首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,201 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,151 阅读
3
【高数】形心计算公式讲解大全
8,759 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,456 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,838 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
📡电子&通信(共112篇)
找到
112
篇与
📡电子&通信
相关的结果
2024-07-05
Linux之不使用命令删除文件中的第N行
1.问题描述 2. 解题思路: 3. 代码实现: 1.问题描述 设计一个程序,通过命令行参数接收一个文件名 filename.txt (纯文本文件)和一个整型数字 n,实现从 filename.txt 中删除第 n 行数据。 2. 解题思路: (1) 借助临时文件: 将文件逐行读取,跳过要删除的行,并将其写入临时文件,然后删除源文件,重命名临时文件为源文件,完成删除指定行数据。 (2) 不借助临时文件: 将文件以读写方式打开,读取到要删除行后,通过移动文件指针将文件后面所有行前移一行,但是最后一行会重复,可以通过截断文件操作完成在源文件上删除指定行数据。 (3) 通过sed 或 awk 删除文件指定行 3. 代码实现: (1) 通过 fopen 打开文件借助临时文件删除指定行数据 #filename:ques_15a.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如exit int main(int argc, char *argv[]) { // 检查命令行参数的数量是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 如果不正确,打印用法信息并退出 } char buf[4096]; // 定义一个足够大的字符数组用于读取文件行 int linenum = atoi(argv[2]); // 将命令行参数中的行号转换为整数 FILE *fp = fopen(argv[1], "r"); // 尝试以只读模式打开源文件 FILE *fpt = fopen("temp.txt", "w"); // 创建一个临时文件用于写入 // 如果源文件无法打开,打印错误信息并退出 if (!fp) { printf("File %s not exist!\n", argv[1]); exit(EXIT_FAILURE); } // 检查是否有权限修改源文件 char str[100]; sprintf(str, "%s%s", "test -w ", argv[1]); if (system(str)) { // 如果没有写权限 printf("Can't modify file %s, permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打印错误信息并退出 } int total_line = 0; // 初始化文件总行数计数器 while (fgets(buf, sizeof(buf), fp)) { // 读取文件的每一行 total_line++; } fseek(fp, 0, SEEK_SET); // 将文件指针重置到文件的开头 // 如果要删除的行数大于文件的总行数,打印错误信息并退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int i = 0; // 初始化当前行计数器 while (fgets(buf, sizeof(buf), fp)) { // 再次读取文件的每一行 i++; // 当前行数加1 if (i != linenum) { // 如果当前行不是要删除的行 fputs(buf, fpt); // 将当前行写入临时文件 } } remove(argv[1]); // 删除原始文件 rename("temp.txt", argv[1]); // 将临时文件重命名为原始文件名 // 关闭文件指针 fclose(fp); fclose(fpt); return 0; // 程序正常退出 }(2) 通过 Linux 系统调用 open 打开文件,需要自定义读取一行的函数,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如atoi和exit #include <string.h> // 包含字符串操作函数,比如strlen #include <fcntl.h> // 包含文件控制的定义 #include <sys/stat.h> // 包含文件状态的定义 #include <sys/types.h>// 包含各种数据类型 #include <unistd.h> // 包含UNIX标准函数定义 // 函数声明:读取一行文件内容到缓冲区 int readline(int fd, char *buf) { int t = 0; // 用于记录读取的字符数 // 循环读取直到遇到换行符 for (; ;) { read(fd, &buf[t], 1); // 从文件描述符fd读取一个字符到buf t++; // 增加读取的字符数 if (buf[t-1] == '\n') { // 如果读取到换行符 break; // 退出循环 } } return t; // 返回读取的字符数 } // 函数声明:获取文件的大小和行数 int get_file_info(int fd, int *size) { int num = 0; // 记录行数 char ch; // 临时变量用于存储读取的字符 // 循环读取直到文件结束 while (read(fd, &ch, 1) > 0) { (*size)++; // 文件大小加1 if (ch == '\n') { // 如果读取到换行符 num++; // 行数加1 } } return num; // 返回行数 } int main(int argc, char *argv[]) { // 检查命令行参数数量 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出 } int fd; // 文件描述符 char buf[4096]; // 缓冲区 int linenum = atoi(argv[2]); // 将命令行参数转换为整数 // 尝试以读写模式打开文件 fd = open(argv[1], O_RDWR); if (fd < 0) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打开失败时退出 } int size = 0; // 文件大小 // 获取文件的行数和大小 int total_line = get_file_info(fd, &size); // 如果要删除的行数大于文件总行数,退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 要删除行的大小 int t = 0; // 当前行的大小 int i = 0; // 当前行数 lseek(fd, 0, SEEK_SET); // 将文件指针移到文件头 // 循环读取文件,直到文件结束 while (read(fd, &buf[0], 1) > 0) { lseek(fd, -1, SEEK_CUR); // 回退一个字符 memset(buf, 0, sizeof(buf)); // 清空缓冲区 readline(fd, buf); // 读取一行到缓冲区 i++; // 行数加1 t = strlen(buf); // 当前行的大小 // 如果当前行是目标行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在目标行之后,将该行前移 if (i > linenum) { lseek(fd, -(s+t), SEEK_CUR); // 移动文件指针 write(fd, buf, strlen(buf)); // 写入当前行 lseek(fd, s, SEEK_CUR); // 移动文件指针 } } ftruncate(fd, size-s); // 截断文件,删除指定行 close(fd); // 关闭文件描述符 return 0; // 正常退出 }(3) 通过 fopen 打开文件,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,如atoi和exit #include <string.h> // 包含字符串处理函数,如strlen #include <math.h> // 包含数学函数,虽然在这个程序中没有使用 #include <unistd.h> // 包含UNIX标准函数,如truncate int main(int argc, char *argv[]) { // 检查命令行参数个数是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出程序 } int linenum = atoi(argv[2]); // 将命令行中指定的行号转换为整数 char buf[4096]; // 定义缓冲区,用于读取文件内容 // 尝试以读写模式打开文件 FILE *fp = fopen(argv[1], "r+"); // 如果文件无法打开,打印错误信息并退出程序 if (!fp) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); } int total_line = 0; // 记录文件的总行数 int size = 0; // 记录文件的总大小 // 循环读取文件直到文件末尾,计算总行数和总大小 while (fgets(buf, sizeof(buf), fp)) { size += strlen(buf); // 累加每行的长度 total_line++; // 行数加1 } // 如果要删除的行数大于文件的总行数,打印错误信息并退出程序 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 记录要删除的行的大小 int t = 0; // 记录当前读取行的大小 int i = 0; // 记录当前行数 fseek(fp, 0L, SEEK_SET); // 将文件指针重置到文件开头 // 再次循环读取文件,准备删除指定行 while (fgets(buf, sizeof(buf), fp)) { i++; // 当前行数加1 t = strlen(buf); // 当前行的长度 // 如果当前行是要删除的行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在要删除的行之后,将其前移 if (i > linenum) { fseek(fp, -(s+t), SEEK_CUR); // 将文件指针移动到正确的位置 fputs(buf, fp); // 写入当前行 fseek(fp, s, SEEK_CUR); // 将文件指针向前移动s个字节 } } // 截断文件,删除指定行 truncate(argv[1], size-s); // 关闭文件指针 fclose(fp); return 0; // 正常退出程序 }(4) 这三个删除文件指定行的函数都需借助临时文件完成
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
362
1
2024-06-27
基础概念:中断、任务、进程、线程、RTOS、Linux
