首页
📁归档
⏳时光机
🚩友链
📫留言
📧订阅本站
推荐
📕考研课程
🏜️ 免费壁纸
❤ 捐助本站
💰资助名单
🎵音乐实验
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
20,039 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,601 阅读
3
【高数】形心计算公式讲解大全
9,035 阅读
4
Vivado-FPGA Verilog烧写固化教程
7,859 阅读
5
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,803 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
/
注册
FPGA&ASIC(共60篇)
找到
60
篇与
FPGA&ASIC
相关的结果
- 第 3 页
2023-02-10
FPGA与数字IC设计中接口命名规范
在硬件编程中,接口命名规范也是一个良好的习惯。接口在确定模块划分后需要明确模块的端口以及模块间的数据交互。完成项目模块划分后,可以在确定端口及数据流向时参考使用。本节重点是EN与vld的区别! ` 端口信号规范 ` 信号说明clk模块工作时钟rst_n系统复位信号,低电平有效en门控时钟,请搜索本站关于门控时钟讲解,这是低功耗的设计,EN=0睡眠状态、阻断时钟输入vld数据有效标志指示信号,表示当前的 data 数据有效。注意,vld 不仅表示了数据有效,而且还表示了其有效次数。时钟收到多少个 vld=1,就表示有多少个数据有data数据总线。输入一般名称为 din,输出一般名称为 dout。类似的信号还有 addr,len 等err整个报文错误指示,在 eop=1 且 vld=1 有效时才有效sop报文起始指示信号,用于表示有效报文数据的第一个数据,当 vld=1 时此信号有效eop报文结束指示信号,用于表示有效报文数据的最后一个数据,当 vld=1 时此信号有效rdy模块准备好信号,用于模块之间控制数据发送速度。例如模块 A 发数据给模块 B,则rdy 信号由模块 B 产生,连到模块 A(该信号对于 B 是输出信号,对于 A 是输入信号);B 要确保 rdy 产生正确,当此信号为 1 时,B 一定能接收数据;A 要确保仅在 rdy=1 时才发送图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
511
2
IC设计技巧-流水线设计
流水线概述 如下图为工厂流水线,工厂流水线就是将一个工作(比如生产一个产品)分成多个细分工作,在生产流水线上由多个不同的人分步完成。这个待完成的产品在流水线上一级一级往下传递。 图片 比如完成一个产品,需要8道工序,每道工序需要10s,那么流水线启动后,不间断工作的话,第一个产品虽然要80s才完成,但是接下来每10s就能产出一个产品。使得速度大大提高。当然这也增加了人员等资源的付出。 对于电路的流水线设计思想与上述思想异曲同工,也是以付出增加资源消耗为代价,去提高电路运算速度。 流水线设计实例 这里以一个简单的8位无符号数全加器的设计为实例来进行讲解,实现 assign {c_out,data_out [7:0]} = a[7:0] + b[7:0] +c_in c_out 为进位位。如果有数字电路常识的人都知道,利用一块组合逻辑电路去做8位的加法,其速度肯定比做2位的加法慢。因此这里可以采用4级流水线设计,每一级只做两位的加法操作,当流水线一启动后,除第一个加法运算之外,后面每经过一个2位加法器的延时,就会得到一个结果。 整体结构如下,每一级通过in_valid,o_valid信号交互,分别代表每一级的输入输出有效信号。 图片 第一级:做最低两位与进位位的加法操作,并将运算结果和未做运算的高六位传给下一级。 图片 第二级:做2,3两位与上一级加法器的进位位的加法操作,并将本级运算结果和未做运算的高4位传给下一级。 图片 第三级:做4,5两位与进位位的加法操作,并将运算结果和未做运算的高2位传给下一级。 图片 第四级:做最高两位与上一级加法器输出的进位位的加法操作,并将结果组合输出。 图片 仿真结果如下 如图,当整体模块in_valid有效时,送进去的数据a=1,b=5,c_in=1;故经过四个周期后,o_valid信号拉高,同时获得运算结果data_out=7。(本设计的流水线每级延时为一个时钟周期)后续输出信号7、9、10显然是间隔2个周期延迟,而不是延迟4周期、8周期逐个输出 图片 总结 流水线就是通过将一个大的组合逻辑划分成分步运算的多个小组合逻辑来运算,从而达到提高速度的目的。 在设计流水线的时候,我们一般要尽量使得每级运算所需要的时间差不多,从而做到流水匹配,提高效率。因为流水线的速度由运算最慢的那一级电路决定。
FPGA&ASIC
VLSI&IC验证
# VLSI
# ASIC/FPGA
刘航宇
3年前
0
630
1
2023-02-08
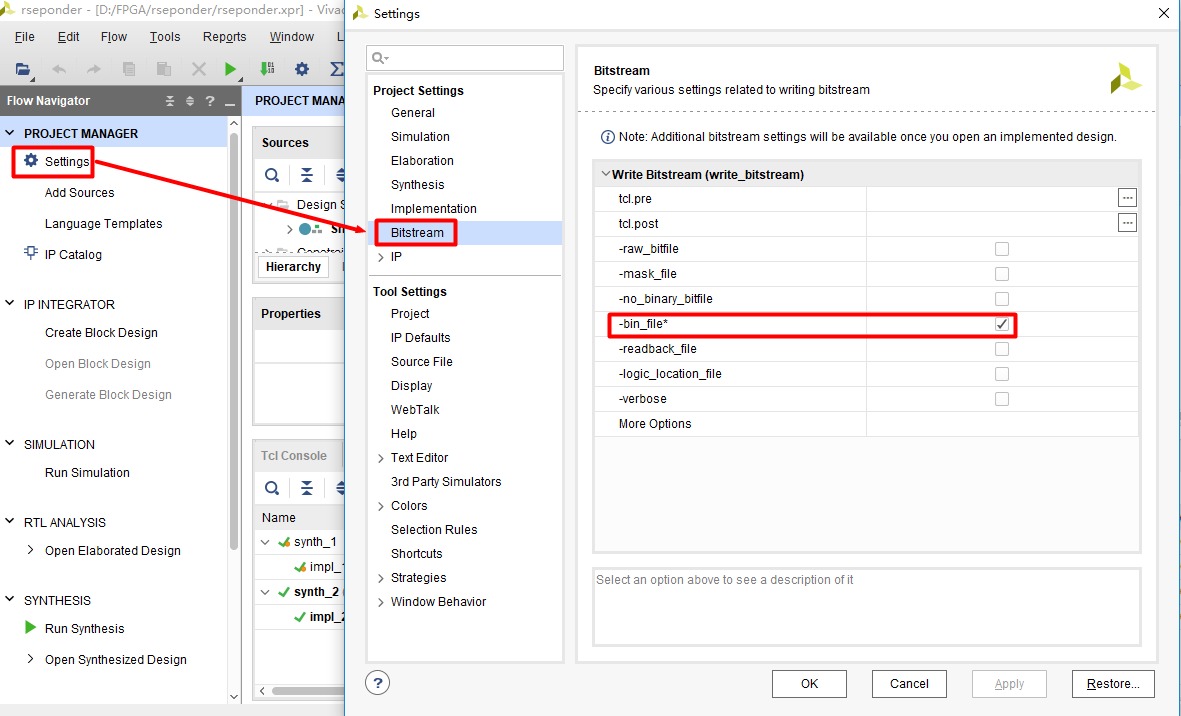
Vivado-FPGA Verilog烧写固化教程
Vivado里程序固化详细教程 编者注:初玩FPGA开发板,我们都会遇到这种情况,每次事先写好的程序编译成功后,下载到板子里,输出结果十分赏心悦目,随着掉电之后,程序也就随之消失,再次上电,又要重新编译下载程序,十分麻烦,不是我们想看到的结果。所以学会固化程序十分重要!下面就来说说如何固化程序。 目的简介:将FPGA的配置文件(固化用的配置文件是二进制文件,仅bin文件)烧写到板载Flash中,实现上电自启动,完成程序固化。 目录 Vivado里程序固化详细教程 法1:烧录bin文件 法二烧mcs文件 法1:烧录bin文件 过程步骤: 1)在Vivado软件里找到Settings设置选项,进入,点击Bitstream选项,将 bin_file 勾上,点击 OK 图片 2)点击 generate bitstream (可以分步进行,Run Synthesis—Run implementation— genereate bitstream),生成 bit 文件和 bin 文件。 图片 3)点击 open hardware manager,连接板子 图片 4)在Hardware面板中右击FPGA器件(xc7a35t_0),选择Add Configuration Memery Device。 图片 5)在弹出的添加配置存储器的界面中,找到板载的Flash存储器型号,点击OK,完成添加。这里开发板flash型号是( n25q64 )选择3.3v。 图片 6)添加完成后,Vivado会提示添加完成,是否立即配置存储器。点击OK,进入配置存储器的界面,开始将二进制bin文件烧写到外部配置flash存储器中。 图片 提醒:如果配置存储器的界面突然找不到,可以右击flash存储器,点击Program Configuration Memory Device,会出现存储器的配置界面。 图片 7)找到二进制bin文件,选中,进行代码烧写, 实现上电自启动,完成程序固化。 图片 选择好烧写的二进制文件,选中后点击 OK,将代码烧录到 flash,。其他设置可以保持默认 提醒:二进制文件路径为:project_name\project_name.runs\impl_1\xxx.bin。 或project_name \project_name.runs\impl_2\xxx.bin。 (project_name根据用户工程进行修改)。点击OK,烧写二进制文件。 由于需要擦除存储器原有数据,校验,以及烧写等几步,所以配置时间可能会稍微久一点。完成后,点击OK。 这样FPGA硬件程序就固化到外部配置存储器中了,下次上电就可以通过QSPI自启动。需要注意的是板载的配置跳线帽需要设置到QSPI模式。 法二烧mcs文件 第一步:先综合,然后打开综合设计 图片 第二步:点击Tools—Edit Device Properties(注意,必须按照第一步打开综合后的设计,才能找到这个选项),然后配置相应参数。 图片 可以选择压缩bit流,这样后面固化时会快一些。 图片 选择合适的固化速率,可以适当设置高一些(默认是3MHZ),因为固化本身比较慢;设置SPI 的bus width,因为flash使用的是QSPI,也即SPI4x(后面还会设置此参数),所以这里要设置为4 图片 选择编程模式,因为我们是将程序固化到flash中,以后上电自动从flash读取程序,所以这里要勾选上。JTAG是一直且默认勾选的。 图片 点击OK进行下一步。 第三步:生成bit流 第四步:生成.mcs内存配置文件 图片 图片 点击OK,即可在指定的路径下生成所需的.mcs文件 第五步:打开硬件管理器,连接开发板。 图片 第六步:往flash下载.mcs文件 图片 图片 点击OK,然后出现下面的界面,等待下载完成即可。 图片 第七步:断电重启 注意: 一定要注意将自己开发板上设置编程模式的跳线帽跳到QSPI模式。还有就是固化完成后,不会立即运行程序,需要断电重启,此时开发板会自动从flash读取程序并运行。这样以后每次上电都会自动加载并运行这段程序,除非再次固化别的程序!!!
FPGA&ASIC
EDA&虚拟机
刘航宇
3年前
0
7,859
8
Verilog RTL级低功耗设计-门控时钟及时钟树
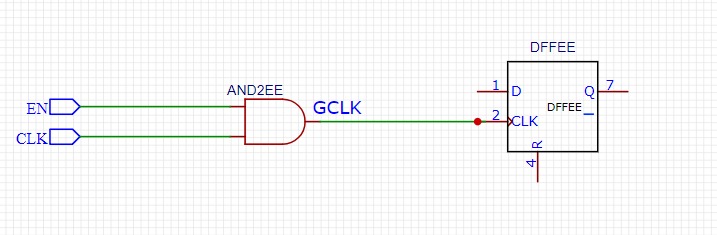
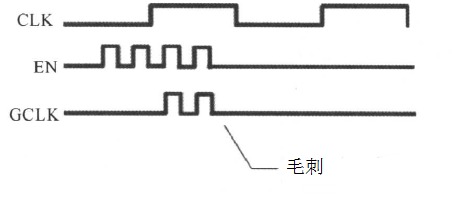
在ASIC/FGPA设计中,我们外界控制所设计的模块时候需要实现告诉他,我要给你输入信号了,你的工作了,反之你不用工作,这个就是门控时钟,就是使能信号EN,一般来说我们用EN控制CLK的产生。芯片功耗组成中,有高达40%甚至更多是由时钟树消耗掉的。这个结果的原因也很直观,因为这些时钟树在系统中具有最高的切换频率,而且有很多时钟buffer,而且为了最小化时钟延时,它们通常具有很高的驱动强度。此外,即使输入和输出保持不变,接收时钟的触发器也会消耗一定的功耗。而且这些功耗主要是动态功耗。 那么减少时钟网络的功耗消耗,最直接的办法就是如果不需要时钟的时候,就把时钟关掉。这种方法就是大家熟悉的门控时钟:clock gating。(大家电路图中看到的CG cell就是门控时钟了) 目录 1门控时钟的结构1.1与门门控 1.2 锁存门控 1.3 寄存门控 1.4 门控时钟结构选择 2 RTL中的门控时钟 附加:门控时钟的时钟树设计 3 RTL 门控时钟编码风格 后记 1门控时钟的结构 1.1与门门控 如果让我们设计一个门控时钟的电路,我们会怎么设计呢?最直接的方法,不需要时钟的时候关掉时钟,这就是与操作,我们只需要把enable和CLK进行“与”操作不就行了么,电路图如下: 图片 这种直接将控制EN信号和时钟CLK进行与操作完成门控的方式,可以完成EN为0时,时钟被关掉。但是同时带来另外一个很大的问题:毛刺 图片 如上图所示,EN是不受控制的,随时可能跳变,这样纯组合输出GCLK就完全可能会有毛刺产生。时钟信号上产生毛刺是很危险的。实际中,这种直接与门的方式基本不会被采样。 所以我们需要改进电路,为了使门控时钟不产生毛刺,我们必须对EN信号进行处理,使其在CLK的高低电平期间保持不变,或者说EN的变化就是以CLK为基准的。 1 很自然的我们会想到触发器,只要把EN用CLK寄存一下,那么输出就是以CLK为基准的; 2 其实还有一种办法是锁存器,把EN用锁存器锁存的输出,也是以CLK为基准的。 1.2 锁存门控 我们先看一下第二种电路,增加锁存器的电路如下: 图片 对应的时序如下: 图片 可以看到,只有在CLK为高的时候,GCLK才可能会输出高,这样就能消除EN带来的毛刺。这是因为D锁存器是电平触发,在clk=1时,数据通过D锁存器流到了Q;在Clk=0时,Q保持原来的值不变。 虽然达到了我们消除毛刺的目的,但是这个电路还有两个缺点: 1如果在电路中,锁存器与与门相隔很远,到达锁存器的时钟与到达与门的时钟有较大的延迟差别,则仍会出现毛刺。 2 如果在电路中,时钟使能信号距离锁存器很近,可能会不满足锁存器的建立时间,会造成锁存器输出出现亚稳态。 如下图分析所示: 图片 上述的右上图中,B点的时钟比A时钟迟到,并且Skew > delay,这种情况下,产生了毛刺。为了消除毛刺,要控制Clock Skew,使它满足Skew ENsetup 一 (D->Q),这种情况下,也产生了毛刺。为了消除毛刺,要控制Clock Skew,使它满足|Skew|< ENsetup一(D->Q)。 1.3 寄存门控 如1.1中提到的,我们还有另外的解决办法,就是用寄存器来寄存EN信号再与上CLK得到GCLK,电路图如下所示: 图片 时序如下所示: 图片 由于DFF输出会delay一个周期,所以除非CLKB上升沿提前CLKA很多,快半个周期,才会出现毛刺,而这种情况一般很难发生。但是,这种情况CLKB比CLKA迟到,是不会出现毛刺的。 当然,如果第一个D触发器不能满足setup时间,还是有可能产生亚稳态。 1.4 门控时钟结构选择 那么到底采用哪一种门控时钟的结构呢?是锁存结构还是寄存结构呢?通过分析,我们大概会选择寄存器结构的门控时钟,这种结构比锁存器结构的问题要少,只需要满足寄存器的建立时间就不会出现问题。 那么实际中是这样么?答案恰恰相反,SOC芯片设计中使用最多的却是锁存结构的门控时钟。 原因是:在实际的SOC芯片中,要使用大量的门控时钟单元。所以通常会把门控时钟做出一个标准单元,有工艺厂商提供。那么锁存器结构中线延时带来的问题就不存在了,因为是做成一个单元,线延时是可控和不变的。而且也可以通过挑选锁存器和增加延时,总是能满足锁存器的建立时间,这样通过工艺厂预先把门控时钟做出标准单元,这些问题都解决了。 那么用寄存器结构也可以达到这种效果,为什么不用寄存器结构呢?那是因为面积!一个DFF是由两个D锁存器组成的,采样D锁存器组成门控时钟单元,可以节省一个锁存器的面积。当大量的门控时钟插入到SOC芯片中时,这个节省的面积就相当可观了。 所以,我们在工艺库中看到的标准门控时钟单元就是锁存结构了: 图片 当然,这里说的是SOC芯片中使用的标准库单元。如果是FPGA或者用RTL实现,个人认为还是用寄存器门控加上setup约束来实现比较稳妥。 门控时钟代码 always@(CLK or CLK_EN) if(!CLK) CLK_TEMP<=CLK_EN assign GCLK=CLK&CLK_TEMP2 RTL中的门控时钟 通常情况下,时钟树由大量的缓冲器和反相器组成,时钟信号为设计中翻转率最高的信号,时钟树的功耗可能高达整个设计功耗40%。 加入门控时钟电路后,由于减少了时钟树的翻转,节省了翻转功耗。同时,由于减少了寄存器时钟引脚的翻转行为,寄存器的内部功耗也减少了。采用门控时钟,可以非常有效地降低设计的功耗,一般情况下能够节省20%~60%的功耗。 那么RTL中怎么才能实现门控时钟呢?答案是不用实现。现在的综合工具比如DC会自动插入门控时钟。如下图所示: 图片 这里有两点需要注意: 插入门控时钟单元后,上面电路中的MUX就不需要了,如果数据D是多bit的(一般都是如此),插入CG后的面积可能反而会减少; 如果D是单bit信号,节省的功耗就比较少,但是如果D是一个32bit的信号,那么插入CG后节省的功耗就比较多了。 这里的决定因素就是D的位宽了,如果D的位宽很小,那么可能插入的CG面积比原来的MUX大很多,而且节省的功耗又很少,这样得不偿失。只有D位宽超过了一定的bit数后,插入CG的收益就比较大。 那么这个临界值是多少呢?不同的工艺可能不一样,但是DC给的默认值是3. 也就是说,如果D的位宽超过了3bit,那么DC就会默认插入CG,这样综合考虑就会有收益。 我们可以通过DC命令: set_clock_gating_style -minimum_bitwidth 4 来控制芯片中,对不同位宽的寄存器是否自动插入CG。一般情况都不会去修改它。 附加:门控时钟的时钟树设计 在时钟树的设计中,门控时钟单元应尽量摆放在时钟源附近,即防止在门控时钟单元的前面摆放大量的时钟缓冲器(Buffer)。 这样,在利用门控时钟电路停时钟时不仅能将该模块中的时钟停掉,也能将时钟树上的时钟缓冲器停止反转,有效地控制了时钟树上的功耗。如图11-24所示,在布局时将门控时钟电路的部件摆放在一起,并摆放在时钟源GCLK附近,停掉时钟后,整个时钟树_上的缓冲器(CTS)和时钟树驱动的模块都停止了翻转。通常的SoC设计中,门控时钟单元会被做成一个硬核或标准单元。 图片 3 RTL 门控时钟编码风格 组合逻辑中,为避免生成锁存器,好的代码风格是if语句都加上else,case语句都加上default。 时序逻辑中,为了让综合工具能够自动生成门控时钟,好的代码风格则是“若无必要,尽量不加else和default”——以减小数据翻转机会。 虽然现在综合工具可以自动插入门控时钟,但是如果编码风格不好,也不能达到自动插入CG的目的。比较下面两种RTL写法: 图片 左边的RTL代码能够成功的综合成自动插入CG的电路; 右边的RTL不能综合成插入CG的电路; 右边电路在d_valid为低时,d_out也会一直变化,其实没有真正的数据有效的指示信号,所以综合不出来插入CG的电路。 需要注意的是,有的前端设计人员,为了仿真的时候看的比较清楚,很容易会写成右边的代码,这样不仅不能在综合的时候自动插入CG来减少功耗;而且增加了d_out的翻转率,进一步增加了功耗。 在不用的时候把数据设成0并不能减少功耗,保持数据不变化才能减少toggle,降低功耗! 所以我们在RTL编写的时候一定要注意。 作为前端设计者,了解这些知识就足够了,如果想深入了解综合的控制,可以去了解 set_clock_gating_style 这个核心控制命令 后记 门控时钟是低功耗技术的一种常规方法,应用已经很成熟了,所以很多人会忽视它的存在和注意事项,也不了解它的具体时序。本文从SOC前端设计的角度详细解释了各种门控时钟的结构和RTL编码需要注意的事项,希望能对设计人员有所帮助。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# SOC优化技术
刘航宇
3年前
0
2,537
3
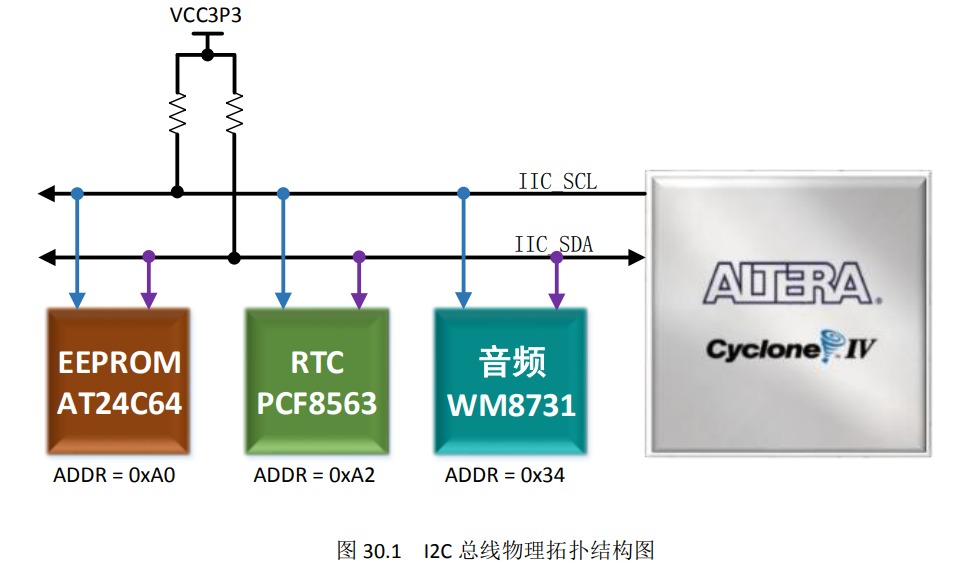
I2C协议及verilog实现-串口读写 EEPROM
I2C 基本概念 I2C 总线(I2C bus,Inter-IC bus)是一个双向的两线连续总线,提供集成电路(ICs)之间的通信线路。I2C 总线是一种串行扩展技术,最早由 Philips 公司推出,广泛应用于电视,录像机和音频设备。I2C 总线的意思是“完成集成电路或功能单元之间信息交换的规范或协议”。Philips 公司推出的 I2C 总线采用一条数据线(SDA),加一条时钟线(SCL)来完成数据的传输及外围器件的扩展。I2C 总线物理拓扑结构如图 30.1 所示。 图片 I2C 总线在物理连接上比较简单,分别由 SDA(串行数据线)和 SCL(串行时钟线)两条总线及上拉电阻组成。通信的原理是通过控制 SCL 和 SDA 的时序,使其满足 I2C 的总线协议从而进行数据的传输。 I2C 总线上的每一个设备都可以作为主设备或者从设备,而且每一个设备都会对应一个唯一的地址(可以从 I2C 器件数据手册得知),主从设备之间就是通过这个地址来确定与哪个器件进行通信。本次实验我们把 FPGA 作为主设备,把挂载在总线上的其他设备(如 EEPROM、PFC8563 等 I2C 器件)作为从设备。 I2C 总线数据传输速率在标准模式下可达 100kbit/s,快速模式下可达 400kbit/s,高速模式下可达 3.4Mbit/s。I2C 总线上的主设备与从设备之间以字节(8 位)为单位进行双向的数据传输。 目录 I2C 基本概念 I2C 协议时序介绍 inout信号原理 I2C 器件地址 I2C 存储器地址 I2C 单字节写时序 I2C 连续写时序(页写时序) I2C 单字节读时序 I2C 连续读时序(页读取) I2C 读写器件控制程序 本节小结 I2C 协议时序介绍 I2C 协议整体时序图如图 30.2 所示 图片 I2C 协议整体时序说明如下: (1) 总线空闲状态:SDA 为高电平,SCL 为高电平; (2) I2C 协议起始位:SCL 为高电平时,SDA 出现下降沿,产生一个起始位; (3) I2C 协议结束位:SCL 为高电平时,SDA 出现上升沿,产生一个结束位; (4) I2C 读写数据状态:主要包括数据的串行输出输入和数据接收方对数据发送方的响应信号。具体时序如图 30.3 所示。 图片 当 I2C 主机(后面简称主机)向 I2C 从机(后面简称从机)写入数据时,SDA 上的每一位数据在 SCL 的高电平期间被写入从机中。从主机角度来看,需要在 SCL 低电平期间改变要写入的数据。而当主机读取从机中数据时,从机在 SCL 低电平期间将数据输出到 SDA 总线上,在 SCL 的高电平期间保持数据稳定,从主机角度来看,需要在 SCL 的高电平期间将 SDA 线上的数据读取并存储。 每当一个字节的数据或命令传输完成时,数据接收方都会向发送方响应一位应答位。在响应应答位时,数据发出方将 SDA 总线设置为三态输入,由于 I2C 总线上都有上拉电阻,因此此时总线默认为高电平,若数据接收方正确接收到数据,则数据接收方将 SDA 总线拉低,以示正确应答。例如当主机向从机写入数据或命令时,每个字节都需要从机产生应答信号以告诉主机此次的数据或命令是否成功被写入。所以,当主机将一字节的数据或命令传出后,会将 SDA 信号设置为三态输入,等待从机应答(等待 SDA 被从机拉低为低电平),若从机正确应答,表明当前数据或命令传输成功,可以结束或开始下一个数据或命令的传输,否则表明数据或命令写入失败,主机就可以决定是否放弃写入或者重新发起写入。 inout信号原理 图片 图片 I2C 器件地址 每个 I2C 器件都有一个器件地址,有的器件地址在出厂时地址就设置好了,用户不可以更改(例如 OV7670 器件地址为固定的 0x42),有的确定了几位,剩下几位由硬件确定(比如常见的 I2C 接口的 EEPROM 存储器,留有 3 个控制地址的引脚,由用户自己在硬件设计时确定)。严格讲,主机不是直接向从机发送地址,而是主机往总线上发送地址,所有的从机都能接收到主机发出的地址,然后每个从机都将主机发出的地址与自己的地址比较,如 果匹配上了,这个从机就会向主机发出一个响应信号。主机收到响应信号后,开始向总线上发送数据,与这个从机的通讯就建立起来了。如果主机没有收到响应信号,则表示寻址失败。 通常情况下,主从器件的角色是确定的,也就是说从机一直工作在从机模式。不同器件定义地址的方式是不同的,有的是软件定义,有的是硬件定义。例如某些单片机的I2C 接口作为从机时,其器件地址是可以通过软件修改从机地址寄存器确定的。而对于一些其他器件,如 CMOS 图像传感器、EEPROM 存储器,其器件地址在出厂时就已经设定好了,具体值可以在对应的数据手册中查到。 对于 AT24C64 这样一颗 EEPROM 器件,其器件地址为 1010 加 3 位的片选信号。3位片选信号由硬件连接决定。例如 SOIC 封装的该芯片 PIN1、PIN2、PIN3 为片选地址。当硬件电路上分别将这三个 pin 连接到 GND 或 VCC 时,就可以设置不同的片选地址。I2C 协议在进行数据传输时,主机需要首先向总线上发出控制命令,其中,控制命令就包含了从机地址/片选信号+读写控制。然后等待从机响应。如图 30.4 所示为 I2C 控制命令传输的数据格式。 图片 I2C 传输时,按照从高到低的位序进行传输。控制字节的最低位为读写控制位,当该位为 0 时表示主机对从机进行写操作,当该位为 1 时表示主机对从机进行读操作。例如,当需要对片选地址为 100 的 AT24LC64 发起写操作,则控制字节应该为 1010_100_0。若进行读操作,则控制字节应该为 1010_100_1。 I2C 存储器地址 每个支持 I2C 协议的器件,内部总会有一些可供读写的寄存器或存储器,例如,对于我们用到的 EEPROM 存储器,内部就是顺序编址的一系列存储单元。对于我们常接触的 CMOS 摄像头如 OV7670(OV7670 的该接口叫 SCCB 接口,其实质也是一种特殊的 I2C协议,可以直接兼容 I2C 协议),其内部就是一系列编址的可供读写的寄存器。因此,我们要对一个器件中的存储单元(寄存器和存储器以下简称存储单元)进行读写,就必须要能够指定存储单元的地址。I2C 协议设计了有从机存储单元寻址地址段,该地址段为一个字或两个字节长度,在主机确认收到从机返回的控制字节响应后由主机发出。地址段长度视不同的器件类型,长度不同,例如同是 EEPROM 存储器,AT24C04 的址段长度为一个字节,而 AT24C64 的地址段长度为两个字节。具体是一个字节还是两个字节,与器件的存储单元数量有关。如图 30.5 和图 30.6 分别为 1 字节地址和 2 字节地址器件的地址分布图,其中 1 字节地址的器件是以内存为 1kbit 的 EEPROM 存储器 AT24C01 举例,2 字节地址的器件是以内存为 64kbit 的 EEPROM 存储器 AT24C64 举例的。 图片 I2C 单字节写时序 根据前面讲的,不同器件,I2C 器件地址字节不同,这样对于 I2C 单字节写时序就会有所差别,图 30.7 和图 30.8 分别为 1 字节地址段器件和 2 字节地址段器件单字节写时序图。 图片 图片 根据时序图,从主机角度来描述一次写入单字节数据过程如下: a. 主机设置 SDA 为输出; b. 主机发起起始信号; c. 主机传输器件地址字节,其中最低位为 0,表明为写操作; d. 主机设置 SDA 为三态门输入,读取从机应答信号; e. 读取应答信号成功,主机设置 SDA 为输出,传输 1 字节地址数据; f. 主机设置 SDA 为三态门输入,读取从机应答信号; g. 读取应答信号成功,对于两字节地址段器件,传输地址数据低字节,对于 1 字节地址段器件,主机设置 SDA 为输出,传输待写入的数据; h. 设置 SDA 为三态门输入,读取从机应答信号,对于两字节地址段器件,接着步骤 i;对于 1 字节地址段器件,直接跳转到步骤 k; i. 读取应答信号成功,主机设置 SDA 为输出,传输待写入的数据(对于两字节地址段器件); j. 