首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,064 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,068 阅读
3
【高数】形心计算公式讲解大全
8,735 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,424 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,768 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
DL/ML(共2篇)
找到
2
篇与
DL/ML
相关的结果
2023-11-01
机器学习/深度学习-10个激活函数详解
图片 综述 1. Sigmoid 激活函数 2. Tanh / 双曲正切激活函数 3. ReLU 激活函数 4. Leaky ReLU 5. ELU 6. PReLU(Parametric ReLU) 7. Softmax 8. Swish 9. Maxout 10. Softplus 综述 激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。 在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式,本文概述了深度学习中常见的十种激活函数及其优缺点。 首先我们来了解一下人工神经元的工作原理,大致如下: 图片 上述过程的数学可视化过程如下图所示: 图片 1. Sigmoid 激活函数 lofj8ajx.png图片 Sigmoid 函数的图像看起来像一个 S 形曲线。 函数表达式如下: $$\[\mathrm{f(z)=1/(1+e^{\wedge}-z)}\]$$ 在什么情况下适合使用 Sigmoid 激活函数呢? Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化; 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适; 梯度平滑,避免「跳跃」的输出值; 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率; 明确的预测,即非常接近 1 或 0。 Sigmoid 激活函数有哪些缺点? 倾向于梯度消失; 函数输出不是以 0 为中心的,这会降低权重更新的效率; Sigmoid 函数执行指数运算,计算机运行得较慢。 2. Tanh / 双曲正切激活函数 图片 tanh 激活函数的图像也是 S 形,表达式如下: $$f(x)=tanh(x)=\frac{2}{1+e^{-2x}}-1$$ tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。 图片 首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好; 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。 注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。 3. ReLU 激活函数 图片 ReLU 激活函数图像如上图所示,函数表达式如下: 图片 ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点: 当输入为正时,不存在梯度饱和问题。 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快 当然,它也有缺点: Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题; 我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。 4. Leaky ReLU 它是一种专门设计用于解决 Dead ReLU 问题的激活函数: 图片 ReLU vs Leaky ReLU 为什么 Leaky ReLU 比 ReLU 更好? $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 1、Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题; 2、leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右; 3、Leaky ReLU 的函数范围是(负无穷到正无穷)。 注意:从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。 5. ELU 图片 ELU vs Leaky ReLU vs ReLU ELU 的提出也解决了 ReLU 的问题。与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零。均值激活接近于零可以使学习更快,因为它们使梯度更接近自然梯度。 