中断 任务 进程 线程 它们之间的区别 RTOS和Linux的区别 中断、任务、进程和线程是计算机科学和操作系统中的基本概念,它们在多任务操作和资源管理中扮演着重要的角色。下面是这些概念的简要解释以及它们之间的区别: 中断 中断是硬件或软件发出的信号,用来通知CPU暂停当前的工作,转而去执行一个特殊的程序(中断处理程序)。中断可以是外部的,比如来自硬件设备的信号,或者是内部的,比如软件生成的信号。中断机制允许操作系统响应外部事件,如用户输入或硬件状态变化。 任务 在某些操作系统中,任务是一个抽象概念,用来表示一个执行单元,它可以是一个进程或者线程。任务通常指的是需要操作系统调度和资源管理的执行流。 进程 进程是操作系统分配资源和调度的基本单位。每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程状态和执行的资源。进程可以包含一个或多个线程。 线程 线程是进程中的一个实体,是CPU调度和执行的单位。线程共享所属进程的资源,但拥有自己的堆栈和程序计数器。线程比进程更轻量级,创建和切换的开销更小。 它们之间的区别 资源分配:进程是资源分配的最小单位,线程则不是。 执行:进程是执行程序的实例,线程是进程中的实际执行流。 地址空间:进程有独立的地址空间,线程共享进程的地址空间。 创建开销:进程的创建开销通常大于线程。 通信:线程间可以通过共享内存进行通信,进程间通信需要使用IPC(进程间通信)机制。 RTOS和Linux的区别 RTOS(实时操作系统)和Linux是两种不同类型的操作系统,它们在设计目标和特性上有所区别: 设计目标: RTOS:设计用于需要快速、可预测响应的系统,如嵌入式系统、工业控制等。 Linux:是一个通用操作系统,主要用于桌面、服务器、移动设备等。 实时性: RTOS:提供确定的响应时间,可以保证任务在指定的时间内得到处理。 Linux:虽然可以配置为实时系统,但通常不具备RTOS的严格实时性。 调度策略: RTOS:通常使用基于优先级的抢占式调度。 Linux:使用完全公平调度器(CFS)进行调度,可以配置为实时调度。 内存管理: RTOS:通常有简单的内存管理机制,适合资源受限的环境。 Linux:具有复杂的内存管理机制,支持虚拟内存和内存共享。 应用场景: RTOS:适用于对实时性要求高、资源受限的场合。 Linux:适用于需要高度灵活性和扩展性的场合。 开源和社区支持: RTOS:有些RTOS是开源的,但社区规模通常小于Linux。 Linux:是一个开源项目,拥有庞大的社区和开发者支持。 总的来说,RTOS和Linux各有优势,选择哪个系统取决于应用的具体需求。RTOS适合对实时性要求极高的场景,而Linux适合需要高度灵活性和功能丰富的环境。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
776
1
2024-03-12
C语言编译的四个步骤
编译一个C语言程序是一个多阶段的过程。从总体上看,这个过程可以分成四个独立的阶段。预处理、编译、汇编和连接。 在这篇文章中,我将逐一介绍编译下列C程序的四个阶段。 /* * "Hello, World!": A classic. */ #include <stdio.h> int main(void) { puts("Hello, World!"); return 0; }预处理 编译的第一个阶段称为预处理。在这个阶段,以#字符开头的行被预处理器解释为预处理器命令。这些命令形成一种简单的宏语言,有自己的语法和语义。这种语言通过提供内联文件、定义宏和有条件地省略代码的功能,来减少源代码的重复性。 在解释命令之前,预处理器会做一些初始处理。这包括连接续行(以 \ 结尾的行)和剥离注释。 要打印预处理阶段的结果,请向gcc传递-E选项。 gcc -E hello_world.c 考虑到上面的 "Hello, World!"的例子,预处理器将产生stdio.h头文件的内容和hello_world.c文件的内容,并将其前面的注释剥离出来。 编译 编译的第二个阶段被称为编译,令人困惑。在这个阶段,预处理过的代码被翻译成目标处理器架构特有的汇编指令。这些形成了一种中间的人类可读语言。 这一步骤的存在允许C代码包含内联汇编指令,并允许使用不同的汇编器。 一些编译器也支持使用集成汇编器,在这种情况下,编译阶段直接生成机器代码,避免了生成中间汇编指令和调用汇编器的开销。 要保存编译阶段的结果,可以向gcc传递-S选项。 gcc -S hello_world.c 这将创建一个名为hello_world.s的文件,包含生成的汇编指令。 汇编 在这个阶段,汇编器被用来将汇编指令翻译成目标代码。输出包括目标处理器要运行的实际指令。 要保存汇编阶段的结果,请向gcc传递-c选项。 gcc -c hello_world.c 运行上述命令将创建一个名为hello_world.o的文件,包含程序的目标代码。这个文件的内容是二进制格式,可以用运行命令hexdump或od来检查。 hexdump hello_world.o od -c hello_world.oLinux中的od(octal dump)命令用于转换输入内容为八进制。 Hexdump是一个命令行工具,用于以各种方式显示文件的原始内容,包括十六进制,可用于Linux、FreeBDS、OS X和其他平台。Hexdump不是传统Unix系统或GNU命令的一部分。 链接 汇编阶段产生的目标代码是由处理器能够理解的机器指令组成的,但程序的某些部分是不符合顺序的或缺失的。为了产生一个可执行的程序,现有的部分必须被重新排列,并把缺失的部分补上。这个过程被称为链接。 链接器将安排目标代码的各个部分,使某些部分的功能能够成功地调用其他部分的功能。它还将添加包含程序所使用的库函数指令的片段。在 "Hello,world!"程序的例子中,链接器将添加puts函数的对象代码。 这一阶段的结果是最终的可执行程序。当不使用选项运行时,gcc 将把这个文件命名为 a.out。如果要给文件命名,请向 gcc 传递 -o 选项。 gcc -o hello_world hello_world.c
编程&脚本笔记
# C/C++
刘航宇
2年前
0
549
0
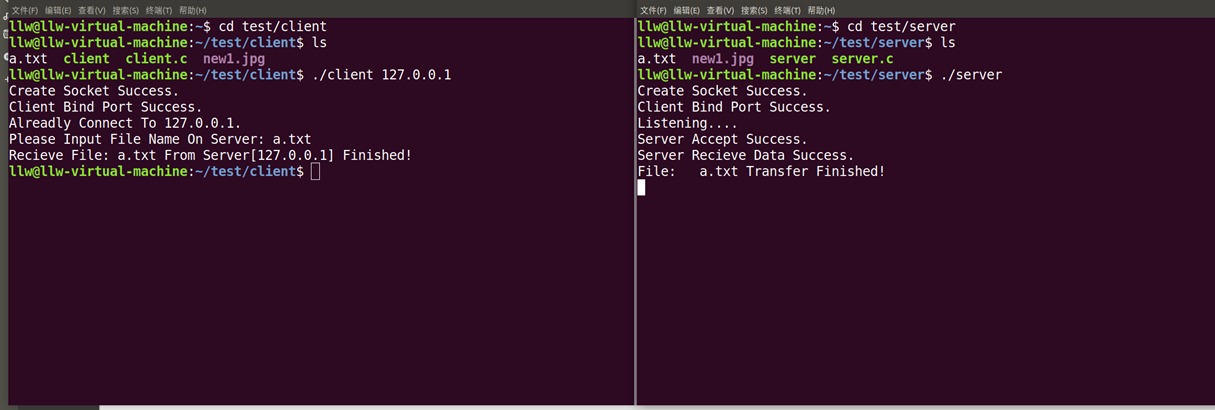
Socket通信-Linux系统中C语言实现TCP/UDP图片和文件传输
TCP实现1.服务端 2.客户端 二、UDP实现1.服务端 2.客户端 TCP实现 传输控制协议(TCP,Transmission Control Protocol) 是为了在不可靠的互联网络上提供可靠的端到端字节流而专门设计的一个传输协议。TCP是因特网中的传输层协议,使用三次握手协议建立连接。当主动方发出SYN连接请求后,等待对方回答SYN+ACK,并最终对对方的 SYN 执行 ACK 确认。这种建立连接的方法可以防止产生错误的连接,TCP使用的流量控制协议是可变大小的滑动窗口协议。 1.服务端 基于TCP协议的socket的server端程序编程步骤: 1、建立socket ,使用socket() 2、绑定socket ,使用bind() 3、打开listening socket,使用listen() 4、等待client连接请求,使用accept() 5、收到连接请求,确定连接成功后,使用输入,输出函数recv(),send()与client端互传信息 6、关闭socket,使用close() 服务端代码server.c /*server.c*/ #include<netinet/in.h> #include<sys/types.h> #include<sys/socket.h> #include<stdio.h> #include<stdlib.h> #include<string.h> #define SERVER_PORT 5678 //端口号 #define LENGTH_OF_LISTEN_QUEUE 20 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { // 设置一个socket地址结构server_addr,代表服务器ip地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htons(INADDR_ANY); server_addr.sin_port = htons(SERVER_PORT); // 创建用于流协议(TCP)socket,用server_socket代表服务器向客户端提供服务的接口 int server_socket = socket(PF_INET, SOCK_STREAM, 0); if (server_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把socket和socket地址结构绑定 if (bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr))) { printf("Server Bind Port: %d Failed!\n", SERVER_PORT); exit(1); } else printf("Client Bind Port Success.\n"); // server_socket用于监听 if (listen(server_socket, LENGTH_OF_LISTEN_QUEUE)) { printf("Server Listen Failed!\n"); exit(1); } else printf("Listening....\n"); // 服务器始终监听 while(1) { // 定义客户端的socket地址结构client_addr,当收到来自客户端的请求后,调用accept // 接受此请求,同时将client端的地址和端口等信息写入client_addr中 struct sockaddr_in client_addr; socklen_t length = sizeof(client_addr); // 接受一个从client端到达server端的连接请求,将客户端的信息保存在client_addr中 // 如果没有连接请求,则一直等待直到有连接请求为止,这是accept函数的特性 // accpet返回一个新的socket,这个socket用来与此次连接到server的client进行通信 // 这里的new_server_socket代表了这个通信通道 int new_server_socket = accept(server_socket, (struct sockaddr*)&client_addr, &length); if (new_server_socket < 0) { printf("Server Accept Failed!\n"); break; } else printf("Server Accept Success.\n"); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); length = recv(new_server_socket, buffer, BUFFER_SIZE, 0); if (length < 0) { printf("Server Recieve Data Failed!\n"); break; } else printf("Server Recieve Data Success.\n"); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); strncpy(file_name, buffer, strlen(buffer) > FILE_NAME_MAX_SIZE ? FILE_NAME_MAX_SIZE : strlen(buffer)); FILE *fp = fopen(file_name, "r"); //获取文件操作符 if (fp == NULL) { printf("File:\t%s Not Found!\n", file_name); } else { bzero(buffer, BUFFER_SIZE); int file_block_length = 0; while( (file_block_length = fread(buffer, sizeof(char), BUFFER_SIZE, fp)) > 0) { // 发送buffer中的字符串到new_server_socket,实际上就是发送给客户端 if (send(new_server_socket, buffer, file_block_length, 0) < 0) { printf("Send File:\t%s Failed!\n", file_name); break; } bzero(buffer, sizeof(buffer)); } fclose(fp); printf("File:\t%s Transfer Finished!\n", file_name); } close(new_server_socket); } close(server_socket); return 0; } 2.