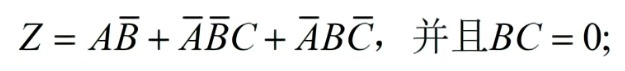首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,946 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,529 阅读
3
【高数】形心计算公式讲解大全
8,984 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,743 阅读
5
Vivado-FPGA Verilog烧写固化教程
7,645 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
三个(共39篇)
找到
39
篇与
三个
相关的结果
国家线已出,26复试与27届考研西北大学843电子信息该如何准备?
🔥 26届复试党(迫在眉睫版) 🌱 27届考研党(早鸟规划版) 27考研概况 843专业招生人数 考试科目 初试题型与分值 下面针对新生常见提问的一些问答: 国家线终于出了是264分!考西北大学843电子信息的宝子们看过来,这篇一次性说清26届复试和27届初试该怎么准备! 图片 peSlNL9.png图片 🔥 26届复试党(迫在眉睫版) 先联系导师,选导师!!提前占据自己喜欢的研究方向 ⏰ 时间节点要记牢 国家线公布后1-2周内,西大自划线+复试名单就会出 复试一般安排在3月底-4月初 📋 西北大学复试考什么?843电子信息复试通常包含: 专业课笔试 综合面试 实验操作 💡 现阶段必做3件事: 速查官网 → 按研究生网站或提供的资料看以往复试细则 联系导师 → 邮件模板准备好,附上简历+初试成绩 狂补专业课 → 重点看初试没考但复试常考的内容 💬 西大复试很公平,不歧视双非!本科没项目也别慌,把毕业设计吃透也能聊! 推荐的复试指导班和资料 ✅26 届 843 复试指导课仅需31(资料整理服务费68) 不到一顿饭钱轻松助你考研一臂之力,报名链接👉 https://mooc1.chaoxing.com/course/portal/f4Jg9QrC9ticE_Jwt1BcCA peSuvvj.png图片 peSlNL9.png图片 🌱 27届考研党(早鸟规划版) 📌 843电子信息考情速览 初试科目:政治、英语一、数学一、843电子基础综合 参考书:模电、数电和电路 🗓️ 全年时间轴(建议版) 图片 全科真题模拟;专业课刷西大历年真题(重点!) ⚠️ 西大843避坑提醒: 真题重复率不低!务必搞到近10年真题(报名27课程或者考研Q群519462257获取) 电路计算题要动手算,别只看不做 关注电子学院和计算机学院官网,9月看招生简章有无变动 推荐的初试系统全程班和资料(报名特惠488,该班级会送复试) ✅27 届 843 电子通信考研系统班:从基础划重点到真题逐题讲,还有复试全程指导,赠送 07-26 年 843/849 真题 + 笔记课件 + 复试资料包,报名链接👉https://mooc1.chaoxing.com/course/260044360.html peSlIW8.png图片 peSlNL9.png图片 请记住: 初试分数是硬道理,复试表现是加分项 别被"本科出身"焦虑绑架,西大真的很公平 现在准备完全来得及,执行力比完美计划更重要 27考研概况 西北大学在大厂如华为、中兴、腾讯和阿里的认可度一向不错,西北大学电子信息类专业在211中报名人数一直较少,21~25年,这几年来看,复试分数线一直都是国家线或者比国家线高几分,因此从报考性价比和上岸概率来说无疑是个不错的选择! 843专业招生人数 新一代电子信息专硕专硕专硕120人左右,电子科学与技术(学硕)20人左右,信息与通信工程(学硕)20人左右 考试科目 模电、数电、电路----(三门课不少章节不考,考的不算多) 初试题型与分值 初试:三门,每门2~3题,每科目占50分 考察基础理解程度 下面针对新生常见提问的一些问答: 问:西北大学843就业情况如何? 答:就业不错,高的有年薪50~60W的,也低的也有18W、15W的,每年有不少去大厂、银行的。 问:西北大学843三个专业初试是一样的吗? 答:完全一样,卷子也一样,复试略有不同 问:我本科不是电子信息类专业可以报名吗? 答:可以,不歧视,根据以往843考研班统计结果来看,是有不少跨专业上岸的,跨幅最大是本科土木 问:我本科是二本,专升本可以吗? 答:可以报名,考试流程都是正常的,对于这类学生可能存在自身学习能力低下,但是只要努力就会有结果,根据以往843考研班统计结果:每年都有二本上岸的,2024年有两位是专升本过来的 问:有没有843考研交流群? 答:有,推荐下面这个843群有500多人QQ群号:519462257QQ群号:519462257QQ群号:519462257 点击快速加入,西大843QQ交流大群 问:843初试都有考哪些东西? 答:模电,数电,电路分析三本书,不过不少地方不考,不用太担心!如果不知道重点可以进一步问学长 问:是否有推荐的靠谱843课程班或资料? 答:下面两个链接是推荐的843班 https://edu.ee.ac.cn/ https://mooc1.chaoxing.com/course/260044360.html peS1nSO.png图片 peSlNL9.png图片 如果只是需要考研初试复试真题资料话可以联系学长哦~ 问:843复试难吗,歧视双非吗? 答:不难中规中矩,不歧视双非,每年有二本上岸的,双非压线上岸的 问:843报考专业如何选择? 答:这个开放的,大家可能根据自己本科专业或者喜好进行选择,学硕毕业要求会难一些,其次招生人数也会少一些
我的随笔
# 西北大学843
刘航宇
1年前
0
2,502
2
通讯等不确定性条件下设计无人机之间的安全距离
引用文章: 简介 1. 研究问题 2. 分离原理介绍 3. 安全半径设计 4. 仿真及实验验证 引用文章: Q. Quan, R. Fu and K. -Y. Cai, "How Far Two UAVs Should Be subject to Communication Uncertainties," in IEEE Transactions on Intelligent Transportation Systems, doi: 10.1109/TITS.2022.3213555. 简介 近年来,无人机技术的快速发展使得低空空域中无人机的数量爆炸增长。碰撞避免作为无人机应用的关键技术,近年来人们已经进行了大量研究,设计出各种方法使得无人机在飞行过程中与障碍物保持一定安全距离(本文将该距离称为无人机的 安全半径)。然而, 在碰撞避免相关研究中,不确定性往往是难以处理的问题。针对不确定性,主流的方法包括对不确定性进行预测,以及在闭环控制中给予补偿。然而,以上方法很依赖于预测及补偿的精准设计,设计不当将有可能导致控制器失效。本研究受地面交通中车辆间安全距离启发,基于对通信不确定性和无人机控制器性能的假设,提出了 安全半径设计和控制器设计的原则 (本文称为 分离原理 )。进一步,安全半径具体通常通过经验预先设计,如果设计得过大或过小将分别影响无人机飞行的高效性及安全性。 如何根据无人机模型及通信不确定性确定其安全半径下界仍然是悬而未决的问题 。利用分离原理,本文研究了 设计阶段(无不确定性)和飞行阶段(受不确定性影响)的无人机安全半径设计 。最后,通过仿真和实验表明了所提方法的有效性。 图片 1. 研究问题 本研究中,无人机与障碍物的运动模型均建模为多旋翼模型,换句话说,我们考虑的障碍物可以等效为另一架多旋翼飞行器。对于多旋翼飞行器而言,其可以获得自身以及障碍物的实时位置和速度。为简单描述起见,本文建模均为二维,类似的建模及分析方法可以扩展到三维情况。 我们首先建立多旋翼的具体控制模型如下。 其中多旋翼的位置和速度分别表示为 ,速度控制模型建立为一阶惯性环节,其时间常数 与无人机的机动性能相关,控制输入 为期望速度。在此基础上,本文定义一种新的滤波位置模型如下。 多旋翼滤波位置的物理意义是根据多旋翼的当前位置、速度及机动能力,对其运动趋势预测。在此基础上,定义多旋翼的安全区域为以滤波位置为圆心的圆形区域,其半径称为安全半径 。对于障碍物,我们类似定义其滤波位置,以及以障碍物滤波位置为圆心的圆形障碍物区域,半径称为障碍物半径 。 图片 进一步,我们针对不确定性做了以下2点假设:(1)无人机和障碍物对自身的三维位置及三维速度估计均存在噪声;(2)无人机在获取障碍物状态信息时,存在通信延迟及丢包。该通信网络模型如下图所示。 图片 本研究中,丢包模型进一步建模为均值模型,且假设估计噪声、通信延迟、丢包均值模型误差均存在上界且上界已知。其数学定义如下: 图片 进一步,本文对无人机的控制器性能做出如下假设:(1)在无不确定性的理想状态下,无人机的控制器可以使无人机和障碍物之间的 真实距离 始终大于给定安全距离;(2)在存在以上不确定性的实际情况中,无人机的控制器可以使无人机和障碍物之间的 估计距离 始终保持给定安全距离。本研究的具体目标是在不确定性上界已知的条件下计算出无人机安全半径的下界。 图片 2. 分离原理介绍 无人机在理想状态下设计的控制器中给定的安全半径值 ,在实际含有不确定性的环境中将转化为估计安全半径 ;直观上理解,将含有不确定性的无人机与障碍物之间的估计位置误差代替真实位置误差作为反馈时,控制器将难以维持给定的安全半径。本研究中, 分离原理具体研究的是不确定性在满足什么条件时无人机的控制器设计和安全半径设计过程可分离 ,也就是估计安全半径和安全半径相等, 成立。分离原理具体数学描述如下: 图片 分离原理中提出的三个条件包括一个充分必要条件(i)以及两个充分条件(ii)和(iii)。其中,条件(i)为理论推导,在实际中难以得到验证,通常可通过条件(ii)和(iii)进行验证。条件(ii)对无人机速度的限制较宽,该式在障碍物主动躲避无人机的条件下容易达成。反之,条件(iii)对无人机速度的限制较苛刻,要求无人机速度严格大于障碍物速度,适用于在障碍物不主动躲避无人机的情况下。以上两种情况的区别如下图所示。 图片 3. 安全半径设计 根据上述分离原理的提出,在分离原理满足的前提下,基于无人机的安全半径模型和通信网络模型,可以进一步设计 合适大小的无人机安全半径 。如前文所述,安全半径设计过大会增加环境的冗余度,设计过小则无法保证飞行过程的安全。在本研究中,给出了在理想情况下以及实际情况下安全半径的下界,分别如下: 图片 4. 仿真及实验验证 仿真及实验验证在仿真中,我们针对单障碍物、多非合作障碍物、多合作障碍物设计了三种场景来验证我们方法的有效性。在实验中,我们使用DJI tello无人机对以上情况进行测试,结果与我们的理论一致。实验视频: https://youtu.be/LkSDPFGa_1E 论文地址 https://rfly.buaa.edu.cn/pdfs/2022/How_far_two_UAVs_should_be_subject_to_communication_uncertainties.pdf
软硬件算法
# 软件算法
刘航宇
2年前
0
1,017
1
2024-07-05
Linux之不使用命令删除文件中的第N行
1.问题描述 2. 解题思路: 3. 代码实现: 1.问题描述 设计一个程序,通过命令行参数接收一个文件名 filename.txt (纯文本文件)和一个整型数字 n,实现从 filename.txt 中删除第 n 行数据。 2. 解题思路: (1) 借助临时文件: 将文件逐行读取,跳过要删除的行,并将其写入临时文件,然后删除源文件,重命名临时文件为源文件,完成删除指定行数据。 (2) 不借助临时文件: 将文件以读写方式打开,读取到要删除行后,通过移动文件指针将文件后面所有行前移一行,但是最后一行会重复,可以通过截断文件操作完成在源文件上删除指定行数据。 (3) 通过sed 或 awk 删除文件指定行 3. 代码实现: (1) 通过 fopen 打开文件借助临时文件删除指定行数据 #filename:ques_15a.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如exit int main(int argc, char *argv[]) { // 检查命令行参数的数量是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 如果不正确,打印用法信息并退出 } char buf[4096]; // 定义一个足够大的字符数组用于读取文件行 int linenum = atoi(argv[2]); // 将命令行参数中的行号转换为整数 FILE *fp = fopen(argv[1], "r"); // 尝试以只读模式打开源文件 FILE *fpt = fopen("temp.txt", "w"); // 创建一个临时文件用于写入 // 如果源文件无法打开,打印错误信息并退出 if (!fp) { printf("File %s not exist!