图片 显然,ELU 具有 ReLU 的所有优点,并且: 没有 Dead ReLU 问题,输出的平均值接近 0,以 0 为中心; ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习; ELU 在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。 一个小问题是它的计算强度更高。与 Leaky ReLU 类似,尽管理论上比 ReLU 要好,但目前在实践中没有充分的证据表明 ELU 总是比 ReLU 好。 6. PReLU(Parametric ReLU) 图片 PReLU 也是 ReLU 的改进版本: $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 看一下 PReLU 的公式:参数α通常为 0 到 1 之间的数字,并且通常相对较小。 如果 a_i= 0,则 f 变为 ReLU 如果 a_i> 0,则 f 变为 leaky ReLU 如果 a_i 是可学习的参数,则 f 变为 PReLU PReLU 的优点如下: 在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU 问题。 与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。 7. Softmax 图片 Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。 图片 Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。 Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。 Softmax 激活函数的主要缺点是: 在零点不可微; 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。 8. Swish 图片 函数表达式:y = x * sigmoid (x) Swish 的设计受到了 LSTM 和高速网络中 gating 的 sigmoid 函数使用的启发。我们使用相同的 gating 值来简化 gating 机制,这称为 self-gating。 self-gating 的优点在于它只需要简单的标量输入,而普通的 gating 则需要多个标量输入。这使得诸如 Swish 之类的 self-gated 激活函数能够轻松替换以单个标量为输入的激活函数(例如 ReLU),而无需更改隐藏容量或参数数量。 Swish 激活函数的主要优点如下: 「无界性」有助于防止慢速训练期间,梯度逐渐接近 0 并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决); 导数恒 > 0; 平滑度在优化和泛化中起了重要作用。 9. Maxout 图片 在 Maxout 层,激活函数是输入的最大值,因此只有 2 个 maxout 节点的多层感知机就可以拟合任意的凸函数。 单个 Maxout 节点可以解释为对一个实值函数进行分段线性近似 (PWL) ,其中函数图上任意两点之间的线段位于图(凸函数)的上方。 $ReLU=\max\bigl(0,x\bigr),\mathrm{abs}\bigl(x\bigr)=\max\bigl(x,-x\bigr)$ Maxout 也可以对 d 维向量(V)实现: 图片 假设两个凸函数 h_1(x) 和 h_2(x),由两个 Maxout 节点近似化,函数 g(x) 是连续的 PWL 函数。 $$g\bigl(x\bigr)=h_1\bigl(x\bigr)-h_2\bigl(x\bigr)$$ 因此,由两个 Maxout 节点组成的 Maxout 层可以很好地近似任何连续函数。 图片 10. Softplus 图片 Softplus 函数:f(x)= ln(1 + exp x) Softplus 的导数为 f ′(x)=exp(x) / ( 1+exp x ) = 1/ (1 +exp(−x )) ,也称为 logistic / sigmoid 函数。 Softplus 函数类似于 ReLU 函数,但是相对较平滑,像 ReLU 一样是单侧抑制。它的接受范围很广:(0, + inf)。
机器学习
# 机器学习
# 软件算法
# DL/ML
刘航宇
3年前
0
593
0
2023-10-15
DL-神经网络的正向传播与反向传播
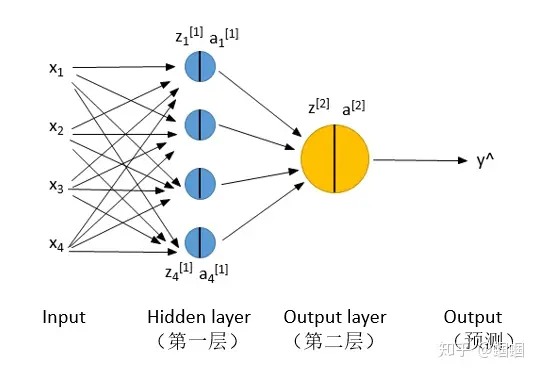
