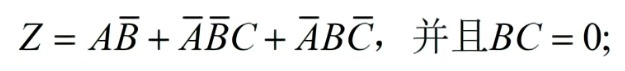首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,076 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,074 阅读
3
【高数】形心计算公式讲解大全
8,736 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,424 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,774 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
软硬件算法(共8篇)
找到
8
篇与
软硬件算法
相关的结果
通讯等不确定性条件下设计无人机之间的安全距离
引用文章: 简介 1. 研究问题 2. 分离原理介绍 3. 安全半径设计 4. 仿真及实验验证 引用文章: Q. Quan, R. Fu and K. -Y. Cai, "How Far Two UAVs Should Be subject to Communication Uncertainties," in IEEE Transactions on Intelligent Transportation Systems, doi: 10.1109/TITS.2022.3213555. 简介 近年来,无人机技术的快速发展使得低空空域中无人机的数量爆炸增长。碰撞避免作为无人机应用的关键技术,近年来人们已经进行了大量研究,设计出各种方法使得无人机在飞行过程中与障碍物保持一定安全距离(本文将该距离称为无人机的 安全半径)。然而, 在碰撞避免相关研究中,不确定性往往是难以处理的问题。针对不确定性,主流的方法包括对不确定性进行预测,以及在闭环控制中给予补偿。然而,以上方法很依赖于预测及补偿的精准设计,设计不当将有可能导致控制器失效。本研究受地面交通中车辆间安全距离启发,基于对通信不确定性和无人机控制器性能的假设,提出了 安全半径设计和控制器设计的原则 (本文称为 分离原理 )。进一步,安全半径具体通常通过经验预先设计,如果设计得过大或过小将分别影响无人机飞行的高效性及安全性。 如何根据无人机模型及通信不确定性确定其安全半径下界仍然是悬而未决的问题 。利用分离原理,本文研究了 设计阶段(无不确定性)和飞行阶段(受不确定性影响)的无人机安全半径设计 。最后,通过仿真和实验表明了所提方法的有效性。 图片 1. 研究问题 本研究中,无人机与障碍物的运动模型均建模为多旋翼模型,换句话说,我们考虑的障碍物可以等效为另一架多旋翼飞行器。对于多旋翼飞行器而言,其可以获得自身以及障碍物的实时位置和速度。为简单描述起见,本文建模均为二维,类似的建模及分析方法可以扩展到三维情况。 我们首先建立多旋翼的具体控制模型如下。 其中多旋翼的位置和速度分别表示为 ,速度控制模型建立为一阶惯性环节,其时间常数 与无人机的机动性能相关,控制输入 为期望速度。在此基础上,本文定义一种新的滤波位置模型如下。 多旋翼滤波位置的物理意义是根据多旋翼的当前位置、速度及机动能力,对其运动趋势预测。在此基础上,定义多旋翼的安全区域为以滤波位置为圆心的圆形区域,其半径称为安全半径 。对于障碍物,我们类似定义其滤波位置,以及以障碍物滤波位置为圆心的圆形障碍物区域,半径称为障碍物半径 。 图片 进一步,我们针对不确定性做了以下2点假设:(1)无人机和障碍物对自身的三维位置及三维速度估计均存在噪声;(2)无人机在获取障碍物状态信息时,存在通信延迟及丢包。该通信网络模型如下图所示。 图片 本研究中,丢包模型进一步建模为均值模型,且假设估计噪声、通信延迟、丢包均值模型误差均存在上界且上界已知。其数学定义如下: 图片 进一步,本文对无人机的控制器性能做出如下假设:(1)在无不确定性的理想状态下,无人机的控制器可以使无人机和障碍物之间的 真实距离 始终大于给定安全距离;(2)在存在以上不确定性的实际情况中,无人机的控制器可以使无人机和障碍物之间的 估计距离 始终保持给定安全距离。本研究的具体目标是在不确定性上界已知的条件下计算出无人机安全半径的下界。 图片 2. 分离原理介绍 无人机在理想状态下设计的控制器中给定的安全半径值 ,在实际含有不确定性的环境中将转化为估计安全半径 ;直观上理解,将含有不确定性的无人机与障碍物之间的估计位置误差代替真实位置误差作为反馈时,控制器将难以维持给定的安全半径。本研究中, 分离原理具体研究的是不确定性在满足什么条件时无人机的控制器设计和安全半径设计过程可分离 ,也就是估计安全半径和安全半径相等, 成立。分离原理具体数学描述如下: 图片 分离原理中提出的三个条件包括一个充分必要条件(i)以及两个充分条件(ii)和(iii)。其中,条件(i)为理论推导,在实际中难以得到验证,通常可通过条件(ii)和(iii)进行验证。条件(ii)对无人机速度的限制较宽,该式在障碍物主动躲避无人机的条件下容易达成。反之,条件(iii)对无人机速度的限制较苛刻,要求无人机速度严格大于障碍物速度,适用于在障碍物不主动躲避无人机的情况下。以上两种情况的区别如下图所示。 图片 3. 安全半径设计 根据上述分离原理的提出,在分离原理满足的前提下,基于无人机的安全半径模型和通信网络模型,可以进一步设计 合适大小的无人机安全半径 。如前文所述,安全半径设计过大会增加环境的冗余度,设计过小则无法保证飞行过程的安全。在本研究中,给出了在理想情况下以及实际情况下安全半径的下界,分别如下: 图片 4. 仿真及实验验证 仿真及实验验证在仿真中,我们针对单障碍物、多非合作障碍物、多合作障碍物设计了三种场景来验证我们方法的有效性。在实验中,我们使用DJI tello无人机对以上情况进行测试,结果与我们的理论一致。实验视频: https://youtu.be/LkSDPFGa_1E 论文地址 https://rfly.buaa.edu.cn/pdfs/2022/How_far_two_UAVs_should_be_subject_to_communication_uncertainties.pdf
软硬件算法
# 软件算法
刘航宇
2年前
0
934
1
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
497
0
算法-反转链表C&Python实现
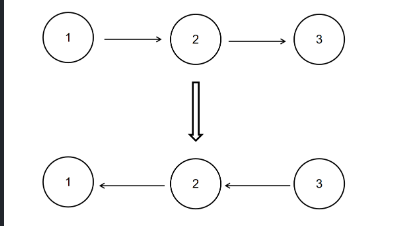
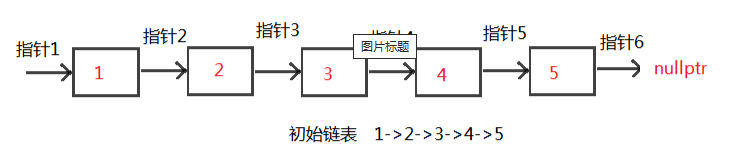
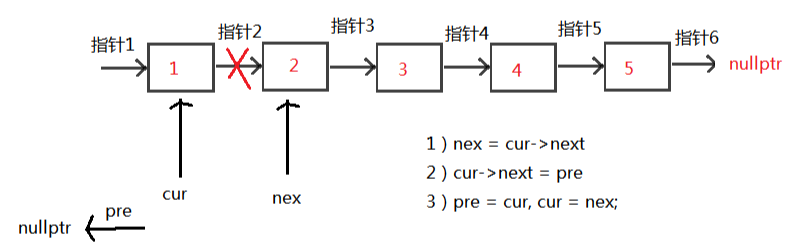
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
312
1
FPGA&Matlab联合开发之滤波器模块(带通滤波器为例)
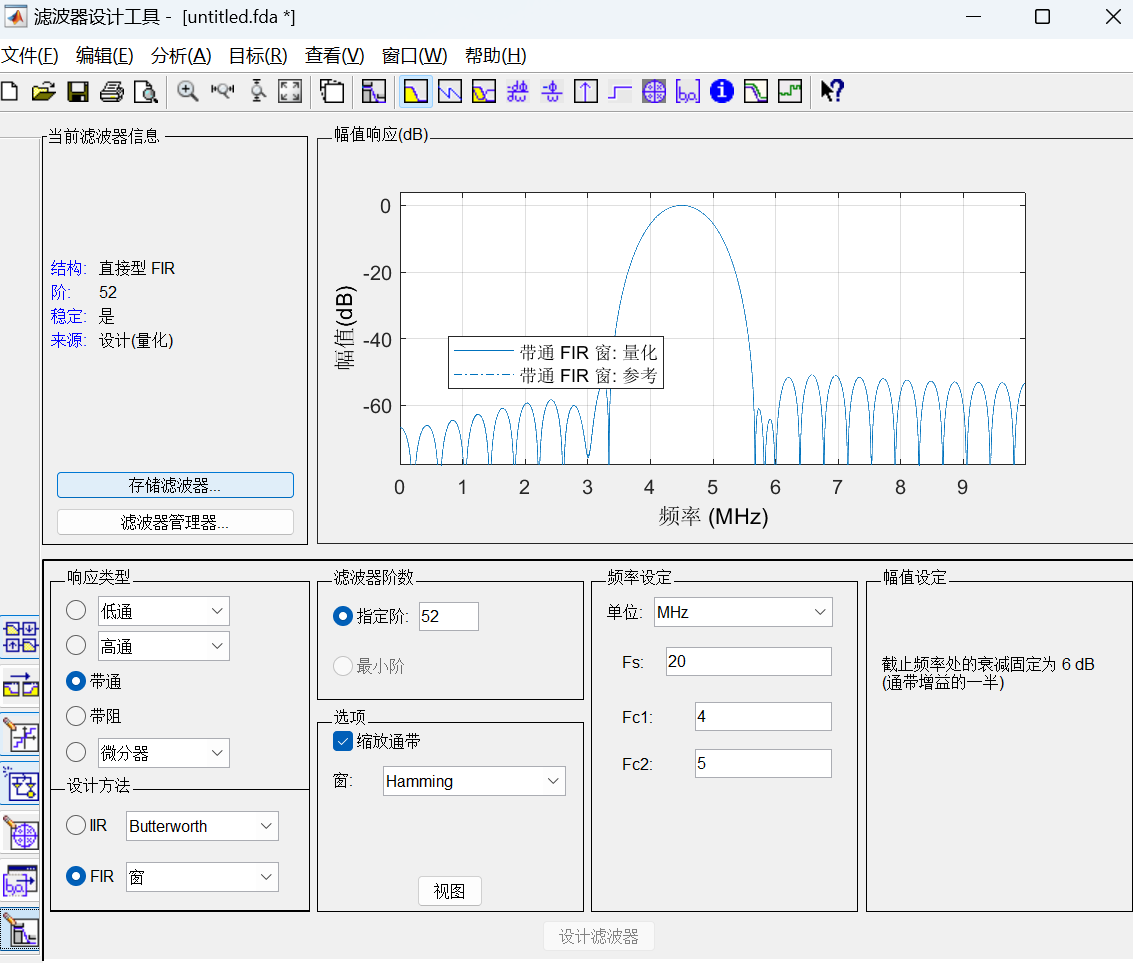
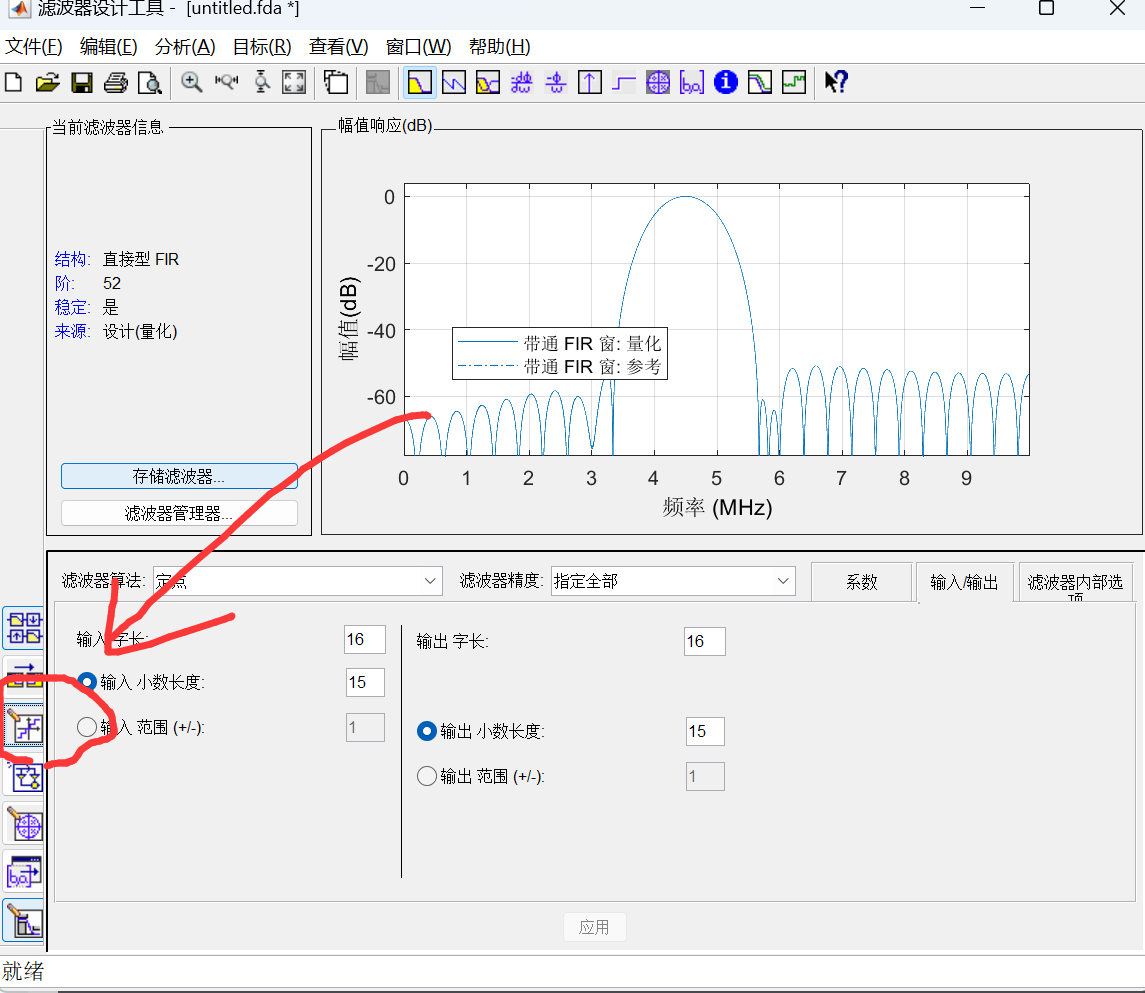
