首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,182 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,140 阅读
3
【高数】形心计算公式讲解大全
8,751 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,450 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,814 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
⌨️IC&系统(共78篇)
找到
78
篇与
⌨️IC&系统
相关的结果
- 第 5 页
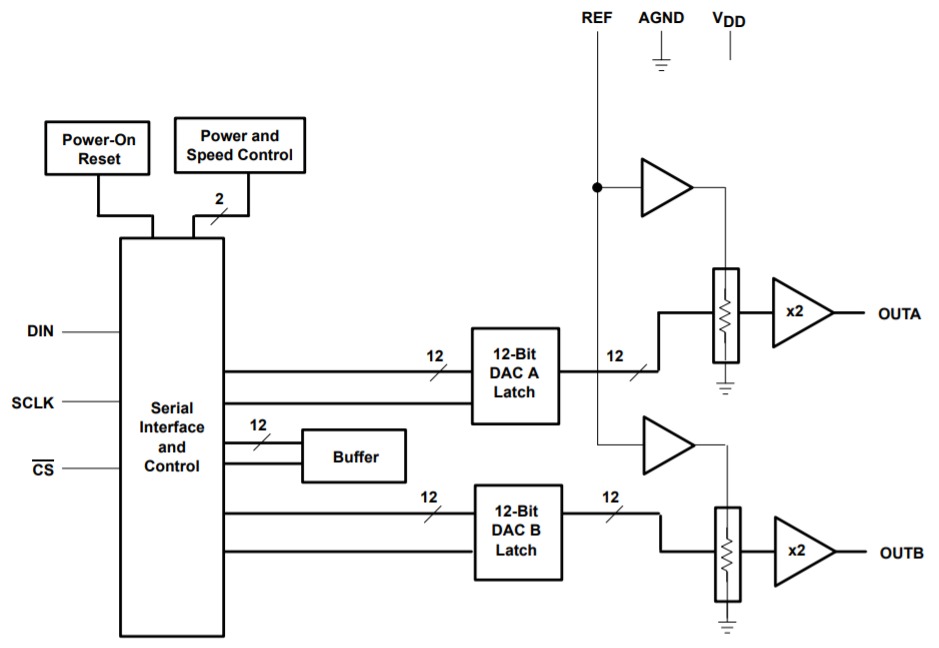
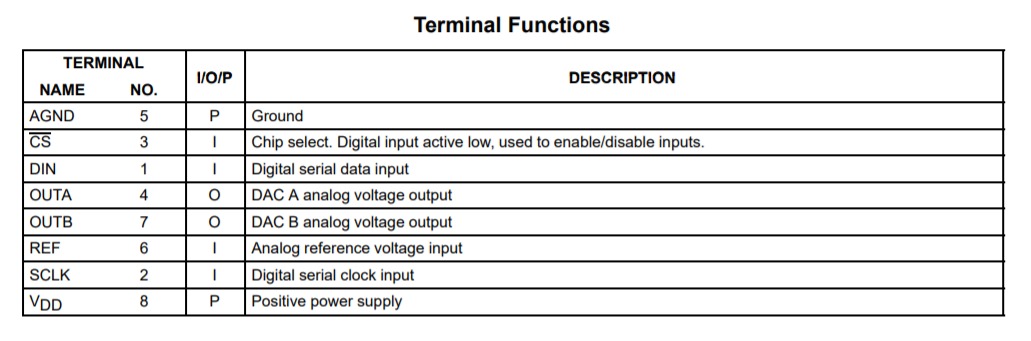
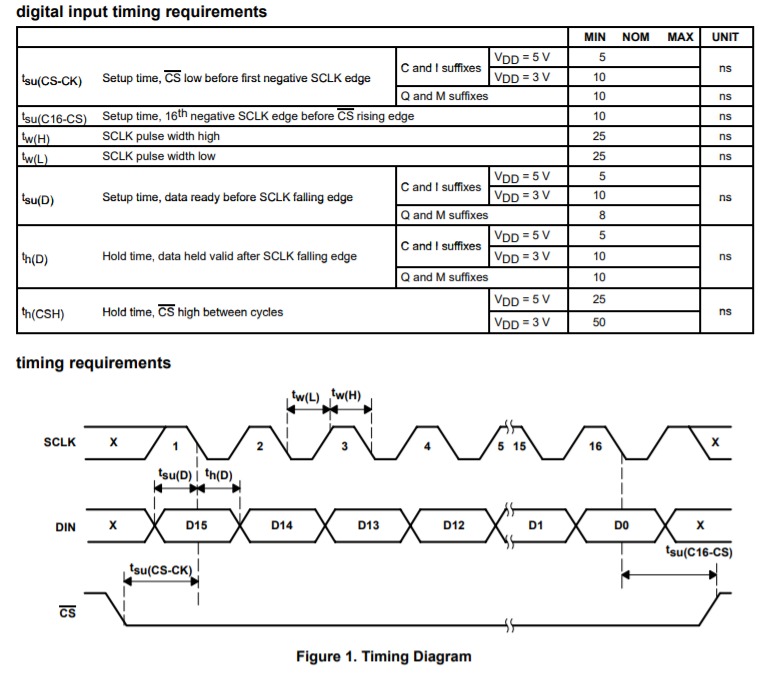
【FPGA】【SPI】线性序列机与串行接口 DAC 驱动设计与验证
概述:ADC和DAC是FPGA与外部信号的接口,从数据接口类型的角度划分,有低速的串行接口和高速的并行接口。FPGA经常用来采集中高频信号,因此使用并行ADC和DAC居多。并行接口包括两种数字编码方式:带符号数signed与无符号数unsigned。 DAC DA转化一般将数字信号“010101”转化为模拟信号去控制其它电子设备。 导读: 数模转换器即 D/A 转换器,或简称 DAC(Digital to Analog Conver),是指将数字信号转变为模拟信号的电子元件。 DAC 的内部电路构成无太大差异,一般按输出是电流还是电压、能否作乘法运算等进行分类。大多数 DAC 由电阻阵列和 n 个电流开关(或电压开关)构成,按数字输入值切换开关,产生比例于输入的电流(或电压) 。此外,也有为了改善精度而把恒流源放入器件内部的。 DAC 可分为电压型和电流型两大类,电压型 DAC 有权电阻网络、T 型电阻网络和树形开关网络等;电流型 DAC 有权电流型电阻网络和倒 T 型电阻网络等。 电压输出型(如 TLV5618) 。电压输出型 DAC 虽有直接从电阻阵列输出电压的,但一般采用内置输出放大器以低阻抗输出。直接输出电压的器件仅用于高阻抗负载,由于无输出放大器部分的延迟,故常作为高速 DAC 使用。 电流输出型(如 THS5661A ) 。电流输出型 DAC 很少直接利用电流输出,大多外接电流- 电压转换电路得到电压输出,后者有两种方法:一是只在输出引脚上接负载电阻而进行电流- 电压转换,二是外接运算放大器。 乘算型(如 AD7533) 。DAC 中有使用恒定基准电压的,也有在基准电压输入上加交流信号的,后者由于能得到数字输入和基准电压输入相乘的结果而输出,因而称为乘算型 DAC。 乘算型 DAC 一般不仅可以进行乘法运算,而且可以作为使输入信号数字化地衰减的衰减器及对输入信号进行调制的调制器使用。 一位 DAC。一位 DAC 与前述转换方式全然不同,它将数字值转换为脉冲宽度调制或频率调制的输出,然后用数字滤波器作平均化而得到一般的电压输出,用于音频等场合。 本章以 TLV5618 为例介绍 DAC 的工作原理及时序图解释,并用线性序列机(LSM)来描述时序图进而正确驱动此类设备。在 Quartus Pime 软件中,使用 ISSP 工具输入希望输出的电压值,控制 FPGA 进而操作 TLV5618 芯片输出对应的电压值。 任务 使用FPGA芯片控制DAC采集芯片,输出指定的电压值。 硬件部分 为了将FPGA输出的数字电压转换成模拟电压,使用到了数模转换芯片(简称DAC)TLV5618。进行设计前, 需要查看该芯片的数据手册 。 1.芯片功能图 本章使用的 DAC 芯片为 TLV5618,其芯片内部结构如图所示。TLV5618 是一个基于电压输出型的双通道 12 位单电源数模转换器,其由串行接口、一个速度和电源控制器、电阻网络、轨到轨输出缓冲器组成。 图片 TLV5618 使用 CMOS 电平兼容的三线制串行总线与各种处理器进行连接,接收控制器发送的 16 位的控制字,这 16 位的控制字被分为 2 个部分,包括 4 位的编程位,12 位的数据位。 2.端口功能表 图片 从功能图和功能表中我们可以看出,TLV5618有四个输入端口: 片选信号CS、数据串行输入端口DIN、模拟参考电压REF、数字时钟SCLK。 两个输出端分别为OUTA和OUTB,均为对应的模拟电压输出端。 3.时序图 当片选(CS)信号为低电平时,输入数据以最高有效位在前的方式被读入 16 位移位寄存器。在 SCLK 输入信号的下降沿,把数据移入寄存器 A、B。当片选(CS)信号进入上升沿时,再把数据送至 12 位 A/D 转换器。 图片 从时序图中我们可以看到使用该芯片时要注意这几个参数: tw(L):低电平最小宽度,25ns。 tw(H):高电平最小宽度,25ns。 tsu(D):数据最短建立时间。 th(D):数据最短保持时间。 tsu(CS-CK):片选信号下降沿到第一个时钟下降沿最短时间。 th(CSH):片选信号最短拉高时间。 TLV5618 的 16 位数据格式如下: 图片 其中,SPD 为速度控制位,PWR 为电源控制位。上电时,SPD 和 PWR 复位到 0(低速模式和正常工作)。 图片 R1 与 R0 所有可能的组合以及代表的含义如下所示。如果其中一个寄存器或者缓冲区被选择,那么 12 位数据将决定新的 DAC 输出电压值。 图片 这样针对 D[15:12]不同组合构成的典型操作如下: 1)设置 DAC A 输出,选择快速模式:写新的 DAC A 的值,更新 DAC A 输出。DAC A 的输出在 D0 后的时钟上升沿更新。 图片 2)设置 DAC B 输出,选择快速模式: 写新的 DAC B 的值到缓冲区,并且更新 DAC B 输出。DAC B 的输出在 D0 后的时钟上升沿更新。 图片 3) 设置 DAC A、DAC B 的值,选择低速模式:在写 DAC A 的数据 D0 后的时钟上升沿 DAC A 和 B 同时更新输出。 a.写 DAC B 的数据到缓冲区: 图片 b.写新的 DAC A 的值并且同时更新 DAC A 和 B: 图片 4) 设置掉电模式:×=不关心 图片 4.输出电压计算 图片 图片 由手册给出的公式知,输出电压与输入的编码值成正比,同时还要乘以一个系数REF,这个系数从芯片的REF引脚输入。我们打开并查看开发板的原理图:其中参考电压为由 LM4040 提供的 2.048V,与FPGA 采用三线制 SPI 通信。 图片 从图中知,我们用到了芯片LM4040-2.0给DAC供电,这个芯片工作时输出电压为4.028V(即精度为12位),故参数REF为4.028。 5.时钟频率与刷新率计算 图片 我们查阅手册后知道,使用该芯片时,时钟最大频率为20MHz,刷新率为时钟频率的1/16。而开发板提供的原始时钟为50MHz,因此可以采用四分频后得到12.5MHz的时钟频率。 线性序列机设计思想与接口时序设计 从图 24.3 中可以看出,该接口的时序是一个很有规律的序列,SCLK 信号什么时候该由变高,什么时候由高变低。DIN 信号什么时候该传输哪一位数据,都是可以根据时序参数唯一确定下来的。 这样就可以将该数据波形放到以时间为横轴的一个二维坐标系中,纵轴就是每个信号对应的状态: 图片 因此只需要在逻辑中使用一个计数器来计数,然后每个计数值时就相当于在 t 轴上对应了一个相应的时间点,那么在这个时间点上,各个信号需要进行什么操作,直接赋值即可。 经查阅手册可知器件工作频率SCLK最大为20MHz,这里定义其工作频率为12.5MHz。设置一个两倍于 SCLK 的采样时钟 SCLK2X,使用 50M 系统时钟二分频而来即 SCLK2X 为25MHz。针对 SCLK2X 进行计数来确定图 24.4 中各个信号的状态。可得出每个时间点对应信号操作详表。 图片 图片 线性序列机计数器的控制逻辑判断依据,如表 24.7 所示。 图片 以上就是通过线性序列机设计接口时序的一个典型案例,可以看到,线性序列机可以大大简化设计思路。线性序列机的设计思想就是使用一个计数器不断计数,由于每个计数值都会对应一个时间,那么当该时间符合需要操作信号的时刻时,就对该信号进行操作。这样,就能够轻松的设计出各种时序接口了。 基于线性序列机的 DAC 驱动设计 模块接口设计 设计 TLV5618 接口逻辑的模块如图 24.8 所示。 图片 其中,每个端口的功能描述如表 24.6 所示。 表 24.6 模块端口功能描述 图片 生成使能信号,当输入使能信号有效后便将使能信号 en 置 1,当转换完成信号有效时便将其重新置 0。 reg en;//转换使能信号 always@(posedge Clk or negedge Rst_n) if(!Rst_n) en <= 1'b0; else if(Start) en <= 1'b1; else if(Set_Done) en <= 1'b0; else en <= en;在数据手册中SCLK的频率范围为0.8~3.2MHz。这里为了方便适配不同的频率需求率,设置了一个可调的计数器,改变 DIV_PARAM 的值即可改变 DAC 工作频率。根据表 中可以看出,需要根据计数器的值周期性的产生 SCLK 时钟信号,这里可以将计数器的值等倍数放大,形成过采样。这里产生一个两倍于 SCLK 的信号,命名为 SCLK2X。 首先编写分频计数器,时钟 SCLK2X 的计数器。 //生成 2 倍 SCLK 使能时钟计数器 reg [7:0]DIV_CNT;//分频计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) DIV_CNT <= 4'd0; else if(en)begin if(DIV_CNT == (DIV_PARAM - 1'b1))//2-1=1,cnt=0,25MHZ,cnt=1为12.5MHZ DIV_CNT <= 4'd0; else DIV_CNT <= DIV_CNT + 1'b1; end else DIV_CNT <= 4'd0;根据使能信号以及计数器状态生成 SCLK2X 时钟。 //生成 2 倍 SCLK 使能时钟计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK2X <= 1'b0; else if(en && (DIV_CNT == (DIV_PARAM - 1'b1))) SCLK2X <= 1'b1; else SCLK2X <= 1'b0;每当使能转换后,对 SCLK2X 时钟进行计数。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK_GEN_CNT <= 6'd0; else if(SCLK2X && en)begin if(SCLK_GEN_CNT == 6'd32) SCLK_GEN_CNT <= 6'd0; else SCLK_GEN_CNT <= SCLK_GEN_CNT + 1'd1; end else SCLK_GEN_CNT <= SCLK_GEN_CNT;根据 SCLK2X 计数器的值来确认工作状态以及数据传输进程。 //依次将数据移出到 DAC 芯片 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin DIN <= 1'b1; SCLK <= 1'b0; r_DAC_DATA <= 16'd0; end else begin if(Start)//收到开始发送命令时,寄存 DAC_DATA 值 r_DAC_DATA <= DAC_DATA; if(!Set_Done && SCLK2X) begin if(!SCLK_GEN_CNT[0])begin //偶数, 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30: SCLK <= 1'b1; DIN <= r_DAC_DATA[15]; r_DAC_DATA <= #1 r_DAC_DATA << 1; end else //奇数, 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31: SCLK <= 1'b0; end endDAC 工作状态,处于数据传输状态时 CS_N 为低电平状态,空闲时为高。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) CS_N <= 1'b1; else if(en && SCLK2X) CS_N <= SCLK_GEN_CNT[5]; else CS_N <= CS_N;一次转换结束的标志,即 SCLK_GEN_CNT[5] && SCLK2X,并产生一个高脉冲的转换完成标志信号 Set_Done。 assign Set_Done = SCLK_GEN_CNT[5] && SCLK2X;仿真及板级测试 这里仿真文件需输出几次并行数据,观测串行数据输出 DIN 的状态即可判断是否能驱动正常。这里输出四次数据分别为 C_AAAh、4_555h、1_555h、F_555h。部分代码如下,只写出了前两个数据,后面两个可直接复制修改即可。 initial begin Rst_n = 0; Start = 0; DAC_DATA = 0; #201; Rst_n = 1; #200; DAC_DATA = 16'hC_AAA; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h4_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); $stop; end开始仿真后,可看出人为控制 DAC_DATA 数据输入状态正常。 图片 放大第一个数据传输过程,可以看出正常 1100_1010_1010_1010b,计数器计数到'd32 符合设计要求,且每个传输过程中 CS_N 为低。传输完成后产生一个时钟周期的 Set_Done 标志信号。 图片 为了再次验证 TLV5618 驱动模块设计的正确性,使用 ISSP 在线调试工具。创建一个 ISSPIP 核,主要配置如图 24.7 所示。 图片 加入工程后新建顶层文件 DAC_test.v,并对 ISSP 以及设计好的 TLV5618 进行例化. 在接口时序介绍中指出,TLV5618 有三种更新输出电压方式,下面分别测试这三种电压更新方式。上电复位后两通道输出电压初始值均为 0V。 1.单独测试 A 通道,依次输入 CFFFh、C7FFh、C1FFh,理论输出电压值应为 4.096、2.048、0.512。可在通道 A 测量输出电压依次为 4.10、2.05、0.51,此时通道 B 电压一直保持 0,电压输出在误差允许范围内。 2.单独测试 B 通道,依次输入 4FFFh、47FFh、4000h,可在通道 B 测量输出电压依次为4.10、2.05、0。此时通道 A 电压一直保持 0.51,电压输出在误差允许范围内。 3.测量 AB 两通道同时更新,首先输入 1FFF 将数据写入通道 B 寄存器,再写入 8FFF 到通道 A 寄存器。这样可以测量出写完后会两个通道输出电压会同时变为 4.10。 通过以上三组测试数据的,可以发现 DAC 芯片输出电压数据更新正常。 这样就完成了一个 DAC 模块的设计与仿真验证,基于本讲以及 14 讲即可实现信号发 生器,详细内容可以参考第五篇中的进阶课程 DDS2。 