设置 SDA 为三态门输入,读取从机应答信号(两字节地址段器件); k. 读取应答信号成功,主机产生 STOP 位,终止传输。 I2C 连续写时序(页写时序) 注:I2C 连续写时序仅部分器件支持。 连续写是主机连续写多个字节数据到从机,这个和单字节写操作类似,连续多字节写操作也是分为 1 字节地址段器件和 2 字节地址段器件的写操作,图 30.9 和图 30.10 分别为 1 字节地址段器件和 2 字节地址段器件连续多字节写时序图。 图片 根据时序图,从主机角度来描述一次写入多字节数据过程如下: a. 主机设置 SDA 为输出; b. 主机发起起始信号; c. 主机传输器件地址字节,其中最低位为 0,表明为写操作; d. 主机设置 SDA 为三态门输入,读取从机应答信号; e. 读取应答信号成功,主机设置 SDA 为输出,传输 1 字节地址数据; f. 主机设置 SDA 为三态门输入,读取从机应答信号; g. 读取应答信号成功后,主机设置 SDA 为输出,对于两字节地址段器件,传输低字节地址数据,对于 1 字节地址段器件,传输待写入的第 1 个数据 h. 设置 SDA 为三态门输入,读取从机应答信号,对于两字节地址段器件,接着步骤 i;对于 1 字节地址段器件,直接跳转到步骤 k; i. 读取应答信号成功后,主机设置 SDA 为输出,传输待写入的第 1 个数据(两字节地址段器件); j. 设置 SDA 为三态门输入,读取从机应答信号(两字节地址段器件); k. 读取应答信号成功后,主机设置 SDA 为输出,传输待写入的下一个数据; l. 设置 SDA 为三态门输入,读取从机应答信号;n 个数据被写完,转到步骤 m,若数据未被写完,转到步骤 k; m. 读取应答信号成功后,主机产生 STOP 位,终止传输。 注:对于 AT24Cxx 系列的 EEPROM 存储器,一次可写入的最大长度为 32 字节。 I2C 单字节读时序 同样的,I2C 读操作时序根据不同 I2C 器件具有不同的器件地址字节数,单字节读操作分为 1 字节地址段器件单节数据读操作和 2 字节地址段器件单节数据读操作。图30.11 和图 30.12 分别为 不同情况的时序图。 图片 根据时序图,从主机角度描述一次读数据过程,如下: a. 主机设置 SDA 为输出; b. 主机发起起始信号; c. 主机传输器件地址字节,其中最低位为 0,表明为写操作; d. 主机设置 SDA 为三态门输入,读取从机应答信号; e. 读取应答信号成功,主机设置 SDA 输出,传输 1 字节地址数据; f. 主机设置 SDA 为三态门输入,读取从机应答信号; g. 读取应答信号成功,主机设置 SDA 输出,对于两字节地址段器件,传输低字节地址数据;对于 1 字节地址段器件,无此步骤,直接跳转到步骤 h; h. 主机发起起始信号; i. 主机传输器件地址字节,其中最低位为 1,表明为读操作; j. 设置 SDA 为三态门输入,读取从机应答信号; k. 读取应答信号成功,主机设置 SDA 为三态门输入,读取 SDA 总线上的一个字节的数据; l. 产生无应答信号(高电平)(无需设置为输出高电平,因为总线会被自动拉高);m. 主机产生 STOP 位,终止传输。 I2C 连续读时序(页读取) 连续读是主机连续从从机读取多个字节数据,这个和单字节读操作类似,连续多字节读操作也是分为 1 字节地址段器件和 2 字节地址段器件的读操作,图 30.13 和图 30.14 分别为 1 字节地址段器件和 2 字节地址段器件连续多字节读时序图。 图片 根据时序图,从主机角度描述多字节数据读取过程如下: a. 主机设置 SDA 为输出 b. 主机发起起始信号 c. 主机传输器件地址字节,其中最低位为 0,表明为写操作。 d. 主机设置 SDA 为三态门输入,读取从机应答信号。 e. 读取应答信号成功,主机设置 SDA 输出,传输 1 字节地址数据 f. 主机设置 SDA 为三态门输入,读取从机应答信号。 g. 读取应答信号成功,主机设置 SDA 输出,对于两字节地址段器件,传输低字节地址数据;对于 1 字节地址段器件,无此步骤;直接跳转到步骤h; h. 主机发起起始信号; i. 主机传输器件地址字节,其中最低位为 1,表明为读操作; j. 设置 SDA 为三态门输入,读取从机应答信号; k. 设置 SDA 为三态门输入,读取 SDA 总线上的第 1 个字节的数据; l. 主机设置 SDA 输出,发送一位应答信号; m. 设置 SDA 为三态门输入,读取 SDA 总线上的下一个字节的数据;若 n 个字节数据读完成,跳转到步骤 n,若数据未读完,跳转到步骤 l;(对于 AT24Cxx,一次读取长度最大为 32 字节,即 n 不大于 32) n. 主机设置 SDA 输出,产生无应答信号(高电平)(无需设置为输出高电平,因为总线会被自动拉高); o. 主机产生 STOP 位,终止传输。 I2C 读写器件控制程序 通过上述的讲述,对 I2C 读写器件数据时序有了一定的了解,下面将开始进行控制程序的设计。根据上面 I2C 的基本概念中有关读写时 SDA 与 SCL 时序,不管对于从机还是主机,SDA 上的每一位数据在 SCL 的高电平期间保持不变,而数据的改变总是在 SCL的低电平期间发生。因此,我们可以选用 2 个标志位对时钟 SCL 的高电平和低电平进行标记,如下图所示:scl_high 对 SCL 高电平期间进行标志,scl_low 对 SCL 低电平期间进行标志。这样就可以在 scl_high 有效时读 SDA 数据,在 scl_low 有效时改变数据。scl_high和 scl_low 产生的时序图如图 30.15 所示。 图片 在本实验中,时钟信号 SCL 采用计数器方法产生,计数器最大计数值为系统时钟频率除以 SCL 时钟频率,即:SCL_CNT_M = SYS_CLOCK/SCL_CLOCK。对于 scl_high 和 scl_low则只需要分别在计数到四分之一的最大值和四分之三的最大值时产生标志位即可,具体的时钟信号 SCL 和标志信号 scl_high、scl_low 产生实现代码如下: //系统时钟采用 50MHz parameter SYS_CLOCK = 50_000_000; //SCL 总线时钟采用 400kHz parameter SCL_CLOCK = 400_000; //产生时钟 SCL 计数器最大值 localparam SCL_CNT_M = SYS_CLOCK/SCL_CLOCK; reg [15:0]scl_cnt; //SCL 时钟计数器 reg scl_vaild; //I2C 非空闲时期 reg scl_high; //SCL 时钟高电平中部标志位 reg scl_low; //SCL 时钟低电平中部标志位 //I2C 非空闲时期 scl_vaild 的产生 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) scl_vaild <= 1'b0; else if(Wr | Rd) scl_vaild <= 1'b1; else if(Done) scl_vaild <= 1'b0; else scl_vaild <= scl_vaild; end //scl 时钟计数器 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) scl_cnt <= 16'd0; else if(scl_vaild)begin if(scl_cnt == SCL_CNT_M - 1) scl_cnt <= 16'd0; else scl_cnt <= scl_cnt + 16'd1; end else scl_cnt <= 16'd0; end //scl 时钟,在计数器值到达最大值一半和 0 时翻转 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Scl <= 1'b1; else if(scl_cnt == SCL_CNT_M >>1) Scl <= 1'b0; else if(scl_cnt == 16'd0) Scl <= 1'b1; else Scl <= Scl; end //scl 时钟高低电平中部标志位 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) scl_high <= 1'b0; else if(scl_cnt == (SCL_CNT_M>>2)) scl_high <= 1'b1; else scl_high <= 1'b0; end //scl 时钟低电平中部标志位 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) scl_low <= 1'b0; else if(scl_cnt == (SCL_CNT_M>>1)+(SCL_CNT_M>>2)) scl_low <= 1'b1; else scl_low <= 1'b0; end上述代码中 Wr 和 Rd 信号为 I2C 进行一次写和读操作的门控使能信号,Done 信号为一次I2C写和读操作完成标志位。(SCL_CNT_M>>2)和(SCL_CNT_M>>1)+(SCL_CNT_M>>2)分别为 1/2 的 SCL_CNT_M 和 3/4 的 SCL_CNT_M 的计数值。 在 SCL 时钟总线以及其高低电平标志位产生完成后,接下来的事情就是 SDA 数据线的产生,这个需要根据具体的读写操作时序完成。本实验主要采用状态机实现,根据上面讲述的读写数据的时序关系,设计了如图 30.16 所示的状态转移图,其状态机状态编码采用独热编码,若需要改变状态编码形式,只需改变程序中的 parameter 定义即可。 图片 根据上面 I2C 基本概念可知,不同的器件其寄存器地址字节数分为 1 字节或和 2 字节地址段,并且有些 I2C 器件是支持多字节的数据读写,所以在设计时考虑到该 I2C 控制器的通用性,我们将设计寄存器地址字节和读取数据个数均可自行设置的 I2C 控制器,用户可根据自己的实际应用情况设置选择与器件对应的寄存器地址字节数或是读写数据的字节数。寄存器地址字节数的可变主要是通过一个计数器对字节数进行计数,当计数值达到指定值后跳转到下一状态,具体的可参见代码。 在状态机中,从主机角度来看,SDA 数据线上在写控制、写数据、读控制状态过程是需要串行输出数据,而在读数据状态过程是需要串行输入数据。根据数据在时钟高电平期间保持不变,改变数据在低电平时期的规则,本设计对时钟信号的高低电平进行计数,从而在指定的计数值进行输出或读取数据实现数据的串行输出和串行输入。串行输出和串行输入数据采用任务的形式进行表示,便于在主状态机中多次的调用。图 30.17为计数的过程以及特定状态变化的时序图,这里的特定状态主要是指读/写控制、读/写地址和读/写数据状态。 图片 图 30.17 中计数器 halfbit_cnt 和数据接收方对发送的响应检测标志位 ack 以及串行输出、输入数据任务的具体代码如下: //sda 串行接收与发送时 scl 高低电平计数器 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) halfbit_cnt <= 8'd0; else if((main_state == WR_CTRL)|| (main_state == WR_WADDR)|| (main_state == WR_DATA)|| (main_state == RD_CTRL)|| (main_state == RD_DATA))begin if(scl_low | scl_high)begin if(halfbit_cnt == 8'd17) halfbit_cnt <= 8'd0; else halfbit_cnt <= halfbit_cnt + 8'd1; end else halfbit_cnt <= halfbit_cnt; end else halfbit_cnt <= 8'd0; end //数据接收方对发送的响应检测标志位 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) ack <= 1'b0; else if((halfbit_cnt == 8'd16)&&scl_high&&(Sda==1'b0)) ack <= 1'b1; else if((halfbit_cnt == 8'd17)&&scl_low) ack <= 1'b0; else ack <= ack; end //输出串行数据任务 task send_8bit_data; if(scl_high && (halfbit_cnt == 8'd16)) FF <= 1; else if(halfbit_cnt < 8'd17)begin sda_reg <= sda_data_out[7]; if(scl_low) sda_data_out <= {sda_data_out[6:0],1'b0}; else sda_data_out <= sda_data_out; end else ; endtask //串行数据输入任务 task receive_8bit_data; if(scl_low && (halfbit_cnt == 8'd15)) FF <= 1; else if((halfbit_cnt < 8'd15))begin if(scl_high) sda_data_in <= {sda_data_in[6:0],Sda}; else begin sda_data_in <= sda_data_in; end end else ; endtask对于计数器 halfbit_cnt 只在写控制、写数据、读控制、读数据状态下才进行计数,其他状态为零。代码中 FF 是进行串行输出或输入任务的标志位,当 FF 为 1 时表示退出任务,FF 为 0 时表示进入任务。这样便于在状态机中对任务的调用,以及在指定的时间退出任务。 接下来就是主状态机的设计,主状态机的状态转移图上面已经给出,具体转移过程是依据 I2C 读写时序进行的,代码如下: //主状态机 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n)begin main_state <= IDLE; sda_reg <= 1'b1; W_flag <= 1'b0; R_flag <= 1'b0; Done <= 1'b0; waddr_cnt <= 2'd1; wdata_cnt <= 8'd1; rdata_cnt <= 8'd1; end else begin case(main_state) IDLE:begin sda_reg <= 1'b1; W_flag <= 1'b0; R_flag <= 1'b0; Done <= 1'b0; waddr_cnt <= 2'd1; wdata_cnt <= 8'd1; rdata_cnt <= 8'd1; if(Wr)begin main_state <= WR_START; W_flag <= 1'b1; end else if(Rd)begin main_state <= WR_START; R_flag <= 1'b1; end else main_state <= IDLE; end WR_START:begin if(scl_low)begin main_state <= WR_CTRL; sda_data_out <= wr_ctrl_word; FF <= 1'b0; end else if(scl_high)begin sda_reg <= 1'b0; main_state <= WR_START; end else main_state <= WR_START; end WR_CTRL:begin if(FF == 1'b0) send_8bit_data; else begin if(ack == 1'b1) begin//收到响应 if(scl_low)begin main_state <= WR_WADDR; FF <= 1'b0; if(Wdaddr_num == 2'b1) sda_data_out <= Word_addr[7:0]; else sda_data_out <= Word_addr[15:8]; end else main_state <= WR_CTRL; end else//未收到响应 main_state <= IDLE; end end WR_WADDR:begin if(FF == 1'b0) send_8bit_data; else begin if(ack == 1'b1) begin//收到响应 if(waddr_cnt == Wdaddr_num)begin if(W_flag && scl_low)begin main_state <= WR_DATA; sda_data_out <= Wr_data; waddr_cnt <= 2'd1; FF <= 1'b0; end else if(R_flag && scl_low)begin main_state <= RD_START; sda_reg <= 1'b1; end else main_state <= WR_WADDR; end else begin if(scl_low)begin waddr_cnt <= waddr_cnt + 2'd1; main_state <= WR_WADDR; sda_data_out <= Word_addr[7:0]; FF <= 1'b0; end else main_state <= WR_WADDR; end end else//未收到响应 main_state <= IDLE; end end WR_DATA:begin if(FF == 1'b0) send_8bit_data; else begin if(ack == 1'b1) begin//收到响应 if(wdata_cnt == Wrdata_num)begin if(scl_low)begin main_state <= STOP; sda_reg <= 1'b0; wdata_cnt <= 8'd1; end else main_state <= WR_DATA; end else begin if(scl_low)begin wdata_cnt <= wdata_cnt + 8'd1; main_state <= WR_DATA; sda_data_out <= Wr_data; FF <= 1'b0; end else main_state <= WR_DATA; end end else//未收到响应 main_state <= IDLE; end end RD_START:begin if(scl_low)begin main_state <= RD_CTRL; sda_data_out <= rd_ctrl_word; FF <= 1'b0; end else if(scl_high)begin main_state <= RD_START; sda_reg <= 1'b0; end else main_state <= RD_START; end RD_CTRL:begin if(FF == 1'b0) send_8bit_data; else begin if(ack == 1'b1) begin//收到响应 if(scl_low)begin main_state <= RD_DATA; FF <= 1'b0; end else main_state <= RD_CTRL; end else//未收到响应 main_state <= IDLE; end end RD_DATA:begin if(FF == 1'b0) receive_8bit_data; else begin if(rdata_cnt == Rddata_num)begin sda_reg <= 1'b1; if(scl_low)begin main_state <= STOP; sda_reg <= 1'b0; end else main_state <= RD_DATA; end else begin sda_reg <= 1'b0; if(scl_low)begin rdata_cnt <= rdata_cnt + 8'd1; main_state <= RD_DATA; FF <= 1'b0; end else main_state <= RD_DATA; end end end STOP:begin//结束操作 if(scl_high)begin sda_reg <= 1'b1; main_state <= IDLE; Done <= 1'b1; end else main_state <= STOP; end default: main_state <= IDLE; endcase end end主状态机完成后,I2C 控制器设计的大块就解决了,剩下的就是 SDA 数据线的输出了,该数据线采用三态使能输出,具体代码如下: assign Sda = sda_en ? sda_reg : 1'bz;对于使能信号 sda_en 按照上面的时序关系图可知,该信号在不同的状态,其高低电平变化的时刻是有差别的,比如在开始和结束状态,它是一直为高电平的,在写控制、写数据、读控制状态,它是在串行输出一字节数据期间(即 halfbit_cnt < 16 时)为高电平,之外的一个数据为位低电平,而在读数据状态时串行输入一字节数据期间(即halfbit_cnt < 16 时)为低电平电平,之外的一个数据位为高电平。具体代码如下: //SDA 三态使能信号 sda_en always@(*) begin case(main_state) IDLE: sda_en = 1'b0; WR_START,RD_START,STOP: sda_en = 1'b1; WR_CTRL,WR_WADDR,WR_DATA,RD_CTRL: if(halfbit_cnt < 16) sda_en = 1'b1; else sda_en = 1'b0; RD_DATA: if(halfbit_cnt < 16) sda_en = 1'b0; else sda_en = 1'b1; default: sda_en = 1'b0; endcase end本实验设计考虑到了多字节数据的读取情况,所以增加了数据读取和数据写入时的 有效标志位信号。主要是标志读取数据时数据有效时刻和写数据时提供待写入数据时刻。 具体代码如下: //写数据有效标志位 assign Wr_data_vaild = ((main_state==WR_WADDR)&& (waddr_cnt==Wdaddr_num)&& (W_flag && scl_low)&& (ack == 1'b1))|| ((main_state == WR_DATA)&& (ack == 1'b1)&&(scl_low)&& (wdata_cnt != Wrdata_num)); //读数据有效标志位前寄存器 assign rdata_vaild_r = (main_state == RD_DATA) &&(halfbit_cnt == 8'd15)&&scl_low; //读出数据有效标志位 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Rd_data_vaild <= 1'b0; else if(rdata_vaild_r) Rd_data_vaild <= 1'b1; else Rd_data_vaild <= 1'b0; end //读出的有效数据 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Rd_data <= 8'd0; else if(rdata_vaild_r) Rd_data <= sda_data_in; else Rd_data <= Rd_data; end到目前为止,整个 I2C 控制器的设计就完成了,接下来就进入仿真环节,我们需要EEPROM 的仿真模型进行仿真,这样能更好的检验 I2C 控制器设计的是否存在问题,以便后面进行优化改进。本实验采用的是镁光官网提供的 EEPROM 仿真模型,具体下载网 址 为 http://www.microchip.com/zh/design-centers/memory/serial-eeprom/verilog-ibis-models,我们选择两个具有代表性的模型进行仿真,分别为 1 字节寄存器地址段的 24LC04B 和 2 字节寄存器地址段的 24LC64 仿真模型,利用这两个模型对我们设计的 I2C 控制器进行仿真。如图 30.18 为仿真验证的结构框图。 