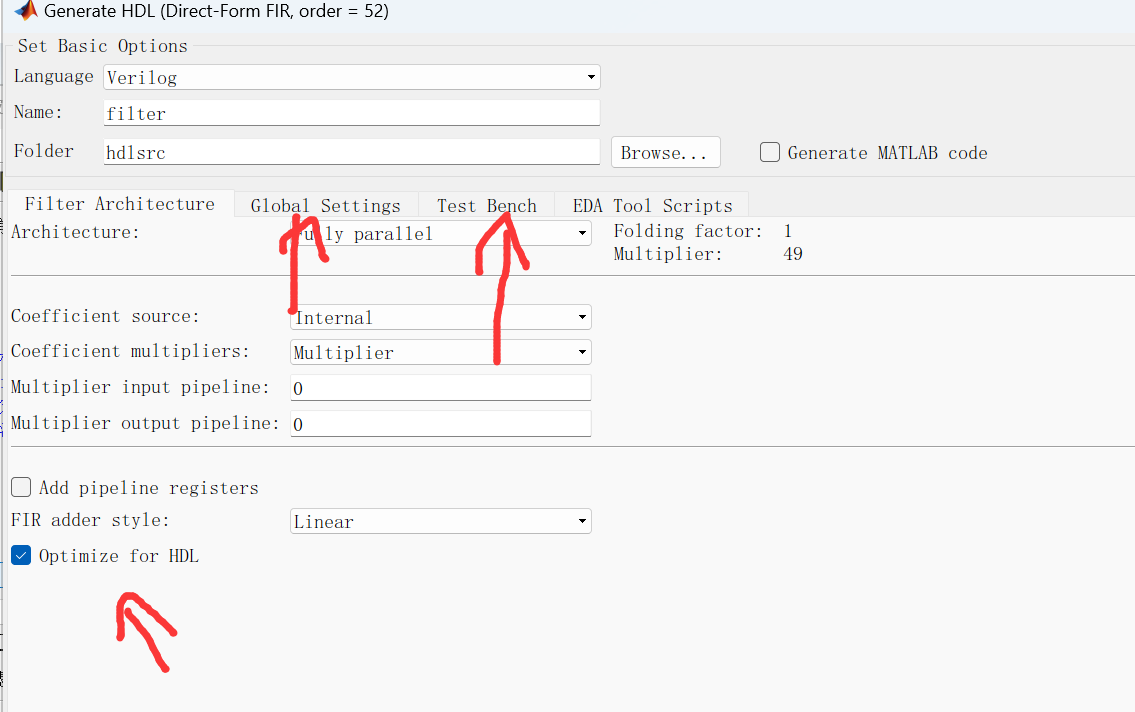
在通信或者信号处理中,数字滤波器是非常重要的模块,前面有关博文中提到FIR滤波器的一步步Verilog设计,如https://ee.ac.cn/index.php/archives/511.html 本文以带通滤波器为例,利用Matlab进行高效开发 目录 MATLAB生成低通滤波器设计步骤: Modelsim仿真上述文件 MATLAB生成低通滤波器设计步骤: (1)在MATLAB命令窗口中输入“filterDesigner”或“fdatool”出现如下对话框 image.png图片 设置FIR滤波器为和需要的阶数滤波器,选择窗函数的类型为海明窗函数,海明窗函数可以得到旁瓣更小的效果,能量更加集中在主瓣中 设置带通滤波器的上下截至频率分别为4MHz 和 5MHz (2)量化输入输出,点击工作栏左边的量化选项,即“set quantization parameters”选项,选择定点,设置输入字长为8,其他选择默认,如下图示: image.png图片 (3)根据自己需求,细化一些配置。这里不难探索 设置完成后,点击Targets中Generate HDL,选择生成Verilog 代码,设置路径,MATLAB即可生成设计好的滤波器Verilog HDL 代码以及测试文件: image.png图片 (4)根据需求,配置输出.v文件的全局信号、测试文件,点击生成,生成后,Matlab主页面会提示.v生成的文件路径 Modelsim仿真上述文件 image.png图片 可以看到输入信号在4MHZ~5MHZ备保留,设计无误。需要注意一点,一般Modelsim仿真输出波形都是离散的01信号,这里需要配置一下,在上图被选中的信号中,在左侧右键鼠标。 右击,format,analog(automatic); 右击,radix,decimal; 这两个步骤完成之后,就出现上图模拟信号的效果
嵌入式&系统
FPGA&ASIC
通信&信息处理
软硬件算法
# ASIC/FPGA
# 信号处理
# 硬件算法
刘航宇
3年前
0
569
2
2023-05-15
机器学习代码实现:线性回归与岭回归
1.线性回归模型 线性回归模型是最简单的一种线性模型,模型的形式就是: $y=W^T x+b$ 我们可以通过对原本的输入向量x扩增一个为1的维度将参数W和b统一成一个参数W,即模型变成了 $y=W^T x$ 这里的W是原本两个参数合并之后的而其损失函数的形式是残差平方损失RSS $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)$ 我们很容易就可以通过求导得到线性回归模型的关于W的梯度 $\nabla_W L=\frac{1}{m} \sum_{i=1}^m\left(W^T x_i-y_i\right) x_i=\frac{1}{m} X^T\left(W^T X-y\right)$ 这样一来我们就可以通过梯度下降的方式来训练参数W,可以用下面的公式表示 $W:=W-\alpha \frac{1}{m} X^T\left(W^T X-y\right)$ 但实际上线性模型的参数W可以直接求解出,即: $W=\left(X^T X\right)^{-1} X^T y$ 2.线性回归的编程实现 具体代码中的参数的形式可能和上面的公式推导略有区别,我们实现了一个LinearRegression的类,包含fit,predict和loss三个主要的方法,fit方法就是求解线性模型的过程,这里我们直接使用了正规方程来解 class LinearRegression: def fit(self, X: np.ndarray, y: np.ndarray) -> float: N, D = X.shape # 将每个样本的特征增加一个维度,用1表示,使得bias和weight可以一起计算 # 这里在输入的样本矩阵X末尾增加一列来给每个样本的特征向量增加一个维度 # 现在X变成了N*(D+1)维的矩阵了 expand_X = np.column_stack((X, np.ones((N, 1)))) self.w = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X)), expand_X.T), y) return self.loss(X, y)predict实际上就是将输入的矩阵X放到模型中进行计算得到对应的结果,loss给出了损失函数的计算方式: def loss(self, X: np.ndarray, y: np.ndarray): """ 线性回归模型使用的是RSS损失函数 :param X:需要预测的特征矩阵X,维度是N*D :param y:标签label :return: """ delta = y - self.predict(X) total_loss = np.sum(delta ** 2) / X.shape[0] return total_loss3.岭回归Ridge Regression与代码实现 岭回归实际上就是一种使用了正则项的线性回归模型,也就是在损失函数上加上了正则项来控制参数的规模,即: $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2+\lambda\|W\|_2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)+\lambda W^T W$ 因此最终的模型的正规方程就变成了: $W=\left(X^T X+\lambda I\right)^{-1} X^T y$ 这里的\lambda是待定的正则项参数,可以根据情况选定,岭回归模型训练的具体代码如下 class RidgeRegression: def fit(self, X: np.ndarray, y: np.ndarray): N, D = X.shape I = np.identity(D + 1) I[D][D] = 0 expand_X = np.column_stack((X, np.ones((N, 1)))) self.W = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X) + self.reg * I), expand_X.T), y) return self.loss(X, y)4.数据集实验 这里使用了随机生成的二位数据点来对线性模型进行测试,测试结果如下: image.png图片 线性模型测试结果 岭回归也使用同样的代码进行测试。
机器学习
软硬件算法
# 机器学习
# 软件算法
刘航宇
3年前
0
315
1
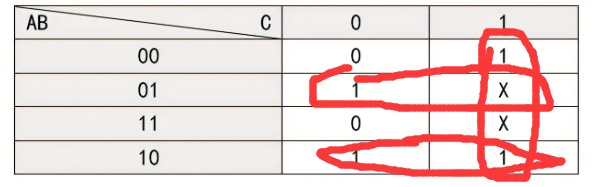
联发科2024年数字IC设计验证实习生考题解析
