首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,961 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,535 阅读
3
【高数】形心计算公式讲解大全
8,986 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,751 阅读
5
Vivado-FPGA Verilog烧写固化教程
7,691 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
/
注册
刘航宇(共305篇)
找到
305
篇与
刘航宇
相关的结果
- 第 3 页
2023-10-15
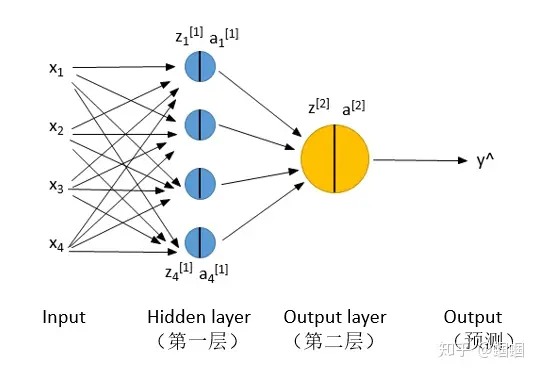
DL-神经网络的正向传播与反向传播
神经网络简述 前向传播 反向传播 四、深层神经网络(Deep Neural Network) 1.单个神经元 2.由神经元组成的神经网络 3.目标函数 4.求解损失函数对某个权值的梯度 5.反向传播算法Backpropgation 5.2 计算一个梯度 5.3 反向传播误差 6.优化示例 神经网络简述 神经网络,就是在Logistic regression的基础上增加了一个或几个隐层(hidden layer),下面展示的是一个最最最简单的神经网络,只有两层: 两层神经网络 图片 需要注意的是,上面的图是“两层”,而不是三层或者四层,输入和输出不算层! 这里,我们先规定一下记号(Notation): z是x和w、b线性运算的结果,z=wx+b; a是z的激活值; 下标的1,2,3,4代表该层的第i个神经元(unit); 上标的[1],[2]等代表当前是第几层。 y^代表模型的输出,y才是真实值,也就是标签 另外,有一点经常搞混: 上图中的x1,x2,x3,x4不是代表4个样本!而是一个样本的四个特征(4个维度的值)! 你如果有m个样本,代表要把上图的过程重复m次: 图片 神经网络的“两个传播”: 前向传播(Forward Propagation)前向传播就是从input,经过一层层的layer,不断计算每一层的z和a,最后得到输出y^ 的过程,计算出了y^,就可以根据它和真实值y的差别来计算损失(loss)。 反向传播(Backward Propagation)反向传播就是根据损失函数L(y^,y)来反方向地计算每一层的z、a、w、b的偏导数(梯度),从而更新参数。 前向传播和反向传播: 图片 每经过一次前向传播和反向传播之后,参数就更新一次,然后用新的参数再次循环上面的过程。这就是神经网络训练的整个过程。 前向传播 如果用for循环一个样本一个样本的计算,显然太慢,是使用Vectorization,把m个样本压缩成一个向量X来计算,同样的把z、a都进行向量化处理得到Z、A,这样就可以对m的样本同时进行表示和计算了。不熟悉的朋友可以看这里: 这样,我们用公式在表示一下我们的两层神经网络的前向传播过程: Layer 1:Z[1] = W[1]·X + b[1]A[1] = σ(Z[1]) Layer 2:Z[2] = W[2]·A[1] + b[2]A[2] = σ(Z[2]) 而我们知道,X其实就是A[0],所以不难看出:每一层的计算都是一样的: Layer i:Z[i] = W[i]·A[i-1] + b[i]A[i] = σ(Z[i]) (注:σ是sigmoid函数) 因此,其实不管我们神经网络有几层,都是将上面过程的重复。 对于 损失函数,就跟Logistic regression中的一样,使用 “交叉熵(cross-entropy)”,公式就是 二分类问题:L(y^,y) = -[y·log(y^ )+(1-y)·log(1-y^ )]- 多分类问题:L=-Σy(j)·y^(j) 这个是每个样本的loss,我们一般还要计算整个样本集的loss,也称为cost,用J表示,J就是L的平均: J(W,b) = 1/m·ΣL(y^(i),y(i)) 上面的求Z、A、L、J的过程就是正向传播。 反向传播 反向传播说白了根据根据J的公式对W和b求偏导,也就是求梯度。因为我们需要用梯度下降法来对参数进行更新,而更新就需要梯度。 但是,根据求偏导的链式法则我们知道,第l层的参数的梯度,需要通过l+1层的梯度来求得,因此我们求导的过程是“反向”的,这也就是为什么叫“反向传播”。 具体求导的过程,这里就不赘述了。像各种 深度学习框架TensorFlow、Keras,它们都是 只需要我们自己构建正向传播过程, 反向传播的过程是自动完成的,所以大家也确实不用操这个心。 进行了反向传播之后,我们就可以根据每一层的参数的梯度来更新参数了,更新了之后,重复正向、反向传播的过程,就可以不断训练学习更好的参数了。 四、深层神经网络(Deep Neural Network) 前面的讲解都是拿一个两层的很浅的神经网络为例的。 深层神经网络也没什么神秘,就是多了几个/几十个/上百个hidden layers罢了。 可以用一个简单的示意图表示: 深层神经网络: 图片 注意,在深层神经网络中,我们在中间层使用了 “ReLU”激活函数,而不是sigmoid函数了,只有在最后的输出层才使用了sigmoid函数,这是因为 ReLU函数在求梯度的时候更快,还可以一定程度上防止梯度消失现象,因此在深层的网络中常常采用。 关于深层神经网络,我们有必要再详细的观察一下它的结构,尤其是 每一层的各个变量的维度,毕竟我们在搭建模型的时候,维度至关重要。 图片 我们设: 总共有m个样本,问题为二分类问题(即y为0,1); 网络总共有L层,当前层为l层(l=1,2,...,L); 第l层的单元数为n[l];那么下面参数或变量的维度为: W[l]:(n[l],n[l-1])(该层的单元数,上层的单元数) b[l]:(n[l],1) z[l]:(n[l],1) Z[l]:(n[l],m) a[l]:(n[l],1) A[l]:(n[l],m) X:(n[0],m) Y:(1,m) 可能有人问,为什么 W和b的维度里面没有m? 因为 W和b对每个样本都是一样的,所有样本采用同一套参数(W,b), 而Z和A就不一样了,虽然计算时的参数一样,但是样本不一样的话,计算结果也不一样,所以维度中有m。 深度神经网络的正向传播、反向传播和前面写的2层的神经网络类似,就是多了几层,然后中间的激活函数由sigmoid变为ReLU了。 1.单个神经元 神经网络是由一系列神经元组成的模型,每一个神经元实际上做得事情就是实现非线性变换。 如下图就是一个神经元的结构: 图片 神经元将两个部分:上一层的输出(x1,x2,....,xn)与权重(w1,w2,....,wn),对应相乘相加,然后再加上一个偏置 b之后的值经过激活函数处理后完成非线性变换。 记 z = w ⋅ x + b ,a=σ(z),则 z 是神经元非线性变换之前的结果,这部分仅仅是一个简单的线性函数。σ 是Sigmod激活函数,该函数可以将无穷区间内的数映射到(-1,1)的范围内。a 是神经元将 z z 进行非线性变换之后的结果。 Sigmod函数图像如下图 $$\mathrm{sigmod(x)=\frac{1}{1+e^{-x}}}$$ 图片 因此,结果 a 就等于: 图片 这里再强调一遍,神经元的本质就是做非线性变换 2.由神经元组成的神经网络 神经元可以理解成一个函数,神经网络就是由很多个非线性变换的神经元组成的模型,因此神经网络可以理解成是一个非常复杂的复合函数。 图片 对于上图中的网络: (x1,x2,....,xn)为n维输入向量 Wij,表示后一层低i个神经元与前一层第j个神经元之间的权值 z = Wx + b是没有经过激活函数非线性变换之前的结果 a=σ(z),是 z 经过激活函数非线性变换之后的结果 \mathrm{s=U^Ta},为网络最终的输出结果。 3.目标函数 以折页损失为目标函数: $$\mathrm{minmizeJ}=\max(\Delta+s_{c}-s,0)$$ 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 一般来说,学习算法的学习过程就是优化调整参数,使得损失函数,或者说预测结果和实际结果的误差减小。BP算法其实是一个双向算法,包含两个步骤: 1.正向传递输入信息,得到 Loss 值。 2.反向传播误差,从而由优化算法来调整网络权值。 4.求解损失函数对某个权值的梯度 图片 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 对于上面的图, 假设图中指示出的网络中的某个权值 w$_\mathrm{jk}^\mathrm{l}$ 发生了一个小的改变 $\Delta w_\mathrm{jk}^\mathrm{l}$ , 假设网络最终损失函数的输出为$\mathbb{C}$,则 C 应该是关于 $\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 的一个复合函数。 所谓复合函数,就是把 $\mathbb{C}$ 看成因变量,则$\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 可以看成导致 C 改变的自变量, 比如假设有一个复 合函数 $\mathrm{y=f(g(x))}$,则 y 就好比这里的$\mathbb{C}$ , x 就好比$\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}$, w$_{jk}^{\mathrm{l}}$ 每经过一层网络可以看成是经过某个函数的处理。而下面求写的时候都用偏导数, 是因为虽然我们这里只关注了一个 w$_\mathrm{jk}^{\mathrm{l}}$,但是实际上网络中的每一个 w 都可以看成一个 x。 显然,这个$\Delta w_\mathrm{jk}^\mathrm{l}$的变化会引起下一层直接与其相连的一个神经元,以及下一层之后所有神经元直到 最终输出 C 的变化, 如图中蓝线标记的就是该权值变化的影响传播路径。 把 C 的改变记为 $\Delta\mathbb{C}$, 则根据高等数学中导数的知识可以得到: 则神经元 a$_\mathrm{j}^1$ 下面一层第 q 个与其相连的神经元 a$_{\mathrm{q}}^{1+1}$ 的变化为: $$ \Delta\mathrm{a_q^{1+1}}\approx\frac{\partial\mathrm{a_q^{1+1}}}{\partial\mathrm{a_j^1}}\Delta\mathrm{a_j^1} $$将 $(2)$ 代入 (3) 可以得到: $$ \Delta\mathrm{a_{q}^{l+1}}\:\approx\:\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\:\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\:\Delta\mathrm{w_{jk}^{l}} $$假设从 $\mathrm{a_j}^1$ 到 C的一条路径为$\mathrm{a_j}^1,\mathrm{a_q}^{1+1},...,\mathrm{a_n}^{\mathrm{L-1}},\mathrm{a_m}^{\mathrm{L}}$,则在该条路径上 C 的变化量 $\Delta C$ 为: $$\Delta\mathrm{C}\approx\frac{\partial\mathrm{C}}{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}\frac{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}\frac{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}{\partial\mathrm{a}_\mathrm{p}^\mathrm{L-2}}[USD3P]\frac{\partial\mathrm{a}_\mathrm{q}^\mathrm{l+1}}{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}\frac{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}{\partial\mathrm{w}_\mathrm{jk}^\mathrm{l}}\Delta\mathrm{w}_\mathrm{jk}^\mathrm{l}$$ 至此,我们已经得到了一条路径上的变化量, 其实本质就是链式求导法则,或者说是复合函数求导法则。那么整个的变化量就县把所有可能链路上的变化量加起来: $$\Delta\mathrm{C}\approx\sum_{\mathrm{minp[USD3P]q}}\frac{\partial\mathrm{C}}{\partial\mathrm{a_{m}^{L}}}\frac{\partial\mathrm{a_{m}^{L}}}{\partial\mathrm{a_{n}^{L-1}}}\frac{\partial\mathrm{a_{n}^{L-1}}}{\partial\mathrm{a_{p}^{L-2}}}[USD3P]\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\Delta\mathrm{w_{jk}^{l}}$$ $$\begin{aligned}\text{则 C 对某个权值 w}_{\mathrm{jk}}^{\dagger}&\text{的梯度为:}\\&\frac{\partial\mathrm{C}}{\partial\mathrm{w}_{\mathrm{jk}}^{\dagger}}\approx\sum_{\mathrm{nmp},<0}\frac{\partial\mathrm{C}}{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}\frac{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}\frac{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}{\partial\mathrm{a}_{\mathrm{p}}^{\mathrm{L}-2}}[USD3P]\frac{\partial\mathrm{a}_{\mathrm{q}}^{\mathrm{l}+1}}{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}\frac{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}{\partial\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}}\end{aligned}$$ 到这里从数学分析的角度来说,我们可以知道这个梯度是可以计算和求解的。 总结: 1.每两个神经元之间是由一条边连接的,这个边就是一个权重值,它是后一个神经元 z 部分,也就是未经激活函数非线性变换之前的结果对前一个神经元的 a 部分,也就是经激活函数非线性变换之后的结果的偏导数。 2.一条链路上所有偏导数的乘积就是这条路径的变化量。 3.所有路径变化量之和就是整个损失函数的变化量。 5.反向传播算法Backpropgation 5.1 明确一些定义 图片 对于上面的神经网络, 首先明确下面一些定义: 图片 5.2 计算一个梯度 假设损失函数为:J=(1+sc −s) 来计第一下 $\frac{\partial\mathrm{J}}{\partial\mathrm{W}_{14}^{(1)}}$,由于 s 是网络的输出, $\frac{\partial\mathrm{J}}{\partial\mathrm{s}}=-1$, 所以只需要计算$\frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}$ 即可。 而由于 s 激活函数就是1, 所以有: $$ \mathrm{s=a_1^{(3)}=z_1^{(3)}=W_{11}^{(2)}a_1^{(2)}+W_{12}^{(2)}a_2^{(2)}} $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial(\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}+\mathrm{W}_{12}^{(2)}\mathrm{a}_{2}^{(2)})}{\partial\mathrm{W}_{14}^{(1)}} $$图片 所以: $$\frac{\partial s}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}$$ 由于图片代入公式(9)可以得到 $$\begin{gathered} \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{z}_{1}^{(2)}}\frac{\partial\mathrm{z}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}1} \ =\operatorname{W}_{11}^{(2)}\mathfrak{\sigma}^{\prime}(\mathfrak{z}_{1}^{(2)})\frac{\partial(\mathfrak{b}_{1}^{(1)}+\sum_{\mathrm{k}}\mathfrak{a}_{\mathrm{k}}^{(1)}\mathfrak{W}_{1\text{k}} ^ { ( 1 ) })}{\partial\mathrm{W}_{14}^{(1)}} \end{gathered}$$ $$ \text{公式}(10)中\frac{\partial(\mathrm{h}_{1}^{(1)}+\sum_{k}a_{k}^{(1)}W_{1k}^{(1)})}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{a}_{4}^{(1)}。 $$此外还有一个更重要的变换, 同样的方法可以求出: $$ \frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}=\mathrm{W}_{11}^{(2)}\mathrm{\sigma}^{\prime}(\mathrm{z}_1^{(2)}) $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}\mathrm{a}_4^{(1)}=\delta_1^{(2)}\mathrm{a}_4^{(1)} $$并且结合前面对 $\delta_\mathrm{j}^{(\mathrm{k})}$ 的定义,公式 (10) 可以写成: 所以损失函数对任离一个网络权伯的梯度可以弓成两个值相乘的形式。