图片 这里我们对 1 字节寄存器地址段的 24LC04B 和 2 字节寄存器地址段的 24LC64 仿真模型的器件地址{A3,A2,A1}分别设置为 3’b001 和 3’b000,仿真时为了能分别对不同型号的模型进行仿真,在编写的 testbench 文件中采用了申明方法去选择当前使用哪个模型进行仿真,具体代码如下: `timescale 1ns/1ns `define CLK_PERIOD 20 //仿真模型选择 //`define TEST_M24LC64 //24LC64 `define TEST_M24LC04 //24LC04 module I2C_tb; reg Clk; //系统时钟 reg Rst_n; //系统复位信号 reg [15:0] Word_addr; //I2C 器件寄存器地址 reg Wr; //I2C 器件写使能 reg [7:0] Wr_data; //I2C 器件写数据 wire Wr_data_vaild;//I2C 器件写数据有效标志位 reg Rd; //I2C 器件读使能 wire[7:0] Rd_data; //I2C 器件读数据 wire Rd_data_vaild;//I2C 器件读数据有效标志位 wire Scl; //I2C 时钟线 wire Sda; //I2C 数据线 wire Done; //对 I2C 器件读写完成标识位 localparam NUM = 6'd4; //单次读写数据字节数 `ifdef TEST_M24LC64 localparam DevAddr = 3'b000; //I2C 器件的器件地址 localparam WdAr_NUM= 2; //I2C 器件的存储器地址字节数 `elsif TEST_M24LC04 localparam DevAddr = 3'b001; //I2C 器件的器件地址 localparam WdAr_NUM= 1; //I2C 器件的存储器地址字节数 `endif I2C I2C( .Clk(Clk), .Rst_n(Rst_n), .Rddata_num(NUM), .Wrdata_num(NUM), .Wdaddr_num(WdAr_NUM), .Device_addr(DevAddr), .Word_addr(Word_addr), .Wr(Wr), .Wr_data(Wr_data), .Wr_data_vaild(Wr_data_vaild), .Rd(Rd), .Rd_data(Rd_data), .Rd_data_vaild(Rd_data_vaild), .Scl(Scl), .Sda(Sda), .Done(Done) ); `ifdef TEST_M24LC64 M24LC64 M24LC64( .A0(1'b0), .A1(1'b0), .A2(1'b0), .WP(1'b0), .SDA(Sda), .SCL(Scl), .RESET(!Rst_n) ); `elsif TEST_M24LC04 M24LC04B M24LC04( .A0(1'b1), .A1(1'b0), .A2(1'b0), .WP(1'b0), .SDA(Sda), .SCL(Scl), .RESET(!Rst_n) ); `endif //系统时钟产生 initial Clk = 1'b1; always #(`CLK_PERIOD/2)Clk = ~Clk; initial begin Rst_n = 0; Word_addr = 0; Wr = 0; Wr_data = 0; Rd = 0; #(`CLK_PERIOD*200 + 1) Rst_n = 1; #200; `ifdef TEST_M24LC64 //仿真验证 24LC64 模型 //写入 20 组数据 Word_addr = 0; Wr_data = 0; repeat(20)begin Wr = 1'b1; #(`CLK_PERIOD); Wr = 1'b0; repeat(NUM)begin //在写数据有效前给待写入数据 @(posedge Wr_data_vaild) Wr_data = Wr_data + 1; end @(posedge Done); #2000; Word_addr = Word_addr + NUM; end #2000; //读出刚写入的 20 组数据 Word_addr = 0; repeat(20)begin Rd = 1'b1; #(`CLK_PERIOD); Rd = 1'b0; @(posedge Done); #2000; Word_addr = Word_addr + NUM; end `elsif TEST_M24LC04 //仿真验证 24LC04 模型 //写入 20 组数据 Word_addr = 100; Wr_data = 100; repeat(20)begin Wr = 1'b1; #(`CLK_PERIOD); Wr = 1'b0; repeat(NUM)begin //在写数据有效前给待写入数据 @(posedge Wr_data_vaild) Wr_data = Wr_data + 1; end @(posedge Done); #2000; Word_addr = Word_addr + NUM; end #2000; //读出刚写入的 20 组数据 Word_addr = 100; repeat(20)begin Rd = 1'b1; #(`CLK_PERIOD); Rd = 1'b0; @(posedge Done); #2000; Word_addr = Word_addr + NUM; end `endif #5000; $stop; end endmodule在 testbench 文件中,通过对 EEPROM 模型进行 20 写操作,每次写字节数为NUM,然后对 EEPROM 模型在刚写入数据的地址段进行读操作,通过比较读出和写入的数据验证 I2C 控制器设计是否正确。这里分别通过申明选择 TEST_M24LC64 或TEST_M24LC04 来作为当前的仿真模型。如图 30.19 所示为 2 字节地址的 EEPROM模型 24LC64 仿真结果。图 30.20 和图 30.21 分别为型号 24LC64 仿真模型写操作时序和读操作时序放大后的波形图。 图片 图片 同样的方式选择 24LC04 型号 EEPROM 模型进行仿真,如图 30.22 所示为 1 字节地址的 EEPROM 模型 24LC604 仿真结果。图 30.23 和图 30.24 分别为型号24LC604 仿真模型写操作时序和读操作时序放大后的波形图。 图片 通过观察图 30.21 和图 30.24 的时序波形发现,在读操作时序结果中,读出的数据中某些位是高阻态,仔细观察波形可知,高阻态的位置正好是需要输出高电平的位置,这个的原因是 EEPROM 的仿真模型是完全与实际的器件是一样的,对于器件来说,只在输出 0 时将数据线拉低,而在高阻态或本应该为高电平的时刻都是设置为高阻态的,这个在仿真模型的代码中也有体现,具体体现这一点的代码如下: bufif1 (SDA, 1'b0, SDA_DriveEnableDlyd);图片 其中,器件地址包括器件的地址字节数和 3 位的器件地址,具体分配如下: 图片 功能码主要是区分是写数据操作还是读数据操作,为了方便,我们直接规定,功能码为 0xf1 表示写数据操作,0xf2 表示读数据操作;起始地址是我们要读写数据的第一个地址;数据字节数表示要写入或读取的数据的字节个数,后面的数据 1 到数据n 表示要写入的 n 个数据,对于读操作没有这部分。如图 30.25 为该实验整体的设计框图。 图片 有关串口发送和接收以及 fifo 模块在前面章节都已经进行了讲解,这里就不重复讲解了,这里重点讲解命令解析模块的设计,命令解析模块的主要作用是对串口接收的数据进行解析,通过对接收的数据进行解析分析判断出是进行何种操作。根据我们自己规定的数据协议,进行如下的设计,首先我们将串口发送的数据的前 4 个数据存入一个缓冲区数据内,通过对功能码识别判断是写操作还是读操作,如果是写操作,就将后面待写入的数据存入 fifo 中;同时将器件地址、地址字节数、起始地址、数据字节数赋值给 I2C 对应的信号线;如果是读操作,就在前 4 个字节接收完成后将器件地址、地址字节数、起始 地址、数据字节数赋值给 I2C 对应的信号线,同时给 I2C 控制器模块的读使能给一个时钟周期的门控信号,使能 I2C 的读操作。读出的数据同样也是先存放在另外一个 fifo 中,然后送给串口发送模块发出。具体实现代码如下: module cmd_analysis( Clk, Rst_n, Rx_done, Rx_data, Wfifo_req, Wfifo_data, Rddata_num, Wrdata_num, Wdaddr_num, Device_addr, Word_addr, Rd ); input Clk; //系统时钟 input Rst_n; //系统复位 input Rx_done; //串口接收一字节数据完成 input[7:0] Rx_data; //串口接收一字节数据 output reg Wfifo_req; //写 fifo 请求信号 output reg[7:0] Wfifo_data; //写 fifo 数据 output reg[5:0] Rddata_num; //I2C 总线连续读取数据字节数 output reg[5:0] Wrdata_num; //I2C 总线连续读取数据字节数 output reg[1:0] Wdaddr_num; //I2C 器件数据地址字节数 output reg[2:0] Device_addr; //EEPROM 器件地址 output reg[15:0] Word_addr; //EEPROM 寄存器地址 output reg Rd; //EEPROM 读请求信号 reg [7:0] buff_data[4:0];//串口接收数据缓存器 //串口接收数据计数器 reg [7:0]byte_cnt; always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) byte_cnt <= 8'd0; else if(Rx_done && byte_cnt==8'd4)begin if(buff_data[1]==8'hf2) //读数据指令 byte_cnt <= 8'd0; else if(buff_data[1]==8'hf1) //写数据指令 byte_cnt <= byte_cnt + 8'd1; else byte_cnt <= 8'd0; //错误指令 end else if(Rx_done)begin if(byte_cnt == 8'd4 + buff_data[4]) byte_cnt <= 8'd0; else byte_cnt <= byte_cnt + 8'd1; end else byte_cnt <= byte_cnt; end //串口接收数据缓存器 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n)begin buff_data[0] <= 8'h00; buff_data[1] <= 8'h00; buff_data[2] <= 8'h00; buff_data[3] <= 8'h00; buff_data[4] <= 8'h00; end else if(Rx_done && byte_cnt<5) buff_data[byte_cnt] <= Rx_data; else ; end //写 fifo 请求信号 Wfifo_req always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Wfifo_req <= 1'b0; else if(byte_cnt >8'd4 && Rx_done) Wfifo_req <= 1'b1; else Wfifo_req <= 1'b0; end //写 fifo 数据 Wfifo_data always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Wfifo_data <= 8'd0; else if(byte_cnt > 8'd4 && Rx_done) Wfifo_data <= Rx_data; else Wfifo_data <= Wfifo_data; end //EEPROM 读请求信号 Rd always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) Rd <= 1'b0; else if(byte_cnt == 8'd4 && Rx_done && buff_data[1]==8'hf2) Rd <= 1'b1; else Rd <= 1'b0; end //指令完成标志位 reg cmd_flag; always@(posedge Clk or negedge Rst_n) begin if(!Rst_n) cmd_flag <= 1'b0; else if((byte_cnt == 8'd4)&& Rx_done) cmd_flag <= 1'b1; else cmd_flag <= 1'b0; end //EEPROM 读写数据、寄存器地址字节数,器件地址,寄存器地址 always@(posedge Clk or negedge Rst_n) begin if(!Rst_n)begin Rddata_num <= 6'd0; Wrdata_num <= 6'd0; Wdaddr_num <= 2'd0; Device_addr <= 3'd0; Word_addr <= 16'd0; end else if(cmd_flag == 1'b1)begin Rddata_num <= buff_data[4][5:0]; Wrdata_num <= buff_data[4][5:0]; Wdaddr_num <= buff_data[0][5:4]; Device_addr <= buff_data[0][2:0]; Word_addr <= {buff_data[2],buff_data[3]}; end else ; end endmodule下面编写 testbench 测试文件对设计的命令解析模块进行仿真验证,该仿真主要是分别模拟发送写数据操作和读数据操作指令,来观察相应的输出时序波形结果。通过仿真时序结果可以对该模块进行优化改进,具体的 testbench 文件如下: `timescale 1ns/1ns `define CLK_PERIOD 20 module cmd_analysis_tb; reg Clk; reg Rst_n; reg Rx_done; reg [7:0] Rx_data; wire Wfifo_req; wire[7:0] Wfifo_data; wire[5:0] Rddata_num; wire[5:0] Wrdata_num; wire[1:0] Wdaddr_num; wire[2:0] Device_addr; wire[15:0] Word_addr; wire Rd; reg [15:0] addr; reg [7:0] data_num; reg [7:0] wr_data; reg [39:0] wdata_cmd; reg [39:0] rdata_cmd; cmd_analysis cmd_analysis( .Clk(Clk), .Rst_n(Rst_n), .Rx_done(Rx_done), .Rx_data(Rx_data), .Wfifo_req(Wfifo_req), .Wfifo_data(Wfifo_data), .Rddata_num(Rddata_num), .Wrdata_num(Wrdata_num), .Wdaddr_num(Wdaddr_num), .Device_addr(Device_addr), .Word_addr(Word_addr), .Rd(Rd) ); //写 FIFO 模块例化 fifo_wr wr( .clock(Clk), .data(Wfifo_data), .rdreq(), .wrreq(Wfifo_req), .empty(), .full(), .q(), .usedw() ); //系统时钟产生 initial Clk = 1'b1; always #(`CLK_PERIOD/2)Clk = ~Clk; initial begin Rst_n = 0; Rx_done = 0; Rx_data = 0; addr = 0; data_num = 0; wr_data = 0; wdata_cmd = 0; rdata_cmd = 0; #(`CLK_PERIOD*200 + 1) Rst_n = 1; #200; addr = 0; data_num = 4; wr_data = 0; send_uart_data_wr; //写数据 #500; send_uart_data_rd; //读数据 #500; addr = 4; data_num = 8; wr_data = 20; send_uart_data_wr; //写数据 #500; send_uart_data_rd; //读数据 #500; $stop; end //串口发送写数据命令和待写入数据任务 task send_uart_data_wr; begin //写数据指令 wdata_cmd = {8'h21,8'hf1,addr[15:8],addr[7:0],data_num}; //发送写数据指令 repeat(5)begin Rx_done = 1; Rx_data = wdata_cmd[39:32]; #(`CLK_PERIOD) Rx_done = 0; #500; wdata_cmd = {wdata_cmd[31:0],8'h00}; end //待写入数据 Rx_data = wr_data; repeat(data_num)begin Rx_done = 1; Rx_data = Rx_data + 1; #(`CLK_PERIOD) Rx_done = 0; #500; end end endtask //串口发送读数据命令任务 task send_uart_data_rd; begin //读数据指令 rdata_cmd = {8'h21,8'hf2,addr[15:8],addr[7:0],data_num}; //发送读数据指令 repeat(5)begin Rx_done = 1; Rx_data = rdata_cmd[39:32]; #(`CLK_PERIOD) Rx_done = 0; #500; rdata_cmd = {rdata_cmd[31:0],8'h00}; end end endtask endmodule仿真过程主要是模拟命令解析模块接收到写或读 EEPROM 操作指令后的操作是否和我们设计想要达到的目标是否一致。这里的写或读数据指令均采用任务的形式,写数据指令下待写入的数据是采用给定一个值的基础上递增进行赋值的。命令解析模块仿真的结果如图 30.26 所示。 图片 根据波形时序图,在模拟发送写操作命令 0x21,0xf1,0x00,0x00,0x04,0x06,0x07,0x08,0x09 时,在接收完数据字节数这个数据后,后面收到的数据就存入到 fifo 中去了,与我们设计的是一致的,同理可以分析读数据操作命令,也是没有问题的,这样命令解析模块就设计完成了。 下面就是整个系统的设计,如图 30.25 整体设计框图中,在 I2C 写数据操作之前和读数据后分别加入了 fifo 模块,因为串口读写速度和 I2C 读写速度不一样,在这之间加入的 fifo 模块具有读写时钟不一致的特点,可以对数据进行一个缓存,这样就能解决前后速度不一样的问题,这里的两个 fifo 均设置的是读取数据在读请求前有效,这样设计的目的是为了与其他模块待输入数据与使能信号相匹配,里面的 fifo模块都是通过 QuartusII 软件生成的 IP 核,fifo 输入输出数据位宽均设置为 8位,深度设置为 64(多字节读取最多支持 32 字节,稍大于这个数就可以了)。在各模块均设计完成后,整个系统的顶层电路设计就显得比较简单了,根据设计的系统框图进行整合就可以了。整个系统设计的代码如下: module uart_eeprom( Clk, Rst_n, Uart_rx, Uart_tx, Sda, Scl ); parameter Baud_set = 3'd4;//波特率设置,这里设置为 115200 input Clk; //系统时钟 input Rst_n; //系统复位 input Uart_rx; //串口接收 output Uart_tx; //串口发送 inout Sda; //I2C 时钟线 output Scl; //I2C 数据线 wire [7:0] Rx_data; //串口接收一字节数据 wire Rx_done; //串口接收一字节数据完成 wire wfifo_req; //写 FIFO 模块写请求 wire [7:0] wfifo_data; //写 FIFO 模块写数据 wire [5:0] wfifo_usedw; //写 FIFO 模块已写数据量 wire [5:0] rfifo_usedw; //读 FIFO 模块可读数据量 wire rfifo_rdreq; //读 FIFO 模块读请求 wire [5:0] Rddata_num; //I2C 总线连续读取数据字节数 wire [5:0] Wrdata_num; //I2C 总线连续写取数据字节数 wire [1:0] Wdaddr_num; //EEPROM 数据地址字节数 wire [2:0] Device_addr; //EEPROM 地址 wire [15:0] Word_addr; //EEPROM 寄存器地址 wire Wr; //EEPROM 写使能 wire [7:0] Wr_data; //EEPROM 写数据 wire Wr_data_vaild;//EEPROM 写数据有效标志位 wire Rd; //EEPROM 读使能 wire [7:0] Rd_data; //EEPROM 读数据 wire Rd_data_vaild;//EEPROM 读数据有效标志位 wire Done; //EEPRO 读写完成标识位 wire tx_en; //串口发送使能 wire [7:0] tx_data; //串口待发送数据 wire tx_done ; //一次串口发送完成标志位 //串口接收模块例化 uart_byte_rx uart_rx( .Clk(Clk), .Rst_n(Rst_n), .Rs232_rx(Uart_rx), .baud_set(Baud_set), .Data_Byte(Rx_data), .Rx_Done(Rx_done) ); //指令解析模块例化 cmd_analysis cmd_analysis( .Clk(Clk), .Rst_n(Rst_n), .Rx_done(Rx_done), .Rx_data(Rx_data), .Wfifo_req(wfifo_req), .Wfifo_data(wfifo_data), .Rddata_num(Rddata_num), .Wrdata_num(Wrdata_num), .Wdaddr_num(Wdaddr_num), .Device_addr(Device_addr), .Word_addr(Word_addr), .Rd(Rd) ); //写缓存 fifo 模块例化 fifo_wr fifo_wr( .clock(Clk), .data(wfifo_data), .rdreq(Wr_data_vaild), .wrreq(wfifo_req), .empty(), .full(), .q(Wr_data), .usedw(wfifo_usedw) ); //EEPROM 写使能 assign Wr = (wfifo_usedw == Wrdata_num)&& (wfifo_usedw != 6'd0); //I2C 控制模块例化 I2C I2C( .Clk(Clk), .Rst_n(Rst_n), .Rddata_num(Rddata_num), .Wrdata_num(Wrdata_num), .Wdaddr_num(Wdaddr_num), .Device_addr(Device_addr), .Word_addr(Word_addr), .Wr(Wr), .Wr_data(Wr_data), .Wr_data_vaild(Wr_data_vaild), .Rd(Rd), .Rd_data(Rd_data), .Rd_data_vaild(Rd_data_vaild), .Scl(Scl), .Sda(Sda), .Done(Done) ); //读缓存 fifo 模块例化 fifo_rd fifo_rd( .clock(Clk), .data(Rd_data), .rdreq(rfifo_rdreq), .wrreq(Rd_data_vaild), .empty(), .full(), .q(tx_data), .usedw(rfifo_usedw) ); //串口发送使能 assign tx_en = ((rfifo_usedw == Rddata_num)&&Done)|| ((rfifo_usedw < Rddata_num)&& (rfifo_usedw >0)&&tx_done); //读 FIFO 模块读请求 assign rfifo_rdreq = tx_en; //串口发送模块例化 uart_byte_tx uart_tx( .Clk(Clk), .Rst_n(Rst_n), .send_en(tx_en), .baud_set(Baud_set), .Data_Byte(tx_data), .Rs232_Tx(Uart_tx), .Tx_Done(tx_done), .uart_state() ); endmodule下面对设计的整个系统进行编写 testbench 文件来仿真验证,整个仿真主要是通过串口发送模块模拟对该系统发送指令进行仿真验证,这里就只选用 M24LC64 这个仿真模型进行仿真,M24LC04 的仿真模型类似(读者可尝试对该模型进行仿真),编写的 testbench 文件具体代码如下: `timescale 1ns/1ns `define CLK_PERIOD 20 module uart_eeprom_tb; reg Clk; reg Rst_n; reg tx_en; reg [7:0] tx_data; wire tx_done; wire Uart_rx; wire Uart_tx; wire Sda; wire Scl; reg [15:0] addr; reg [7:0] data_num; reg [7:0] wr_data; reg [39:0] wdata_cmd; reg [39:0] rdata_cmd; localparam Baud_set = 3'd4; //波特率设置,这里设置为 115200 localparam DevAddr = 3'b000;//I2C 器件的器件地址 localparam WdAr_NUM = 2'd2; //I2C 器件的存储器地址字节数 //串口发送模块例化 uart_byte_tx uart_tx( .Clk(Clk), .Rst_n(Rst_n), .send_en(tx_en), .baud_set(Baud_set), .Data_Byte(tx_data), .Rs232_Tx(Uart_rx), .Tx_Done(tx_done), .uart_state() ); //串口读写 