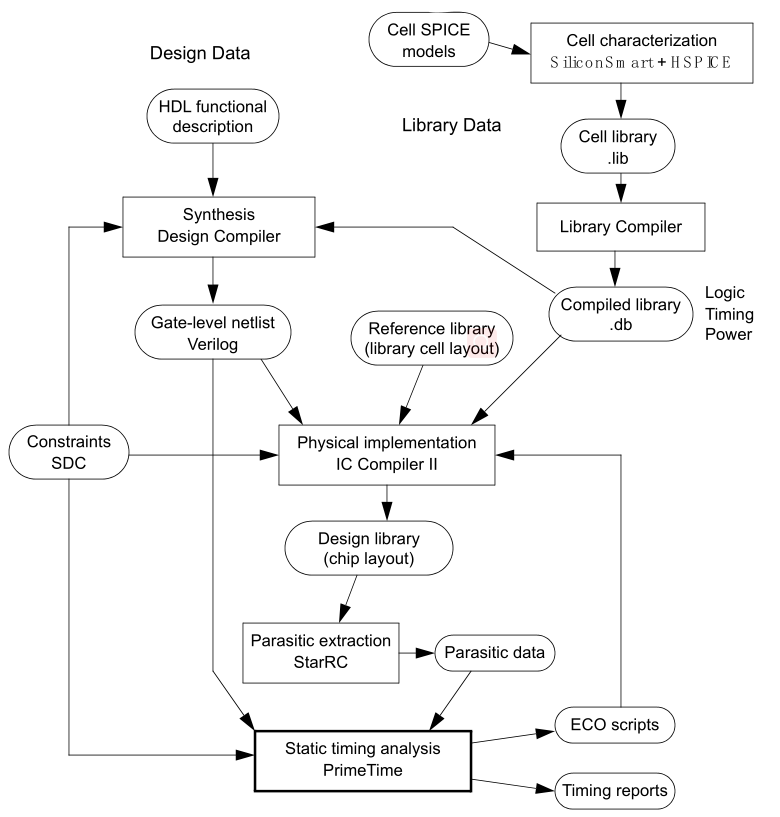
一、设计内容
完成一个 16 位的超前进位加法器模块设计。
视频介绍
二、设计目标
本设计的主要目标是在电路速度尽可能高的条件下减小芯片的面积与功耗。首先考虑电路的逻辑优化,再考虑逻辑门、逻辑模块和电路的结构设计、最后在版图的布局与布线及面积优化方面进行考虑。
三、实验原理
1位全加器原理
全加器的求和输出信号和进位信号,定义为输入变量A、B、C的两种组合布尔函数:
求和输出信号 = A ⊕ B ⊕ C
进位信号 = AB + AC + BC
实现这两个函数的门级电路如下图。并不是单独实现这两个函数,而是用进位信号来产生求和输出信号。这样可以减少电路的复杂度,因此节省了芯片面积。![图片[1] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4ae01face21e9ef6af0af.jpg "图片[1] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
上述全加器电路可以用作一般的n位二进制加法器的基本组合模块,它允许两个n位的二进制数作为输入,在输出端产生二进制和。最简单的n位加法器可由全加器串联构成,这里每级加法器实现两位加法运算,产生相应求和位,再将进位输出传到下一级。这样串联的加法器结构称为并行加法器,但其整体速度明显受限于进位链中进位信号的延迟。因此,为了能够减少从最低有效位到最高有效位的最坏情况进位传播延时,最终选择的电路是十六位超前加法器。
2超前进位加法器原理
超前进位加法器的结构如下图。超前进位加法器的每一位由一个改进型全加器产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,产生的等式为:
$g_i=A_i B_i$
$p_i=A_i+B_i$
改进的全加器的进位输出可由一个进位信号和一个进位传输信号计算得出,因此进位信号可改写为:
$C_{i+1}=g_i+p_i C_i$
式中可以看出,当gi = 1(Ai = Bi = 1)时,产生进位;当pi = 1(Ai =1或Bi = 1)时,传输进位输入,这两种情况都使得进位输出是1。近似可以得到i+2和i+3级的进位输出如下:![图片[2] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4af7dface21e9ef6e463f.jpg "图片[2] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
下图为一个四位超前进位加法器的结构图。信号经过pi和gi产生一级时延,经过计算C产生一级时延,则A,B输入一旦产生,首先经过两级时延算出第1轮进位值C’不过这个值是不正确的。C’再次送入加法器,进行第2轮2级时延的计算,算出第2轮进位值C,这一次是正确的进位值。这里的4个4位超前进位加法器仍是串行的,所以一次计算经过4级加法器,一级加法器有2级时延,因此1次计算一共经过8级时延,相比串行加法器里的16级时延,速度提高很多。![图片[3] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4af8dface21e9ef6e6c6d.jpg "图片[3] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
四、实验过程和结果
1、1位改进型全加器
(1)1位改进型全加器电路
将原始的一位全加器进行改进,使其产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,得到如下电路图。![图片[4] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4afd6face21e9ef6f294d.jpg "图片[4] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
(2)1位改进型全加器逻辑验证
在cadence中将导出改进型1位全加器的cdl文件,并编写1bit.sp文件用Hspice进行仿真验证。仿真结果如下图所示,输入信号a、b、c都为脉冲信号,即下图中第一条和第二条曲线,输出信号s为第三条曲线,由图像可知逻辑功能正确,说明改进型一位全加器电路逻辑没有问题。![图片[5] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b09bface21e9ef70c306.jpg "图片[5] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
2、4位超前进位加法器
(1)4位超前进位加法器电路
将1位改进型全加器连接成如下图的4位超前进位加法器,其中电路内部每一个进位信号不是进位传播得到,而使用进位信号和进位传播信号同时计算得到。![图片[6] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b0fcface21e9ef719533.jpg "图片[6] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
(2)4位超前进位加法器逻辑验证
在cadence中将导出4位超前进位加法器的cdl文件,并编写4bit.sp文件用Hspice进行仿真验证。仿真结果如下图。
