首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,021 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,045 阅读
3
【高数】形心计算公式讲解大全
8,728 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,417 阅读
5
【1】基于STM32CubeMX-STM32GPIO端口开发
6,750 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
VLSI&IC验证(共19篇)
找到
19
篇与
VLSI&IC验证
相关的结果
- 第 2 页
RAM与ROM及Verilog实现
概念 RAM(random access memory)即随机存储内存,这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序。 ROM 指的是“只读存储器”,即Read-Only Memory。只读存储器(Read-Only Memory,ROM)以非破坏性读出方式工作,只能读出无法写入信息。信息一旦写入后就固定下来,即使切断电源,信息也不会丢失,所以又称为固定存储器。ROM所存数据通常是装入整机前写入的,整机工作过程中只能读出,不像随机存储器能快速方便地改写存储内容。ROM所存数据稳定 ,断电后所存数据也不会改变,并且结构较简单,使用方便,因而常用于存储各种固定程序和数据。 PROM 指的是“可编程只读存储器”既Programmable Red-Only Memory。这样的产品只允许写入一次,所以也被称为“一次可编程只读存储器”(One Time Progarmming ROM,OTP-ROM)。最初从工厂中制作完成的PROM内部并没有资料,用户可以用专用的编程器将自己的资料写入,但是这种机会只有一次,一旦写入后也无法修改。 EPROM 指的是“可擦写可编程只读存储器”,即Erasable Programmable Read-Only Memory。它的特点是具有可擦除功能,擦除后即可进行再编程,但是缺点是擦除需要使用紫外线照射一定的时间。 EEPROM 指的是“电可擦除可编程只读存储器”,即Electrically Erasable Programmable Read-Only Memory。它的最大优点是可直接用电信号擦除,也可用电信号写入。EEPROM不能取代RAM的原因是其工艺复杂, 耗费的门电路过多,且重编程时间比较长,同时其有效重编程次数也比较低。 Flash memory 指的是“闪存”,所谓“闪存”,它也是一种非易失性的内存,属于EEPROM的改进产品。它的最大特点是必须按块(Block)擦除(每个区块的大小不定,不同厂家的产品有不同的规格), 而EEPROM则可以一次只擦除一个字节(Byte)。目前“闪存”被广泛用在PC机的主板上,用来保存BIOS程序,便于进行程序的升级。其另外一大应用领域是用来作为硬盘的替代品,具有抗震、速度快、无噪声、耗电低的优点,但是将其用来取代RAM就显得不合适,因为RAM需要能够按字节改写,而Flash ROM做不到。 二、编程 1.要求: 编程实现512x8的ROM和RAM。 ROM、RAM至少应该包含的端口包括地址线、数据线、片选线、读写使能端,复位端和时钟端(其中部分信号线只适用于RAM)。 ROM、RAM和总测试模块分别包含在不同的.v文件中。 端口意义: Data: 双向数据总线,用于读写数据。它的宽度由width参数决定。 Addr: 输入地址总线,用于指定要访问的内存单元。它的宽度也由width参数决定,默认为8位。 CS: 输入芯片选择信号,用于使能或禁止模块的读写操作。当CS为1时,模块可以进行读写操作;当CS为0时,模块不响应任何操作。 RWEnable: 输入读写使能信号,用于指定模块的工作模式。当RWEnable为1时,模块处于写模式,可以将Data总线上的数据写入到Addr指定的内存单元中;当RWEnable为0时,模块处于读模式,可以将Addr指定的内存单元中的数据输出到Data总线上。 2.设计思路: 512x8的ROM和RAM,至少需要9位地址线和8位数据位。 3.RAM实现代码 //模块声明,指定模块名和端口引脚 module RAM (Data,Addr,CS,RWEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RWEnable,Reset,Clk; //输入信号,分别为芯片选择、读写使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 inout[width-1:0] Data; //双向数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_temp; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为0 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= 0; //将每个内存单元赋值为0 end //写操作条件,当RWEnable为1且CS为1时,将Data总线上的数据写入到Addr指定的内存单元中 else if((RWEnable==1'b1)&&(CS==1'b1)) begin Mem[Addr] <= Data; //将Data总线上的数据赋值给Mem[Addr] end //读操作条件,当RWEnable为0且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_temp中 else if((RWEnable==1'b0)&&(CS==1'b1)) begin