首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,250 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,181 阅读
3
【高数】形心计算公式讲解大全
8,771 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,474 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,880 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
Python(共2篇)
找到
2
篇与
Python
相关的结果
2023-07-23
Python机器学习- 鸢尾花分类
1、描述 2、code 3、描述 4、code 1、描述 请编写代码实现train_and_predict功能,实现能够根据四个特征对三种类型的鸢尾花进行分类。 train_and_predict函数接收三个参数: train_input_features—二维NumPy数组,其中每个元素都是一个数组,它包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 train_outputs—一维NumPy数组,其中每个元素都是一个数字,表示在train_input_features的同一行中描述的鸢尾花种类。0表示鸢尾setosa,1表示versicolor,2代表Iris virginica。 prediction_features—二维NumPy数组,其中每个元素都是一个数组,包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 该函数使用train_input_features作为输入数据,使用train_outputs作为预期结果来训练分类器。请使用训练过的分类器来预测prediction_features的标签,并将它们作为可迭代对象返回(如list或numpy.ndarray)。结果中的第n个位置是prediction_features参数的第n行。 2、code # 导入numpy库,用于处理多维数组 import numpy as np # 导入sklearn库中的数据集、模型选择、度量和朴素贝叶斯模块 from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.naive_bayes import GaussianNB # 定义train_and_predict函数,接收三个参数:训练输入特征、训练输出标签和预测输入特征 def train_and_predict(train_input_features, train_outputs, prediction_features): # 创建一个高斯朴素贝叶斯分类器对象 clf = GaussianNB() # 使用训练输入特征和训练输出标签来训练分类器 clf.fit(train_input_features, train_outputs) # 使用预测输入特征来预测输出标签,并将结果返回 y_pred = clf.predict(prediction_features) return y_pred # 加载鸢尾花数据集,包含150个样本,每个样本有四个特征和一个标签 iris = datasets.load_iris() # 将数据集随机分成训练集和测试集,其中训练集占70%,测试集占30%,并设置随机种子为0 X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3, random_state=0 ) # 调用train_and_predict函数,使用训练集来训练分类器,并使用测试集来预测标签,将结果赋值给y_pred y_pred = train_and_predict(X_train, y_train, X_test) # 如果y_pred不为空,打印预测标签和真实标签的准确率,即正确预测的比例 if y_pred is not None: print(metrics.accuracy_score(y_test, y_pred))3、描述 机器学习库 sklearn 自带鸢尾花分类数据集,分为四个特征和三个类别,其中这三个类别在数据集中分别表示为 0, 1 和 2,请实现 transform_three2two_cate 函数的功能,该函数是一个无参函数,要求将数据集中 label 为 2 的数据进行移除,也就是说仅保留 label 为 0 和为 1 的情况,并且对 label 为 0 和 1 的特征数据进行保留,返回值为 numpy.ndarray 格式的训练特征数据和 label 数据,分别为命名为 new_feat 和 new_label。 然后在此基础上,实现 train_and_evaluate 功能,并使用生成的 new_feat 和 new_label 数据集进行二分类训练,限定机器学习分类器只能从逻辑回归和决策树中进行选择,将训练数据和测试数据按照 8:2 的比例进行分割。 要求输出测试集上的 accuracy_score,同时要求 accuracy_score 要不小于 0.95。 