对于$\mathrm{a}_4^{(1)}$,它是网络前向传递过程中的一个神经元的输出, 我们当然可以在网络前向传递的时候将它保存下来。而对于 $\delta_1^{(2)}$,它是反向传播过来的梯度,也就是 J 对 z 的梯度, 下面来者如何通过后面神经元的 $\delta_{\mathrm{i}}^{(\mathrm{k})}$ 反向传播得到 前一个神经元处的 $\delta_\mathrm{j}^{(k-1)}$ 。 5.3 反向传播误差 到这里需要注意,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,可以使用比如随机梯度下降算法等来进行学习。 反向传播算法传播的是误差,传播方向是从最后一层依次往前,这是一个迭代的过程。在上面的过程中,我们求得了损失函数对于某个权值的梯度,通过该处的梯度值,可以将其向前传播,得到前一个结点的梯度。 图片 $(k-1)$ 例如对于上面的图, 假设已经求出 z$^{(\mathrm{k})}$ 处的柠伊卡$^{(\mathrm{k})}$,则行误差仅照某杀连接路径, 传递到 $\mathrm{a_j}^{[\mathrm{l}]}$ per 处,则该处的梯度为$\delta_{\mathrm{i}}^{(\mathrm{k})}W_{\mathrm{ij}}^{(\mathrm{k}-1)}$。实际上这只是一条路径, $\mathrm{a_j}^{(\mathrm{k-1})}$处可能会收到很多个不同的误差, 例如下面该神经元后面有两条权值 边的情况: 图片 这个时候只要把它们相加就好了,所以 a$_{\mathrm{j}}^{(\mathrm{k}-1)}$处,则该处的梯度为$\sum_{\mathrm{i}}\delta_{\mathrm{i}}^{(\mathrm{k})}\mathrm{W}_{\mathrm{ij}}^{(\mathrm{k}-1)}$。 图片 6.优化示例 再次说一下,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,还需要使用比如随机梯度下降算法等来进行学习。 在上面的过程中, 我们通过反向传播弹法求解出了任意一个$z_j^{(\mathrm{i})}$处的梯度$\delta_j^{(\mathrm{i})}$,为什么是$z_j^{(\mathrm{i})}$而不是$a_j^{(\mathrm{i})}$,因为$z_j^{(\mathrm{i})}$前面就是连接它的w,以随机梯度下降算法为例,w的优化方法为: $$\mathrm{w_{ijnew}^{(1)}=w_{ijold}^{(1)}-\eta\cdot\frac{\partial J}{\partial w_{ij}^{(1)}}=w_{ijold}^{(1)}-\eta\cdot\delta_{i}^{(1+1)}\cdot a_{j}^{(1)}}$$
机器学习
# DL/ML
刘航宇
3年前
0
667
2
RFID编码简介
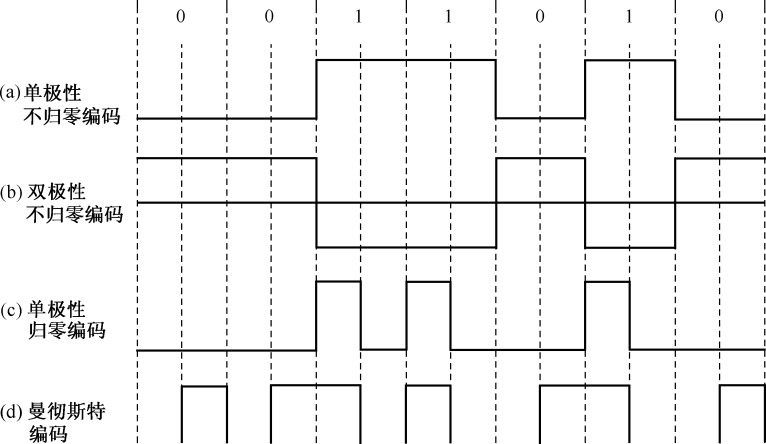
信号编码系统包括信源编码和信道编码两大类,器作用是把要传输的信息尽可能的与传输信道相匹配,并提供对信息的某种保护以防止信息受到干扰。信源编码与信源译码的目的是提高信息传输的有效性以及完成模数转换等;信道编码与信道译码的目的是增强信号的抗干扰能力,提高传输的可靠性。 常见的编码方法如下图: 图片 RFID系统常用编码方法: 反向不归零(NRZ)编码 曼彻斯特(Manchester)编码 单极性归零(RZ)编码 差动双相(DBP)编码 密勒(Miller)编码和差动编码 图片 1、反向不归零编码(NRZ,Non Return Zero) 反向不归零编码用高电平表示二进制“1”,低电平表示二进制“0”,如下图所示: 图片 此码型不宜传输,有以下原因 有直流,一般信道难于传输零频附近的频率分量; 接收端判决门限与信号功率有关,不方便使用; 不能直接用来提取位同步信号,因为NRZ中不含有位同步信号频率成分; 要求传输线有一根接地。 注:ISO14443 TYPE B协议中电子标签和阅读器传递数据时均采用NRZ 2、曼彻斯特编码(Manchester) 曼彻斯特编码也被称为分相编码(Split-Phase Coding)。 某比特位的值是由该比特长度内半个比特周期时电平的变化(上升或下降)来表示的,在半个比特周期时的负跳变表示二进制“1”,半个比特周期时的正跳变表示二进制“0”,如下图所示: 图片 曼彻斯特编码的特点 曼彻斯特编码在采用负载波的负载调制或者反向散射调制时,通常用于从电子标签到读写器的数据传输,因为这有利于发现数据传输的错误。这是因为在比特长度内,“没有变化”的状态是不允许的。 当多个标签同时发送的数据位有不同值时,则接收的上升边和下降边互相抵消,导致在整个比特长度内是不间断的负载波信号,由于该状态不允许,所以读写器利用该错误就可以判定碰撞发生的具体位置。 曼彻斯特编码由于跳变都发生在每一个码元中间,接收端可以方便地利用它作为同步时钟。 注: ISO14443 TYPE A协议中电子标签向阅读器传递数据时采用曼彻斯特编码。 ISO18000-6 TYPE B 读写器向电子标签传递数据时采用的是曼彻斯特编码 3、单极性归零编码(Unipolar RZ) 当发码1时发出正电流,但正电流持续的时间短于一个码元的时间宽度,即发出一个窄脉冲 当发码0时,完全不发送电流 单极性归零编码可用来提取位同步信号。 pPbm28I.png图片 4、差动双相编码(DBP) 差动双相编码在半个比特周期中的任意的边沿表示二进制“0”,而没有边沿就是二进制“1”,如下图所示。此外在每个比特周期开始时,电平都要反相。因此,对于接收器来说,位节拍比较容易重建。 pPbmR2t.png图片 5、密勒编码(Miller) 密勒编码在半个比特周期内的任意边沿表示二进制“1”,而经过下一个比特周期中不变的电平表示二进制“0”。一连串的比特周期开始时产生电平交变,如下图所示,因此,对于接收器来说,位节拍也比较容易重建。 pPbmhKf.png图片 pPbm5qS.png图片 6、修正密勒码编码 7、脉冲-间歇编码 对于脉冲—间歇编码来说,在下一脉冲前的暂停持续时间t表示二进制“1”,而下一脉冲前的暂停持续时间2t则表示二进制“0”,如下图所示。 pPbnUoQ.png图片 这种编码方法在电感耦合的射频系统中用于从读写器到电子标签的数据传输,由于脉冲转换时间很短,所以就可以在数据传输过程中保证从读写器的高频场中连续给射频标签供给能量。 8、脉冲位置编码(PPM,Pulse Position Modulation) 脉冲位置编码与上述的脉冲间歇编码类似,不同的是,在脉冲位置编码中,每个数据比特的宽度是一致的。 其中,脉冲在第一个时间段表示“00”,第二个时间段表示“01”, 第三个时间段表示“10”, 第四个时间段表示“11”, 如图所示 pPbnwJs.png图片 注:ISO15693协议中,数据编码采用PPM 9、FM0编码 FM0(即Bi-Phase Space)编码的全称为双相间隔码编码、 工作原理是在一个位窗内采用电平变化来表示逻辑。如果电平从位窗的起始处翻转,则表示逻辑“1”。如果电平除了在位窗的起始处翻转,还在位窗中间翻转则表示逻辑“0”。 pPbn0Wn.png图片 注:ISO18000-6 typeA 由标签向阅读器的数据发送采用FM0编码 10、PIE编码 PIE(Pulse interval encoding)编码的全称为脉冲宽度编码,原理是通过定义脉冲下降沿之间的不同时间宽度来表示数据。 在该标准的规定中,由阅读器发往标签的数据帧由SOF(帧开始信号)、EOF(帧结束信号)、数据0和1组成。在标准中定义了一个名称为“Tari”的时间间隔,也称为基准时间间隔,该时间段为相邻两个脉冲下降沿的时间宽度,持续为25μs。 pPbnBzq.png图片 注:ISO18000-6 typeA 由阅读器向标签的数据发送采用PIE编码 ============================================= 注:选择编码方法的考虑因素 编码方式的选择要考虑电子标签能量的来源 在REID系统中使用的电子标签常常是无源的,而无源标签需要在读写器的通信过程中获得自身的能量供应。为了保证系统的正常工作,信道编码方式必须保证不能中断读写器对电子标签的能量供应。 在RFID系统中,当电子标签是无源标签时,经常要求基带编码在每两个相邻数据位元间具有跳变的特点,这种相邻数据间有跳变的码,不仅可以保证在连续出现“0”时对电子标签的能量供应,而且便于电子标签从接收到的码中提取时钟信息。 编码方式的选择要考虑电子标签的检错的能力 出于保障系统可靠工作的需要,还必须在编码中提供数据一级的校验保护,编码方式应该提供这种功能。可以根据码型的变化来判断是否发生误码或有电子标签冲突发生。 在实际的数据传输中,由于信道中干扰的存在,数据必然会在传输过程中发生错误,这时要求信道编码能够提供一定程度的检测错误的能力。 曼彻斯特编码、差动双向编码、单极性归零编码具有较强的编码检错能力。 编码方式的选择要考虑电子标签时钟的提取 在电子标签芯片中,一般不会有时钟电路,电子标签芯片一般需要在读写器发来的码流中提取时钟。 曼彻斯特编码、密勒编码、差动双向编码容易使电子标签提取时钟。
通信&信息处理
# 通信&射频
# 软件算法
刘航宇
3年前
0
2,554
0
2023-07-27
一张图看懂数字IC设计前后端全流程(DC ICC PT的关系)
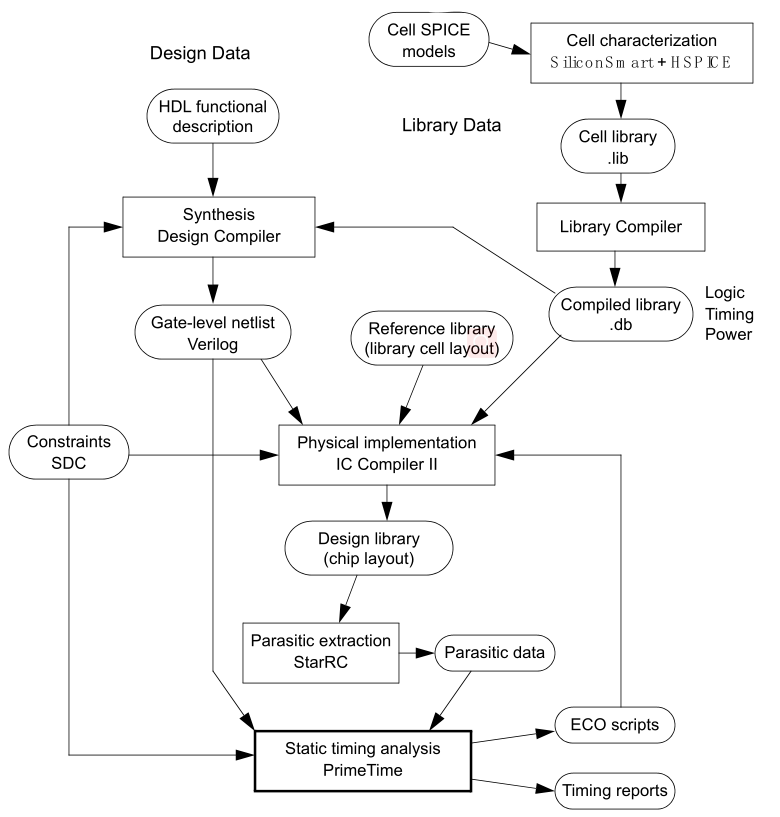
关系图 pCvyhuT.png图片 DC综合后用PrimeTime做一遍STA DC的时候,通过SDC定义了很多约束,留下了很多Margin为后端,DC综合的网表是理想的状态。后端会进行Place和Route并进行CTS,这才接近于真实的电路,后端会通过QRC吐出SPEF, SPEF在转成sdf,供PT分析.此时PT分析的已经不是综合之后的网表,PT分析的是经过PR之后且CTS之后的网表。目的就是看在经过后端处理之后时序是否还signoff。前端DC综合的时候,本身也会进行timing分析,有些路径时序不收敛,DC也会报出来,如果确认这是一条真的路径. 这样你就要改RTL了. DC自己都报时序不收敛,后面也都没有做的必要了。
FPGA&ASIC
EDA&虚拟机
# VLSI
# EDA&虚拟机
刘航宇
3年前
0
2,881
1
2023-07-23
Python机器学习- 鸢尾花分类
1、描述 2、code 3、描述 4、code 1、描述 请编写代码实现train_and_predict功能,实现能够根据四个特征对三种类型的鸢尾花进行分类。 train_and_predict函数接收三个参数: train_input_features—二维NumPy数组,其中每个元素都是一个数组,它包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 train_outputs—一维NumPy数组,其中每个元素都是一个数字,表示在train_input_features的同一行中描述的鸢尾花种类。0表示鸢尾setosa,1表示versicolor,2代表Iris virginica。 prediction_features—二维NumPy数组,其中每个元素都是一个数组,包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 该函数使用train_input_features作为输入数据,使用train_outputs作为预期结果来训练分类器。请使用训练过的分类器来预测prediction_features的标签,并将它们作为可迭代对象返回(如list或numpy.ndarray)。结果中的第n个位置是prediction_features参数的第n行。 2、code # 导入numpy库,用于处理多维数组 import numpy as np # 导入sklearn库中的数据集、模型选择、度量和朴素贝叶斯模块 from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.naive_bayes import GaussianNB # 定义train_and_predict函数,接收三个参数:训练输入特征、训练输出标签和预测输入特征 def train_and_predict(train_input_features, train_outputs, prediction_features): # 创建一个高斯朴素贝叶斯分类器对象 clf = GaussianNB() # 使用训练输入特征和训练输出标签来训练分类器 clf.fit(train_input_features, train_outputs) # 使用预测输入特征来预测输出标签,并将结果返回 y_pred = clf.predict(prediction_features) return y_pred # 加载鸢尾花数据集,包含150个样本,每个样本有四个特征和一个标签 iris = datasets.load_iris() # 将数据集随机分成训练集和测试集,其中训练集占70%,测试集占30%,并设置随机种子为0 X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3, random_state=0 ) # 调用train_and_predict函数,使用训练集来训练分类器,并使用测试集来预测标签,将结果赋值给y_pred y_pred = train_and_predict(X_train, y_train, X_test) # 如果y_pred不为空,打印预测标签和真实标签的准确率,即正确预测的比例 if y_pred is not None: print(metrics.accuracy_score(y_test, y_pred))3、描述 机器学习库 sklearn 自带鸢尾花分类数据集,分为四个特征和三个类别,其中这三个类别在数据集中分别表示为 0, 1 和 2,请实现 transform_three2two_cate 函数的功能,该函数是一个无参函数,要求将数据集中 label 为 2 的数据进行移除,也就是说仅保留 label 为 0 和为 1 的情况,并且对 label 为 0 和 1 的特征数据进行保留,返回值为 numpy.ndarray 格式的训练特征数据和 label 数据,分别为命名为 new_feat 和 new_label。 然后在此基础上,实现 train_and_evaluate 功能,并使用生成的 new_feat 和 new_label 数据集进行二分类训练,限定机器学习分类器只能从逻辑回归和决策树中进行选择,将训练数据和测试数据按照 8:2 的比例进行分割。 要求输出测试集上的 accuracy_score,同时要求 accuracy_score 要不小于 0.95。 4、code #导入numpy库,它是一个提供了多维数组和矩阵运算等功能的Python库 import numpy as np #导入sklearn库中的datasets模块,它提供了一些内置的数据集 from sklearn import datasets #导入sklearn库中的model_selection模块,它提供了一些用于模型选择和评估的工具,比如划分训练集和测试集 from sklearn.model_selection import train_test_split #导入sklearn库中的preprocessing模块,它提供了一些用于数据预处理的工具,比如归一化 from sklearn.preprocessing import MinMaxScaler #导入sklearn库中的linear_model模块,它提供了一些线性模型,比如逻辑回归 from sklearn.linear_model import LogisticRegression #导入sklearn库中的metrics模块,它提供了一些用于评估模型性能的指标,比如F1分数、ROC曲线面积、准确率等 from sklearn.metrics import f1_score,roc_auc_score,accuracy_score #导入sklearn库中的tree模块,它提供了一些树形模型,比如决策树 from sklearn.tree import DecisionTreeClassifier #定义一个函数transform_three2two_cate,它的作用是将鸢尾花数据集中的三分类问题转化为二分类问题 def transform_three2two_cate(): #从datasets模块中加载鸢尾花数据集,并赋值给data变量 data = datasets.load_iris() #其中data特征数据的key为data,标签数据的key为target #需要取出原来的特征数据和标签数据,移除标签为2的label和特征数据,返回值new_feat为numpy.ndarray格式特征数据,new_label为对应的numpy.ndarray格式label数据 #需要注意特征和标签的顺序一致性,否则数据集将混乱 #code start here #使用numpy库中的where函数找出标签为2的索引,并赋值给index_arr变量 index_arr = np.where(data.target == 2)[0] #使用numpy库中的delete函数删除特征数据中对应索引的行,并赋值给new_feat变量 new_feat = np.delete(data.data, index_arr, 0) #使用numpy库中的delete函数删除标签数据中对应索引的元素,并赋值给new_label变量 new_label = np.delete(data.target, index_arr) #code end here #返回新的特征数据和标签数据 return new_feat,new_label #定义一个函数train_and_evaluate,它的作用是用决策树分类器来训练和评估鸢尾花数据集 def train_and_evaluate(): #调用transform_three2two_cate函数,得到新的特征数据和标签数据,并赋值给data_X和data_Y变量 data_X,data_Y = transform_three2two_cate() #使用train_test_split函数,将数据集划分为训练集和测试集,其中测试集占20%,并赋值给train_x,test_x,train_y,test_y变量 train_x,test_x,train_y,test_y = train_test_split(data_X,data_Y,test_size = 0.2) #已经划分好训练集和测试集,接下来请实现对数据的训练 #code start here #创建一个决策树分类器的实例,并赋值给estimator变量 estimator = DecisionTreeClassifier() #使用fit方法,用训练集的特征和标签来训练决策树分类器 estimator.fit(train_x, train_y) #使用predict方法,用测试集的特征来预测标签,并赋值给y_predict变量 y_predict = estimator.predict(test_x) #code end here #注意模型预测的label需要定义为 y_predict,格式为list或numpy.ndarray #使用accuracy_score函数,计算测试集上的准确率分数,并打印出来 print(accuracy_score(y_predict,test_y)) #如果这个文件是作为主程序运行,则执行以下代码 if __name__ == "__main__": #调用train_and_evaluate函数 train_and_evaluate() #要求执行train_and_evaluate()后输出为: #1、{0,1},代表数据label为0和1 #2、测试集上的准确率分数,要求>0.95