Data_temp<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_temp end //其他条件,当CS为0或RWEnable为不确定值时,将Data_temp置为高阻抗状态 else begin Data_temp <= 8'bz; //将Data_temp赋值为高阻抗状态 end end //assign语句,指定Data总线与Data_temp之间的连接关系 assign Data=RWEnable?8'bz:Data_temp; //当RWEnable为1时,Data总线处于高阻抗状态;当RWEnable为0时,Data总线接收Data_temp中的数据 endmodule //模块结束测试代码如下: //模块声明,指定模块名为RAM_TS module RAM_TS; //信号和寄存器的定义,指定与RAM模块相连的端口引脚和内部变量 reg CS_t,RWEnable_t,Reset_t,Clk_t; //芯片选择、读写使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 reg [7:0] Data_temp_t; //用于暂存写入数据的寄存器,也是8位的 //initial块,指定测试RAM模块的过程,只会在仿真开始时执行一次 initial begin RWEnable_t = 1;//w //初始化读写使能信号为1,表示写模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 Data_temp_t = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 Data_temp_t=Addr_t; //将地址总线上的值赋给暂存数据,表示要写入的数据与地址相同 end #70 //延迟70个时间单位后 RWEnable_t = 0;//r //将读写使能信号置为0,表示读模式 Addr_t=0; //将地址总线置为0,表示从第一个内存单元开始读取数据 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //assign语句,指定数据总线与暂存数据之间的连接关系 assign Data_t=RWEnable_t?Data_temp_t:8'bz; always #5 Clk_t=~Clk_t; //实例化一个RAM模块,并且用定义好的信号和寄存器与之相连 RAM myRAM( .Data(Data_t), //将数据总线与RAM模块的Data端口相连 .Addr(Addr_t), //将地址总线与RAM模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与RAM模块的CS端口相连 .RWEnable(RWEnable_t), //将读写使能信号与RAM模块的RWEnable端口相连 .Reset(Reset_t), //将复位信号与RAM模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与RAM模块的Clk端口相连 ); endmodule //模块结束4.RAM仿真测试: ① 数据写入操作 image.png图片 ② 数据读取操作 image.png图片 5.ROM实现代码: RDEnable: 当RDEnable为1时,模块处于读模式,将Addr指定的内存单元中的数据输出到Data总线,当RDEnable为0时,模块处于空闲模式,不对Data驱动。 ROM代码如下: //模块声明,指定模块名和端口引脚 module ROM(Data,Addr,CS,RDEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RDEnable,Reset,Clk; //输入信号,分别为芯片选择、读使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 output [width-1:0] Data; //输出数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_read; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为其地址值 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= i; //将每个内存单元赋值为其地址值 end //读操作条件,当RDEnable为1且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_read中 else if((RDEnable==1'b1)&&(CS==1'b1)) begin Data_read<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_read end //其他条件,当CS为0或RDEnable为不确定值时,将Data_read置为高阻抗状态 else Data_read <= 8'bz; //将Data_read赋值为高阻抗状态 end //assign语句,指定Data总线与Data_read之间的连接关系 assign Data=Data_read; //当RDEnable为1时,Data总线输出Data_read中的数据;当RDEnable为0时,Data总线处于高阻抗状态 endmodule //模块结束测试代码如下: //模块声明,指定模块名为R0M98_TS module R0M_TS; //信号和寄存器的定义,指定与ROM98模块相连的端口引脚和内部变量 reg