设计工程 图片 我们考虑用FPGA设计一个DAC驱动,通过CS、sclk、din三根信号线与DAC芯片连接,设计输入端口Data[15:0]。同时为了便于与其他模块共同协作,我们加上了使能端口en和转换完成标志位Conv_done,这是FPGA设计时必须考虑的一点,对于复杂的驱动模块,这两个信号是不可或缺的。 软件部分 //驱动部分 module tlv5618( Clk, Rst_n, DAC_DATA, //并行数据输入端 Start,//开始标志位 Set_Done,//完成标志位 DAC_CS_N,//片选 DAC_DIN,//串行数据送给ADC芯片 DAC_SCLK,//工作时钟SCLK DAC_State//工作状态 ); parameter fCLK=50;//50MHZ时钟参数 parameter DIV_PARAM=2;//分频参数 input Clk; input Rst_n; input[15:0] DAC_DATA; input Start; output reg Set_Done; output reg DAC_CS_N; output reg DAC_DIN; output reg DAC_SCLK; output DAC_State; assign DAC_State=DAC_CS_N;//工作状态标志与片选信号相同 reg [15:0] r_DAC_DATA;//DAC数据寄存器 reg[3:0] DIV_CNT;//分频计数器 reg SCLK2X;//2倍SCLK的采样时钟 reg[5:0] SCLK_GEN_CNT;//SCLK生成暨序列机计数器 reg en; wire trans_done;//转化序列完成标志信号 always @(posedge Clk or negedge Rst_n) begin if(!Rst_n) en<=1'b0; else if(Start) en<=1'b1; else if(trans_done) en<=1'b0;//转换完成后将使能关闭 else if(treans_done) en<=1'b0;//转换完成后将使能关闭 else en<en; end //分频计数器 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) DIV_CNT<=4'd0; else if(en)begin if(DIV_CNT==(DIV_PARAM-1'b1))//前面设置了分频系数为2,这里计数器能够容纳2拍时钟脉冲 DIV_CNT<=4'b0; else DIV_CNT<=DIV_CNT+1'b1; end else DIV_CNT<=4'd0; end //二分频 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) SCLK2X<=1'b0; else if(en && (DIV_CNT==(DIV_PARAM-1'b1))) SCLK2X<=1'b1; else SCLK2X<=1'b0; end //生成序列计数器,对SCLK脉冲进行计数 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) SCLK_GEN_CNT<=6'd0; else if(SCLK2X && en)begin//在高脉冲期间,累计拍数 if(SCLK_GEN_CNT==6'd33) SCLK_GEN_CNT<=6'd0; else SCLK_GEN_CNT<=SCLK_GEN_CNT+1'd1; end else SCLK_GEN_CNT<=SCLK_GEN_CNT; end always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) r_DAC_DATA<=16'd0; else if(Start) //收到开始发送命令时候,寄存DAC_DATA值 r_DAC_DATA<=DAC_DATA; else r_DAC_DATA<=r_DAC_DATA; end //依次将数据移出到DAC芯片 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin DAC_DIN<=1'b1; DAC_SCLK<=1'b0; DAC_CS_N<=1'b1; end else if(!Set_Done && SCLK2X)begin case(SCLK_GEN_CNT) 0: begin //高脉冲期间内,计数为0时了,打开片选使能,给予时钟上升沿,将最高位数据送给DAC芯片 DAC_CS_N <= 1'b0; DAC_DIN <= r_DAC_DATA[15]; DAC_SCLK <= 1'b1; end 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31: begin DAC_SCLK <= 1'b0; //时钟低电平 end 2: begin DAC_DIN <= r_DAC_DATA[14]; DAC_SCLK <= 1'b1; end 4: begin DAC_DIN <= r_DAC_DATA[13]; DAC_SCLK <= 1'b1; end 6: begin DAC_DIN <= r_DAC_DATA[12]; DAC_SCLK <= 1'b1; end 8: begin DAC_DIN <= r_DAC_DATA[11]; DAC_SCLK <= 1'b1; end 10: begin DAC_DIN <= r_DAC_DATA[10]; DAC_SCLK <= 1'b1; end 12: begin DAC_DIN <= r_DAC_DATA[9]; DAC_SCLK <= 1'b1; end 14: begin DAC_DIN <= r_DAC_DATA[8]; DAC_SCLK <= 1'b1; end 16: begin DAC_DIN <= r_DAC_DATA[7]; DAC_SCLK <= 1'b1; end 18: begin DAC_DIN <= r_DAC_DATA[6]; DAC_SCLK <= 1'b1; end 20: begin DAC_DIN <= r_DAC_DATA[5]; DAC_SCLK <= 1'b1; end 22: begin DAC_DIN <= r_DAC_DATA[4]; DAC_SCLK <= 1'b1; end 24: begin DAC_DIN <= r_DAC_DATA[3]; DAC_SCLK <= 1'b1; end 26: begin DAC_DIN <= r_DAC_DATA[2]; DAC_SCLK <= 1'b1; end 28: begin DAC_DIN <= r_DAC_DATA[1]; DAC_SCLK <= 1'b1; end 30: begin DAC_DIN <= r_DAC_DATA[0]; DAC_SCLK <= 1'b1; end 32: DAC_SCLK <= 1'b1; //时钟拉高 33: DAC_CS_N <= 1'b1; //关闭片选 default:; endcase end assign trans_done = (SCLK_GEN_CNT == 33) && SCLK2X; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Set_Done <= 1'b0; else if(trans_done) Set_Done <= 1'b1; else Set_Done <= 1'b0; endmodule//顶层模块 module DAC_test( Clk,//模块时钟50M Rst_n,//模块复位 DAC_CS_N, //TLV5618的CS_N接口 DAC_DIN, //TLV5618的DIN接口 DAC_SCLK //TLV5618的SCLK接口 ); input Clk; input Rst_n; output DAC_CS_N; output DAC_DIN; output DAC_SCLK; reg Start; reg [15:0]r_DAC_DATA; wire DAC_State; wire [15:0]DAC_DATA; wire Set_Done; tlv5618 tlv5618( .Clk(Clk), .Rst_n(Rst_n), .DAC_DATA(DAC_DATA), .Start(Start), .Set_Done(Set_Done), .DAC_CS_N(DAC_CS_N), .DAC_DIN(DAC_DIN), .DAC_SCLK(DAC_SCLK), .DAC_State(DAC_State) ); always@(posedge Clk or negedge Rst_n) if(!Rst_n) r_DAC_DATA <= 16'd0; else if(DAC_State) r_DAC_DATA <= DAC_DATA; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Start <= 1'd0; else if(r_DAC_DATA != DAC_DATA) Start <= 1'b1; else Start <= 1'd0; endmodule`timescale 1ns/1ns module tlv5618_tb(); reg Clk; reg Rst_n; reg [15:0]DAC_DATA; reg Start; wire Set_Done; wire DAC_CS_N; wire DAC_DIN; wire DAC_SCLK; tlv5618 tlv5618( .Clk(Clk), .Rst_n(Rst_n), .DAC_DATA(DAC_DATA), .Start(Start), .Set_Done(Set_Done), .DAC_CS_N(DAC_CS_N), .DAC_DIN(DAC_DIN), .DAC_SCLK(DAC_SCLK), .DAC_State() ); initial Clk = 1; always#10 Clk = ~Clk; initial begin Rst_n = 0; Start = 0; DAC_DATA = 0; #201; Rst_n = 1; #200; DAC_DATA = 16'hC_AAA; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h4_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h1_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'hf_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; $stop; end endmodule仿真 图片
FPGA&ASIC
# ASIC/FPGA
# 小实验
刘航宇
4年前
0
1,413
1
2022-11-30
VLSI设计-基4 Booth乘法器前端与中端实现
前言 在微处理器芯片中,乘法器是进行数字信号处理的核心,同时也是微处理器中进行数据处理的关键部件。乘法器完成一次操作的周期基本上决定了微处理器的主频。乘法器的速度和面积优化对于整个CPU的性能来说是非常重要的。为了加快乘法器的执行速度,减少乘法器的面积,有必要对乘法器的算法、结构及电路的具体实现做深入的研究。 目录 视频课程,关注本人B站账号有完整版前端中端设计教程 前言 视频课程,关注本人B站账号有完整版前端中端设计教程 1. 设计内容 2. 设计目标 3.原理介绍 4.电路&Verilog代码基4Booth编码器 4-2压缩器 超前进位加法器 4、仿真分析前端逻辑仿真 电路与性能仿真电路图 面积报告 功耗报告 后端 1. 设计内容 完成一个全定制的 8x8 bits 基-4 Booth 编码码乘法器核心电路设计,即可以不考虑输入、输出数据的寄存。 2. 设计目标 本设计最主要的目标是在电路速度尽可能高的条件下最小化电路的功率-延迟积(PDP)。所以首先在电路结构设计完成后需要分析、考虑最长延迟路径。根据设计目标进行逻辑链优化。 3.原理介绍 本乘法器采用基4booth编码,输入为两个8位有符号数,输出为16位有符号数。基4的booth编码将两个8位有符号数计算成4个部分积。4个部分积经过一层4-2压缩器得到2个部分积,得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。 图片 思维扩展: 若输入为两个128位有符号数,输出为256位有符号数。基4的booth编码将两个128位有符号数计算成64个部分积。64个部分积经过一层4-2压缩器得到32个部分积……在经过几层4-2压缩器,最终得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。结构框图如下: 图片 4.电路&Verilog代码 设计理念:功能需求->Verilog代码->代码转电路(DC)->电路转版图(ICC或SOCE) 基4Booth编码器 对于被乘数b_i进行编码,Booth 基-4 编码是根据相邻 3 位为一组,前后相邻分组重叠一比特位,从低位到高位逐次进行,在乘数的最右边另增加一位辅助位 0,作为分组的最低位。Booth 4-基编码的优点是可以减少 Booth 2-基产生部分积的一半,Booth 基-4 除了具有高速特性还具有低功耗的特点。 图片 对应case case(b_i) 3'b000 : booth_o <= 0; 3'b001 : booth_o <= { a_i[length-1], a_i}; 3'b010 : booth_o <= { a_i[length-1], a_i}; 3'b011 : booth_o <= a_i<<1; 3'b100 : booth_o <= -(a_i<<1); 3'b101 : booth_o <= -{a_i[length-1],a_i}; 3'b110 : booth_o <= -{a_i[length-1],a_i}; 3'b111 : booth_o <= 0; default: booth_o <= 0;4-2压缩器 4-2 压缩器的原理图如下所示,把 4 个相同权值的二进制数两个权值高一级的二进制数和,它有 5 个输入端口:包括 4 个待压缩数据 a1、a2、a3、a4 和一个初始进位或低权值 4-2 压缩传递的进位值 Ci;3 个输出端口:包括一比特位溢出进位值 Co,进位数据 C,伪和 S。 下面代码得到的结果out1的权值高一位,下一层部分积计算时需要将out1的结果左移一位(out1<<1); 图片 功能代码: assign w1 = in1 ^ in2 ^ in3 ^ in4; assign w2 = (in1 & in2) | (in3 & in4); assign w3 = (in1 | in2) & (in3 | in4); assign out2 = { w1[length*2-1] , w1} ^ {w3 , cin}; assign cout = w3[length*2-1]; assign out1 = ({ w1[length*2-1] , w1} & {w3 , cin}) | (( ~{w1[length*2-1] , w1}) & { w2[length*2-1] , w2});超前进位加法器 4位超前进位代码: //carry generator assign c[0] = cin; assign c[1] = g[0] + ( c[0] & p[0] ); assign c[2] = g[1] + ( (g[0] + ( c[0] & p[0]) ) & p[1] ); assign c[3] = g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] ); assign c[4] = g[3] + ( (g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] )) & p[3]); assign cout = c[width];代码下载 基4 Booth代码 下载地址:https://wwek.lanzoub.com/ikPEB0m2z41a 提取码: 4、仿真分析 前端逻辑仿真 本设计是单纯的组合逻辑,由仿真结果可知有符号乘法设计结果完全正确。 图片 电路与性能仿真 电路图 图片 面积报告 DC综合后,总共的单元面积为7853.630484等效门,总面积为78273.983938等效门。 图片 功耗报告 图片 由于该电路是完全的组合逻辑,无CLK端口,因此未作时序约束。 后端 做到这里完成了前端中端设计任务,在流片前还需要完成后端设计及验证。由于本电路规模大,我们可以利用EDA如(SOCE或者ICC)完成版图布局,由于时间仓促,笔者暂未更新后端教程。