客户端 基于TCP协议的socket的Client程序编程步骤: 1、建立socket,使用socket() 2、通知server请求连接,使用connect() 3、若连接成功,就使用输入输出函数recv(),send()与server互传信息 4、关闭socket,使用close() 客户端代码client.c /*client.c*/ #include<netinet/in.h> // for sockaddr_in #include<sys/types.h> // for socket #include<sys/socket.h> // for socket #include<stdio.h> // for printf #include<stdlib.h> // for exit #include<string.h> // for bzero #define SERVER_PORT 5678 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { if (argc != 2) //判断有没有输入服务器ip { printf("Usage: ./%s ServerIPAddress\n", argv[0]); exit(1); } // 设置一个socket地址结构client_addr, 代表客户机的ip地址和端口 struct sockaddr_in client_addr; bzero(&client_addr, sizeof(client_addr)); client_addr.sin_family = AF_INET; // internet协议族IPv4 client_addr.sin_addr.s_addr = htons(INADDR_ANY); // INADDR_ANY表示自动获取本机地址 client_addr.sin_port = htons(0); // auto allocated, 让系统自动分配一个空闲端口 // 创建用于internet的流协议(TCP)类型socket,用client_socket代表客户端socket int client_socket = socket(AF_INET, SOCK_STREAM, 0); if (client_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把客户端的socket和客户端的socket地址结构绑定 if (bind(client_socket, (struct sockaddr*)&client_addr, sizeof(client_addr))) { printf("Client Bind Port Failed!\n"); exit(1); } else printf("Client Bind Port Success.\n"); // 设置一个socket地址结构server_addr,代表服务器的internet地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; // 服务器的IP地址来自程序的参数 if (inet_aton(argv[1], &server_addr.sin_addr) == 0) { printf("Server IP Address Error!\n"); exit(1); } server_addr.sin_port = htons(SERVER_PORT); int server_addr_length = sizeof(server_addr); // 向服务器发起连接请求,连接成功后client_socket代表客户端和服务器端的一个socket连接 if (connect(client_socket, (struct sockaddr*)&server_addr, server_addr_length) < 0) { printf("Can Not Connect To %s!\n", argv[1]); exit(1); } else printf("Alreadly Connect To %s.\n", argv[1]); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); printf("Please Input File Name On Server: "); scanf("%s", file_name); char buffer[BUFFER_SIZE];//缓存区 bzero(buffer, sizeof(buffer)); strncpy(buffer, file_name, strlen(file_name) > BUFFER_SIZE ? BUFFER_SIZE : strlen(file_name)); // 向服务器发送buffer中的数据,此时buffer中存放的是客户端需要接收的文件的名字 send(client_socket, buffer, BUFFER_SIZE, 0); // send , sendto(), recv(),recvfrom() FILE *fp = fopen(file_name, "w"); if (fp == NULL) { printf("File: %s Can Not Open To Write!\n", file_name); exit(1); } // 从服务器端接收数据到buffer中 bzero(buffer, sizeof(buffer)); int length = 0; while(length = recv(client_socket, buffer, BUFFER_SIZE, 0)) { if (length < 0) { printf("Recieve Data From Server %s Failed!\n", argv[1]); break; } int write_length = fwrite(buffer, sizeof(char), length, fp); if (write_length < length) { printf("File:\t%s Write Failed!\n", file_name); break; } bzero(buffer, BUFFER_SIZE); } printf("Recieve File: %s From Server[%s] Finished!\n", file_name, argv[1]); // 传输完毕,关闭socket fclose(fp); close(client_socket); return 0; } 如图,客户端(左)从服务端(右)下载文件/图片: 图片 二、UDP实现 UDP(User Datagram Protocol) 全称是用户数据报协议,是一种非面向连接的协议,这种协议并不能保证我们的网络程序的连接是可靠的。 1.服务端 基于UDP协议的socket的server编程步骤: 1、建立socket,使用socket() 2、绑定socket,使用bind() 3、以recvfrom()函数接收发送端传来的数据(使用recvfrom函数 时需设置非阻塞,以免程序卡在此处) 4、关闭socket,使用close() /*server.c*/ #include<netinet/in.h> #include<sys/types.h> #include<sys/socket.h> #include<stdio.h> #include<stdlib.h> #include<string.h> #define SERVER_PORT 5678 //端口号 #define LENGTH_OF_LISTEN_QUEUE 20 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { // 设置一个socket地址结构server_addr,代表服务器internet的地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htons(INADDR_ANY); server_addr.sin_port = htons(SERVER_PORT); // create a stream socket // 创建用于internet的流协议(UDP)socket,用server_socket代表服务器向客户端提供服务的接口 int server_socket = socket(PF_INET, SOCK_DGRAM, 0); if (server_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把socket和socket地址结构绑定 if (bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr))) { printf("Server Bind Port: %d Failed!\n", SERVER_PORT); exit(1); } else printf("Server Bind Port Success.\n"); printf("Waiting......\n"); // 服务器端一直运行用以持续为客户端提供服务 while(1) { // 接受此请求,同时将client端的地址和端口等信息写入client_addr中 struct sockaddr_in client_addr; int length = 0; int addrlen = sizeof(client_addr); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); length = recvfrom(server_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&client_addr,&addrlen); if (length < 0) { printf("Server Recieve Data Failed!\n"); break; } char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); strncpy(file_name, buffer, strlen(buffer) > FILE_NAME_MAX_SIZE ? FILE_NAME_MAX_SIZE : strlen(buffer)); FILE *fp = fopen(file_name, "r"); if (fp == NULL) { printf("File:\t%s Not Found!\n", file_name); } else { bzero(buffer, BUFFER_SIZE); int file_block_length = 0; while( (file_block_length = fread(buffer, sizeof(char), BUFFER_SIZE, fp)) > 0) { // 发送buffer中的字符串到server_socket,实际上就是发送给客户端 if (sendto(server_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&client_addr,addrlen) < 0) { printf("Send File:\t%s Failed!\n", file_name); break; } bzero(buffer, sizeof(buffer)); } fclose(fp); printf("File:\t%s Transfer Finished!\n", file_name); } } close(server_socket); return 0; }2.客户端 基于UDP协议的socket的client端编程步骤: 1、建立Socket,使socket() 2、用sendto()函数向接收端发送数据。 3、关闭socket,使用close()函数 /*client.c*/ #include<netinet/in.h> // for sockaddr_in #include<sys/types.h> // for socket #include<sys/socket.h> // for socket #include<stdio.h> // for printf #include<stdlib.h> // for exit #include<string.h> // for bzero #include <fcntl.h> #include <unistd.h> #include <sys/time.h> #define SERVER_PORT 5678 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { if (argc != 2) { printf("Usage: ./%s ServerIPAddress\n", argv[0]); exit(1); } // 设置一个socket地址结构client_addr, 代表客户机的internet地址和端口 struct sockaddr_in client_addr; bzero(&client_addr, sizeof(client_addr)); client_addr.sin_family = AF_INET; // internet协议族 client_addr.sin_addr.s_addr = htons(INADDR_ANY); // INADDR_ANY表示自动获取本机地址 client_addr.sin_port = htons(0); // auto allocated, 让系统自动分配一个空闲端口 // 创建用于internet的流协议(TCP)类型socket,用client_socket代表客户端socket int client_socket = socket(AF_INET, SOCK_DGRAM, 0); if (client_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } // 设置超时,防止recvfrom()函数阻塞 struct timeval timeout; timeout.tv_sec = 1;//秒 timeout.tv_usec = 0;//微秒 if (setsockopt(client_socket, SOL_SOCKET, SO_RCVTIMEO, &timeout, sizeof(timeout)) == -1) { perror("setsockopt failed:"); } // 把客户端的socket和客户端的socket地址结构绑定 if (bind(client_socket, (struct sockaddr*)&client_addr, sizeof(client_addr))) { printf("Client Bind Port Failed!