CS_t,RDEnable_t,Reset_t,Clk_t; //芯片选择、读使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 //initial块,指定测试ROM98模块的过程,只会在仿真开始时执行一次 initial begin RDEnable_t = 1;//r //初始化读使能信号为1,表示读模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 // Data_read_ts = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #10 //延迟10个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //always块,指定时钟信号的变化规律,每隔5个时间单位翻转一次 always #5 Clk_t=~Clk_t; //实例化一个ROM98模块,并且用定义好的信号和寄存器与之相连 ROM myROM( .Data(Data_t), //将数据总线与ROM98模块的Data端口相连 .Addr(Addr_t), //将地址总线与ROM98模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与ROM98模块的CS端口相连 .RDEnable(RDEnable_t), //将读使能信号与ROM98模块的RDEnable端口相连 .Reset(Reset_t), //将复位信号与ROM98模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与ROM98模块的Clk端口相连 ); endmodule //模块结束 6.ROM仿真测试: image.png图片
FPGA&ASIC
VLSI&IC验证
# 体系结构
刘航宇
3年前
0
1,106
2
IC设计技巧-流水线设计
流水线概述 如下图为工厂流水线,工厂流水线就是将一个工作(比如生产一个产品)分成多个细分工作,在生产流水线上由多个不同的人分步完成。这个待完成的产品在流水线上一级一级往下传递。 图片 比如完成一个产品,需要8道工序,每道工序需要10s,那么流水线启动后,不间断工作的话,第一个产品虽然要80s才完成,但是接下来每10s就能产出一个产品。使得速度大大提高。当然这也增加了人员等资源的付出。 对于电路的流水线设计思想与上述思想异曲同工,也是以付出增加资源消耗为代价,去提高电路运算速度。 流水线设计实例 这里以一个简单的8位无符号数全加器的设计为实例来进行讲解,实现 assign {c_out,data_out [7:0]} = a[7:0] + b[7:0] +c_in c_out 为进位位。如果有数字电路常识的人都知道,利用一块组合逻辑电路去做8位的加法,其速度肯定比做2位的加法慢。因此这里可以采用4级流水线设计,每一级只做两位的加法操作,当流水线一启动后,除第一个加法运算之外,后面每经过一个2位加法器的延时,就会得到一个结果。 整体结构如下,每一级通过in_valid,o_valid信号交互,分别代表每一级的输入输出有效信号。 图片 第一级:做最低两位与进位位的加法操作,并将运算结果和未做运算的高六位传给下一级。 图片 第二级:做2,3两位与上一级加法器的进位位的加法操作,并将本级运算结果和未做运算的高4位传给下一级。 图片 第三级:做4,5两位与进位位的加法操作,并将运算结果和未做运算的高2位传给下一级。 图片 第四级:做最高两位与上一级加法器输出的进位位的加法操作,并将结果组合输出。 图片 仿真结果如下 如图,当整体模块in_valid有效时,送进去的数据a=1,b=5,c_in=1;故经过四个周期后,o_valid信号拉高,同时获得运算结果data_out=7。(本设计的流水线每级延时为一个时钟周期)后续输出信号7、9、10显然是间隔2个周期延迟,而不是延迟4周期、8周期逐个输出 图片 总结 流水线就是通过将一个大的组合逻辑划分成分步运算的多个小组合逻辑来运算,从而达到提高速度的目的。 在设计流水线的时候,我们一般要尽量使得每级运算所需要的时间差不多,从而做到流水匹配,提高效率。因为流水线的速度由运算最慢的那一级电路决定。
FPGA&ASIC
VLSI&IC验证
# VLSI
# ASIC/FPGA
刘航宇
3年前
0
543
1
2023-01-29
CSA&4-2压缩器电路设计及verilog代码
进位保留加法器和4-2压缩加法器是加法阵列中主要采用基本单元 目录 CSA-保留进位加法器 32计数器/32压缩器 5-3计数器/53压缩器 4-2压缩器 Verilog代码 CSA-保留进位加法器 保留进位加法器( carry-save-adder)即为一位全加器 逻辑表达式: \begin{aligned} & S_i=A_i \oplus B_i \oplus C_{i-1} \ & C_i=A_i B_i+C_{i-1}\left(A_i+B_i\right) \end{aligned} CSA电路结构图 图片 图片 如果把保留进位加法器的进位端输出到下一级 图片 这样第一级的延时为一个进位保留加法器的延时 32计数器/32压缩器 此进位保留加法器输入3个一位的数据A、B、Ci; 输出两个1位的数据D、Co。 代数运算式如下: Co*2+D=A+B+Ci ●非常明显,保留进位加法器为一计数器--计算输入信号中“1”的个数,计数值由Co、D指示,且: ●Co权值为2; A、B、Ci、D权值为1。 ●其逻辑表达式如下: \begin{aligned} & D=A @ B @ C i \ & C o=A \& B \# A \& C i \# C i \& A \end{aligned} 5-3计数器/53压缩器 ●CSA将3个数据转换成2个数据为3-2计数器,如果能把5个数据转换成3个数据则称之为5-3计数器。 ●它有五个输入端: I0、I1、I2、I3、Ci; 三个输出端: D、C、Co。 ●代数运算式如下: $$ D+C * 2+C_0 * 2=10+11+12+13+C i $$即: I0、 l1、 12、13、Ci、D权值为1; C、Co权值为2。 其真值表如下页: 图片 图片 有数据表示优化后的结构可以减小门延时,传统结构为2个CSA延时,而优化后的延时大约为1.5个CSA延时 4-2压缩器 ●如果连续的两个高低位5-3计数器之间Ci和Co级联的话,则称为4-2压缩加法器 ●如下图 图片 42压缩加法器 图片 ●对于更多位的部分积也有其他的一些结构树,结构的选取要考虑到电路结构的规整 性对后端布局的影响。 ●左边延时比较小但结构不规整。右边正好相反有时候会选取一些折中的结构。 Verilog代码 //----------------------------------------------------------------------- //module : compressor42 //Description : The function of this module is to compress the partial product //----------------------------------------------------------------------- //author : li hangyu //Email : hyliu@ee.ac.cn //time : 01/28, 2023 //----------------------------------------------------------------------- `timescale 1ns/1ps module compressor42 ( in1,in2,in3,in4,cin,out1,out2,cout ); parameter length = 8; input [length*2-1 : 0] in1,in2,in3,in4; input cin; output [length*2 : 0] out1,out2; output cout; wire [length*2-1 : 0] w1,w2,w3; assign w1 = in1 ^ in2 ^ in3 ^ in4; assign w2 = (in1 & in2) | (in3 & in4); assign w3 = (in1 | in2) & (in3 | in4); assign out2 = { w1[length*2-1] , w1} ^ {w3 , cin}; assign cout = w3[length*2-1]; assign out1 = ({ w1[length*2-1] , w1} & {w3 , cin}) | (( ~{w1[length*2-1] , w1}) & { w2[length*2-1] , w2}); endmodule
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,003
12
VLSI设计-基于Cadence的16位超前进位加法器设计
目录 一、设计内容 视频介绍 二、设计目标 三、实验原理1位全加器原理 2超前进位加法器原理 四、实验过程和结果1、1位改进型全加器 2、4位超前进位加法器 3、16位超前进位加法器 4、16位超前进位加法器的优化 五、版图 一、设计内容 完成一个 16 位的超前进位加法器模块设计。 视频介绍 二、设计目标 本设计的主要目标是在电路速度尽可能高的条件下减小芯片的面积与功耗。首先考虑电路的逻辑优化,再考虑逻辑门、逻辑模块和电路的结构设计、最后在版图的布局与布线及面积优化方面进行考虑。 三、实验原理 1位全加器原理 全加器的求和输出信号和进位信号,定义为输入变量A、B、C的两种组合布尔函数: 求和输出信号 = A ⊕ B ⊕ C 进位信号 = AB + AC + BC 实现这两个函数的门级电路如下图。并不是单独实现这两个函数,而是用进位信号来产生求和输出信号。这样可以减少电路的复杂度,因此节省了芯片面积。 图片 上述全加器电路可以用作一般的n位二进制加法器的基本组合模块,它允许两个n位的二进制数作为输入,在输出端产生二进制和。最简单的n位加法器可由全加器串联构成,这里每级加法器实现两位加法运算,产生相应求和位,再将进位输出传到下一级。这样串联的加法器结构称为并行加法器,但其整体速度明显受限于进位链中进位信号的延迟。因此,为了能够减少从最低有效位到最高有效位的最坏情况进位传播延时,最终选择的电路是十六位超前加法器。 2超前进位加法器原理 超前进位加法器的结构如下图。超前进位加法器的每一位由一个改进型全加器产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,产生的等式为: $g_i=A_i B_i$ $p_i=A_i+B_i$ 改进的全加器的进位输出可由一个进位信号和一个进位传输信号计算得出,因此进位信号可改写为: $C_{i+1}=g_i+p_i C_i$ 式中可以看出,当gi = 1(Ai = Bi = 1)时,产生进位;当pi = 1(Ai =1或Bi = 1)时,传输进位输入,这两种情况都使得进位输出是1。近似可以得到i+2和i+3级的进位输出如下: 图片 下图为一个四位超前进位加法器的结构图。信号经过pi和gi产生一级时延,经过计算C产生一级时延,则A,B输入一旦产生,首先经过两级时延算出第1轮进位值C’不过这个值是不正确的。C’再次送入加法器,进行第2轮2级时延的计算,算出第2轮进位值C,这一次是正确的进位值。这里的4个4位超前进位加法器仍是串行的,所以一次计算经过4级加法器,一级加法器有2级时延,因此1次计算一共经过8级时延,相比串行加法器里的16级时延,速度提高很多。 