EEPROM 模块例化 uart_eeprom #(.Baud_set(Baud_set)) uart_eeprom( .Clk(Clk), .Rst_n(Rst_n), .Uart_rx(Uart_rx), .Uart_tx(Uart_tx), .Sda(Sda), .Scl(Scl) ); //EEPROM 模型例化 M24LC64 M24LC64( .A0(1'b0), .A1(1'b0), .A2(1'b0), .WP(1'b0), .SDA(Sda), .SCL(Scl), .RESET(!Rst_n) ); //系统时钟产生 initial Clk = 1'b1; always #(`CLK_PERIOD/2)Clk = ~Clk; initial begin Rst_n = 0; tx_data = 0; tx_en = 0; addr = 0; data_num = 0; wr_data = 0; wdata_cmd = 0; rdata_cmd = 0; #(`CLK_PERIOD*200 + 1) Rst_n = 1; #200; addr = 0; data_num = 4; wr_data = 0; send_uart_data_wr;//写数据 @(posedge uart_eeprom.I2C.Done); #500; send_uart_data_rd;//读数据 @(posedge uart_eeprom.I2C.Done); #500; addr = 4; data_num = 8; wr_data = 20; send_uart_data_wr;//写数据 @(posedge uart_eeprom.I2C.Done); #500; send_uart_data_rd;//读数据 @(posedge uart_eeprom.I2C.Done); //从 EEPROM 读出的数据串口发送出去,等待发送完成 repeat(data_num)begin @(posedge uart_eeprom.tx_done); end #5000; $stop; end //串口发送写数据命令和待写入数据任务 task send_uart_data_wr; begin //写数据指令 wdata_cmd = {{2'b00,WdAr_NUM,1'b0,DevAddr},8'hf1, addr[15:8],addr[7:0],data_num}; //发送写数据指令 repeat(5)begin tx_en = 1; tx_data = wdata_cmd[39:32]; #(`CLK_PERIOD) tx_en = 0; @(posedge tx_done) #100; wdata_cmd = {wdata_cmd[31:0],8'h00}; end //待写入数据 tx_data = wr_data; repeat(data_num)begin tx_en = 1; tx_data = tx_data + 1; #(`CLK_PERIOD) tx_en = 0; @(posedge tx_done) #100; end end endtask //串口发送读数据命令任务 task send_uart_data_rd; begin //读数据指令 rdata_cmd = {{2'b00,WdAr_NUM,1'b0,DevAddr},8'hf2, addr[15:8],addr[7:0],data_num}; //发送读数据指令 repeat(5)begin tx_en = 1; tx_data = rdata_cmd[39:32]; #(`CLK_PERIOD) tx_en = 0; @(posedge tx_done) #100; rdata_cmd = {rdata_cmd[31:0],8'h00}; end end endtask endmodule仿真过程主要是通过串口发送模块模拟对该系统发送读写指令进行仿真验证,分别进行了 2 次写和读指令的发送,读指令主要是对刚写入地址的数据进行读出,我们可以通过观察时序波形图,比较写入数据与读出数据是否一致来验证系统设计的正确性。如图 30.27 为系统仿真波形时序图。 图片 分别对一次写数据指令和一次读数据指令的波形进行放大后观察分析,如图 30.28 和图30.29 分别为一次对 EEPROM 写数据过程和读数据过程的波形时序图。 图片 这次写数据过程的仿真是通过串口发送模块模拟发送指令数据 0x21,0xf1,0x00,0x00,0x04,0x05,0x06,0x07,0x08,向 EEPROM 中起始地址为 0 开始写入 0x05,0x06,0x07,0x08 四个数据,可以通过观察图 30.28 的中 SDA 和 SCL 波形图分析得知,写入的数据确实是这四个数据,说明系统中串口写 EEPROM 部分是没有问题的。 读数据过程的仿真是通过串口发送模块模拟发送指令数据 0x21,0xf2,0x00,0x00,0x04,向 EEPROM 中起始地址为 0 开始读出四个数据,通过观察图 30.29 的中 SDA和 SCL 波形图分析得知,读出的四个数据为 0x05,0x06,0x07,0x08,与之前在这些地址写入的数据是一致的,说明这次的读数据时没有问题的,同样的方式经过多次的验证,串口读写 EEPROM 系统是可以正常工作的。仿真验证进行完成后,接下来就是进行板级验证,先是引脚的分配,本实验板级验证平台是 AC620 开发板,根据开发板的引脚分配表对本实验所用引脚进行分配。如图 30.30 是 AC620 开发板上 EEPROM 部分的硬件原理图,在引脚分配之前,是需要对这一块硬件电路有所了解的。 图片 细心的读者会发现,I2C 时钟线 SCL 和 I2C 数据线没有进行硬件上拉处理,与前面讲解的需要上拉处理不一样,可能会猜想是硬件设计的问题。这里我说明一下,硬件设计是没有问题的,因为对于 FPGA 是可以通过软件对引脚进行上拉处理的,这个也是本实验包含的一个知识点。通过 Quartus II 软件将管脚设置为上拉电阻(弱上拉)的方法,具体的步骤如下: 1.在菜单 Assignments 中选择 Pin Planner,也可以直接点击面板上引脚分配的图标 图片 2.这样进入引脚分配的界面,在弹出的 Pin Planner 界面的 All Pins 区域里点击鼠标右键,找到 Customize Columns。 图片 在弹出的 Customize Columns 对 话 框的 左 列表 框 选 择 Weak Pull-Up Resistor,再点击,把 Weak Pull-Up Resistor 添加到右列表框,这样在 Pin Planner 的 All Pins 区域里就有一列 Weak Pull-Up Resistor 的设置项。 图片 再把需要上拉的 SDA 和 SCL 在其对应的 Weak Pull-Up Resistor 列的位置双极鼠标左键,就会弹出一个 Off/On 的选项,选上 On 就可以了。最后完成后的设置如下: 图片 引脚分配和上拉设置完成后,对我们设计的系统顶层文件进行综合布局布线生成 sof 下载文件,然后下载到 AC620 实验平台进行板级验证。板级验证需要用到串口软件工具, 这里使用的是名叫格西烽火的串口工具,选择对应的开发板的串口号和波特率,系统设计的波特率在顶层文件 uart_eeprom 中可进行设置,这里我们设置的波特率为115200bps。 板级验证时,我们先往 EEPROM 里写入一些数据,也就是在串口发送 6 组数据,每组数据写入四个数据;写完后发送读数据命令,读出写入的数据,分两次读,一次读 20个数据,一次读 4 个数据,具体的发送读写指令操作和串口接收的数据如下图: 图片 从串口发送和接受的数据分析可得,从 EEPROM 读出的 20 个数据和写入的 20 个数据是一样的,这就说明,设计的整个系统是工作正常的,读者可以多次进行多组测试来验证设计的完整性,整个的测试还可以利用 Quartus II 软件中的 SignalTap II Logic Analyzer 工具对 SDA 和 SCL 的波形进行抓取分析系统设计的正确性,这里就不详细的说明了,读者可以自己进行尝试。整个串口读写 EEPROM 的系统设计就算完成了,里面还有很多需要完善的地方,读者可以在学习完成后,对本实验进行改进和拓展。 本节小结 本节主要从二线制 I2C 协议的基本知识和概念、 I2C 器件之间数据通信过程,比较全面的了解了 I2C 协议,并以此设计一个可进行读写操作的 I2C 控制器,结合前面设计的串口收发模块和 FIFO 模块设计了一个简易应用,实现了串口对 EEPROM 存储器的读写功能,并进行相应的板级验证。读者可以在此基础上进行一定的优化和拓展,AC620实验开发板上还有音频模块和时钟模块挂在在 I2C 总线上,读者可以利用这些模块实现更丰富的应用
FPGA&ASIC
# ASIC/FPGA
# 小实验
刘航宇
3年前
0
1,917
6
2022-12-25
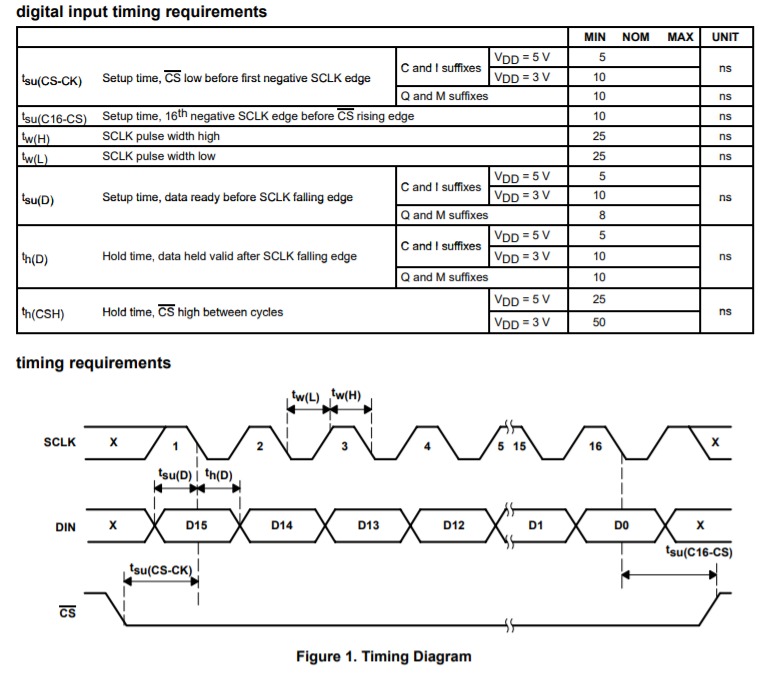
【FPGA】【SPI】线性序列机与串行接口 ADC 驱动设计与验证
本章导读 模数转换器即 A/D 转换器,或简称 ADC(Analog to Digital Conver),通常是指一个将模拟信号转变为数字信号的电子元件。通常的模数转换器是把经过与标准量比较处理后的模拟量转换成以二进制数值表示的离散信号的转换器。 模数转换器的种类很多,按工作原理的不同,可分成间接 ADC 和直接 ADC。间接 ADC是先将输入模拟电压转换成时间或频率,然后再把这些中间量转换成数字量,常用的有双积分型 ADC。直接 ADC 则直接转换成数字量,常用的有并联比较型 ADC 和逐次逼近型 ADC。 并联比较型 ADC:采用各量级同时并行比较,各位输出码也是同时并行产生,所以转换速度快。并联比较型 ADC 的缺点是成本高、功耗大。 逐次逼近型 ADC:它产生一系列比较电压 VR,但它是逐个产生比较电压,逐次与输入电压分别比较,以逐渐逼近的方式进行模数转换。它比并联比较型 ADC 的转换速度慢,比双分积型 ADC 要快得多,属于中速 ADC 器件。 双积分型 ADC:它先对输入采样电压和基准电压进行两次积分,获得与采样电压平均值成正比的时间间隔,同时用计数器对标准时钟脉冲计数。它的优点是抗干扰能力强,稳定性好;主要缺点是转换速度低。 本节以 ADC128S022 为例介绍 ADC 的工作原理及时序图解释,并用线性序列机来描述时序图进而正确驱动此类设备。本实验中,直接使用 AD/DA 模块上的 DAC 模块的输出直接接到 ADC 模块的输入上,通过控制 DAC 输出不同电压值,然后比较 DAC 的输出与 ADC采样到的值的大小,来评估 ADC 驱动的正确性。 ADC 芯片概述及电路设计 ADC128S022 型 ADC 内部工作原理 在 AC620 开发板上使用的模数转换器为逐次逼近型的低功耗芯片 ADC128S022,其具有 8 通道以及 12 位的分辨率。电源采用独立的模拟供电以及数字供电,其中模拟电源 VA输入范围为 2.7V~5.25V,数字电源 VD 输入范围为 2.7V~VA。其与外部通信支持多种接口如:SPI、QSPI、MICROWIRE 以及通用的 DSP 接口。转换速度在 50kps~200kps,典型情况下当3V 供电时功耗为 1.2mW,5V 供电时为 7.5mW。 图片 本款 ADC 为 12 位分辨率,因此 1bit 代表的电压值即为 VA/4096。手册中同时指出,当模拟输入电压低于 VA/8192 时,输出数据即为 0000_0000_0000b。同理由于芯片本身内部构造当输出数 0000_0000_0000b 变为 0000_0000_0001b 时,实际输入电压变化为 VA/8192 而不是 VA/4096。当输入电压大于等于 VA-1.5* VA/4096,输出数据即为 1111_1111_1111b。 ADC128S022 型 ADC 芯片引脚功能 ADC128S022 芯片引脚及功能描述如表 25.1 所示。 图片 ADC128S022 电路设计 ADC128S022 部分电路图如图 25.2 所示。这里外接了一个抗混叠低通滤波器,其作用是为了避免输入信号的高频成分在 ADC 的基带中引起混叠。数字电源与模拟电源电压均为3.3V,且数字电源与模拟电源之间串联磁珠用于抑制电磁干扰。 图片 传输特性 图片 ADC128S022 型 ADC 接口时序 微控制器与 ADC128S022 的接口如图 25.3 所示,该接口使用标准的 SPI 接口,因此可以直接连接到微控制器的片上 SPI。对于 FPGA 来说,则可以使用逻辑按照 SPI 时序搭建控制电路,以实现对 ADC128S022 的控制。 图片 ADC128S022 通过 SPI 接口与控制器进行通信的时序图如图 所示。一个串行帧开始于CS̅̅̅的下降沿,结束于CS̅̅̅的上升沿。一帧包含 16 个上升沿 SCLK。ADC 的 DOUT 引脚当CS̅̅̅为高时代表空闲状态,当为低时为传输状态。也就是相当于CS̅̅̅可以充当输出使能。在CS̅̅̅为高时 SCLK 默认高。在头三个 SCLK 的循环,ADC 处于采样模式(track)。在接下来的 13 个循环为保持模式(hold),转换完成并且完成数据输出。下降沿 1~4 为前导零,5~16 为输出转换结果。如果在持续测量模式中,ADC 在 N(16) 个 SCLK 的上升沿会自动进去采样模式,在N16+4 个下降沿进入保持/转换模式。 图片 图片 进入采样模式有三种方式,第一种当 SCLK 为高电平时 CS 变为低,当 SCLK 第一个下降沿到来时便进入采样模式,如时序图所示;第二种当 SCLK 为低电平时CS变低,自动进入采样模式,CS的下降沿即视为 SCLK 的第一个下降沿;第三种 SCLK 与CS一同变为低,这样对于两信号上升沿没有时序约束,但对于其下降沿有要求。 在 DIN 的 8 个控制寄存器,每一位代表的含义如表 25.2 所示。 图片 其中 ADD[2:0]代表的输入通道选择如表 25.3 所示。 图片 图片 ADC128S022 接口时序设计 经查阅手册可知器件工作频率 SCLK 推荐范围为 0.8~3.2MHz,这里定义其工作频率为1.92MHz(周期为 520ns)。设置一个两倍于 SCLK 的采样时钟 SCLK2X,使用 50M 系统时钟十三分频而来即 SCLK2X 为 3.84MHz。针对 SCLK2X 进行计数来确定图 25.4 中各个信号的状态。结合前面 ADC 的接口时序图,按照线性序列机的设计思路,可以整理得到每个信号发生变化时对应的时刻以及此时对应的计数器的值。表25.4为依照线性序列机的设计思想, 整理得到的每个信号发生变化时对应的时刻以及此时对应的计数器的值。其中 CS_N 为芯片 状态标志信号,SCLK 为芯片时钟输入脚,DIN 为芯片串行数据输入,DOUT 为芯片串行数据输出。 图片 图片 线性序列机计数器的控制逻辑判断依据,如表 4.17.6 所示。 图片 以上就是通过线性序列机设计接口时序的一个典型案例,可以看到,线性序列机可以大大简化设计思路。线性序列机的设计思想就是使用一个计数器不断计数,由于每个计数值都会对应一个时间,那么当该时间符合需要操作信号的时刻时,就对该信号进行操作。这样,就能够轻松的设计出各种时序接口了。 基于线性序列机的 ADC 驱动设计 模块接口设计 ADC128S022 接口逻辑模块图如图 25.5 所示。 图片 每个端口功能描述如表 25.5 所示。 图片 图片 在每次使能转换的时候,寄存当前状态通道选择 Channel 的值,防止在转换过程中该值发生变化对转换过程产生影响。 reg [2:0]r_Channel; //通道选择内部寄存器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) r_Channel <= 3'd0; else if(En_Conv) r_Channel <= Channel; else r_Channel <= r_Channel;生成使能信号,当输入使能信号有效后便将使能信号 en 置 1,当转换完成信号有效时便将其重新置 0。 reg en; //转换使能信号 always@(posedge Clk or negedge Rst_n) if(!Rst_n) en <= 1'b0; else if(En_Conv) en <= 1'b1; else if(Conv_Done) en <= 1'b0; else en <= en;在数据手册中SCLK的频率范围为0.8~3.2MHz。这里为了方便适配不同的频率需求率,设置了一个可调的计数器。根据表中可以看出,需要根据计数器的值周期性的产生 SCLK时钟信号,这里可以将计数器的值等倍数放大,形成过采样。这里产生一个两倍于 SCLK 的信号,命名为 SCLK2X。 首先编写分频计数器,时钟 SCLK2X 的计数器。 reg [7:0]DIV_CNT;//分频计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) DIV_CNT <= 8'd0; else if(en)begin if(DIV_CNT == (DIV_PARAM - 1'b1)) //时钟分频设置 DIV_CNT <= 8'd0; else DIV_CNT <= DIV_CNT + 1'b1; end else DIV_CNT <= 8'd0;根据使能信号以及计数器状态生成 SCLK2X 时钟。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK2X <= 1'b0; else if(en && (DIV_CNT == (DIV_PARAM - 1'b1))) SCLK2X <= 1'b1; else SCLK2X <= 1'b0;每当使能转换后,对 SCLK2X 时钟进行计数。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK_GEN_CNT <= 6'd0; else if(SCLK2X && en)begin if(SCLK_GEN_CNT == 6'd33) SCLK_GEN_CNT <= 6'd0; else SCLK_GEN_CNT <= SCLK_GEN_CNT + 1'd1; end else SCLK_GEN_CNT <= SCLK_GEN_CNT;根据 SCLK2X 计数器的值来确认工作状态以及数据传输进程。 reg [11:0]r_data; //转换结果读取内部寄存器 reg [5:0]SCLK_GEN_CNT;//SCLK2X 计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin SCLK <= 1'b1;CS_N <= 1'b1;DIN <= 1'b1; end else if(en) begin if(SCLK2X)begin case(SCLK_GEN_CNT) 6'd0:begin CS_N <= 1'b0; end 6'd1:begin SCLK <= 1'b0; DIN <= 1'b0; end 6'd2:begin SCLK <= 1'b1; end 6'd3:begin SCLK <= 1'b0; end 6'd4:begin SCLK <= 1'b1; end 6'd5:begin SCLK <= 1'b0; DIN <= r_Channel[2];end 6'd6:begin SCLK <= 1'b1; end 6'd7:begin SCLK <= 1'b0; DIN <= r_Channel[1];end 6'd8:begin SCLK <= 1'b1; end 6'd9:begin SCLK <= 1'b0; DIN <= r_Channel[0];end 6'd10,6'd12,6'd14,6'd16,6'd18,6'd20,6'd22,6'd24,6'd26,6'd28,6'd 30,6'd32: begin SCLK <= 1'b1; r_data <= {r_data[10:0], DOUT}; end 6'd11,6'd13,6'd15,6'd17,6'd19,6'd21,6'd23,6'd25,6'd27,6'd29,6'd 31: begin SCLK <= 1'b0; end 6'd33:begin CS_N <= 1'b1; end//将转换结果输出 default:begin CS_N <= 1'b1; end endcase end else ; end else CS_N <= 1'b1;一次转换结束的标志,即 en && SCLK2X && (SCLK_GEN_CNT == 6'd33)为真,并产生一个高脉冲的转换完成标志信号 Conv_Done。一次转换结束后将内部寄存器 r_data 的数据输出到输出端 Data 上。 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin Data <= 12'd0; Conv_Done <= 1'b0; end else if(en && SCLK2X && (SCLK_GEN_CNT == 6'd33))begin Data <= r_data; Conv_Done <= 1'b1; end else begin Data <= Data; Conv_Done <= 1'b0; endADC 工作状态,在手册中看出 CS_N 在工作时为低电平,因此直接将此信号作为工作状态指示。 assign ADC_State = CS_N;仿真及板级测试 为了测试模块功能,模拟 ADC 芯片的输出。这里用 Sin3e 产生一个正弦波文件,位宽12 位,个数为 4096,并以 sin_12bit.txt 保存当前工程下的 simulation 目录下的 modelsim 文件夹。 这样就需要将产生的数据,发送到 ADC 驱动模块的输入线 DOUT 上,这里使用系统任务$readmemb,其可以用来从文件中读取数据到存储器中。其格式有以下三种: $readmemb("<数据文件名>",<存贮器名>); $readmemb("<数据文件名>",<存贮器名>,<起始地址>); $readmemb("<数据文件名>",<存贮器名>,<起始地址>,<结束地址>。 首先定义文件存放位置。 `define sin_data_file "./sin_12bit.txt"定义 4096 个 12 位的存储单元,然后将波形数据读取到存储器中。 reg[11:0] memory[4095:0];//测试波形数据存储空间 initial $readmemh(`sin_data_file,memory);在测试时将这些数据整体循环三次,进行验证。其中 gene_DOUT(memory[address]);依次将存储器中存储的波形数据读出,按照 ADC 芯片转换结果输出方式的送到 DOUT 信号线上。 integer i; initial begin Rst_n = 0;Channel = 0; En_Conv = 0; DOUT = 0;address = 0; #101; Rst_n = 1; #100; Channel = 5; for(i=0;i<3;i=i+1)begin for(address=0;address<4095;address=address+1)begin En_Conv = 1; #20; En_Conv = 0; gene_DOUT(memory[address]); @(posedge Conv_Done); //等待转换完成信号 #200; end end #20000; $stop; end将存储空间的数据按照 ADC 的数据输出格式,发送到 DOUT 信号线上,供控制模块采集。 task gene_DOUT; input [15:0]vdata; reg [4:0]cnt; begin cnt = 0; wait(!CS_N); while(cnt<16)begin @(negedge SCLK) DOUT = vdata[15-cnt]; cnt = cnt + 1'b1; end end endtask全编译后进行仿真,可看出此次信号较多。这里首先查看与 ADC 相关的使能信号、状态标志信号以及 SCLK 时钟信号等。选中以上这些信号,可以看出,每当外界输入一个周期的 En_Conv 转换信号,模块内部使能信号 en 就置高,一直到转换完成标志信号 Conv_Done有效再置 0。当 SLK2X 计数器值为 33d 且当 SCLK2X 为高时,便输出一个时钟周期的高脉冲信号,标志着本次转换过程结束。同时 SCLK2X 时钟为 ADC 工作时钟 SCLK 的两倍。以上各信号符合既定的设计。 图片 DIN 为 FPGA 控制 ADC 通道选择的信号,这里选择的通道五也就是 ADD[2:0]=101b,可以看出图每个测量循环中发送 DIN 状态均一致。 图片 查看 DOUT 串行数据输出信号,在每个 SCLK 上升沿 DOUT 均会输出一位数据。在第一个转换过程中,DOUT 首先输出 4 个前导 0,然后依次输出 1000_0000_0000b(MSB),也就是在激励文件中例化的正弦波的第一个数据 800h。并在一次转换完成后,输出并行数据 Data。符合既定设计,可以自行分析第二个转换过程。 图片 查看 CS_N 与 ADC_State 工作状态标志信号,可看出当 ADC 处于转换时为低电平,空闲时为高电平,符合设计要求。 图片 将并行输出数据 Data 设置为模拟形式,主要参数如图 25.10 所示,其中波形所占高度可根据实际情况自行设计,此处暂定 100。 图片 重启仿真后可看出数据输入为 3 个周期的正弦波也就是采样正确,符合既定设计。这里如不重启仿真可能会出现如图 25.12 所示的波形影响观测,此为仿真软件本身问题,可不深究。 图片 为了进行板级仿真,新建测试 ADC_test 顶层文件,在顶层文件中例化 ADC 以及 DAC驱动,并设置好相关使能以及标志信号。再分别生成两个 ISSP 文件,其中驱动 DAC 电压数据的命名为 ISSP_DAC(源位宽为 16),采集 ADC 电压以及通道设置的为 ISSP_ADC(源位宽为 3,探针位宽为 12)。