\n"); exit(1); } // 设置一个socket地址结构server_addr,代表服务器的internet地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; // 服务器的IP地址来自程序的参数 if (inet_aton(argv[1], &server_addr.sin_addr) == 0) { printf("Server IP Address Error!\n"); exit(1); } server_addr.sin_port = htons(SERVER_PORT); int server_addr_length = sizeof(server_addr); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); printf("Please Input File Name On Server: "); scanf("%s", file_name); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); strncpy(buffer, file_name, strlen(file_name) > BUFFER_SIZE ? BUFFER_SIZE : strlen(file_name)); // 向服务器发送buffer中的数据,此时buffer中存放的是客户端需要接收的文件的名字 if( sendto(client_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&server_addr,server_addr_length) ) printf("Waiting receive %s from server....\n",file_name); FILE *fp = fopen(file_name, "w"); if (fp == NULL) { printf("File:\t%s Can Not Open To Write!\n", file_name); exit(1); } // 从服务器端接收数据到buffer中 bzero(buffer, sizeof(buffer)); int length = 0; //length = recvfrom(client_socket, buffer, BUFFER_SIZE, 0, (struct sockaddr*)&server_addr, &server_addr_length)//非阻塞 while( length = recvfrom(client_socket, buffer, BUFFER_SIZE, 0, (struct sockaddr*)&server_addr, &server_addr_length)) { if (length < 0) { //printf("Recieve Data From Server %s Failed!\n", argv[1]); break; } int write_length = fwrite(buffer, sizeof(char), length, fp); if (write_length < length) { printf("File: %s Write Failed!\n", file_name); break; } bzero(buffer, BUFFER_SIZE); } printf("Receive File: %s From Server[%s] Finished!\n", file_name, argv[1]); // 传输完毕,关闭socket fclose(fp); close(client_socket); return 0; } 如图,客户端(左)从服务端(右)下载文件/图片: 图片 注:使用recvfrom函数 时需设置非阻塞,以免程序卡住。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
623
0
2024-01-11
嵌入式常见知识点
图片 1、线程、进程的区别?最小执行单元是进程还是线程? 2、如何计算一个整数是不是2的n次方? 3、printf的具体实现? 4、什么是大小端?如何区分?有几种方法? 5、new与malloc的区别? 6、程序链接完毕之后分几部分? 7、Linux、Windows与FreeRtos的区别? 8、Linux系统中的中断为什么分为上下两个部分? 9、会快速排序吗?简要说一下? 10、static关键字的作用? 11、extern 关键字的作用? 12、volatile关键字的作用? 13、编译原理分哪几步? 14、内存分区? 15、freertos启动流程? 16、互斥锁与信号量的区别? 17、什么是死锁?死锁产生的原因?如何避免? 18、什么是内存泄漏? 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 21、freertos中EventBits_t是干啥的? 22、freertos使任务切换的方式有哪些? 23、项目中用到网络了吗? 24、了解Socket吗? 25、c++中set是什么? 26、有没有用到C++模板? 27、有没有对代码裁剪的经验 28、freertos系统是买模块时人家配置好的?还是移植的? 29、任务里有两把锁的时候该怎么处理 30、熟悉Shell脚本吗?$和#啥意思? 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。31、知道#error吗? 32、freertos消息队列的的具体实现? 33、堆栈区别? 34、程序存放状态和区别 1、线程、进程的区别?最小执行单元是进程还是线程? 线程和进程都是程序的执行实体,但是它们有以下区别: 进程是操作系统分配资源的基本单位,每个进程都有自己的独立的地址空间,代码段,数据段,堆栈段等。进程之间的切换需要保存和恢复上下文,开销较大。 线程是操作系统调度的基本单位,每个线程都属于某个进程,一个进程可以有多个线程,它们共享进程的地址空间,但是有自己的栈和寄存器。线程之间的切换只需要保存和恢复少量的寄存器,开销较小。 最小的执行单元是线程,因为一个进程至少要有一个线程,而一个线程可以独立运行。 2、如何计算一个整数是不是2的n次方? 一个整数是2的n次方,当且仅当它的二进制表示中只有一个1,其余都是0。例如,23=8=(1000)2 ,只有一个1。所以,我们可以用以下的方法来判断一个整数x是否是2的n次方: 如果x小于等于0,那么它不是2的n次方。 如果x大于0,那么我们可以用位运算的技巧,将x与x-1做按位与,如果结果为0,那么x是2的n次方,否则不是。例如,8&(8−1)=8&7=(1000)2&(0111)2=(0000)2=0 ,所以8是2的n次方。而9&(9−1)=9&8=(1001)2&(1000)2=(1000)2=0 ,所以9不是2的n次方。 3、printf的具体实现? printf是C语言中的一个标准库函数,用于向标准输出流(通常是屏幕)打印格式化的字符串。它的具体实现可能因编译器和操作系统的不同而有所差异,但是一般来说,它的主要步骤如下: 首先,printf会解析第一个参数,也就是格式化字符串,根据其中的转换说明符(如%d, %f, %s等),确定需要打印的数据类型和格式。 然后,printf会从第二个参数开始,依次获取对应的数据,并将其转换为字符串,拼接到格式化字符串的相应位置。如果参数的个数和类型与格式化字符串不匹配,可能会导致错误或未定义的行为。 最后,printf会调用底层的系统函数,将拼接好的字符串写入到标准输出流中,并返回成功写入的字符数。如果发生错误,返回负值。 4、什么是大小端?如何区分?有几种方法? 大小端是指数据在内存中的存储顺序,大端表示高位字节存放在低地址,低位字节存放在高地址,小端表示高位字节存放在高地址,低位字节存放在低地址。例如,一个32位的整数0x12345678,在大端模式下,存储为0x12 0x34 0x56 0x78,而在小端模式下,存储为0x78 0x56 0x34 0x12。 区分大小端的方法有以下几种: 通过联合体(union)的方式,将一个整数和一个字符数组放在同一个联合体中,然后判断字符数组的第一个元素是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过指针的方式,将一个整数的地址赋给一个字符指针,然后判断指针指向的内容是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过位运算的方式,将一个整数右移24位,然后与0xFF做按位与,得到的结果是不是整数的最高字节,如果是,说明是大端,否则是小端。 5、new与malloc的区别? new和malloc都是用于动态分配内存的,但是它们有以下区别: new是C++中的运算符,malloc是C语言中的函数,它们的用法不同。new可以直接分配对象,而malloc只能分配字节,需要强制类型转换。 new会调用对象的构造函数,初始化对象,而malloc只是分配原始的内存空间,不做任何初始化。 new会根据对象的类型,自动计算所需的内存大小,而malloc需要手动指定分配的字节数。 new分配失败时,会抛出异常,而malloc分配失败时,会返回NULL指针。 new对应的释放内存的运算符是delete,而malloc对应的释放内存的函数是free。 6、程序链接完毕之后分几部分? 程序链接完毕之后,一般分为以下几个部分: 代码段(text segment),存放程序的指令和常量。 数据段(data segment),存放程序的全局变量和静态变量。 堆(heap),存放程序动态分配的内存空间。 栈(stack),存放程序的局部变量,函数参数,返回地址等。 BSS段(bss segment),存放程序未初始化的全局变量和静态变量。 7、Linux、Windows与FreeRtos的区别? Linux、Windows和FreeRtos都是操作系统,但是它们有以下区别: Linux是一个开源的,基于Unix的,多用户,多任务,支持多种硬件平台的操作系统,它有很多不同的发行版,如Ubuntu,RedHat,Debian等。Linux适合用于服务器,嵌入式系统,桌面系统等。 Windows是一个闭源的,基于NT内核的,多用户,多任务,主要支持x86和x64架构的操作系统,它有很多不同的版本,如Windows 10,Windows Server,Windows CE等。Windows适合用于桌面系统,移动设备,游戏机等。 FreeRtos是一个开源的,基于微内核的,实时,多任务,支持多种嵌入式平台的操作系统,它有很多不同的移植,如ARM,MIPS,AVR等。FreeRtos适合用于实时控制,物联网,低功耗设备等。 8、Linux系统中的中断为什么分为上下两个部分? Linux系统中的中断为了提高效率和响应时间,分为上半部(top half)和下半部(bottom half)。上半部是指中断处理程序(interrupt handler),它负责处理中断的紧急事务,如保存寄存器,清除中断标志,识别中断源等。下半部是指中断延迟服务程序(interrupt deferred service routine),它负责处理中断的非紧急事务,如数据传输,设备驱动,信号发送等。上半部和下半部的区别如下: 上半部在中断上下文中执行,下半部在进程上下文中执行。 上半部不能被其他中断打断,下半部可以被其他中断打断。 上半部不能睡眠,下半部可以睡眠。 上半部不能调用可能导致阻塞的函数,如malloc,copy_to_user等,下半部可以调用这些函数。 上半部的执行时间应该尽可能短,下半部的执行时间可以较长。 9、会快速排序吗?简要说一下? 快速排序是一种基于分治思想的排序算法,它的基本步骤如下: 从待排序的数组中选择一个元素作为基准(pivot),通常选择第一个或者最后一个元素。 将数组分成两个子数组,一个子数组中的元素都小于或等于基准,另一个子数组中的元素都大于基准,这个过程称为划分(partition)。 对两个子数组递归地进行快速排序,直到子数组的长度为1或0。 将排好序的子数组合并,得到最终的排序结果。 快速排序的平均时间复杂度是O(nlogn) ,最坏情况是O(n^2) ,空间复杂度是O(logn) ,它是一种不稳定的排序算法。 10、static关键字的作用? static是一个修饰符,它可以用于变量和函数,它有以下作用: 用于全局变量,表示该变量只能在本文件中访问,不能被其他文件引用,这样可以避免命名冲突。 用于局部变量,表示该变量的生命周期是整个程序,而不是函数调用结束,这样可以保持变量的值不被销毁。 用于函数,表示该函数只能在本文件中调用,不能被其他文件引用,这样可以提高函数的封装性和安全性。 