图片 四、实验过程和结果 1、1位改进型全加器 (1)1位改进型全加器电路 将原始的一位全加器进行改进,使其产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,得到如下电路图。 图片 (2)1位改进型全加器逻辑验证 在cadence中将导出改进型1位全加器的cdl文件,并编写1bit.sp文件用Hspice进行仿真验证。仿真结果如下图所示,输入信号a、b、c都为脉冲信号,即下图中第一条和第二条曲线,输出信号s为第三条曲线,由图像可知逻辑功能正确,说明改进型一位全加器电路逻辑没有问题。 图片 2、4位超前进位加法器 (1)4位超前进位加法器电路 将1位改进型全加器连接成如下图的4位超前进位加法器,其中电路内部每一个进位信号不是进位传播得到,而使用进位信号和进位传播信号同时计算得到。 图片 (2)4位超前进位加法器逻辑验证 在cadence中将导出4位超前进位加法器的cdl文件,并编写4bit.sp文件用Hspice进行仿真验证。仿真结果如下图。 在sp文件中对B0,B1,B2,B3都输入5V高电平,对A1,A2,A3输入0V低电平,其中A0,C0输入脉冲信号,这样最终的结果S0,S1,S2,S3会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确 图片 3、16位超前进位加法器 (1)16位超前进位加法器电路 将4位超前进位加法器连接成如下图的16位超前进位加法器,加法器之间为并行连接,前一个4位超前进位加法器的进位输送到下一级。 图片 (2)16位超前进位加法器电路逻辑验证 在cadence中导出16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。 在sp文件中对B0,B1,B2,B3,B4,B5,B6,B7,B8,B9,B10,B11,B12,B13,B14,B15都输入5V高电平,对A1,A2,A3,A4,A5,A6,A7,A8,A9,A10,A11,A12,A13,A14,A15输入0V低电平,其中A0,C0输入脉冲信号,这样输出的结果S0,S1,S2,S3,S4,S5,S6,S7,S8,S9,S10,S11,S12,S13, S14,S15和进位信号C会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确。但是存在较大的延时,经过测量可知延时为8.294ns。 图片 4、16位超前进位加法器的优化 (1)16位超前进位加法器优化原理 由上述结果可知,由于位数增加,超前模块的复杂度也会增加,这将反过来降低加法运算的速度,同时也有较大的延时。为了解决这个问题,对于上述的宽位加法器,使用整组进位信号和,电路结构如下图,4组以上的整组进位信号和传播信号定义为: 图片 上式中每个4组的进位输出信号由进位信号表示如下: 图片 (2)16位超前进位加法器优化电路 由上述改进方法,首先对4位超前进位加法器进行修改,使其输出P,G信号,同时对16位超前进位加法器的电路进行修改,使其每一位的进位信号都可以直接计算出来,而不是依赖于上一个加法器,修改结果如下。 图片 图片 (3)16位超前进位加法器优化电路逻辑验证 在cadence中导出修改后的16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。经过测量可知延时为6.623ns。 图片 图片 五、版图 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,279
1
2022-11-30
VLSI设计-基4 Booth乘法器前端与中端实现
前言 在微处理器芯片中,乘法器是进行数字信号处理的核心,同时也是微处理器中进行数据处理的关键部件。乘法器完成一次操作的周期基本上决定了微处理器的主频。乘法器的速度和面积优化对于整个CPU的性能来说是非常重要的。为了加快乘法器的执行速度,减少乘法器的面积,有必要对乘法器的算法、结构及电路的具体实现做深入的研究。 目录 视频课程,关注本人B站账号有完整版前端中端设计教程 前言 视频课程,关注本人B站账号有完整版前端中端设计教程 1. 设计内容 2. 设计目标 3.原理介绍 4.电路&Verilog代码基4Booth编码器 4-2压缩器 超前进位加法器 4、仿真分析前端逻辑仿真 电路与性能仿真电路图 面积报告 功耗报告 后端 1. 设计内容 完成一个全定制的 8x8 bits 基-4 Booth 编码码乘法器核心电路设计,即可以不考虑输入、输出数据的寄存。 2. 设计目标 本设计最主要的目标是在电路速度尽可能高的条件下最小化电路的功率-延迟积(PDP)。所以首先在电路结构设计完成后需要分析、考虑最长延迟路径。根据设计目标进行逻辑链优化。 3.原理介绍 本乘法器采用基4booth编码,输入为两个8位有符号数,输出为16位有符号数。基4的booth编码将两个8位有符号数计算成4个部分积。4个部分积经过一层4-2压缩器得到2个部分积,得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。 图片 思维扩展: 若输入为两个128位有符号数,输出为256位有符号数。基4的booth编码将两个128位有符号数计算成64个部分积。64个部分积经过一层4-2压缩器得到32个部分积……在经过几层4-2压缩器,最终得到两个部分积,两个部分积进过一个超前进位加法器(cla)得到最终结果。结构框图如下: 图片 4.电路&Verilog代码 设计理念:功能需求->Verilog代码->代码转电路(DC)->电路转版图(ICC或SOCE) 基4Booth编码器 对于被乘数b_i进行编码,Booth 基-4 编码是根据相邻 3 位为一组,前后相邻分组重叠一比特位,从低位到高位逐次进行,在乘数的最右边另增加一位辅助位 0,作为分组的最低位。Booth 4-基编码的优点是可以减少 Booth 2-基产生部分积的一半,Booth 基-4 除了具有高速特性还具有低功耗的特点。 