分配引脚并全编译后,下载程序,并启动 ISSP。 1.DAC 的 DA 输出端连接 ADC 的 A0 输入端。如图 25.13 所示,使得 DAC 输出电压为0,可测得电压为 0。 图片 2.DAC 的 DA 输出端连接 ADC 的 A0 输入端。此时更新 DB 的输出值,如图 25.14,可以看出 A0 测量数据保持 0 不变。 图片 3.DAC 的 DB 输出端接 ADC 的 A1 输入端。此时更新 DB 值,其理论输出电压为7FF/FFF 4.096=2.048V ,如图 25.15 所示,使能 A1 测量端可测得输入电压为2535/40963.3=2.04V,在误差允许范围内。 图片 DAC的DB输出端接ADC的 A1 输入端。此时更新 DB 值,其理论输出电压为 BD3/FFF 4.096=3.072V,如图 25.16 所示,使能 A1 测 量 端 可 测 得 输 入 电 压 为 3815/4096 3.3=2.07V,在误差允许范围内。 图片 同理可测试的其他 DAC 输出电压以及 ADC 输入测量电压值。此处换算时需注意,DAC电路输出电压范围为 0~4V,ADC 电路测量电压范围为 0~3.3V。 工程代码 图片 在我们设计的驱动模块中,需要给ADC芯片三个控制信号SCLK、CS_N、DIN,还需要有接收ADC转化结果的ADC_OUT。ADC芯片的选址信号通过Channel端给到ADC_driver中,然后通过ADC_DIN给到芯片中,用于选择采集模拟信号的通道。12位宽的Data输出给外部的FIFO缓存。 module adc128s022( Clk, Rst_n, Channel, Data, En_Conv, Conv_Done, ADC_State, DIV_PARAM, ADC_SCLK, ADC_DOUT, ADC_DIN, ADC_CS_N ); input Clk; //输入时钟 input Rst_n; //复位输入,低电平复位 input [2:0]Channel; //ADC转换通道选择 output reg [11:0]Data; //ADC转换结果 input En_Conv; //使能单次转换,该信号为单周期有效,高脉冲使能一次转换 output reg Conv_Done; //转换完成信号,完成转换后产生一个时钟周期的高脉冲 output ADC_State; //ADC工作状态,ADC处于转换时为低电平,空闲时为高电平 input [7:0]DIV_PARAM; //时钟分频设置,实际SCLK时钟 频率 = fclk / (DIV_PARAM * 2) output reg ADC_SCLK; //ADC 串行数据接口时钟信号 output reg ADC_CS_N; //ADC 串行数据接口使能信号 input ADC_DOUT; //ADC转换结果,由ADC输给FPGA output reg ADC_DIN; //ADC控制信号输出,由FPGA发送通道控制字给ADC reg [2:0]r_Channel; //通道选择内部寄存器 reg [11:0]r_data; //转换结果读取内部寄存器 reg [7:0]DIV_CNT;//分频计数器 reg SCLK2X;//2倍SCLK的采样时钟 reg [5:0]SCLK_GEN_CNT;//SCLK生成暨序列机计数器 reg en;//转换使能信号 //在每个使能转换的时候,寄存Channel的值,防止在转换过程中该值发生变化 always@(posedge Clk or negedge Rst_n) if(!Rst_n) r_Channel <= 3'd0; else if(En_Conv) r_Channel <= Channel; else r_Channel <= r_Channel; //产生使能转换信号 always@(posedge Clk or negedge Rst_n) if(!Rst_n) en <= 1'b0; else if(En_Conv) en <= 1'b1; else if(Conv_Done) en <= 1'b0; else en <= en; //生成2倍SCLK使能时钟计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) DIV_CNT <= 8'd0; else if(en)begin if(DIV_CNT == (DIV_PARAM - 1'b1)) DIV_CNT <= 8'd0; else DIV_CNT <= DIV_CNT + 1'b1; end else DIV_CNT <= 8'd0; //生成2倍SCLK使能时钟 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK2X <= 1'b0; else if(en && (DIV_CNT == (DIV_PARAM - 1'b1))) SCLK2X <= 1'b1; else SCLK2X <= 1'b0; //生成序列计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK_GEN_CNT <= 6'd0; else if(SCLK2X && en)begin if(SCLK_GEN_CNT == 6'd33) SCLK_GEN_CNT <= 6'd0; else SCLK_GEN_CNT <= SCLK_GEN_CNT + 1'd1; end else SCLK_GEN_CNT <= SCLK_GEN_CNT; //序列机实现ADC串行数据接口的数据发送和接收 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin ADC_SCLK <= 1'b1; ADC_CS_N <= 1'b1; ADC_DIN <= 1'b1; end else if(en) begin if(SCLK2X)begin case(SCLK_GEN_CNT) 6'd0:begin ADC_CS_N <= 1'b0; end 6'd1:begin ADC_SCLK <= 1'b0; ADC_DIN <= 1'b0; end 6'd2:begin ADC_SCLK <= 1'b1; end 6'd3:begin ADC_SCLK <= 1'b0; end 6'd4:begin ADC_SCLK <= 1'b1; end 6'd5:begin ADC_SCLK <= 1'b0; ADC_DIN <= r_Channel[2];end //addr[2] 6'd6:begin ADC_SCLK <= 1'b1; end 6'd7:begin ADC_SCLK <= 1'b0; ADC_DIN <= r_Channel[1];end //addr[1] 6'd8:begin ADC_SCLK <= 1'b1; end 6'd9:begin ADC_SCLK <= 1'b0; ADC_DIN <= r_Channel[0];end //addr[0] //每个上升沿,寄存ADC串行数据输出线上的转换结果 6'd10,6'd12,6'd14,6'd16,6'd18,6'd20,6'd22,6'd24,6'd26,6'd28,6'd30,6'd32: begin ADC_SCLK <= 1'b1; r_data <= {r_data[10:0], ADC_DOUT}; end //循环移位寄存DOUT上的12个数据 6'd11,6'd13,6'd15,6'd17,6'd19,6'd21,6'd23,6'd25,6'd27,6'd29,6'd31: begin ADC_SCLK <= 1'b0; end 6'd33:begin ADC_CS_N <= 1'b1; end default:begin ADC_CS_N <= 1'b1; end //将转换结果输出 endcase end else ; end else begin ADC_CS_N <= 1'b1; end //转换完成时,将转换结果输出到Data端口,同时产生一个时钟周期的高脉冲信号 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin Data <= 12'd0; Conv_Done <= 1'b0; end else if(en && SCLK2X && (SCLK_GEN_CNT == 6'd33))begin Data <= r_data; Conv_Done <= 1'b1; end else begin Data <= Data; Conv_Done <= 1'b0; end //产生ADC工作状态指示信号 assign ADC_State = ADC_CS_N; endmodule ADC工程 下载地址:https://wwek.lanzoub.com/iDiv00jdsyrc 提取码: 仿真结果 图片
FPGA&ASIC
# 小实验
刘航宇
4年前
0
1,903
2
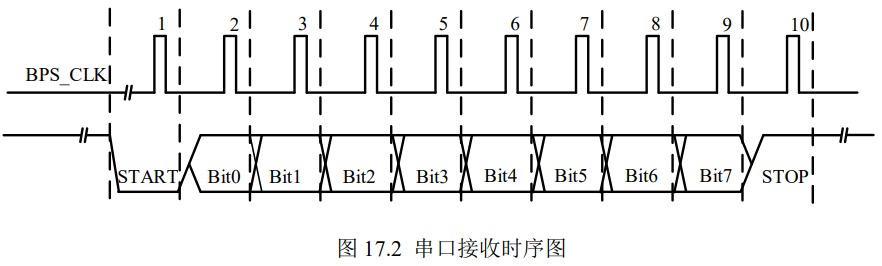
【FPGA】深度理解串口接收模块设计与验证
本章导读 本章将学习 UART 的数据接收设计部分,针对实际使用中强电磁干扰可能会对数据的影响,本节提出一种改进型的串口接收模块设计方式。除了进行常规的功能仿真以外依旧使用 ISSP 工具进行板级测试。 目录 本章导读 串口接收原理分析 UART 异步串行通信接收模块设计与实现串口接收模块接口设计 这里输入数据相对于系统时钟是个异步信号,因此也需要对其进行同步,这里的处理方式与按键的输入部分一样,不再赘述。采样时钟生成模块设计 采样数据接收模块设计 数据状态判定模块设计 仿真及板级验证 代码工程 串口接收原理分析 上一节中学习了串口发送模块的设计与实现,其 UART 发送端发送一个字节数据时序图如图 17.1 所示。 图片 这一讲介绍串口接收模块的设计与实现。当对于数据线 Rs232_Rx 上的每一位进行采样时,一般情况下认为每一位数据的中间点是最稳定的。因此一般应用中,采集中间时刻时的电平即认为是此位数据的电平,如图 17.2 所示。 图片 但是在实际工业应用中,现场往往有非常强的电磁干扰,只采样一次就作为该数据的电平状态是不可靠的。很有可能恰好采集到被干扰的信号而导致结果出错,因此这里提出以下改进型的单 bit 数据接收方式示意图,使用多次采样求概率的方式进行状态判定,如图 17.3所示。 图片 图 17.3 改进型串口接收方式示意图在图 17.3 中,将每一位数据再平均分成了 16 小段。对于 Bit_x 这一位数据,考虑到数据在刚刚发生变化和即将发生变化的这一时期,数据极有可能不稳定的(用深灰色标出的两段),在这两个时间段采集数据,很有可能得到错误的结果,因此判定这两段时间的电平无效,采集时直接忽略。而中间这一时间段(用浅灰色标出),数据本身是比较稳定的,一般都代表了正确的结果。也就是前面提到的中间测量方式,但是也不排除该段数据受强电磁干扰而出现错误的电平脉冲。因此对这一段电平,进行多次采样,并求高低电平发生的概率,6 次采集结果中,取出现次数多的电平作为采样结果。例如,采样 6 次的结果分别为1/1/1/1/0/1/,则取电平结果为 1,若为 0/0/1/0/0/0,,则取电平结果为 0,当 6 次采样结果中 1和 0 各占一半(各 3 次),则可判断当前通信线路环境非常恶劣,数据不具有可靠性,不进 行处理。同理7次采集可以多数决定少数。 UART 异步串行通信接收模块设计与实现 串口接收模块接口设计 基于以上原理,串口接收模块整体框图如图 17.4 所示,其接口列表如表 17.1 所示。 图片 RS232 串行输入信号同步设计 这里输入数据相对于系统时钟是个异步信号,因此也需要对其进行同步,这里的处理方式与按键的输入部分一样,不再赘述。 reg s0_Rs232_Rx,s1_Rs232_Rx; //同步寄存器 reg tmp0_Rs232_Rx,tmp1_Rs232_Rx; //数据寄存器 //同步寄存器,消除亚稳态 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin s0_Rs232_Rx <= 1'b0; s1_Rs232_Rx <= 1'b0; end else begin s0_Rs232_Rx <= Rs232_Rx; s1_Rs232_Rx <= s0_Rs232_Rx; end //数据寄存器 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin tmp0_Rs232_Rx <= 1'b0; tmp1_Rs232_Rx <= 1'b0; end else begin tmp0_Rs232_Rx <= s1_Rs232_Rx; tmp1_Rs232_Rx <= tmp0_Rs232_Rx; end assign nedege = !tmp0_Rs232_Rx && tmp1_Rs232_Rx;采样时钟生成模块设计 串口接收模块主要构成之一即为波特率时钟生成模块。这里根据本章原理部分提到的过采样方式,即实际的采样频率是波特率的 16 倍,得出计数值与波特率之间的关系如表 17.2所示,其中系统时钟周期为 System_clk_period,这里为 20ns。 图片 这里依旧使用一个选择器,来实现不同波特率与采样时钟分频计数值之间的对应关系。设计代码如下所示。 reg [15:0]bps_DR; always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_DR <= 16'd324; else begin case(baud_set) 0:bps_DR <= 16'd324; 1:bps_DR <= 16'd162; 2:bps_DR <= 16'd80; 3:bps_DR <= 16'd53; 4:bps_DR <= 16'd26; default:bps_DR <= 16'd324; endcase end现在产生采样时钟,即波特率时钟的 16 倍。 reg [15:0]div_cnt; reg bps_clk; always@(posedge Clk or negedge Rst_n) if(!Rst_n) div_cnt <= 16'd0; else if(uart_state)begin if(div_cnt == bps_DR) div_cnt <= 16'd0; else div_cnt <= div_cnt + 1'b1; end else div_cnt <= 16'd0; always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_clk <= 1'b0; else if(div_cnt == 16'd1) bps_clk <= 1'b1; else bps_clk <= 1'b0;采样时钟计数器,计数器清零条件之一 bps_cnt == 8'd159 代表一个字节接收完毕。(bps_cnt == 8'd12 && (START_BIT > 2))是实现起始位检测是否出错,在后面会对此进行详细解释。 reg [7:0]bps_cnt; always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_cnt <= 8'd0; else if(bps_cnt == 8'd159 || (bps_cnt == 8'd12 && (START_BIT > 2))) bps_cnt <= 8'd0; else if(bps_clk) bps_cnt <= bps_cnt + 1'b1; else bps_cnt <= bps_cnt; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Rx_Done <= 1'b0; else if(bps_cnt == 8'd159) Rx_Done <= 1'b1; else Rx_Done <= 1'b0;采样数据接收模块设计 以图 17.3 起始位为例,位于中间的采样时间段对应的 bps_cnt 值分别为 6、7、8、9、10、11,在这些时刻直接累加本位数据。然后,后一位数据的采样时间段的第一个 bps_cnt值为前一位数据采样时间段的第一个 bps_cnt 值加 16。所以,起始位后面紧跟的第一个数据位 Bit0 的采样时间段的 bps_cnt 值分别是 22、23、24、25、26、27,同样,在这些时刻,直接累加本位数据。以此类推,可以得到其他位的采样时间段对应的 bps_cnt 值。 现解释为何在上面清零条件之一为(bps_cnt == 8'd12 && (START_BIT > 2)),理想情况下(真正的起始位)也就是当 bps_cnt 计数值为 12 时,START_BIT 的计算值应该为 0。而在实际中,有可能会出现一个干扰信号,而并非真正的起始信号,也导致下降沿的出现。此时,如果不加判断,直接视之为起始信号,进入接收状态,那么必然会接收到错误数据,也可能导致错过正确数据的接收。为了增加抗干扰能力,这里采样了这样的一种思路:当数据线上出现了下降沿时,先假设它是起始信号,然后对其进行中间段采样。如果这 6 次采样值累加结果大于 2,即 6 次采样中有至少一半的状态为高电平时,那么这显然不符合真正起始信号的持续低电平要求,此时就把刚才到来的下降沿视为干扰信号,而不视为起始信号。 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin START_BIT <= 3'd0; r_data_byte[0] <= 3'd0; r_data_byte[1] <= 3'd0; r_data_byte[2] <= 3'd0; r_data_byte[3] <= 3'd0; r_data_byte[4] <= 3'd0; r_data_byte[5] <= 3'd0; r_data_byte[6] <= 3'd0; r_data_byte[7] <= 3'd0; STOP_BIT = 3'd0; end else if(bps_clk)begin case(bps_cnt) 0:begin START_BIT <= 3'd0; r_data_byte[0] <= 3'd0; r_data_byte[1] <= 3'd0; r_data_byte[2] <= 3'd0; r_data_byte[3] <= 3'd0; r_data_byte[4] <= 3'd0; r_data_byte[5] <= 3'd0; r_data_byte[6] <= 3'd0; r_data_byte[7] <= 3'd0; STOP_BIT <= 3'd0; end 6,7,8,9,10,11:START_BIT <= START_BIT + s1_Rs232_Rx; 22,23,24,25,26,27:r_data_byte[0] <= r_data_byte[0] + s1_Rs232_Rx; 38,39,40,41,42,43:r_data_byte[1] <= r_data_byte[1] + s1_Rs232_Rx; 54,55,56,57,58,59:r_data_byte[2] <= r_data_byte[2] + s1_Rs232_Rx; 70,71,72,73,74,75:r_data_byte[3] <= r_data_byte[3] + s1_Rs232_Rx; 86,87,88,89,90,91:r_data_byte[4] <= r_data_byte[4] + s1_Rs232_Rx; 102,103,104,105,106,107:r_data_byte[5] <= r_data_byte[5] + s1_Rs232_Rx; 118,119,120,121,122,123:r_data_byte[6] <= r_data_byte[6] + s1_Rs232_Rx; 134,135,136,137,138,139:r_data_byte[7] <= r_data_byte[7] + s1_Rs232_Rx; 150,151,152,153,154,155:STOP_BIT <= STOP_BIT + s1_Rs232_Rx; default: begin START_BIT <= START_BIT; r_data_byte[0] <= r_data_byte[0]; r_data_byte[1] <= r_data_byte[1]; r_data_byte[2] <= r_data_byte[2]; r_data_byte[3] <= r_data_byte[3]; r_data_byte[4] <= r_data_byte[4]; r_data_byte[5] <= r_data_byte[5]; r_data_byte[6] <= r_data_byte[6]; r_data_byte[7] <= r_data_byte[7]; STOP_BIT <= STOP_BIT; end endcase end数据状态判定模块设计 在原理部分介绍过,对一位数据需进行 6 次采样,然后取出现次数较多的数据作为采样结果,也就是说,6 次采样中出现次数多于 3 次的数据才能作为最终的有效数据。对此,可以用接收到数据 r_data_byte[n]结合数值比较器来判断,也可以直接令其等于当前位的最高位数据。以下面例子说明:当 r_data_byte[n]分别为二进制的 011B/010B/100B/101B时,这几个数据十进制格式分别为 3d/2d/4d/5d,可以发现大于等 4d 的为 100B/101B。当最高位是 1 即此时的数据累加值大于等于 4d,可以说明数据真实值为 1;当最高位是 0 即此时的数据累加值小于等于 3d,可以说明数据真实值为 0,因此只需判断最高位即可。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) data_byte <= 8'd0; else if(bps_cnt == 8'd159)begin data_byte[0] <= r_data_byte[0][2]; data_byte[1] <= r_data_byte[1][2]; data_byte[2] <= r_data_byte[2][2]; data_byte[3] <= r_data_byte[3][2]; data_byte[4] <= r_data_byte[4][2]; data_byte[5] <= r_data_byte[5][2]; data_byte[6] <= r_data_byte[6][2]; data_byte[7] <= r_data_byte[7][2]; end仿真及板级验证 完成设计之后,对其进行功能仿真。在下面的 testbench 文件中,这里产生数据的激励输入使用上一章的发送数据模块的输出来实现,因此激励文件只需在上一章的激励文件中,修改端口信息、例化本模块以及将发送模块输出的 Rs232_Tx 连接到接收模块上的 Rs232_Rx即可。修改后的部分激励文件如下: wire Rs232_Tx; uart_byte_rx uart_byte_rx( .Clk(Clk), .Rst_n(Rst_n), .baud_set(baud_set), .Rs232_Rx(Rs232_Tx), .data_byte(data_byte_r), .Rx_Done(Rx_Done) ); uart_byte_tx uart_byte_tx( .Clk(Clk), .Rst_n(Rst_n), .data_byte(data_byte_t), .send_en(send_en), .baud_set(baud_set), .Rs232_Tx(Rs232_Tx), .Tx_Done(Tx_Done), .uart_state(uart_state) );设置好仿真脚本后进行功能仿真,可以看到如图 17.5 所示的波形文件,每当一个字节发送结束后,数据输出 data_byte_r 均会更新输出一次。下图中由于 Rs232_Rx 仅声明了但并未调用,因此无数据显示,可以直接删除。 图片 与上一章不同,这里使用 ISSP 的探针功能,对本次数据接收模块进行板级调试与验证。其主要配置如图 17.6 所示,并加入到工程中。 图片 新建一个顶层文件 uart_rx_top.v,这里例化数据接收模块以及 ISSP 工具。只有接收成功后才采集下一次数据,符合实际使用情况。 module uart_rx_top(Clk,Rst_n,Rs232_Rx); input Clk; input Rst_n; input Rs232_Rx; reg [7:0]data_rx_r; wire [7:0]data_rx; wire Rx_Done; uart_byte_rx uart_byte_rx( .Clk(Clk), .Rst_n(Rst_n), .baud_set(3'd0), .Rs232_Rx(Rs232_Rx), .data_byte(data_rx), .Rx_Done(Rx_Done) ); issp issp( .probe(data_rx_r) ); always@(posedge Clk or negedge Rst_n) if(!Rst_n) data_rx_r <= 8'd0; else if(Rx_Done) data_rx_r <= data_rx; else data_rx_r <= data_rx_r; endmodule分配引脚并全编译无误后下载工程到开发板中。在 Quartus Prime 中点击 Tools→InSystem Source and Probes Editor 启动 ISSP,手动选择下载器后,并将数据格式改为设计中的 hex 格式,持续触发模式。打开电脑上的串口助手,将主要参数设置为:波特率为 9600、无校验位、8 位数据位以及 1bit 停止位。 图片 图 17.8 ISSP 工具设置界面在串口助手上先后输入 aa、38 后在 ISSP 使用界面可以看到 Data 会随之对应变化。可知设计无误。 图片 本章学习了串口接收的相关原理,在设计过程中针对工业现场的强电磁干扰等问题,提出了一种基于权重的改进型数据接收方式。并在板级调试中使用了 ISSP 中的探针功能(probe)。 在本章实验的基础上,可以将接收到的数据在 4 位 LED 或者数码管上进行更直观的显示。 代码工程 串口接收 下载地址:https://wwek.lanzoub.com/iEZDG0j3flaj 提取码:
FPGA&ASIC
# 小实验
刘航宇
4年前
0
780
0
2022-12-18
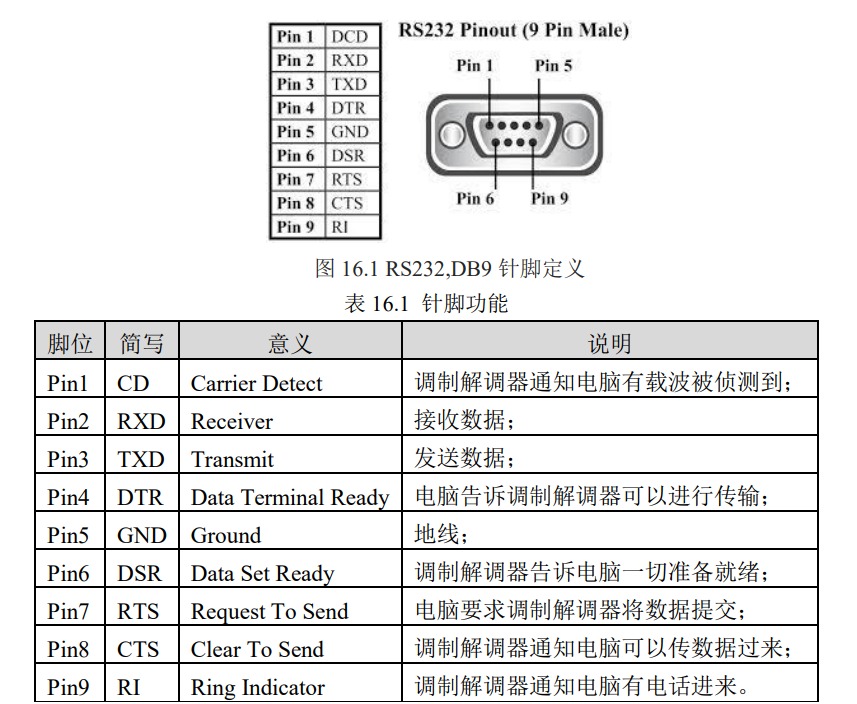
【FPGA】深度理解串口发送模块设计与验证
本章导读 在当今的电子系统中,经常需要板内、板间或者下位机与上位机之间进行数据的发送与接收,这就需要双方共同遵循一定的通信协议来保证数据传输的正确性。常见的协议有UART(通用异步收发传输器)、IIC(双向两线总线)、SPI(串行外围总线)、USB2.0/3.0(通用串行总线)以及 Ethernet(以太网)等。在这些协议当中,最为基础的就是 UART,因其电路结构简单、成本较低,所以在注重性价比的情况下,使用非常广泛。 本章将学习 UART 通信的原理及其硬件电路设计,并使用 FPGA 来实现 UART 通信中的数据发送部分设计。在仿真验证时除进行正常的功能仿真以外,还将在 Quartus Prime 中使用 In system sources and probes editor(ISSP)工具进行板级验证,具体方法是:输入需要通过串口发送出去的数据,然后通过按下 AC620 开发板上的按键来控制 FPGA 将待发送的数据发送出去,并在串口助手中查看 PC 端接收到的数据。 目录 本章导读 异步串行通信原理及电路设计RS232 通信接口标准 UART 关键参数及时序图 RS232 通信电路设计 UART 异步串行通信发送模块设计与实现串口发送模块接口设计 波特率时钟生成模块设计 数据输出模块设计 数据传输状态控制模块设计 激励创建及仿真测试 按键控制串口发送设计 代码工程 异步串行通信原理及电路设计 RS232 通信接口标准 通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)是一种异步收发传输器,其在数据发送时将并行数据转换成串行数据来传输,在数据接收时将接收到的串行数据转换成并行数据,可以实现全双工传输和接收。它包括了 RS232、RS449、RS423、RS422 和 RS485 等接口标准规范和总线标准规范。换句话说,UART 是异步串行通信的总称。而 RS232、RS449、RS423、RS422 和 RS485 等,是对应各种异步串行通信口的接口标准和总线标准,它们规定了通信口的电气特性、传输速率、连接特性和接口的机械特性等内容。 本章要重点学习的 RS-232 是美国电子工业联盟(EIA)制定的串行数据通信的接口标准,原始编号全称是 EIA-RS-232(简称 232,RS232),被广泛用于计算机串行接口外设连接。其 DB9 接口的针脚定义如图 16.1 所示,引脚功能如表 16.1 所示。若系统存在多个 UART接口,则可分别称为 COM1、COM2 等。 图片 UART 关键参数及时序图 UART 通信在使用前需要做多项设置,最常见的设置包括数据位数、波特率大小、奇偶校验类型和停止位数。 数据位(Data bits):该参数定义单个 UART 数据传输在开始到停止期间发送的数据位数。可选择为:5、6、7 或者 8(默认)。 波特率(Baud):是指从一设备发到另一设备的波特率,即每秒钟可以通信的数据比特个数。典型的波特率有 300, 1200, 2400, 9600, 19200, 115200 等。一般通信两端设备都要设为相同的波特率,但有些设备也可设置为自动检测波特率。 奇偶校验类型(Parity Type):是用来验证数据的正确性。奇偶校验一般不使用,如果使用,则既可以做奇校验(Odd)也可以做偶校验(Even)。在偶校验中,因为奇偶校验位会被相应的置 1 或 0(一般是最高位或最低位),所以数据会被改变以使得所有传送的数位(含字符的各数位和校验位)中“1”的个数为偶数;在奇校验中,所有传送的数位(含字符的各数位和校验位)中“1”的个数为奇数。奇偶校验可以用于接受方检查传输是否发送生错 误,如果某一字节中“1”的个数发生了错误,那么这个字节在传输中一定有错误发生。如果奇偶校验是正确的,那么要么没有发生错误,要么发生了偶数个的错误。如果用户选择数据长度为 8 位,则因为没有多余的比特可被用来作为奇偶校验位,因此就叫做“无奇偶校验(Non)”。 停止位(Stop bits):在每个字节的数据位发送完成之后,发送停止位,来标志着一次数据传输完成,同时用来帮助接受信号方硬件重同步。可选择为:1(默认)、1.5 或者 2 位。 在 RS-232 标准中,最常用的配置是 8N1(即八个数据位、无奇偶校验、一个停止位),其发送一个字节时序图如图 16.2 所示。 按照一个完整的字节包括一位起始位、8 位数据位、一位停止位即总共十位数据来算,要想完整的实现这十位数据的发送,就需要 11 个波特率时钟脉冲,第 1 个脉冲标记一次传输的起始,第 11 个脉冲标记一次传输的结束,如下所示: 图片 RS232 通信电路设计 RS232 通信协议需要一定的硬件支持,早期大多使用的方案是 RS232 转 TTL,这时需要 MAX232 或者 SP3232 等电平转换芯片来做数据转换。其外围电路简单,最少只需要 4 个电容即可正常工作,其典型电路图如 16.3 所示。在这里只使用了两路通信中的一路,且通过加入的 D7、D8 两个发光二极管可以更好的观察数据状态。 图片 现在系统集成度越来越高,DB9 的 RS232 接口占用 PCB 面积过大,多数系统已经转用USB 转 TTL,其电路图如图 16.4 所示。 图片 CH340G 是一个支持 5V 或 3.3V 供电的 USB 总线的转接芯片,实现 USB 转串口、USB 转 IrDA 红外或者 USB 转打印口。支持硬件全双工串口、内置收发缓冲区,支持通讯波特率 50bps~2Mbps 并支持常用的 MODEM 联络信号 RTS、DTR、DCD、RI、DSR、CTS。 并可通过外加电平转换器件,可以提供 RS232、RS485、RS422 等接口。在 Windows 操作系统下,CH340 的驱动程序能够仿真标准串口,所以与绝大部分原串口应用程序完全兼容,不需要作任何修改。 UART 异步串行通信发送模块设计与实现 串口发送模块接口设计 基于上述原理,本章要实现的串口发送模块整体框图,如图 16.9 所示,其接口列表如表 16.2 所示。 图片 根据功能需求,串口发送模块可进一步细化为如图 16.10 所示详细结构图,其中每一子模块的作用如表 16.3 所示。其中绿色的框代表单一结构的寄存器,来实现数据的稳定输入以及输出。 图片 图片 波特率时钟生成模块设计 从原理部分可知,波特率是 UART 通信中需要设置的参数之一。在波特率时钟生成模块中,计数器需要的计数值与波特率之间的关系如表 16.4 所示,其中系统时钟周期为System_clk_period,这里为 20ns。如果接入到该模块的时钟频率为其他值,需要根据具体的频率值修改该参数。 图片 本模块的设计是为了保证模块的复用性。当需要不同的波特率时,只需设置不同的波特率时钟计数器的计数值。使用查找表即可实现,下面的设计代码中只包含了针对 5 个波特率的设置,如需要其他波特率可根据实际使用情况具体修改。 reg [15:0]bps_DR;//分频计数最大值 always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_DR <= 16'd5207; else begin case(baud_set) 0:bps_DR <= 16'd5207; //9600bps 1:bps_DR <= 16'd2603; //19200bps 2:bps_DR <= 16'd1301; //38400bps 3:bps_DR <= 16'd867; //57600bps 4:bps_DR <= 16'd433; //115200bps default:bps_DR <= 16'd5207; endcase end利用计数器来生成波特率时钟。 reg bps_clk; //波特率时钟 reg [15:0]div_cnt;//分频计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) div_cnt <= 16'd0; else if(uart_state)begin if(div_cnt == bps_DR) div_cnt <= 16'd0; else div_cnt <= div_cnt + 1'b1; end else div_cnt <= 16'd0; always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_clk <= 1'b0; else if(div_cnt == 16'd1) bps_clk <= 1'b1; else bps_clk <= 1'b0;所谓波特率生成,就是用一个定时器来定时,产生频率与对应波特率时钟频率相同的时钟信号。例如,我们使用波特率为 115200bps,则我们需要产生一个频率为 115200Hz 的时钟信号。那么如何产生这样一个 115200Hz 的时钟信号呢?这里,我们首先将 115200Hz 时钟信号的周期计算出来,1 秒钟为 1000_000_000ns,因此波特率时钟的周期 Tb= 1000000000/115200 =8680.6ns,即115200信号的一个周期为8680.6ns,那么,我们只需要设定我们的定时器定时时间为8680.6ns,每当定时时间到,产生一个系统时钟周期长度的高脉冲信号即可。系统时钟频率为 50MHz,即周期为 20ns,那么,我们只需要计数 8680/20 个系统时钟,就可获得 8680ns 的定时,bps115200=Tb/Tclk - 1=Tb*fclk - 1=fclk/115200-1。相应的,其它波特率定时值的计算与此相同为了能够通过外部控制波特率,设计中使用了一个 3 位的波特率选择端口:Baud_Set。通过给此端口不同的值,就能选择不同的波特率,此端口控制不同波特率的原理很简单,就是一个多路选择器,多路选择器通过选择不同的定时器计数最大值来设置不同的比特率时钟频率。 Baud_Set 的值与各波特率的对应关系如下: 000 : 9600bps; 001 : 19200bps; 010 :38400bps; 011 :57600bps; 100 :115200bps; 数据输出模块设计 通过对波特率时钟进行计数,来确定数据发送的循环状态。 reg [3:0]bps_cnt;//波特率时钟计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) bps_cnt <= 4'd0; else if(bps_cnt == 4'd11) bps_cnt <= 4'd0; else if(bps_clk) bps_cnt <= bps_cnt + 1'b1; else bps_cnt <= bps_cnt;同样为了使得模块可以对其他模块进行控制或者调用,这里产生一个 byte 传送结束的信号。一个数据位传输结束后 Tx_done 信号输出一个时钟的高电平。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) Tx_Done <= 1'b0; else if(bps_cnt == 4'd11) Tx_Done <= 1'b1; else Tx_Done <= 1'b0;产生数据传输状态信号,即当在正常传输的时候 uart_state 信号为高电平,其他情况均为低电平。这里实现的电路结构同样是具有优先级顺序的,但与 C 语言本质是不同的。在图16.10 中的 MUX2_1 与 MUX2_2 就是下面的设计实现的 if—else if—else 的电路结构。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) uart_state <= 1'b0; else if(send_en) uart_state <= 1'b1; else if(bps_cnt == 4'd11) uart_state <= 1'b0; else uart_state <= uart_state;由于 RS232 是一个异步的收发器,因此为了保证发送的数据在时钟到来的时候是稳定的,这里也需要对输入数据进行寄存。 reg [7:0]r_data_byte; always@(posedge Clk or negedge Rst_n) if(!Rst_n) r_data_byte <= 8'd0; else if(send_en) r_data_byte <= data_byte; else r_data_byte <= r_data_byte;数据传输状态控制模块设计 在模块结构图 16.10 中还有一个十选一多路器 ,作用是根据 bps_cnt 的值来确定数据传输的状态。如时序图 16.2 所示,在不同的波特率时钟计数值时,有对应的传输数据。 localparam START_BIT = 1'b0; localparam STOP_BIT = 1'b1; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Rs232_Tx <= 1'b1; else begin case(bps_cnt) 0:Rs232_Tx <= 1'b1; 1:Rs232_Tx <= START_BIT; 2:Rs232_Tx <= r_data_byte[0]; 3:Rs232_Tx <= r_data_byte[1]; 4:Rs232_Tx <= r_data_byte[2]; 5:Rs232_Tx <= r_data_byte[3]; 6:Rs232_Tx <= r_data_byte[4]; 7:Rs232_Tx <= r_data_byte[5]; 8:Rs232_Tx <= r_data_byte[6]; 9:Rs232_Tx <= r_data_byte[7]; 10:Rs232_Tx <= STOP_BIT; default:Rs232_Tx <= 1'b1; endcase end激励创建及仿真测试 完成设计之后,需要对其进行功能仿真。在下面的 testbench 文件中,生成了复位信号以及使能信号、待传输数据。这里将所有数据变化与系统时钟错开 1ns,是为了能更清楚看到输入输出数据与时钟的时序关系。 initial begin Rst_n = 1'b0; data_byte = 8'd0; send_en = 1'd0; baud_set = 3'd4; #(`clk_period*20 + 1 ) Rst_n = 1'b1; #(`clk_period*50); data_byte = 8'haa; send_en = 1'd1; #`clk_period; send_en = 1'd0; @(posedge Tx_Done) #(`clk_period*5000); data_byte = 8'h55; send_en = 1'd1; #`clk_period; send_en = 1'd0; @(posedge Tx_Done) #(`clk_period*5000); $stop; end设置好仿真脚本后进行功能仿真,得到如图 16.11 所示的波形文件,可以看出在复位信号置高以及使能信号有效之前输出信号 Rs232_Tx 均为 0,在复位结束以及使能后输出信号才开始正常,且当输入数据为 10101010b(MSB)后,输出信号依次为 1、0(起始位)、01010101b(LSB)、1(停止位);当输入数据为 01010101b(MSB)后,输出信号依次为 1、0(起始位)、10101010b(LSB)、1(停止位)。同时 uart_state 处于发送状态时为 1,即仿真通过。 图片 按键控制串口发送设计 为了实现导读中所设定的目标,将以前编写好的按键消抖模块添加到工程当中,并再次使用 ISSP,其主要参数配置如图 16.12 所示,并加入到工程中。 图片 然后,新建一个顶层文件,并将按键消抖、串口发送以及 ISSP 例化,并将按键状态与串口发送使能端连接即可。部分设计如下所示,并将串口发送状态连接到 LED 上,以更好的观察数据发送状态。 assign send_en = key_flag0 & !key_state0; uart_byte_tx uart_byte_tx( .Clk(Clk), .Rst_n(Rst_n), .data_byte(data_byte), .send_en(send_en), .baud_set(3'd0), .Rs232_Tx(Rs232_Tx), .Tx_Done(), .uart_state(led) );编译无误后,点击 RTL_viewer 可以看到如图 16.13 的各模块连接图。 图片 分配引脚并全编译无误后下载工程到 AC620 开发板中。然后,在 Quartus Prime 中点击Tools→In-System Source and Probes Editor 启动 ISSP,手动选择下载器后,并将数据格式改为设计中的 hex 格式。打开电脑上的串口助手,将主要参数设置为:波特率为 9600、无校验位、8 位数据位以及 1bit 停止位。 在 Quartus Prime 中,使用 In system sources and probes editor 工具,输入需要通过串口发送出去的数据,然后按下学习板上的按键 0,FPGA 自动将所需要发送的数据发送出去,即可在串口助手中看到相关数据。且板载的 LED_RX 每接收一 byte 数据均会亮一下,这里由于时钟较快,数据传输过程很快,因此代表传输状态的 led0 看着“常亮”。 图片 至此,完成了基于 FPGA 的串口通信发送部分实现。 在本章中学习了 UART 的分类以及原理,介绍了 RS232 协议的数据格式以及相关参数所代表的含义,并设计了串口的硬件电路,且在板级调试中再次使用了 ISSP 中的源功能(source)。 代码工程 代码下载 下载地址:https://wwek.lanzoub.com/ijx1z0izahvc 提取码:
FPGA&ASIC
# 小实验
刘航宇
4年前
0
1,121
1
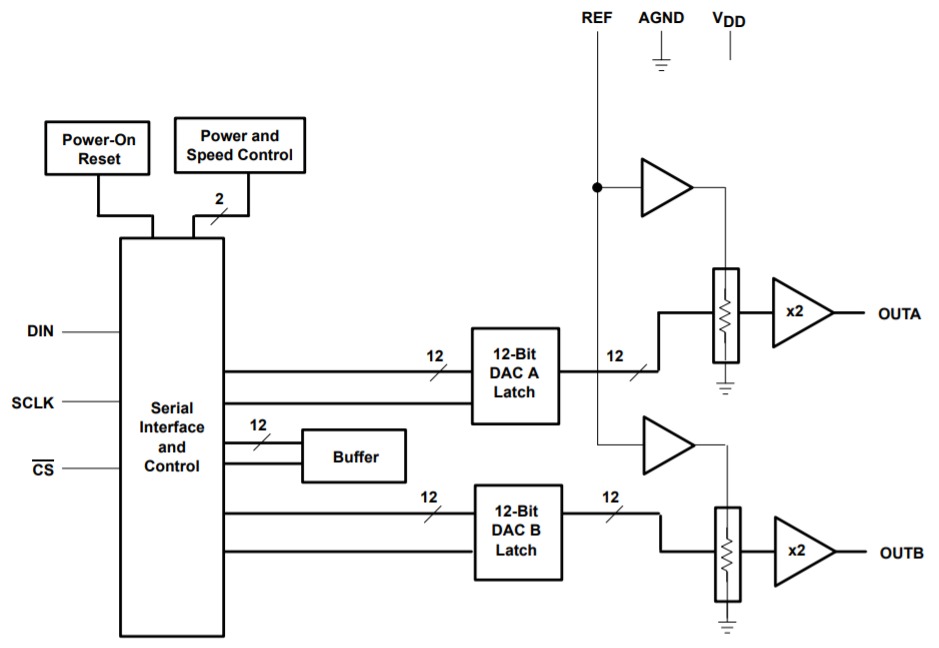
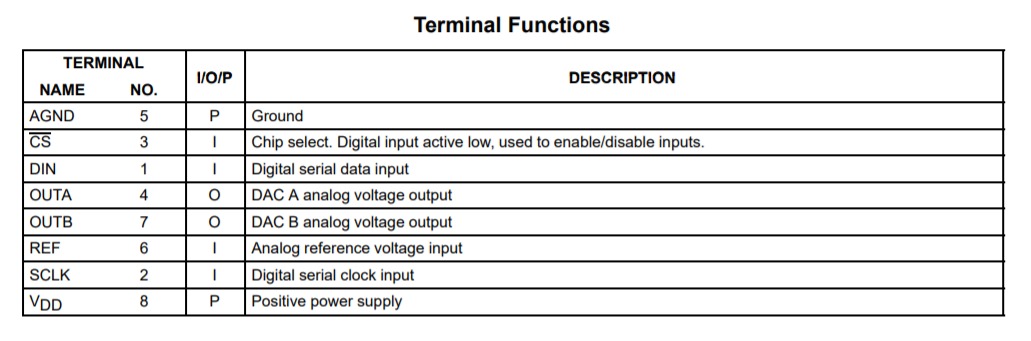
【FPGA】【SPI】线性序列机与串行接口 DAC 驱动设计与验证
概述:ADC和DAC是FPGA与外部信号的接口,从数据接口类型的角度划分,有低速的串行接口和高速的并行接口。FPGA经常用来采集中高频信号,因此使用并行ADC和DAC居多。并行接口包括两种数字编码方式:带符号数signed与无符号数unsigned。 DAC DA转化一般将数字信号“010101”转化为模拟信号去控制其它电子设备。 导读: 数模转换器即 D/A 转换器,或简称 DAC(Digital to Analog Conver),是指将数字信号转变为模拟信号的电子元件。 DAC 的内部电路构成无太大差异,一般按输出是电流还是电压、能否作乘法运算等进行分类。大多数 DAC 由电阻阵列和 n 个电流开关(或电压开关)构成,按数字输入值切换开关,产生比例于输入的电流(或电压) 。此外,也有为了改善精度而把恒流源放入器件内部的。 DAC 可分为电压型和电流型两大类,电压型 DAC 有权电阻网络、T 型电阻网络和树形开关网络等;电流型 DAC 有权电流型电阻网络和倒 T 型电阻网络等。 电压输出型(如 TLV5618) 。电压输出型 DAC 虽有直接从电阻阵列输出电压的,但一般采用内置输出放大器以低阻抗输出。直接输出电压的器件仅用于高阻抗负载,由于无输出放大器部分的延迟,故常作为高速 DAC 使用。 电流输出型(如 THS5661A ) 。电流输出型 DAC 很少直接利用电流输出,大多外接电流- 电压转换电路得到电压输出,后者有两种方法:一是只在输出引脚上接负载电阻而进行电流- 电压转换,二是外接运算放大器。 乘算型(如 AD7533) 。DAC 中有使用恒定基准电压的,也有在基准电压输入上加交流信号的,后者由于能得到数字输入和基准电压输入相乘的结果而输出,因而称为乘算型 DAC。 乘算型 DAC 一般不仅可以进行乘法运算,而且可以作为使输入信号数字化地衰减的衰减器及对输入信号进行调制的调制器使用。 一位 DAC。一位 DAC 与前述转换方式全然不同,它将数字值转换为脉冲宽度调制或频率调制的输出,然后用数字滤波器作平均化而得到一般的电压输出,用于音频等场合。 本章以 TLV5618 为例介绍 DAC 的工作原理及时序图解释,并用线性序列机(LSM)来描述时序图进而正确驱动此类设备。在 Quartus Pime 软件中,使用 ISSP 工具输入希望输出的电压值,控制 FPGA 进而操作 TLV5618 芯片输出对应的电压值。 任务 使用FPGA芯片控制DAC采集芯片,输出指定的电压值。 硬件部分 为了将FPGA输出的数字电压转换成模拟电压,使用到了数模转换芯片(简称DAC)TLV5618。进行设计前, 需要查看该芯片的数据手册 。 1.芯片功能图 本章使用的 DAC 芯片为 TLV5618,其芯片内部结构如图所示。TLV5618 是一个基于电压输出型的双通道 12 位单电源数模转换器,其由串行接口、一个速度和电源控制器、电阻网络、轨到轨输出缓冲器组成。 图片 TLV5618 使用 CMOS 电平兼容的三线制串行总线与各种处理器进行连接,接收控制器发送的 16 位的控制字,这 16 位的控制字被分为 2 个部分,包括 4 位的编程位,12 位的数据位。 2.端口功能表 图片 从功能图和功能表中我们可以看出,TLV5618有四个输入端口: 片选信号CS、数据串行输入端口DIN、模拟参考电压REF、数字时钟SCLK。 两个输出端分别为OUTA和OUTB,均为对应的模拟电压输出端。 3.时序图 当片选(CS)信号为低电平时,输入数据以最高有效位在前的方式被读入 16 位移位寄存器。在 SCLK 输入信号的下降沿,把数据移入寄存器 A、B。当片选(CS)信号进入上升沿时,再把数据送至 12 位 A/D 转换器。 图片 从时序图中我们可以看到使用该芯片时要注意这几个参数: tw(L):低电平最小宽度,25ns。 tw(H):高电平最小宽度,25ns。 tsu(D):数据最短建立时间。 th(D):数据最短保持时间。 tsu(CS-CK):片选信号下降沿到第一个时钟下降沿最短时间。 th(CSH):片选信号最短拉高时间。 TLV5618 的 16 位数据格式如下: 图片 其中,SPD 为速度控制位,PWR 为电源控制位。上电时,SPD 和 PWR 复位到 0(低速模式和正常工作)。 图片 R1 与 R0 所有可能的组合以及代表的含义如下所示。如果其中一个寄存器或者缓冲区被选择,那么 12 位数据将决定新的 DAC 输出电压值。 图片 这样针对 D[15:12]不同组合构成的典型操作如下: 1)设置 DAC A 输出,选择快速模式:写新的 DAC A 的值,更新 DAC A 输出。DAC A 的输出在 D0 后的时钟上升沿更新。 图片 2)设置 DAC B 输出,选择快速模式: 写新的 DAC B 的值到缓冲区,并且更新 DAC B 输出。DAC B 的输出在 D0 后的时钟上升沿更新。 图片 3) 设置 DAC A、DAC B 的值,选择低速模式:在写 DAC A 的数据 D0 后的时钟上升沿 DAC A 和 B 同时更新输出。 a.写 DAC B 的数据到缓冲区: 图片 b.写新的 DAC A 的值并且同时更新 DAC A 和 B: 图片 4) 设置掉电模式:×=不关心 图片 4.输出电压计算 图片 图片 由手册给出的公式知,输出电压与输入的编码值成正比,同时还要乘以一个系数REF,这个系数从芯片的REF引脚输入。我们打开并查看开发板的原理图:其中参考电压为由 LM4040 提供的 2.048V,与FPGA 采用三线制 SPI 通信。 图片 从图中知,我们用到了芯片LM4040-2.0给DAC供电,这个芯片工作时输出电压为4.028V(即精度为12位),故参数REF为4.028。 5.时钟频率与刷新率计算 图片 我们查阅手册后知道,使用该芯片时,时钟最大频率为20MHz,刷新率为时钟频率的1/16。而开发板提供的原始时钟为50MHz,因此可以采用四分频后得到12.5MHz的时钟频率。 线性序列机设计思想与接口时序设计 从图 24.3 中可以看出,该接口的时序是一个很有规律的序列,SCLK 信号什么时候该由变高,什么时候由高变低。DIN 信号什么时候该传输哪一位数据,都是可以根据时序参数唯一确定下来的。 这样就可以将该数据波形放到以时间为横轴的一个二维坐标系中,纵轴就是每个信号对应的状态: 图片 因此只需要在逻辑中使用一个计数器来计数,然后每个计数值时就相当于在 t 轴上对应了一个相应的时间点,那么在这个时间点上,各个信号需要进行什么操作,直接赋值即可。 经查阅手册可知器件工作频率SCLK最大为20MHz,这里定义其工作频率为12.5MHz。设置一个两倍于 SCLK 的采样时钟 SCLK2X,使用 50M 系统时钟二分频而来即 SCLK2X 为25MHz。针对 SCLK2X 进行计数来确定图 24.4 中各个信号的状态。可得出每个时间点对应信号操作详表。 图片 图片 线性序列机计数器的控制逻辑判断依据,如表 24.7 所示。 图片 以上就是通过线性序列机设计接口时序的一个典型案例,可以看到,线性序列机可以大大简化设计思路。线性序列机的设计思想就是使用一个计数器不断计数,由于每个计数值都会对应一个时间,那么当该时间符合需要操作信号的时刻时,就对该信号进行操作。这样,就能够轻松的设计出各种时序接口了。 基于线性序列机的 DAC 驱动设计 模块接口设计 设计 TLV5618 接口逻辑的模块如图 24.8 所示。 图片 其中,每个端口的功能描述如表 24.6 所示。 表 24.6 模块端口功能描述 图片 生成使能信号,当输入使能信号有效后便将使能信号 en 置 1,当转换完成信号有效时便将其重新置 0。 