11、extern 关键字的作用? extern是一个修饰符,它可以用于变量和函数,它有以下作用: 用于变量,表示该变量是在其他文件中定义的,需要在本文件中引用,这样可以避免重复定义。 用于函数,表示该函数是在其他文件中定义的,需要在本文件中声明,这样可以避免隐式声明。 12、volatile关键字的作用? volatile是一个修饰符,它可以用于变量,它有以下作用: 用于变量,表示该变量可能会被外部因素(如中断,多线程,硬件等)改变,需要每次都从内存中读取,而不是从寄存器或缓存中读取,这样可以保证变量的实时性和一致性。 用于变量,表示该变量不会被编译器优化,需要按照程序的顺序执行,而不是进行重排或删除,这样可以避免编译器的干扰。 13、编译原理分哪几步? 编译原理是指将一种高级语言(源语言)的程序转换为另一种低级语言(目标语言)的程序的原理和方法,它一般分为以下几个步骤: 词法分析(lexical analysis),将源程序的字符序列分割成有意义的单词(token)。 语法分析(syntax analysis),将单词序列组织成语法树(parse tree)或抽象语法树(abstract syntax tree),表示程序的结构和语义。 语义分析(semantic analysis),检查程序是否符合语言的语法规则和语义规则,如类型检查,作用域分析等。 中间代码生成(intermediate code generation),将抽象语法树转换为一种中间表示(intermediate representation),如三地址码,四元式,后缀表达式等,便于优化和目标代码生成。 代码优化(code optimization),对中间表示进行一些变换,以提高程序的执行效率,如常量折叠,公共子表达式消除,循环优化,死代码删除等。 目标代码生成(target code generation),将中间表示转换为目标语言的代码,如汇编语言,机器语言等,同时进行一些分配,如寄存器分配,指令选择等。 14、内存分区? 内存分区是指将物理内存划分为若干个逻辑区域,以便于管理和使用。内存分区的方式有以下几种: 固定分区,将内存分为大小相等或不等的若干个区域,每个区域只能装入一个进程,如果进程的大小超过区域的大小,就会产生内部碎片。 动态分区,根据进程的大小和数量,动态地分配和回收内存空间,每个区域可以装入一个或多个进程,如果进程的大小不是区域的整数倍,就会产生外部碎片。 页式分区,将进程的地址空间划分为大小相等的若干个页,将物理内存划分为大小相等的若干个页框,然后将页映射到页框,实现非连续的内存分配,避免了外部碎片,但是可能产生内部碎片。 段式分区,将进程的地址空间划分为大小不等的若干个段,每个段有自己的逻辑地址和属性,然后将段映射到物理内存,实现非连续的内存分配,避免了内部碎片,但是可能产生外部碎片。 段页式分区,将进程的地址空间划分为若干个段,每个段再划分为若干个页,然后将页映射到物理内存的页框,实现非连续的内存分配,避免了内部碎片和外部碎片,但是增加了地址转换的复杂度。 15、freertos启动流程? freertos是一个实时操作系统,它的启动流程一般如下: 首先,执行硬件初始化,如设置时钟,中断,堆栈等。 然后,执行软件初始化,如创建任务,队列,信号量,定时器等。 接着,调用vTaskStartScheduler ()函数,启动调度器,选择优先级最高的就绪任务运行。 最后,当发生中断,延时,阻塞等事件时,调度器会根据算法,如优先级抢占式,时间片轮转式等,切换任务,实现多任务的并发执行。 16、互斥锁与信号量的区别? 互斥锁(mutex)和信号量(semaphore)都是用于实现多任务的同步和互斥的机制,但是它们有以下区别: 互斥锁是一个二元的同步对象,它只有两种状态:锁定和解锁。一个互斥锁只能被一个任务拥有,当一个任务获取互斥锁后,其他任务就不能再获取该互斥锁,直到拥有者释放它。互斥锁通常用于保护临界区的访问,避免数据的不一致。 信号量是一个计数的同步对象,它有一个初始值,表示可用的资源数量。一个信号量可以被多个任务共享,当一个任务获取信号量后,信号量的值减一,表示资源被占用。当信号量的值为零时,表示没有可用的资源,其他任务就要等待,直到有任务释放信号量,信号量的值加一,表示资源被释放。信号量通常用于实现生产者-消费者模型,控制资源的分配和回收。 17、什么是死锁?死锁产生的原因?如何避免? 死锁是指多个任务因为争夺有限的资源而相互等待,导致无法继续执行的现象。死锁产生的原因一般有以下四个必要条件: 互斥条件,指每个资源只能被一个任务拥有,其他任务不能访问。 占有且等待条件,指一个任务已经占有了至少一个资源,但是又申请了其他已经被占有的资源,同时不释放自己已经占有的资源。 不可抢占条件,指一个任务占有的资源不能被其他任务强行剥夺,只能由占有者主动释放。 循环等待条件,指多个任务形成一个环路,每个任务都在等待下一个任务占有的资源。 避免死锁的方法有以下几种: 破坏互斥条件,使用非互斥的资源,如可复制的资源,或者使用软件技术,如事务,来实现对资源的虚拟访问。 破坏占有且等待条件,要求一个任务在申请资源时,必须一次性申请所有需要的资源,或者在申请新的资源时,必须先释放已经占有的资源。 破坏不可抢占条件,允许一个任务在占有资源时,被其他任务抢占,或者主动释放资源,以满足其他任务的需求。 破坏循环等待条件,给每个资源分配一个优先级,要求一个任务只能申请优先级高于或等于自己已经占有的资源的资源,或者按照一定的顺序申请资源,避免形成环路。 18、什么是内存泄漏? 内存泄漏是指程序在运行过程中,动态分配了一些内存空间,但是没有及时释放,导致这些内存空间无法被其他程序使用,造成内存的浪费和紧张。内存泄漏可能会导致程序的性能下降,甚至崩溃。 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 系统死机是指系统无法响应用户的输入,或者出现异常的错误,导致系统无法正常运行。排查系统死机的原因有以下几种方法: 通过日志文件,查看系统在死机前的运行状态,是否有异常的信息,如错误码,警告,断言等,以及死机的时间,位置,频率等,从而定位可能的问题源。 通过调试工具,如gdb,lldb等,对系统进行调试,查看系统的内存,寄存器,堆栈,断点等,分析系统的运行流程,发现潜在的错误,如内存泄漏,空指针,死锁等。 通过测试工具,如valgrind,asan等,对系统进行测试,检测系统的内存管理,性能,覆盖率等,发现系统的缺陷,如内存错误,资源泄漏,性能瓶颈等。 通过代码审查,对系统的代码进行分析,检查代码的风格,规范,逻辑,注释等,发现代码的不合理,不一致,不完善等,提高代码的质量,可读性,可维护性等。 通过重现问题,对系统的死机现象进行复现,观察系统的表现,输入,输出等,找出问题的触发条件,规律,范围等,缩小问题的范围,提高问题的可解决性。 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 同一类型的结构体定义两个变量,不能用内存大小来比较判断两者一样,因为内存大小只能反映结构体的占用空间,而不能反映结构体的内容。例如,以下两个结构体变量的内存大小都是8字节,但是它们的内容是不一样的: struct Point { int x; int y; }; struct Point p1 = {1, 2}; struct Point p2 = {3, 4}; 如果要比较两个结构体变量是否一样,需要逐个比较它们的成员,或者使用memcmp函数比较它们的内存内容。例如: // 逐个比较 if (p1.x == p2.x && p1.y == p2.y) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); } // 使用memcmp比较 if (memcmp(&p1, &p2, sizeof(struct Point)) == 0) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); }21、freertos中EventBits_t是干啥的? EventBits_t是一个数据类型,它用于表示事件标志组(event group)中的每个位的状态,每个位可以表示一个事件的发生或者一个条件的满足。EventBits_t通常是一个无符号整数,它可以使用位运算来设置,清除,读取或等待事件标志。 22、freertos使任务切换的方式有哪些? freertos使任务切换的方式有以下几种: 时间片轮转法,按照任务的优先级和时间片的长度,依次轮流执行每个就绪任务,当一个任务的时间片用完或者主动放弃时,切换到下一个任务。 优先级抢占法,按照任务的优先级,总是执行优先级最高的就绪任务,当有更高优先级的任务就绪时,立即抢占当前任务,切换到更高优先级的任务。 混合法,结合时间片轮转法和优先级抢占法,对于同一优先级的任务,使用时间片轮转法,对于不同优先级的任务,使用优先级抢占法,实现任务的公平性和效率。 23、项目中用到网络了吗? 这个问题的答案取决于你的项目的具体情况,如果你的项目需要与其他设备或服务器进行通信,或者需要访问互联网上的资源,那么你的项目就用到了网络。如果你的项目只是在本地运行,不需要与外界交互,那么你的项目就没有用到网络。 24、了解Socket吗? Socket是一种通信机制,它可以实现不同进程或不同设备之间的数据交换。Socket通常基于TCP/IP协议,提供了可靠的,双向的,面向连接的通信服务。Socket的基本操作包括创建,绑定,监听,连接,发送,接收,关闭等。Socket的编程接口通常是一组函数或类,不同的编程语言或平台可能有不同的实现,如C语言的socket.h,Java语言的java.net.Socket等。 25、c++中set是什么? set是C++标准模板库(STL)中的一个容器,它可以存储一组不重复的元素,并且按照一定的顺序排列。set的元素可以是任意类型,但是必须支持比较操作,如<,==等。set的底层实现通常是红黑树,所以它的插入,删除,查找等操作的时间复杂度都是O(logn) ,其中n是元素的个数。set的优点是可以快速地检查一个元素是否存在,以及保持元素的有序性。set的缺点是不能存储重复的元素,以及不能直接访问元素,只能通过迭代器遍历。 26、有没有用到C++模板? C++模板是一种泛型编程的技术,它可以让程序员定义一种通用的模式,然后根据不同的类型或参数,生成不同的代码,从而实现代码的复用和抽象。C++模板有两种,一种是函数模板,用于定义通用的函数,另一种是类模板,用于定义通用的类。例如,以下是一个函数模板,用于比较两个值的大小: template <typename T> T max(T x, T y) { return (x > y) ? x : y; } 我有用过C++模板,它们可以让我的代码更简洁,更灵活,更高效。我用过STL中的一些类模板,如vector,map,set等,也用过自己定义的一些函数模板和类模板,来实现一些通用的算法和数据结构。 27、有没有对代码裁剪的经验 代码裁剪是指对代码进行优化,删除不必要的或冗余的代码,减少代码的体积和复杂度,提高代码的可读性和可维护性。代码裁剪的目的是为了提高程序的性能,节省内存空间,降低编译时间,避免错误和漏洞等。 我有对代码裁剪的经验,我用过一些工具和方法来进行代码裁剪,如: 使用编译器的优化选项,如-Os,-O3等,让编译器自动进行一些代码裁剪,如常量折叠,死代码删除,循环展开等。 使用代码分析工具,如lint,coverity等,检查代码的质量,发现代码的缺陷,如未使用的变量,函数,参数等,以及代码的风格,规范,注释等,然后根据工具的建议,修改或删除代码。 使用代码重构工具,如refactor,eclipse等,对代码进行重构,改善代码的结构,设计,逻辑等,消除代码的冗余,重复,复杂等,提高代码的可读性,可维护性,可扩展性等。 使用代码压缩工具,如upx,gzip等,对代码进行压缩,减少代码的体积,提高代码的传输速度,节省存储空间等。 28、freertos系统是买模块时人家配置好的?还是移植的? freertos系统是一个开源的,可移植的,实时的操作系统,它可以运行在多种嵌入式平台上,如ARM,MIPS,AVR等。freertos系统不是买模块时人家配置好的,而是需要根据不同的硬件和需求进行移植和定制的。移植freertos系统的步骤一般如下: 下载freertos的源码,选择合适的移植层,如portable/GCC/ARM_CM3等,根据目标平台的特性,修改一些配置参数,如configCPU_CLOCK_HZ,configTICK_RATE_HZ等。 编写启动代码,如设置时钟,中断,堆栈等,调用vPortStartFirstTask ()函数,启动第一个任务。 编写应用代码,如创建任务,队列,信号量,定时器等,调用vTaskStartScheduler ()函数,启动调度器。 编译,链接,下载,调试代码,检查系统的运行情况,如任务切换,中断响应,内存管理等。 29、任务里有两把锁的时候该怎么处理 任务里有两把锁的时候,可能会出现死锁的问题,即两个或多个任务因为互相等待对方占有的锁而无法继续执行。处理任务里有两把锁的时候,有以下几种方法: 避免使用两把锁,如果可能的话,尽量使用一把锁来保护临界区,或者使用其他同步机制,如信号量,事件标志等,来实现任务之间的协作。 