图片 对应case case(b_i) 3'b000 : booth_o <= 0; 3'b001 : booth_o <= { a_i[length-1], a_i}; 3'b010 : booth_o <= { a_i[length-1], a_i}; 3'b011 : booth_o <= a_i<<1; 3'b100 : booth_o <= -(a_i<<1); 3'b101 : booth_o <= -{a_i[length-1],a_i}; 3'b110 : booth_o <= -{a_i[length-1],a_i}; 3'b111 : booth_o <= 0; default: booth_o <= 0;4-2压缩器 4-2 压缩器的原理图如下所示,把 4 个相同权值的二进制数两个权值高一级的二进制数和,它有 5 个输入端口:包括 4 个待压缩数据 a1、a2、a3、a4 和一个初始进位或低权值 4-2 压缩传递的进位值 Ci;3 个输出端口:包括一比特位溢出进位值 Co,进位数据 C,伪和 S。 下面代码得到的结果out1的权值高一位,下一层部分积计算时需要将out1的结果左移一位(out1<<1); 图片 功能代码: assign w1 = in1 ^ in2 ^ in3 ^ in4; assign w2 = (in1 & in2) | (in3 & in4); assign w3 = (in1 | in2) & (in3 | in4); assign out2 = { w1[length*2-1] , w1} ^ {w3 , cin}; assign cout = w3[length*2-1]; assign out1 = ({ w1[length*2-1] , w1} & {w3 , cin}) | (( ~{w1[length*2-1] , w1}) & { w2[length*2-1] , w2});超前进位加法器 4位超前进位代码: //carry generator assign c[0] = cin; assign c[1] = g[0] + ( c[0] & p[0] ); assign c[2] = g[1] + ( (g[0] + ( c[0] & p[0]) ) & p[1] ); assign c[3] = g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] ); assign c[4] = g[3] + ( (g[2] + ( (g[1] + ( (g[0] + (c[0] & p[0]) ) & p[1])) & p[2] )) & p[3]); assign cout = c[width];代码下载 基4 Booth代码 下载地址:https://wwek.lanzoub.com/ikPEB0m2z41a 提取码: 4、仿真分析 前端逻辑仿真 本设计是单纯的组合逻辑,由仿真结果可知有符号乘法设计结果完全正确。 图片 电路与性能仿真 电路图 图片 面积报告 DC综合后,总共的单元面积为7853.630484等效门,总面积为78273.983938等效门。 图片 功耗报告 图片 由于该电路是完全的组合逻辑,无CLK端口,因此未作时序约束。 后端 做到这里完成了前端中端设计任务,在流片前还需要完成后端设计及验证。由于本电路规模大,我们可以利用EDA如(SOCE或者ICC)完成版图布局,由于时间仓促,笔者暂未更新后端教程。
FPGA&ASIC
VLSI&IC验证
# ASIC/FPGA
刘航宇
4年前
0
1,355
4
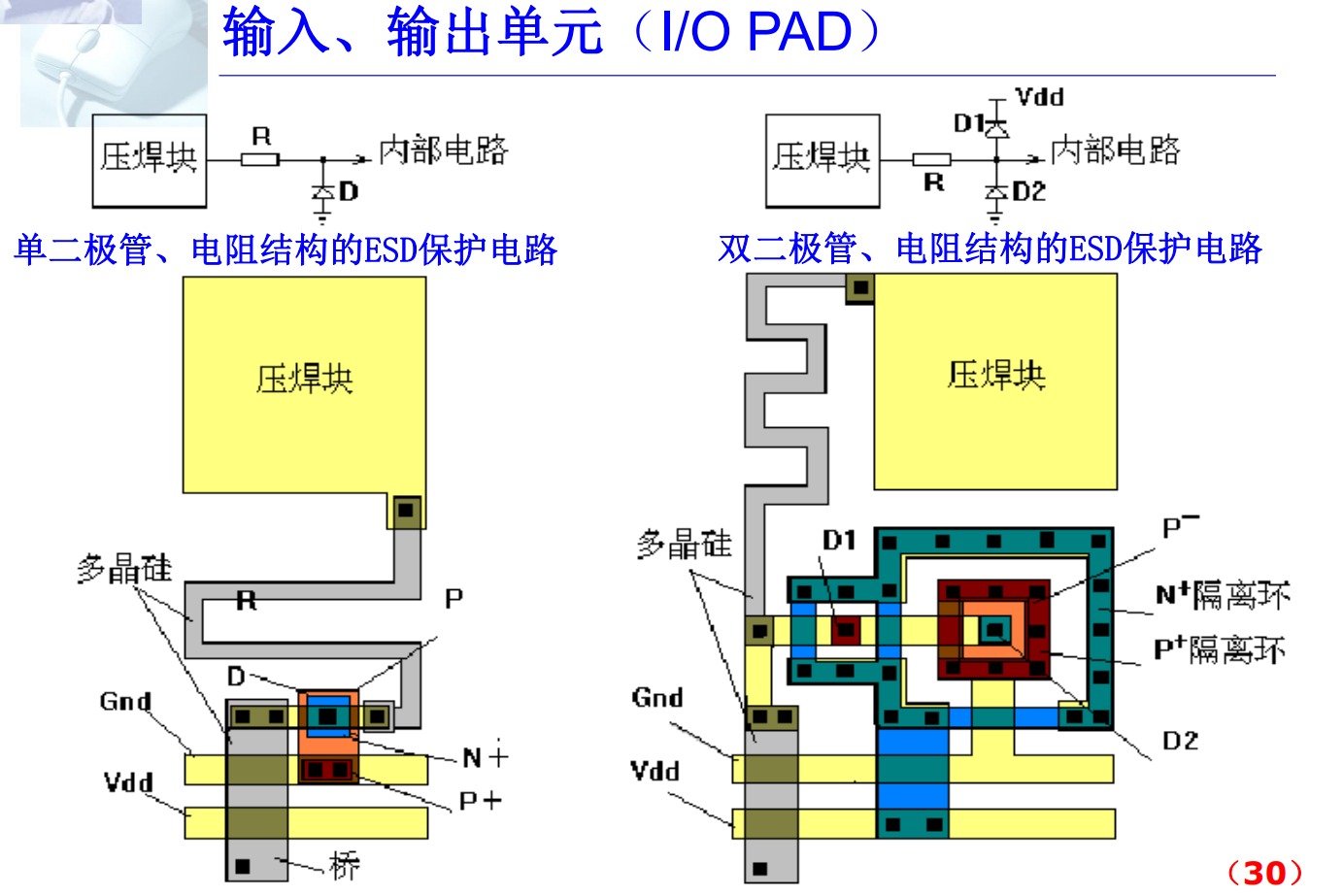
集成电路中I/O PAD及其版图
标准单元设计技术的特点: 标准单元是一个具有规则外部形状的单元,其内容是优化设计的逻辑单元版图,各单元的规模应相近,并遵循一致的引线规则。 一个标准单元库内的所有单元遵循同一的工艺设计规则,一个单元库对应一条或一组完全相同的工艺线。也就是说,当工艺发生变化时,单元库必须修改或重建。 不论是局部逻辑或是完整的集成电路或系统,用标准单元实现的版图采用“行式结构”,即各标准单元排列成行。 输入、输出单元(I/O PAD) 任何一种设计技术、版图结构都需要输入/输出单元。 想想看, I/O单元有什么作用? 连接芯片内部与芯片外部系统 (压焊块) 要的功能:对外的驱动 内提供内外的隔离和输入保护功能 I /O单元的形式 I/O PAD不仅是压焊块,还有电路,需电源和地线连通。 焊块用于连接芯片与封装管座,这些压焊块通常是边长几十微米的矩形。 大部分I/O PAD都是以标准单元的结构形式出现。通常具有等高不等宽的外部形状。 图片 图片 图片
VLSI&IC验证
# VLSI
刘航宇
4年前
0
3,782
4
关于射频芯片马上懂!
一部可支持打电话、发短信、网络服务、APP应用的手机,通常包含五个部分:射频、基带、电源管理、外设、软件。 射频: 一般是信息发送和接收的部分; 基带: 一般是信息处理的部分; 电源管理: 一般是节电的部分,由于手机是能源有限的设备,所以电源管理十分重要; 外设: 一般包括LCD,键盘,机壳等; 软件: 一般包括系统、驱动、中间件、应用。 目录 射频芯片和基带芯片的关系 工作原理与电路分析 接收电路的结构和工作原理1.电路结构 2.各元件的功能与作用 3.接收信号流程 1.电路结构 2.各元件的功能与作用 3.发射信号流程 国产射频芯片产业链现状 在手机终端中,最重要的核心就是射频芯片和基带芯片。射频芯片负责射频收发、频率合成、功率放大;基带芯片负责信号处理和协议处理。那么射频芯片和基带芯片是什么关系? 射频芯片和基带芯片的关系 射频(Radio Frenquency)和基带(Base Band)皆来自英文直译。其中射频最早的应用就是Radio——无线广播(FM/AM),迄今为止这仍是射频技术乃至无线电领域最经典的应用。 