机器学习
# 机器学习
# Python
刘航宇
3年前
0
565
0
算法-反转链表C&Python实现
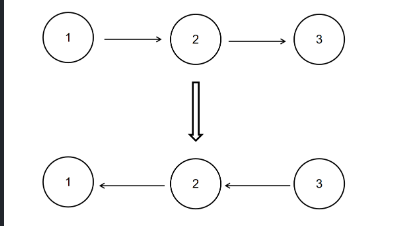
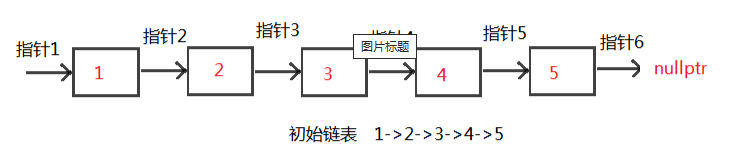
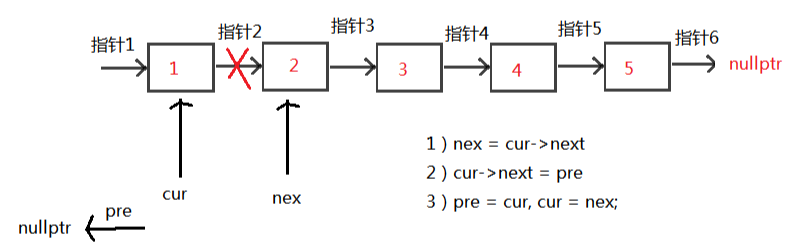
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
367
1
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
386
0
2023-07-19
嵌入式软件-基于C语言小端转大端
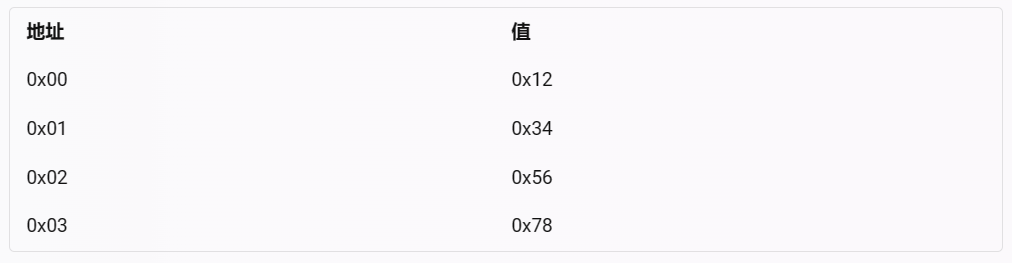
意义 题目 示例 解答1.char指针,按字节替换 2.利用union联合体共用内存空间特性,使用char数组来改变 3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 4. 使用预定义好的宏函数 意义 大端小端转化对嵌入式系统有意义,因为不同的处理器或者通信协议可能采用不同的字节序来存储或者传输数据。字节序是指一个多字节数据在内存中的存放顺序,它有两种主要的形式: 大端:最高有效位(MSB)存放在最低的内存地址,最低有效位(LSB)存放在最高的内存地址。 小端:最低有效位(LSB)存放在最低的内存地址,最高有效位(MSB)存放在最高的内存地址。 例如,一个32位的整数0x12345678,在大端系统中,它的内存布局是: pC703EF.png图片 而在小端系统中,它的内存布局是: pC70G4J.png图片 如果一个嵌入式系统需要和不同字节序的设备或者网络进行交互,就需要进行字节序的转换,否则会导致数据错误或者通信失败。例如,TCP/IP协议族中的所有层都采用大端字节序来表示数据包头中的16位或32位的值,如IP地址、包长、校验和等。如果一个嵌入式系统使用小端字节序的处理器,并且想要建立一个TCP连接,就需要将IP地址等信息从小端转换为大端再发送出去,否则对方无法正确解析。 题目 输入一个数字n,假设它是以小端模式保存在机器的,请将其转换为大端方式保存时的值。 示例 输入:1 返回值:16777216 解答 1.char指针,按字节替换 /* * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here int tmp = 0x00000000; //开辟新的int空间用于接收转化结果 unsigned char *p = &tmp, *q = &n; p[0] = q[3]; p[1] = q[2]; p[2] = q[1]; p[3] = q[0]; return tmp; }2.利用union联合体共用内存空间特性,使用char数组来改变 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ typedef union { int i; unsigned char c[4] } inc_u; int convert(int n ) { // write code here inc_u x; //这里也可以用新开辟空间进行置换 x.i = n; //利用按位异或运算可叠加、可还原性 x.c[0] ^= x.c[3], x.c[3] ^= x.c[0], x.c[0] ^= x.c[3]; //首尾两字节对调 x.c[1] ^= x.c[2], x.c[2] ^= x.c[1], x.c[1] ^= x.c[2]; //中间两字节对调 return x.i; /* 按位<<到正确位置,并用|拼装 return (x.c[0]<<24)|(x.c[1]<<16)|(x.c[2]<<8)|x.c[3]; */ }3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return (((n & 0xff000000)>>24) | ((n & 0x00ff0000)>>8 ) | ((n & 0x0000ff00)<<8 ) | ((n & 0x000000ff)<<24); //按位与时,遇0清零,遇1保留 ); }4. 使用预定义好的宏函数 本条方法参考 https://www.codeproject.com/Articles/4804/Basic-concepts-on-Endianness 文中提到网络上常用的套接字接口(socket API)指定了一种称为网络字节顺序的标准字节顺序,这个顺序其实就是大端模式;而当时,同时代的 x86 系列主机反而是小端模式。所以就促使产生了如: ntohs() convert Network order TO Host order in Short (16 bit 大转小); ntohl() convert Network order TO Host order in Long (32 bit 大转小); htons() convert Host order TO Network order in Short (16 bit 小转大); htonl() convert Host order TO Network order in Long (32 bit 小转大). 所以我们这里使用 32 bit 小转大的 htonl() 宏函数来解决这个问题。 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return htonl(n); ); }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
621
1
2023-07-13
反向散射理论与ADG902电路实现
后向散射通信技术,是在天线对信号散射的基础上,采用标签后向散射的方式,通过改变发射端标签的反射系数来实现后向散射通信。无线电波在传输过程中,当通过不同介质时,因为介质阻抗的差异性,会产生反射作用,根据介质材料和阻抗的不同,会产生不同的反射量。因此通过调节天线端口的阻抗匹配度,入射的无线电波就可以产生不同反射量,导致入射信号和反射信号的差异性,也就是反射系数 Γ 。具体表示如下: $$\Gamma=\frac{Z_L-Z_0}{Z_L+Z_0}$$ 式中 Z0表示天线端的特征阻抗,一般是 50 Ω,ZL表示标签端口的输入阻抗,Γ表示入射信号振幅和反射信号振幅的复数比。当Γ=0 时,阻抗匹配,入射信号全部传递,无反射信号的产生;Γ = 1时,标签端的输入阻抗为开路,阻抗失配,入射信号被全部反射,产生幅值相同相位相同的反射信号;Γ = −1时,标签端的输入阻抗为短路状态,阻抗失配,入射信号被全部反射,产生幅值相同相位相反的反射信号。因此,通过改变标签的输入阻抗,产生不同的反射系数,就可以控制无线电波的入射和反射,实现有效信号的传递,这也就是后向散射通信的基本原理。为了实现上述后向散射通信,还需要加载天线端口的控制,结构如下图。通过射频开关来控制两个不同的负载阻抗与天线端口的连接,实现阻抗的匹配和失调,完成信号的入射和反射。当开关在负载 Z1和 Z2间转化时,由于负载阻抗的不同,载波信号在天线端的反射比例也不同,因此就产生了不同的调制载波。在实际通信中,为了达到最优传输质量,通常要使反射信号的差异最大,对应完全反射和完全吸收两种形式。对调制后的反射信号进行解调处理后,就可以得到所传递的基带信号,完成后向散射的通信。采用负载 50 Ω 的完全吸收和负载短路的完全反射两种信号传输差异,来实现后向散射的信息传输。 图片 使用后向散射开关 ADG 902 来实现基带信号对天线状态的控制,ADG 902 电路结构如图 4.12 所示。将数字基带信号的接入 ADG 902 的 CTRL 端,通过数字基带信号的“0”、“1”来控制 ADG 902 的关断和闭合,RF2 端连接射频天线。通过 ADG 902 中开关的关断,来控制天线对外界调制载波的反射和吸收。 注意:RF1接天线,RF2接地也可以,这里读者可自行证明 图片 当逻辑电平 CTRL=0时,S1关断,S2闭合,此时天线接收端口接地,由式可得,Z=0,T=1,载波信号被完全反射;当逻辑电平 CTRL=1 时,S1 闭合,S2 关断,此时天线接收端匹配,载波被完全吸收。
通信&信息处理
# 通信&射频
# 物联网
刘航宇
3年前
1
1,543
1
【转载】Libero SOC Debug教程-片上逻辑分析仪IDENTIFY
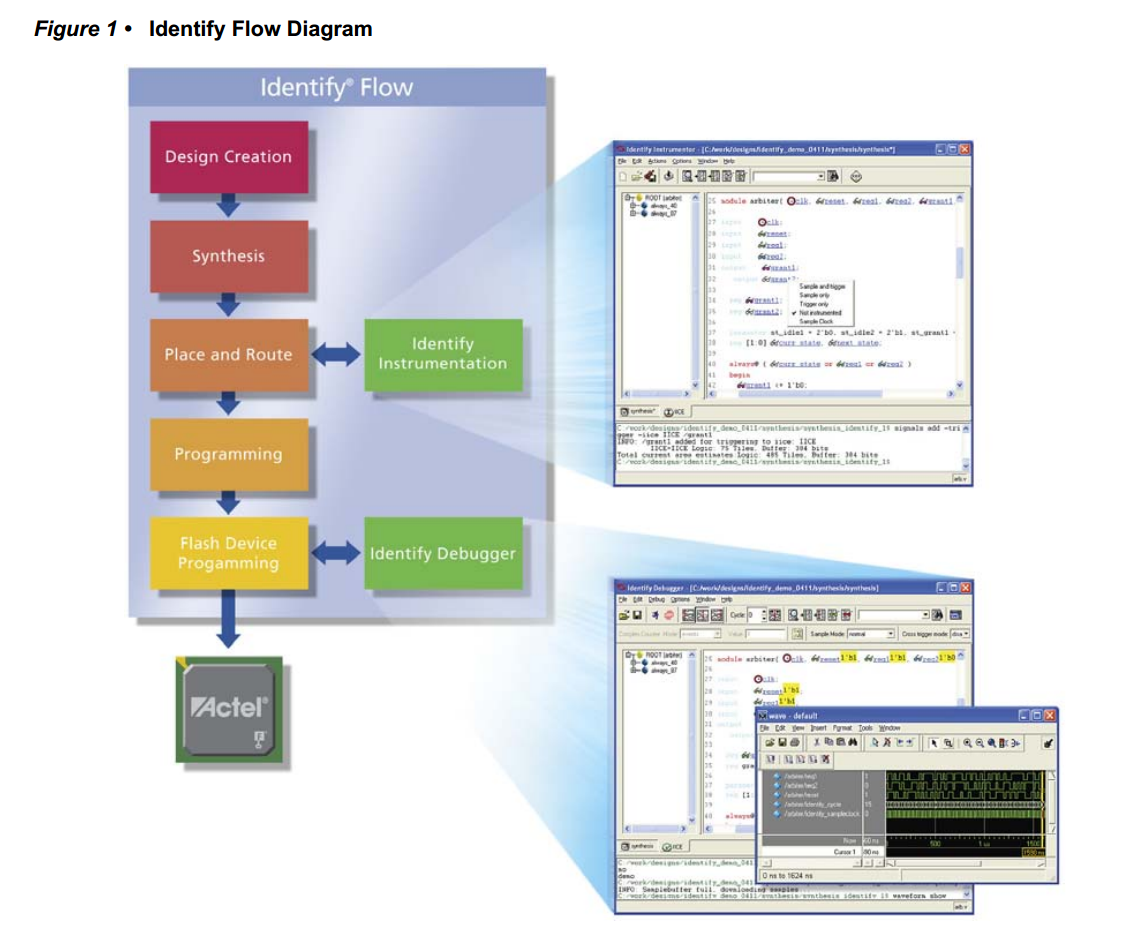
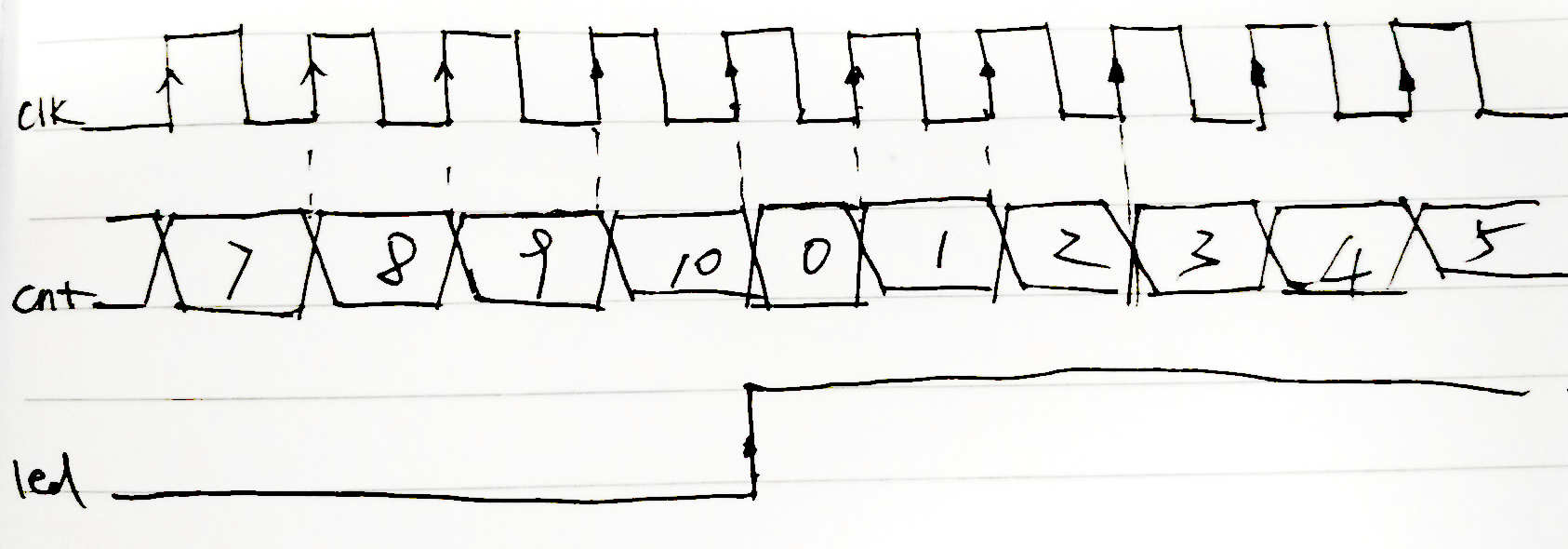
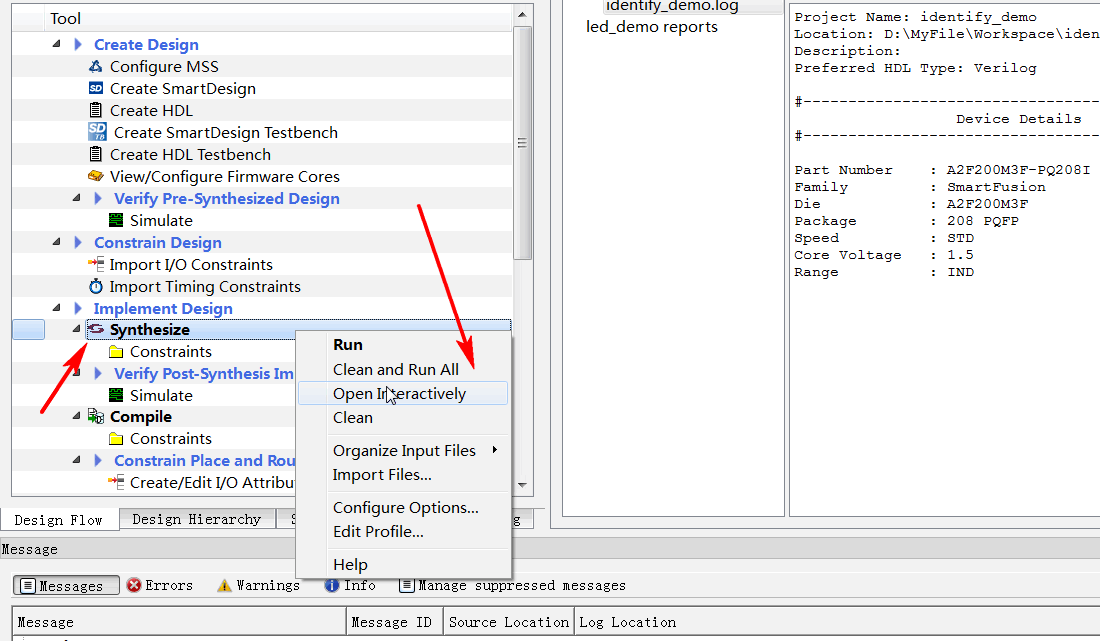
本文转载于https://blog.csdn.net/whik1194/article/details/107074187 FPGA在线调试 关于MICROSEMI片上逻辑分析仪 FPGA片上逻辑分析仪原理 预期效果 0.准备一个创建好的LIBERO工程 1.新建IDENTIFY工程,并添加想要监测的信号 2.管脚分配,编译下载 3.设置触发类型 4.IICE逻辑分析仪核资源占用 原文: 参考: FPGA在线调试 对于嵌入式系统来说,如单片机,进行硬件级程序调试时,通常采用的是JLink/ST-Link调试器,在线调试的方式来获取程序实时运行的状态,可以观察程序运行流程、各种变量的值、中断的触发情况,还可以设置断点、单步运行,方便快速的发现BUG,解决问题。 但是对于FPGA来说,并不是顺序执行的,而是根据每一个Clk并行执行,所以我们不能使用调试器进行单步调试。 FPGA调试需要观察内部信号的值,各个信号之间的时序关系,所以使用逻辑分析仪是最好的调试方式了。 有些FPGA工程,对外的接口,即输入输出,可能只有几个,但是他们之间的逻辑和时序关系非常复杂,所以内部有几十个中间寄存器,程序下载进去了,发现不是我们想要的效果,怎么办?你可能会说,查代码吧!如果这个工程非常简单,你可能只需要耗费几分钟或者几个小时就可以定位代码的问题所在。 但是如果这是一个非常庞大的工程,内部的中间寄存器、信号,几百上千个,各个模块单独软件仿真都正常,整体仿真也正常,就是下载到实际的芯片中运行不正常。你如何进行问题定位?如果再去进行代码审查,这将会消耗非常多的时间。那么如果能在FPGA芯片内部装上一个逻辑分析仪,那不就直接可以看到内部信号的值了,而且还可以看到各个信号之间的时序关系。需求推动技术发展,既然开发者有这个需求,那么FPGA厂商肯定会实现这个功能!下面来一起看一下Microsemi FPGA片上逻辑分析仪的使用方法吧! 关于MICROSEMI片上逻辑分析仪 几大厂商的片上逻辑分析仪: Xilinx厂商ISE开发环境下的ChipScope工具 Altera厂商Quartus开发环境下的SignalTap工具 Lattice厂商Diamod开发环境下的Reveal工具 对于 FPGA 工程师来说,这些都是很熟悉的名字。和以上几大FPGA厂商一样,Microsemi Libero也支持片上逻辑分析仪工具,只不过不是自己家研发的,使用的是Synospsy公司出品的Identify工具,其实,Libero中的综合器synplify也是Synospsy公司的。 根据Synospsy官网的描述:Identify RTL 调试仪,这个调试工具除了支持Microsemi的FPGA产品外,还支持Altera和Xilinx的FPGA产品。 FPGA片上逻辑分析仪原理 Identify片上逻辑分析仪的原理,是通过在FPGA工程中加入一个IICE逻辑分析仪IP核,这个IP核,由控制器和采集器组成,采集器用于采集信号,控制器用于和JTAG调试器连接,并把数据发送到上位机,IICE内部有RAM空间,用于存储触发位置附近的信号,RAM空间的大小,即采样深度,可以自己调整。FPGA工程中加入IICE核,会占用一定的资源,资源占用的大小取决于:采样深度,采样信号的个数,采样信号的触发方式等。 所以综上,FPGA片上逻辑分析仪需要3个组件:片上的IICE逻辑分析仪核、JTAG下载器、上位机。 pC5Uq6e.png图片 JTAG下载器也就是我们下载程序时使用的FlashPro x下载器,上位机软件也就是Identify工具,这个工具已经在安装Libero SoC时一同安装并注册**了。所以不需要安装其他的工具软件,只需要在已经设计好的FPGA公司中,配置一下IIC逻辑分析仪核就可以了。 在已经创建好的Libero工程中,加入IICE逻辑分析仪核,并演示Identify工具的使用。 预期效果 以Microsemi SmartFusion系列的A2F200M3F芯片为例,其他芯片使用操作方法类似。示例工程功能:led每隔10个clk翻转一次为例,演示identify的使用。 identify添加完成之后,把led设置为上升沿触发,会抓取到类似如下的波形。 pChB2qJ.png图片 0.准备一个创建好的LIBERO工程 这里以LED每隔10个时钟周期翻转为例。HDL文件内容: module led_demo( //inputs input clk, input rst_n, //outputs output reg led ); reg [3:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 0; else if(cnt == 10) /* max=10, 0-10 */ cnt <= 0; else cnt <= cnt + 1; end always @ (posedge clk) begin if(!rst_n) led <= 0; else if(cnt == 10) led <= ~led; end endmodule1.新建IDENTIFY工程,并添加想要监测的信号 1.0 先运行Synthesize 1.1 在Synthesize上右键,选择Open Interactively pChr5jO.png图片 1.2 在Synthesis上右键新建一个Identify工程 pChrTDe.png图片 1.3 输入新建的identify工程的名称和保存路径,选择默认的就行。 pChrqUA.png图片 1.4 在新建的identify工程上右键选择identify instrumentor pChsSKS.png图片 1.5 在HDL文件中选择要监测的信号和采样时钟,采样时钟选择Sample Clock,作为触发的信号选择Trigger Only,要监测的信号选择Sample Only,也可以选择Sample and Trigger,这样会占用更多的资源。 pChsG26.png图片 pChsNrD.png图片 设置完成的信号会有标注 pChsgsS.png图片 sample clock 表示采样时钟,所有在 IICE 中添加的信号都会在 sample clock 的边沿进行采样,设为 sample clock 的信号前会出现一个时钟状的图标。 设置为 sample 和 trigger 的信号都将作为被采样信号,区别在于 sample 信号只能被采样,而 trigger 信号可以作为触发采集的条件,当然你可以把一个信号同时设置为 sample 和 trigger 。 1.6 设置采样深度,选择Instrumentor->IICE pChsWZQ.png图片 采样深度最大支持1048576 pChsfaj.png图片 输入采样深度,数值越大,采样时间越长,相应的FPGA资源占用也越多。 pChsqLF.png图片 1.7 选择Run->Run pChsOZ4.png图片 或者直接点击主界面的Run按钮 pChsjo9.png图片 1.8 编译完成之后,保存退出。 pChsxiR.png图片 2.管脚分配,编译下载 2.1 和正常流程一样,管脚分配,编译下载。可以看到JTAG部分的管脚已经被IICE逻辑分析仪核使用了 pChyiLD.png图片 2.2 在Identify Debug Design上右键,选择Open Interactively,打开identify工具 pChymWt.png图片 3.设置触发类型 3.1 选择要触发的信号,和触发类型,这里我选择的是led,上升沿触发。 pChyYYn.png图片 3.2 连接FlashPro下载器,点击小人图标,启动抓取,满足触发条件自动停止。 pChy6YR.png图片 D:/identify_demo/synthesis$ run -iice {IICE} INFO: run -iice IICE INFO: Info: Attempting to connect to: usb Info: Type: FlashPro4 Info: ID: 08152 Info: Connection: usb2.0 Info: Revision: UndefRev INFO: Checking communication with the Microsemi_BuiltinJTAG cable and the hardware INFO: The hardware is responding correctly INFO: Auto-detecting the device chain INFO: Device at chain position 1 is "A2F200M3F" INFO: IICE 'IICE' configured, waiting for trigger INFO: IICE 'IICE' Trigger detected, downloading samples INFO: notify -notify INFO: waveform viewer INFO: waveform viewer INFO: write vcd -iice IICE -comment {Identify created VCD dump} -gtkwave -noequiv IICE.vcd D:/identify_demo/synthesis$ 3.3 右侧黄色的显示就是触发瞬间时信号的值。右键可以改变数据格式。 pChyO6f.png图片 3.4 选择Debugger preferences可以设置采样时钟的周期,用于后面波形的时间测量 pChyz7Q.png图片 3.5 设置采样时钟的周期 pCh6Chn.png图片 3.6 点击波形按钮,在GTKWave中打开抓取到的波形。 pCh6kcV.png图片 3.7 可以按住左键拖动测量时间差 pCh6uN9.png图片 3.8 还可以给每个通道设置不同的颜色,和显示方式。 pCh6Q91.png图片 4.IICE逻辑分析仪核资源占用 IICE逻辑分析仪核占用的主要是逻辑资源和RAM资源,可以看到资源占用还是很多的。 图片 图片 原文: https://blog.csdn.net/whik1194/article/details/107074187 参考: https://zhuanlan.zhihu.com/p/88314552 https://www.synopsys.com/zh-cn/implementation-and-signoff/fpga-based-design/identify-rtl-debugger.html http://training.eeworld.com.cn/video/1059 https://www.microsemi.com/document-portal/doc_view/132760-synopsys-identify-me-h-2013-03m-sp1-user-guide
