首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,119 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,101 阅读
3
【高数】形心计算公式讲解大全
8,743 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,437 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,790 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
C/C++(共7篇)
找到
7
篇与
C/C++
相关的结果
2024-03-12
C语言编译的四个步骤
编译一个C语言程序是一个多阶段的过程。从总体上看,这个过程可以分成四个独立的阶段。预处理、编译、汇编和连接。 在这篇文章中,我将逐一介绍编译下列C程序的四个阶段。 /* * "Hello, World!": A classic. */ #include <stdio.h> int main(void) { puts("Hello, World!"); return 0; }预处理 编译的第一个阶段称为预处理。在这个阶段,以#字符开头的行被预处理器解释为预处理器命令。这些命令形成一种简单的宏语言,有自己的语法和语义。这种语言通过提供内联文件、定义宏和有条件地省略代码的功能,来减少源代码的重复性。 在解释命令之前,预处理器会做一些初始处理。这包括连接续行(以 \ 结尾的行)和剥离注释。 要打印预处理阶段的结果,请向gcc传递-E选项。 gcc -E hello_world.c 考虑到上面的 "Hello, World!"的例子,预处理器将产生stdio.h头文件的内容和hello_world.c文件的内容,并将其前面的注释剥离出来。 编译 编译的第二个阶段被称为编译,令人困惑。在这个阶段,预处理过的代码被翻译成目标处理器架构特有的汇编指令。这些形成了一种中间的人类可读语言。 这一步骤的存在允许C代码包含内联汇编指令,并允许使用不同的汇编器。 一些编译器也支持使用集成汇编器,在这种情况下,编译阶段直接生成机器代码,避免了生成中间汇编指令和调用汇编器的开销。 要保存编译阶段的结果,可以向gcc传递-S选项。 gcc -S hello_world.c 这将创建一个名为hello_world.s的文件,包含生成的汇编指令。 汇编 在这个阶段,汇编器被用来将汇编指令翻译成目标代码。输出包括目标处理器要运行的实际指令。 要保存汇编阶段的结果,请向gcc传递-c选项。 gcc -c hello_world.c 运行上述命令将创建一个名为hello_world.o的文件,包含程序的目标代码。这个文件的内容是二进制格式,可以用运行命令hexdump或od来检查。 hexdump hello_world.o od -c hello_world.oLinux中的od(octal dump)命令用于转换输入内容为八进制。 Hexdump是一个命令行工具,用于以各种方式显示文件的原始内容,包括十六进制,可用于Linux、FreeBDS、OS X和其他平台。Hexdump不是传统Unix系统或GNU命令的一部分。 链接 汇编阶段产生的目标代码是由处理器能够理解的机器指令组成的,但程序的某些部分是不符合顺序的或缺失的。为了产生一个可执行的程序,现有的部分必须被重新排列,并把缺失的部分补上。这个过程被称为链接。 链接器将安排目标代码的各个部分,使某些部分的功能能够成功地调用其他部分的功能。它还将添加包含程序所使用的库函数指令的片段。在 "Hello,world!"程序的例子中,链接器将添加puts函数的对象代码。 这一阶段的结果是最终的可执行程序。当不使用选项运行时,gcc 将把这个文件命名为 a.out。如果要给文件命名,请向 gcc 传递 -o 选项。 gcc -o hello_world hello_world.c
编程&脚本笔记
# C/C++
刘航宇
2年前
0
542
0
面向对象在编程中的概念
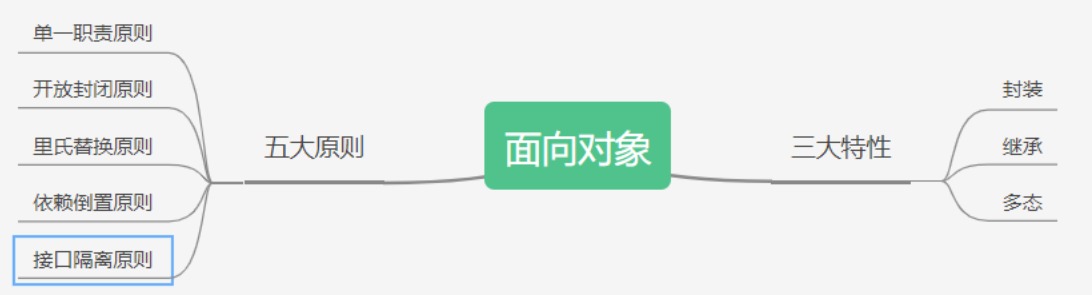