基带则是band中心点在0Hz的信号,所以基带就是最基础的信号。有人也把基带叫做“未调制信号”,曾经这个概念是对的,例如AM为调制信号(无需调制,接收后即可通过发声元器件读取内容)。 但对于现代通信领域而言,基带信号通常都是指经过数字调制的,频谱中心点在0Hz的信号。而且没有明确的概念表明基带必须是模拟或者数字的,这完全看具体的实现机制。 言归正传,基带芯片可以认为是包括调制解调器,但不止于调制解调器,还包括信道编解码、信源编解码,以及一些信令处理。而射频芯片,则可看做是最简单的基带调制信号的上变频和下变频。 所谓调制,就是把需要传输的信号,通过一定的规则调制到载波上面让后通过无线收发器(RF Transceiver)发送出去的工程,解调就是相反的过程。 工作原理与电路分析 射频简称RF射频就是射频电流,是一种高频交流变化电磁波,为是Radio Frequency的缩写,表示可以辐射到空间的电磁频率,频率范围在300KHz~300GHz之间。每秒变化小于1000次的交流电称为低频电流,大于10000次的称为高频电流,而射频就是这样一种高频电流。高频(大于10K);射频(300K-300G)是高频的较高频段;微波频段(300M-300G)又是射频的较高频段。射频技术在无线通信领域中被广泛使用,有线电视系统就是采用射频传输方式。 射频芯片指的就是将无线电信号通信转换成一定的无线电信号波形, 并通过天线谐振发送出去的一个电子元器件,它包括功率放大器、低噪声放大器和天线开关。射频芯片架构包括接收通道和发射通道两大部分。 射频电路方框图图片 接收电路的结构和工作原理 接收时,天线把基站发送来电磁波转为微弱交流电流信号经滤波,高频放大后,送入中频内进行解调,得到接收基带信息(RXI-P、RXI-N、RXQ-P、RXQ-N);送到逻辑音频电路进一步处理。 该电路掌握重点:1、接收电路结构;2、各元件的功能与作用;3、接收信号流程。 1.电路结构 接收电路由天线、天线开关、滤波器、高放管(低噪声放大器)、中频集成块(接收解调器)等电路组成。早期手机有一级、二级混频电路,其目的把接收频率降低后再解调(如下图) 接收电路方框图图片 2.各元件的功能与作用 1)、手机天线: 结构:(如下图) 由手机天线分外置和内置天线两种;由天线座、螺线管、塑料封套组成。 图片 作用:a)、接收时把基站发送来电磁波转为微弱交流电流信号。b)、发射时把功放放大后的交流电流转化为电磁波信号。 2)、天线开关: 结构:(如下图) 手机天线开关(合路器、双工滤波器)由四个电子开关构成。 图片 作用: 完成接收和发射切换; 完成900M/1800M信号接收切换。 逻辑电路根据手机工作状态分别送出控制信号(GSM-RX-EN;DCS- RX-EN;GSM-TX-EN;DCS- TX-EN),令各自通路导通,使接收和发射信号各走其道,互不干扰。 由于手机工作时接收和发射不能同时在一个时隙工作(即接收时不发射,发射时不接收)。因此后期新型手机把接收通路的两开关去掉,只留两个发射转换开关;接收切换任务交由高放管完成。 3)、滤波器: 结构:手机中有高频滤波器、中频滤波器。 作用:滤除其他无用信号,得到纯正接收信号。后期新型手机都为零中频手机;因此,手机中再没有中频滤波器。 4)、高放管(高频放大管、低噪声放大器): 结构:手机中高放管有两个:900M高放管、1800M高放管。都是三极管共发射极放大电路;后期新型手机把高放管集成在中频内部。 高频放大管供电图图片 作用: 对天线感应到微弱电流进行放大,满足后级电路对信号幅度的需求。 完成900M/1800M接收信号切换。 原理: 供电:900M/1800M两个高放管的基极偏压共用一路,由中频同时路提供;而两管的集电极的偏压由中频CPU根据手机的接收状态命令中频分两路送出;其目的完成900M/1800M接收信号切换。 经过滤波器滤除其他杂波得到纯正935M-960M的接收信号由电容器耦合后送入相应的高放管放大后经电容器耦合送入中频进行后一级处理。 5)、中频(射频接囗、射频信号处理器): 结构:由接收解调器、发射调制器、发射鉴相器等电路组成;新型手机还把高放管、频率合成、26M振荡及分频电路也集成在内部(如下图)。 图片 作用: a)、内部高放管把天线感应到微弱电流进行放大; b)、接收时把935M-960M(GSM)的接收载频信号(带对方信息)与本振信号(不带信息)进行解调,得到67.707KHZ的接收基带信息; c)、发射时把逻辑电路处理过的发射信息与本振信号调制成发射中频; d)、结合13M/26M晶体产生13M时钟(参考时钟电路); e)、根据CPU送来参考信号,产生符合手机工作信道的本振信号。 3.接收信号流程 手机接收时,天线把基站发送来电磁波转为微弱交流电流信号,经过天线开关接收通路,送高频滤波器滤除其它无用杂波,得到纯正935M-960M(GSM)的接收信号,由电容器耦合送入中频内部相应的高放管放大后,送入解调器与本振信号(不带信息)进行解调,得到67.707KHZ的接收基带信息(RXI-P、RXI-N、RXQ-P、RXQ-N);送到逻辑音频电路进一步处理。 #发射电路的结构和工作原理 发射时,把逻辑电路处理过的发射基带信息调制成的发射中频,用TX-VCO把发射中频信号频率上变为890M-915M(GSM)的频率信号。经功放放大后由天线转为电磁波辐射出去。 该电路掌握重点:(1)、电路结构;(2)、各元件的功能与作用;(3)、发射信号流程。 1.电路结构 发射电路由中频内部的发射调制器、发射鉴相器;发射压控振荡器(TX-VCO)、功率放大器(功放)、功率控制器(功控)、发射互感器等电路组成。(如下图) 发射电路方框图图片 2.各元件的功能与作用 1)、发射调制器: 结构:发射调制器在中频内部,相当于宽带网络中的MOD。 作用:发射时把逻辑电路处理过的发射基带信息(TXI-P;TXI-N;TXQ-P;TXQ-N)与本振信号调制成发射中频。 