\n", argv[1]); exit(EXIT_FAILURE); } // 检查是否有权限修改源文件 char str[100]; sprintf(str, "%s%s", "test -w ", argv[1]); if (system(str)) { // 如果没有写权限 printf("Can't modify file %s, permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打印错误信息并退出 } int total_line = 0; // 初始化文件总行数计数器 while (fgets(buf, sizeof(buf), fp)) { // 读取文件的每一行 total_line++; } fseek(fp, 0, SEEK_SET); // 将文件指针重置到文件的开头 // 如果要删除的行数大于文件的总行数,打印错误信息并退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int i = 0; // 初始化当前行计数器 while (fgets(buf, sizeof(buf), fp)) { // 再次读取文件的每一行 i++; // 当前行数加1 if (i != linenum) { // 如果当前行不是要删除的行 fputs(buf, fpt); // 将当前行写入临时文件 } } remove(argv[1]); // 删除原始文件 rename("temp.txt", argv[1]); // 将临时文件重命名为原始文件名 // 关闭文件指针 fclose(fp); fclose(fpt); return 0; // 程序正常退出 }(2) 通过 Linux 系统调用 open 打开文件,需要自定义读取一行的函数,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如atoi和exit #include <string.h> // 包含字符串操作函数,比如strlen #include <fcntl.h> // 包含文件控制的定义 #include <sys/stat.h> // 包含文件状态的定义 #include <sys/types.h>// 包含各种数据类型 #include <unistd.h> // 包含UNIX标准函数定义 // 函数声明:读取一行文件内容到缓冲区 int readline(int fd, char *buf) { int t = 0; // 用于记录读取的字符数 // 循环读取直到遇到换行符 for (; ;) { read(fd, &buf[t], 1); // 从文件描述符fd读取一个字符到buf t++; // 增加读取的字符数 if (buf[t-1] == '\n') { // 如果读取到换行符 break; // 退出循环 } } return t; // 返回读取的字符数 } // 函数声明:获取文件的大小和行数 int get_file_info(int fd, int *size) { int num = 0; // 记录行数 char ch; // 临时变量用于存储读取的字符 // 循环读取直到文件结束 while (read(fd, &ch, 1) > 0) { (*size)++; // 文件大小加1 if (ch == '\n') { // 如果读取到换行符 num++; // 行数加1 } } return num; // 返回行数 } int main(int argc, char *argv[]) { // 检查命令行参数数量 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出 } int fd; // 文件描述符 char buf[4096]; // 缓冲区 int linenum = atoi(argv[2]); // 将命令行参数转换为整数 // 尝试以读写模式打开文件 fd = open(argv[1], O_RDWR); if (fd < 0) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打开失败时退出 } int size = 0; // 文件大小 // 获取文件的行数和大小 int total_line = get_file_info(fd, &size); // 如果要删除的行数大于文件总行数,退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 要删除行的大小 int t = 0; // 当前行的大小 int i = 0; // 当前行数 lseek(fd, 0, SEEK_SET); // 将文件指针移到文件头 // 循环读取文件,直到文件结束 while (read(fd, &buf[0], 1) > 0) { lseek(fd, -1, SEEK_CUR); // 回退一个字符 memset(buf, 0, sizeof(buf)); // 清空缓冲区 readline(fd, buf); // 读取一行到缓冲区 i++; // 行数加1 t = strlen(buf); // 当前行的大小 // 如果当前行是目标行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在目标行之后,将该行前移 if (i > linenum) { lseek(fd, -(s+t), SEEK_CUR); // 移动文件指针 write(fd, buf, strlen(buf)); // 写入当前行 lseek(fd, s, SEEK_CUR); // 移动文件指针 } } ftruncate(fd, size-s); // 截断文件,删除指定行 close(fd); // 关闭文件描述符 return 0; // 正常退出 }(3) 通过 fopen 打开文件,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,如atoi和exit #include <string.h> // 包含字符串处理函数,如strlen #include <math.h> // 包含数学函数,虽然在这个程序中没有使用 #include <unistd.h> // 包含UNIX标准函数,如truncate int main(int argc, char *argv[]) { // 检查命令行参数个数是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出程序 } int linenum = atoi(argv[2]); // 将命令行中指定的行号转换为整数 char buf[4096]; // 定义缓冲区,用于读取文件内容 // 尝试以读写模式打开文件 FILE *fp = fopen(argv[1], "r+"); // 如果文件无法打开,打印错误信息并退出程序 if (!fp) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); } int total_line = 0; // 记录文件的总行数 int size = 0; // 记录文件的总大小 // 循环读取文件直到文件末尾,计算总行数和总大小 while (fgets(buf, sizeof(buf), fp)) { size += strlen(buf); // 累加每行的长度 total_line++; // 行数加1 } // 如果要删除的行数大于文件的总行数,打印错误信息并退出程序 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 记录要删除的行的大小 int t = 0; // 记录当前读取行的大小 int i = 0; // 记录当前行数 fseek(fp, 0L, SEEK_SET); // 将文件指针重置到文件开头 // 再次循环读取文件,准备删除指定行 while (fgets(buf, sizeof(buf), fp)) { i++; // 当前行数加1 t = strlen(buf); // 当前行的长度 // 如果当前行是要删除的行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在要删除的行之后,将其前移 if (i > linenum) { fseek(fp, -(s+t), SEEK_CUR); // 将文件指针移动到正确的位置 fputs(buf, fp); // 写入当前行 fseek(fp, s, SEEK_CUR); // 将文件指针向前移动s个字节 } } // 截断文件,删除指定行 truncate(argv[1], size-s); // 关闭文件指针 fclose(fp); return 0; // 正常退出程序 }(4) 这三个删除文件指定行的函数都需借助临时文件完成
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
443
1
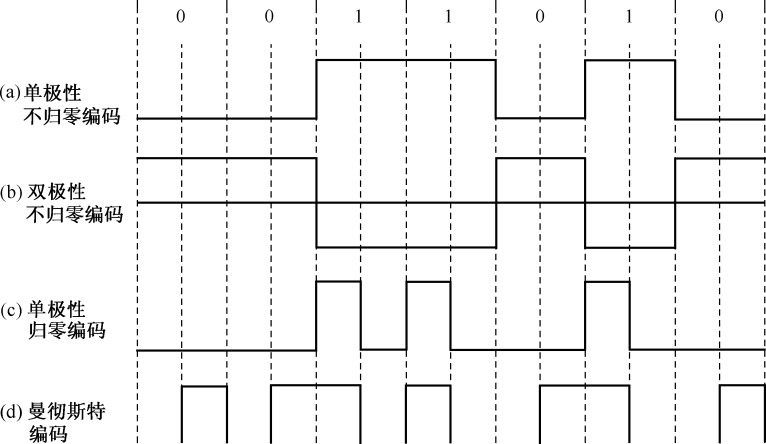
RFID编码简介
信号编码系统包括信源编码和信道编码两大类,器作用是把要传输的信息尽可能的与传输信道相匹配,并提供对信息的某种保护以防止信息受到干扰。信源编码与信源译码的目的是提高信息传输的有效性以及完成模数转换等;信道编码与信道译码的目的是增强信号的抗干扰能力,提高传输的可靠性。 常见的编码方法如下图: 图片 RFID系统常用编码方法: 反向不归零(NRZ)编码 曼彻斯特(Manchester)编码 单极性归零(RZ)编码 差动双相(DBP)编码 密勒(Miller)编码和差动编码 图片 1、反向不归零编码(NRZ,Non Return Zero) 反向不归零编码用高电平表示二进制“1”,低电平表示二进制“0”,如下图所示: 图片 此码型不宜传输,有以下原因 有直流,一般信道难于传输零频附近的频率分量; 接收端判决门限与信号功率有关,不方便使用; 不能直接用来提取位同步信号,因为NRZ中不含有位同步信号频率成分; 要求传输线有一根接地。 注:ISO14443 TYPE B协议中电子标签和阅读器传递数据时均采用NRZ 2、曼彻斯特编码(Manchester) 曼彻斯特编码也被称为分相编码(Split-Phase Coding)。 某比特位的值是由该比特长度内半个比特周期时电平的变化(上升或下降)来表示的,在半个比特周期时的负跳变表示二进制“1”,半个比特周期时的正跳变表示二进制“0”,如下图所示: 图片 曼彻斯特编码的特点 曼彻斯特编码在采用负载波的负载调制或者反向散射调制时,通常用于从电子标签到读写器的数据传输,因为这有利于发现数据传输的错误。这是因为在比特长度内,“没有变化”的状态是不允许的。 当多个标签同时发送的数据位有不同值时,则接收的上升边和下降边互相抵消,导致在整个比特长度内是不间断的负载波信号,由于该状态不允许,所以读写器利用该错误就可以判定碰撞发生的具体位置。 曼彻斯特编码由于跳变都发生在每一个码元中间,接收端可以方便地利用它作为同步时钟。 注: ISO14443 TYPE A协议中电子标签向阅读器传递数据时采用曼彻斯特编码。 ISO18000-6 TYPE B 读写器向电子标签传递数据时采用的是曼彻斯特编码 3、单极性归零编码(Unipolar RZ) 当发码1时发出正电流,但正电流持续的时间短于一个码元的时间宽度,即发出一个窄脉冲 当发码0时,完全不发送电流 单极性归零编码可用来提取位同步信号。 pPbm28I.png图片 4、差动双相编码(DBP) 差动双相编码在半个比特周期中的任意的边沿表示二进制“0”,而没有边沿就是二进制“1”,如下图所示。此外在每个比特周期开始时,电平都要反相。因此,对于接收器来说,位节拍比较容易重建。 pPbmR2t.png图片 5、密勒编码(Miller) 密勒编码在半个比特周期内的任意边沿表示二进制“1”,而经过下一个比特周期中不变的电平表示二进制“0”。一连串的比特周期开始时产生电平交变,如下图所示,因此,对于接收器来说,位节拍也比较容易重建。 pPbmhKf.png图片 pPbm5qS.png图片 6、修正密勒码编码 7、脉冲-间歇编码 对于脉冲—间歇编码来说,在下一脉冲前的暂停持续时间t表示二进制“1”,而下一脉冲前的暂停持续时间2t则表示二进制“0”,如下图所示。 pPbnUoQ.png图片 这种编码方法在电感耦合的射频系统中用于从读写器到电子标签的数据传输,由于脉冲转换时间很短,所以就可以在数据传输过程中保证从读写器的高频场中连续给射频标签供给能量。 8、脉冲位置编码(PPM,Pulse Position Modulation) 脉冲位置编码与上述的脉冲间歇编码类似,不同的是,在脉冲位置编码中,每个数据比特的宽度是一致的。 其中,脉冲在第一个时间段表示“00”,第二个时间段表示“01”, 第三个时间段表示“10”, 第四个时间段表示“11”, 如图所示 pPbnwJs.png图片 注:ISO15693协议中,数据编码采用PPM 9、FM0编码 FM0(即Bi-Phase Space)编码的全称为双相间隔码编码、 工作原理是在一个位窗内采用电平变化来表示逻辑。如果电平从位窗的起始处翻转,则表示逻辑“1”。如果电平除了在位窗的起始处翻转,还在位窗中间翻转则表示逻辑“0”。 pPbn0Wn.png图片 注:ISO18000-6 typeA 由标签向阅读器的数据发送采用FM0编码 10、PIE编码 PIE(Pulse interval encoding)编码的全称为脉冲宽度编码,原理是通过定义脉冲下降沿之间的不同时间宽度来表示数据。 在该标准的规定中,由阅读器发往标签的数据帧由SOF(帧开始信号)、EOF(帧结束信号)、数据0和1组成。在标准中定义了一个名称为“Tari”的时间间隔,也称为基准时间间隔,该时间段为相邻两个脉冲下降沿的时间宽度,持续为25μs。 pPbnBzq.png图片 注:ISO18000-6 typeA 由阅读器向标签的数据发送采用PIE编码 ============================================= 注:选择编码方法的考虑因素 编码方式的选择要考虑电子标签能量的来源 在REID系统中使用的电子标签常常是无源的,而无源标签需要在读写器的通信过程中获得自身的能量供应。为了保证系统的正常工作,信道编码方式必须保证不能中断读写器对电子标签的能量供应。 在RFID系统中,当电子标签是无源标签时,经常要求基带编码在每两个相邻数据位元间具有跳变的特点,这种相邻数据间有跳变的码,不仅可以保证在连续出现“0”时对电子标签的能量供应,而且便于电子标签从接收到的码中提取时钟信息。 编码方式的选择要考虑电子标签的检错的能力 出于保障系统可靠工作的需要,还必须在编码中提供数据一级的校验保护,编码方式应该提供这种功能。可以根据码型的变化来判断是否发生误码或有电子标签冲突发生。 在实际的数据传输中,由于信道中干扰的存在,数据必然会在传输过程中发生错误,这时要求信道编码能够提供一定程度的检测错误的能力。 曼彻斯特编码、差动双向编码、单极性归零编码具有较强的编码检错能力。 编码方式的选择要考虑电子标签时钟的提取 在电子标签芯片中,一般不会有时钟电路,电子标签芯片一般需要在读写器发来的码流中提取时钟。 曼彻斯特编码、密勒编码、差动双向编码容易使电子标签提取时钟。
通信&信息处理
# 通信&射频
# 软件算法
刘航宇
3年前
0
2,553
0
2023-07-23
Python机器学习- 鸢尾花分类