神经网络简述 前向传播 反向传播 四、深层神经网络(Deep Neural Network) 1.单个神经元 2.由神经元组成的神经网络 3.目标函数 4.求解损失函数对某个权值的梯度 5.反向传播算法Backpropgation 5.2 计算一个梯度 5.3 反向传播误差 6.优化示例 神经网络简述 神经网络,就是在Logistic regression的基础上增加了一个或几个隐层(hidden layer),下面展示的是一个最最最简单的神经网络,只有两层: 两层神经网络 图片 需要注意的是,上面的图是“两层”,而不是三层或者四层,输入和输出不算层! 这里,我们先规定一下记号(Notation): z是x和w、b线性运算的结果,z=wx+b; a是z的激活值; 下标的1,2,3,4代表该层的第i个神经元(unit); 上标的[1],[2]等代表当前是第几层。 y^代表模型的输出,y才是真实值,也就是标签 另外,有一点经常搞混: 上图中的x1,x2,x3,x4不是代表4个样本!而是一个样本的四个特征(4个维度的值)! 你如果有m个样本,代表要把上图的过程重复m次: 图片 神经网络的“两个传播”: 前向传播(Forward Propagation)前向传播就是从input,经过一层层的layer,不断计算每一层的z和a,最后得到输出y^ 的过程,计算出了y^,就可以根据它和真实值y的差别来计算损失(loss)。 反向传播(Backward Propagation)反向传播就是根据损失函数L(y^,y)来反方向地计算每一层的z、a、w、b的偏导数(梯度),从而更新参数。 前向传播和反向传播: 图片 每经过一次前向传播和反向传播之后,参数就更新一次,然后用新的参数再次循环上面的过程。这就是神经网络训练的整个过程。 前向传播 如果用for循环一个样本一个样本的计算,显然太慢,是使用Vectorization,把m个样本压缩成一个向量X来计算,同样的把z、a都进行向量化处理得到Z、A,这样就可以对m的样本同时进行表示和计算了。不熟悉的朋友可以看这里: 这样,我们用公式在表示一下我们的两层神经网络的前向传播过程: Layer 1:Z[1] = W[1]·X + b[1]A[1] = σ(Z[1]) Layer 2:Z[2] = W[2]·A[1] + b[2]A[2] = σ(Z[2]) 而我们知道,X其实就是A[0],所以不难看出:每一层的计算都是一样的: Layer i:Z[i] = W[i]·A[i-1] + b[i]A[i] = σ(Z[i]) (注:σ是sigmoid函数) 因此,其实不管我们神经网络有几层,都是将上面过程的重复。 对于 损失函数,就跟Logistic regression中的一样,使用 “交叉熵(cross-entropy)”,公式就是 二分类问题:L(y^,y) = -[y·log(y^ )+(1-y)·log(1-y^ )]- 多分类问题:L=-Σy(j)·y^(j) 这个是每个样本的loss,我们一般还要计算整个样本集的loss,也称为cost,用J表示,J就是L的平均: J(W,b) = 1/m·ΣL(y^(i),y(i)) 上面的求Z、A、L、J的过程就是正向传播。 反向传播 反向传播说白了根据根据J的公式对W和b求偏导,也就是求梯度。因为我们需要用梯度下降法来对参数进行更新,而更新就需要梯度。 但是,根据求偏导的链式法则我们知道,第l层的参数的梯度,需要通过l+1层的梯度来求得,因此我们求导的过程是“反向”的,这也就是为什么叫“反向传播”。 具体求导的过程,这里就不赘述了。像各种 深度学习框架TensorFlow、Keras,它们都是 只需要我们自己构建正向传播过程, 反向传播的过程是自动完成的,所以大家也确实不用操这个心。 进行了反向传播之后,我们就可以根据每一层的参数的梯度来更新参数了,更新了之后,重复正向、反向传播的过程,就可以不断训练学习更好的参数了。 四、深层神经网络(Deep Neural Network) 前面的讲解都是拿一个两层的很浅的神经网络为例的。 深层神经网络也没什么神秘,就是多了几个/几十个/上百个hidden layers罢了。 可以用一个简单的示意图表示: 深层神经网络: 图片 注意,在深层神经网络中,我们在中间层使用了 “ReLU”激活函数,而不是sigmoid函数了,只有在最后的输出层才使用了sigmoid函数,这是因为 ReLU函数在求梯度的时候更快,还可以一定程度上防止梯度消失现象,因此在深层的网络中常常采用。 关于深层神经网络,我们有必要再详细的观察一下它的结构,尤其是 每一层的各个变量的维度,毕竟我们在搭建模型的时候,维度至关重要。 图片 我们设: 总共有m个样本,问题为二分类问题(即y为0,1); 网络总共有L层,当前层为l层(l=1,2,...,L); 第l层的单元数为n[l];那么下面参数或变量的维度为: W[l]:(n[l],n[l-1])(该层的单元数,上层的单元数) b[l]:(n[l],1) z[l]:(n[l],1) Z[l]:(n[l],m) a[l]:(n[l],1) A[l]:(n[l],m) X:(n[0],m) Y:(1,m) 可能有人问,为什么 W和b的维度里面没有m? 因为 W和b对每个样本都是一样的,所有样本采用同一套参数(W,b), 而Z和A就不一样了,虽然计算时的参数一样,但是样本不一样的话,计算结果也不一样,所以维度中有m。 深度神经网络的正向传播、反向传播和前面写的2层的神经网络类似,就是多了几层,然后中间的激活函数由sigmoid变为ReLU了。 1.单个神经元 神经网络是由一系列神经元组成的模型,每一个神经元实际上做得事情就是实现非线性变换。 如下图就是一个神经元的结构: 图片 神经元将两个部分:上一层的输出(x1,x2,....,xn)与权重(w1,w2,....,wn),对应相乘相加,然后再加上一个偏置 b之后的值经过激活函数处理后完成非线性变换。 