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
2
3,104
2
2023-07-10
Verilog实现AMBA--AHB To APB Bridge
1、APB桥 2、读传输 3、写传输 4、背靠背传输 5、AHB_to_APB Bridge的Verilog实现 6、仿真 1、APB桥 APB桥是AMBA APB总线上的唯一主机,也是AMBA AHB的一个从机。下图表示了APB桥接口信号: 图片 APB Bridge将AHB传输转成APB传输并实现一下功能: (1)对锁存的地址进行译码并产生选择信号PSELx,在传输过程中只有一个选择信号可以被激活。 也就是选择出唯一 一个APB从设备以进行读写动作。 (2)写操作时:负责将AHB送来的数据送上APB总线。 (3)读操作时:负责将APB的数据送上AHB系统总线。 (4)产生一时序选通信号PENABLE来作为数据传递时的启动信号 2、读传输 下图表示了APB到AHB的读传输: 图片 传输开始于AHB总线上的T1时刻,在T2时刻地址信息被APB采样,如果传输目标是外设总线,那么这个地址就会被译码成选择信号发给外设,T2即为APB总线的SETUP周期,T3为APB的ENABLE周期,PENABLE信号拉高。在该周期内,外设必须提供读数据,通常情况下,读数据直接AHB读数据总线上,总线主机在T4时刻对读数据进行采样。 在频率很高的情况下,在ENABLE CYCLE中可能数据不能够直接映射到AHB总线,需要在APB桥中在T4的时候打插入一个额外的等待周期,并在T5的时候才被AHB主采样。虽然需要多一个等待周期(一共2个),但是由于频率提升了因此总的性能也提升了。 下图表示了一个读突发传输,所有的传输都只有一个等待周期 图片 3、写传输 下图表示了一个写传输: 图片 APB总线上的单块数据写操作不需要等待周期。 APB桥负责对地址和数据进行采样,并在写操作的过程中保持它们的值。 下图表示了一个写突发传输: 图片 虽然第一个传输可以零等待完成,但后续每一个传输都需要插入一个等待状态。 APB桥需要两个地址寄存器,以便在当前传输进行时,锁存下一次传输的地址。 4、背靠背传输 下图表示了一个背靠背传输,顺序为写、读、写、读: 如果写操作之后跟随着读操作,那么需要 3 个等待周期来完成这个读操作。通常的情况下,不会有读操作之后紧跟着写操作的发生,因为两者之间 CPU 会进行指令读取,并且指令存储器也不太可能挂在在APB总线上。 图片 下面以ARM DesignStart项目提供的软件包里的AHB转APB桥的代码,对其进行学习与仿真,以深入理解APB桥的实现方法,该转换桥比较简单,实现的是一对一的转换,也可以配合APB slave multiplexer模块,实现一对多的方式(主要依靠APB高位地址译码得到各个从机的PSEL信号)。如果想学习APB系统总线,可以参考Synopsys公司的DW_APB IP,该IP最多可支持16个APB从机,并支持所有的突发传输类型。 5、AHB_to_APB Bridge的Verilog实现 `timescale 1ns / 1ps module ahb_to_apb #( // Parameter to define address width // 16 = 2^16 = 64KB APB address space parameter ADDRWIDTH = 16, parameter REGISTER_RDATA = 1, parameter REGISTER_WDATA = 0 ) ( //---------------------------------- // IO Declarations //---------------------------------- input wire HCLK, // Clock input wire HRESETn, // Reset input wire PCLKEN, // APB clock enable signal input wire HSEL, // Device select input wire [ADDRWIDTH-1:0] HADDR, // Address input wire [1:0] HTRANS, // Transfer control input wire [2:0] HSIZE, // Transfer size input wire [3:0] HPROT, // Protection control input wire HWRITE, // Write control input wire HREADY, // Transfer phase done input wire [31:0] HWDATA, // Write data output reg HREADYOUT, // Device ready output wire [31:0] HRDATA, // Read data output output wire HRESP, // Device response // APB Output output wire [ADDRWIDTH-1:0] PADDR, // APB Address output wire PENABLE, // APB Enable output wire PWRITE, // APB Write output wire [3:0] PSTRB, // APB Byte Strobe output wire [2:0] PPROT, // APB Prot output wire [31:0] PWDATA, // APB write data output wire PSEL, // APB Select output wire APBACTIVE, // APB bus is active, for clock gating of APB bus // APB Input input wire [31:0] PRDATA, // Read data for each APB slave input wire PREADY, // Ready for each APB slave input wire PSLVERR // Error state for each APB slave ); //---------------------------------- // Variable Declarations //---------------------------------- reg [ADDRWIDTH-3:0] addr_reg; // Address sample register reg wr_reg; // Write control sample register reg [2:0] state_reg; // State for finite state machine reg [3:0] pstrb_reg; // Byte lane strobe register wire [3:0] pstrb_nxt; // Byte lane strobe next state reg [1:0] pprot_reg; // PPROT register wire [1:0] pprot_nxt; // PPROT register next state wire apb_select; // APB bridge is selected wire apb_tran_end; // Transfer is completed on APB reg [2:0] next_state; // Next state for finite state machine reg [31:0] rwdata_reg; // Read/Write data sample register wire reg_rdata_cfg; // REGISTER_RDATA paramater wire reg_wdata_cfg; // REGISTER_WDATA paramater reg sample_wdata_reg; // Control signal to sample HWDATA //---------------------------------- // Local Parameter Declarations //---------------------------------- // State machine localparam ST_BITS = 3; localparam [ST_BITS-1:0] ST_IDLE = 3'b000; // Idle waiting for transaction localparam [ST_BITS-1:0] ST_APB_WAIT = 3'b001; // Wait APB transfer localparam [ST_BITS-1:0] ST_APB_TRNF = 3'b010; // Start APB transfer localparam [ST_BITS-1:0] ST_APB_TRNF2 = 3'b011; // Second APB transfer cycle localparam [ST_BITS-1:0] ST_APB_ENDOK = 3'b100; // Ending cycle for OKAY localparam [ST_BITS-1:0] ST_APB_ERR1 = 3'b101; // First cycle for Error response localparam [ST_BITS-1:0] ST_APB_ERR2 = 3'b110; // Second cycle for Error response localparam [ST_BITS-1:0] ST_ILLEGAL = 3'b111; // Illegal state //---------------------------------- // Start of Main Code //---------------------------------- // Configuration signal assign reg_rdata_cfg = (REGISTER_RDATA == 0) ? 1'b0 : 1'b1; assign reg_wdata_cfg = (REGISTER_WDATA == 0) ? 1'b0 : 1'b1; // Generate APB bridge select assign apb_select = HSEL & HTRANS[1] & HREADY; // Generate APB transfer ended assign apb_tran_end = (state_reg == 3'b011) & PREADY; assign pprot_nxt[0] = HPROT[1]; // (0) Normal, (1) Privileged assign pprot_nxt[1] = ~HPROT[0]; // (0) Data, (1) Instruction // Byte strobe generation // - Only enable for write operations // - For word write transfers (HSIZE[1]=1), all byte strobes are 1 // - For hword write transfers (HSIZE[0]=1), check HADDR[1] // - For byte write transfers, check HADDR[1:0] assign pstrb_nxt[0] = HWRITE & ((HSIZE[1])|((HSIZE[0])&(~HADDR[1]))|(HADDR[1:0]==2'b00)); assign pstrb_nxt[1] = HWRITE & ((HSIZE[1])|((HSIZE[0])&(~HADDR[1]))|(HADDR[1:0]==2'b01)); assign pstrb_nxt[2] = HWRITE & ((HSIZE[1])|((HSIZE[0])&( HADDR[1]))|(HADDR[1:0]==2'b10)); assign pstrb_nxt[3] = HWRITE & ((HSIZE[1])|((HSIZE[0])&( HADDR[1]))|(HADDR[1:0]==2'b11)); // Sample control signals always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) begin addr_reg <= {(ADDRWIDTH-2){1'b0}}; wr_reg <= 1'b0; pprot_reg <= {2{1'b0}}; pstrb_reg <= {4{1'b0}}; end else if (apb_select) begin // Capture transfer information at the end of AHB address phase addr_reg <= HADDR[ADDRWIDTH-1:2]; wr_reg <= HWRITE; pprot_reg <= pprot_nxt; pstrb_reg <= pstrb_nxt; end end // Sample write data control signal // Assert after write address phase, deassert after PCLKEN=1 wire sample_wdata_set = apb_select & HWRITE & reg_wdata_cfg; wire sample_wdata_clr = sample_wdata_reg & PCLKEN; always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) sample_wdata_reg <= 1'b0; else if (sample_wdata_set | sample_wdata_clr) sample_wdata_reg <= sample_wdata_set; end // Generate next state for FSM // Note : case 3'b111 is not used. The design has been checked that // this illegal state cannot be entered using formal verification. always @(state_reg or PREADY or PSLVERR or apb_select or reg_rdata_cfg or PCLKEN or reg_wdata_cfg or HWRITE) begin case (state_reg) // Idle ST_IDLE : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end // Transfer announced on AHB, but PCLKEN was low, so waiting ST_APB_WAIT : begin if (PCLKEN) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high end // First APB transfer cycle ST_APB_TRNF : begin if (PCLKEN) next_state = ST_APB_TRNF2; // Change to second cycle of APB transfer else next_state = ST_APB_TRNF; // Change to state-2 end // Second APB transfer cycle ST_APB_TRNF2 : begin if (PREADY & PSLVERR & PCLKEN) // Error received - Generate two cycle // Error response on AHB by next_state = ST_APB_ERR1; // Changing to state-5 and 6 else if (PREADY & (~PSLVERR) & PCLKEN) begin // Okay received if (reg_rdata_cfg) // Registered version next_state = ST_APB_ENDOK; // Generate okay response in state 4 else // Non-registered version next_state = {2'b00, apb_select}; // Terminate transfer end else // Slave not ready next_state = ST_APB_TRNF2; // Unchange end // Ending cycle for OKAY (registered response) ST_APB_ENDOK : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end // First cycle for Error response ST_APB_ERR1 : next_state = ST_APB_ERR2; // Goto 2nd cycle of error response // Second cycle for Error response ST_APB_ERR2 : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end default : // Not used next_state = 