1、描述 2、code 3、描述 4、code 1、描述 请编写代码实现train_and_predict功能,实现能够根据四个特征对三种类型的鸢尾花进行分类。 train_and_predict函数接收三个参数: train_input_features—二维NumPy数组,其中每个元素都是一个数组,它包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 train_outputs—一维NumPy数组,其中每个元素都是一个数字,表示在train_input_features的同一行中描述的鸢尾花种类。0表示鸢尾setosa,1表示versicolor,2代表Iris virginica。 prediction_features—二维NumPy数组,其中每个元素都是一个数组,包含:萼片长度、萼片宽度、花瓣长度和花瓣宽度。 该函数使用train_input_features作为输入数据,使用train_outputs作为预期结果来训练分类器。请使用训练过的分类器来预测prediction_features的标签,并将它们作为可迭代对象返回(如list或numpy.ndarray)。结果中的第n个位置是prediction_features参数的第n行。 2、code # 导入numpy库,用于处理多维数组 import numpy as np # 导入sklearn库中的数据集、模型选择、度量和朴素贝叶斯模块 from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.naive_bayes import GaussianNB # 定义train_and_predict函数,接收三个参数:训练输入特征、训练输出标签和预测输入特征 def train_and_predict(train_input_features, train_outputs, prediction_features): # 创建一个高斯朴素贝叶斯分类器对象 clf = GaussianNB() # 使用训练输入特征和训练输出标签来训练分类器 clf.fit(train_input_features, train_outputs) # 使用预测输入特征来预测输出标签,并将结果返回 y_pred = clf.predict(prediction_features) return y_pred # 加载鸢尾花数据集,包含150个样本,每个样本有四个特征和一个标签 iris = datasets.load_iris() # 将数据集随机分成训练集和测试集,其中训练集占70%,测试集占30%,并设置随机种子为0 X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3, random_state=0 ) # 调用train_and_predict函数,使用训练集来训练分类器,并使用测试集来预测标签,将结果赋值给y_pred y_pred = train_and_predict(X_train, y_train, X_test) # 如果y_pred不为空,打印预测标签和真实标签的准确率,即正确预测的比例 if y_pred is not None: print(metrics.accuracy_score(y_test, y_pred))3、描述 机器学习库 sklearn 自带鸢尾花分类数据集,分为四个特征和三个类别,其中这三个类别在数据集中分别表示为 0, 1 和 2,请实现 transform_three2two_cate 函数的功能,该函数是一个无参函数,要求将数据集中 label 为 2 的数据进行移除,也就是说仅保留 label 为 0 和为 1 的情况,并且对 label 为 0 和 1 的特征数据进行保留,返回值为 numpy.ndarray 格式的训练特征数据和 label 数据,分别为命名为 new_feat 和 new_label。 然后在此基础上,实现 train_and_evaluate 功能,并使用生成的 new_feat 和 new_label 数据集进行二分类训练,限定机器学习分类器只能从逻辑回归和决策树中进行选择,将训练数据和测试数据按照 8:2 的比例进行分割。 要求输出测试集上的 accuracy_score,同时要求 accuracy_score 要不小于 0.95。 4、code #导入numpy库,它是一个提供了多维数组和矩阵运算等功能的Python库 import numpy as np #导入sklearn库中的datasets模块,它提供了一些内置的数据集 from sklearn import datasets #导入sklearn库中的model_selection模块,它提供了一些用于模型选择和评估的工具,比如划分训练集和测试集 from sklearn.model_selection import train_test_split #导入sklearn库中的preprocessing模块,它提供了一些用于数据预处理的工具,比如归一化 from sklearn.preprocessing import MinMaxScaler #导入sklearn库中的linear_model模块,它提供了一些线性模型,比如逻辑回归 from sklearn.linear_model import LogisticRegression #导入sklearn库中的metrics模块,它提供了一些用于评估模型性能的指标,比如F1分数、ROC曲线面积、准确率等 from sklearn.metrics import f1_score,roc_auc_score,accuracy_score #导入sklearn库中的tree模块,它提供了一些树形模型,比如决策树 from sklearn.tree import DecisionTreeClassifier #定义一个函数transform_three2two_cate,它的作用是将鸢尾花数据集中的三分类问题转化为二分类问题 def transform_three2two_cate(): #从datasets模块中加载鸢尾花数据集,并赋值给data变量 data = datasets.load_iris() #其中data特征数据的key为data,标签数据的key为target #需要取出原来的特征数据和标签数据,移除标签为2的label和特征数据,返回值new_feat为numpy.ndarray格式特征数据,new_label为对应的numpy.ndarray格式label数据 #需要注意特征和标签的顺序一致性,否则数据集将混乱 #code start here #使用numpy库中的where函数找出标签为2的索引,并赋值给index_arr变量 index_arr = np.where(data.target == 2)[0] #使用numpy库中的delete函数删除特征数据中对应索引的行,并赋值给new_feat变量 new_feat = np.delete(data.data, index_arr, 0) #使用numpy库中的delete函数删除标签数据中对应索引的元素,并赋值给new_label变量 new_label = np.delete(data.target, index_arr) #code end here #返回新的特征数据和标签数据 return new_feat,new_label #定义一个函数train_and_evaluate,它的作用是用决策树分类器来训练和评估鸢尾花数据集 def train_and_evaluate(): #调用transform_three2two_cate函数,得到新的特征数据和标签数据,并赋值给data_X和data_Y变量 data_X,data_Y = transform_three2two_cate() #使用train_test_split函数,将数据集划分为训练集和测试集,其中测试集占20%,并赋值给train_x,test_x,train_y,test_y变量 train_x,test_x,train_y,test_y = train_test_split(data_X,data_Y,test_size = 0.2) #已经划分好训练集和测试集,接下来请实现对数据的训练 #code start here #创建一个决策树分类器的实例,并赋值给estimator变量 estimator = DecisionTreeClassifier() #使用fit方法,用训练集的特征和标签来训练决策树分类器 estimator.fit(train_x, train_y) #使用predict方法,用测试集的特征来预测标签,并赋值给y_predict变量 y_predict = estimator.predict(test_x) #code end here #注意模型预测的label需要定义为 y_predict,格式为list或numpy.ndarray #使用accuracy_score函数,计算测试集上的准确率分数,并打印出来 print(accuracy_score(y_predict,test_y)) #如果这个文件是作为主程序运行,则执行以下代码 if __name__ == "__main__": #调用train_and_evaluate函数 train_and_evaluate() #要求执行train_and_evaluate()后输出为: #1、{0,1},代表数据label为0和1 #2、测试集上的准确率分数,要求>0.95
机器学习
# 机器学习
# Python
刘航宇
3年前
0
561
0
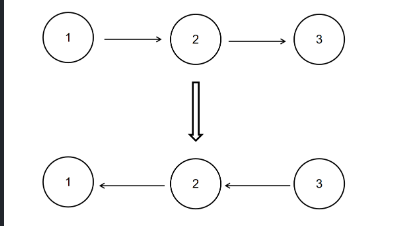
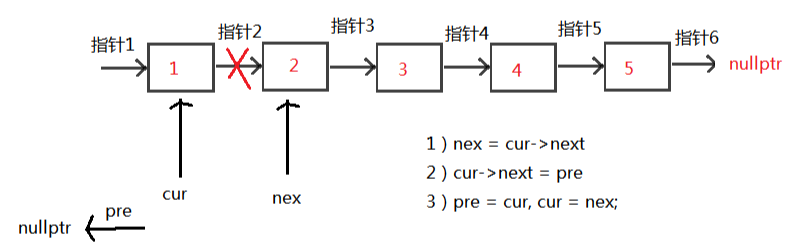
算法-反转链表C&Python实现
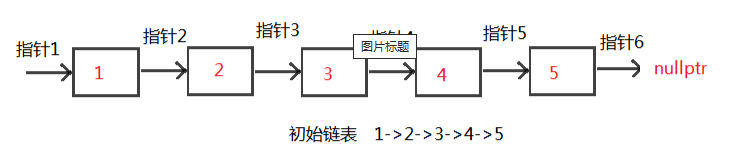
描述 基础数据结构知识回顾 题解C++篇 题解Python篇 描述 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 数据范围: 0≤n≤1000 要求:空间复杂度 O(1) ,时间复杂度 O(n) 。 如当输入链表{1,2,3}时, 经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。 以上转换过程如下图所示: pCqibqO.png图片 基础数据结构知识回顾 空间复杂度 O (1) 表示算法执行所需要的临时空间不随着某个变量 n 的大小而变化,即此算法空间复杂度为一个常量,可表示为 O (1)。例如,下面的代码中,变量 i、j、m 所分配的空间都不随着 n 的变化而变化,因此它的空间复杂度是 O (1)。 int i = 1; int j = 2; ++i; j++; int m = i + j;时间复杂度 O (n) 表示算法执行的时间与 n 成正比,即此算法时间复杂度为线性阶,可表示为 O (n)。例如,下面的代码中,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。 for (i=1; i<=n; ++i) { j = i; j++; }题解C++篇 可以先用一个vector将单链表的指针都存起来,然后再构造链表。 此方法简单易懂,代码好些。 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 如果头节点指针为空,直接返回空指针 if (!pHead) return nullptr; // 定义一个vector,用于存储链表中的每个节点指针 vector<ListNode*> v; // 遍历链表,将每个节点指针放入vector中 while (pHead) { v.push_back(pHead); pHead = pHead->next; } // 反转vector,也可以逆向遍历 reverse(v.begin(), v.end()); // 取出vector中的第一个元素,作为反转后的链表的头节点指针 ListNode *head = v[0]; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = head; // 从第二个元素开始遍历vector,构造反转后的链表 for (int i=1; i<v.size(); ++i) { // 当前节点的下一个指针指向下一个节点 cur->next = v[i]; // 当前节点后移 cur = cur->next; } // 切记最后一个节点的下一个指针指向nullptr cur->next = nullptr; // 返回反转后的链表的头节点指针 return head; } };初始化:3个指针 1)pre指针指向已经反转好的链表的最后一个节点,最开始没有反转,所以指向nullptr 2)cur指针指向待反转链表的第一个节点,最开始第一个节点待反转,所以指向head 3)nex指针指向待反转链表的第二个节点,目的是保存链表,因为cur改变指向后,后面的链表则失效了,所以需要保存 接下来,循环执行以下三个操作 1)nex = cur->next, 保存作用 2)cur->next = pre 未反转链表的第一个节点的下个指针指向已反转链表的最后一个节点 3)pre = cur, cur = nex; 指针后移,操作下一个未反转链表的第一个节点 循环条件,当然是cur != nullptr 循环结束后,cur当然为nullptr,所以返回pre,即为反转后的头结点 这里以1->2->3->4->5 举例: pCqAcsP.png图片 pCqAgqf.png图片 pCqAWdS.png图片 pCqA4iQ.png图片 pCqAIRs.png图片 // 定义一个Solution类 class Solution { public: // 定义一个函数,接收一个链表的头节点指针,返回一个反转后的链表的头节点指针 ListNode* ReverseList(ListNode* pHead) { // 定义一个前驱节点指针,初始化为nullptr ListNode *pre = nullptr; // 定义一个当前节点指针,初始化为头节点指针 ListNode *cur = pHead; // 