FPGA&ASIC
VLSI&IC验证
# ASIC/FPGA
刘航宇
4年前
0
1,367
4
集成电路中I/O PAD及其版图
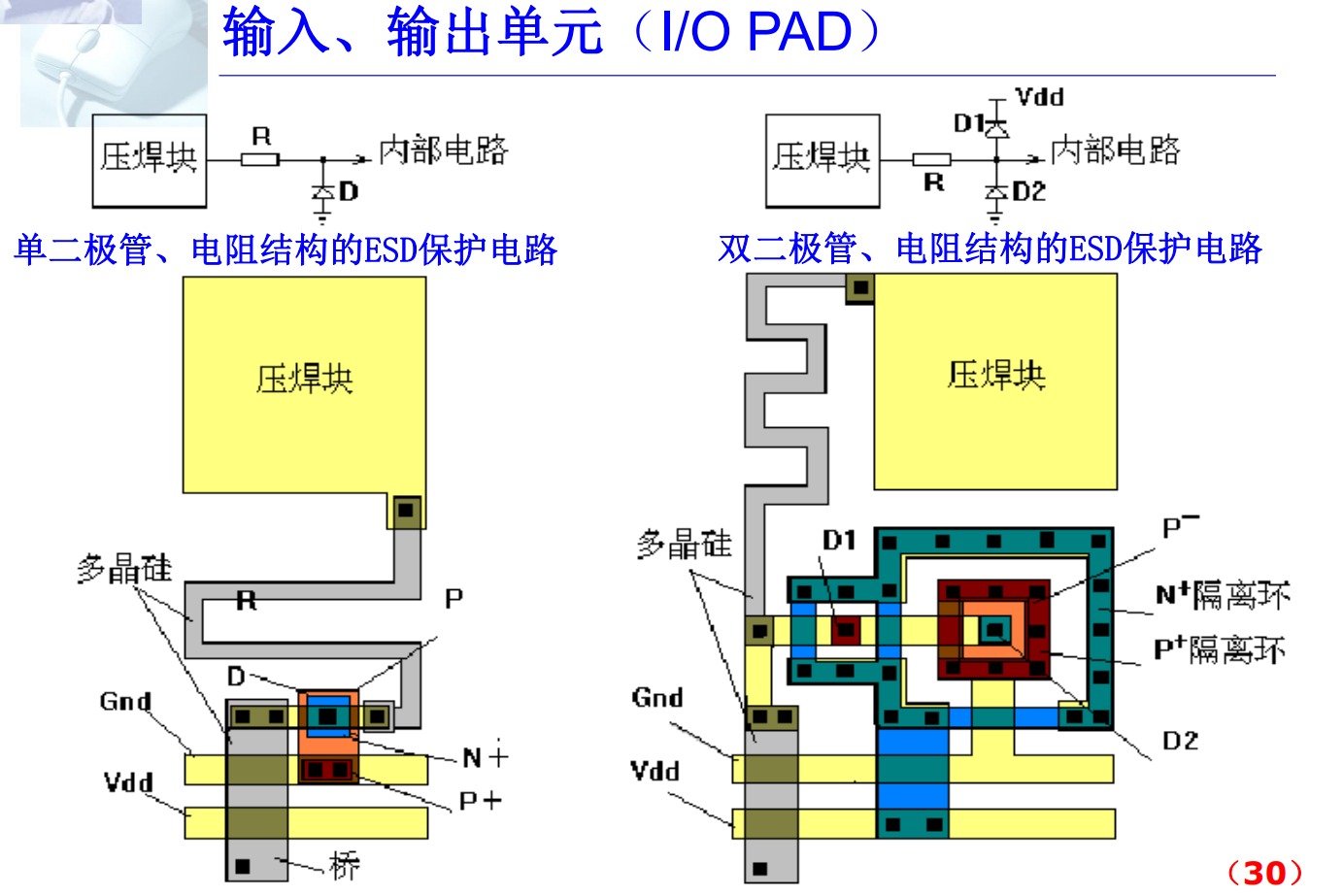
标准单元设计技术的特点: 标准单元是一个具有规则外部形状的单元,其内容是优化设计的逻辑单元版图,各单元的规模应相近,并遵循一致的引线规则。 一个标准单元库内的所有单元遵循同一的工艺设计规则,一个单元库对应一条或一组完全相同的工艺线。也就是说,当工艺发生变化时,单元库必须修改或重建。 不论是局部逻辑或是完整的集成电路或系统,用标准单元实现的版图采用“行式结构”,即各标准单元排列成行。 输入、输出单元(I/O PAD) 任何一种设计技术、版图结构都需要输入/输出单元。 想想看, I/O单元有什么作用? 连接芯片内部与芯片外部系统 (压焊块) 要的功能:对外的驱动 内提供内外的隔离和输入保护功能 I /O单元的形式 I/O PAD不仅是压焊块,还有电路,需电源和地线连通。 焊块用于连接芯片与封装管座,这些压焊块通常是边长几十微米的矩形。 大部分I/O PAD都是以标准单元的结构形式出现。通常具有等高不等宽的外部形状。 图片 图片 图片
VLSI&IC验证
# VLSI
刘航宇
4年前
0
3,814
4
关于射频芯片马上懂!
一部可支持打电话、发短信、网络服务、APP应用的手机,通常包含五个部分:射频、基带、电源管理、外设、软件。 射频: 一般是信息发送和接收的部分; 基带: 一般是信息处理的部分; 电源管理: 一般是节电的部分,由于手机是能源有限的设备,所以电源管理十分重要; 外设: 一般包括LCD,键盘,机壳等; 软件: 一般包括系统、驱动、中间件、应用。 目录 射频芯片和基带芯片的关系 工作原理与电路分析 接收电路的结构和工作原理1.电路结构 2.各元件的功能与作用 3.接收信号流程 1.电路结构 2.各元件的功能与作用 3.发射信号流程 国产射频芯片产业链现状 在手机终端中,最重要的核心就是射频芯片和基带芯片。射频芯片负责射频收发、频率合成、功率放大;基带芯片负责信号处理和协议处理。那么射频芯片和基带芯片是什么关系? 射频芯片和基带芯片的关系 射频(Radio Frenquency)和基带(Base Band)皆来自英文直译。其中射频最早的应用就是Radio——无线广播(FM/AM),迄今为止这仍是射频技术乃至无线电领域最经典的应用。 基带则是band中心点在0Hz的信号,所以基带就是最基础的信号。有人也把基带叫做“未调制信号”,曾经这个概念是对的,例如AM为调制信号(无需调制,接收后即可通过发声元器件读取内容)。 但对于现代通信领域而言,基带信号通常都是指经过数字调制的,频谱中心点在0Hz的信号。而且没有明确的概念表明基带必须是模拟或者数字的,这完全看具体的实现机制。 言归正传,基带芯片可以认为是包括调制解调器,但不止于调制解调器,还包括信道编解码、信源编解码,以及一些信令处理。而射频芯片,则可看做是最简单的基带调制信号的上变频和下变频。 所谓调制,就是把需要传输的信号,通过一定的规则调制到载波上面让后通过无线收发器(RF Transceiver)发送出去的工程,解调就是相反的过程。 工作原理与电路分析 射频简称RF射频就是射频电流,是一种高频交流变化电磁波,为是Radio Frequency的缩写,表示可以辐射到空间的电磁频率,频率范围在300KHz~300GHz之间。每秒变化小于1000次的交流电称为低频电流,大于10000次的称为高频电流,而射频就是这样一种高频电流。高频(大于10K);射频(300K-300G)是高频的较高频段;微波频段(300M-300G)又是射频的较高频段。射频技术在无线通信领域中被广泛使用,有线电视系统就是采用射频传输方式。 射频芯片指的就是将无线电信号通信转换成一定的无线电信号波形, 并通过天线谐振发送出去的一个电子元器件,它包括功率放大器、低噪声放大器和天线开关。射频芯片架构包括接收通道和发射通道两大部分。 射频电路方框图图片 接收电路的结构和工作原理 接收时,天线把基站发送来电磁波转为微弱交流电流信号经滤波,高频放大后,送入中频内进行解调,得到接收基带信息(RXI-P、RXI-N、RXQ-P、RXQ-N);送到逻辑音频电路进一步处理。 该电路掌握重点:1、接收电路结构;2、各元件的功能与作用;3、接收信号流程。 1.电路结构 接收电路由天线、天线开关、滤波器、高放管(低噪声放大器)、中频集成块(接收解调器)等电路组成。早期手机有一级、二级混频电路,其目的把接收频率降低后再解调(如下图) 接收电路方框图图片 2.各元件的功能与作用 1)、手机天线: 结构:(如下图) 由手机天线分外置和内置天线两种;由天线座、螺线管、塑料封套组成。 图片 作用:a)、接收时把基站发送来电磁波转为微弱交流电流信号。b)、发射时把功放放大后的交流电流转化为电磁波信号。 2)、天线开关: 结构:(如下图) 手机天线开关(合路器、双工滤波器)由四个电子开关构成。 图片 作用: 完成接收和发射切换; 完成900M/1800M信号接收切换。 逻辑电路根据手机工作状态分别送出控制信号(GSM-RX-EN;DCS- RX-EN;GSM-TX-EN;DCS- TX-EN),令各自通路导通,使接收和发射信号各走其道,互不干扰。 由于手机工作时接收和发射不能同时在一个时隙工作(即接收时不发射,发射时不接收)。因此后期新型手机把接收通路的两开关去掉,只留两个发射转换开关;接收切换任务交由高放管完成。 3)、滤波器: 结构:手机中有高频滤波器、中频滤波器。 作用:滤除其他无用信号,得到纯正接收信号。后期新型手机都为零中频手机;因此,手机中再没有中频滤波器。 4)、高放管(高频放大管、低噪声放大器): 结构:手机中高放管有两个:900M高放管、1800M高放管。都是三极管共发射极放大电路;后期新型手机把高放管集成在中频内部。 高频放大管供电图图片 作用: 对天线感应到微弱电流进行放大,满足后级电路对信号幅度的需求。 完成900M/1800M接收信号切换。 原理: 供电:900M/1800M两个高放管的基极偏压共用一路,由中频同时路提供;而两管的集电极的偏压由中频CPU根据手机的接收状态命令中频分两路送出;其目的完成900M/1800M接收信号切换。 经过滤波器滤除其他杂波得到纯正935M-960M的接收信号由电容器耦合后送入相应的高放管放大后经电容器耦合送入中频进行后一级处理。 5)、中频(射频接囗、射频信号处理器): 结构:由接收解调器、发射调制器、发射鉴相器等电路组成;新型手机还把高放管、频率合成、26M振荡及分频电路也集成在内部(如下图)。 图片 作用: a)、内部高放管把天线感应到微弱电流进行放大; b)、接收时把935M-960M(GSM)的接收载频信号(带对方信息)与本振信号(不带信息)进行解调,得到67.707KHZ的接收基带信息; c)、发射时把逻辑电路处理过的发射信息与本振信号调制成发射中频; d)、结合13M/26M晶体产生13M时钟(参考时钟电路); e)、根据CPU送来参考信号,产生符合手机工作信道的本振信号。 3.接收信号流程 手机接收时,天线把基站发送来电磁波转为微弱交流电流信号,经过天线开关接收通路,送高频滤波器滤除其它无用杂波,得到纯正935M-960M(GSM)的接收信号,由电容器耦合送入中频内部相应的高放管放大后,送入解调器与本振信号(不带信息)进行解调,得到67.707KHZ的接收基带信息(RXI-P、RXI-N、RXQ-P、RXQ-N);送到逻辑音频电路进一步处理。 #发射电路的结构和工作原理 发射时,把逻辑电路处理过的发射基带信息调制成的发射中频,用TX-VCO把发射中频信号频率上变为890M-915M(GSM)的频率信号。经功放放大后由天线转为电磁波辐射出去。 该电路掌握重点:(1)、电路结构;(2)、各元件的功能与作用;(3)、发射信号流程。 1.电路结构 发射电路由中频内部的发射调制器、发射鉴相器;发射压控振荡器(TX-VCO)、功率放大器(功放)、功率控制器(功控)、发射互感器等电路组成。(如下图) 发射电路方框图图片 2.各元件的功能与作用 1)、发射调制器: 结构:发射调制器在中频内部,相当于宽带网络中的MOD。 作用:发射时把逻辑电路处理过的发射基带信息(TXI-P;TXI-N;TXQ-P;TXQ-N)与本振信号调制成发射中频。 2)、发射压控振荡器(TX-VCO): 结构:发射压控振荡器是由电压控制输出频率的电容三点式振荡电路;在生产制造时集成为一小电路板上,引出五个脚:供电脚、接地脚、输出脚、控制脚、900M/1800M频段切换脚。当有合适工作电压后便振荡产生相应频率信号。 作用:把中频内调制器调制成的发射中频信号转为基站能接收的890M-915M(GSM)的频率信号。 原理:众所周知,基站只能接收890M-915M(GSM)的频率信号,而中频调制器调制的中频信号(如三星发射中频信号135M)基站不能接收的,因此,要用TX-VCO把发射中频信号频率上变为890M-915M(GSM)的频率信号。 当发射时,电源部分送出3VTX电压使TX-VCO工作,产生890M-915M(GSM)的频率信号分两路走:a)、取样送回中频内部,与本振信号混频产生一个与发射中频相等的发射鉴频信号,送入鉴相器中与发射中频进行较;若TX-VCO振荡出频率不符合手机的工作信道,则鉴相器会产生1-4V跳变电压(带有交流发射信息的直流电压)去控制TX-VCO内部变容二极管的电容量,达到调整频率准确性目的。b)、送入功放经放大后由天线转为电磁波辐射出去。 从上看出:由TX-VCO产生频率到取样送回中频内部,再产生电压去控制TX-VCO工作;刚好形成一个闭合环路,且是控制频率相位的,因此该电路也称发射锁相环电路。 3)、功率放大器(功放): 结构:目前手机的功放为双频功放(900M功放和1800M功放集成一体),分黑胶功放和铁壳功放两种;不同型号功放不能互换。 作用:把TX-VCO振荡出频率信号放大,获得足够功率电流,经天线转化为电磁波辐射出去。 值得注意:功放放大的是发射频率信号的幅值,不能放大他的频率。 功率放大器的工作条件: a)、工作电压(VCC):手机功放供电由电池直接提供(3.6V); b)、接地端(GND):使电流形成回路; c)、双频功换信号(BANDSEL):控制功放工作于900M或工作于1800M; d)、功率控制信号(PAC):控制功放的放大量(工作电流); e)、输入信号(IN);输出信号(OUT)。 4)、发射互感器: 结构:两个线径和匝数相等的线圈相互靠近,利用互感原理组成。 作用:把功放发射功率电流取样送入功控。 原理:当发射时功放发射功率电流经过发射互感器时,在其次级感生与功率电流同样大小的电流,经检波(高频整流)后并送入功控。 5)、功率等级信号: 所谓功率等级就是工程师们在手机编程时把接收信号分为八个等级,每个接收等级对应一级发射功率(如下表),手机在工作时,CPU根据接的信号强度来判断手机与基站距离远近,送出适当的发射等级信号,从而来决定功放的放大量(即接收强时,发射就弱)。 附功率等级表: 图片 6)、功率控制器(功控): 结构:为一个运算比较放大器。 作用:把发射功率电流取样信号和功率等级信号进行比较,得到一个合适电压信号去控制功放的放大量。 原理:当发射时功率电流经过发射互感器时,在其次级感生的电流,经检波(高频整流)后并送入功控;同时编程时预设功率等级信号也送入功控;两个信号在内部比较后产生一个电压信号去控制功放的放大量,使功放工作电流适中,既省电又能长功放使用寿命(功控电压高,功放功率就大)。 3.发射信号流程 当发射时,逻辑电路处理过的发射基带信息(TXI-P;TXI-N;TXQ-P;TXQ-N),送入中频内部的发射调制器,与本振信号调制成发射中频。而中频信号基站不能接收的,要用TX-VCO把发射中频信号频率上升为890M-915M(GSM)的频率信号基站才能接收。当TX-VCO工作后,产生890M-915M(GSM)的频率信号分两路走: a)、一路取样送回中频内部,与本振信号混频产生一个与发射中频相等的发射鉴频信号,送入鉴相器中与发射中频进行较;若TX-VCO振荡出频率不符合手机的工作信道,则鉴相器会产生一个1-4V跳变电压去控制TX-VCO内部变容二极管的电容量,达到调整频率目的。 b)、二路送入功放经放大后由天线转化为电磁波辐射出去。为了控制功放放大量,当发射时功率电流经过发射互感器时,在其次级感生的电流,经检波(高频整流)后并送入功控;同时编程时预设功率等级信号也送入功控;两个信号在内部比较后产生一个电压信号去控制功放的放大量,使功放工作电流适中,既省电又能长功放使用寿命。 国产射频芯片产业链现状 在射频芯片领域,市场主要被海外巨头所垄断,国内射频芯片方面,没有公司能够独立支撑IDM的运营模式,主要为Fabless设计类公司;国内企业通过设计、代工、封装环节的协同,形成了“软IDM“”的运营模式。 图片 射频芯片设计方面,国内公司在5G芯片已经有所成绩,具有一定的出货能力。射频芯片设计具有较高的门槛,具备射频开发经验后,可以加速后续高级品类射频芯片的开发。 射频芯片封装方面,5G射频芯片一方面频率升高导致电路中连接线的对电路性能影响更大,封装时需要减小信号连接线的长度;另一方面需要把功率放大器、低噪声放大器、开关和滤波器封装成为一个模块,一方面减小体积另一方面方便下游终端厂商使用。为了减小射频参数的寄生需要采用Flip-Chip、Fan-In和Fan-Out封装技术。 Flip-Chip和Fan-In、Fan-Out工艺封装时,不需要通过金丝键合线进行信号连接,减少了由于金丝键合线带来的寄生电效应,提高芯片射频性能;到5G时代,高性能的Flip-Chip/Fan-In/Fan-Out结合Sip封装技术会是未来封装的趋势。 在射频芯片领域,市场主要被海外巨头所垄断,国内射频芯片方面,没有公司能够独立支撑IDM的运营模式,主要为Fabless设计类公司;国内企业通过设计、代工、封装环节的协同,形成了“软IDM“”的运营模式。 图片 Flip-Chip/Fan-In/Fan-Out和Sip封装属于高级封装,其盈利能力远高于传统封装。国内上市公司,形成了完整的FlipChip+Sip技术的封装能力。