总体而言难度中等偏上,如有错误欢迎指正,考察感觉更像是考察嵌入式工程师(有STM32、FPGA基础就很轻松):有数电、模电、python、verilog、C语言、SOC系统等基础知识,可以看到其实很对口电子信息类专业如电子信息、微电子、通信工程、电子科学、集成电路等专业,没有考察模集如果考模集大部分人要G,数集也没考,可能太底层了与工业界需求有偏差,数集在笔试面试中我认为如果考,可能考时序与功耗部分。这里的Round-Robin算法很值得学习。 目录 1、(20分)逻辑化简: 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 3、(10分)智力题 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 1、(20分)逻辑化简: 图片 (1)列出真值表 (2)列出其卡诺图 (3)写出Z的最简表达式 答:卡诺图:卡诺图画完后勾1就完事了 提示:约束项的一般形式为:与或式 = 0 (如果不是此种形式,化为此种形式);如此题的BC = 0;或者AB +CD = 0;ABC + CD = 0;等等。BC=0(即B=1,且C=1)对应的格子画X。 图片 图片 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 答:ASIC flow 中综合工具的作用是将RTL级的硬件描述语言转换为与特定工艺库相匹配的门级网表,同时进行优化以满足时序、面积和功耗等约束。 综合的时候需要SDC文件进行约束,SDC文件是一种基于Tcl的格式,用于指定设计的时序约束34。SDC文件中的常用时序约束语法有: create_clock -name <clock_name> -period <clock_period> [get_ports <clock_port>] 用于创建时钟源并指定时钟周期。 set_input_delay -clock <clock_name> <delay_value> [get_ports <input_port>] 用于指定输入端口相对于时钟源的延迟。 set_output_delay -clock <clock_name> <delay_value> [get_ports <output_port>] 用于指定输出端口相对于时钟源的延迟。 set_clock_uncertainty -setup <setup_value> -hold <hold_value> <clock_name> 用于指定时钟源的不确定性,包括建立时间和保持时间。 set_false_path -from [get_ports <source_port>] -to [get_ports <destination_port>] 用于指定不需要进行时序分析的路径。 set_multicycle_path -setup -from [get_clocks <source_clock>] -to [get_clocks <destination_clock>] <cycle_number> 用于指定多周期路径,即源时钟和目标时钟之间有多个周期的时间差。3、(10分)智力题 (1)2 12 1112 3112 132112 ,下一个数?给理由; 答:第一个数是2,第二个数是12,表示前一个数有1个2;第三个数是1112,表示前一个数有1个1和1个2;以此类推。所以,下一个数是1113122112,表示前一个数有1个1,1个3,2个1和2个2 (2)有一个小偷费劲力气进入到了银行的金库里。在金库里他找到了一百个箱子,每一个箱子里都装满了金币。不过,只有一个箱子里装的是真的金币,剩下的99个箱子里都是假的。真假金币的外形和质感完全一样,任何人都无法通过肉眼分辨出来。它们只有一个区别:真金币每一个重量为101克,而假金币的重量是100克。在金库里有一个电子秤,它可以准确地测量出任何物品的重量,精确到克。但很不幸的是,这个电子秤和银行的报警系统相连接,只要被使用一次就会立刻失效。请问,小偷怎么做才能只使用一次电子秤就找到装着真金币的箱子呢? 答:小偷可以这样做:从第一个箱子里拿出1个金币,从第二个箱子里拿出2个金币,从第三个箱子里拿出3个金币,以此类推,直到从第一百个箱子里拿出100个金币。然后,把所有拿出来的金币放在电子秤上,测量它们的总重量。如果所有的金币都是假的,那么总重量应该是5050克(等于1+2+3+…+100)。如果有一个箱子里是真的金币,那么总重量会比5050克多出一些。这个多出来的部分就是真金币的数量乘以1克。例如,如果第十一个箱子里是真的金币,那么总重量会比5050克多出11克,因为从第十一个箱子里拿出了11个真金币。所以,小偷只要看电子秤上显示的数字减去5050,就能知道哪个箱子里是真的金币了。 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 答:优先答ASIC的设计与验证项目,其次是FPGA项目(如基于FPGA的图像处理、天线阵、雷达、加速器等等),其它项目不要答。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 # 定义冒泡排序函数 def bubble_sort(lst): # 获取列表长度 n = len(lst) # 遍历列表n-1次 for i in range(n-1): # 设置一个标志,用于判断是否发生交换 swapped = False # 遍历未排序的部分 for j in range(n-1-i): # 如果前一个元素大于后一个元素,交换位置 if lst[j] > lst[j+1]: lst[j], lst[j+1] = lst[j+1], lst[j] # 标志设为True,表示发生了交换 swapped = True # 如果没有发生交换,说明列表已经有序,提前结束循环 if not swapped: break # 返回排序后的列表 return lst # 定义测试程序 # 创建一个乱序的列表 lst = [5, 3, 8, 2, 9, 1, 4, 7, 6] # 打印原始列表 print("Original list:", lst) # 调用冒泡排序函数,对列表进行排序 lst = bubble_sort(lst) # 打印排序后的列表 print("Sorted list:", lst)结果图 image.png图片 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: input clock; input reset_b; input [N-1:0] request; input [N-1] lock; output [N-1] grant; //one-hot此处的 lock 输入信号,表示请求方收到了仲裁许可,在对应的lock拉低之前,仲裁器不可以开启新的仲裁。(可简单理解为仲裁器占用) 该题要求参数化编程,在模块例化时可调整参数。也即是说你不能写一个固定参数,比如N=8的模块。 参考波形图: image.png图片 答: Round-Robin算法:当有多个设备同时想占用同一个资源时,需要仲裁器通过某种调度算法决定不同设备使用资源的先后顺序。 