定义一个后继节点指针,初始化为nullptr ListNode *nex = nullptr; // 遍历链表,反转每个节点的指向 while (cur) { // 记录当前节点的下一个节点 nex = cur->next; // 将当前节点的下一个指针指向前驱节点 cur->next = pre; // 将前驱节点更新为当前节点 pre = cur; // 将当前节点更新为后继节点 cur = nex; } // 返回反转后的链表的头节点指针,即原链表的尾节点指针 return pre; } };题解Python篇 假设 链表为 1->2->3->4->null 空就是链表的尾 obj: 4->3->2->1->null 那么逻辑是 首先设定待反转链表的尾 pre = none head 代表一个动态的表头 逐步取下一次链表的值 然后利用temp保存 head.next 第一次迭代head为1 temp 为2 原始链表中是1->2 现在我们需要翻转 即 令head.next = pre 实现 1->none 但此时链表切断了 变成了 1->none 2->3->4 所以我们要移动指针,另pre = head 也就是pre从none 变成1 下一次即可完成2->1的链接 此外另head = next 也就是说 把指针移动到后面仍然链接的链表上 这样执行下一次循环 则实现 把2->3 转变为 2->1->none 然后再次迭代 直到最后一次 head 变成了none 而pre变成了4 则pre是新的链表的表头 完成翻转 # -*- coding:utf-8 -*- # 定义一个ListNode类,表示链表中的节点 # class ListNode: # def __init__(self, x): # self.val = x # 节点的值 # self.next = None # 节点的下一个指针 # 定义一个Solution类,用于解决问题 class Solution: # 定义一个函数,接收一个链表的头节点,返回一个反转后的链表的头节点 def ReverseList(self, pHead): # write code here pre = None # 定义一个前驱节点,初始化为None head = pHead # 定义一个当前节点,初始化为头节点 while head: # 遍历链表,反转每个节点的指向 temp = head.next # 记录当前节点的下一个节点 head.next = pre # 将当前节点的下一个指针指向前驱节点 pre = head # 将前驱节点更新为当前节点 head = temp # 将当前节点更新为下一个节点 return pre # 返回反转后的链表的头节点,即原链表的尾节点
编程&脚本笔记
软硬件算法
# 软件算法
# C/C++
# Python
刘航宇
3年前
0
367
1
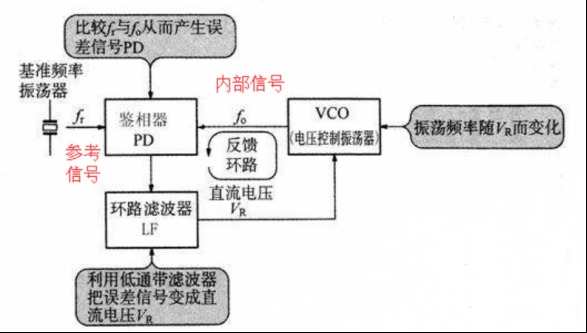
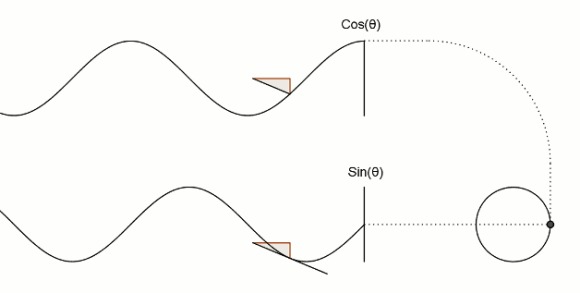
数字锁相环(DPLL)研究与设计
前言 工程代码下载 锁相环的原理和组成 数字锁相环的原理和组成 数字鉴相器设计DPD 数字振荡器(DCO) 数字缓冲器(DB) 数字锁相环(DPLL)的实现 电路硬件与性能评估 前言 随着数字电路技术的发展,数字锁相环在调制解调、频率合成、FM 立体声解码、彩色副载波同步、图象处理等各个方面得到了广泛的应用。数字锁相环不仅吸收了数字电路可靠性高、体积小、价格低等优点,还解决了模拟锁相环的直流零点漂移、器件饱和及易受电源和环境温度变化等缺点,此外还具有对离散样值的实时处理能力,已成为锁相技术发展的方向。 所谓数字PLL,就是指应用于数字系统的PLL,也就是说数字PLL中的各个模块都是以数字器件来实现的,是一个数字的电路。 数字锁相环的优点是电路最简单有效,可采用没有压控的晶振,降低了成本,提高了晶振的稳定性。但缺点是和模拟锁相环一样,一旦失去基准频率,输出频率立刻跳回振荡器本身的频率;另外还有一个缺点,就是当进行频率调整的时候,输出频率会产生抖动,频差越大,抖动会越大于密,不利于某些场合的应用。随着大规模、超高速的数字集成电路的发展,为数字锁相环路的研究与应用提供了广阔空间。由于晶体振荡器和数字调整技术的加盟,可以在不降低振荡器的频率稳定度的情况下,加大频率的跟踪范围,从而提高整个环路工作的稳定性与可靠性。 简单的说有两个不同来源的信号:一个信号是参考信号,这个信号一般是由芯片的晶振得到的信号,它具有信号的稳定性较好等优点,但是其频率是固定不变的。另一个信号是由芯片或者模块内部的压控振荡器得到的。这种由压控振荡器得到的信号可以是某范围内的任意频率的信号,但是这种信号的稳定型较差,容易受到外界干扰。 那么在实际使用过程中,我们需要一种频率能够变化的,同时质量较好的信号;或者对于一块芯片,我们需要不同的模块的内部时钟(这种时钟可以是压控振荡器产生)都能参考一个总的时钟来进行同步,从而避免两个模块内部时钟的差异而产生的数据传输的漂移等问题。因此,如何将压控振荡器得到的信号能够具有晶振信号的信号质量呢? 那就是通过PLL锁相环来实现,如图1所示。只要压控振荡器产生的时钟(下称输入信号)是参考信号的整数倍(或者整除倍),那么就能将输入信号先进行分频,后得到与参考信号频率相同的时钟,将分频后的信号和参考信号进行比较,从而使分频后的信号和参考信号保持相同的稳定的频率和相位。被分频后的信号稳定,也就是间接的表示输入信号的稳定。从而我们得到了一个频率在一定范围内可变的稳定的信号。 有上述可以看出,锁相环具有以下功能: (1)能够将一个信号和另一参考信号同步; (2)当这个信号是输出信号分频后得到的信号,PLL就能够得到参考信号的倍频信号(实际上倍频器很多都是利用了这个功能); (3)当输入信号频率可变、分频系数可变时,PLL就能够得到在频率一定范围内稳定信号。 图片 工程代码下载 DPLL 下载地址:https://wwek.lanzoub.com/iJLd5102ig6j 提取码: 锁相环的原理和组成 锁相环(PLL)的作用我们已经大概了解了,其最主要功能的实现,是在于如何将两个频率不同、相位差始终在变化的信号,变成两个相同频率、相同相位的信号。 这里引入一个概念,首先我们都知道,对于三角函数,只有两个同频率的三角函数才能比较其相位差。但这里的相位差是指两个正弦函数的初始相位差。而实际上根据三角函数的欧拉定义的理解来看,我们可以把三角函数看做是在某个圆上逆时针运动的点到x轴的距离。那么频率就是点在圆上运动的角速度,频率越大,其运动的角速度越大。相位就是点在圆上的位置,而初始相位就是点在圆上开始运动时的位置。当两个点的运动角速度相同时,我们可以得到两个点的初始位置差,就是两个正弦函数频率相同时,得到初始相位差。这个差值在运动过程中一直是不变的。但是当两个点运动角速度不同时,我们去看它的初始位置差是没有意义的,因为两个点的位置差是一直在变的,而初始位置差只是一个开始的位置差,是个不变的量,所以说对于频率不同的三角函数,我们讨论起初始相位差是没有意义的。但是不代表不能比较某一时刻两个点的位置。也就是相位差,相位是存在的。 图片 现在我们假设两个点在圆上赛跑,如图3所示,我们想让这两个点角速度相等。那么有一个办法就是以一个点为参考,参考点角速度不变,另一个点是速度可变点。每过一段时间,观察另一个点到参考点的位置,是在前,还是在后。如果在前,就让另一个点速度慢一点;如果在后,就让另一个点速度快一点。就这样不断调整另一个点的角速度,直到每次观察两个点都处于相同的位置。这样我们就可以认为这两个点达到了相同的速度。这种方法就是利用反馈调节来实现两个信号的同频同相。也就是锁相环(PLL)的实现原理。 首先通过一个鉴相器来得到两个信号之间的相位差。并根据相位差输出电压信号。然后通过滤波器稳压后得到稳定的电压信号,该信号驱动压控振荡器得到新的频率的信号。当两个信号存在相位差时,电压信号就会改变,从而使受控信号不断变化。直到当两个信号没有相位差时,电压信号不再改变,从而使受控信号保持当前频率,这时,受控信号不再变化了,就叫做受控信号被锁定了。 由上所述,一个锁相环由鉴相器、滤波器、振荡器三部分组成。外部输入是参考信号,内部输入和总的输出是受控信号。 数字锁相环的原理和组成 在数字电路中,原来模拟信号正弦波、余弦波的频率和相位变成了0和1的脉冲信号,那么我们如何理解数字信号中的频率和相位呢?对于脉冲信号来说,我们可以把频率理解为在某固定时间内脉冲出现的个数,为了方便表示,我们把上升沿的出现视为脉冲的出现,把相邻两个脉冲出现的时间t求倒数,就得到了该信号在这个时刻处的信号频率。而对于相位,相位差就是指,存在两个脉冲信号,以一个脉冲信号为参考,在其出现脉冲后,到另一个信号出现脉冲之间的时间差就是相位差,当另一个信号脉冲晚于参考信号脉冲出现的时间,称之为另一个信号的相位滞后于参考信号。当另一个信号的脉冲出现在参考信号之前,称之为另一个信号的相位提前于参考信号。 上述是一种较为简单的描述方式,适合初识脉冲信号的读者理解。而实际上,对于脉冲信号的频率、相位等问题,严格来说这样理解有一点点问题,但是对于我们来搭建数字锁相环DPLL来说足够了。其实这种三角函数和信号之间的转化,其根本的原理来源于傅里叶变换,从而我们对一个时间域上的信号(例如脉冲信号)可以进行频率域(其代表的三角函数的合成)上的分析。 我们知道了在数字电路中,脉冲信号也有了频率和相位的属性。那么我们的参考信号是以来时钟源的固定频率的信号,因为信号的质量比较好,所以该信号两个脉冲之间的时间差均是相同的,误差很小。我们在参考信号出现上升沿时,观察受控信号此时的状态。如果受控信号为高电平,我们就认为此时受控信号超前于参考信号;反之,如果受控信号是低电平,则认为此时的受控信号滞后于参考信号。当出现超前状态时,鉴相器会输出一个超前信号,超前信号会作用于振荡器,使得振荡器发出的受控信号频率降低。而滞后信号会使振荡器发出的受控信号频率升高,从而实现受控信号频率的反馈调节。 如图4所示,当参考信号出现上升沿时,受控信号为低电平,此时输出一个滞后信号。(由于模块只在时钟为上升沿时触发,所以超前信号的触发延迟了半个时钟周期) 图片 由此我们能够大概了解了数字锁相环中如何看待脉冲信号的频率和相位,如何处理得到相位差以及相位差如何在锁相环中起作用来实现信号频率的反馈控制。同模拟的锁相环(PLL)类似,数字锁相环(DPLL)也是由:数字鉴相器(Digital Phase Detector)、数字缓冲器(Digital Buffer)、数字振荡器(Digital Controlled Oscillator)三个模块构成,其外部输入为参考信号,内部输入和输出为受控信号。下面我们就来具体讨论如何用verilog实现各个模块。 数字鉴相器设计DPD 实现一个数字锁相环(DPLL),最重要的部分就是实现数字鉴相器(DPD)和数字振荡器(DF)。并且,这两个模块并不是独立存在的,而是说,数字振荡器的实现方式和数字振荡器的实现方式相互影响。所以只有两个模块共同设计,才能较好的实现一个数字锁相环的功能。 首先我们来具体讨论一下一个数字鉴相器应该具有那些功能和特性: 顾名思义,数字鉴相器就是能够鉴别两个数字信号相位的差别,并通过信号将这种差别表示出来。由上文我们已经知道了,对于两个矩形方波信号,其相位差可以看做是两个信号先后出现上升沿(或下降沿)之间的时间差。为了方便表示,假设以其中一个信号作为参考信号,另一个信号为受控信号,当参考信号出现上升沿(或下降沿)时,观察另一个信号是否已经出现了上升沿(或下降沿)。 如果还未出现上升沿(或下降沿),则叫做“受控信号滞后于参考信号”,或者简称“滞后”;如果已经出现了上升沿(或下降沿),则叫做“受控信号提前于参考信号”,或者简称“提前”。 而判断上升沿(或下降沿)是否已经出现,方法就是看当参考信号出现上升沿时,受控信号是1还是0:当受控信号为0,表示上升沿还没出现,所以是“滞后”;当受控信号为1,表示上升沿已经出现,所以是“提前”。对于下降沿也是按照同样的方法考虑。 图片 目前为止,我们已经有两个输入,参考信号和受控信号;两个输出,滞后信号和提前信号。如何通过verilog实现上述的输入输出关系呢?首先先讲异或与门,通过图4的描述,我们可以很容易看出来:滞后信号是参考信号与受控信号先异或,异或的结果和受控信号相与得到;提前信号是参考信号与受控信号先异或,异或的结果和参考信号相与得到。再加上一个RST的复位信号,我们可以得到如下图5电路: 图片 根据这个关系,来调节受控信号的频率,从而使受控信号的频率和参考信号最终相同。 再考虑,如果按照上述方法调节,当受控信号和参考信号频率相差很大时,就会出现刚开始有一段时间,受控信号的频率是不断变化,不可预知的。这样的调节效果实时性并不好,需要时间来稳定。因此读者想到,如果能够在参考信号出现上升沿时,就让受控信号也出现上升沿,相当于两个人在赛跑时,当一个人从起点出发时,无论另一个人在哪,强制让另一个人也回到原点,两个人一起从原点出发。这样就能使受控信号和参考信号强制达到相同的频率,只是此时受控信号的占空比不是50%。然后再根据滞后和提前信号,调节受控信号的占空比,从而最终达到50%的占空比。 按照这种方法,鉴相器就需要一个信号输出来表示上升沿的出现。再考虑到电路中的总的时钟源,我们这里采用触发的方法来实现。同时将上述的异或与门加入到代码中可以得到数字鉴相器的代码。但是在实际运用过程中发现,可能存在着受控信号先出现上升沿,从而过早的出现了提前或者滞后信号,导致数字振荡器的计数器上限呈现一个周期变化的不可控的数值的情况。为了避免这种情况,需要仔细考虑参考信号和受控信号如何生成提前和滞后信号这个问题,而不是简单的用异或来实现。如图6表示这种关系。 图片 按照上述代码写出来的数字鉴相器,具有更好的性能。根据这个表格,通过类似状态机的方法,来实现提前信号和滞后信号的输出。 数字振荡器(DCO) 现在我们已经构造出来了一个数字鉴相器,接下来我们将继续探讨如何实现一个数字振荡器(DCO)。 实现一个固定脉冲频率的信号,我们可以通过已知的时钟源,分频得到一定频率范围内的脉冲。具体实现方法就是通过计数器的方式,当出现时钟脉冲时,计数器+1,计数器上限就是分频系数,当计数器的数小于上限的1/2时,输出1,当计数器的数大于上限的1/2时,输出0,当计数器的数超过上限时,计数器归零。这样就能实现对时钟源的分频。 根据上述方法,只要改变计数器的上下限,就能改变分频系数,从而改变输出信号的频率。