VLSI&IC验证
# 射频IC
刘航宇
4年前
0
1,456
0
2022-09-30
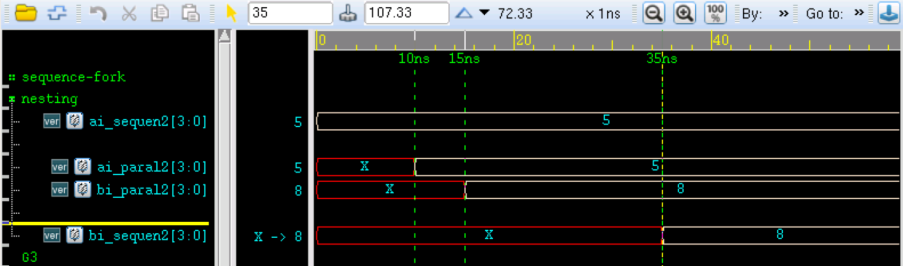
【Verilog编解码】数据的串并转化
目录 一、串转并转换模块1、利用移位寄存器 2、利用计数器 二、并转串转换模块 一、串转并转换模块 1、利用移位寄存器 串行转并行数据输出:采用位拼接技术(移位寄存器),将串行的数据总数先表示出来,然后发送一位数据加一,后面的接收的这样标志: data_o <= {data_o[6:0],data_i }; 这是左移,右移也是可以的,依据项目而定。 1输入8输出 的 串转并模块的Verilog代码 module serial_parallel( input clk, input rst_n,en, input data_i, //一位输入 output reg [7:0] data_o //8位并行输出 ); always @(posedge clk or negedge rst_n) begin if (rst_n == 1'b0) data_o <= 8'b0; else if (en == 1'b1) data_o <= {data_o[6:0], data_i}; //低位先赋值 //data_o <= {data_i,data_o[7:1],}; //高位先赋值 else data_o <= data_o; end endmodule测试代码 `timescale 1ns/100ps module serial_parallel_tb; reg clk,rst_n,en; reg data_i; wire [7:0] data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.en(en),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; en = 0; #20 rst_n = 1; #20 en = 1; data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; #20 data_i = 0; end initial begin forever #10 clk = ~clk; end endmodule2、利用计数器 利用计数器cnt 时钟计数,开始数据先给高位,每过一个时钟周期,数据便给低一位。这样便可以达到串转并的效果 1输入8输出 的 串转并模块的Verilog代码 module serial_parallel( input clk, input rst_n, input data_i, output reg [7:0] data_o ); //msb first most significant bit 表示二进制数据的最高位 reg [2:0] cnt; //计数器0-7 always @(posedge clk or negedge rst_n)begin if(rst_n == 1'b0)begin data_o <= 8'b0; cnt <= 3'd0; end else begin data_o[7 - cnt] <= data_i; //高位先赋值 //data_o[cnt] <= data_i; //低位先赋值 cnt <= cnt + 1'b1; end end endmodule测试代码 `timescale 1ns/100ps module serial_parallel_tb; reg clk,rst_n; reg data_i; wire [7:0] data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; #20 rst_n = 1; data_i = 1; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; end initial begin forever #10 clk = ~clk; end endmodule二、并转串转换模块 并串转换的原理是: 先将八位数据暂存于一个四位寄存器器中,然后左移输出到一位输出端口,这里通过一个“移位”指令。 8输入1输出 的 并转串模块的Verilog代码 使能信号en表示开始执行并转串操作,由于并转串是移位操作,当一次并转串完成后,需要重新载入待转换的并行数据时,使能信号要再起来一次 module parallel_serial(clk, rst_n, en, data_i, data_o); input clk, rst_n,en; input [7:0] data_i; output data_o; reg [7:0] data_buf; always @(posedge clk or negedge rst_n) begin if (rst_n == 1'b0) begin data_buf <= 8'b0; end else if (en == 1'b1) data_buf <= data_i; else data_buf <= data_buf <<1; //将寄存器内的值左移,依次读出 //data_buf <= {data_buf[6:0],1'b0}; end assign data_o = data_buf[7]; endmodule测试代码 `timescale 1ns/100ps module parallel_serial_tb; reg clk,rst_n,en; reg [7:0]data_i; wire data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.en(en),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; en = 0; #10 rst_n = 1; #15 en = 1; data_i = 8'b10111010; #10 en = 0; #195 en = 1; data_i = 8'b10110110; #10 en = 0; end initial begin forever #10 clk = ~clk; end endmodule图片
FPGA&ASIC
刘航宇
4年前
0
970
1
Verilog实现FIFO的设计
FIFO(First In First Out)是异步数据传输时经常使用的存储器。该存储器的特点是数据先进先出(后进后出)。其实,多位宽数据的异步传输问题,无论是从快时钟到慢时钟域,还是从慢时钟到快时钟域,都可以使用 FIFO 处理。 完整的 FIFO 设计见附件,包括输入数据位宽小于输出数据位宽时的异步设计和仿真。 源代码FIFO.zip 下载地址:https://wwu.lanzoub.com/iIdvu0am46cf 提取码: 目录 FIFO 原理工作流程 读写时刻 读空状态 写满状态 FIFO 设计设计要求 双口 RAM 设计 计数器设计 FIFO 设计FIFO 调用 testbench 仿真分析 FIFO 原理 工作流程 复位之后,在写时钟和状态信号的控制下,数据写入 FIFO 中。RAM 的写地址从 0 开始,每写一次数据写地址指针加一,指向下一个存储单元。当 FIFO 写满后,数据将不能再写入,否则数据会因覆盖而丢失。 FIFO 数据为非空、或满状态时,在读时钟和状态信号的控制下,可以将数据从 FIFO 中读出。RAM 的读地址从 0 开始,每读一次数据读地址指针加一,指向下一个存储单元。当 FIFO 读空后,就不能再读数据,否则读出的数据将是错误的。 FIFO 的存储结构为双口 RAM,所以允许读写同时进行。典型异步 FIFO 结构图如下所示。端口及内部信号将在代码编写时进行说明。 图片 读写时刻 关于写时刻,只要 FIFO 中数据为非满状态,就可以进行写操作;如果 FIFO 为满状态,则禁止再写数据。 关于读时刻,只要 FIFO 中数据为非空状态,就可以进行读操作;如果 FIFO 为空状态,则禁止再读数据。 不管怎样,一段正常读写 FIFO 的时间段,如果读写同时进行,则要求写 FIFO 速率不能大于读速率。 读空状态 开始复位时,FIFO 没有数据,空状态信号是有效的。当 FIFO 中被写入数据后,空状态信号拉低无效。当读数据地址追赶上写地址,即读写地址都相等时,FIFO 为空状态。 因为是异步 FIFO,所以读写地址进行比较时,需要同步打拍逻辑,就需要耗费一定的时间。所以空状态的指示信号不是实时的,会有一定的延时。如果在这段延迟时间内又有新的数据写入 FIFO,就会出现空状态指示信号有效,但是 FIFO 中其实存在数据的现象。 严格来讲该空状态指示是错误的。但是产生空状态的意义在于防止读操作对空状态的 FIFO 进行数据读取。产生空状态信号时,实际 FIFO 中有数据,相当于提前判断了空状态信号,此时不再进行读 FIFO 数据操作也是安全的。所以,该设计从应用上来说是没有问题的。 写满状态 开始复位时,FIFO 没有数据,满信号是无效的。当 FIFO 中被写入数据后,此时读操作不进行或读速率相对较慢,只要写数据地址超过读数据地址一个 FIFO 深度时,便会产生满状态信号。此时写地址和读地址也是相等的,但是意义是不一样的。 图片 此时经常使用多余的 1bit 分别当做读写地址的拓展位,来区分读写地址相同的时候,FIFO 的状态是空还是满状态。当读写地址与拓展位均相同的时候,表明读写数据的数量是一致的,则此时 FIFO 是空状态。如果读写地址相同,拓展位为相反数,表明写数据的数量已经超过读数据数量的一个 FIFO 深度了,此时 FIFO 是满状态。当然,此条件成立的前提是空状态禁止读操作、满状态禁止写操作。 同理,由于异步延迟逻辑的存在,满状态信号也不是实时的。但是也相当于提前判断了满状态信号,此时不再进行写 FIFO 操作也不会影响应用的正确性。 FIFO 设计 设计要求 为设计应用于各种场景的 FIFO,这里对设计提出如下要求: (1) FIFO 深度、宽度参数化,输出空、满状态信号,并输出一个可配置的满状态信号。当 FIFO 内部数据达到设置的参数数量时,拉高该信号。 (2) 输入数据和输出数据位宽可以不一致,但要保证写数据、写地址位宽与读数据、读地址位宽的一致性。例如写数据位宽 8bit,写地址位宽为 6bit(64 个数据)。如果输出数据位宽要求 32bit,则输出地址位宽应该为 4bit(16 个数据)。 (3) FIFO 是异步的,即读写控制信号来自不同的时钟域。输出空、满状态信号之前,读写地址信号要用格雷码做同步处理,通过减少多位宽信号的翻转来减少打拍法同步时数据的传输错误。 格雷码与二进制之间的转换如下图所示。 图片 双口 RAM 设计 RAM 端口参数可配置,读写位宽可以不一致。建议 memory 数组定义时,以长位宽地址、短位宽数据的参数为参考,方便数组变量进行选择访问。 Verilog 描述如下。 module ramdp #( parameter AWI = 5 , parameter AWO = 7 , parameter DWI = 64 , parameter DWO = 16 ) ( input CLK_WR , //写时钟 input WR_EN , //写使能 input [AWI-1:0] ADDR_WR ,//写地址 input [DWI-1:0] D , //写数据 input CLK_RD , //读时钟 input RD_EN , //读使能 input [AWO-1:0] ADDR_RD ,//读地址 output reg [DWO-1:0] Q //读数据 ); //输出位宽大于输入位宽,求取扩大的倍数及对应的位数 parameter EXTENT = DWO/DWI ; parameter EXTENT_BIT = AWI-AWO > 0 ? AWI-AWO : 'b1 ; //输入位宽大于输出位宽,求取缩小的倍数及对应的位数 parameter SHRINK = DWI/DWO ; parameter SHRINK_BIT = AWO-AWI > 0 ? AWO-AWI : 'b1; genvar i ; generate //数据位宽展宽(地址位宽缩小) if (DWO >= DWI) begin //写逻辑,每时钟写一次 reg [DWI-1:0] mem [(1<<AWI)-1 : 0] ; always @(posedge CLK_WR) begin if (WR_EN) begin mem[ADDR_WR] <= D ; end end //读逻辑,每时钟读 4 次 for (i=0; i<EXTENT; i=i+1) begin always @(posedge CLK_RD) begin if (RD_EN) begin Q[(i+1)*DWI-1: i*DWI] <= mem[(ADDR_RD*EXTENT) + i ] ; end end end end //================================================= //数据位宽缩小(地址位宽展宽) else begin //写逻辑,每时钟写 4 次 reg [DWO-1:0] mem [(1<<AWO)-1 : 0] ; for (i=0; i<SHRINK; i=i+1) begin always @(posedge CLK_WR) begin if (WR_EN) begin mem[(ADDR_WR*SHRINK)+i] <= D[(i+1)*DWO -1: i*DWO] ; end end end //读逻辑,每时钟读 1 次 always @(posedge CLK_RD) begin if (RD_EN) begin Q <= mem[ADDR_RD] ; end end end endgenerate endmodule计数器设计 计数器用于产生读写地址信息,位宽可配置,不需要设置结束值,让其溢出后自动重新计数即可。Verilg 描述如下。 module ccnt #(parameter W ) ( input rstn , input clk , input en , output [W-1:0] count ); reg [W-1:0] count_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin count_r <= 'b0 ; end else if (en) begin count_r <= count_r + 1'b1 ; end end assign count = count_r ; endmoduleFIFO 设计 该模块为 FIFO 的主体部分,产生读写控制逻辑,并产生空、满、可编程满状态信号。 鉴于篇幅原因,这里只给出读数据位宽大于写数据位宽的逻辑代码,写数据位宽大于读数据位宽的代码描述详见附件。 