘,这样 VS 安装时仍然读写的是系统盘的路径,但实际上这些路径被我们转移到了非系统盘了,如此便释放了系统盘空间。 基本用法: mklink /d "链接需要放置的路径" "链接指向的路径" 以下为 VS 占用的系统盘文件夹路径(我的系统盘符是 C) C:\Program Files (x86)\Microsoft SDKs C:\Program Files (x86)\Microsoft Visual Studio C:\Program Files (x86)\Windows Kits C:\ProgramData\Microsoft\VisualStudio C:\ProgramData\Package Cache下面是一段代码示例(注意 cmd 以管理员身份运行):对上面那些文件夹移动完成后使用mklink /d创建链接即可知道了原理操作起来就十分简单, 这些必要的文件夹如果有文件在里面,就把这些文件夹移动到非系统盘,如果没有就删除他们 (因为之后我们要创建链接,不删除就不能用他们的名字创建链接) mklink /d "C:\Program Files (x86)\Microsoft SDKs" "D:\Program Files (x86)\Microsoft SDKs" mklink /d "C:\Program Files (x86)\Microsoft Visual Studio" "D:\Program Files (x86)\Microsoft Visual Studio" mklink /d "C:\Program Files (x86)\Windows Kits" "D:\Program Files (x86)\Windows Kits" mklink /d "C:\ProgramData\Microsoft\VisualStudio" "D:\ProgramData\Microsoft\VisualStudio" mklink /d "C:\ProgramData\Package Cache" "D:\ProgramData\Package Cache"图片 图片 目标文件夹可以自己根据喜好自定义,对安装无影响,但是需要注意要在D盘创建好C盘链接的目标文件夹,不然无法安装。 第三步:以正常方式安装 VS2019 第一步会在你的系统上装一个 Visual Studio Installer,这次直接运行这个程序安装。 注意:安装程序中自定义路径的那一步最好还是自定义到非系统盘,这样能最小化系统盘占用。 温馨提示:目标文件夹一定要创建好,不然从 C 盘点过去会提示不存在导致 VS 安装失败。 安装包及安装教程: https://mp.weixin.qq.com/s/dsqCMhO7r8zZ83Fc74gWbQ
通信&信息处理
编程&脚本笔记
刘航宇
5年前
0
1,364
2
1
2
下一页