3'bxxx; // X-Propagation endcase end // Registering state machine always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) state_reg <= 3'b000; else state_reg <= next_state; end // Sample PRDATA or HWDATA always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) rwdata_reg <= {32{1'b0}}; else if (sample_wdata_reg & reg_wdata_cfg & PCLKEN) rwdata_reg <= HWDATA; else if (apb_tran_end & reg_rdata_cfg & PCLKEN) rwdata_reg <= PRDATA; end // Connect outputs to top level assign PADDR = {addr_reg, 2'b00}; // from sample register assign PWRITE = wr_reg; // from sample register // From sample register or from HWDATA directly assign PWDATA = (reg_wdata_cfg) ? rwdata_reg : HWDATA; assign PSEL = (state_reg == ST_APB_TRNF) | (state_reg == ST_APB_TRNF2); assign PENABLE = (state_reg == ST_APB_TRNF2); assign PPROT = {pprot_reg[1], 1'b0, pprot_reg[0]}; assign PSTRB = pstrb_reg[3:0]; // Generate HREADYOUT always @(state_reg or reg_rdata_cfg or PREADY or PSLVERR or PCLKEN) begin case (state_reg) ST_IDLE : HREADYOUT = 1'b1; // Idle ST_APB_WAIT : HREADYOUT = 1'b0; // Transfer announced on AHB, but PCLKEN was low, so waiting ST_APB_TRNF : HREADYOUT = 1'b0; // First APB transfer cycle // Second APB transfer cycle: // if Non-registered feedback version, and APB transfer completed without error // Then response with ready immediately. If registered feedback version, // wait until state_reg == ST_APB_ENDOK ST_APB_TRNF2 : HREADYOUT = (~reg_rdata_cfg) & PREADY & (~PSLVERR) & PCLKEN; ST_APB_ENDOK : HREADYOUT = reg_rdata_cfg; // Ending cycle for OKAY (registered response only) ST_APB_ERR1 : HREADYOUT = 1'b0; // First cycle for Error response ST_APB_ERR2 : HREADYOUT = 1'b1; // Second cycle for Error response default : HREADYOUT = 1'bx; // x propagation (note :3'b111 is illegal state) endcase end // From sample register or from PRDATA directly assign HRDATA = (reg_rdata_cfg) ? rwdata_reg : PRDATA; assign HRESP = (state_reg == ST_APB_ERR1) | (state_reg == ST_APB_ERR2); assign APBACTIVE = (HSEL & HTRANS[1]) | (|state_reg); endmodule使用的测试用例和AHB从机的测试用例基本一样,首先是顶层: `timescale 1ns / 1ps module top_tb(); //---------------------------------- // Local Parameter Declarations //---------------------------------- localparam AHB_CLK_PERIOD = 5; // Assuming AHB CLK to be 100MHz localparam SIZE_IN_BYTES = 2048; localparam ADDRWIDTH = 32; //---------------------------------- // Variable Declarations //---------------------------------- reg HCLK = 0; wire HWRITE; wire [1:0] HTRANS; wire [2:0] HSIZE; wire [2:0] HBURST; wire HREADYIN; wire [31:0] HADDR; wire [3:0] HPROT; wire [31:0] HWDATA; wire HREADYOUT; wire [1:0] HRESP; wire [31:0] HRDATA; reg HRESETn; wire HREADY; wire [ADDRWIDTH-1:0] PADDR; // APB Address wire PENABLE; // APB Enable wire PWRITE; // APB Write wire [31:0] PWDATA; // APB write data wire PSEL; // APB Select wire PREADY; wire PSLVERR; wire [2:0] PPROT; wire [3:0] PSTRB; wire [31:0] PRDATA; //---------------------------------- // Start of Main Code //---------------------------------- assign HREADY = HREADYOUT; //----------------------------------------------------------------------- // Generate HCLK //----------------------------------------------------------------------- always #AHB_CLK_PERIOD HCLK <= ~HCLK; //----------------------------------------------------------------------- // Generate HRESETn //----------------------------------------------------------------------- initial begin HRESETn = 1'b0; repeat(5) @(posedge HCLK); HRESETn = 1'b1; end ahb_master #( .START_ADDR (32'h0), .DEPTH_IN_BYTES (SIZE_IN_BYTES) ) u_ahb_master ( .HRESETn (HRESETn), .HCLK (HCLK), .HADDR (HADDR), .HPROT (HPROT), .HTRANS (HTRANS), .HWRITE (HWRITE), .HSIZE (HSIZE), .HBURST (HBURST), .HWDATA (HWDATA), .HRDATA (HRDATA), .HRESP (HRESP), .HREADY (HREADYOUT) ); ahb_to_apb #( .ADDRWIDTH (ADDRWIDTH), .REGISTER_RDATA (0), .REGISTER_WDATA (0) ) u_ahb_to_apb( .HCLK (HCLK), .HRESETn (HRESETn), .PCLKEN (1'b1), .HSEL (1'b1), .HADDR (HADDR), .HTRANS (HTRANS), .HSIZE (HSIZE), .HPROT (HPROT), .HWRITE (HWRITE), .HREADY (HREADY), .HWDATA (HWDATA), .HREADYOUT (HREADYOUT), .HRDATA (HRDATA), .HRESP (HRESP), .PADDR (PADDR), .PENABLE (PENABLE), .PWRITE (PWRITE), .PREADY (PREADY), .PSLVERR (PSLVERR), .PSTRB (PSTRB), .PPROT (PPROT), .PWDATA (PWDATA), .PSEL (PSEL), .APBACTIVE (APBACTIVE), .PRDATA (PRDATA) ); apb_mem #( .P_SLV_ID (0), .ADDRWIDTH (ADDRWIDTH), .P_SIZE_IN_BYTES (SIZE_IN_BYTES), .P_DELAY (0) ) u_apb_mem ( `ifdef AMBA_APB3 .PREADY (PREADY), .PSLVERR (PSLVERR), `endif `ifdef AMBA_APB4 .PSTRB (PSTRB), .PPROT (PPROT), `endif .PRESETn (HRESETn), .PCLK (HCLK), .PSEL (PSEL), .PENABLE (PENABLE), .PADDR (PADDR), .PWRITE (PWRITE), .PRDATA (PRDATA), .PWDATA (PWDATA) ); `ifdef VCS initial begin $fsdbDumpfile("top_tb.fsdb"); $fsdbDumpvars; end initial begin `ifdef DUMP_VPD $vcdpluson(); `endif end `endif endmodule然后是AHB master的功能模型: `timescale 1ns / 1ps `define SINGLE_TEST `define BURST_TEST module ahb_master #( //---------------------------------- // Paramter Declarations //---------------------------------- parameter START_ADDR = 0, parameter DEPTH_IN_BYTES = 32'h100, parameter END_ADDR = START_ADDR+DEPTH_IN_BYTES-1 ) ( //---------------------------------- // IO Declarations //---------------------------------- input wire HRESETn, input wire HCLK, output reg [31:0] HADDR, output reg [1:0] HTRANS, output reg HWRITE, output reg [2:0] HSIZE, output reg [2:0] HBURST, output reg [3:0] HPROT, output reg [31:0] HWDATA, input wire [31:0] HRDATA, input wire [1:0] HRESP, input wire HREADY ); //---------------------------------- // Variable Declarations //---------------------------------- reg [31:0] data_burst[0:1023]; //---------------------------------- // Start of Main Code //---------------------------------- initial begin HADDR = 0; HTRANS = 0; HPROT = 0; HWRITE = 0; HSIZE = 0; HBURST = 0; HWDATA = 0; while(HRESETn === 1'bx) @(posedge HCLK); while(HRESETn === 1'b1) @(posedge HCLK); while(HRESETn === 1'b0) @(posedge HCLK); `ifdef SINGLE_TEST repeat(3) @(posedge HCLK); memory_test(START_ADDR, END_ADDR, 1); memory_test(START_ADDR, END_ADDR, 2); memory_test(START_ADDR, END_ADDR, 4); `endif `ifdef BURST_TEST repeat(5) @(posedge HCLK); memory_test_burst(START_ADDR, END_ADDR, 1); memory_test_burst(START_ADDR, END_ADDR, 2); memory_test_burst(START_ADDR, END_ADDR, 4); memory_test_burst(START_ADDR, END_ADDR, 6); memory_test_burst(START_ADDR, END_ADDR, 8); memory_test_burst(START_ADDR, END_ADDR, 10); memory_test_burst(START_ADDR, END_ADDR, 16); memory_test_burst(START_ADDR, END_ADDR, 32); memory_test_burst(START_ADDR, END_ADDR, 64); memory_test_burst(START_ADDR, END_ADDR, 128); memory_test_burst(START_ADDR, END_ADDR, 255); repeat(5) @(posedge HCLK); `endif $finish(2); end //----------------------------------------------------------------------- // Single transfer test //----------------------------------------------------------------------- task memory_test; input [31:0] start; // start address input [31:0] finish; // end address input [2:0] size; // data size: 1, 2, 4 integer i; integer error; reg [31:0] data; reg [31:0] gen; reg [31:0] got; reg [31:0] reposit[START_ADDR:END_ADDR]; begin $display("%m: read-after-write test with %d-byte access", size); error = 0; gen = $random(7); for (i = start; i < (finish-size+1); i = i + size) begin gen = $random & ~32'b0; data = align(i, gen, size); ahb_write(i, size, data); ahb_read(i, size, got); got = align(i, got, size); if (got !== data) begin $display("[%10d] %m A:%x D:%x, but %x expected", $time, i, got, data); error = error + 1; end end if (error == 0) $display("[%10d] %m OK: from %x to %x", $time, start, finish); $display("%m read-all-after-write-all with %d-byte access", size); error = 0; gen = $random(1); for (i = start; i < (finish-size+1); i = i + size) begin gen = {$random} & ~32'b0; data = align(i, gen, size); reposit[i] = data; ahb_write(i, size, data); end for (i = start; i < (finish-size+1); i = i + size) begin data = reposit[i]; ahb_read(i, size, got); got = align(i, got, size); if (got !