前言 那么究竟什么是面向对象呢?面向过程 面向对象 面向对象的三大特性封装 继承 多态 面向对象的五大基本原则单一职责原则(Single-Responsibility Principle) 开放封闭原则(Open-Closed principle) 里氏替换原则(Liskov-Substitution Principle) 依赖倒置原则(Dependecy-Inversion Principle) 接口隔离原则(Interface-Segregation Principle) 面向对象编程的用途 面向对象编程的应用领域 前言 在刚接触java、C++、Python语言的时候,就知道这是一门面向对象的语言。学不好java的原因找到了,面向对象的语言,没有对象怎么学 ::(狗头) 图片 那么究竟什么是面向对象呢? 面向对象,Object Oriented Programming,简称为OOP。说到面向对象,不得不提一嘴面向过程。 面向过程 面向过程是一种自顶而下的编程模式。 把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。 举个生活中的例子,假如你想吃红烧肉,你需要买肉,买调料,洗肉,切肉,烧肉,装盘。 需要我们具体每一步去实现,每个步骤相互协调,最终盛出来的才是正宗好吃的红烧肉。 面向对象 面向对象就是将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。 还是你想吃红烧肉这个例子,不过这次不同的是你发现了一家餐馆里有红烧肉这道菜,你要做的只是去点菜,就可以吃到红烧肉。 针不戳,针不戳,面向对象针不戳,你不用再去关心红烧肉繁琐的制作流程,就能吃到美味的红烧肉。 我们接着往下看 图片 面向对象的三大特性 封装 封装就是把客观的事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类进行信息的隐藏。简单的说就是:封装使对象的设计者与对象的使用者分开,使用者只要知道对象可以做什么就可以了,不需要知道具体是怎么实现的。封装可以有助于提高类和系统的安全性 这里有点像FPGA的IP了,电子人懂! 继承 当多个类中存在相同属性和行为时,将这些内容就可以抽取到一个单独的类中,使得多个类无需再定义这些属性和行为,只需继承那个类即可。通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类” 多态 多态同一个行为具有多个不同表现形式或形态的能力。是指一个类实例(对象)的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。 菜鸟教程中的例子就很形象 现实中,比如我们按下 F1 键这个动作: 如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档; 如果当前在 Word 下弹出的就是 Word 帮助; 在 Windows 下弹出的就是 Windows 帮助和支持。 同一个事件发生在不同的对象上会产生不同的结果。 面向对象的五大基本原则 单一职责原则(Single-Responsibility Principle) 简而言之,就是一个类最好只有一个能引起变化的原因,只做一件事,单一职责原则可以看做是低耦合高内聚思想的延伸,提高高内聚来减少引起变化的原因。 开放封闭原则(Open-Closed principle) 简而言之,就是软件实体应该是可扩展的,但是不可修改。因为修改程序有可能会对原来的程序造成错误。即对扩展开放,对修改封闭 里氏替换原则(Liskov-Substitution Principle) 简而言之,就是子类一定可以替换父类,子类包含其基类(父类)的功能 依赖倒置原则(Dependecy-Inversion Principle) 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。依赖于抽象即对接口编程,不要对实现编程 接口隔离原则(Interface-Segregation Principle) 图片 简而言之,就是使用多个小的专门的接口,而不要使用一个大的总接口。例如将一个房子再分割成卧室,厨房,厕所等等,而不是将所有功能放在一起 面向对象编程的用途 使用封装(信息隐藏)可以对外部隐藏数据 使用继承可以重用代码 使用多态可以重载操作符/方法/函数,即相同的函数名或操作符名称可用于多种任务 数据抽象可以用抽象实现 项目易于迁移(可以从小项目转换成大项目) 同一项目分工 软件复杂性可控 面向对象编程的应用领域 人工智能与专家系统 企业级应用 神经网络与并行编程 办公自动化系统