按照一定的顺序获取和释放锁,如果必须使用两把锁,那么要求所有的任务都按照相同的顺序获取和释放锁,避免形成循环等待的条件。 使用超时机制,如果一个任务在获取锁时,发现锁已经被占用,那么不要无限期地等待,而是设置一个超时时间,如果超时时间到了,还没有获取到锁,那么就放弃获取,释放已经占有的锁,然后重新尝试或者执行其他操作。 使用优先级继承机制,如果一个任务在获取锁时,发现锁已经被占用,那么就把自己的优先级赋给占有锁的任务,让占有锁的任务尽快执行完毕,释放锁,然后恢复原来的优先级,这样可以避免优先级反转的问题。 30、熟悉Shell脚本吗?$和#啥意思? Shell脚本是一种用于控制Unix或Linux系统的命令行解释器,它可以实现一些自动化的任务,如文件操作,文本处理,程序运行等。Shell脚本的语法和结构类似于C语言,但是更加简洁和灵活。Shell脚本的文件名通常以.sh为后缀,例如test.sh。 $和#是Shell脚本中的两个特殊符号,它们有以下含义: $表示变量的引用,可以用来获取或设置变量的值,例如x=10,echo $x,表示将10赋值给变量x,然后打印x的值。 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。 31、知道#error吗? 、#error是一个预处理指令,它可以用来在编译时产生一个错误信息,中断编译过程。#error通常用来检查一些条件,如宏定义,平台,版本等,如果不满足条件,就提示错误,防止编译出错的代码。例如: #ifdef __linux__ #error This code is not compatible with Linux #endif 这段代码表示如果定义了__linux__宏,就产生一个错误信息,表示这段代码不兼容Linux系统。 32、freertos消息队列的的具体实现? freertos消息队列是一种用于实现任务之间或任务与中断之间的异步通信的机制,它可以存储一组有序的消息,每个消息可以是任意类型的数据。freertos消息队列的具体实现如下: 消息队列是一个结构体,它包含了一些成员,如队列的头指针,尾指针,长度,容量,锁,信号量等,用来管理队列的状态和操作。 消息队列的存储空间是一个数组,它可以是静态分配的或动态分配的,它的大小要能够容纳队列的最大容量乘以每个消息的大小。 消息队列的操作有以下几种,如创建,删除,发送,接收等,它们都是通过调用一些API函数来实现的,如xQueueCreate,vQueueDelete,xQueueSend,xQueueReceive等。 消息队列的操作都是原子的,即在操作过程中,不会被其他任务或中断打断,这是通过使用临界区或中断屏蔽来实现的,以保证队列的一致性和完整性。 消息队列的操作都是阻塞的,即如果队列满了,就不能发送消息,如果队列空了,就不能接收消息,这是通过使用信号量来实现的,以实现任务的同步和等待。 33、堆栈区别? 堆(heap)和栈(stack)都是程序运行时使用的内存空间,但是它们有以下区别: 堆是动态分配的,程序员可以自由地申请和释放堆上的内存空间,堆的大小受到物理内存的限制,堆上的内存空间的地址是不连续的。 栈是静态分配的,编译器会自动地分配和回收栈上的内存空间,栈的大小受到操作系统的限制,栈上的内存空间的地址是连续的。 堆是全局共享的,堆上的内存空间可以被任何函数或模块访问,堆上的内存空间的生命周期是由程序员控制的,如果不及时释放,可能会导致内存泄漏。 栈是局部私有的,栈上的内存空间只能被当前函数或模块访问,栈上的内存空间的生命周期是由编译器控制的,当函数调用结束时,栈上的内存空间就会被自动释放。 34、程序存放状态和区别 程序存放状态是指程序在运行过程中的不同阶段,它有以下几种: 新建状态,指程序刚刚被创建,还没有被加载到内存中,等待调度器的调度。 就绪状态,指程序已经被加载到内存中,已经分配了必要的资源,等待处理器的分配。 运行状态,指程序已经被分配了处理器,正在执行程序的指令。 阻塞状态,指程序在执行过程中,因为等待某些事件的发生,如输入输出,信号量,中断等,而暂时停止执行,释放处理器,等待事件的完成。 终止状态,指程序已经执行完毕,或者因为某些原因,如错误,异常,中断等,而被终止,释放内存和资源,从系统中消失。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
621
4
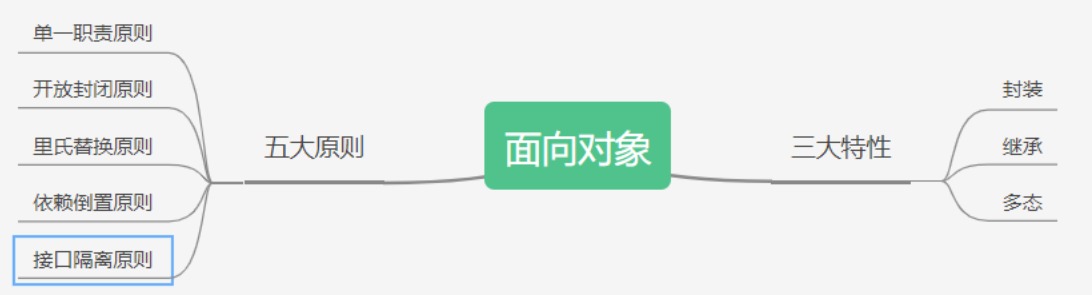
面向对象在编程中的概念
前言 那么究竟什么是面向对象呢?面向过程 面向对象 面向对象的三大特性封装 继承 多态 面向对象的五大基本原则单一职责原则(Single-Responsibility Principle) 开放封闭原则(Open-Closed principle) 里氏替换原则(Liskov-Substitution Principle) 依赖倒置原则(Dependecy-Inversion Principle) 接口隔离原则(Interface-Segregation Principle) 面向对象编程的用途 面向对象编程的应用领域 前言 在刚接触java、C++、Python语言的时候,就知道这是一门面向对象的语言。学不好java的原因找到了,面向对象的语言,没有对象怎么学 ::(狗头) 图片 那么究竟什么是面向对象呢? 面向对象,Object Oriented Programming,简称为OOP。说到面向对象,不得不提一嘴面向过程。 面向过程 面向过程是一种自顶而下的编程模式。 把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。 举个生活中的例子,假如你想吃红烧肉,你需要买肉,买调料,洗肉,切肉,烧肉,装盘。 需要我们具体每一步去实现,每个步骤相互协调,最终盛出来的才是正宗好吃的红烧肉。 面向对象 面向对象就是将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。 还是你想吃红烧肉这个例子,不过这次不同的是你发现了一家餐馆里有红烧肉这道菜,你要做的只是去点菜,就可以吃到红烧肉。 针不戳,针不戳,面向对象针不戳,你不用再去关心红烧肉繁琐的制作流程,就能吃到美味的红烧肉。 我们接着往下看 图片 面向对象的三大特性 封装 封装就是把客观的事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类进行信息的隐藏。简单的说就是:封装使对象的设计者与对象的使用者分开,使用者只要知道对象可以做什么就可以了,不需要知道具体是怎么实现的。封装可以有助于提高类和系统的安全性 这里有点像FPGA的IP了,电子人懂! 继承 当多个类中存在相同属性和行为时,将这些内容就可以抽取到一个单独的类中,使得多个类无需再定义这些属性和行为,只需继承那个类即可。通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类” 多态 多态同一个行为具有多个不同表现形式或形态的能力。是指一个类实例(对象)的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。 菜鸟教程中的例子就很形象 现实中,比如我们按下 F1 键这个动作: 如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档; 如果当前在 Word 下弹出的就是 Word 帮助; 在 Windows 下弹出的就是 Windows 帮助和支持。 同一个事件发生在不同的对象上会产生不同的结果。 面向对象的五大基本原则 单一职责原则(Single-Responsibility Principle) 简而言之,就是一个类最好只有一个能引起变化的原因,只做一件事,单一职责原则可以看做是低耦合高内聚思想的延伸,提高高内聚来减少引起变化的原因。 开放封闭原则(Open-Closed principle) 简而言之,就是软件实体应该是可扩展的,但是不可修改。因为修改程序有可能会对原来的程序造成错误。即对扩展开放,对修改封闭 里氏替换原则(Liskov-Substitution Principle) 简而言之,就是子类一定可以替换父类,子类包含其基类(父类)的功能 依赖倒置原则(Dependecy-Inversion Principle) 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。依赖于抽象即对接口编程,不要对实现编程 接口隔离原则(Interface-Segregation Principle) 图片 简而言之,就是使用多个小的专门的接口,而不要使用一个大的总接口。例如将一个房子再分割成卧室,厨房,厕所等等,而不是将所有功能放在一起 面向对象编程的用途 使用封装(信息隐藏)可以对外部隐藏数据 使用继承可以重用代码 使用多态可以重载操作符/方法/函数,即相同的函数名或操作符名称可用于多种任务 数据抽象可以用抽象实现 项目易于迁移(可以从小项目转换成大项目) 同一项目分工 软件复杂性可控 面向对象编程的应用领域 人工智能与专家系统 企业级应用 神经网络与并行编程 办公自动化系统
编程&脚本笔记
# 软件算法
# C/C++
刘航宇
3年前
0
436
3
2023-12-20
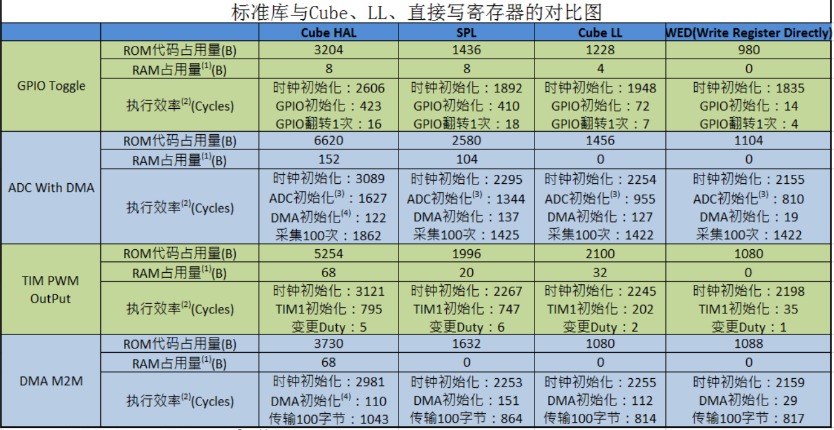
【嵌软】STM32的4种开发方式介绍
与FPGA一样,STM32也属于板级开发,可适用于大多数计算场合,但神经网络这种需要大量并行计算的需求难以满足。 STM32的开发主要指的是通过程序实现功能,ST官方提供的开发方式来说从远及近分别是: 1、直接读写寄存器 2、标准外设驱动库 SPL 3、硬件抽象层库 HAL库 4、底层库 LL库 四种开发方式各有优缺点,可以参考ST官方的测试与说明: 图片 标准外设库:这是ST官方提供的一套固件库,包含了STM32所有外设的驱动函数,可以方便地调用。它的优点是稳定、兼容、易用,缺点是占用资源较多,效率较低,更新较慢。 寄存器操作:这是直接对STM32的寄存器进行读写的方式,可以实现最底层的控制。它的优点是占用资源最少,效率最高,缺点是难度较大,需要熟悉寄存器的功能和位定义,不利于移植。 HAL库:这是ST官方推出的一套新的固件库,基于硬件抽象层(Hardware Abstraction Layer)的思想,提供了更加简洁和统一的接口。它的优点是支持多种IDE,更新较快,易于移植,缺点是文档较少,兼容性较差,有些BUG。CubeMX:这是ST官方提供的一套图形化的配置工具,可以自动生成HAL库的代码,还可以集成一些中间件和应用层的功能。它的优点是操作简单,功能强大,缺点是生成的代码较冗余,不易修改,有些功能不完善。 直接读写寄存器 开发是最慢的,可移植性最差,基本不推荐使用,只有个别对时间或是内存要求特别高、或者在写操作系统调度器时才需要直接读写寄存器; 标准外设驱动库 是ST最开始提供的库(国内的教程也很多是依据题库出的),现在已经被ST放弃了; HAL库 和 LL库 是近几年推出的库,结合 STM32CubeIDE 使用非常方便, HAL库 性能较差、在STM32系列芯片中可移植性好, LL库 性能好、可移植性差。
嵌入式&系统
# 嵌入式
# C/C++
刘航宇
3年前
0
1,163
3
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
504
0
2023-11-20
超声模块HC_SR04基本原理与FPGA、STM32应用