module fifo #( parameter AWI = 5 , parameter AWO = 3 , parameter DWI = 4 , parameter DWO = 16 , parameter PROG_DEPTH = 16) //可设置深度 ( input rstn, //读写使用一个复位 input wclk, //写时钟 input winc, //写使能 input [DWI-1: 0] wdata, //写数据 input rclk, //读时钟 input rinc, //读使能 output [DWO-1 : 0] rdata, //读数据 output wfull, //写满标志 output rempty, //读空标志 output prog_full //可编程满标志 ); //输出位宽大于输入位宽,求取扩大的倍数及对应的位数 parameter EXTENT = DWO/DWI ; parameter EXTENT_BIT = AWI-AWO ; //输出位宽小于输入位宽,求取缩小的倍数及对应的位数 parameter SHRINK = DWI/DWO ; parameter SHRINK_BIT = AWO-AWI ; //==================== push/wr counter =============== wire [AWI-1:0] waddr ; wire wover_flag ; //多使用一位做写地址拓展 ccnt #(.W(AWI+1)) u_push_cnt( .rstn (rstn), .clk (wclk), .en (winc && !wfull), //full 时禁止写 .count ({wover_flag, waddr}) ); //============== pop/rd counter =================== wire [AWO-1:0] raddr ; wire rover_flag ; //多使用一位做读地址拓展 ccnt #(.W(AWO+1)) u_pop_cnt( .rstn (rstn), .clk (rclk), .en (rinc & !rempty), //empyt 时禁止读 .count ({rover_flag, raddr}) ); //============================================== //窄数据进,宽数据出 generate if (DWO >= DWI) begin : EXTENT_WIDTH //格雷码转换 wire [AWI:0] wptr = ({wover_flag, waddr}>>1) ^ ({wover_flag, waddr}) ; //将写数据指针同步到读时钟域 reg [AWI:0] rq2_wptr_r0 ; reg [AWI:0] rq2_wptr_r1 ; always @(posedge rclk or negedge rstn) begin if (!rstn) begin rq2_wptr_r0 <= 'b0 ; rq2_wptr_r1 <= 'b0 ; end else begin rq2_wptr_r0 <= wptr ; rq2_wptr_r1 <= rq2_wptr_r0 ; end end //格雷码转换 wire [AWI-1:0] raddr_ex = raddr << EXTENT_BIT ; wire [AWI:0] rptr = ({rover_flag, raddr_ex}>>1) ^ ({rover_flag, raddr_ex}) ; //将读数据指针同步到写时钟域 reg [AWI:0] wq2_rptr_r0 ; reg [AWI:0] wq2_rptr_r1 ; always @(posedge wclk or negedge rstn) begin if (!rstn) begin wq2_rptr_r0 <= 'b0 ; wq2_rptr_r1 <= 'b0 ; end else begin wq2_rptr_r0 <= rptr ; wq2_rptr_r1 <= wq2_rptr_r0 ; end end //格雷码反解码 //如果只需要空、满状态信号,则不需要反解码 //因为可编程满状态信号的存在,地址反解码后便于比较 reg [AWI:0] wq2_rptr_decode ; reg [AWI:0] rq2_wptr_decode ; integer i ; always @(*) begin wq2_rptr_decode[AWI] = wq2_rptr_r1[AWI]; for (i=AWI-1; i>=0; i=i-1) begin wq2_rptr_decode[i] = wq2_rptr_decode[i+1] ^ wq2_rptr_r1[i] ; end end always @(*) begin rq2_wptr_decode[AWI] = rq2_wptr_r1[AWI]; for (i=AWI-1; i>=0; i=i-1) begin rq2_wptr_decode[i] = rq2_wptr_decode[i+1] ^ rq2_wptr_r1[i] ; end end //读写地址、拓展位完全相同是,为空状态 assign rempty = (rover_flag == rq2_wptr_decode[AWI]) && (raddr_ex >= rq2_wptr_decode[AWI-1:0]); //读写地址相同、拓展位不同,为满状态 assign wfull = (wover_flag != wq2_rptr_decode[AWI]) && (waddr >= wq2_rptr_decode[AWI-1:0]) ; //拓展位一样时,写地址必然不小于读地址 //拓展位不同时,写地址部分比如小于读地址,实际写地址要增加一个FIFO深度 assign prog_full = (wover_flag == wq2_rptr_decode[AWI]) ? waddr - wq2_rptr_decode[AWI-1:0] >= PROG_DEPTH-1 : waddr + (1<<AWI) - wq2_rptr_decode[AWI-1:0] >= PROG_DEPTH-1; //双口 ram 例化 ramdp #( .AWI (AWI), .AWO (AWO), .DWI (DWI), .DWO (DWO)) u_ramdp ( .CLK_WR (wclk), .WR_EN (winc & !wfull), //写满时禁止写 .ADDR_WR (waddr), .D (wdata[DWI-1:0]), .CLK_RD (rclk), .RD_EN (rinc & !rempty), //读空时禁止读 .ADDR_RD (raddr), .Q (rdata[DWO-1:0]) ); end //============================================== //big in and small out /* else begin: SHRINK_WIDTH …… end */ endgenerate endmoduleFIFO 调用 下面可以调用设计的 FIFO,完成多位宽数据传输的异步处理。 写数据位宽为 4bit,写深度为 32。 读数据位宽为 16bit,读深度为 8,可配置 full 深度为 16。 module fifo_s2b( input rstn, input [4-1: 0] din, //异步写数据 input din_clk, //异步写时钟 input din_en, //异步写使能 output [16-1 : 0] dout, //同步后数据 input dout_clk, //同步使用时钟 input dout_en ); //同步数据使能 wire fifo_empty, fifo_full, prog_full ; wire rd_en_wir ; wire [15:0] dout_wir ; //读空状态时禁止读,否则一直读 assign rd_en_wir = fifo_empty ? 1'b0 : 1'b1 ; fifo #(.AWI(5), .AWO(3), .DWI(4), .DWO(16), .PROG_DEPTH(16)) u_buf_s2b( .rstn (rstn), .wclk (din_clk), .winc (din_en), .wdata (din), .rclk (dout_clk), .rinc (rd_en_wir), .rdata (dout_wir), .wfull (fifo_full), .rempty (fifo_empty), .prog_full (prog_full)); //缓存同步后的数据和使能 reg dout_en_r ; always @(posedge dout_clk or negedge rstn) begin if (!rstn) begin dout_en_r <= 1'b0 ; end else begin dout_en_r <= rd_en_wir ; end end assign dout = dout_wir ; assign dout_en = dout_en_r ; endmoduletestbench `timescale 1ns/1ns `define SMALL2BIG module test ; `ifdef SMALL2BIG reg rstn ; reg clk_slow, clk_fast ; reg [3:0] din ; reg din_en ; wire [15:0] dout ; wire dout_en ; //reset initial begin clk_slow = 0 ; clk_fast = 0 ; rstn = 0 ; #50 rstn = 1 ; end //读时钟 clock_slow 较快于写时钟 clk_fast 的 1/4 //保证读数据稍快于写数据 parameter CYCLE_WR = 40 ; always #(CYCLE_WR/2/4) clk_fast = ~clk_fast ; always #(CYCLE_WR/2-1) clk_slow = ~clk_slow ; //data generate initial begin din = 16'h4321 ; din_en = 0 ; wait (rstn) ; //(1) 测试 full、prog_full、empyt 信号 force test.u_data_buf2.u_buf_s2b.rinc = 1'b0 ; repeat(32) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end @(negedge clk_fast) din_en = 1'b0 ; //(2) 测试数据读写 #500 ; rstn = 0 ; #10 rstn = 1 ; release test.u_data_buf2.u_buf_s2b.rinc; repeat(100) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end //(3) 停止读取再一次测试 empyt、full、prog_full 信号 force test.u_data_buf2.u_buf_s2b.rinc = 1'b0 ; repeat(18) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end end fifo_s2b u_data_buf2( .rstn (rstn), .din (din), .din_clk (clk_fast), .din_en (din_en), .dout (dout), .dout_clk (clk_slow), .dout_en (dout_en)); `else `endif //stop sim initial begin forever begin #100; if ($time >= 5000) $finish ; end end endmodule仿真分析 根据 testbench 中的 3 步测试激励,分析如下: 测试 (1) : FIFO 端口及一些内部信号时序结果如下。 由图可知,FIFO 内部开始写数据,空状态信号拉低之前有一段时间延迟,这是同步读写地址信息导致的。 由于此时没有进行读 FIFO 操作,相对于写数据操作,full 和 prog_full 拉高几乎没有延迟。 图片 测试 (2) : FIFO 同时进行读写时,数字顶层异步处理模块的端口信号如下所示,两图分别显示了数据开始传输、结束传输时的读取过程。 由图可知,数据在开始、末尾均能正确传输,完成了不同时钟域之间多位宽数据的异步处理。 图片 图片 测试 (3) :整个 FIFO 读写行为及读停止的时序仿真图如下所示。 由图可知,读写同时进行时,读空状态信号 rempty 会拉低,表明 FIFO 中有数据写入。一方面读数据速率稍高于写速率,且数据之间传输会有延迟,所以中间过程中 rempty 会有拉高的行为。 读写过程中,full 与 prog_full 信号一直为低,说明 FIFO 中数据并没有到达一定的数量。当停止读操作后,两个 full 信号不久便拉高,表明 FIFO 已满。仔细对比读写地址信息,FIFO 行为没有问题。 图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
4年前
0
849
2
2022-08-30
【verilog】单端口与双端口RAM设计
RAM (Random Access Memory)随机访问存储器. RAM又称随机存取存储器,存储单元的内容可按照需要随机取出或存入,且存取的速度与存储单元的位置无关。这种存储器在断电时,将丢失其存储内容,所以主要用于存储短时间使用的程序。它主要用来存储程序中用到的变量。凡是整个程序中,所用到的需要被改写的量(包括全局变量、局部变量、堆栈段等),都存储在RAM中。 目录 单端口RAM设计 双端口RAM设计 单端口RAM设计 题目描述: 设计一个单端口RAM,它有: 写接口,读接口,地址接口,时钟接口和复位;存储宽度是4位,深度128。 注意rst为低电平复位 信号示意图: 图片 输入描述: 输入信号 enb, clk, rst addr w_data 类型 wire 在testbench中,clk为周期5ns的时钟,rst为低电平复位 输出描述: 输出信号 r_data 类型 wire `timescale 1ns/1ns module RAM_1port( input clk, input rst, input enb, input [6:0]addr, input [3:0]w_data, output wire [3:0]r_data ); //*************code***********// reg [3:0] ram_reg[127:0]; reg [3:0] ram_data; integer i; always@(posedge clk or negedge rst)begin if(~rst) begin for(i=0;i<128;i=i+1)begin ram_reg[i]<=4'b0; end end else begin if(enb)begin//wire ram_reg[addr]<=w_data; end else begin ram_reg[addr]<=ram_reg[addr]; end end end assign r_data = enb? 4'b0:ram_reg[addr]; //*************code***********// endmodule双端口RAM设计 描述 实现一个深度为8,位宽为4bit的双端口RAM,数据全部初始化为0000。具有两组端口,分别用于读数据和写数据,读写操作可以同时进行。当读数据指示信号read_en有效时,通过读地址信号read_addr读取相应位置的数据read_data,并输出;当写数据指示信号write_en有效时,通过写地址信号write_addr 和写数据write-data,向对应位置写入相应的数据。 程序的信号接口图如下: 图片 模块的时序图如下: 图片 使用Verilog HDL实现以上功能并编写testbench验证。 输入描述: clk:系统时钟信号 rst_n:异步复位信号,低电平有效 read_en,write_en:单比特信号,读/写使能信号,表示进行读/写操作 read_addr,write_addr:8比特位宽的信号,表示读/写操作对应的地址 write_data:4比特位宽的信号,在执行写操作时写入RAM的数据 输出描述: read_data:4比特位宽的信号,在执行读操作时从RAM中读出的数据 `timescale 1ns/1ns module ram_mod( input clk, input rst_n, input write_en, input [7:0]write_addr, input [3:0]write_data, input read_en, input [7:0]read_addr, output reg [3:0]read_data ); reg [3:0] ram_reg[7:0]; integer i; always@(posedge clk or negedge rst_n)begin if(~rst_n) begin for(i=0;i<8;i=i+1)begin ram_reg[i]<=4'b0; end end else begin if(write_en)begin ram_reg[write_addr]<=write_data; end end end always@(posedge clk or negedge rst_n)begin if(~rst_n) begin read_data<=4'b0; end else begin if(read_en)begin read_data<=ram_reg[read_addr]; end end end endmodule