编程&脚本笔记
# 软件算法
# C/C++
刘航宇
3年前
0
434
3
2023-12-20
【嵌软】STM32的4种开发方式介绍
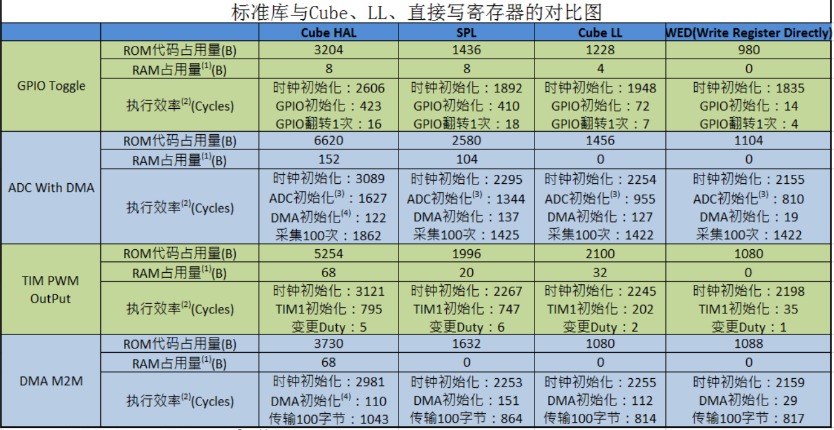
与FPGA一样,STM32也属于板级开发,可适用于大多数计算场合,但神经网络这种需要大量并行计算的需求难以满足。 STM32的开发主要指的是通过程序实现功能,ST官方提供的开发方式来说从远及近分别是: 1、直接读写寄存器 2、标准外设驱动库 SPL 3、硬件抽象层库 HAL库 4、底层库 LL库 四种开发方式各有优缺点,可以参考ST官方的测试与说明: 图片 标准外设库:这是ST官方提供的一套固件库,包含了STM32所有外设的驱动函数,可以方便地调用。它的优点是稳定、兼容、易用,缺点是占用资源较多,效率较低,更新较慢。 寄存器操作:这是直接对STM32的寄存器进行读写的方式,可以实现最底层的控制。它的优点是占用资源最少,效率最高,缺点是难度较大,需要熟悉寄存器的功能和位定义,不利于移植。 HAL库:这是ST官方推出的一套新的固件库,基于硬件抽象层(Hardware Abstraction Layer)的思想,提供了更加简洁和统一的接口。它的优点是支持多种IDE,更新较快,易于移植,缺点是文档较少,兼容性较差,有些BUG。CubeMX:这是ST官方提供的一套图形化的配置工具,可以自动生成HAL库的代码,还可以集成一些中间件和应用层的功能。它的优点是操作简单,功能强大,缺点是生成的代码较冗余,不易修改,有些功能不完善。 直接读写寄存器 开发是最慢的,可移植性最差,基本不推荐使用,只有个别对时间或是内存要求特别高、或者在写操作系统调度器时才需要直接读写寄存器; 标准外设驱动库 是ST最开始提供的库(国内的教程也很多是依据题库出的),现在已经被ST放弃了; HAL库 和 LL库 是近几年推出的库,结合 STM32CubeIDE 使用非常方便, HAL库 性能较差、在STM32系列芯片中可移植性好, LL库 性能好、可移植性差。
嵌入式&系统
# 嵌入式
# C/C++
刘航宇
3年前
0
1,160
3
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
501
0
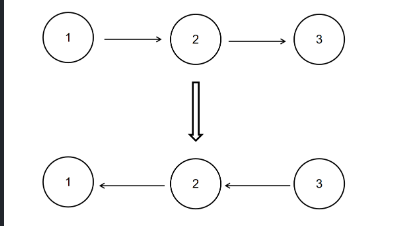
算法-反转链表C&Python实现
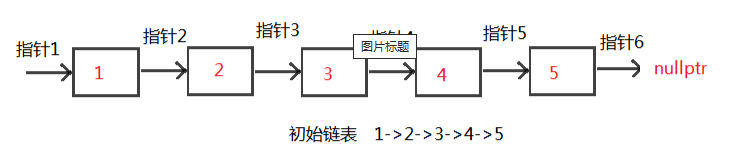
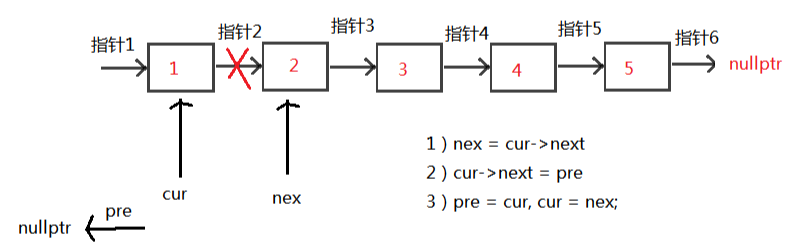
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
313
1
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
334
0
2023-07-19
嵌入式软件-基于C语言小端转大端
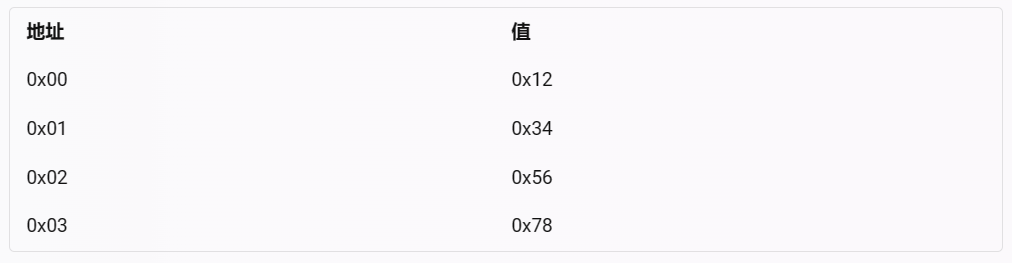
意义 题目 示例 解答1.char指针,按字节替换 2.利用union联合体共用内存空间特性,使用char数组来改变 3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 4. 使用预定义好的宏函数 意义 大端小端转化对嵌入式系统有意义,因为不同的处理器或者通信协议可能采用不同的字节序来存储或者传输数据。字节序是指一个多字节数据在内存中的存放顺序,它有两种主要的形式: 大端:最高有效位(MSB)存放在最低的内存地址,最低有效位(LSB)存放在最高的内存地址。 小端:最低有效位(LSB)存放在最低的内存地址,最高有效位(MSB)存放在最高的内存地址。 