Round Robin算法就是其中一种调度算法,其思路是,当多个仲裁请求(request)送给仲裁器时,仲裁器通过轮询的方式分时给不同的设备返回许可(grant),当一个requestor 得到了grant许可之后,它的优先级在接下来的仲裁中就变成了最低,当同时有多个requestor的时候,grant可以依次给到每个requestor,即使之前高优先级的requestor再次有新的request,也会等前面的requestor都grant之后再轮到它。由此看出,Round Robin算法是一种公平的算法,它避免了当最高优先级的requestor不断有新的request时,具有最高优先级的requestor一直占用资源,导致其他requestor无法占用资源的阻塞现象。 在verilog设计中,如何实现呢?假设request是位宽是6,最高位是第5位,最低位是第0位,默认低比特位具有高优先级。 1.首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1。 2.在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持,这个操作可以利用掩码111000和request相与实现得到。 得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 3.通过第二步得到第2位到第0位被屏蔽的request_new信号,判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位,则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 // 功能: // -1- Round Robin 仲裁器 // -2- 仲裁请求个数N可变 // -3- 加入lock机制(类似握手) // -4- 复位时的最高优先级定为 0 ,次优先级:1 -> 2 …… -> N-2 -> N-1 `timescale 1ns / 1ps module RoundRobinArbiter #( parameter N = 4 //仲裁请求个数 )( input clock, input reset_b, input [N-1:0] request, input [N-1:0] lock, output reg [N-1:0] grant//one-hot ); // 模块内部参数 localparam IDLE = 3'b001;// 复位进入空闲状态,接收并处理系统的初次仲裁请求 localparam WAIT_REQ_GRANT = 3'b010;// 等待后续仲裁请求到来,并进行仲裁 localparam WAIT_LOCK = 3'b100;// 等待LOCK拉低 // 模块内部信号 reg [2:0] R_STATUS; //请求状态 reg [N-1:0] R_MASK; //掩码 wire [N-1:0] W_REQ_MASKED; assign W_REQ_MASKED = request & R_MASK; //屏蔽低位 always @ (posedge clock) begin if(~reset_b) begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end else begin case(R_STATUS) IDLE: begin if(|request) //首次仲裁请求,不全为0 begin R_STATUS <= WAIT_LOCK; //首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。 //这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1 grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); //得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 end else begin R_STATUS <= IDLE; end end WAIT_REQ_GRANT://处理后续的仲裁请求 begin if(|request) begin R_STATUS <= WAIT_LOCK; //在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。 //因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持 //这个操作可以利用掩码111000和request相与实现得到。 if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end //通过第二步得到第2位到第0位被屏蔽的request_new信号, //判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位, //对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位, //则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 WAIT_LOCK: begin if(|(lock & grant)) //未释放仲裁器 begin R_STATUS <= WAIT_LOCK; end else if(|request) //释放的同时存在仲裁请求 begin R_STATUS <= WAIT_LOCK; if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end default: begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end endcase end end endmodule测试代码 `timescale 1ns / 1ps module RoundRobinArbiter_tb; parameter N = 4; // 可以在测试时调整参数 // 定义测试信号 reg clock; reg reset_b; reg [N-1:0] request; reg [N-1:0] lock; wire [N-1:0] grant; // 定义时钟信号 initial clock = 0; always #10 clock = ~clock; // 实例化仲裁器模块 RoundRobinArbiter #( .N(N) ) inst_RoundRobinArbiter ( .clock (clock), .reset_b (reset_b), .request (request), .lock (lock), .grant (grant) ); // 定义时钟周期和初始值 initial begin reset_b <= 1'b0; request <= 0; lock <= 0; end // 定义请求和锁定信号的变化 initial begin #20; reset_b <= 1'b1; @(posedge clock) request <= 2; lock <= 2; @(posedge clock) request <= 0; @(posedge clock) request <= 5; lock <= 7; @(posedge clock) lock <= 5; @(posedge clock) request <= 1; @(posedge clock) lock <= 1; @(posedge clock) request <= 0; @(posedge clock) lock <= 0; #1000 $stop; // 测试结束 end // 显示测试结果和波形图 initial begin $monitor("Time=%t, clock=%b, reset_b=%b, request=%b, lock=%b, grant=%b", $time, clock, reset_b, request, lock, grant); $dumpfile("RoundRobinArbiter_tb.vcd"); $dumpvars(0,RoundRobinArbiter_tb); end endmodule结果: image.png图片 如果对波形图无法理解可以看此博文 https://blog.csdn.net/m0_49540263/article/details/114967443 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: image.png图片 image.png图片 Type 表示读写类型。Reset 表示复位值。 写一个C函数 void dma_driver(void),按步骤完成以下需求: 分配DMA所需的源地址(0x30) 分配DMA所需的目的地址(0x300) 设置传输128 Byte 数据 开始DMA传输 等待DMA传输结束 答: // 假设有以下宏定义 #define DMA_REG 0x81050010 // DMA控制寄存器的地址 #define DMA_SRC_ADDR 0x30 // DMA源地址 #define DMA_DST_ADDR 0x300 // DMA目的地址 #define DMA_SIZE 128 // DMA传输大小 #define DMA_START 1 // DMA开始传输的标志位 // 定义C函数 void dma_driver(void) void dma_driver(void) { // 定义一个指向DMA控制寄存器的指针 volatile uint32_t *dma_reg = (volatile uint32_t *)DMA_REG; // 清空DMA控制寄存器的值 *dma_reg = 0; // 设置DMA源地址,目的地址和传输大小 *dma_reg |= (DMA_SRC_ADDR << 2) | (DMA_DST_ADDR << 13) | (DMA_SIZE << 24); // 开始DMA传输 *dma_reg |= DMA_START; // 等待DMA传输结束 while (*dma_reg & DMA_START) { // 可以在这里做一些其他的事情,比如打印日志或者检查错误 // printf("Waiting for DMA to finish...\n"); // check_error(); } }官方一点的表达:DMA,全称为:Direct Memory Access,即直接存储器访问。直接存储器存取( DMA )用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须 CPU 干预,数据可以通过 DMA 快速地移动,这就节省了 CPU 的资源来做其他操作。典型的例子就是移动一个外部内存的区块到芯片内部更快的内存区。像是这样的操作并没有让处理器工作拖延,反而可以被重新排程去处理其他的工作。DMA 传输对于高效能嵌入式系统算法和网络是很重要的。DMA 传输方式无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件为 RAM 与 I/O 设备开辟一条直接传送数据的通路, 能使 CPU 的效率大为提高。 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 答:第一步首得知道二阶带通(RC)滤波器的电路长啥样,高、低通组合一下就是带通,自己思考一下高、低通组合:如串联或并联,会得到带通还是带组? 电路图: H___H21L__E34_WC@43F1_8.jpg图片 这个一看就是总传递函数=A1*A2(模电二阶有源或无源滤波器绝对有) _LIYXIHR_08YNK__EV8SXDH.jpg图片 然后化简 X25LO__~TXMGO59LTLV@9S9.jpg图片 根据推导得到的表达式,对于 jwRC2 ,这一项,当 w 趋于无穷大时,uo/ui 趋于零。那么高频的临界点就是 wRC2 = 1+2C2/C1;(此时忽略低频项1/jwRC1) 同理,对于低频项 1 /jwRC1, w 趋于无穷小时,uo/ui 趋于零 ,那么低频的临界点就是 1/wRC1 = 1+2C2/C1;然后解二元一次方程两个电容就被解出来了 这里提供一种更简单方法: 二阶带通滤波器的中心频率 f0 和品质因数 Q 可以用下面的公式计算: image.png图片 已知 R1 = R2 = 10kΩ,f0 = (1kHz + 30kHz) / 2 = 15.5kHz,Q = f0 / (30kHz - 1kHz) = 0.54,代入上面的公式,可以求得: image.png图片 这是一个二元一次方程组,可以用任意方法求解,例如消元法或代入法。为了方便起见,我们假设 C1 和 C2 的值相近,那么可以近似地认为 C1 = C2 = 3.45nF。这样就得到了两个电容的容值。当然,也可以选择其他的电容值,只要满足上面的方程组即可。
FPGA&ASIC
软硬件算法
# 笔试面试
刘航宇
3年前
0
1,939
9
【硬件算法进阶】Verilog实现802.3 CRC-32校验运算电路
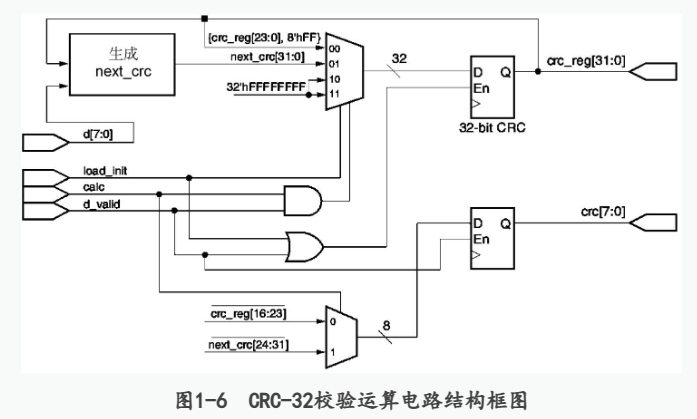