记 z = w ⋅ x + b ,a=σ(z),则 z 是神经元非线性变换之前的结果,这部分仅仅是一个简单的线性函数。σ 是Sigmod激活函数,该函数可以将无穷区间内的数映射到(-1,1)的范围内。a 是神经元将 z z 进行非线性变换之后的结果。 Sigmod函数图像如下图 $$\mathrm{sigmod(x)=\frac{1}{1+e^{-x}}}$$ 图片 因此,结果 a 就等于: 图片 这里再强调一遍,神经元的本质就是做非线性变换 2.由神经元组成的神经网络 神经元可以理解成一个函数,神经网络就是由很多个非线性变换的神经元组成的模型,因此神经网络可以理解成是一个非常复杂的复合函数。 图片 对于上图中的网络: (x1,x2,....,xn)为n维输入向量 Wij,表示后一层低i个神经元与前一层第j个神经元之间的权值 z = Wx + b是没有经过激活函数非线性变换之前的结果 a=σ(z),是 z 经过激活函数非线性变换之后的结果 \mathrm{s=U^Ta},为网络最终的输出结果。 3.目标函数 以折页损失为目标函数: $$\mathrm{minmizeJ}=\max(\Delta+s_{c}-s,0)$$ 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 一般来说,学习算法的学习过程就是优化调整参数,使得损失函数,或者说预测结果和实际结果的误差减小。BP算法其实是一个双向算法,包含两个步骤: 1.正向传递输入信息,得到 Loss 值。 2.反向传播误差,从而由优化算法来调整网络权值。 4.求解损失函数对某个权值的梯度 图片 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 对于上面的图, 假设图中指示出的网络中的某个权值 w$_\mathrm{jk}^\mathrm{l}$ 发生了一个小的改变 $\Delta w_\mathrm{jk}^\mathrm{l}$ , 假设网络最终损失函数的输出为$\mathbb{C}$,则 C 应该是关于 $\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 的一个复合函数。 所谓复合函数,就是把 $\mathbb{C}$ 看成因变量,则$\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 可以看成导致 C 改变的自变量, 比如假设有一个复 合函数 $\mathrm{y=f(g(x))}$,则 y 就好比这里的$\mathbb{C}$ , x 就好比$\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}$, w$_{jk}^{\mathrm{l}}$ 每经过一层网络可以看成是经过某个函数的处理。而下面求写的时候都用偏导数, 是因为虽然我们这里只关注了一个 w$_\mathrm{jk}^{\mathrm{l}}$,但是实际上网络中的每一个 w 都可以看成一个 x。 显然,这个$\Delta w_\mathrm{jk}^\mathrm{l}$的变化会引起下一层直接与其相连的一个神经元,以及下一层之后所有神经元直到 最终输出 C 的变化, 如图中蓝线标记的就是该权值变化的影响传播路径。 把 C 的改变记为 $\Delta\mathbb{C}$, 则根据高等数学中导数的知识可以得到: 则神经元 a$_\mathrm{j}^1$ 下面一层第 q 个与其相连的神经元 a$_{\mathrm{q}}^{1+1}$ 的变化为: $$ \Delta\mathrm{a_q^{1+1}}\approx\frac{\partial\mathrm{a_q^{1+1}}}{\partial\mathrm{a_j^1}}\Delta\mathrm{a_j^1} $$将 $(2)$ 代入 (3) 可以得到: $$ \Delta\mathrm{a_{q}^{l+1}}\:\approx\:\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\:\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\:\Delta\mathrm{w_{jk}^{l}} $$假设从 $\mathrm{a_j}^1$ 到 C的一条路径为$\mathrm{a_j}^1,\mathrm{a_q}^{1+1},...,\mathrm{a_n}^{\mathrm{L-1}},\mathrm{a_m}^{\mathrm{L}}$,则在该条路径上 C 的变化量 $\Delta C$ 为: $$\Delta\mathrm{C}\approx\frac{\partial\mathrm{C}}{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}\frac{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}\frac{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}{\partial\mathrm{a}_\mathrm{p}^\mathrm{L-2}}[USD3P]\frac{\partial\mathrm{a}_\mathrm{q}^\mathrm{l+1}}{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}\frac{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}{\partial\mathrm{w}_\mathrm{jk}^\mathrm{l}}\Delta\mathrm{w}_\mathrm{jk}^\mathrm{l}$$ 至此,我们已经得到了一条路径上的变化量, 其实本质就是链式求导法则,或者说是复合函数求导法则。那么整个的变化量就县把所有可能链路上的变化量加起来: $$\Delta\mathrm{C}\approx\sum_{\mathrm{minp[USD3P]q}}\frac{\partial\mathrm{C}}{\partial\mathrm{a_{m}^{L}}}\frac{\partial\mathrm{a_{m}^{L}}}{\partial\mathrm{a_{n}^{L-1}}}\frac{\partial\mathrm{a_{n}^{L-1}}}{\partial\mathrm{a_{p}^{L-2}}}[USD3P]\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\Delta\mathrm{w_{jk}^{l}}$$ $$\begin{aligned}\text{则 C 对某个权值 w}_{\mathrm{jk}}^{\dagger}&\text{的梯度为:}\\&\frac{\partial\mathrm{C}}{\partial\mathrm{w}_{\mathrm{jk}}^{\dagger}}\approx\sum_{\mathrm{nmp},<0}\frac{\partial\mathrm{C}}{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}\frac{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}\frac{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}{\partial\mathrm{a}_{\mathrm{p}}^{\mathrm{L}-2}}[USD3P]\frac{\partial\mathrm{a}_{\mathrm{q}}^{\mathrm{l}+1}}{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}\frac{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}{\partial\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}}\end{aligned}$$ 到这里从数学分析的角度来说,我们可以知道这个梯度是可以计算和求解的。 总结: 1.每两个神经元之间是由一条边连接的,这个边就是一个权重值,它是后一个神经元 z 部分,也就是未经激活函数非线性变换之前的结果对前一个神经元的 a 部分,也就是经激活函数非线性变换之后的结果的偏导数。 2.一条链路上所有偏导数的乘积就是这条路径的变化量。 3.所有路径变化量之和就是整个损失函数的变化量。 5.反向传播算法Backpropgation 5.1 明确一些定义 图片 对于上面的神经网络, 首先明确下面一些定义: 图片 5.2 计算一个梯度 假设损失函数为:J=(1+sc −s) 来计第一下 $\frac{\partial\mathrm{J}}{\partial\mathrm{W}_{14}^{(1)}}$,由于 s 是网络的输出, $\frac{\partial\mathrm{J}}{\partial\mathrm{s}}=-1$, 所以只需要计算$\frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}$ 即可。 而由于 s 激活函数就是1, 所以有: $$ \mathrm{s=a_1^{(3)}=z_1^{(3)}=W_{11}^{(2)}a_1^{(2)}+W_{12}^{(2)}a_2^{(2)}} $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial(\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}+\mathrm{W}_{12}^{(2)}\mathrm{a}_{2}^{(2)})}{\partial\mathrm{W}_{14}^{(1)}} $$图片 所以: $$\frac{\partial s}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}$$ 