reg en;//转换使能信号 always@(posedge Clk or negedge Rst_n) if(!Rst_n) en <= 1'b0; else if(Start) en <= 1'b1; else if(Set_Done) en <= 1'b0; else en <= en;在数据手册中SCLK的频率范围为0.8~3.2MHz。这里为了方便适配不同的频率需求率,设置了一个可调的计数器,改变 DIV_PARAM 的值即可改变 DAC 工作频率。根据表 中可以看出,需要根据计数器的值周期性的产生 SCLK 时钟信号,这里可以将计数器的值等倍数放大,形成过采样。这里产生一个两倍于 SCLK 的信号,命名为 SCLK2X。 首先编写分频计数器,时钟 SCLK2X 的计数器。 //生成 2 倍 SCLK 使能时钟计数器 reg [7:0]DIV_CNT;//分频计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) DIV_CNT <= 4'd0; else if(en)begin if(DIV_CNT == (DIV_PARAM - 1'b1))//2-1=1,cnt=0,25MHZ,cnt=1为12.5MHZ DIV_CNT <= 4'd0; else DIV_CNT <= DIV_CNT + 1'b1; end else DIV_CNT <= 4'd0;根据使能信号以及计数器状态生成 SCLK2X 时钟。 //生成 2 倍 SCLK 使能时钟计数器 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK2X <= 1'b0; else if(en && (DIV_CNT == (DIV_PARAM - 1'b1))) SCLK2X <= 1'b1; else SCLK2X <= 1'b0;每当使能转换后,对 SCLK2X 时钟进行计数。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) SCLK_GEN_CNT <= 6'd0; else if(SCLK2X && en)begin if(SCLK_GEN_CNT == 6'd32) SCLK_GEN_CNT <= 6'd0; else SCLK_GEN_CNT <= SCLK_GEN_CNT + 1'd1; end else SCLK_GEN_CNT <= SCLK_GEN_CNT;根据 SCLK2X 计数器的值来确认工作状态以及数据传输进程。 //依次将数据移出到 DAC 芯片 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin DIN <= 1'b1; SCLK <= 1'b0; r_DAC_DATA <= 16'd0; end else begin if(Start)//收到开始发送命令时,寄存 DAC_DATA 值 r_DAC_DATA <= DAC_DATA; if(!Set_Done && SCLK2X) begin if(!SCLK_GEN_CNT[0])begin //偶数, 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30: SCLK <= 1'b1; DIN <= r_DAC_DATA[15]; r_DAC_DATA <= #1 r_DAC_DATA << 1; end else //奇数, 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31: SCLK <= 1'b0; end endDAC 工作状态,处于数据传输状态时 CS_N 为低电平状态,空闲时为高。 always@(posedge Clk or negedge Rst_n) if(!Rst_n) CS_N <= 1'b1; else if(en && SCLK2X) CS_N <= SCLK_GEN_CNT[5]; else CS_N <= CS_N;一次转换结束的标志,即 SCLK_GEN_CNT[5] && SCLK2X,并产生一个高脉冲的转换完成标志信号 Set_Done。 assign Set_Done = SCLK_GEN_CNT[5] && SCLK2X;仿真及板级测试 这里仿真文件需输出几次并行数据,观测串行数据输出 DIN 的状态即可判断是否能驱动正常。这里输出四次数据分别为 C_AAAh、4_555h、1_555h、F_555h。部分代码如下,只写出了前两个数据,后面两个可直接复制修改即可。 initial begin Rst_n = 0; Start = 0; DAC_DATA = 0; #201; Rst_n = 1; #200; DAC_DATA = 16'hC_AAA; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h4_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); $stop; end开始仿真后,可看出人为控制 DAC_DATA 数据输入状态正常。 图片 放大第一个数据传输过程,可以看出正常 1100_1010_1010_1010b,计数器计数到'd32 符合设计要求,且每个传输过程中 CS_N 为低。传输完成后产生一个时钟周期的 Set_Done 标志信号。 图片 为了再次验证 TLV5618 驱动模块设计的正确性,使用 ISSP 在线调试工具。创建一个 ISSPIP 核,主要配置如图 24.7 所示。 图片 加入工程后新建顶层文件 DAC_test.v,并对 ISSP 以及设计好的 TLV5618 进行例化. 在接口时序介绍中指出,TLV5618 有三种更新输出电压方式,下面分别测试这三种电压更新方式。上电复位后两通道输出电压初始值均为 0V。 1.单独测试 A 通道,依次输入 CFFFh、C7FFh、C1FFh,理论输出电压值应为 4.096、2.048、0.512。可在通道 A 测量输出电压依次为 4.10、2.05、0.51,此时通道 B 电压一直保持 0,电压输出在误差允许范围内。 2.单独测试 B 通道,依次输入 4FFFh、47FFh、4000h,可在通道 B 测量输出电压依次为4.10、2.05、0。此时通道 A 电压一直保持 0.51,电压输出在误差允许范围内。 3.测量 AB 两通道同时更新,首先输入 1FFF 将数据写入通道 B 寄存器,再写入 8FFF 到通道 A 寄存器。这样可以测量出写完后会两个通道输出电压会同时变为 4.10。 通过以上三组测试数据的,可以发现 DAC 芯片输出电压数据更新正常。 这样就完成了一个 DAC 模块的设计与仿真验证,基于本讲以及 14 讲即可实现信号发 生器,详细内容可以参考第五篇中的进阶课程 DDS2。 设计工程 图片 我们考虑用FPGA设计一个DAC驱动,通过CS、sclk、din三根信号线与DAC芯片连接,设计输入端口Data[15:0]。同时为了便于与其他模块共同协作,我们加上了使能端口en和转换完成标志位Conv_done,这是FPGA设计时必须考虑的一点,对于复杂的驱动模块,这两个信号是不可或缺的。 软件部分 //驱动部分 module tlv5618( Clk, Rst_n, DAC_DATA, //并行数据输入端 Start,//开始标志位 Set_Done,//完成标志位 DAC_CS_N,//片选 DAC_DIN,//串行数据送给ADC芯片 DAC_SCLK,//工作时钟SCLK DAC_State//工作状态 ); parameter fCLK=50;//50MHZ时钟参数 parameter DIV_PARAM=2;//分频参数 input Clk; input Rst_n; input[15:0] DAC_DATA; input Start; output reg Set_Done; output reg DAC_CS_N; output reg DAC_DIN; output reg DAC_SCLK; output DAC_State; assign DAC_State=DAC_CS_N;//工作状态标志与片选信号相同 reg [15:0] r_DAC_DATA;//DAC数据寄存器 reg[3:0] DIV_CNT;//分频计数器 reg SCLK2X;//2倍SCLK的采样时钟 reg[5:0] SCLK_GEN_CNT;//SCLK生成暨序列机计数器 reg en; wire trans_done;//转化序列完成标志信号 always @(posedge Clk or negedge Rst_n) begin if(!Rst_n) en<=1'b0; else if(Start) en<=1'b1; else if(trans_done) en<=1'b0;//转换完成后将使能关闭 else if(treans_done) en<=1'b0;//转换完成后将使能关闭 else en<en; end //分频计数器 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) DIV_CNT<=4'd0; else if(en)begin if(DIV_CNT==(DIV_PARAM-1'b1))//前面设置了分频系数为2,这里计数器能够容纳2拍时钟脉冲 DIV_CNT<=4'b0; else DIV_CNT<=DIV_CNT+1'b1; end else DIV_CNT<=4'd0; end //二分频 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) SCLK2X<=1'b0; else if(en && (DIV_CNT==(DIV_PARAM-1'b1))) SCLK2X<=1'b1; else SCLK2X<=1'b0; end //生成序列计数器,对SCLK脉冲进行计数 always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) SCLK_GEN_CNT<=6'd0; else if(SCLK2X && en)begin//在高脉冲期间,累计拍数 if(SCLK_GEN_CNT==6'd33) SCLK_GEN_CNT<=6'd0; else SCLK_GEN_CNT<=SCLK_GEN_CNT+1'd1; end else SCLK_GEN_CNT<=SCLK_GEN_CNT; end always@(posedge Clk or negedge Rst_n)begin if(!Rst_n) r_DAC_DATA<=16'd0; else if(Start) //收到开始发送命令时候,寄存DAC_DATA值 r_DAC_DATA<=DAC_DATA; else r_DAC_DATA<=r_DAC_DATA; end //依次将数据移出到DAC芯片 always@(posedge Clk or negedge Rst_n) if(!Rst_n)begin DAC_DIN<=1'b1; DAC_SCLK<=1'b0; DAC_CS_N<=1'b1; end else if(!Set_Done && SCLK2X)begin case(SCLK_GEN_CNT) 0: begin //高脉冲期间内,计数为0时了,打开片选使能,给予时钟上升沿,将最高位数据送给DAC芯片 DAC_CS_N <= 1'b0; DAC_DIN <= r_DAC_DATA[15]; DAC_SCLK <= 1'b1; end 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31: begin DAC_SCLK <= 1'b0; //时钟低电平 end 2: begin DAC_DIN <= r_DAC_DATA[14]; DAC_SCLK <= 1'b1; end 4: begin DAC_DIN <= r_DAC_DATA[13]; DAC_SCLK <= 1'b1; end 6: begin DAC_DIN <= r_DAC_DATA[12]; DAC_SCLK <= 1'b1; end 8: begin DAC_DIN <= r_DAC_DATA[11]; DAC_SCLK <= 1'b1; end 10: begin DAC_DIN <= r_DAC_DATA[10]; DAC_SCLK <= 1'b1; end 12: begin DAC_DIN <= r_DAC_DATA[9]; DAC_SCLK <= 1'b1; end 14: begin DAC_DIN <= r_DAC_DATA[8]; DAC_SCLK <= 1'b1; end 16: begin DAC_DIN <= r_DAC_DATA[7]; DAC_SCLK <= 1'b1; end 18: begin DAC_DIN <= r_DAC_DATA[6]; DAC_SCLK <= 1'b1; end 20: begin DAC_DIN <= r_DAC_DATA[5]; DAC_SCLK <= 1'b1; end 22: begin DAC_DIN <= r_DAC_DATA[4]; DAC_SCLK <= 1'b1; end 24: begin DAC_DIN <= r_DAC_DATA[3]; DAC_SCLK <= 1'b1; end 26: begin DAC_DIN <= r_DAC_DATA[2]; DAC_SCLK <= 1'b1; end 28: begin DAC_DIN <= r_DAC_DATA[1]; DAC_SCLK <= 1'b1; end 30: begin DAC_DIN <= r_DAC_DATA[0]; DAC_SCLK <= 1'b1; end 32: DAC_SCLK <= 1'b1; //时钟拉高 33: DAC_CS_N <= 1'b1; //关闭片选 default:; endcase end assign trans_done = (SCLK_GEN_CNT == 33) && SCLK2X; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Set_Done <= 1'b0; else if(trans_done) Set_Done <= 1'b1; else Set_Done <= 1'b0; endmodule//顶层模块 module DAC_test( Clk,//模块时钟50M Rst_n,//模块复位 DAC_CS_N, //TLV5618的CS_N接口 DAC_DIN, //TLV5618的DIN接口 DAC_SCLK //TLV5618的SCLK接口 ); input Clk; input Rst_n; output DAC_CS_N; output DAC_DIN; output DAC_SCLK; reg Start; reg [15:0]r_DAC_DATA; wire DAC_State; wire [15:0]DAC_DATA; wire Set_Done; tlv5618 tlv5618( .Clk(Clk), .Rst_n(Rst_n), .DAC_DATA(DAC_DATA), .Start(Start), .Set_Done(Set_Done), .DAC_CS_N(DAC_CS_N), .DAC_DIN(DAC_DIN), .DAC_SCLK(DAC_SCLK), .DAC_State(DAC_State) ); always@(posedge Clk or negedge Rst_n) if(!Rst_n) r_DAC_DATA <= 16'd0; else if(DAC_State) r_DAC_DATA <= DAC_DATA; always@(posedge Clk or negedge Rst_n) if(!Rst_n) Start <= 1'd0; else if(r_DAC_DATA != DAC_DATA) Start <= 1'b1; else Start <= 1'd0; endmodule`timescale 1ns/1ns module tlv5618_tb(); reg Clk; reg Rst_n; reg [15:0]DAC_DATA; reg Start; wire Set_Done; wire DAC_CS_N; wire DAC_DIN; wire DAC_SCLK; tlv5618 tlv5618( .Clk(Clk), .Rst_n(Rst_n), .DAC_DATA(DAC_DATA), .Start(Start), .Set_Done(Set_Done), .DAC_CS_N(DAC_CS_N), .DAC_DIN(DAC_DIN), .DAC_SCLK(DAC_SCLK), .DAC_State() ); initial Clk = 1; always#10 Clk = ~Clk; initial begin Rst_n = 0; Start = 0; DAC_DATA = 0; #201; Rst_n = 1; #200; DAC_DATA = 16'hC_AAA; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h4_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'h1_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; DAC_DATA = 16'hf_555; Start = 1; #20; Start = 0; #200; wait(Set_Done); #20000; $stop; end endmodule仿真 图片
FPGA&ASIC
# ASIC/FPGA
# 小实验
刘航宇
4年前
0
1,505
1
2022-11-30
VLSI设计-基4 Booth乘法器前端与中端实现
前言 在微处理器芯片中,乘法器是进行数字信号处理的核心,同时也是微处理器中进行数据处理的关键部件。乘法器完成一次操作的周期基本上决定了微处理器的主频。乘法器的速度和面积优化对于整个CPU的性能来说是非常重要的。为了加快乘法器的执行速度,减少乘法器的面积,有必要对乘法器的算法、结构及电路的具体实现做深入的研究。 目录 视频课程,关注本人B站账号有完整版前端中端设计教程 前言 视频课程,关注本人B站账号有完整版前端中端设计教程 1. 设计内容 2. 设计目标 3.原理介绍 4.电路&Verilog代码基4Booth编码器 4-2压缩器 超前进位加法器 代码下载 4、仿真分析前端逻辑仿真 电路与性能仿真电路图 面积报告 功耗报告 后端 代码下载 1. 设计内容 完成一个全定制的 8x8 bits 基-4 Booth 编码码乘法器核心电路设计,即可以不考虑输入、输出数据的寄存。 2. 设计目标 本设计最主要的目标是在电路速度尽可能高的条件下最小化电路的功率-延迟积(PDP)。所以首先在电路结构设计完成后需要分析、考虑最长延迟路径。根据设计目标进行逻辑链优化。 3.原理介绍 本乘法器采用基4booth编码,输入为两个8位有符号数,输出为16位有符号数。基4的booth编码将两个8位有符号数计算成4个部分积。4个部分积经过一层4-2压缩器得到2个部分积,得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。 图片 思维扩展: 若输入为两个128位有符号数,输出为256位有符号数。基4的booth编码将两个128位有符号数计算成64个部分积。64个部分积经过一层4-2压缩器得到32个部分积……在经过几层4-2压缩器,最终得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。结构框图如下: 图片 4.电路&Verilog代码 设计理念:功能需求->Verilog代码->代码转电路(DC)->电路转版图(ICC或SOCE) 基4Booth编码器 对于被乘数b_i进行编码,Booth 基-4 编码是根据相邻 3 位为一组,前后相邻分组重叠一比特位,从低位到高位逐次进行,在乘数的最右边另增加一位辅助位 0,作为分组的最低位。Booth 4-基编码的优点是可以减少 Booth 2-基产生部分积的一半,Booth 基-4 除了具有高速特性还具有低功耗的特点。 图片 对应case casebib_ibi 3'b000 : booth_o <= 0; 3'b001 : booth_o <= { a_ilength−1length-1length−1, a_i}; 3'b010 : booth_o <= { a_ilength−1length-1length−1, a_i}; 3'b011 : booth_o <= a_i<<1; 3'b100 : booth_o <= -ai<<1a_i<<1ai<<1; 3'b101 : booth_o <= -{a_ilength−1length-1length−1,a_i}; 3'b110 : booth_o <= -{a_ilength−1length-1length−1,a_i}; 3'b111 : booth_o <= 0; default: booth_o <= 0;4-2压缩器 4-2 压缩器的原理图如下所示,把 4 个相同权值的二进制数两个权值高一级的二进制数和,它有 5 个输入端口:包括 4 个待压缩数据 a1、a2、a3、a4 和一个初始进位或低权值 4-2 压缩传递的进位值 Ci;3 个输出端口:包括一比特位溢出进位值 Co,进位数据 C,伪和 S。 下面代码得到的结果out1的权值高一位,下一层部分积计算时需要将out1的结果左移一位(out1<<1); 图片 功能代码: assign w1 = in1 ^ in2 ^ in3 ^ in4; assign w2 = (in1 & in2) | (in3 & in4); assign w3 = (in1 | in2) & (in3 | in4); assign out2 = { w1[length*2-1] , w1} ^ {w3 , cin}; assign cout = w3[length*2-1]; assign out1 = ({ w1[length*2-1] , w1} & {w3 , cin}) | (( ~{w1[length*2-1] , w1}) & { w2[length*2-1] , w2});超前进位加法器 4位超前进位代码: //carry generator assign c[0] = cin; assign c[1] = g[0] + ( c[0] & p[0] ); assign c[2] = g[1] + ( (g[0] + ( c[0] & p[0]) ) & p[1] ); assign c[3] = g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] ); assign c[4] = g[3] + ( (g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] )) & p[3]); assign cout = c[width];代码下载 见文章末尾 4、仿真分析 前端逻辑仿真 本设计是单纯的组合逻辑,由仿真结果可知有符号乘法设计结果完全正确。 图片 电路与性能仿真 电路图 图片 面积报告 DC综合后,总共的单元面积为7853.630484等效门,总面积为78273.983938等效门。 图片 功耗报告 图片 由于该电路是完全的组合逻辑,无CLK端口,因此未作时序约束。 后端 做到这里完成了前端中端设计任务,在流片前还需要完成后端设计及验证。由于本电路规模大,我们可以利用EDA如(SOCE或者ICC)完成版图布局,由于时间仓促,笔者暂未更新后端教程。 代码下载
FPGA&ASIC
VLSI&IC验证
# ASIC/FPGA
刘航宇
4年前
0
1,519
4
2022-09-30
【Verilog编解码】数据的串并转化