HC-SR04硬件概述 接口定义: 模式选择: 测量操作: FPGA实现超声测距模块代码 ifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" endif / HCSR04_H_ / include "hc-sr04.h" include "hc-sr04.h" include "printf.h" HC-SR04 硬件概述 HC-SR04超声波距离传感器的核心是两个超声波传感器。一个用作发射器,将电信号转换为40 KHz超声波脉冲。接收器监听发射的脉冲。如果接收到它们,它将产生一个输出脉冲,其宽度可用于确定脉冲传播的距离。就是如此简单! 该传感器体积小,易于在任何机器人项目中使用,并提供2厘米至600厘米(约1英寸至13英尺)之间出色的非接触范围检测,精度为3mm。 图片 接口定义: 图片 模式选择: 图片 测量操作: 一:GPIO模式 图片 外部MCU给模块Trig脚一个大于10uS的高电平脉冲;模块会给出一个与距离等比的高电平脉冲信号,可根据脉宽时间“T” 算出: 距离=T*C/2 (C为声速) 声速温度公式:c=(331.45+0.61t/℃)m•s-1 (其中330.45是在0℃) 0℃声速: 330.45M/S 20℃声速: 342.62M/S 40℃声速: 354.85M/S0℃-40℃声速误差7%左右。实际应用,如果需要精确距离值,必需要考虑温度影响,做温度补偿。 二:UART模式 UART 模式波特率设置: 9600 N 1 图片 连接串口。外部MCU或PC发命令0XA0,模块完成测距后发3个返回距离 数据,BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 三:IIC模式 IIC地址: 0X57 IIC传输格式: 写数据: 图片 读数据: 图片 命令格式: 图片 向模块写入0X01,模块开始测距;等待200mS(模块最大测距时间) 以上。直接读出3个距离数据。BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 FPGA实现超声测距 本次测距教程一律按基本原理实现,至于UART、ICC测距原理可以网上查询 FPGA 产生周期性的 TRIG 脉冲信号,使得超声波模块周期性发出测距脉冲,当这些脉冲发出后遇到障碍物返回,超声波模块将返回的脉冲处理整形后返回给 FPGA,即 ECHO 信号。我们通过对 ECHO 信号的高脉冲保持时间就可以推算出超声波脉冲和障碍物之间的距离。 本实例的功能如图三所示,FPGA 产生 10us 脉冲 TRIG 给超声波测距模块,然后以 10us 为单位计算超声波测距模块返回的回响信号 ECHO 的高电平保持时间。ECHO 的高电平保持时间通过一定的换算后可以得到障碍物和超声波测距模块之间的距离(由距离公式计算&进制换算模块实现),我们将最终获得的以 mm 为单位的距离信息显示在 4 位数码管上。 图片 模块代码 1、vlg_en模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 15:24:01 * @Email: hyliu@ee.ac.cn * @Descripttion: 板子时钟转化1us * @Last Modified time: 2023-11-20 15:24:01 */ //1us/50ns=20 module vlg_1us#(parameter P_CLK_PERIORD = 50) //i_clk的时钟周期50ns,20MHZ ( input i_clk, input i_rst_n, output reg o_clk //时钟周期1us ); parameter NUM_DIV = 20;// (1MHZ = 1us,20MHZ/20 = 1MHZ) reg [3:0] cnt; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) begin cnt <= 4'd0; o_clk <= 1'b0; end else if(cnt == NUM_DIV/2 - 1) begin cnt <= 4'b0; o_clk <= ~o_clk; end else cnt <= cnt + 1'b1; end endmodule2、vlg_trig模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 16:50:44 * @Email: hyliu@ee.ac.cn * @Descripttion: 产生10us的触发超声信号 * @Last Modified time: 2023-11-20 16:50:44 */ module vlg_trig ( input i_rst_n, input clk_1us, //1us output reg o_trig ); reg[17:0] r_tricnt; //200ms的周期计数 1us一个单位 always @(posedge clk_1us or negedge i_rst_n)begin if(!i_rst_n) r_tricnt <= 18'd0; else if((r_tricnt == 18'd199999)) r_tricnt <= 18'd0; else r_tricnt <= r_tricnt + 1'b1; end //产生保持10us的高脉冲o_tring信号 always @(posedge clk_1us or negedge i_rst_n) begin if(!i_rst_n) o_trig<=1'b0; else if((r_tricnt > 18'd0) && (r_tricnt <= 18'd10)) o_trig <= 1'b1; //不从0开始0~9,防止出现不到10us的波干扰 else o_trig <= 1'b0; end endmodule3、vlg_echo模块 module vlg_echo ( input i_clk, //1us input i_rst_n, input i_clk_1us, input i_echo, output reg[15:0] o_t_us ); reg[1:0] r_echo; wire pos_echo,neg_echo; reg r_cnt_en; reg[15:0] r_echo_cnt; //对i_echo信号同步处理,获取边沿检测信号,产生计数使能信号r_cnt_en always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_echo <= 2'd0; else r_echo <= {r_echo[0],i_echo}; //设置两个寄存器进行打拍寄存 end assign pos_echo = r_echo[0] & ~r_echo[1]; //现状态是1上状态是0,就是上升沿 assign neg_echo = ~r_echo[0] & r_echo[1]; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_cnt_en <= 1'b0; else if(pos_echo) r_cnt_en <= 1'b1; else if(neg_echo) r_cnt_en <= 1'b0; else r_cnt_en <= r_cnt_en; end //对i_echo信号的高脉冲计时,以us为单位 always @(posedge i_clk_1us or negedge i_rst_n) begin if(!i_rst_n) r_echo_cnt <= 1'b0; else if(r_cnt_en) r_echo_cnt <= r_echo_cnt + 1'b1; else r_echo_cnt <= 1'b0; end //在下降沿对计数最大值进行保存 always @(negedge i_clk or negedge i_rst_n) begin if(!i_rst_n) o_t_us <= 16'd0; else if(neg_echo) o_t_us <= r_echo_cnt; else o_t_us <= o_t_us; end endmodule 4、顶层模块例化/* @Author: Hangyu Liu @Date: 2023-11-23 17:16:40 @Email: hyliu@ee.ac.cn @Descripttion:HR04驱动模块 @Last Modified time: 2023-11-23 17:16:40 */ module vlg_design ( input i_clk, //200MHZ input i_rst_n, input i_echo, //这是超声模块给的输入 output o_trig, output wire[15:0] w_t_us); wire clk_20MHZ; clk_div_20MHZ UU( .i_clk(i_clk), .i_rst_n(i_rst_n), .clk_div(clk_20MHZ)); localparam P_CLK_PERIORD = 50; wire clk_1us; //使能时钟产生模块 vlg_1us #( .P_CLK_PERIORD(P_CLK_PERIORD) //i_clk的时钟周期50ns,20MHZ)U1( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .o_clk(clk_1us)); //产生超声波测距模块的触发信号o_trig vlg_trig U2( .i_rst_n(i_rst_n), .clk_1us(clk_1us), .o_trig(o_trig)); //超声波测距模块的回响信号i_echo的高电平时间采集 vlg_echo U3( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .i_clk_1us(clk_1us), .i_echo(i_echo), .o_t_us(w_t_us)); endmodule ## STM32(Cubemax)实现超声波测距 ### CubeMX配置STM32 1 时钟配置 这里我用的是STM32F103C8T6的核心板,时钟配置如下图,我用了8MHz的HSE,HCLK调到了最大值72MHz  2 设置输入捕获的定时器 设置定时器TIM2每1us向上计数一次,通道4为上升沿捕获并连接到超声波模块的ECHO引脚,记得开启定时器中断(涉及到捕获中断+定时器溢出中断)。  3 触发引脚 PB10接到了HC-SR04的TIRG触发引脚,默认输出低电平  4 串口配置 还要开启一个串口,以便通过串口查看测距结果  ### 编写代码 hc-sr04.hifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" typedef struct { uint8_t edge_state; uint16_t tim_overflow_counter; uint32_t prescaler; uint32_t period; uint32_t t1; // 上升沿时间 uint32_t t2; // 下降沿时间 uint32_t high_level_us; // 高电平持续时间 float distance; TIM_TypeDef* instance;uint32_t ic_tim_ch; HAL_TIM_ActiveChannel active_channel;}Hcsr04InfoTypeDef; extern Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel); /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start(); /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim); /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim); /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read(); endif / HCSR04_H_ / hc-sr04.cinclude "hc-sr04.h" Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel) { /--------[ Configure The HCSR04 IC Timer Channel ] / // MX_TIM2_Init(); // cubemx中配置 Hcsr04Info.prescaler = htim->Init.Prescaler; // 72-1 Hcsr04Info.period = htim->Init.Period; // 65535 Hcsr04Info.instance = htim->Instance; // TIM2 Hcsr04Info.ic_tim_ch = Channel; if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_1) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_1; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_2) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_2; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_3) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_3; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} /--------[ Start The ICU Channel ]-------/ HAL_TIM_Base_Start_IT(htim); HAL_TIM_IC_Start_IT(htim, Channel); } /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start() { HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_SET); DelayUs(10); // 10us以上 HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_RESET); } /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim) { if(htim->Instance == Hcsr04Info.instance) // TIM2 { Hcsr04Info.tim_overflow_counter++;} } /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim) { if((htim->Instance == Hcsr04Info.instance) && (htim->Channel == Hcsr04Info.active_channel)) { if(Hcsr04Info.edge_state == 0) // 捕获上升沿 { // 得到上升沿开始时间T1,并更改输入捕获为下降沿 Hcsr04Info.t1 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_FALLING); Hcsr04Info.tim_overflow_counter = 0; // 定时器溢出计数器清零 Hcsr04Info.edge_state = 1; // 上升沿、下降沿捕获标志位 } else if(Hcsr04Info.edge_state == 1) // 捕获下降沿 { // 捕获下降沿时间T2,并计算高电平时间 Hcsr04Info.t2 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); Hcsr04Info.t2 += Hcsr04Info.tim_overflow_counter * Hcsr04Info.period; // 需要考虑定时器溢出中断 Hcsr04Info.high_level_us = Hcsr04Info.t2 - Hcsr04Info.t1; // 高电平持续时间 = 下降沿时间点 - 上升沿时间点 // 计算距离 Hcsr04Info.distance = (Hcsr04Info.high_level_us / 1000000.0) * 340.0 / 2.0 * 100.0; // 重新开启上升沿捕获 Hcsr04Info.edge_state = 0; // 一次采集完毕,清零 __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_RISING); }} } /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read() { // 测距结果限幅 if(Hcsr04Info.distance >= 450) { Hcsr04Info.distance = 450;} return Hcsr04Info.distance; } main.c 1、引用对应的头文件/ USER CODE BEGIN Includes / include "hc-sr04.h" include "printf.h" / USER CODE END Includes / 2、200ms测距一次/** @brief The application entry point. @retval int */ int main(void) { / USER CODE BEGIN 1 / / USER CODE END 1 / / MCU Configuration--------------------------------------------------------/ / Reset of all peripherals, Initializes the Flash interface and the Systick. / HAL_Init(); / USER CODE BEGIN Init / / USER CODE END Init / / Configure the system clock / SystemClock_Config(); / USER CODE BEGIN SysInit / / USER CODE END SysInit / / Initialize all configured peripherals / MX_GPIO_Init(); MX_TIM2_Init(); MX_USART1_UART_Init(); / USER CODE BEGIN 2 / DelayInit(72); Hcsr04Init(&htim2, TIM_CHANNEL_4); // 超声波模块初始化 Hcsr04Start(); // 开启超声波模块测距 printf("hc-sr04 start!\r\n"); / USER CODE END 2 / / Infinite loop / / USER CODE BEGIN WHILE / while (1) { // 打印测距结果 printf("distance:%.1f cm\r\n", Hcsr04Read()); Hcsr04Start(); DelayMs(200); // 测距周期200ms /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */} / USER CODE END 3 / } 3、重定义定时器的中断服务函数/ USER CODE BEGIN 4 / /** @description: 定时器输出捕获中断 @param {TIM_HandleTypeDef} *htim @return {*} */ void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim) { Hcsr04TimIcIsr(htim); } /** @description: 定时器溢出中断 @param {*} @return {*} */ void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef* htim) { Hcsr04TimOverflowIsr(htim); } / USER CODE END 4 / 4、串口打印结果
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
0
1,307
2
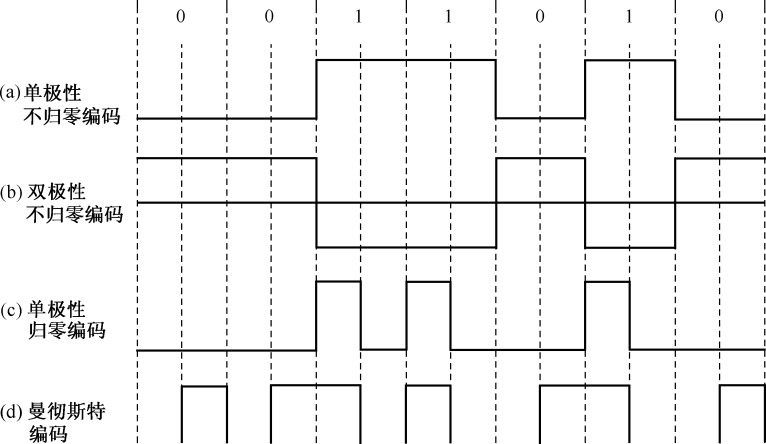
RFID编码简介
信号编码系统包括信源编码和信道编码两大类,器作用是把要传输的信息尽可能的与传输信道相匹配,并提供对信息的某种保护以防止信息受到干扰。信源编码与信源译码的目的是提高信息传输的有效性以及完成模数转换等;信道编码与信道译码的目的是增强信号的抗干扰能力,提高传输的可靠性。 常见的编码方法如下图: 图片 RFID系统常用编码方法: 反向不归零(NRZ)编码 曼彻斯特(Manchester)编码 单极性归零(RZ)编码 差动双相(DBP)编码 密勒(Miller)编码和差动编码 图片 1、反向不归零编码(NRZ,Non Return Zero) 反向不归零编码用高电平表示二进制“1”,低电平表示二进制“0”,如下图所示: 图片 此码型不宜传输,有以下原因 有直流,一般信道难于传输零频附近的频率分量; 接收端判决门限与信号功率有关,不方便使用; 不能直接用来提取位同步信号,因为NRZ中不含有位同步信号频率成分; 要求传输线有一根接地。 注:ISO14443 TYPE B协议中电子标签和阅读器传递数据时均采用NRZ 2、曼彻斯特编码(Manchester) 曼彻斯特编码也被称为分相编码(Split-Phase Coding)。 某比特位的值是由该比特长度内半个比特周期时电平的变化(上升或下降)来表示的,在半个比特周期时的负跳变表示二进制“1”,半个比特周期时的正跳变表示二进制“0”,如下图所示: 图片 曼彻斯特编码的特点 曼彻斯特编码在采用负载波的负载调制或者反向散射调制时,通常用于从电子标签到读写器的数据传输,因为这有利于发现数据传输的错误。这是因为在比特长度内,“没有变化”的状态是不允许的。 当多个标签同时发送的数据位有不同值时,则接收的上升边和下降边互相抵消,导致在整个比特长度内是不间断的负载波信号,由于该状态不允许,所以读写器利用该错误就可以判定碰撞发生的具体位置。 曼彻斯特编码由于跳变都发生在每一个码元中间,接收端可以方便地利用它作为同步时钟。 注: ISO14443 TYPE A协议中电子标签向阅读器传递数据时采用曼彻斯特编码。 ISO18000-6 TYPE B 读写器向电子标签传递数据时采用的是曼彻斯特编码 3、单极性归零编码(Unipolar RZ) 当发码1时发出正电流,但正电流持续的时间短于一个码元的时间宽度,即发出一个窄脉冲 当发码0时,完全不发送电流 单极性归零编码可用来提取位同步信号。 pPbm28I.png图片 4、差动双相编码(DBP) 差动双相编码在半个比特周期中的任意的边沿表示二进制“0”,而没有边沿就是二进制“1”,如下图所示。此外在每个比特周期开始时,电平都要反相。因此,对于接收器来说,位节拍比较容易重建。 pPbmR2t.png图片 5、密勒编码(Miller) 密勒编码在半个比特周期内的任意边沿表示二进制“1”,而经过下一个比特周期中不变的电平表示二进制“0”。一连串的比特周期开始时产生电平交变,如下图所示,因此,对于接收器来说,位节拍也比较容易重建。 pPbmhKf.png图片 pPbm5qS.png图片 6、修正密勒码编码 7、脉冲-间歇编码 对于脉冲—间歇编码来说,在下一脉冲前的暂停持续时间t表示二进制“1”,而下一脉冲前的暂停持续时间2t则表示二进制“0”,如下图所示。 pPbnUoQ.png图片 这种编码方法在电感耦合的射频系统中用于从读写器到电子标签的数据传输,由于脉冲转换时间很短,所以就可以在数据传输过程中保证从读写器的高频场中连续给射频标签供给能量。 8、脉冲位置编码(PPM,Pulse Position Modulation) 脉冲位置编码与上述的脉冲间歇编码类似,不同的是,在脉冲位置编码中,每个数据比特的宽度是一致的。 其中,脉冲在第一个时间段表示“00”,第二个时间段表示“01”, 第三个时间段表示“10”, 第四个时间段表示“11”, 如图所示 pPbnwJs.png图片 注:ISO15693协议中,数据编码采用PPM 9、FM0编码 FM0(即Bi-Phase Space)编码的全称为双相间隔码编码、 工作原理是在一个位窗内采用电平变化来表示逻辑。如果电平从位窗的起始处翻转,则表示逻辑“1”。如果电平除了在位窗的起始处翻转,还在位窗中间翻转则表示逻辑“0”。 pPbn0Wn.png图片 注:ISO18000-6 typeA 由标签向阅读器的数据发送采用FM0编码 10、PIE编码 PIE(Pulse interval encoding)编码的全称为脉冲宽度编码,原理是通过定义脉冲下降沿之间的不同时间宽度来表示数据。 在该标准的规定中,由阅读器发往标签的数据帧由SOF(帧开始信号)、EOF(帧结束信号)、数据0和1组成。在标准中定义了一个名称为“Tari”的时间间隔,也称为基准时间间隔,该时间段为相邻两个脉冲下降沿的时间宽度,持续为25μs。 pPbnBzq.png图片 注:ISO18000-6 typeA 由阅读器向标签的数据发送采用PIE编码 ============================================= 注:选择编码方法的考虑因素 编码方式的选择要考虑电子标签能量的来源 在REID系统中使用的电子标签常常是无源的,而无源标签需要在读写器的通信过程中获得自身的能量供应。为了保证系统的正常工作,信道编码方式必须保证不能中断读写器对电子标签的能量供应。 在RFID系统中,当电子标签是无源标签时,经常要求基带编码在每两个相邻数据位元间具有跳变的特点,这种相邻数据间有跳变的码,不仅可以保证在连续出现“0”时对电子标签的能量供应,而且便于电子标签从接收到的码中提取时钟信息。 编码方式的选择要考虑电子标签的检错的能力 出于保障系统可靠工作的需要,还必须在编码中提供数据一级的校验保护,编码方式应该提供这种功能。可以根据码型的变化来判断是否发生误码或有电子标签冲突发生。 在实际的数据传输中,由于信道中干扰的存在,数据必然会在传输过程中发生错误,这时要求信道编码能够提供一定程度的检测错误的能力。 曼彻斯特编码、差动双向编码、单极性归零编码具有较强的编码检错能力。 编码方式的选择要考虑电子标签时钟的提取 在电子标签芯片中,一般不会有时钟电路,电子标签芯片一般需要在读写器发来的码流中提取时钟。 曼彻斯特编码、密勒编码、差动双向编码容易使电子标签提取时钟。
通信&信息处理
# 通信&射频
# 软件算法
刘航宇
3年前
0
2,437
0
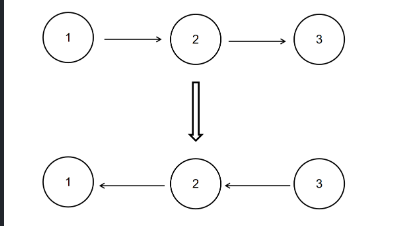
算法-反转链表C&Python实现
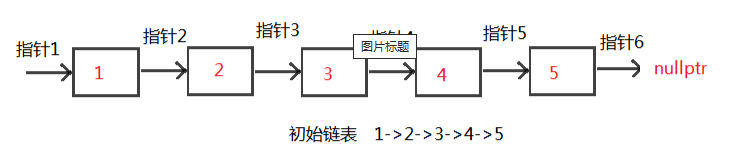
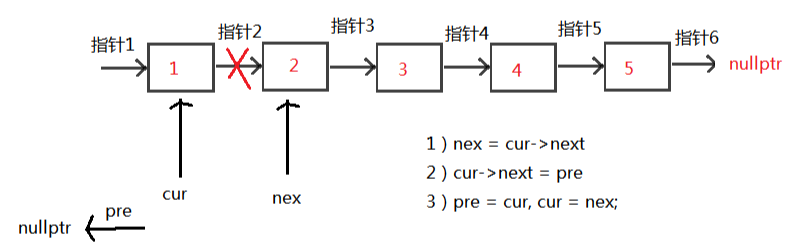
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
315
1
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
338
0
1
2
...
10
下一页