再参考上文受控信号和滞后提前信号的关系,我们就能通过根据滞后提前信号,改变计数器上下限,来实现对受控信号频率的控制。当计数器上限增加时,分频系数增加,频率减小;当计数器上限减小时,分频系数减小,频率增加;因此有: 滞后信号——>受控信号的频率小——>增加受控信号的频率——>计数器上限减小 提前信号——>受控信号的频率大——>减小受控信号的频率——>计数器上限增加 此外根据上述对上升沿触发同步的说法,当出现上升沿触发信号时,受控信号应强制产生上升沿,即受控信号强制从该脉冲周期的开始处开始,即计数器的数回到0从新开始计数。 综上所述,再加上复位信号,一个数字振荡器的所有构成就有了。到这里,一个数字锁相环(DPLL)其实就已经能够实现了,因为数字滤波器(DB)只是让受控信号的抗干扰能力更强,如图所示是仿真后的结果: 图片 数字缓冲器(DB) 下面再介绍一下数字缓冲器,来使受控信号的抗干扰能力更强。前面我们知道了,持续一个时钟周期的提前信号或者滞后信号能够使数字振荡器的计数器上限加一或者减一。当我的预设的数字振荡器的计数器上限与实际的参考信号的频率对应的计数器上限两个数值相差很大时,就有可能出现锁相环调节时间过长等现象。为了解决这种情况,如果能够让原来持续一个周期的提前信号或滞后信号成倍数的增加,变成持续n个周期的提前信号或者滞后信号,就能够使数字振荡器的计数器上限修改更快,从而更快的到达参考频率附近。但是相应的,受控信号的频率精度就会降低。也就是说,牺牲精度,追求速度。 同时考虑另外一种情况,如果我对速度要求不高,但是对于精度要求较高,同时在信号传输过程中可能存在干扰,导致接收到的提前信号或滞后信号不是完全真实的信号,此时就可以通过一个累加器,只有接受到n个周期的提前信号,或者滞后信号,才对数字振荡器输出一个进位信号或者借位信号,此时数字振荡器的计数器上限才只加减1,这样就能有效的提高精度,减少信号干扰带来的影响。但是这种做法牺牲了数字锁相换锁定的时间。 综上所述,一个时钟周期的提前或滞后信号,对应n个时钟周期的借位或进位信号,是提高锁定速度,降低锁定精度。想法,n个时钟周期的提前或滞后信号,对应一个时钟周期的借位或进位信号,是提高锁定精度,降低锁定速度。因此在实际运用中,应该按照自己的工程需要,合理选择比值。 上述过程的实现方法,是通过一个计数器,当接收到一个提前或滞后信号时,计数器加a,当输出一个进位或借位信号时,计数器减b,调节a和b的比值,就能实现上述过程。 数字缓冲器的仿真效果: 1、分时效果 图片 2、倍时效果 图片 数字锁相环(DPLL)的实现 所有的子模块都已经实现了,剩下的数字锁相环的实现,根据实际的要求,将上述几个模块进行例化就行。例化后的测试结果如图9所示,可以看到受控信号逐渐与参考信号对齐达到锁相环效果。 图片 为了方便起见,对输出信号进行2分频,再次观察输出结果,输出相当于2倍频了,成功完成PD、DCO、Divider等模块正确设计。 图片 电路硬件与性能评估 图11为电路硬件图从图中可以看出各模块的连接关系,每个模块由基本门电路构成。通过性能优化后的的电路如图12所示。 图片 利用SMIC180nm工艺进行电路综合, 时序报告:周期2ns 图片 面积报告:2119um2 图片 功耗报告:uw级别 图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
1
3,938
3
2023-05-15
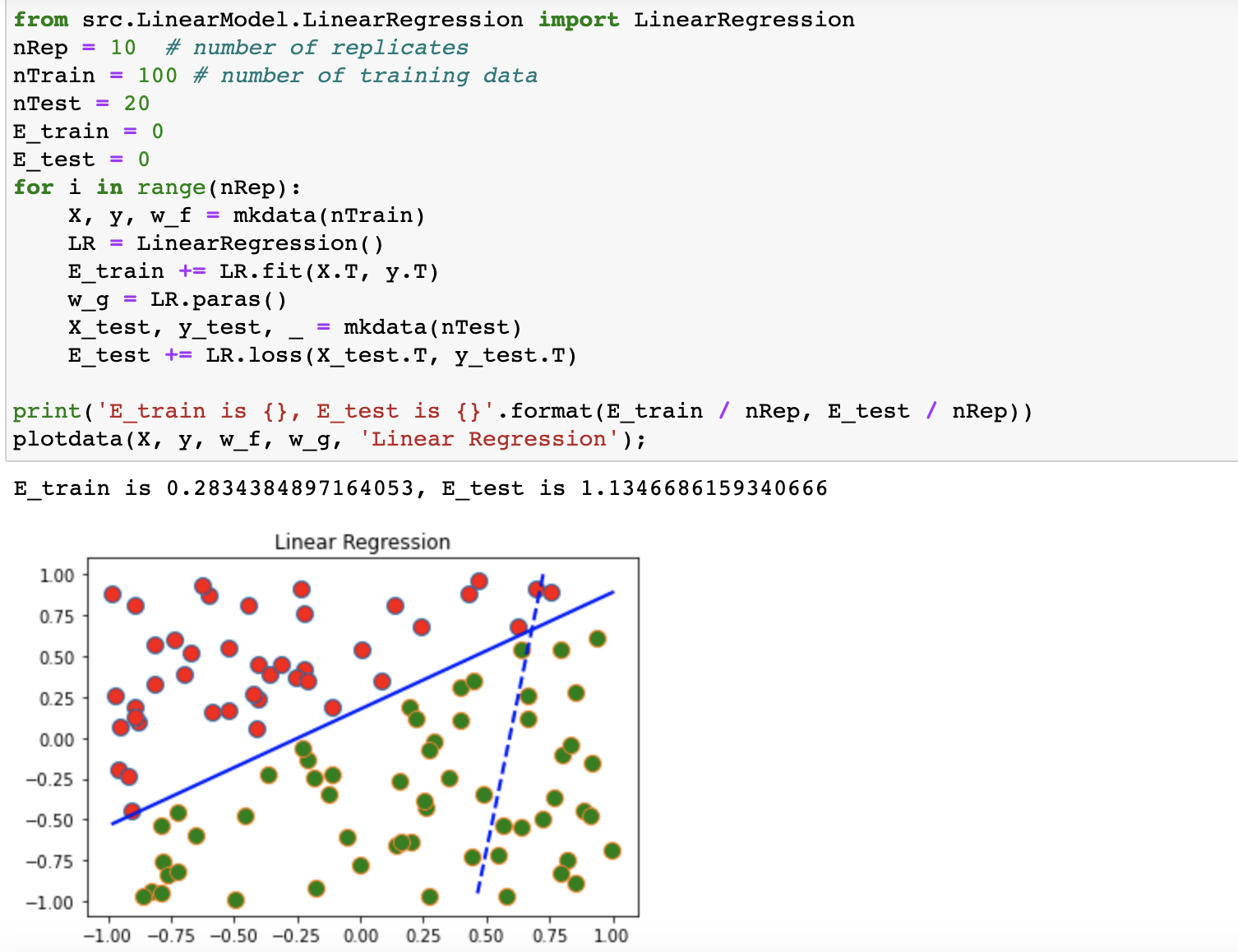
机器学习代码实现:线性回归与岭回归
1.线性回归模型 线性回归模型是最简单的一种线性模型,模型的形式就是: $y=W^T x+b$ 我们可以通过对原本的输入向量x扩增一个为1的维度将参数W和b统一成一个参数W,即模型变成了 $y=W^T x$ 这里的W是原本两个参数合并之后的而其损失函数的形式是残差平方损失RSS $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)$ 我们很容易就可以通过求导得到线性回归模型的关于W的梯度 $\nabla_W L=\frac{1}{m} \sum_{i=1}^m\left(W^T x_i-y_i\right) x_i=\frac{1}{m} X^T\left(W^T X-y\right)$ 这样一来我们就可以通过梯度下降的方式来训练参数W,可以用下面的公式表示 $W:=W-\alpha \frac{1}{m} X^T\left(W^T X-y\right)$ 但实际上线性模型的参数W可以直接求解出,即: $W=\left(X^T X\right)^{-1} X^T y$ 2.线性回归的编程实现 具体代码中的参数的形式可能和上面的公式推导略有区别,我们实现了一个LinearRegression的类,包含fit,predict和loss三个主要的方法,fit方法就是求解线性模型的过程,这里我们直接使用了正规方程来解 class LinearRegression: def fit(self, X: np.ndarray, y: np.ndarray) -> float: N, D = X.shape # 将每个样本的特征增加一个维度,用1表示,使得bias和weight可以一起计算 # 这里在输入的样本矩阵X末尾增加一列来给每个样本的特征向量增加一个维度 # 现在X变成了N*(D+1)维的矩阵了 expand_X = np.column_stack((X, np.ones((N, 1)))) self.w = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X)), expand_X.T), y) return self.loss(X, y)predict实际上就是将输入的矩阵X放到模型中进行计算得到对应的结果,loss给出了损失函数的计算方式: def loss(self, X: np.ndarray, y: np.ndarray): """ 线性回归模型使用的是RSS损失函数 :param X:需要预测的特征矩阵X,维度是N*D :param y:标签label :return: """ delta = y - self.predict(X) total_loss = np.sum(delta ** 2) / X.shape[0] return total_loss3.岭回归Ridge Regression与代码实现 岭回归实际上就是一种使用了正则项的线性回归模型,也就是在损失函数上加上了正则项来控制参数的规模,即: $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2+\lambda\|W\|_2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)+\lambda W^T W$ 因此最终的模型的正规方程就变成了: $W=\left(X^T X+\lambda I\right)^{-1} X^T y$ 这里的\lambda是待定的正则项参数,可以根据情况选定,岭回归模型训练的具体代码如下 class RidgeRegression: def fit(self, X: np.ndarray, y: np.ndarray): N, D = X.shape I = np.identity(D + 1) I[D][D] = 0 expand_X = np.column_stack((X, np.ones((N, 1)))) self.W = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X) + self.reg * I), expand_X.T), y) return self.loss(X, y)4.数据集实验 这里使用了随机生成的二位数据点来对线性模型进行测试,测试结果如下: image.png图片 线性模型测试结果 岭回归也使用同样的代码进行测试。
机器学习
软硬件算法
# 机器学习
# 软件算法
刘航宇
3年前
0
363
1
联发科2024年数字IC设计验证实习生考题解析
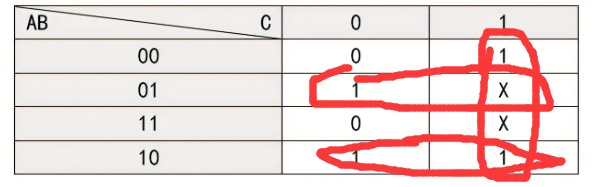
总体而言难度中等偏上,如有错误欢迎指正,考察感觉更像是考察嵌入式工程师(有STM32、FPGA基础就很轻松):有数电、模电、python、verilog、C语言、SOC系统等基础知识,可以看到其实很对口电子信息类专业如电子信息、微电子、通信工程、电子科学、集成电路等专业,没有考察模集如果考模集大部分人要G,数集也没考,可能太底层了与工业界需求有偏差,数集在笔试面试中我认为如果考,可能考时序与功耗部分。这里的Round-Robin算法很值得学习。 目录 1、(20分)逻辑化简: 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 3、(10分)智力题 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 1、(20分)逻辑化简: 图片 (1)列出真值表 (2)列出其卡诺图 (3)写出Z的最简表达式 答:卡诺图:卡诺图画完后勾1就完事了 提示:约束项的一般形式为:与或式 = 0 (如果不是此种形式,化为此种形式);如此题的BC = 0;或者AB +CD = 0;ABC + CD = 0;等等。BC=0(即B=1,且C=1)对应的格子画X。 图片 图片 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 答:ASIC flow 中综合工具的作用是将RTL级的硬件描述语言转换为与特定工艺库相匹配的门级网表,同时进行优化以满足时序、面积和功耗等约束。 综合的时候需要SDC文件进行约束,SDC文件是一种基于Tcl的格式,用于指定设计的时序约束34。SDC文件中的常用时序约束语法有: create_clock -name <clock_name> -period <clock_period> [get_ports <clock_port>] 用于创建时钟源并指定时钟周期。 set_input_delay -clock <clock_name> <delay_value> [get_ports <input_port>] 用于指定输入端口相对于时钟源的延迟。 set_output_delay -clock <clock_name> <delay_value> [get_ports <output_port>] 用于指定输出端口相对于时钟源的延迟。 set_clock_uncertainty -setup <setup_value> -hold <hold_value> <clock_name> 用于指定时钟源的不确定性,包括建立时间和保持时间。 set_false_path -from [get_ports <source_port>] -to [get_ports <destination_port>] 用于指定不需要进行时序分析的路径。 set_multicycle_path -setup -from [get_clocks <source_clock>] -to [get_clocks <destination_clock>] <cycle_number> 用于指定多周期路径,即源时钟和目标时钟之间有多个周期的时间差。3、(10分)智力题 (1)2 12 1112 3112 132112 ,下一个数?给理由; 答:第一个数是2,第二个数是12,表示前一个数有1个2;第三个数是1112,表示前一个数有1个1和1个2;以此类推。所以,下一个数是1113122112,表示前一个数有1个1,1个3,2个1和2个2 (2)有一个小偷费劲力气进入到了银行的金库里。在金库里他找到了一百个箱子,每一个箱子里都装满了金币。不过,只有一个箱子里装的是真的金币,剩下的99个箱子里都是假的。真假金币的外形和质感完全一样,任何人都无法通过肉眼分辨出来。它们只有一个区别:真金币每一个重量为101克,而假金币的重量是100克。在金库里有一个电子秤,它可以准确地测量出任何物品的重量,精确到克。但很不幸的是,这个电子秤和银行的报警系统相连接,只要被使用一次就会立刻失效。请问,小偷怎么做才能只使用一次电子秤就找到装着真金币的箱子呢? 答:小偷可以这样做:从第一个箱子里拿出1个金币,从第二个箱子里拿出2个金币,从第三个箱子里拿出3个金币,以此类推,直到从第一百个箱子里拿出100个金币。然后,把所有拿出来的金币放在电子秤上,测量它们的总重量。如果所有的金币都是假的,那么总重量应该是5050克(等于1+2+3+…+100)。如果有一个箱子里是真的金币,那么总重量会比5050克多出一些。这个多出来的部分就是真金币的数量乘以1克。例如,如果第十一个箱子里是真的金币,那么总重量会比5050克多出11克,因为从第十一个箱子里拿出了11个真金币。所以,小偷只要看电子秤上显示的数字减去5050,就能知道哪个箱子里是真的金币了。 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 答:优先答ASIC的设计与验证项目,其次是FPGA项目(如基于FPGA的图像处理、天线阵、雷达、加速器等等),其它项目不要答。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 # 定义冒泡排序函数 def bubble_sort(lst): # 获取列表长度 n = len(lst) # 遍历列表n-1次 for i in range(n-1): # 设置一个标志,用于判断是否发生交换 swapped = False # 遍历未排序的部分 for j in range(n-1-i): # 如果前一个元素大于后一个元素,交换位置 if lst[j] > lst[j+1]: lst[j], lst[j+1] = lst[j+1], lst[j] # 标志设为True,表示发生了交换 swapped = True # 如果没有发生交换,说明列表已经有序,提前结束循环 if not swapped: break # 返回排序后的列表 return lst # 定义测试程序 # 创建一个乱序的列表 lst = [5, 3, 8, 2, 9, 1, 4, 7, 6] # 打印原始列表 print("Original list:", lst) # 调用冒泡排序函数,对列表进行排序 lst = bubble_sort(lst) # 打印排序后的列表 print("Sorted list:", lst)结果图 image.png图片 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: input clock; input reset_b; input [N-1:0] request; input [N-1] lock; output [N-1] grant; //one-hot此处的 lock 输入信号,表示请求方收到了仲裁许可,在对应的lock拉低之前,仲裁器不可以开启新的仲裁。