2)、发射压控振荡器(TX-VCO): 结构:发射压控振荡器是由电压控制输出频率的电容三点式振荡电路;在生产制造时集成为一小电路板上,引出五个脚:供电脚、接地脚、输出脚、控制脚、900M/1800M频段切换脚。当有合适工作电压后便振荡产生相应频率信号。 作用:把中频内调制器调制成的发射中频信号转为基站能接收的890M-915M(GSM)的频率信号。 原理:众所周知,基站只能接收890M-915M(GSM)的频率信号,而中频调制器调制的中频信号(如三星发射中频信号135M)基站不能接收的,因此,要用TX-VCO把发射中频信号频率上变为890M-915M(GSM)的频率信号。 当发射时,电源部分送出3VTX电压使TX-VCO工作,产生890M-915M(GSM)的频率信号分两路走:a)、取样送回中频内部,与本振信号混频产生一个与发射中频相等的发射鉴频信号,送入鉴相器中与发射中频进行较;若TX-VCO振荡出频率不符合手机的工作信道,则鉴相器会产生1-4V跳变电压(带有交流发射信息的直流电压)去控制TX-VCO内部变容二极管的电容量,达到调整频率准确性目的。b)、送入功放经放大后由天线转为电磁波辐射出去。 从上看出:由TX-VCO产生频率到取样送回中频内部,再产生电压去控制TX-VCO工作;刚好形成一个闭合环路,且是控制频率相位的,因此该电路也称发射锁相环电路。 3)、功率放大器(功放): 结构:目前手机的功放为双频功放(900M功放和1800M功放集成一体),分黑胶功放和铁壳功放两种;不同型号功放不能互换。 作用:把TX-VCO振荡出频率信号放大,获得足够功率电流,经天线转化为电磁波辐射出去。 值得注意:功放放大的是发射频率信号的幅值,不能放大他的频率。 功率放大器的工作条件: a)、工作电压(VCC):手机功放供电由电池直接提供(3.6V); b)、接地端(GND):使电流形成回路; c)、双频功换信号(BANDSEL):控制功放工作于900M或工作于1800M; d)、功率控制信号(PAC):控制功放的放大量(工作电流); e)、输入信号(IN);输出信号(OUT)。 4)、发射互感器: 结构:两个线径和匝数相等的线圈相互靠近,利用互感原理组成。 作用:把功放发射功率电流取样送入功控。 原理:当发射时功放发射功率电流经过发射互感器时,在其次级感生与功率电流同样大小的电流,经检波(高频整流)后并送入功控。 5)、功率等级信号: 所谓功率等级就是工程师们在手机编程时把接收信号分为八个等级,每个接收等级对应一级发射功率(如下表),手机在工作时,CPU根据接的信号强度来判断手机与基站距离远近,送出适当的发射等级信号,从而来决定功放的放大量(即接收强时,发射就弱)。 附功率等级表: 图片 6)、功率控制器(功控): 结构:为一个运算比较放大器。 作用:把发射功率电流取样信号和功率等级信号进行比较,得到一个合适电压信号去控制功放的放大量。 原理:当发射时功率电流经过发射互感器时,在其次级感生的电流,经检波(高频整流)后并送入功控;同时编程时预设功率等级信号也送入功控;两个信号在内部比较后产生一个电压信号去控制功放的放大量,使功放工作电流适中,既省电又能长功放使用寿命(功控电压高,功放功率就大)。 3.发射信号流程 当发射时,逻辑电路处理过的发射基带信息(TXI-P;TXI-N;TXQ-P;TXQ-N),送入中频内部的发射调制器,与本振信号调制成发射中频。而中频信号基站不能接收的,要用TX-VCO把发射中频信号频率上升为890M-915M(GSM)的频率信号基站才能接收。当TX-VCO工作后,产生890M-915M(GSM)的频率信号分两路走: a)、一路取样送回中频内部,与本振信号混频产生一个与发射中频相等的发射鉴频信号,送入鉴相器中与发射中频进行较;若TX-VCO振荡出频率不符合手机的工作信道,则鉴相器会产生一个1-4V跳变电压去控制TX-VCO内部变容二极管的电容量,达到调整频率目的。 b)、二路送入功放经放大后由天线转化为电磁波辐射出去。为了控制功放放大量,当发射时功率电流经过发射互感器时,在其次级感生的电流,经检波(高频整流)后并送入功控;同时编程时预设功率等级信号也送入功控;两个信号在内部比较后产生一个电压信号去控制功放的放大量,使功放工作电流适中,既省电又能长功放使用寿命。 国产射频芯片产业链现状 在射频芯片领域,市场主要被海外巨头所垄断,国内射频芯片方面,没有公司能够独立支撑IDM的运营模式,主要为Fabless设计类公司;国内企业通过设计、代工、封装环节的协同,形成了“软IDM“”的运营模式。 图片 射频芯片设计方面,国内公司在5G芯片已经有所成绩,具有一定的出货能力。射频芯片设计具有较高的门槛,具备射频开发经验后,可以加速后续高级品类射频芯片的开发。 射频芯片封装方面,5G射频芯片一方面频率升高导致电路中连接线的对电路性能影响更大,封装时需要减小信号连接线的长度;另一方面需要把功率放大器、低噪声放大器、开关和滤波器封装成为一个模块,一方面减小体积另一方面方便下游终端厂商使用。为了减小射频参数的寄生需要采用Flip-Chip、Fan-In和Fan-Out封装技术。 Flip-Chip和Fan-In、Fan-Out工艺封装时,不需要通过金丝键合线进行信号连接,减少了由于金丝键合线带来的寄生电效应,提高芯片射频性能;到5G时代,高性能的Flip-Chip/Fan-In/Fan-Out结合Sip封装技术会是未来封装的趋势。 在射频芯片领域,市场主要被海外巨头所垄断,国内射频芯片方面,没有公司能够独立支撑IDM的运营模式,主要为Fabless设计类公司;国内企业通过设计、代工、封装环节的协同,形成了“软IDM“”的运营模式。 图片 Flip-Chip/Fan-In/Fan-Out和Sip封装属于高级封装,其盈利能力远高于传统封装。国内上市公司,形成了完整的FlipChip+Sip技术的封装能力。
VLSI&IC验证
# 射频IC
刘航宇
4年前
0
1,445
0
上一页
1
2