== data) begin $display("[%10d] %m A:%x D:%x, but %x expected", $time, i, got, data); error = error + 1; end end if (error == 0) $display("[%10d] %m OK: from %x to %x", $time, start, finish); end endtask //----------------------------------------------------------------------- // Burst transfer test //----------------------------------------------------------------------- task memory_test_burst; input [31:0] start; // start address input [31:0] finish; // end address input [7:0] leng; // burst length integer i; integer j; integer k; integer r; integer error; reg [31:0] data; reg [31:0] gen; reg [31:0] got; reg [31:0] reposit[0:1023]; integer seed; begin $display("[%10d] %m: read-all-after-write-all burst test with %d-beat access", $time, leng); error = 0; seed = 111; gen = $random(seed); k = 0; if (finish > (start+leng*4)) begin for (i = start; i < (finish-(leng*4)+1); i = i + leng*4) begin for (j = 0; j < leng; j = j + 1) begin data_burst[j] = $random; reposit[j+k*leng] = data_burst[j]; end @(posedge HCLK); ahb_write_burst(i, leng); k = k + 1; end gen = $random(seed); k = 0; for (i = start; i < (finish-(leng*4)+1); i = i + leng*4) begin @(posedge HCLK); ahb_read_burst(i, leng); for (j = 0; j < leng; j = j + 1) begin if (data_burst[j] != reposit[j+k*leng]) begin error = error+1; $display("[%10d] %m A=%hh D=%hh, but %hh expected", $time, i+j*leng, data_burst[j], reposit[j+k*leng]); end end k = k + 1; r = $random & 8'h0F; repeat(r) @(posedge HCLK); end if (error == 0) $display("%m %d-length burst read-after-write OK: from %hh to %hh",leng, start, finish); end else begin $display("%m %d-length burst read-after-write from %hh to %hh ???",leng, start, finish); end end endtask //----------------------------------------------------------------------- // As AMBA AHB bus uses non-justified data bus scheme, data should be // aligned according to the address. //----------------------------------------------------------------------- function [31:0] align; input [ 1:0] addr; input [31:0] data; input [ 2:0] size; // num of bytes begin `ifdef BIG_ENDIAN case (size) 1 : case (addr[1:0]) 0 : align = data & 32'hFF00_0000; 1 : align = data & 32'h00FF_0000; 2 : align = data & 32'h0000_FF00; 3 : align = data & 32'h0000_00FF; endcase 2 : case (addr[1]) 0 : align = data & 32'hFFFF_0000; 1 : align = data & 32'h0000_FFFF; endcase 4 : align = data&32'hFFFF_FFFF; default : $display($time,,"%m ERROR %d-byte not supported for size", size); endcase `else case (size) 1 : case (addr[1:0]) 0 : align = data & 32'h0000_00FF; 1 : align = data & 32'h0000_FF00; 2 : align = data & 32'h00FF_0000; 3 : align = data & 32'hFF00_0000; endcase 2 : case (addr[1]) 0 : align = data & 32'h0000_FFFF; 1 : align = data & 32'hFFFF_0000; endcase 4 : align = data&32'hFFFF_FFFF; default : $display($time,,"%m ERROR %d-byte not supported for size", size); endcase `endif end endfunction `include "ahb_transaction_tasks.v" endmoduleahb_transaction_tasks.v文件如下: `ifndef __AHB_TRANSACTION_TASKS_V__ `define __AHB_TRANSACTION_TASKS_V__ //----------------------------------------------------------------------- // AHB Read Task //----------------------------------------------------------------------- task ahb_read; input [31:0] address; input [2:0] size; output [31:0] data; begin @(posedge HCLK); HADDR <= #1 address; HPROT <= #1 4'b0001; // DATA HTRANS <= #1 2'b10; // NONSEQ; HBURST <= #1 3'b000; // SINGLE; HWRITE <= #1 1'b0; // READ; case (size) 1 : HSIZE <= #1 3'b000; // BYTE; 2 : HSIZE <= #1 3'b001; // HWORD; 4 : HSIZE <= #1 3'b010; // WORD; default : $display($time,, "ERROR: unsupported transfer size: %d-byte", size); endcase @(posedge HCLK); while (HREADY !== 1'b1) @(posedge HCLK); HTRANS <= #1 2'b0; // IDLE @(posedge HCLK); while (HREADY === 0) @(posedge HCLK); data = HRDATA; // must be blocking if (HRESP != 2'b00) $display($time,, "ERROR: non OK response for read"); @(posedge HCLK); end endtask //----------------------------------------------------------------------- // AHB Write Task //----------------------------------------------------------------------- task ahb_write; input [31:0] address; input [2:0] size; input [31:0] data; begin @(posedge HCLK); HADDR <= #1 address; HPROT <= #1 4'b0001; // DATA HTRANS <= #1 2'b10; // NONSEQ HBURST <= #1 3'b000; // SINGLE HWRITE <= #1 1'b1; // WRITE case (size) 1 : HSIZE <= #1 3'b000; // BYTE 2 : HSIZE <= #1 3'b001; // HWORD 4 : HSIZE <= #1 3'b010; // WORD default : $display($time,, "ERROR: unsupported transfer size: %d-byte", size); endcase @(posedge HCLK); while (HREADY !== 1) @(posedge HCLK); HWDATA <= #1 data; HTRANS <= #1 2'b0; // IDLE @(posedge HCLK); while (HREADY === 0) @(posedge HCLK); if (HRESP != 2'b00) $display($time,, "ERROR: non OK response write"); @(posedge HCLK); end endtask //----------------------------------------------------------------------- // AHB Read Burst Task //----------------------------------------------------------------------- task ahb_read_burst; input [31:0] addr; input [31:0] leng; integer i; integer ln; integer k; begin k = 0; @(posedge HCLK); HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR ln = leng; end HWRITE <= #1 1'b0; // READ HSIZE <= #1 3'b010; // WORD @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); while (leng > 0) begin for (i = 0; i < ln-1; i = i + 1) begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b11; // SEQ; @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); data_burst[k%1024] <= HRDATA; k = k + 1; end leng = leng - ln; if (leng == 0) begin HADDR <= #1 0; HTRANS <= #1 0; HBURST <= #1 0; HWRITE <= #1 0; HSIZE <= #1 0; end else begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR1 ln = leng; end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); data_burst[k%1024] = HRDATA; // must be blocking k = k + 1; end end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); data_burst[k%1024] = HRDATA; // must be blocking end endtask //----------------------------------------------------------------------- // AHB Write Burst Task // It takes suitable burst first and then incremental. //----------------------------------------------------------------------- task ahb_write_burst; input [31:0] addr; input [31:0] leng; integer i; integer j; integer ln; begin j = 0; ln = 0; @(posedge HCLK); while (leng > 0) begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR ln = leng; end HWRITE <= #1 1'b1; // WRITE HSIZE <= #1 3'b010; // WORD for (i = 0; i < ln-1; i = i + 1) begin @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); HWDATA <= #1 data_burst[(j+i)%1024]; HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b11; // SEQ; while (HREADY == 1'b0) @(posedge HCLK); end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); HWDATA <= #1 data_burst[(j+i)%1024]; if (ln == leng) begin HADDR <= #1 0; HTRANS <= #1 0; HBURST <= #1 0; HWRITE <= #1 0; HSIZE <= #1 0; end leng = leng - ln; j = j + ln; end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); if (HRESP != 2'b00) begin // OKAY $display($time,, "ERROR: non OK response write"); end `ifdef DEBUG $display($time,, "INFO: write(%x, %d, %x)", addr, size, data); `endif HWDATA <= #1 0; @(posedge HCLK); end endtask `endif还需要一个APB的从机模块: `timescale 1ns / 1ps `define AMBA_APB3 `define AMBA_APB4 module apb_mem #( parameter P_SLV_ID = 0, parameter ADDRWIDTH = 32, parameter P_SIZE_IN_BYTES = 1024, // memory depth parameter P_DELAY = 0 // reponse delay ) ( //---------------------------------- // IO Declarations //---------------------------------- `ifdef AMBA_APB3 output wire PREADY, output wire PSLVERR, `endif `ifdef AMBA_APB4 input wire [2:0] PPROT, input wire [3:0] PSTRB, `endif input wire PRESETn, input wire PCLK, input wire PSEL, input wire PENABLE, input wire [ADDRWIDTH-1:0] PADDR, input wire PWRITE, output reg [31:0] PRDATA = 32'h0, input wire [31:0] PWDATA ); //---------------------------------- // Local Parameter Declarations //---------------------------------- localparam DEPTH = (P_SIZE_IN_BYTES+3)/4; localparam AW = logb2(P_SIZE_IN_BYTES); //---------------------------------- // Variable Declarations //---------------------------------- `ifndef AMBA_APB3 wire PREADY; `else assign PSLVERR = 1'b0; `endif `ifndef AMBA_APB4 wire [3:0] PSTRB = 4'hF; `endif reg [7:0] mem0[0:DEPTH-1]; reg [7:0] mem1[0:DEPTH-1]; reg [7:0] mem2[0:DEPTH-1]; reg [7:0] mem3[0:DEPTH-1]; wire [AW-3:0] TA = PADDR[AW-1:2]; //---------------------------------- // Start of Main Code //---------------------------------- //-------------------------------------------------------------------------- // write transfer // ____ ____ ____ // PCLK ___| |____| |____| |_ // ____ ___________________ _____ // PADDR ____X__A________________X_____ // ____ ___________________ _____ // PWDATA ____X__DW_______________X_____ // ___________________ // PWRITE ____| |_____ // ___________________ // PSEL ____| |_____ // _________ // PENABLE ______________| |_____ //-------------------------------------------------------------------------- always @(posedge PCLK) begin if (PRESETn & PSEL & PENABLE & PWRITE & PREADY) begin if (PSTRB[0]) mem0[TA] <= PWDATA[ 7: 0]; if (PSTRB[1]) mem1[TA] <= PWDATA[15: 8]; if (PSTRB[2]) mem2[TA] <= PWDATA[23:16]; if (PSTRB[3]) mem3[TA] <= PWDATA[31:24]; end end //-------------------------------------------------------------------------- // read // ____ ____ ____ // PCLK ___| |____| |____| |_ // ____ ___________________ _____ // PADDR ____X__A________________X_____ // ____ _________ _____ // PRDATA ____XXXXXXXXXXX__DR_____X_____ // ____ _____ // PWRITE ____|___________________|_____ // ___________________ // PSEL ____| |_____ // _________ // PENABLE ______________| |_____ //-------------------------------------------------------------------------- always @(posedge PCLK) begin if (PRESETn & PSEL & ~PENABLE & ~PWRITE) begin PRDATA[ 7: 0] <= mem0[TA]; PRDATA[15: 8] <= mem1[TA]; PRDATA[23:16] <= mem2[TA]; PRDATA[31:24] <= mem3[TA]; end end `ifdef AMBA_APB3 localparam ST_IDLE = 'h0, ST_CNT = 'h1, ST_WAIT = 'h2; reg [7:0] count; reg ready; reg [1:0] state=ST_IDLE; assign PREADY = (P_DELAY == 0) ? 1'b1 : ready; always @(posedge PCLK or negedge PRESETn) begin if (PRESETn == 1'b0) begin count <= 'h0; ready <= 'b1; state <= ST_IDLE; end else begin case (state) ST_IDLE : begin if (PSEL && (P_DELAY > 0)) begin ready <= 1'b0; count <= 'h1; state <= ST_CNT; end else begin ready <= 1'b1; end end // ST_IDLE ST_CNT : begin count <= count + 1; if (count >= P_DELAY) begin count <= 'h0; ready <= 1'b1; state <= ST_WAIT; end end // ST_CNT ST_WAIT : begin ready <= 1'b1; state <= ST_IDLE; end // ST_WAIT default : begin ready <= 1'b1; state <= ST_IDLE; end endcase end // if end // always `else assign PREADY = 1'b1; `endif // Calculate log-base2 function integer logb2; input [31:0] value; reg [31:0] tmp; begin tmp = value - 1; for (logb2 = 0; tmp > 0; logb2 = logb2 + 1) tmp = tmp >> 1; end endfunction // synopsys translate_off `ifdef RIGOR always @(posedge PCLK or negedge PRESETn) begin if (PRESETn == 1'b0) begin end else begin if (PSEL & PENABLE) begin if (TA >= DEPTH) $display($time,,"%m: ERROR: out-of-bound 0x%x", PADDR); end end end `endif // synopsys translate_on endmodule6、仿真 用VCS进行仿真,打印信息如下 图片 可见仿真完全正确,这里也只是做了AHB总线的单一传输和各种长度的增量突发,回环突发未涉及(对APB桥来说,它并不关心HBURST的信号值)。 下面挂两张仿真截图: 单一传输,先写后读: 图片 突发传输,先写完,再读完 图片
IP&SOC设计
# SOC设计
刘航宇
3年前
1
1,552
1
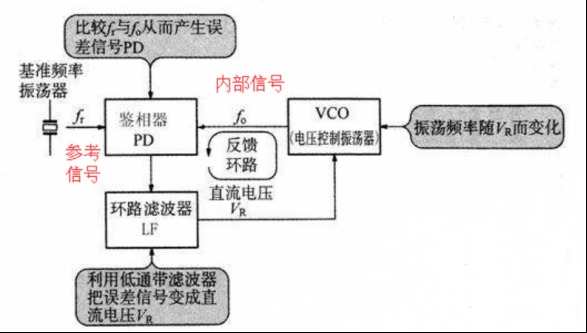
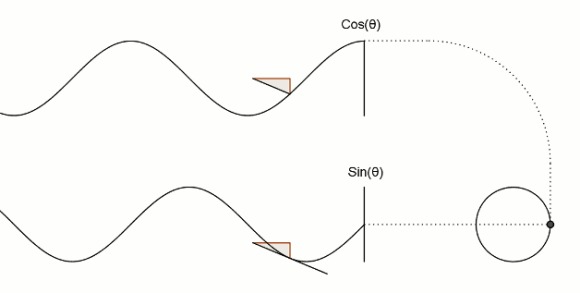
数字锁相环(DPLL)研究与设计-面向FPGA/数字IC
前言 锁相环的原理和组成 数字锁相环的原理和组成 数字鉴相器设计DPD 数字振荡器(DCO) 数字缓冲器(DB) 数字锁相环(DPLL)的实现 电路硬件与性能评估 工程代码下载 前言 随着数字电路技术的发展,数字锁相环在调制解调、频率合成、FM 立体声解码、彩色副载波同步、图象处理等各个方面得到了广泛的应用。数字锁相环不仅吸收了数字电路可靠性高、体积小、价格低等优点,还解决了模拟锁相环的直流零点漂移、器件饱和及易受电源和环境温度变化等缺点,此外还具有对离散样值的实时处理能力,已成为锁相技术发展的方向。 所谓数字PLL,就是指应用于数字系统的PLL,也就是说数字PLL中的各个模块都是以数字器件来实现的,是一个数字的电路。 数字锁相环的优点是电路最简单有效,可采用没有压控的晶振,降低了成本,提高了晶振的稳定性。但缺点是和模拟锁相环一样,一旦失去基准频率,输出频率立刻跳回振荡器本身的频率;另外还有一个缺点,就是当进行频率调整的时候,输出频率会产生抖动,频差越大,抖动会越大于密,不利于某些场合的应用。随着大规模、超高速的数字集成电路的发展,为数字锁相环路的研究与应用提供了广阔空间。由于晶体振荡器和数字调整技术的加盟,可以在不降低振荡器的频率稳定度的情况下,加大频率的跟踪范围,从而提高整个环路工作的稳定性与可靠性。 简单的说有两个不同来源的信号:一个信号是参考信号,这个信号一般是由芯片的晶振得到的信号,它具有信号的稳定性较好等优点,但是其频率是固定不变的。另一个信号是由芯片或者模块内部的压控振荡器得到的。这种由压控振荡器得到的信号可以是某范围内的任意频率的信号,但是这种信号的稳定型较差,容易受到外界干扰。 那么在实际使用过程中,我们需要一种频率能够变化的,同时质量较好的信号;或者对于一块芯片,我们需要不同的模块的内部时钟(这种时钟可以是压控振荡器产生)都能参考一个总的时钟来进行同步,从而避免两个模块内部时钟的差异而产生的数据传输的漂移等问题。因此,如何将压控振荡器得到的信号能够具有晶振信号的信号质量呢? 那就是通过PLL锁相环来实现,如图1所示。只要压控振荡器产生的时钟(下称输入信号)是参考信号的整数倍(或者整除倍),那么就能将输入信号先进行分频,后得到与参考信号频率相同的时钟,将分频后的信号和参考信号进行比较,从而使分频后的信号和参考信号保持相同的稳定的频率和相位。被分频后的信号稳定,也就是间接的表示输入信号的稳定。从而我们得到了一个频率在一定范围内可变的稳定的信号。 有上述可以看出,锁相环具有以下功能: (1)能够将一个信号和另一参考信号同步; (2)当这个信号是输出信号分频后得到的信号,PLL就能够得到参考信号的倍频信号(实际上倍频器很多都是利用了这个功能); (3)当输入信号频率可变、分频系数可变时,PLL就能够得到在频率一定范围内稳定信号。 图片 锁相环的原理和组成 锁相环(PLL)的作用我们已经大概了解了,其最主要功能的实现,是在于如何将两个频率不同、相位差始终在变化的信号,变成两个相同频率、相同相位的信号。 这里引入一个概念,首先我们都知道,对于三角函数,只有两个同频率的三角函数才能比较其相位差。但这里的相位差是指两个正弦函数的初始相位差。而实际上根据三角函数的欧拉定义的理解来看,我们可以把三角函数看做是在某个圆上逆时针运动的点到x轴的距离。那么频率就是点在圆上运动的角速度,频率越大,其运动的角速度越大。相位就是点在圆上的位置,而初始相位就是点在圆上开始运动时的位置。当两个点的运动角速度相同时,我们可以得到两个点的初始位置差,就是两个正弦函数频率相同时,得到初始相位差。这个差值在运动过程中一直是不变的。但是当两个点运动角速度不同时,我们去看它的初始位置差是没有意义的,因为两个点的位置差是一直在变的,而初始位置差只是一个开始的位置差,是个不变的量,所以说对于频率不同的三角函数,我们讨论起初始相位差是没有意义的。但是不代表不能比较某一时刻两个点的位置。也就是相位差,相位是存在的。 图片 现在我们假设两个点在圆上赛跑,如图3所示,我们想让这两个点角速度相等。那么有一个办法就是以一个点为参考,参考点角速度不变,另一个点是速度可变点。每过一段时间,观察另一个点到参考点的位置,是在前,还是在后。如果在前,就让另一个点速度慢一点;如果在后,就让另一个点速度快一点。就这样不断调整另一个点的角速度,直到每次观察两个点都处于相同的位置。这样我们就可以认为这两个点达到了相同的速度。这种方法就是利用反馈调节来实现两个信号的同频同相。也就是锁相环(PLL)的实现原理。 首先通过一个鉴相器来得到两个信号之间的相位差。并根据相位差输出电压信号。然后通过滤波器稳压后得到稳定的电压信号,该信号驱动压控振荡器得到新的频率的信号。当两个信号存在相位差时,电压信号就会改变,从而使受控信号不断变化。直到当两个信号没有相位差时,电压信号不再改变,从而使受控信号保持当前频率,这时,受控信号不再变化了,就叫做受控信号被锁定了。 由上所述,一个锁相环由鉴相器、滤波器、振荡器三部分组成。外部输入是参考信号,内部输入和总的输出是受控信号。 数字锁相环的原理和组成 在数字电路中,原来模拟信号正弦波、余弦波的频率和相位变成了0和1的脉冲信号,那么我们如何理解数字信号中的频率和相位呢?对于脉冲信号来说,我们可以把频率理解为在某固定时间内脉冲出现的个数,为了方便表示,我们把上升沿的出现视为脉冲的出现,把相邻两个脉冲出现的时间t求倒数,就得到了该信号在这个时刻处的信号频率。而对于相位,相位差就是指,存在两个脉冲信号,以一个脉冲信号为参考,在其出现脉冲后,到另一个信号出现脉冲之间的时间差就是相位差,当另一个信号脉冲晚于参考信号脉冲出现的时间,称之为另一个信号的相位滞后于参考信号。当另一个信号的脉冲出现在参考信号之前,称之为另一个信号的相位提前于参考信号。 上述是一种较为简单的描述方式,适合初识脉冲信号的读者理解。而实际上,对于脉冲信号的频率、相位等问题,严格来说这样理解有一点点问题,但是对于我们来搭建数字锁相环DPLL来说足够了。其实这种三角函数和信号之间的转化,其根本的原理来源于傅里叶变换,从而我们对一个时间域上的信号(例如脉冲信号)可以进行频率域(其代表的三角函数的合成)上的分析。 我们知道了在数字电路中,脉冲信号也有了频率和相位的属性。那么我们的参考信号是以来时钟源的固定频率的信号,因为信号的质量比较好,所以该信号两个脉冲之间的时间差均是相同的,误差很小。我们在参考信号出现上升沿时,观察受控信号此时的状态。如果受控信号为高电平,我们就认为此时受控信号超前于参考信号;反之,如果受控信号是低电平,则认为此时的受控信号滞后于参考信号。当出现超前状态时,鉴相器会输出一个超前信号,超前信号会作用于振荡器,使得振荡器发出的受控信号频率降低。而滞后信号会使振荡器发出的受控信号频率升高,从而实现受控信号频率的反馈调节。 如图4所示,当参考信号出现上升沿时,受控信号为低电平,此时输出一个滞后信号。(由于模块只在时钟为上升沿时触发,所以超前信号的触发延迟了半个时钟周期) 图片 由此我们能够大概了解了数字锁相环中如何看待脉冲信号的频率和相位,如何处理得到相位差以及相位差如何在锁相环中起作用来实现信号频率的反馈控制。同模拟的锁相环(PLL)类似,数字锁相环(DPLL)也是由:数字鉴相器(Digital Phase Detector)、数字缓冲器(Digital Buffer)、数字振荡器(Digital Controlled Oscillator)三个模块构成,其外部输入为参考信号,内部输入和输出为受控信号。下面我们就来具体讨论如何用verilog实现各个模块。 数字鉴相器设计DPD 实现一个数字锁相环(DPLL),最重要的部分就是实现数字鉴相器(DPD)和数字振荡器(DF)。并且,这两个模块并不是独立存在的,而是说,数字振荡器的实现方式和数字振荡器的实现方式相互影响。所以只有两个模块共同设计,才能较好的实现一个数字锁相环的功能。 首先我们来具体讨论一下一个数字鉴相器应该具有那些功能和特性: 顾名思义,数字鉴相器就是能够鉴别两个数字信号相位的差别,并通过信号将这种差别表示出来。由上文我们已经知道了,对于两个矩形方波信号,其相位差可以看做是两个信号先后出现上升沿(或下降沿)之间的时间差。为了方便表示,假设以其中一个信号作为参考信号,另一个信号为受控信号,当参考信号出现上升沿(或下降沿)时,观察另一个信号是否已经出现了上升沿(或下降沿)。 如果还未出现上升沿(或下降沿),则叫做“受控信号滞后于参考信号”,或者简称“滞后”;如果已经出现了上升沿(或下降沿),则叫做“受控信号提前于参考信号”,或者简称“提前”。 而判断上升沿(或下降沿)是否已经出现,方法就是看当参考信号出现上升沿时,受控信号是1还是0:当受控信号为0,表示上升沿还没出现,所以是“滞后”;当受控信号为1,表示上升沿已经出现,所以是“提前”。对于下降沿也是按照同样的方法考虑。 !https://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpghttps://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpghttps://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpg 目前为止,我们已经有两个输入,参考信号和受控信号;两个输出,滞后信号和提前信号。如何通过verilog实现上述的输入输出关系呢?首先先讲异或与门,通过图4的描述,我们可以很容易看出来:滞后信号是参考信号与受控信号先异或,异或的结果和受控信号相与得到;提前信号是参考信号与受控信号先异或,异或的结果和参考信号相与得到。再加上一个RST的复位信号,我们可以得到如下图5电路: !https://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpghttps://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpghttps://pic.imgdb.cn/item/6496faef1ddac507ccf67242.jpg 根据这个关系,来调节受控信号的频率,从而使受控信号的频率和参考信号最终相同。 再考虑,如果按照上述方法调节,当受控信号和参考信号频率相差很大时,就会出现刚开始有一段时间,受控信号的频率是不断变化,不可预知的。这样的调节效果实时性并不好,需要时间来稳定。因此读者想到,如果能够在参考信号出现上升沿时,就让受控信号也出现上升沿,相当于两个人在赛跑时,当一个人从起点出发时,无论另一个人在哪,强制让另一个人也回到原点,两个人一起从原点出发。这样就能使受控信号和参考信号强制达到相同的频率,只是此时受控信号的占空比不是50%。然后再根据滞后和提前信号,调节受控信号的占空比,从而最终达到50%的占空比。 按照这种方法,鉴相器就需要一个信号输出来表示上升沿的出现。再考虑到电路中的总的时钟源,我们这里采用触发的方法来实现。同时将上述的异或与门加入到代码中可以得到数字鉴相器的代码。但是在实际运用过程中发现,可能存在着受控信号先出现上升沿,从而过早的出现了提前或者滞后信号,导致数字振荡器的计数器上限呈现一个周期变化的不可控的数值的情况。为了避免这种情况,需要仔细考虑参考信号和受控信号如何生成提前和滞后信号这个问题,而不是简单的用异或来实现。如图6表示这种关系。 图片 按照上述代码写出来的数字鉴相器,具有更好的性能。根据这个表格,通过类似状态机的方法,来实现提前信号和滞后信号的输出。 此外异或门配合D触发器方式也可以实现鉴相器效果仍可应用于本设计中。