(可简单理解为仲裁器占用) 该题要求参数化编程,在模块例化时可调整参数。也即是说你不能写一个固定参数,比如N=8的模块。 参考波形图: image.png图片 答: Round-Robin算法:当有多个设备同时想占用同一个资源时,需要仲裁器通过某种调度算法决定不同设备使用资源的先后顺序。 Round Robin算法就是其中一种调度算法,其思路是,当多个仲裁请求(request)送给仲裁器时,仲裁器通过轮询的方式分时给不同的设备返回许可(grant),当一个requestor 得到了grant许可之后,它的优先级在接下来的仲裁中就变成了最低,当同时有多个requestor的时候,grant可以依次给到每个requestor,即使之前高优先级的requestor再次有新的request,也会等前面的requestor都grant之后再轮到它。由此看出,Round Robin算法是一种公平的算法,它避免了当最高优先级的requestor不断有新的request时,具有最高优先级的requestor一直占用资源,导致其他requestor无法占用资源的阻塞现象。 在verilog设计中,如何实现呢?假设request是位宽是6,最高位是第5位,最低位是第0位,默认低比特位具有高优先级。 1.首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1。 2.在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持,这个操作可以利用掩码111000和request相与实现得到。 得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 3.通过第二步得到第2位到第0位被屏蔽的request_new信号,判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位,则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 // 功能: // -1- Round Robin 仲裁器 // -2- 仲裁请求个数N可变 // -3- 加入lock机制(类似握手) // -4- 复位时的最高优先级定为 0 ,次优先级:1 -> 2 …… -> N-2 -> N-1 `timescale 1ns / 1ps module RoundRobinArbiter #( parameter N = 4 //仲裁请求个数 )( input clock, input reset_b, input [N-1:0] request, input [N-1:0] lock, output reg [N-1:0] grant//one-hot ); // 模块内部参数 localparam IDLE = 3'b001;// 复位进入空闲状态,接收并处理系统的初次仲裁请求 localparam WAIT_REQ_GRANT = 3'b010;// 等待后续仲裁请求到来,并进行仲裁 localparam WAIT_LOCK = 3'b100;// 等待LOCK拉低 // 模块内部信号 reg [2:0] R_STATUS; //请求状态 reg [N-1:0] R_MASK; //掩码 wire [N-1:0] W_REQ_MASKED; assign W_REQ_MASKED = request & R_MASK; //屏蔽低位 always @ (posedge clock) begin if(~reset_b) begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end else begin case(R_STATUS) IDLE: begin if(|request) //首次仲裁请求,不全为0 begin R_STATUS <= WAIT_LOCK; //首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。 //这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1 grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); //得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 end else begin R_STATUS <= IDLE; end end WAIT_REQ_GRANT://处理后续的仲裁请求 begin if(|request) begin R_STATUS <= WAIT_LOCK; //在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。 //因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持 //这个操作可以利用掩码111000和request相与实现得到。 if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end //通过第二步得到第2位到第0位被屏蔽的request_new信号, //判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位, //对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位, //则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 WAIT_LOCK: begin if(|(lock & grant)) //未释放仲裁器 begin R_STATUS <= WAIT_LOCK; end else if(|request) //释放的同时存在仲裁请求 begin R_STATUS <= WAIT_LOCK; if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end default: begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end endcase end end endmodule测试代码 `timescale 1ns / 1ps module RoundRobinArbiter_tb; parameter N = 4; // 可以在测试时调整参数 // 定义测试信号 reg clock; reg reset_b; reg [N-1:0] request; reg [N-1:0] lock; wire [N-1:0] grant; // 定义时钟信号 initial clock = 0; always #10 clock = ~clock; // 实例化仲裁器模块 RoundRobinArbiter #( .N(N) ) inst_RoundRobinArbiter ( .clock (clock), .reset_b (reset_b), .request (request), .lock (lock), .grant (grant) ); // 定义时钟周期和初始值 initial begin reset_b <= 1'b0; request <= 0; lock <= 0; end // 定义请求和锁定信号的变化 initial begin #20; reset_b <= 1'b1; @(posedge clock) request <= 2; lock <= 2; @(posedge clock) request <= 0; @(posedge clock) request <= 5; lock <= 7; @(posedge clock) lock <= 5; @(posedge clock) request <= 1; @(posedge clock) lock <= 1; @(posedge clock) request <= 0; @(posedge clock) lock <= 0; #1000 $stop; // 测试结束 end // 显示测试结果和波形图 initial begin $monitor("Time=%t, clock=%b, reset_b=%b, request=%b, lock=%b, grant=%b", $time, clock, reset_b, request, lock, grant); $dumpfile("RoundRobinArbiter_tb.vcd"); $dumpvars(0,RoundRobinArbiter_tb); end endmodule结果: image.png图片 如果对波形图无法理解可以看此博文 https://blog.csdn.net/m0_49540263/article/details/114967443 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: image.png图片 image.png图片 Type 表示读写类型。Reset 表示复位值。 写一个C函数 void dma_driver(void),按步骤完成以下需求: 分配DMA所需的源地址(0x30) 分配DMA所需的目的地址(0x300) 设置传输128 Byte 数据 开始DMA传输 等待DMA传输结束 答: // 假设有以下宏定义 #define DMA_REG 0x81050010 // DMA控制寄存器的地址 #define DMA_SRC_ADDR 0x30 // DMA源地址 #define DMA_DST_ADDR 0x300 // DMA目的地址 #define DMA_SIZE 128 // DMA传输大小 #define DMA_START 1 // DMA开始传输的标志位 // 定义C函数 void dma_driver(void) void dma_driver(void) { // 定义一个指向DMA控制寄存器的指针 volatile uint32_t *dma_reg = (volatile uint32_t *)DMA_REG; // 清空DMA控制寄存器的值 *dma_reg = 0; // 设置DMA源地址,目的地址和传输大小 *dma_reg |= (DMA_SRC_ADDR << 2) | (DMA_DST_ADDR << 13) | (DMA_SIZE << 24); // 开始DMA传输 *dma_reg |= DMA_START; // 等待DMA传输结束 while (*dma_reg & DMA_START) { // 可以在这里做一些其他的事情,比如打印日志或者检查错误 // printf("Waiting for DMA to finish...\n"); // check_error(); } }官方一点的表达:DMA,全称为:Direct Memory Access,即直接存储器访问。直接存储器存取( DMA )用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须 CPU 干预,数据可以通过 DMA 快速地移动,这就节省了 CPU 的资源来做其他操作。典型的例子就是移动一个外部内存的区块到芯片内部更快的内存区。像是这样的操作并没有让处理器工作拖延,反而可以被重新排程去处理其他的工作。DMA 传输对于高效能嵌入式系统算法和网络是很重要的。DMA 传输方式无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件为 RAM 与 I/O 设备开辟一条直接传送数据的通路, 能使 CPU 的效率大为提高。 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 答:第一步首得知道二阶带通(RC)滤波器的电路长啥样,高、低通组合一下就是带通,自己思考一下高、低通组合:如串联或并联,会得到带通还是带组? 电路图: H___H21L__E34_WC@43F1_8.jpg图片 这个一看就是总传递函数=A1*A2(模电二阶有源或无源滤波器绝对有) _LIYXIHR_08YNK__EV8SXDH.jpg图片 然后化简 X25LO__~TXMGO59LTLV@9S9.jpg图片 根据推导得到的表达式,对于 jwRC2 ,这一项,当 w 趋于无穷大时,uo/ui 趋于零。那么高频的临界点就是 wRC2 = 1+2C2/C1;(此时忽略低频项1/jwRC1) 同理,对于低频项 1 /jwRC1, w 趋于无穷小时,uo/ui 趋于零 ,那么低频的临界点就是 1/wRC1 = 1+2C2/C1;然后解二元一次方程两个电容就被解出来了 这里提供一种更简单方法: 二阶带通滤波器的中心频率 f0 和品质因数 Q 可以用下面的公式计算: image.png图片 已知 R1 = R2 = 10kΩ,f0 = (1kHz + 30kHz) / 2 = 15.5kHz,Q = f0 / (30kHz - 1kHz) = 0.54,代入上面的公式,可以求得: image.png图片 这是一个二元一次方程组,可以用任意方法求解,例如消元法或代入法。为了方便起见,我们假设 C1 和 C2 的值相近,那么可以近似地认为 C1 = C2 = 3.45nF。这样就得到了两个电容的容值。当然,也可以选择其他的电容值,只要满足上面的方程组即可。
FPGA&ASIC
软硬件算法
# 笔试面试
刘航宇
3年前
0
2,103
9