例如,一个32位的整数0x12345678,在大端系统中,它的内存布局是: pC703EF.png图片 而在小端系统中,它的内存布局是: pC70G4J.png图片 如果一个嵌入式系统需要和不同字节序的设备或者网络进行交互,就需要进行字节序的转换,否则会导致数据错误或者通信失败。例如,TCP/IP协议族中的所有层都采用大端字节序来表示数据包头中的16位或32位的值,如IP地址、包长、校验和等。如果一个嵌入式系统使用小端字节序的处理器,并且想要建立一个TCP连接,就需要将IP地址等信息从小端转换为大端再发送出去,否则对方无法正确解析。 题目 输入一个数字n,假设它是以小端模式保存在机器的,请将其转换为大端方式保存时的值。 示例 输入:1 返回值:16777216 解答 1.char指针,按字节替换 /* * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here int tmp = 0x00000000; //开辟新的int空间用于接收转化结果 unsigned char *p = &tmp, *q = &n; p[0] = q[3]; p[1] = q[2]; p[2] = q[1]; p[3] = q[0]; return tmp; }2.利用union联合体共用内存空间特性,使用char数组来改变 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ typedef union { int i; unsigned char c[4] } inc_u; int convert(int n ) { // write code here inc_u x; //这里也可以用新开辟空间进行置换 x.i = n; //利用按位异或运算可叠加、可还原性 x.c[0] ^= x.c[3], x.c[3] ^= x.c[0], x.c[0] ^= x.c[3]; //首尾两字节对调 x.c[1] ^= x.c[2], x.c[2] ^= x.c[1], x.c[1] ^= x.c[2]; //中间两字节对调 return x.i; /* 按位<<到正确位置,并用|拼装 return (x.c[0]<<24)|(x.c[1]<<16)|(x.c[2]<<8)|x.c[3]; */ }3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return (((n & 0xff000000)>>24) | ((n & 0x00ff0000)>>8 ) | ((n & 0x0000ff00)<<8 ) | ((n & 0x000000ff)<<24); //按位与时,遇0清零,遇1保留 ); }4. 使用预定义好的宏函数 本条方法参考 https://www.codeproject.com/Articles/4804/Basic-concepts-on-Endianness 文中提到网络上常用的套接字接口(socket API)指定了一种称为网络字节顺序的标准字节顺序,这个顺序其实就是大端模式;而当时,同时代的 x86 系列主机反而是小端模式。所以就促使产生了如: ntohs() convert Network order TO Host order in Short (16 bit 大转小); ntohl() convert Network order TO Host order in Long (32 bit 大转小); htons() convert Host order TO Network order in Short (16 bit 小转大); htonl() convert Host order TO Network order in Long (32 bit 小转大). 所以我们这里使用 32 bit 小转大的 htonl() 宏函数来解决这个问题。 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return htonl(n); ); }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
504
1