示例代码如下: module DPD_2 ( input reference_signal, // 参考时钟输入(来自外部晶振或基准源) input controlled_signal, // 反馈时钟输入(来自VCO分频后的时钟) input rst, // 异步复位信号,高电平有效 input clk, output reg lead_signal_wire, // 相位超前指示信号(输出到电荷泵) output reg lag_signal_wire, // 相位滞后指示信号(输出到电荷泵) output bothEdge ); // 延迟寄存器:用于检测两个时钟的到达顺序 reg ref_flag, fb_flag; reg ref_nflag, fb_nflag; reg lead_signal,lead_signal_n; reg lag_signal,lag_signal_n; reg reference_signal_d1,reference_signal_d2; reg controlled_signal_d1,controlled_signal_d2; wire bothEdge_fb; reg fb_flag_d1,fb_flag_d2,fb_nflag_d1,fb_nflag_d2; reg ref_flag_d1,ref_flag_d2,ref_nflag_d1,ref_nflag_d2; always @(posedge clk or negedge rst) begin if(!rst) begin reference_signal_d1 <= 'd0; controlled_signal_d1 <= 'd0; fb_flag_d1 <= 'd0; fb_flag_d2 <= 'd0; fb_nflag_d1 <= 'd0; fb_nflag_d2 <= 'd0; ref_flag_d1 <= 'd0; ref_flag_d2 <= 'd0; ref_nflag_d1 <= 'd0; ref_nflag_d2 <= 'd0; end else begin reference_signal_d1 <= reference_signal; reference_signal_d2 <= reference_signal_d1; controlled_signal_d1 <= controlled_signal; controlled_signal_d2 <= controlled_signal_d1; fb_flag_d1 <= fb_flag; fb_flag_d2 <= fb_flag_d1; fb_nflag_d1 <= fb_nflag; fb_nflag_d2 <= fb_nflag_d1; ref_flag_d1 <= fb_flag; ref_flag_d2 <= ref_flag_d1; ref_nflag_d1 <= ref_nflag; ref_nflag_d2 <= ref_nflag_d1; end end assign bothEdge = reference_signal & (~reference_signal_d1); wire bothEdge_n; assign bothEdge_n = (~reference_signal) & reference_signal_d1; // assign bothEdge_fb = controlled_signal & (~controlled_signal_d1); wire bothEdge_fb_n; //控制下降沿 assign bothEdge_fb_n = (~controlled_signal) & controlled_signal_d1; // // 参考时钟延迟寄存器:在reference_signal上升沿采样 // 功能:标记参考时钟是否到来 always @(posedge reference_signal or negedge rst) begin if (!rst) begin ref_flag <= 1'b0; // 复位时清零 ref_nflag <= 1'b0; end else begin ref_flag <= 1'b1; // 参考时钟到来后置1 ref_nflag <= 1'b0; end end // 反馈时钟延迟寄存器:在controlled_signal上升沿采样 // 功能:标记反馈时钟是否到来 always @(posedge controlled_signal or negedge rst) begin if (!rst) begin fb_flag <= 1'b0; // 复位时清零 fb_nflag <= 1'b0; end else begin fb_flag <= 1'b1; // 反馈时钟到来后置1 fb_nflag <= 1'b0; end end // 主逻辑:检测相位关系 - 谁先来谁占优 // 在参考时钟上升沿判断:如果反馈时钟还没来,说明参考超前 always @(posedge reference_signal_d2) begin if (!fb_flag_d2) lag_signal <= 1'b1; // fb_dly为0表示controlled_signal尚未到达,reference_signal超前 else lag_signal <= 1'b0; // fb_dly为1表示controlled_signal已到,两者已对齐或参考滞后 end // 在反馈时钟上升沿判断:如果参考时钟还没来,说明反馈超前(即参考滞后) always @(posedge controlled_signal_d2) begin if (!ref_flag_d2) lead_signal <= 1'b1; // ref_dly为0表示reference_signal尚未到达,controlled_signal超前 else lead_signal <= 1'b0; // ref_dly为1表示reference_signal已到,两者已对齐或反馈滞后 end //下降沿 always @(negedge reference_signal or negedge rst) begin if (!rst) begin ref_nflag <= 1'b0; // 复位时清零 ref_flag <= 1'b0; end else begin ref_nflag <= 1'b1; // 参考时钟到来后置1 ref_flag <= 1'b0; end end always @(negedge controlled_signal or negedge rst) begin if (!rst) begin fb_nflag <= 1'b0; // 复位时清零 fb_flag <= 1'b0; end else begin fb_nflag <= 1'b1; // 反馈时钟到来后置1 fb_flag <= 1'b0; end end always @(negedge reference_signal_d2) begin if (!fb_nflag_d2) lag_signal_n <= 1'b1; // fb_dly为0表示controlled_signal尚未到达,reference_signal超前 else lag_signal_n <= 1'b0; // fb_dly为1表示controlled_signal已到,两者已对齐或参考滞后 end // 在反馈时钟上升沿判断:如果参考时钟还没来,说明反馈超前(即参考滞后) always @(negedge controlled_signal_d2) begin if (!ref_nflag_d2) lead_signal_n <= 1'b1; // ref_dly为0表示reference_signal尚未到达,controlled_signal超前 else lead_signal_n <= 1'b0; // ref_dly为1表示reference_signal已到,两者已对齐或反馈滞后 end // 消毛刺逻辑:在任一时钟下降沿清零lead_signal_wire/lag_signal_wire信号 // 防止多脉冲叠加,确保每个周期只产生一个有效脉冲 /* always @(negedge reference_signal or negedge controlled_signal) begin {lead_signal_wire, lag_signal_wire} <= 2'b00; // 在时钟下降沿同时复位两个输出 end */ always @(posedge clk or negedge rst) begin if (!rst) begin lead_signal_wire <= 'b0; lag_signal_wire <= 'b0; end //else if(bothEdge & bothEdge_fb) begin else if((bothEdge & bothEdge_fb) | (bothEdge_n & bothEdge_fb_n)) begin lead_signal_wire <= 'b0; lag_signal_wire <= 'b0; end else begin lead_signal_wire <= lead_signal | lead_signal_n; lag_signal_wire <= lag_signal | lag_signal_n; end end endmodule数字振荡器(DCO) 现在我们已经构造出来了一个数字鉴相器,接下来我们将继续探讨如何实现一个数字振荡器(DCO)。 实现一个固定脉冲频率的信号,我们可以通过已知的时钟源,分频得到一定频率范围内的脉冲。具体实现方法就是通过计数器的方式,当出现时钟脉冲时,计数器+1,计数器上限就是分频系数,当计数器的数小于上限的1/2时,输出1,当计数器的数大于上限的1/2时,输出0,当计数器的数超过上限时,计数器归零。这样就能实现对时钟源的分频。 根据上述方法,只要改变计数器的上下限,就能改变分频系数,从而改变输出信号的频率。再参考上文受控信号和滞后提前信号的关系,我们就能通过根据滞后提前信号,改变计数器上下限,来实现对受控信号频率的控制。当计数器上限增加时,分频系数增加,频率减小;当计数器上限减小时,分频系数减小,频率增加;因此有: 滞后信号——>受控信号的频率小——>增加受控信号的频率——>计数器上限减小 提前信号——>受控信号的频率大——>减小受控信号的频率——>计数器上限增加 此外根据上述对上升沿触发同步的说法,当出现上升沿触发信号时,受控信号应强制产生上升沿,即受控信号强制从该脉冲周期的开始处开始,即计数器的数回到0从新开始计数。 综上所述,再加上复位信号,一个数字振荡器的所有构成就有了。到这里,一个数字锁相环(DPLL)其实就已经能够实现了,因为数字滤波器(DB)只是让受控信号的抗干扰能力更强,如图所示是仿真后的结果: 图片 数字缓冲器(DB) 下面再介绍一下数字缓冲器,来使受控信号的抗干扰能力更强。前面我们知道了,持续一个时钟周期的提前信号或者滞后信号能够使数字振荡器的计数器上限加一或者减一。当我的预设的数字振荡器的计数器上限与实际的参考信号的频率对应的计数器上限两个数值相差很大时,就有可能出现锁相环调节时间过长等现象。为了解决这种情况,如果能够让原来持续一个周期的提前信号或滞后信号成倍数的增加,变成持续n个周期的提前信号或者滞后信号,就能够使数字振荡器的计数器上限修改更快,从而更快的到达参考频率附近。但是相应的,受控信号的频率精度就会降低。也就是说,牺牲精度,追求速度。 同时考虑另外一种情况,如果我对速度要求不高,但是对于精度要求较高,同时在信号传输过程中可能存在干扰,导致接收到的提前信号或滞后信号不是完全真实的信号,此时就可以通过一个累加器,只有接受到n个周期的提前信号,或者滞后信号,才对数字振荡器输出一个进位信号或者借位信号,此时数字振荡器的计数器上限才只加减1,这样就能有效的提高精度,减少信号干扰带来的影响。但是这种做法牺牲了数字锁相换锁定的时间。 综上所述,一个时钟周期的提前或滞后信号,对应n个时钟周期的借位或进位信号,是提高锁定速度,降低锁定精度。想法,n个时钟周期的提前或滞后信号,对应一个时钟周期的借位或进位信号,是提高锁定精度,降低锁定速度。因此在实际运用中,应该按照自己的工程需要,合理选择比值。 上述过程的实现方法,是通过一个计数器,当接收到一个提前或滞后信号时,计数器加a,当输出一个进位或借位信号时,计数器减b,调节a和b的比值,就能实现上述过程。 数字缓冲器的仿真效果: 1、分时效果 图片 2、倍时效果 图片 数字锁相环(DPLL)的实现 所有的子模块都已经实现了,剩下的数字锁相环的实现,根据实际的要求,将上述几个模块进行例化就行。例化后的测试结果如图9所示,可以看到受控信号逐渐与参考信号对齐达到锁相环效果。 图片 为了方便起见,对输出信号进行2分频,再次观察输出结果,输出相当于2倍频了,成功完成PD、DCO、Divider等模块正确设计。 图片 电路硬件与性能评估 图11为电路硬件图从图中可以看出各模块的连接关系,每个模块由基本门电路构成。通过性能优化后的的电路如图12所示。 图片 利用SMIC180nm工艺进行电路综合, 时序报告:周期2ns 图片 面积报告:2119um2 图片 功耗报告:uw级别 图片 工程代码下载
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
1
3,951
4
2023-06-20
Microsemi Libero SOC常见问题-FPGA全局网络的设置
问题描述 最近在一个FPGA工程中分配rst_n引脚时,发现rst_n引脚类型为CLKBUF,而不是常用的INBUF,在分配完引脚commit检查报错,提示需要连接到全局网络引脚上。 Running Global Checker... Error:PLC002:No legal assignment exists for global net rst.n_c. Info:Uhlocking the driver or removing the region constraint for net rst nc may help to satisfy Error:PLC005:Automat ic global net placement failed. 尝试忽略这个错误,直接进行编译,在布局布线时又报错。 Error: PLC002: No legal assignment exists for global net rst_n_c. Error: PLC005: Automatic global net placement failed. Error: Failure when executing Tcl script. [ Line 18 ] 尝试取消引脚锁定LOCK,再次commit检查成功,编译下载正常,但是功能不对,再次打开引脚分配界面,发现是rst_n对应的引脚并不是我设置的那个,看来是CLKBUF的原因。 问题分析 网络上搜索一些资料后,发现是在一些工程中会出现这个问题,如果rst_n信号连接了许多IP核,和很多自己写的模块,这样rst_n就需要很强的驱动能力,即扇出能力(Fan Out),而且布线会很长,所以在分配管脚时,IDE自动添加了CLKBUF,来提供更大的驱动能力和更小的延时。那么什么是FPGA的全局时钟网络资源呢? FPGA全局布线资源简介 我们知道FPGA的资源主要由以下几部分组成: 可编程输入输出单元(IOB) 基本可编程逻辑单元(CLB) 数字时钟管理模块(DCM) 嵌入块式RAM(BRAM) 丰富的布线资源 内嵌专用硬件 模块。 我们重点介绍布线资源,FPGA中布线的长度和工艺决定着信号在的驱动能力和传输速度。FPGA的布线资源可大概分为4类: 全局布线资源:芯片内部全局时钟和全局复位/置位的布线 长线资源:完成芯片Bank间的高速信号和第二全局时钟信号的布线 短线资源:完成基本逻辑单元之间的逻辑互连和布线 分布式布线资源:用于专有时钟、复位等控制信号线。 一般设计中,我们不需要直接参与布线资源的分配,IDE中的布局布线器(Place and Route)可以根据输入逻辑网表的拓扑结构,和用户设定的约束条件来自动的选择布线资源。 其中全局布线资源具有最强的驱动能力和最小的延时,但是只能限制在全局管脚上,厂商会特殊设计这部分资源,如Xilinx FPGA中的全局时钟资源一般使用全铜层工艺实现,并设计了专门时钟缓冲和驱动结构,从而使全局时钟到达芯片内部的所有可配置逻辑单元(CLB)、I/O单元(IOB)和选择性块RAM(Block Select ROM)的时延和抖动都为最小。 一般全局布线资源都是针对输入信号来说的,如果IDE自动把rst_n引脚优化为了全局网络,而硬件电路设计上却把rst_n分配到了普通管脚上,那么就很麻烦了,要么牺牲全局网络的优势,手动将全局网络改为普通网络,要么为了利用全局网络的优势,修改电路,重新分配硬件引脚。所以如果一些关键的信号确定了,如时钟、复位等,产品迭代修改电路时,不要轻易调整这些关键引脚。 Microsemi FPGA的全局布线资源 Microsemi FPGA的全局时钟管脚编号,我们可以通过官方Datasheet来找到,在手册中关于全局IO的命名规则上,有如下介绍: 即只有管脚名称为GFA0/1/2,GFB0/1/2,GFC0/1/2,GCA0/1/2,GCB0/1/2,GCC0/1/2(共18个)才支持全局网络分配,而且,如果使用了GFA0引脚作为全局输入引脚,那么GFA1和GFA2都不能再作为全局网络了,其他GFC等同理,这一点在设计电路时要特别注意。 对于Microsemi SmartFusion系列FPGA芯片A2F200M3F-PQ208来说,只有7个,分别是:GFA0-15、GFA1-14、GFA2-13、GCA0-145、GCA1-146、GCC2-151、GCA2-153,引脚分配如下图所示: 所以在设计A2F200M3F-PQ208硬件电路时,时钟和复位信号尽量分配在这些管脚上,以获得硬件性能的最大效率。 这些全局引脚的延时时间都是非常小的,具体的时间参数可以从数据手册上获得。 全局网络改为普通输入 像文章开头介绍的情况,IDE自动把rst_n设置为全局网络,而实际硬件却不是全局引脚,应该怎么修改为普通输入呢?即CLKBUF改为普通的INBUF?网络上zlg的教程中使用的是版本较低的Libero IDE 8.0,新版的Libero SoC改动非常大,文中介绍的修改sdc文件的方法已经不能使用了,这里提供新的修改方法——调用INBUF IP Core的方式。 这里官方已经考虑到了,在官方提供的INBUF IP Core可以把CLKBUF改为INBUF。 在Catalog搜索框中输入:INBUF,可以看到这里也提供了LVDS信号专用的IP Core。 拖动到SmartDesign中进行连接 或者在源文件中直接例化的方式调用INBUF Core: INBUF INBUF_0( // Inputs .PAD ( rst_n ), // Outputs .Y ( rst_n_Y ) );这两种方法都是一样的。添加完成之后,再进行管脚分配,可以看到rst_n已经是普通的INBUF类型了,可以进行普通管脚的分配,而且commit检查也是没有错误的。 普通输入上全局网络 如果布局布线器没有把我们要的信号上全局网络,如本工程的CLK信号,IDE自动生成的是INBUF类型,我们想让他变成CLKBUF,即全局网络,来获取最大的驱动能力和最小的延时。那么应该怎么办呢? 这里同样要使用到一个IP Core,和INBUF类似,这个IP Core的名称是CLKBUF,同样是在Catalog目录中搜索:CLKBUF,可以看到有CLKBUF开头的很多Core,这里同样也提供了LVDS信号专用的IP Core。 可以直接拖动Core到SmartDesign图形编辑窗口: 或者是在源文件中以直接例化的方式调用: CLKBUF CLKBUF_0( // Inputs .PAD ( CLKA ), // Outputs .Y ( CLKA_Y ) );这两种方式都是一样的,添加完成之后,再进行管脚分配,可以看到CLKA已经是全局网络了,只能分配在全局管脚上。 总结 对于不同厂家的FPGA,让某个信号上全局网络的方法都不尽相同,如Xilinx的FPGA是通过BUFG Core来让信号上全局网络,而且还有带使能端的全局缓冲 BUFGCE , BUFGMUX 的应用更为灵活,有2个输入,可通过选择端选择输出哪一个。所以,信号的全局缓冲设置要根据不同厂商Core的不同来使用。
嵌入式&系统
FPGA&ASIC
IP&SOC设计
# 嵌入式
刘航宇
3年前
0
1,561
3
上一页
1
2
3
4
...
26
下一页