FPGA&ASIC
刘航宇
4年前
0
1,504
0
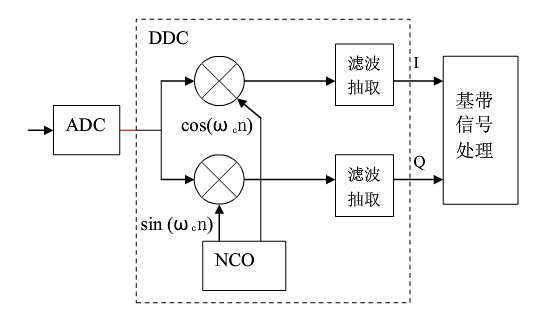
Verilog教程-CIC 滤波器设计
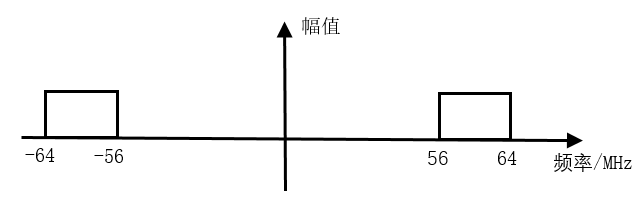
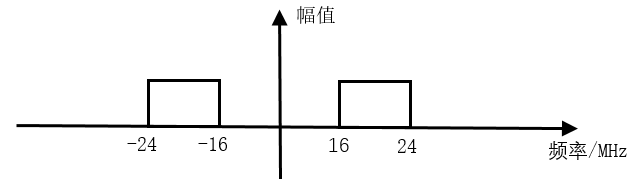
积分梳状滤波器(CIC,Cascaded Integrator Comb),一般用于数字下变频(DDC)和数字上变频(DUC)系统。CIC 滤波器结构简单,没有乘法器,只有加法器、积分器和寄存器,资源消耗少,运算速率高,可实现高速滤波,常用在输入采样率最高的第一级,在多速率信号处理系统中具有着广泛应用。 目录 DDC 原理 带通采样定理 DDC 频谱搬移 单级 CIC 滤波器 积分器 梳状器 抽取器 参数说明 多级 CIC 滤波器 CIC 滤波器设计 积分器设计 抽取器设计 梳状器设计 顶层例化 仿真结果 DDC 原理 DDC 工作原理 DDC 主要由本地振荡器(NCO) 、混频器、滤波器等组成,如下图所示。 图片 DDC 将中频信号与振荡器产生的载波信号进行混频,信号中心频率被搬移,再经过抽取滤波,恢复原始信号,实现了下变频功能。 中频数据采样时,需要很高的采样频率来确保 ADC(模数转换器)采集到信号的信噪比。经过数字下变频后,得到的基带信号采样频率仍然是 ADC 采样频率,所以数据率很高。此时基带信号的有效带宽往往已经远小于采样频率,所以利用抽取、滤波进行数据速率的转换,使采样率降低,避免资源的浪费和设计的困难,就成为 DDC 不可缺少的一部分。 而采用 CIC 滤波器进行数据处理,是 DDC 抽取滤波部分最常用的方法。 带通采样定理 在 DDC 系统中,输入的中频载波信号会根据载波频率进行频移,得到一个带通信号。如果此时仍然采用奈奎斯特采样定理,即采样频率为带通信号最高频率的两倍,那么此时所需的采样频率将会很高,设计会变的复杂。此时可按照带通采样定理来确定抽样频率。 带通采样定理:一个频带限制在$\left(f_{L}, f_{H}\right)$的连续带通信号,带宽为$\mathrm{B}=f_{H}-f_{L}$。令$0 \leq m \leq N-1$,其中 N 为不大于$f_{H} / B$的最大正整数,如果采样频率满足条件:$\frac{2 f_{H}}{m+1} \leq F_{S} \leq \frac{2 f_{L}}{m}$,$0 \leq m \leq N-1$ 则该信号完全可以由其采样值无失真的重建。 当 m=1 时,带通采样定理便是奈奎斯特采样定理。 带通采样定理的另一种描述方式为:若信号最高频率为信号带宽的整数倍,采样频率只需大于信号带宽的两倍即可,此时不会发生频谱混叠。 所以,可以认为采样频率的一半是 CIC 滤波器的截止频率。 DDC 频谱搬移 例如一个带宽信号中心频率为 60MHz,带宽为 8MHz, 则频率范围为 56MHz ~ 64MHz,m 的可取值范围为 0 ~ 7。取 m=1, 则采样频率范围为 64MHz ~ 112MHz。 取采样频率为 80MHz,设 NCO 中心频率为 20 MHz,下面讨论复信号频谱搬移示意图。 (1)考虑频谱的对称性,输入复信号的频谱示意图如下: 图片 (2)80MHz 采样频率采样后,56~64MHz 的频带被搬移到了 -24~ -16MHz 与 136 ~ 144MHz(高于采样频率被滤除)的频带处,-64~ -56MHz 的频带被搬移到 -144~ -136MHz(高于采样频率被滤除)与 16~24MHz 的频带处。 采样后频带分布如下: 图片 (3)信号经过 20MHz NCO 的正交电路后, -24~ -16MHz 的频带被搬移到 -4~4MHz 与 -44~ -36MHz 的频带处,16~24MHz 的频带被搬移到 -4~4MHz 与 36~44MHz 的频带处,如下所示。 图片 (4)此时中频输入的信号已经被搬移到零中频基带处。 -44~ -36MHz 和 36~44MHz 的带宽信号是不需要的,可以滤除;-4~4MHz 的零中频信号数据速率仍然是 80MHz,可以进行抽取降低数据速率。而 CIC 滤波,就是要完成这个过程。 上述复习了很多数字信号处理的内容,权当抛 DDC 的砖,引 CIC 的玉。 CIC 滤波器原理 单级 CIC 滤波器 设滤波器抽取倍数为 D,则单级滤波器的冲激响应为: 图片 对其进行 z 变换,可得单级 CIC 滤波器的系统函数为: 图片 令 图片 可以看出,单级 CIC 滤波器包括两个基本组成部分:积分部分和梳状部分,结构图如下: 图片 积分器 积分器是一个单级点的 IIR(Infinite Impulse Response,无限长脉冲冲激响应)滤波器,且反馈系数为 1,其状态方程和系统函数分别为: 图片 图片 梳状器 梳状器是一个 FIR 滤波器,其状态方程和系统函数分别为: 图片 图片 抽取器 在积分器之后,还有一个抽取器,抽取倍数与梳状器的延时参数是一致的。利用 z 变换的性质进行恒等变换,将抽取器移动到积分器与梳状器之间,可得到单级 CIC 滤波器结构,如下所示。 图片 参数说明 CIC 滤波器结构变换之前的参数 D 可以理解为梳状滤波器的延时或阶数;变换之后,D 的含义 变为抽取倍数,而此时梳状滤波器的延时为 1,即阶数为 1。 很多学者会引入一个变量 M,表示梳状器每一级的延时,此时梳妆部分的延时就不为 1 了。那么梳状器的系统函数就变为: 图片 其实把 DM 整体理解为单级滤波器延时,或者抽取倍数,也都是可以的。可能实现的方式或结构不同,但是最后的结果都是一样的。本次设计中,单级滤波器延时都为 M=1,即抽取倍数与滤波延时相同。 多级 CIC 滤波器 单级 CIC 滤波器的阻带衰减较差,为了提高滤波效果,抽取滤波时往往会采用多级 CIC 滤波器级联的结构。 实现多级直接级联的 CIC 滤波器在设计和资源上并不是最优的方式,需要对其结构进行调整。如下所示,将积分器和梳状滤波器分别移至一组,并将抽取器移到梳状滤波器之前。先抽取再进行滤波,可以减少数据处理的长度,节约硬件资源。 图片 当然,级联数越大,旁瓣抑制越好,但是通带内的平坦度也会变差。所以级联数不宜过多,一般最多 5 级。 CIC 滤波器设计 设计说明 CIC 滤波器本质上就是一个简单的低通滤波器,截止频率为采样频率除以抽取倍数后的一半。输入数据信号仍然是 7.5MHz 和 250KHz,采样频率 50MHz。抽取倍数设置为 5,则截止频率为 5MHz,小于 7.5MHz,可以滤除 7.5MHz 的频率成分。设计参数如下: 输入频率: 7.5MHz 和 250KHz 采样频率: 50MHz 阻带: 5MHz 阶数: 1(M=1) 级数: 3(N=3) 关于积分时中间数据信号的位宽,很多地方给出了不同的计算方式,计算结果也大相径庭。这里总结一下使用最多的计算方式: 图片 其中,D 为抽取倍数,M 为滤波器阶数,N 为滤波器级数。抽取倍数为 5,滤波器阶数为 1,滤波器级联数为 3,取输入信号数据位宽为 12bit,对数部分向上取整,则积分后数据不溢出的中间信号位宽为 21bit。 为了更加宽裕的设计,滤波器阶数如果理解为未变换结构前的多级 CIC 滤波器直接型结构,则滤波器阶数可以认为是 5,此时中间信号最大位宽为 27bit。 积分器设计 根据输入数据的有效信号的控制,积分器做一个简单的累加即可,注意数据位宽。 //3 stages integrator module integrator #(parameter NIN = 12, parameter NOUT = 21) ( input clk , input rstn , input en , input [NIN-1:0] din , output valid , output [NOUT-1:0] dout) ; reg [NOUT-1:0] int_d0 ; reg [NOUT-1:0] int_d1 ; reg [NOUT-1:0] int_d2 ; wire [NOUT-1:0] sxtx = {{(NOUT-NIN){1'b0}}, din} ; //data input enable delay reg [2:0] en_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin en_r <= 'b0 ; end else begin en_r <= {en_r[1:0], en}; end end //integrator //stage1 always @(posedge clk or negedge rstn) begin if (!rstn) begin int_d0 <= 'b0 ; end else if (en) begin int_d0 <= int_d0 + sxtx ; end end //stage2 always @(posedge clk or negedge rstn) begin if (!rstn) begin int_d1 <= 'b0 ; end else if (en_r[0]) begin int_d1 <= int_d1 + int_d0 ; end end //stage3 always @(posedge clk or negedge rstn) begin if (!rstn) begin int_d2 <= 'b0 ; end else if (en_r[1]) begin int_d2 <= int_d2 + int_d1 ; end end assign dout = int_d2 ; assign valid = en_r[2]; endmodule抽取器设计 抽取器设计时,对积分器输出的数据进行计数,然后间隔 5 个数据进行抽取即可。 module decimation #(parameter NDEC = 21) ( input clk, input rstn, input en, input [NDEC-1:0] din, output valid, output [NDEC-1:0] dout); reg valid_r ; reg [2:0] cnt ; reg [NDEC-1:0] dout_r ; //counter always @(posedge clk or negedge rstn) begin if (!rstn) begin cnt <= 3'b0; end else if (en) begin if (cnt==4) begin cnt <= 'b0 ; end else begin cnt <= cnt + 1'b1 ; end end end //data, valid always @(posedge clk or negedge rstn) begin if (!rstn) begin valid_r <= 1'b0 ; dout_r <= 'b0 ; end else if (en) begin if (cnt==4) begin valid_r <= 1'b1 ; dout_r <= din; end else begin valid_r <= 1'b0 ; end end end assign dout = dout_r ; assign valid = valid_r ; endmodule梳状器设计 梳状滤波器就是简单的一阶 FIR 滤波器,每一级的 FIR 滤波器对数据进行一个时钟延时,然后做相减即可。因为系数为 ±1,所以不需要乘法器。 module comb #(parameter NIN = 21, parameter NOUT = 17) ( input clk, input rstn, input en, input [NIN-1:0] din, input valid, output [NOUT-1:0] dout); //en delay reg [5:0] en_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin en_r <= 'b0 ; end else if (en) begin en_r <= {en_r[5:0], en} ; end end reg [NOUT-1:0] d1, d1_d, d2, d2_d, d3, d3_d ; //stage 1, as fir filter, shift and add(sub), //no need for multiplier always @(posedge clk or negedge rstn) begin if (!rstn) d1 <= 'b0 ; else if (en) d1 <= din ; end always @(posedge clk or negedge rstn) begin if (!rstn) d1_d <= 'b0 ; else if (en) d1_d <= d1 ; end wire [NOUT-1:0] s1_out = d1 - d1_d ; //stage 2 always @(posedge clk or negedge rstn) begin if (!rstn) d2 <= 'b0 ; else if (en) d2 <= s1_out ; end always @(posedge clk or negedge rstn) begin if (!rstn) d2_d <= 'b0 ; else if (en) d2_d <= d2 ; end wire [NOUT-1:0] s2_out = d2 - d2_d ; //stage 3 always @(posedge clk or negedge rstn) begin if (!rstn) d3 <= 'b0 ; else if (en) d3 <= s2_out ; end always @(posedge clk or negedge rstn) begin if (!rstn) d3_d <= 'b0 ; else if (en) d3_d <= d3 ; end wire [NOUT-1:0] s3_out = d3 - d3_d ; //tap the output data for better display reg [NOUT-1:0] dout_r ; reg valid_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin dout_r <= 'b0 ; valid_r <= 'b0 ; end else if (en) begin dout_r <= s3_out ; valid_r <= 1'b1 ; end else begin valid_r <= 1'b0 ; end end assign dout = dout_r ; assign valid = valid_r ; endmodule顶层例化 按信号的流向将积分器、抽取器、梳状器分别例化,即可组成最后的 CIC 滤波器模块。 