在sp文件中对B0,B1,B2,B3都输入5V高电平,对A1,A2,A3输入0V低电平,其中A0,C0输入脉冲信号,这样最终的结果S0,S1,S2,S3会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确![图片[7] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b12fface21e9ef720698.jpg "图片[7] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
3、16位超前进位加法器
(1)16位超前进位加法器电路
将4位超前进位加法器连接成如下图的16位超前进位加法器,加法器之间为并行连接,前一个4位超前进位加法器的进位输送到下一级。![图片[8] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b15dface21e9ef726611.jpg "图片[8] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
(2)16位超前进位加法器电路逻辑验证
在cadence中导出16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。
在sp文件中对B0,B1,B2,B3,B4,B5,B6,B7,B8,B9,B10,B11,B12,B13,B14,B15都输入5V高电平,对A1,A2,A3,A4,A5,A6,A7,A8,A9,A10,A11,A12,A13,A14,A15输入0V低电平,其中A0,C0输入脉冲信号,这样输出的结果S0,S1,S2,S3,S4,S5,S6,S7,S8,S9,S10,S11,S12,S13,
S14,S15和进位信号C会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确。但是存在较大的延时,经过测量可知延时为8.294ns。![图片[9] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b19eface21e9ef72f084.jpg "图片[9] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
4、16位超前进位加法器的优化
(1)16位超前进位加法器优化原理
由上述结果可知,由于位数增加,超前模块的复杂度也会增加,这将反过来降低加法运算的速度,同时也有较大的延时。为了解决这个问题,对于上述的宽位加法器,使用整组进位信号和,电路结构如下图,4组以上的整组进位信号和传播信号定义为:![图片[10] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b1d1face21e9ef735777.jpg "图片[10] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
上式中每个4组的进位输出信号由进位信号表示如下:![图片[11] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b230face21e9ef744000.jpg "图片[11] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
(2)16位超前进位加法器优化电路
由上述改进方法,首先对4位超前进位加法器进行修改,使其输出P,G信号,同时对16位超前进位加法器的电路进行修改,使其每一位的进位信号都可以直接计算出来,而不是依赖于上一个加法器,修改结果如下。![图片[12] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b258face21e9ef7487e7.jpg "图片[12] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
![图片[13] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b29bface21e9ef750ba1.jpg "图片[13] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
(3)16位超前进位加法器优化电路逻辑验证
在cadence中导出修改后的16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。经过测量可知延时为6.623ns。![图片[14] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b2bdface21e9ef754851.jpg "图片[14] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
![图片[15] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b2d4face21e9ef7577cb.jpg "图片[15] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")
五、版图
![图片[16] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客](https://pic.imgdb.cn/item/63d4b300face21e9ef761270.jpg "图片[16] - VLSI设计-基于Cadence的16位超前进位加法器设计 - 我的学记|刘航宇的博客")