循环冗余校验(Cyclic Redundancy Check,CRC)是通信中常用的差错检测编码方式,其基本工作原理是根据输入的信息位(信息码元),按照给定的生成多项式产生校验位(校验码元),并一起传送到接收端。在接收端,接收电路按照相同的规则对接收数据进行计算并生成本地的校验位,然后与收到的校验位进行对比,如果二者不同,则说明传输过程中发生了错误,否则说明传输是正确的。带有CRC校验结果的数据帧结构如表1-2所示。 image.png图片 CRC检验位生成与检测工作包括以下基本步骤。 image.png图片 图1-6是一个并行CRC-32校验运算电路。图中的d[7:0]是输入的用户数据,它是按照字节的方式输入的。load_ini是在对一个新的数据包开始校验计算之前对电路进行初始化的控制信号,经过初始化后,电路内部32比特寄存器的值改变为全1。calc是电路运算指示信号,在整个数据帧输入和CRC校验结果输出的过程中其都应该保持有效(高电平有效)。d_valid为1时表示当前输入的是需要进行校验运算的有效数据。crc[7:0]是电路输出的CRC校验运算结果,它是按照字节方式,在有效数据输入完成后开始输出的,一共有4个有效字节。crc_reg[31:0]是内部寄存器的值,具体使用时不需要该输出。 image.png图片 并行计算的思想,输入数据S要并行输入到G(x)系数为1的支路中,输入数据从输入端按高到低逐bit输入,就可以实现。 假如被除数是2位的数据S[1:0]=01,多项式是10011,x4 +x+1。在CRC校验里面,习惯省略最高位的1,多项式用0011表示。那么S除以0011的模二运算数字电路结构为: image.png图片 其中d1~ d4是寄存器输入;q1~q4是寄存器输出。寄存器需要赋初值,一般赋全1或全0。 d1=S[1]^q4; d2= S[1]^ q1^q4; d3=q2; d4=q3。 经过一次移位后: q1=d1= S[1]^q4; q2= d2= S[1]^ q1^q4; q3= d3=q2; q4= d4=q3。 此时有: d1=S[0]^q3; d2= S[0]^ S[1]^ q4^q3; d3= S[1]^ q1^q4; d4= q2。 令c[3:0]={q4,q3,q2,q1},d[3:0]={d4,d3,d2,d1},那么d就是最终的运算结果表达式,如下 d[3]=c[1]; d[2]= S[1]^ c[0]^c[3]; d[1]= S[0]^ S[1]^ c[3]^ c[2]; d[0]= S[0]^ c[2]。 令c的初值为0,则01对0011的模二除法的余数为0011。 再比如多项式为x5 +x3 +x+1,简记式为01011,其数字电路结构为: image.png图片 输入数据S要全部输入完,寄存器得到的结果才是最后的结果。同理可推导出其他多项式和输入数据的情况。 对于循环检验,这里举个例子,如果数据是10bit*100个包,则每次输入10bit得到校验码后,该检验码为下次数据计算时寄存器D的初值,如此反复计算得到最后的检验码添加到整个数据后面即可,而不需要每个数据包后面都添加检验码。 下面是以太网循环冗余校验电路的设计代码: module crc32_8023( clk, reset, d, load_init, calc, d_valid, crc_reg, crc ); input clk; input reset; input [7:0] d; input load_init; input calc; input d_valid; output reg [31:0] crc_reg; output reg [7:0] crc; wire [2:0] ctl; wire [31:0] next_crc; wire [31:0] i; assign i = crc_reg; assign ctl = {load_init,calc,d_valid}; always @(posedge clk or posedge reset) begin if(reset) crc_reg <= 32'hffffffff; else begin case (ctl) //{load_init,calc,d_vaild} 3'b000,3'b010: begin crc_reg <= crc_reg; crc <= crc;end 3'b001: begin crc_reg <= {crc_reg[23:0],8'hff}; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b011: begin crc_reg <= next_crc[31:0]; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end 3'b100,3'b110: begin crc_reg <= 32'hffffffff; crc <= crc; end 3'b101: begin crc_reg <= 32'hffffffff; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b111: begin crc_reg <= 32'hffffffff; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end endcase end end assign next_crc[0] = d[7]^i[24]^d[1]^i[30]; //d+i=31 assign next_crc[1] = d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[30]^i[31]; assign next_crc[2] = d[5]^d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[26]^i[30]^i[31]; assign next_crc[3] = d[4]^d[5]^d[6]^d[0]^i[25]^i[26]^i[27]^i[31]; assign next_crc[4] = d[3]^d[4]^d[5]^d[7]^d[1]^i[24]^i[26]^i[27]^i[28]^i[30]; assign next_crc[5] = d[0]^d[1]^d[2]^d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[29]^i[30]^i[31]; assign next_crc[6] = d[0]^d[1]^d[2]^d[3]^d[5]^d[6]^i[25]^i[26]^i[28]^i[29]^i[30]^i[31]; assign next_crc[7] = d[0]^d[2]^d[4]^d[5]^d[7]^i[24]^i[26]^i[27]^i[29]^i[31]; assign next_crc[8] = d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[0]; //每项多出i[i],i=0、1、2...23 assign next_crc[9] = d[2]^d[3]^d[5]^d[6]^i[1]^i[25]^i[26]^i[28]^i[29]; assign next_crc[10] =d[2]^d[4]^d[5]^d[7]^i[2]^i[24]^i[26]^ i[27]^i[29]; assign next_crc[11] =i[3]^d[3]^i[28]^d[4]^i[27]^d[6]^i[25]^d[7]^i[24]; assign