目录 一、串转并转换模块1、利用移位寄存器 2、利用计数器 二、并转串转换模块 一、串转并转换模块 1、利用移位寄存器 串行转并行数据输出:采用位拼接技术(移位寄存器),将串行的数据总数先表示出来,然后发送一位数据加一,后面的接收的这样标志: data_o <= {data_o[6:0],data_i }; 这是左移,右移也是可以的,依据项目而定。 1输入8输出 的 串转并模块的Verilog代码 module serial_parallel( input clk, input rst_n,en, input data_i, //一位输入 output reg [7:0] data_o //8位并行输出 ); always @(posedge clk or negedge rst_n) begin if (rst_n == 1'b0) data_o <= 8'b0; else if (en == 1'b1) data_o <= {data_o[6:0], data_i}; //低位先赋值 //data_o <= {data_i,data_o[7:1],}; //高位先赋值 else data_o <= data_o; end endmodule测试代码 `timescale 1ns/100ps module serial_parallel_tb; reg clk,rst_n,en; reg data_i; wire [7:0] data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.en(en),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; en = 0; #20 rst_n = 1; #20 en = 1; data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; #20 data_i = 0; end initial begin forever #10 clk = ~clk; end endmodule2、利用计数器 利用计数器cnt 时钟计数,开始数据先给高位,每过一个时钟周期,数据便给低一位。这样便可以达到串转并的效果 1输入8输出 的 串转并模块的Verilog代码 module serial_parallel( input clk, input rst_n, input data_i, output reg [7:0] data_o ); //msb first most significant bit 表示二进制数据的最高位 reg [2:0] cnt; //计数器0-7 always @(posedge clk or negedge rst_n)begin if(rst_n == 1'b0)begin data_o <= 8'b0; cnt <= 3'd0; end else begin data_o[7 - cnt] <= data_i; //高位先赋值 //data_o[cnt] <= data_i; //低位先赋值 cnt <= cnt + 1'b1; end end endmodule测试代码 `timescale 1ns/100ps module serial_parallel_tb; reg clk,rst_n; reg data_i; wire [7:0] data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; #20 rst_n = 1; data_i = 1; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; #20 data_i = 1; #20 data_i = 1; #20 data_i = 1; #20 data_i = 0; end initial begin forever #10 clk = ~clk; end endmodule二、并转串转换模块 并串转换的原理是: 先将八位数据暂存于一个四位寄存器器中,然后左移输出到一位输出端口,这里通过一个“移位”指令。 8输入1输出 的 并转串模块的Verilog代码 使能信号en表示开始执行并转串操作,由于并转串是移位操作,当一次并转串完成后,需要重新载入待转换的并行数据时,使能信号要再起来一次 module parallel_serial(clk, rst_n, en, data_i, data_o); input clk, rst_n,en; input [7:0] data_i; output data_o; reg [7:0] data_buf; always @(posedge clk or negedge rst_n) begin if (rst_n == 1'b0) begin data_buf <= 8'b0; end else if (en == 1'b1) data_buf <= data_i; else data_buf <= data_buf <<1; //将寄存器内的值左移,依次读出 //data_buf <= {data_buf[6:0],1'b0}; end assign data_o = data_buf[7]; endmodule测试代码 `timescale 1ns/100ps module parallel_serial_tb; reg clk,rst_n,en; reg [7:0]data_i; wire data_o; serial_parallel n1(.clk(clk),.rst_n(rst_n),.en(en),.data_i(data_i),.data_o(data_o)); initial begin clk = 0; rst_n = 0; en = 0; #10 rst_n = 1; #15 en = 1; data_i = 8'b10111010; #10 en = 0; #195 en = 1; data_i = 8'b10110110; #10 en = 0; end initial begin forever #10 clk = ~clk; end endmodule图片
FPGA&ASIC
刘航宇
4年前
0
1,023
1
Verilog实现FIFO的设计
FIFO(First In First Out)是异步数据传输时经常使用的存储器。该存储器的特点是数据先进先出(后进后出)。其实,多位宽数据的异步传输问题,无论是从快时钟到慢时钟域,还是从慢时钟到快时钟域,都可以使用 FIFO 处理。 完整的 FIFO 设计见附件,包括输入数据位宽小于输出数据位宽时的异步设计和仿真。 源代码FIFO.zip 下载地址:https://wwu.lanzoub.com/iIdvu0am46cf 提取码: 目录 FIFO 原理工作流程 读写时刻 读空状态 写满状态 FIFO 设计设计要求 双口 RAM 设计 计数器设计 FIFO 设计FIFO 调用 testbench 仿真分析 FIFO 原理 工作流程 复位之后,在写时钟和状态信号的控制下,数据写入 FIFO 中。RAM 的写地址从 0 开始,每写一次数据写地址指针加一,指向下一个存储单元。当 FIFO 写满后,数据将不能再写入,否则数据会因覆盖而丢失。 FIFO 数据为非空、或满状态时,在读时钟和状态信号的控制下,可以将数据从 FIFO 中读出。RAM 的读地址从 0 开始,每读一次数据读地址指针加一,指向下一个存储单元。当 FIFO 读空后,就不能再读数据,否则读出的数据将是错误的。 FIFO 的存储结构为双口 RAM,所以允许读写同时进行。典型异步 FIFO 结构图如下所示。端口及内部信号将在代码编写时进行说明。 图片 读写时刻 关于写时刻,只要 FIFO 中数据为非满状态,就可以进行写操作;如果 FIFO 为满状态,则禁止再写数据。 关于读时刻,只要 FIFO 中数据为非空状态,就可以进行读操作;如果 FIFO 为空状态,则禁止再读数据。 不管怎样,一段正常读写 FIFO 的时间段,如果读写同时进行,则要求写 FIFO 速率不能大于读速率。 读空状态 开始复位时,FIFO 没有数据,空状态信号是有效的。当 FIFO 中被写入数据后,空状态信号拉低无效。当读数据地址追赶上写地址,即读写地址都相等时,FIFO 为空状态。 因为是异步 FIFO,所以读写地址进行比较时,需要同步打拍逻辑,就需要耗费一定的时间。所以空状态的指示信号不是实时的,会有一定的延时。如果在这段延迟时间内又有新的数据写入 FIFO,就会出现空状态指示信号有效,但是 FIFO 中其实存在数据的现象。 严格来讲该空状态指示是错误的。但是产生空状态的意义在于防止读操作对空状态的 FIFO 进行数据读取。产生空状态信号时,实际 FIFO 中有数据,相当于提前判断了空状态信号,此时不再进行读 FIFO 数据操作也是安全的。所以,该设计从应用上来说是没有问题的。 写满状态 开始复位时,FIFO 没有数据,满信号是无效的。当 FIFO 中被写入数据后,此时读操作不进行或读速率相对较慢,只要写数据地址超过读数据地址一个 FIFO 深度时,便会产生满状态信号。此时写地址和读地址也是相等的,但是意义是不一样的。 图片 此时经常使用多余的 1bit 分别当做读写地址的拓展位,来区分读写地址相同的时候,FIFO 的状态是空还是满状态。当读写地址与拓展位均相同的时候,表明读写数据的数量是一致的,则此时 FIFO 是空状态。如果读写地址相同,拓展位为相反数,表明写数据的数量已经超过读数据数量的一个 FIFO 深度了,此时 FIFO 是满状态。当然,此条件成立的前提是空状态禁止读操作、满状态禁止写操作。 同理,由于异步延迟逻辑的存在,满状态信号也不是实时的。但是也相当于提前判断了满状态信号,此时不再进行写 FIFO 操作也不会影响应用的正确性。 FIFO 设计 设计要求 为设计应用于各种场景的 FIFO,这里对设计提出如下要求: (1) FIFO 深度、宽度参数化,输出空、满状态信号,并输出一个可配置的满状态信号。当 FIFO 内部数据达到设置的参数数量时,拉高该信号。 (2) 输入数据和输出数据位宽可以不一致,但要保证写数据、写地址位宽与读数据、读地址位宽的一致性。例如写数据位宽 8bit,写地址位宽为 6bit(64 个数据)。如果输出数据位宽要求 32bit,则输出地址位宽应该为 4bit(16 个数据)。 (3) FIFO 是异步的,即读写控制信号来自不同的时钟域。输出空、满状态信号之前,读写地址信号要用格雷码做同步处理,通过减少多位宽信号的翻转来减少打拍法同步时数据的传输错误。 格雷码与二进制之间的转换如下图所示。 图片 双口 RAM 设计 RAM 端口参数可配置,读写位宽可以不一致。建议 memory 数组定义时,以长位宽地址、短位宽数据的参数为参考,方便数组变量进行选择访问。 Verilog 描述如下。 module ramdp #( parameter AWI = 5 , parameter AWO = 7 , parameter DWI = 64 , parameter DWO = 16 ) ( input CLK_WR , //写时钟 input WR_EN , //写使能 input [AWI-1:0] ADDR_WR ,//写地址 input [DWI-1:0] D , //写数据 input CLK_RD , //读时钟 input RD_EN , //读使能 input [AWO-1:0] ADDR_RD ,//读地址 output reg [DWO-1:0] Q //读数据 ); //输出位宽大于输入位宽,求取扩大的倍数及对应的位数 parameter EXTENT = DWO/DWI ; parameter EXTENT_BIT = AWI-AWO > 0 ? AWI-AWO : 'b1 ; //输入位宽大于输出位宽,求取缩小的倍数及对应的位数 parameter SHRINK = DWI/DWO ; parameter SHRINK_BIT = AWO-AWI > 0 ? AWO-AWI : 'b1; genvar i ; generate //数据位宽展宽(地址位宽缩小) if (DWO >= DWI) begin //写逻辑,每时钟写一次 reg [DWI-1:0] mem [(1<<AWI)-1 : 0] ; always @(posedge CLK_WR) begin if (WR_EN) begin mem[ADDR_WR] <= D ; end end //读逻辑,每时钟读 4 次 for (i=0; i<EXTENT; i=i+1) begin always @(posedge CLK_RD) begin if (RD_EN) begin Q[(i+1)*DWI-1: i*DWI] <= mem[(ADDR_RD*EXTENT) + i ] ; end end end end //================================================= //数据位宽缩小(地址位宽展宽) else begin //写逻辑,每时钟写 4 次 reg [DWO-1:0] mem [(1<<AWO)-1 : 0] ; for (i=0; i<SHRINK; i=i+1) begin always @(posedge CLK_WR) begin if (WR_EN) begin mem[(ADDR_WR*SHRINK)+i] <= D[(i+1)*DWO -1: i*DWO] ; end end end //读逻辑,每时钟读 1 次 always @(posedge CLK_RD) begin if (RD_EN) begin Q <= mem[ADDR_RD] ; end end end endgenerate endmodule计数器设计 计数器用于产生读写地址信息,位宽可配置,不需要设置结束值,让其溢出后自动重新计数即可。Verilg 描述如下。 module ccnt #(parameter W ) ( input rstn , input clk , input en , output [W-1:0] count ); reg [W-1:0] count_r ; always @(posedge clk or negedge rstn) begin if (!rstn) begin count_r <= 'b0 ; end else if (en) begin count_r <= count_r + 1'b1 ; end end assign count = count_r ; endmoduleFIFO 设计 该模块为 FIFO 的主体部分,产生读写控制逻辑,并产生空、满、可编程满状态信号。 鉴于篇幅原因,这里只给出读数据位宽大于写数据位宽的逻辑代码,写数据位宽大于读数据位宽的代码描述详见附件。 module fifo #( parameter AWI = 5 , parameter AWO = 3 , parameter DWI = 4 , parameter DWO = 16 , parameter PROG_DEPTH = 16) //可设置深度 ( input rstn, //读写使用一个复位 input wclk, //写时钟 input winc, //写使能 input [DWI-1: 0] wdata, //写数据 input rclk, //读时钟 input rinc, //读使能 output [DWO-1 : 0] rdata, //读数据 output wfull, //写满标志 output rempty, //读空标志 output prog_full //可编程满标志 ); //输出位宽大于输入位宽,求取扩大的倍数及对应的位数 parameter EXTENT = DWO/DWI ; parameter EXTENT_BIT = AWI-AWO ; //输出位宽小于输入位宽,求取缩小的倍数及对应的位数 parameter SHRINK = DWI/DWO ; parameter SHRINK_BIT = AWO-AWI ; //==================== push/wr counter =============== wire [AWI-1:0] waddr ; wire wover_flag ; //多使用一位做写地址拓展 ccnt #(.W(AWI+1)) u_push_cnt( .rstn (rstn), .clk (wclk), .en (winc && !wfull), //full 时禁止写 .count ({wover_flag, waddr}) ); //============== pop/rd counter =================== wire [AWO-1:0] raddr ; wire rover_flag ; //多使用一位做读地址拓展 ccnt #(.W(AWO+1)) u_pop_cnt( .rstn (rstn), .clk (rclk), .en (rinc & !rempty), //empyt 时禁止读 .count ({rover_flag, raddr}) ); //============================================== //窄数据进,宽数据出 generate if (DWO >= DWI) begin : EXTENT_WIDTH //格雷码转换 wire [AWI:0] wptr = ({wover_flag, waddr}>>1) ^ ({wover_flag, waddr}) ; //将写数据指针同步到读时钟域 reg [AWI:0] rq2_wptr_r0 ; reg [AWI:0] rq2_wptr_r1 ; always @(posedge rclk or negedge rstn) begin if (!rstn) begin rq2_wptr_r0 <= 'b0 ; rq2_wptr_r1 <= 'b0 ; end else begin rq2_wptr_r0 <= wptr ; rq2_wptr_r1 <= rq2_wptr_r0 ; end end //格雷码转换 wire [AWI-1:0] raddr_ex = raddr << EXTENT_BIT ; wire [AWI:0] rptr = ({rover_flag, raddr_ex}>>1) ^ ({rover_flag, raddr_ex}) ; //将读数据指针同步到写时钟域 reg [AWI:0] wq2_rptr_r0 ; reg [AWI:0] wq2_rptr_r1 ; always @(posedge wclk or negedge rstn) begin if (!rstn) begin wq2_rptr_r0 <= 'b0 ; wq2_rptr_r1 <= 'b0 ; end else begin wq2_rptr_r0 <= rptr ; wq2_rptr_r1 <= wq2_rptr_r0 ; end end //格雷码反解码 //如果只需要空、满状态信号,则不需要反解码 //因为可编程满状态信号的存在,地址反解码后便于比较 reg [AWI:0] wq2_rptr_decode ; reg [AWI:0] rq2_wptr_decode ; integer i ; always @(*) begin wq2_rptr_decode[AWI] = wq2_rptr_r1[AWI]; for (i=AWI-1; i>=0; i=i-1) begin wq2_rptr_decode[i] = wq2_rptr_decode[i+1] ^ wq2_rptr_r1[i] ; end end always @(*) begin rq2_wptr_decode[AWI] = rq2_wptr_r1[AWI]; for (i=AWI-1; i>=0; i=i-1) begin rq2_wptr_decode[i] = rq2_wptr_decode[i+1] ^ rq2_wptr_r1[i] ; end end //读写地址、拓展位完全相同是,为空状态 assign rempty = (rover_flag == rq2_wptr_decode[AWI]) && (raddr_ex >= rq2_wptr_decode[AWI-1:0]); //读写地址相同、拓展位不同,为满状态 assign wfull = (wover_flag != wq2_rptr_decode[AWI]) && (waddr >= wq2_rptr_decode[AWI-1:0]) ; //拓展位一样时,写地址必然不小于读地址 //拓展位不同时,写地址部分比如小于读地址,实际写地址要增加一个FIFO深度 assign prog_full = (wover_flag == wq2_rptr_decode[AWI]) ? waddr - wq2_rptr_decode[AWI-1:0] >= PROG_DEPTH-1 : waddr + (1<<AWI) - wq2_rptr_decode[AWI-1:0] >= PROG_DEPTH-1; //双口 ram 例化 ramdp #( .AWI (AWI), .AWO (AWO), .DWI (DWI), .DWO (DWO)) u_ramdp ( .CLK_WR (wclk), .WR_EN (winc & !wfull), //写满时禁止写 .ADDR_WR (waddr), .D (wdata[DWI-1:0]), .CLK_RD (rclk), .RD_EN (rinc & !rempty), //读空时禁止读 .ADDR_RD (raddr), .Q (rdata[DWO-1:0]) ); end //============================================== //big in and small out /* else begin: SHRINK_WIDTH …… end */ endgenerate endmoduleFIFO 调用 下面可以调用设计的 FIFO,完成多位宽数据传输的异步处理。 写数据位宽为 4bit,写深度为 32。 读数据位宽为 16bit,读深度为 8,可配置 full 深度为 16。 module fifo_s2b( input rstn, input [4-1: 0] din, //异步写数据 input din_clk, //异步写时钟 input din_en, //异步写使能 output [16-1 : 0] dout, //同步后数据 input dout_clk, //同步使用时钟 input dout_en ); //同步数据使能 wire fifo_empty, fifo_full, prog_full ; wire rd_en_wir ; wire [15:0] dout_wir ; //读空状态时禁止读,否则一直读 assign rd_en_wir = fifo_empty ? 1'b0 : 1'b1 ; fifo #(.AWI(5), .AWO(3), .DWI(4), .DWO(16), .PROG_DEPTH(16)) u_buf_s2b( .rstn (rstn), .wclk (din_clk), .winc (din_en), .wdata (din), .rclk (dout_clk), .rinc (rd_en_wir), .rdata (dout_wir), .wfull (fifo_full), .rempty (fifo_empty), .prog_full (prog_full)); //缓存同步后的数据和使能 reg dout_en_r ; always @(posedge dout_clk or negedge rstn) begin if (!rstn) begin dout_en_r <= 1'b0 ; end else begin dout_en_r <= rd_en_wir ; end end assign dout = dout_wir ; assign dout_en = dout_en_r ; endmoduletestbench `timescale 1ns/1ns `define SMALL2BIG module test ; `ifdef SMALL2BIG reg rstn ; reg clk_slow, clk_fast ; reg [3:0] din ; reg din_en ; wire [15:0] dout ; wire dout_en ; //reset initial begin clk_slow = 0 ; clk_fast = 0 ; rstn = 0 ; #50 rstn = 1 ; end //读时钟 clock_slow 较快于写时钟 clk_fast 的 1/4 //保证读数据稍快于写数据 parameter CYCLE_WR = 40 ; always #(CYCLE_WR/2/4) clk_fast = ~clk_fast ; always #(CYCLE_WR/2-1) clk_slow = ~clk_slow ; //data generate initial begin din = 16'h4321 ; din_en = 0 ; wait (rstn) ; //(1) 测试 full、prog_full、empyt 信号 force test.u_data_buf2.u_buf_s2b.rinc = 1'b0 ; repeat(32) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end @(negedge clk_fast) din_en = 1'b0 ; //(2) 测试数据读写 #500 ; rstn = 0 ; #10 rstn = 1 ; release test.u_data_buf2.u_buf_s2b.rinc; repeat(100) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end //(3) 停止读取再一次测试 empyt、full、prog_full 信号 force test.u_data_buf2.u_buf_s2b.rinc = 1'b0 ; repeat(18) begin @(negedge clk_fast) ; din_en = 1'b1 ; din = {$random()} % 16; end end fifo_s2b u_data_buf2( .rstn (rstn), .din (din), .din_clk (clk_fast), .din_en (din_en), .dout (dout), .dout_clk (clk_slow), .dout_en (dout_en)); `else `endif //stop sim initial begin forever begin #100; if ($time >= 5000) $finish ; end end endmodule仿真分析 根据 testbench 中的 3 步测试激励,分析如下: 测试 (1) : FIFO 端口及一些内部信号时序结果如下。 由图可知,FIFO 内部开始写数据,空状态信号拉低之前有一段时间延迟,这是同步读写地址信息导致的。 由于此时没有进行读 FIFO 操作,相对于写数据操作,full 和 prog_full 拉高几乎没有延迟。 图片 测试 (2) : FIFO 同时进行读写时,数字顶层异步处理模块的端口信号如下所示,两图分别显示了数据开始传输、结束传输时的读取过程。 由图可知,数据在开始、末尾均能正确传输,完成了不同时钟域之间多位宽数据的异步处理。 图片 图片 测试 (3) :整个 FIFO 读写行为及读停止的时序仿真图如下所示。 由图可知,读写同时进行时,读空状态信号 rempty 会拉低,表明 FIFO 中有数据写入。一方面读数据速率稍高于写速率,且数据之间传输会有延迟,所以中间过程中 rempty 会有拉高的行为。 读写过程中,full 与 prog_full 信号一直为低,说明 FIFO 中数据并没有到达一定的数量。当停止读操作后,两个 full 信号不久便拉高,表明 FIFO 已满。仔细对比读写地址信息,FIFO 行为没有问题。 图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
4年前
0
916
2
上一页
1
2
3
4
5
下一页