梳状滤波器的最终输出位宽一般会比输入信号小一些,这里取 17bit。当然输出位宽完全可以与输入数据的位宽一致。 module cic #(parameter NIN = 12, parameter NMAX = 21, parameter NOUT = 17) ( input clk, input rstn, input en, input [NIN-1:0] din, input valid, output [NOUT-1:0] dout); wire [NMAX-1:0] itg_out ; wire [NMAX-1:0] dec_out ; wire [1:0] en_r ; integrator #(.NIN(NIN), .NOUT(NMAX)) u_integrator ( .clk (clk), .rstn (rstn), .en (en), .din (din), .valid (en_r[0]), .dout (itg_out)); decimation #(.NDEC(NMAX)) u_decimator ( .clk (clk), .rstn (rstn), .en (en_r[0]), .din (itg_out), .dout (dec_out), .valid (en_r[1])); comb #(.NIN(NMAX), .NOUT(NOUT)) u_comb ( .clk (clk), .rstn (rstn), .en (en_r[1]), .din (dec_out), .valid (valid), .dout (dout)); endmoduletestbench testbench 编写如下,主要功能就是不间断连续的输入 250KHz 与 7.5MHz 的正弦波混合信号数据。输入的混合信号数据也可由 matlab 生成,具体过程参考《并行 FIR 滤波器设计》一节。 module test ; parameter NIN = 12 ; parameter NMAX = 21 ; parameter NOUT = NMAX ; reg clk ; reg rstn ; reg en ; reg [NIN-1:0] din ; wire valid ; wire [NOUT-1:0] dout ; //===================================== // 50MHz clk generating localparam T50M_HALF = 10000; initial begin clk = 1'b0 ; forever begin # T50M_HALF clk = ~clk ; end end //============================ // reset and finish initial begin rstn = 1'b0 ; # 30 ; rstn = 1'b1 ; # (T50M_HALF * 2 * 2000) ; $finish ; end //======================================= // read cos data into register parameter SIN_DATA_NUM = 200 ; reg [NIN-1:0] stimulus [0: SIN_DATA_NUM-1] ; integer i ; initial begin $readmemh("../tb/cosx0p25m7p5m12bit.txt", stimulus) ; i = 0 ; en = 0 ; din = 0 ; # 200 ; forever begin @(negedge clk) begin en = 1 ; din = stimulus[i] ; if (i == SIN_DATA_NUM-1) begin i = 0 ; end else begin i = i + 1 ; end end end end cic #(.NIN(NIN), .NMAX(NMAX), .NOUT(NOUT)) u_cic ( .clk (clk), .rstn (rstn), .en (en), .din (din), .valid (valid), .dout (dout)); endmodule // test仿真结果 由下图仿真结果可知,经过 CIC 滤波器后的信号只有一种低频率信号(250KHz),高频信号(7.5MHz)被滤除了。 但是波形不是非常完美,这与设计的截止频率、数据不是持续输出等有一定关系。 此时发现,积分器输出的数据信号也非常的不规则,这与其位宽有关系。 图片 为了更好的观察积分器输出的数据,将其位宽由 21bit 改为 34bit,仿真结果如下。 此时发现,CIC 滤波器的数据输出并没有实质性的变化,但是积分器输出的数据信号呈现锯齿状,也称之为梳状。这也是梳状滤波器名字的由来。 图片
FPGA&ASIC
刘航宇
4年前
0
1,407
2
2022-08-13
Verilog 实现并行 FIR 滤波器设计
FIR(Finite Impulse Response)滤波器是一种有限长单位冲激响应滤波器,又称为非递归型滤波器。 FIR 滤波器具有严格的线性相频特性,同时其单位响应是有限长的,因而是稳定的系统,在数字通信、图像处理等领域都有着广泛的应用。 目录 FIR 滤波器原理 并行 FIR 滤波器设计 并行设计 仿真结果 附录:matlab 使用 生成输入的混合信号 FIR 滤波器原理 FIR 滤波器是有限长单位冲击响应滤波器。直接型结构如下: 图片 FIR 滤波器本质上就是输入信号与单位冲击响应函数的卷积,表达式如下: 图片 FIR 滤波器有如下几个特性: (1) 响应是有限长序列。 (2) 系统函数在 |z| > 0 处收敛,极点全部在 z=0 处,属于因果系统。 (3) 结构上是非递归的,没有输出到输入的反馈。 (4) 输入信号相位响应是线性的,因为响应函数 h(n) 系数是对称的。 (5) 输入信号的各频率之间,相对相位差也是固定不变的。 (6) 时域卷积等于频域相乘,因此该卷积相当于筛选频谱中各频率分量的增益倍数。某些频率分量保留,某些频率分量衰减,从而实现滤波的效果。 并行 FIR 滤波器设计 设计说明 输入频率为 7.5 MHz 和 250 KHz 的正弦波混合信号,经过 FIR 滤波器后,高频信号 7.5MHz 被滤除,只保留 250KHz 的信号。设计参数如下: 输入频率: 7.5MHz 和 250KHz 采样频率: 50MHz 阻带: 1MHz ~ 6MHz 阶数: 15(N-1=15) 由 FIR 滤波器结构可知,阶数为 15 时,FIR 的实现需要 16 个乘法器,15 个加法器和 15 组延时寄存器。为了稳定第一拍的数据,可以再多用一组延时寄存器,即共用 16 组延时寄存器。由于 FIR 滤波器系数的对称性,乘法器可以少用一半,即共使用 8 个乘法器。 并行设计,就是在一个时钟周期内对 16 个延时数据同时进行乘法、加法运算,然后在时钟驱动下输出滤波值。这种方法的优点是滤波延时短,但是对时序要求比较高。 并行设计 设计中使用到的乘法器模块代码,可参考流水线式设计的乘法器。 为方便快速仿真,也可以直接使用乘号 * 完成乘法运算,设计中加入宏定义 SAFE_DESIGN 来选择使用哪种乘法器。 FIR 滤波器系数可由 matlab 生成,具体见附录。 /*********************************************************** >> V201001 : Fs:50Mhz, fstop:1Mhz-6Mhz, order: 15 ************************************************************/ `define SAFE_DESIGN module fir_guide ( input rstn, //复位,低有效 input clk, //工作频率,即采样频率 input en, //输入数据有效信号 input [11:0] xin, //输入混合频率的信号数据 output valid, //输出数据有效信号 output [28:0] yout //输出数据,低频信号,即250KHz ); //data en delay reg [3:0] en_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin en_r[3:0] <= 'b0 ; end else begin en_r[3:0] <= {en_r[2:0], en} ; end end //(1) 16 组移位寄存器 reg [11:0] xin_reg[15:0]; reg [3:0] i, j ; always @(posedge clk or negedge rstn) begin if (!rstn) begin for (i=0; i<15; i=i+1) begin xin_reg[i] <= 12'b0; end end else if (en) begin xin_reg[0] <= xin ; for (j=0; j<15; j=j+1) begin xin_reg[j+1] <= xin_reg[j] ; //周期性移位操作 end end end //Only 8 multipliers needed because of the symmetry of FIR filter coefficient //(2) 系数对称,16个移位寄存器数据进行首位相加 reg [12:0] add_reg[7:0]; always @(posedge clk or negedge rstn) begin if (!rstn) begin for (i=0; i<8; i=i+1) begin add_reg[i] <= 13'd0 ; end end else if (en_r[0]) begin for (i=0; i<8; i=i+1) begin add_reg[i] <= xin_reg[i] + xin_reg[15-i] ; end end end //(3) 8个乘法器 // 滤波器系数,已经过一定倍数的放大 wire [11:0] coe[7:0] ; assign coe[0] = 12'd11 ; assign coe[1] = 12'd31 ; assign coe[2] = 12'd63 ; assign coe[3] = 12'd104 ; assign coe[4] = 12'd152 ; assign coe[5] = 12'd198 ; assign coe[6] = 12'd235 ; assign coe[7] = 12'd255 ; reg [24:0] mout[7:0]; `ifdef SAFE_DESIGN //流水线式乘法器 wire [7:0] valid_mult ; genvar k ; generate for (k=0; k<8; k=k+1) begin mult_man #(13, 12) u_mult_paral ( .clk (clk), .rstn (rstn), .data_rdy (en_r[1]), .mult1 (add_reg[k]), .mult2 (coe[k]), .res_rdy (valid_mult[k]), //所有输出使能完全一致 .res (mout[k]) ); end endgenerate wire valid_mult7 = valid_mult[7] ; `else //如果对时序要求不高,可以直接用乘号 always @(posedge clk or negedge rstn) begin if (!rstn) begin for (i=0 ; i<8; i=i+1) begin mout[i] <= 25'b0 ; end end else if (en_r[1]) begin for (i=0 ; i<8; i=i+1) begin mout[i] <= coe[i] * add_reg[i] ; end end end wire valid_mult7 = en_r[2]; `endif //(4) 积分累加,8组25bit数据 -> 1组 29bit 数据 //数据有效延时 reg [3:0] valid_mult_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin valid_mult_r[3:0] <= 'b0 ; end else begin valid_mult_r[3:0] <= {valid_mult_r[2:0], valid_mult7} ; end end `ifdef SAFE_DESIGN //加法运算时,分多个周期进行流水,优化时序 reg [28:0] sum1 ; reg [28:0] sum2 ; reg [28:0] yout_t ; always @(posedge clk or negedge rstn) begin if (!rstn) begin sum1 <= 29'd0 ; sum2 <= 29'd0 ; yout_t <= 29'd0 ; end else if(valid_mult7) begin sum1 <= mout[0] + mout[1] + mout[2] + mout[3] ; sum2 <= mout[4] + mout[5] + mout[6] + mout[7] ; yout_t <= sum1 + sum2 ; end end `else //一步计算累加结果,但是实际中时序非常危险 reg signed [28:0] sum ; reg signed [28:0] yout_t ; always @(posedge clk or negedge rstn) begin if (!rstn) begin sum <= 29'd0 ; yout_t <= 29'd0 ; end else if (valid_mult7) begin sum <= mout[0] + mout[1] + mout[2] + mout[3] + mout[4] + mout[5] + mout[6] + mout[7]; yout_t <= sum ; end end `endif assign yout = yout_t ; assign valid = valid_mult_r[0]; endmoduletestbench testbench 编写如下,主要功能就是不间断连续的输入 250KHz 与 7.5MHz 的正弦波混合信号数据。