next_crc[12] =d[1]^d[2]^d[3]^d[5]^d[6]^d[7]^i[4]^i[24]^i[25]^i[26]^i[28]^i[29]^i[30]; assign next_crc[13] =d[0]^d[1]^d[2]^d[4]^d[5]^d[6]^i[5]^i[25]^i[26]^i[27]^i[29]^i[30]^i[31]; assign next_crc[14] =d[0]^d[1]^d[3]^d[4]^d[5]^i[6]^i[26]^i[27]^i[28]^i[30]^i[31]; assign next_crc[15] =d[0]^d[2]^d[3]^d[4]^i[7]^i[27]^i[28]^i[29]^i[31]; assign next_crc[16] =d[2]^d[3]^d[7]^i[8]^i[24]^i[28]^i[29]; assign next_crc[17] =d[1]^d[2]^d[6]^i[9]^i[25]^i[29]^i[30]; assign next_crc[18] =d[0]^d[1]^d[5]^i[10]^i[26]^i[30]^i[31]; assign next_crc[19] =d[0]^d[4]^i[11]^i[27]^i[31]; assign next_crc[20] =d[3]^i[12]^i[28]; assign next_crc[21] =d[2]^i[13]^i[29]; assign next_crc[22] =d[7]^i[14]^i[24]; assign next_crc[23] =d[1]^d[6]^d[7]^i[15]^i[24]^i[25]^i[30]; assign next_crc[24] =d[0]^d[5]^d[6]^i[16]^i[25]^i[26]^i[31]; assign next_crc[25] =d[4]^d[5]^i[17]^i[26]^i[27]; assign next_crc[26] =d[1]^d[3]^d[4]^d[7]^i[18]^i[28]^i[27]^i[24]^i[30]; assign next_crc[27] =d[0]^d[2]^d[3]^d[6]^i[19]^i[29]^i[28]^i[25]^i[31]; assign next_crc[28] =d[1]^d[2]^d[5]^i[20]^i[30]^i[29]^i[26]; assign next_crc[29] =d[0]^d[1]^d[4]^i[21]^i[31]^i[30]^i[27]; assign next_crc[30] =d[0]^d[3]^i[22]^i[31]^i[28]; assign next_crc[31] =d[2]^i[23]^i[29]; endmodule测试代码 `timescale 1ns/1ns module crc_test(); reg clk, reset; reg [7:0] d; reg load_init; reg calc; reg data_valid; wire [31:0] crc_reg; wire [7:0] crc; initial begin clk=0; reset=0; load_init=0; calc=0; data_valid=0; d=0; end always begin #10 clk=1; #10 clk=0; end always begin crc_reset; crc_cal; end task crc_reset; begin reset=1; repeat(2)@(posedge clk); #5; reset=0; repeat(2)@(posedge clk); end endtask task crc_cal; begin repeat(5) @ (posedge clk); //通过losd_init=1 对CRC计算电路进行初始化 #5; load_init= 1; repeat(1)@ (posedge clk); //设置1oad_init=0,data_valid= 1,calc=1 //开始对输人数据进行CRC校验运算 #5; load_init= 0; data_valid=1; calc=1; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hcc; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hdd; repeat(1)@ (posedge clk); //设置load_init=0,data_valid=1,calc=0 //停止对数据进行CRC校验运算,开始输出 //计算结果 #5; data_valid=1; calc=0; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hee; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hdd; repeat(1)@ (posedge clk); #5; data_valid=0; repeat(10)@ (posedge clk); end endtask crc32_8023 my_crc_test(.clk(clk),.reset(reset),.d(d),.load_init(load_init),.calc(calc),.d_valid(data_valid),.crc_reg(crc_reg),.crc(crc)); endmodule图1-7是电路的仿真结果。图中①是电路进行CRC校验计算之前对电路进行初始化操作的过程,经过初始化之后,crc_reg内部数值为全1。②是对输入数据aa-> bb-> cc-> dd进行运算操作的过程,此时calc和data_valid均为1。③是输出计算结果的过程,CRC校验运算结果a7、01、b4和55先后被输出。 图片 图片 在接收方向上,可以采用相同的电路进行校验检查,判断是否在传输过程中发生了差错。具体工作时,可以边接收用户数据边进行校验运算,当一个完整的MAC帧接收完成后(此时接收数据帧中的校验结果也参加了校验运算),如果当前校验电路的crc_reg值为0xC704DD7B(对于以太网中使用的CRC-32校验,无论原始数据是什么,正确接收时校验和都是此固定数值),说明没有发生错误,否则说明MAC帧有错。 CRC-32校验值的作用是用于检测数据传输或存储中的错误。发送数据时,会根据数据内容生成简短的校验和,并将其与数据一起发送。接收数据时,将再次生成校验和并将其与发送的校验和进行比较。如果两者相等,则没有数据损坏。如果两者不相等,则说明数据在传输或存储过程中发生了改变,可能是由于噪声、干扰、故障或恶意篡改等原因造成的。 CRC-32校验值可以有效地检测出数据中的随机错误,但是不能保证检测出所有的错误。例如,如果数据中有偶数个比特发生了翻转,那么CRC-32校验值可能不会改变,从而无法发现错误。因此,CRC-32校验值只能作为一种辅助的错误检测手段,不能完全依赖它来保证数据的正确性和完整性。 相关工具 如果不理解推导过程的话,可以由相关工具帮忙计算出结果和得到Verilog代码: CRC校验Verilog代码生成链接:http://outputlogic.com/?page_id=321 CRC校验计算工具链接:http://www.ip33.com/crc.html,这个工具只能计算16bit为一个数据包的数据,如果数据包为10bit等之类的就不太适用 在线计算器使用举例 报文 : 1011001 (0x59) 生成多项式 : g(x) = x^4 + x^3 + 1 CRC : 1010 ( 0xa) CRC计算结果截图: image.png图片 参考文献 Verilog HDL算法与电路设计-乔庐峰