4、code #导入numpy库,它是一个提供了多维数组和矩阵运算等功能的Python库 import numpy as np #导入sklearn库中的datasets模块,它提供了一些内置的数据集 from sklearn import datasets #导入sklearn库中的model_selection模块,它提供了一些用于模型选择和评估的工具,比如划分训练集和测试集 from sklearn.model_selection import train_test_split #导入sklearn库中的preprocessing模块,它提供了一些用于数据预处理的工具,比如归一化 from sklearn.preprocessing import MinMaxScaler #导入sklearn库中的linear_model模块,它提供了一些线性模型,比如逻辑回归 from sklearn.linear_model import LogisticRegression #导入sklearn库中的metrics模块,它提供了一些用于评估模型性能的指标,比如F1分数、ROC曲线面积、准确率等 from sklearn.metrics import f1_score,roc_auc_score,accuracy_score #导入sklearn库中的tree模块,它提供了一些树形模型,比如决策树 from sklearn.tree import DecisionTreeClassifier #定义一个函数transform_three2two_cate,它的作用是将鸢尾花数据集中的三分类问题转化为二分类问题 def transform_three2two_cate(): #从datasets模块中加载鸢尾花数据集,并赋值给data变量 data = datasets.load_iris() #其中data特征数据的key为data,标签数据的key为target #需要取出原来的特征数据和标签数据,移除标签为2的label和特征数据,返回值new_feat为numpy.ndarray格式特征数据,new_label为对应的numpy.ndarray格式label数据 #需要注意特征和标签的顺序一致性,否则数据集将混乱 #code start here #使用numpy库中的where函数找出标签为2的索引,并赋值给index_arr变量 index_arr = np.where(data.target == 2)[0] #使用numpy库中的delete函数删除特征数据中对应索引的行,并赋值给new_feat变量 new_feat = np.delete(data.data, index_arr, 0) #使用numpy库中的delete函数删除标签数据中对应索引的元素,并赋值给new_label变量 new_label = np.delete(data.target, index_arr) #code end here #返回新的特征数据和标签数据 return new_feat,new_label #定义一个函数train_and_evaluate,它的作用是用决策树分类器来训练和评估鸢尾花数据集 def train_and_evaluate(): #调用transform_three2two_cate函数,得到新的特征数据和标签数据,并赋值给data_X和data_Y变量 data_X,data_Y = transform_three2two_cate() #使用train_test_split函数,将数据集划分为训练集和测试集,其中测试集占20%,并赋值给train_x,test_x,train_y,test_y变量 train_x,test_x,train_y,test_y = train_test_split(data_X,data_Y,test_size = 0.2) #已经划分好训练集和测试集,接下来请实现对数据的训练 #code start here #创建一个决策树分类器的实例,并赋值给estimator变量 estimator = DecisionTreeClassifier() #使用fit方法,用训练集的特征和标签来训练决策树分类器 estimator.fit(train_x, train_y) #使用predict方法,用测试集的特征来预测标签,并赋值给y_predict变量 y_predict = estimator.predict(test_x) #code end here #注意模型预测的label需要定义为 y_predict,格式为list或numpy.ndarray #使用accuracy_score函数,计算测试集上的准确率分数,并打印出来 print(accuracy_score(y_predict,test_y)) #如果这个文件是作为主程序运行,则执行以下代码 if __name__ == "__main__": #调用train_and_evaluate函数 train_and_evaluate() #要求执行train_and_evaluate()后输出为: #1、{0,1},代表数据label为0和1 #2、测试集上的准确率分数,要求>0.95
机器学习
# 机器学习
# Python
刘航宇
3年前
0
477
0
算法-反转链表C&Python实现
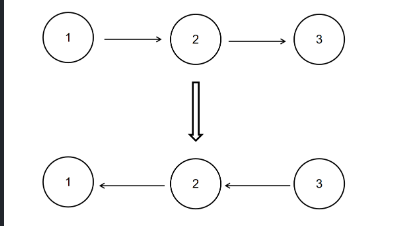
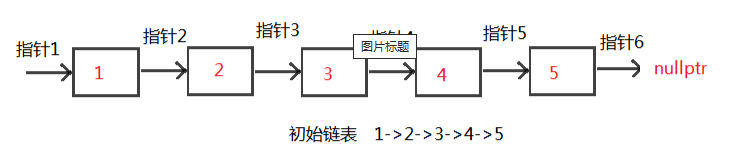
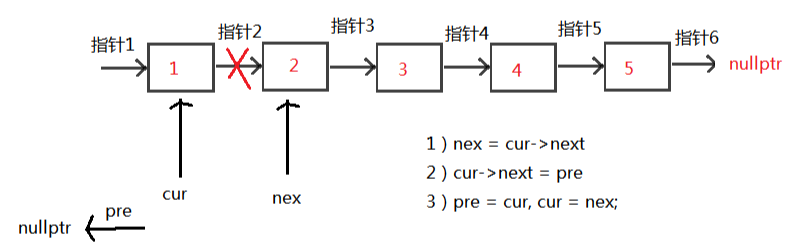
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
318
1