输入的混合信号数据也可由 matlab 生成,具体见附录。 `timescale 1ps/1ps module test ; //input reg clk ; reg rst_n ; reg en ; reg [11:0] xin ; //output wire valid ; wire [28:0] yout ; parameter SIMU_CYCLE = 64'd2000 ; //50MHz 采样频率 parameter SIN_DATA_NUM = 200 ; //仿真周期 //===================================== // 50MHz clk generating localparam TCLK_HALF = 10_000; initial begin clk = 1'b0 ; forever begin # TCLK_HALF ; clk = ~clk ; end end //============================ // reset and finish initial begin rst_n = 1'b0 ; # 30 rst_n = 1'b1 ; # (TCLK_HALF * 2 * SIMU_CYCLE) ; $finish ; end //======================================= // read signal data into register reg [11:0] stimulus [0: SIN_DATA_NUM-1] ; integer i ; initial begin $readmemh("../tb/cosx0p25m7p5m12bit.txt", stimulus) ; i = 0 ; en = 0 ; xin = 0 ; # 200 ; forever begin @(negedge clk) begin en = 1'b1 ; xin = stimulus[i] ; if (i == SIN_DATA_NUM-1) begin //周期送入数据控制 i = 0 ; end else begin i = i + 1 ; end end end end fir_guide u_fir_paral ( .xin (xin), .clk (clk), .en (en), .rstn (rst_n), .valid (valid), .yout (yout)); endmodule仿真结果 由下图仿真结果可知,经过 FIR 滤波器后的信号只有一种低频率信号(250KHz),高频信号(7.5MHz)被滤除了。而且输出波形是连续的,能够持续输出。 但是,如红圈所示,波形起始部分呈不规则状态,对此进行放大。 图片 波形起始端放大后如下图所示,可见不规则波形的时间段,即两根竖线之间的时间间隔是 16 个时钟周期。 因为数据是串行输入,设计中使用了 16 组延时寄存器,所以滤波后的第一个正常点应该较第一个滤波数据输出时刻延迟 16 个时钟周期。即数据输出有效信号 valid 应该再延迟 16 个时钟周期,则会使输出波形更加完美。 图片 附录:matlab 使用 生成 FIR 滤波器系数 打开 matlab,在命令窗口输入命令: fdatool。 然后会打开如下窗口,按照 FIR 滤波器参数进行设置。 这里选择的 FIR 实现方法是最小二乘法(Least-squares),不同的实现方式滤波效果也不同。 图片 点击 File -> Export 将滤波器参数输出,存到变量 coef 中,如下图所示。 图片 此时 coef 变量应该是浮点型数据。对其进行一定倍数的相乘扩大,然后取其近似的定点型数据作为设计中的 FIR 滤波器参数。这里取扩大倍数为 2048,结果如下所示。 图片 生成输入的混合信号 利用 matlab 生成混合的输入信号参考代码如下。 信号为无符号定点型数据,位宽宽度为 12bit,存于文件 cosx0p25m7p5m12bit.txt。 clear all;close all;clc; %======================================================= % generating a cos wave data with txt hex format %======================================================= fc = 0.25e6 ; % 中心频率 fn = 7.5e6 ; % 杂波频率 Fs = 50e6 ; % 采样频率 T = 1/fc ; % 信号周期 Num = Fs * T ; % 周期内信号采样点数 t = (0:Num-1)/Fs ; % 离散时间 cosx = cos(2*pi*fc*t) ; % 中心频率正弦信号 cosn = cos(2*pi*fn*t) ; % 杂波信号 cosy = mapminmax(cosx + cosn) ; %幅值扩展到(-1,1) 之间 cosy_dig = floor((2^11-1) * cosy + 2^11) ; %幅值扩展到 0~4095 fid = fopen('cosx0p25m7p5m12bit.txt', 'wt') ; %写数据文件 fprintf(fid, '%x\n', cosy_dig) ; fclose(fid) ; %时域波形 figure(1); subplot(121);plot(t,cosx);hold on ; plot(t,cosn) ; subplot(122);plot(t,cosy_dig) ; %频域波形 fft_cosy = fftshift(fft(cosy, Num)) ; f_axis = (-Num/2 : Num/2 - 1) * (Fs/Num) ; figure(5) ; plot(f_axis, abs(fft_cosy)) ;
FPGA&ASIC
刘航宇
4年前
0
587
2
Verilog教程语句块
顺序块,并行块,嵌套块,命名块,disable
FPGA&ASIC
刘航宇
4年前
0
330
1
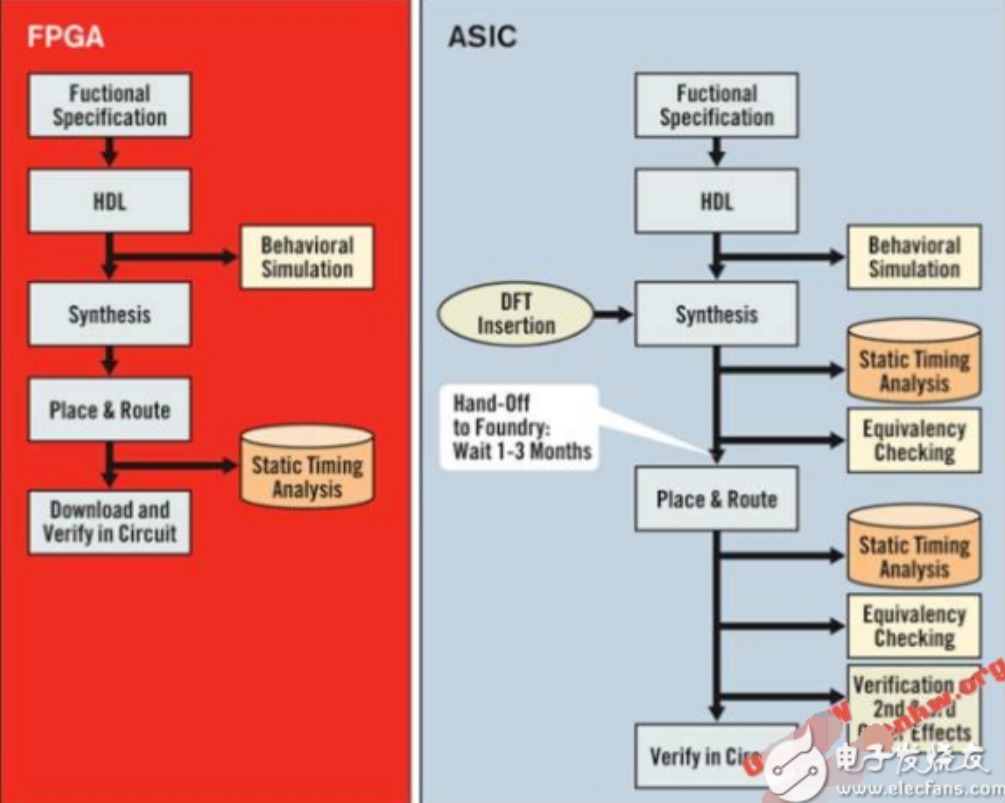
ASIC与FPGA设计哪个前景更好
ASIC和FPGA到底选哪个好?两者的流程有什么区别?做FPGA到底有没有必要转ASIC设计……网上经常看到各种关于ASIC与FPGA的问题。 ASIC (Application Specific Integrated Circuit),即专用集成电路,是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。 FPGA(FieldProgrammable Gate Array),即现场可编程门阵列,它是在PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上进一步发展的产物,FPGA是一种可以重构电路的芯片,是一种硬件可重构的体系结构,通过编程可以随时改变它的应用场景。 图片 FPGA与ASIC的异同 相同点:本质上都是芯片,FPGA开发严格按照ASIC开发流程,都是集成电路方向。一般来说,一些电子类硬件产品能用FPGA做出来就能用ASIC做出来,基本上两种不同的渠道做出来的东西能够实现相同的功能。 不同点:前者是把做好的网表或者电路代码下载到FPGA中,形成门阵列,产品交付的时候或者用的时候发现问题都可以重新打补丁、更新版本后再正常进行。而ASIC最终要去流片,做成一个芯片,要求更高!设计流程上非常漫长,一般是一年左右一个周期,需要用到多个验证师,因为后期一旦发生问题只能重新去生产,出现的bug比较多或者比较严重,还有可能全部回收,甚至存在赔钱风险。 在ASIC的设计过程中,往往要用到FPGA 进行原型验证。完成FPGA 验证可以说就完成了ASIC 整套流程的50~70%。 FPGA和ASIC的设计流程区别 FPGA设计拥有可重新配置芯片的功能,而ASIC设计一般具备较少的可重新配置芯片功能。 图片 FPGA又称为“万能芯片”,其内部包含大量的可配置单元(基于LUT的Slice),可配置IP(DSP、CMT、PCIe、Serdes等),可配置存储器。用户可以将自己的设计下载到FPGA芯片中就可以快速实现自己的功能,可以快速搭建Demo系统,设计周期短。 ASIC芯片首先要经过代码设计、综合、后端等复杂的设计流程,再经过几个月的生产加工以及封装测试,才能拿到芯片来搭建系统,复杂的原因是除了功能要正确之外,各种功耗、面积都要达到一个极致,整个设计周期很长。 不同情况选择哪种设计比较好 考虑到时间问题, ASIC设计流程漫长,大概一年左右一个周期,而FPGA设计一般几个星期或者一两个月就能完成,如果想快速看到成效选择FPGA设计会比较好。 在性能方面,ASIC设计出来的芯片比较好,完整的定制,性能更加稳定。ASIC (Application Specific Integrated Circuit)本身就是一种专用集成电路芯片。用一个比较形象的比喻,电影公司要做尤达大师的模型,方案一:买几箱乐高积木,用搭积木的方式来制作,快速解决问题。方案二:联系模具厂,画图纸开模,大规模生产。FPGA设计出的是积木堆积起来的尤达大师,ASIC设计出的是一次定型的尤达大师,后者更为稳定。 图片 涉及设计成本,ASIC设计完成一般会花费几百万到几个亿不等,但如果产量多,那么单块ASIC芯片成本就会低,特别便宜的芯片还有2块左右的;而FPGA设计完成有时候几百块钱就能搞定,如果产量多那单块成本就摆在这了,最后也是一笔巨资。所以,小批量生产和使用用FPGA设计比较占优势,反之大批量生产和使用ASIC占优势。 其实,国内很多公司刚开始市场发展还不稳定时,都是用的FPGA设计;当有了一定市场和抗风险能力后,才开始用ASIC设计。 FPGA工程师是否有必要转ASIC设计工程师 虽然FPGA工程师目前行情发展也不错,但是很多人在考虑转ASIC设计工程师。 一方面,国内目前FPGA工程师相对来说比较多,很多人在学校时基本上通过几千块买一块FPGA板就可以自己开发,自己就能创造出一个实训环境;而ASIC设计工程师相对来说非常缺乏,因为学校目前无法搭建出一个成熟的实训环境,无法做IC设计,很多人对这方面的知识也比较匮乏。所以,是去做大多数人都会的东西还是做只有少数人会的东西更有前途,答案可想而知。 另一方面,结合目前实际情况来看,还有比较直观的一点就是ASIC设计比FPGA设计工资要高,天花板也要高很多。 原来做FPGA的人一般对于verilog也会比较熟,转ASIC还是非常有优势的,趁着现在年纪不大,处于学习黄金期,基本只要稍微学一下就会了,转起来也是比较快的。
FPGA&ASIC
刘航宇
4年前
0
1,067
1
2022-07-15
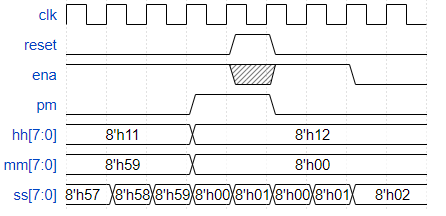
【Verilog】创建12小时时钟的计数器
题目描述 创建一组适合用作12小时时钟的计数器(带有am / pm指示器)。您的计数器由快速运行的时钟提供时钟,每当您的时钟增加(即每秒一次)时,便会在ena上产生一个脉冲。 重置将时钟重置为12:00 AM。 pm对于AM是0,对于PM是1。 hh,mm和ss是两个BCD(二进制-编码的十进制数字分别代表小时(01-12),分钟(00-59)和秒(00-59)。Reset的优先级比enable的优先级高。 以下时序图显示了从11:59:59 AM到12:00:00 PM的过渡行为以及同步复位和启用行为。 图片 请注意,11:59:59 PM前进至12:00:00 AM,12:59:59 PM前进至01:00:00 PM。没有00:00:00。从图中知道,hh、mm、ss都是8位二进制数,且分为前四位和后四位,如果前四位满足了要求,后四位就加一个数;8位都满足了要求,就复位。 解答 module top_module( input clk, input reset, input ena, output pm, output [7:0] hh, output [7:0] mm, output [7:0] ss); wire [3:0] enable; assign enable[0] = ena; assign enable[1] = ena & (ss==8'h59); assign enable[2] = ena & (ss==8'h59) & (mm==8'h59); assign enable[3] = ena & (hh==8'h11) & (ss==8'h59) & (mm==8'h59); count60 second (clk,reset,enable[0],ss); count60 minute (clk,reset,enable[1],mm); count12 hour (clk,reset,enable[2],hh); count2 halfday (clk,reset,enable[3],pm); endmodule module count12( input clk, input reset, input ena, output [7:0] q); always @(posedge clk) begin if (reset) q <= 8'h12; else if (ena) begin if (q == 8'h12) q <= 8'h1; else if (q[3:0] == 4'h9) begin q[3:0] <= 0; q[7:4] <= 1; end else q[3:0] <= q[3:0] + 1; end else q <= q; end endmodule module count60( input clk, input reset, input ena, output [7:0] q); always @(posedge clk) begin if (reset) q <= 0; else if (ena) begin if (q == 8'h59) q <= 0; else if (q[3:0] == 4'h9) begin q[3:0] <= 0; q[7:4] <= q[7:4] + 1; end else q[3:0] <= q[3:0] + 1; end else q <= q; end endmodule module count2( input clk, input reset, input ena, output q); always @(posedge clk) begin if (reset) q <= 0; else if (ena) begin if (q < 1'b1) q <= q + 1; else q <= 0; end else q <= q; end endmodule
FPGA&ASIC
刘航宇
4年前
1
1,217
1
上一页
1
...
4
5
6
7
下一页