FPGA&ASIC
软硬件算法
# ASIC/FPGA
# 硬件算法
刘航宇
3年前
0
2,069
3
2023-04-06
【硬件算法】Verilog之FPGA实现信号移相法
实现信号移相可以用FPGA控制信号0-360度连续可调,对于高频信号(1GHZ以上)超出了FPGA工作频率还有一种办法是FPGA-》DA-》射频前端-》移相器-》阻抗匹配-》天线。本案例直接采用FPGA对数字中频信号处理(kHZ、MHZ) 本质是边沿检测与分频 现象: 图片 代码: /* Function : Phase Shift Interface : clk_fre---unit(MHZ) din_fre---unit(KHz) phase_angle---unit(0-360 Angle) Date: 2023/04/05 Description: Phase shift is carried out on the input square wave. The phase Angle unit is Angle (0-360), or the input can be greater than 360. The system clock unit is MHz and the input signal clock is KHz. */ module PhaseShift( input clk, //clk input rst_n, //rest input [7:0] clk_fre, //system clock frequency,MHZ input [15:0] din_fre, //input signal clock frequency,KHZ input [8:0] phase_angle, //phase shift angle input din, //input signal output reg dout //output signal ); reg [31:0] posedge_counter; reg [31:0] negedge_counter; reg [31:0] delay_counter; reg in_posedge_flg; reg in_negedge_flg; reg out_posedge_flg; reg out_negedge_flg; reg old_din; reg init_data=1'b1; always @(posedge clk or negedge rst_n) begin if(!rst_n) begin posedge_counter <= 1'b0; negedge_counter <= 1'b0; in_posedge_flg <= 1'b0; in_negedge_flg <= 1'b0; out_posedge_flg <= 1'b0; out_negedge_flg <= 1'b0; end else begin if(~old_din & din) in_posedge_flg = 1'b1; if(old_din & ~din) in_negedge_flg = 1'b1; old_din <= din; if(init_data) begin delay_counter <= ((1000000000)/din_fre*clk_fre)/360*(phase_angle%360)/1000000; dout <= din ; init_data <= 1'b0; end if(in_posedge_flg && posedge_counter <= delay_counter) begin posedge_counter <= posedge_counter + 1'b1 ; out_posedge_flg <= 1'b0; end else begin posedge_counter <= 1'b0 ; in_posedge_flg <= 1'b0 ; if(~out_posedge_flg) begin dout <= 1'b1 ; out_posedge_flg <= 1'b1 ; end end if (in_negedge_flg && negedge_counter <= delay_counter) begin negedge_counter <= negedge_counter + 1'b1 ; out_negedge_flg <= 1'b0 ; end else begin negedge_counter <= 1'b0 ; in_negedge_flg <= 1'b0 ; if(~out_negedge_flg) begin dout <= 1'b0 ; out_negedge_flg <= 1'b1; end end end end endmodule测试代码: `timescale 100ps/10ps // module test_PhaseShift; reg clk; reg rst_n; reg [7:0] clk_fre; //system clock frequency,MHZ reg [15:0] din_fre ; //input signal clock frequency,KHZ reg [8:0] phase_angle; //phase shift angle reg din ; //input signal wire dout ; //output signal initial begin clk = 0; din = 0; din_fre = 4000; phase_angle = 90; clk_fre = 100; rst_n = 1; #12 rst_n = 0; #4 rst_n = 1; #10000 $stop; //end end always #5 clk = ~clk; always #125 din = ~din; PhaseShift u1( .clk(clk), .rst_n(rst_n), .clk_fre(clk_fre), .din_fre(din_fre), .phase_angle(phase_angle), .din(din), .dout(dout) ); endmodule
FPGA&ASIC
软硬件算法
# ASIC/FPGA
# 硬件算法
刘航宇
3年前
0
1,507
3