由于图片代入公式(9)可以得到 $$\begin{gathered} \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{z}_{1}^{(2)}}\frac{\partial\mathrm{z}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}1} \ =\operatorname{W}_{11}^{(2)}\mathfrak{\sigma}^{\prime}(\mathfrak{z}_{1}^{(2)})\frac{\partial(\mathfrak{b}_{1}^{(1)}+\sum_{\mathrm{k}}\mathfrak{a}_{\mathrm{k}}^{(1)}\mathfrak{W}_{1\text{k}} ^ { ( 1 ) })}{\partial\mathrm{W}_{14}^{(1)}} \end{gathered}$$ $$ \text{公式}(10)中\frac{\partial(\mathrm{h}_{1}^{(1)}+\sum_{k}a_{k}^{(1)}W_{1k}^{(1)})}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{a}_{4}^{(1)}。 $$此外还有一个更重要的变换, 同样的方法可以求出: $$ \frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}=\mathrm{W}_{11}^{(2)}\mathrm{\sigma}^{\prime}(\mathrm{z}_1^{(2)}) $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}\mathrm{a}_4^{(1)}=\delta_1^{(2)}\mathrm{a}_4^{(1)} $$并且结合前面对 $\delta_\mathrm{j}^{(\mathrm{k})}$ 的定义,公式 (10) 可以写成: 所以损失函数对任离一个网络权伯的梯度可以弓成两个值相乘的形式。对于$\mathrm{a}_4^{(1)}$,它是网络前向传递过程中的一个神经元的输出, 我们当然可以在网络前向传递的时候将它保存下来。而对于 $\delta_1^{(2)}$,它是反向传播过来的梯度,也就是 J 对 z 的梯度, 下面来者如何通过后面神经元的 $\delta_{\mathrm{i}}^{(\mathrm{k})}$ 反向传播得到 前一个神经元处的 $\delta_\mathrm{j}^{(k-1)}$ 。 5.3 反向传播误差 到这里需要注意,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,可以使用比如随机梯度下降算法等来进行学习。 反向传播算法传播的是误差,传播方向是从最后一层依次往前,这是一个迭代的过程。在上面的过程中,我们求得了损失函数对于某个权值的梯度,通过该处的梯度值,可以将其向前传播,得到前一个结点的梯度。 图片 $(k-1)$ 例如对于上面的图, 假设已经求出 z$^{(\mathrm{k})}$ 处的柠伊卡$^{(\mathrm{k})}$,则行误差仅照某杀连接路径, 传递到 $\mathrm{a_j}^{[\mathrm{l}]}$ per 处,则该处的梯度为$\delta_{\mathrm{i}}^{(\mathrm{k})}W_{\mathrm{ij}}^{(\mathrm{k}-1)}$。实际上这只是一条路径, $\mathrm{a_j}^{(\mathrm{k-1})}$处可能会收到很多个不同的误差, 例如下面该神经元后面有两条权值 边的情况: 图片 这个时候只要把它们相加就好了,所以 a$_{\mathrm{j}}^{(\mathrm{k}-1)}$处,则该处的梯度为$\sum_{\mathrm{i}}\delta_{\mathrm{i}}^{(\mathrm{k})}\mathrm{W}_{\mathrm{ij}}^{(\mathrm{k}-1)}$。 图片 6.优化示例 再次说一下,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,还需要使用比如随机梯度下降算法等来进行学习。 在上面的过程中, 我们通过反向传播弹法求解出了任意一个$z_j^{(\mathrm{i})}$处的梯度$\delta_j^{(\mathrm{i})}$,为什么是$z_j^{(\mathrm{i})}$而不是$a_j^{(\mathrm{i})}$,因为$z_j^{(\mathrm{i})}$前面就是连接它的w,以随机梯度下降算法为例,w的优化方法为: $$\mathrm{w_{ijnew}^{(1)}=w_{ijold}^{(1)}-\eta\cdot\frac{\partial J}{\partial w_{ij}^{(1)}}=w_{ijold}^{(1)}-\eta\cdot\delta_{i}^{(1+1)}\cdot a_{j}^{(1)}}$$
机器学习
# DL/ML
刘航宇
3年前
0
577
2