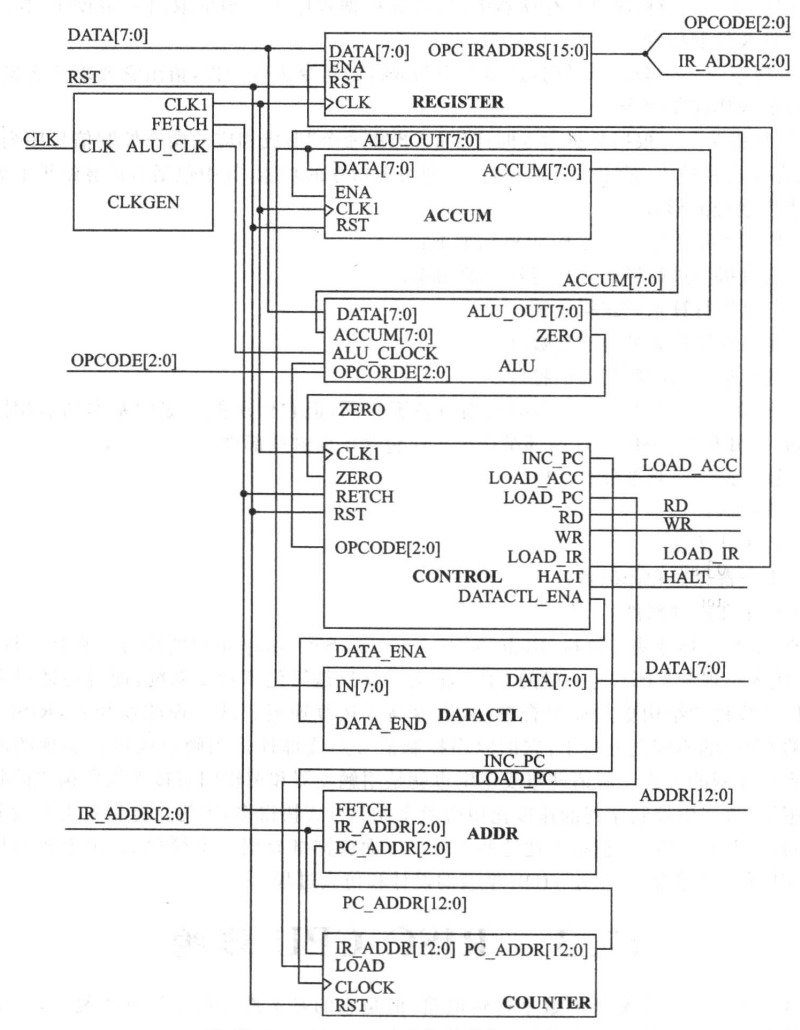
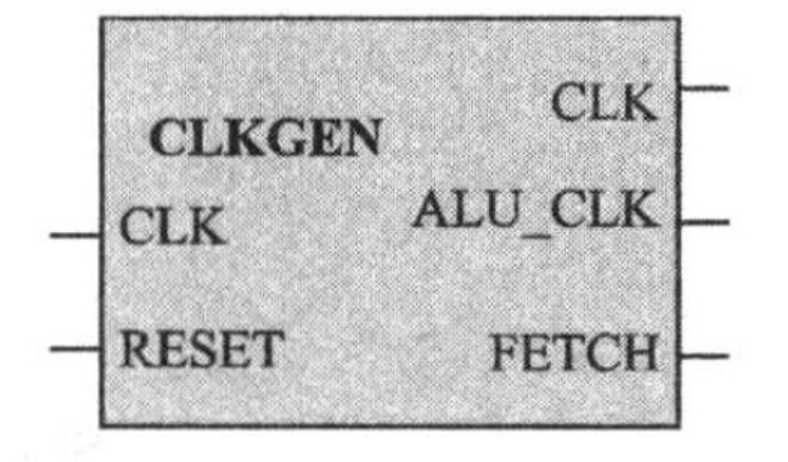
【IC/CPU设计】极简的RISC_CPU设计
CPU为SOC系统的核心环节,该项目来自于夏宇闻老师的经典教材——《Verilog 数字系统设计教程》,通过此练习方便数字ICer更好的入门 本次项目实践环境: 前仿: Modelsim 综合: Design Compile 目录 CPU简介 整体结构时钟发生器 指令寄存器 累加器 算术运算器数据控制器 地址多路器 程序计数器 状态控制器&主状态机 外围模块地址译码器 RAM ROM 顶层模块 TestbenchTest1程序 Test3程序 完整的testbench 源代码&脚本 前仿真结果 DC后仿真 总结 CPU简介 CPU(Central Processing Unit),中文全称中央处理器,作为四大U之首(CPU/GPU/TPU/NPU),是计算机系统的运算和控制核心,也是当今数字系统中不可或缺的组成部分。CPU自诞生到如今发展超过50年,借助冯诺依曼体系,CPU掀起一股又一股的科技浪潮。RISC作为精简了指令集的CPU,除了指令更加简洁,还拥有简单合理的内部结构,从而提高了运算速度。 CPU工作的5个阶段: (1)取指(IF,Instruction Fetch),将指令从存储器取出到指令寄存器。每取一条指令,程序计数器自加一。 (2)译指(ID,Instruction Decode),对取出的指令按照规定格式进行拆分和译码。 (3)执行(EX,Execute),执行具体指令操作。 (4)访问存储(MEM,Memory),根据指令访问存储、完成存储和读取。 (5)写回(WB,Write Back),将计算结果写回到存储器。 CPU内部关键结构: (1)算术逻辑运算器(ALU); (2)累加器; (3)程序计数器; (4)指令寄存器和译码器; (5)时序和控制部件。 RISC_CPU内部结构和Verilog实现 本项目中的RISC_CPU一共有9个模块组成,具体如下: (1)时钟发生器; (2)指令寄存器; (3)累加器; (4)算术逻辑运算单元; (5)数据控制器; (6)状态控制器; (7)主状态机; (8)程序计数器; (9)地址多路器。 整体结构 图片 时钟发生器 模块图: image.png图片 端口描述: reset是高电平复位信号; clk是外部时钟信号; fetch是控制信号,是clk的八分频信号;fetch为高电平时,触发执行指令以及地址多路器输出指令地址和数据地址。 alu_ena是算术逻辑运算单元的使能信号。 图片 可以看到alu_ena提前fetch高电平一个clk周期,fetch是clk的8分频信号。 Verilog代码: // Description: RISC——CPU 时钟发生器 // ----------------------------------------------------------------------------- module clk_gen ( input clk , // Clock input reset , // High level reset output reg fetch , // 8 frequency division output reg alu_ena // Arithmetic enable ); reg [7:0] state; //One-piece state machine parameter S1 = 8'b0000_0001, S2 = 8'b0000_0010, S3 = 8'b0000_0100, S4 = 8'b0000_1000, S5 = 8'b0001_0000, S6 = 8'b0010_0000, S7 = 8'b0100_0000, S8 = 8'b1000_0000, idle = 8'b0000_0000; always@(posedge clk)begin if(reset)begin fetch <= 0; alu_ena <= 0; state <= idle; end else begin case(state) S1: begin alu_ena <= 1; state <= S2; end S2: begin alu_ena <= 0; state <= S3; end S3: begin fetch <= 1; state <=S4; end S4: begin state <= S5; end S5: state <= S6; S6: state <= S7; S7: begin fetch <= 0; state <= S8; end S8: begin state <= S1; end idle: state <= S1; default: state <=idle; endcase end end endmodule指令寄存器 模块图: 图片 端口描述: 寄存器是将数据总线送来的指令存入高8位或低8位寄存器中。 ena信号用来控制是否寄存。 每条指令为两个字节,16位,高3位是操作码,低13位是地址(CPU地址总线为13位,寻址空间为8K字节)。 本设计的数据总线为8位,每条指令需要取两次,先取高8位,再取低8位。 Verilog代码: // Description: RISC—CPU 指令寄存器 // ----------------------------------------------------------------------------- module register ( input [7:0] data , input clk , input rst , input ena , output reg [15:0] opc_iraddr ); reg state ; // always@( posedge clk ) begin if( rst ) begin opc_iraddr <= 16'b 0000_0000_0000_0000; state <= 1'b 0; end // if rst // If load_ir from machine actived, load instruction data from rom in 2 clock periods. // Load high 8 bits first, and then low 8 bits. else if( ena ) begin case( state ) 1'b0 : begin opc_iraddr [ 15 : 8 ] <= data; state <= 1; end 1'b1 : begin opc_iraddr [ 7 : 0 ] <= data; state <= 0; end default : begin opc_iraddr [ 15 : 0 ] <= 16'bxxxx_xxxx_xxxx_xxxx; state <= 1'bx; end endcase // state end // else if ena else state <= 1'b0; end endmodule 累加器 模块图: 图片 端口描述: 累加器用于存放当前结果,ena信号有效时,在clk上升沿输出数据总线的数据。 // Description: RISC-CPU 累加器模块 // ----------------------------------------------------------------------------- module accum ( input clk , // Clock input ena , // Enable input rst , // Asynchronous reset active high input [7:0] data , // Data bus output reg [7:0] accum ); always@(posedge clk)begin if(rst) accum <= 8'b0000_0000;//Reset else if(ena) accum <= data; end endmodule 算术运算器 模块图: image.png图片 端口描述: 算术逻辑运算单元可以根据输入的操作码分别实现相应的加、与、异或、跳转等基本操作运算。 本单元支持8种操作运算。 opcode用来选择计算模式 data是数据输入 accum是累加器输出 alu_ena是模块使能信号 clk是系统时钟 Verilog代码: // Description: RISC-CPU 算术运算器 // ----------------------------------------------------------------------------- module alu ( input clk , // Clock input alu_ena , // Enable input [2:0] opcode , // High three bits are used as opcodes input [7:0] data , // data input [7:0] accum , // accum out output reg [7:0] alu_out , output zero ); parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always @(posedge clk) begin if(alu_ena) begin casex(opcode)//操作码来自指令寄存器的输出 opc_iaddr(15..0)的第三位 HLT: alu_out <= accum ; SKZ: alu_out <= accum ; ADD: alu_out <= data + accum ; ANDD: alu_out <= data & accum ; XORR: alu_out <= data ^ accum ; LDA : alu_out <= data ; STO : alu_out <= accum ; JMP : alu_out <= accum ; default: alu_out <= 8'bxxxx_xxxx ; endcase end end assign zero = !accum; endmodule 数据控制器 模块图: image.png图片 端口描述: 数据控制器的作用是控制累加器的数据输出,数据总线是分时复用的,会根据当前状态传输指令或者数据。 数据只在往RAM区或者端口写时才允许输出,否则呈现高阻态。 in是8bit数据输入 data_ena是使能信号 data是8bit数据输出 Verilog代码: // Description: RISC-CPU 数据控制器 // ----------------------------------------------------------------------------- module datactl ( input [7:0] in , // Data input input data_ena , // Data Enable output wire [7:0] data // Data output ); assign data = (data_ena )? in: 8'bzzzz_zzzz ; endmodule 地址多路器 模块图: image.png图片 端口描述: 用于选择输出地址是PC(程序计数)地址还是数据/端口地址。每个指令周期的前4个时钟周期用于从ROM种读取指令,输出的是PC地址;后四个时钟周期用于对RAM或端口读写。 地址多路器和数据控制器实现的功能十分相似。 fetch信号用来控制地址输出,高电平输出pc_addr ,低电平输出ir_addr ; pc_addr 指令地址; ir_addr ram或端口地址。 Verilog代码: // Description: RISC-CPU 地址多路器 // ----------------------------------------------------------------------------- module adr ( input fetch , // enable input [12:0] ir_addr , // input [12:0] pc_addr , // output wire [12:0] addr ); assign addr = fetch? pc_addr :ir_addr ; endmodule 程序计数器 模块图: image.png图片 端口描述: 程序计数器用来提供指令地址,指令按照地址顺序存放在存储器中。包含两种生成途径: (1)顺序执行的情况 (2)需要改变顺序,例如JMP指令 rst复位信号,高电平时地址清零; clock 时钟信号,系统时钟; ir_addr目标地址,当加载信号有效时输出此地址; pc_addr程序计数器地址 load地址装载信号 Verilog代码: // Description: RISC-CPU 程序计数器 // ----------------------------------------------------------------------------- module counter ( input [12:0] ir_addr , // program address input load , // Load up signal input clock , // CLock input rst , // Reset output reg [12:0] pc_addr // insert program address ); always@(posedge clock or posedge rst) begin if(rst) pc_addr <= 13'b0_0000_0000_0000; else if(load) pc_addr <= ir_addr; else pc_addr <= pc_addr + 1; end endmodule 状态控制器&主状态机 模块图: image.png图片 (图左边)状态机端口描述: 状态控制器接收复位信号rst,rst有效,控制输出ena为0,fetch有效控制ena为1。 // Description: RISC-CPU 状态控制器 // ----------------------------------------------------------------------------- module machinectl ( input clk , // Clock input rst , // Asynchronous reset input fetch , // Asynchronous reset active low output reg ena // Enable ); always@(posedge clk)begin if(rst) ena <= 0; else if(fetch) ena <=1; end endmodule (图右边)主状态端口描述: 主状态机是CPU的控制核心,用于产生一系列控制信号。 指令周期由8个时钟周期组成,每个时钟周期都要完成固定的操作。 (1)第0个时钟,CPU状态控制器的输出rd和load_ir 为高电平,其余为低电平。指令寄存器寄存由ROM送来的高8位指令代码。 (2)第1个时钟,与上一个时钟相比只是inc_pc从0变为1,故PC增1,ROM送来低8位指令代码,指令寄存器寄存该8位指令代码。 (3)第2个时钟,空操作。 (4)第3个时钟,PC增1,指向下一条指令。 操作符为HLT,输出信号HLT为高。 操作符不为HLT,除PC增1外,其余控制线输出为0. (5)第4个时钟,操作。 操作符为AND,ADD,XOR或LDA,读取相应地址的数据; 操作符为JMP,将目的地址送给程序计数器; 操作符为STO,输出累加器数据。 (6)第5个时钟,若操作符为ANDD,ADD或者XORR,算术运算器完成相应的计算; 操作符为LDA,就把数据通过算术运算器送给累加器; 操作符为SKZ,先判断累加器的值是否为0,若为0,PC加1,否则保持原值; 操作符为JMP,锁存目的地址; 操作符为STO,将数据写入地址处。 (7)第6个时钟,空操作。 (8)第7个时钟,若操作符为SKZ且累加器为0,则PC值再加1,跳过一条指令,否则PC无变化。 // Description: RISC-CPU 主状态机 // ----------------------------------------------------------------------------- module machine ( input clk , // Clock input ena , // Clock Enable input zero , // Asynchronous reset active low input [2:0] opcode , // OP code output reg inc_pc , // output reg load_acc , // output reg load_pc , // output reg rd , // output reg wr , // output reg load_ir , // output reg datactl_ena , // output reg halt ); reg [2:0] state ; //parameter parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always@(negedge clk) begin if(!ena) //收到复位信号rst,进行复位操作 begin state <= 3'b000; {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else ctl_cycle; end //------- task ctl_cycle ------- task ctl_cycle; begin casex(state) 3'b000: //load high 8bits in struction begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b001; end 3'b001://pc increased by one then load low 8bits instruction begin {inc_pc,load_acc,load_pc,rd} <= 4'b1001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b010; end 3'b010: //idle begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b011; end 3'b011: //next instruction address setup 分析指令开始点 begin if(opcode == HLT)//指令为暂停HLT begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0001; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b100; end 3'b100: //fetch oprand begin if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b101; end 3'b101://operation begin if(opcode == ADD || opcode == ANDD ||opcode ==XORR ||opcode == LDA)//过一个时钟后与累加器的内存进行运算 begin {inc_pc,load_acc,load_pc,rd} <= 4'b0101; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == SKZ && zero == 1)// & and && begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin//过一个时钟后吧wr变为1,写到RAM中 {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b1010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b110; end 3'b110: begin if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b111; end 3'b111: begin if(opcode == SKZ && zero == 1) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b000; end default: begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b000; end endcase end endtask endmodule 外围模块 为了对RISC-CPU进行测试,需要对ROM、RAM和地址译码器进行设计。 地址译码器 模块说明: 地址译码器用于产生选通信号,选通ROM或者RAM 1FFFH —— 1800H RAM(范围):1_1xxx_xxxx_xxxx 17FFH —— 0000H ROM(范围):0_xxxx_xxxx_xxxx+1_0xxx_xxxx_xxxx Verilog代码: // Description: RISC-CPU 地址译码器 // ----------------------------------------------------------------------------- module addr_decode ( input [12:0] addr , // Address output reg ram_sel , // Ram sel output reg rom_sel // Rom sel ); always@(addr)begin casex(addr) 13'b1_1xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b01; 13'b0_xxxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; 13'b1_0xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; default: {rom_sel,ram_sel} <= 2'b00; endcase end endmodule RAM 模块说明: RAM用于存放临时数据,可读可写。 Verilog代码: // Description: RISC-CPU RAM模块 // ----------------------------------------------------------------------------- module ram ( input ena , // Enable input read , // read Enable input write , // write Enable inout wire [7:0] data , // data input [9:0] addr // address ); reg [7:0] ram [10'h3ff:0] ; assign data = (read && ena )? ram[addr]:8'h zz; always@(posedge write) begin ram[addr] <= data; end endmodule ROM 模块说明: RAM用于存放只读数据。 Verilog代码: // Description: RISC-CPU ROM模块 // ----------------------------------------------------------------------------- module rom ( input [12:0] addr , input read , input ena , output wire [7:0] data ); reg [7:0] memory [13'h1ff:0]; assign data = (read && ena)? memory[addr]:8'b zzzz_zzzz; endmodule 顶层模块 模块图: 图片 图片 Verilog代码: // Description: RISC-CPU 顶层模块 // ----------------------------------------------------------------------------- //`include "clk_gen.v" //`include "accum.v" //`include "adr.v" //`include "alu.v" //`include "machine.v" //`include "counter.v" //`include "machinectl.v" //`iclude "machine.v" //`include "register.v" //`include "datactl.v" module RISC_CPU ( input clk , input reset , output wire rd , output wire wr , output wire halt , output wire fetch , //addr output wire [12:0] addr , output wire [12:0] ir_addr , output wire [12:0] pc_addr , inout wire [7:0] data , //op output wire [2:0] opcode ); wire [7:0] alu_out ; wire [7:0] accum ; wire zero ; wire inc_pc ; wire load_acc ; wire load_pc ; wire load_ir ; wire data_ena ; wire contr_ena ; wire alu_ena ; //inst clk_gen mclk_gen( .clk (clk ), .reset (reset ), .fetch (fetch ), .alu_ena (alu_ena ) ); register m_register( .data (data ), .ena (load_ir ), .rst (reset ), .clk (clk ), .opc_iraddr ({opcode,ir_addr} ) ); accum m_accum( .data (alu_out ), .ena (load_acc ), .clk (clk ), .rst (reset ), .accum (accum ) ); alu m_alu( .data (data ), .accum (accum ), .clk (clk ), .alu_ena (alu_ena ), .opcode (opcode ), .alu_out (alu_out ), .zero (zero ) ); machinectl m_machinectl( .clk (clk ), .rst (reset ), .fetch (fetch ), .ena (contr_ena ) ); machine m_machine( .inc_pc (inc_pc ), .load_acc (load_acc ), .load_pc (load_pc ), .rd (rd ), .wr (wr ), .load_ir (load_ir ), .clk (clk ), .datactl_ena(data_ena ), .halt (halt ), .zero (zero ), .ena (contr_ena ), .opcode (opcode ) ); datactl m_datactl( .in (alu_out ), .data_ena (data_ena ), .data (data ) ); adr m_adr( .fetch (fetch ), .ir_addr (ir_addr ), .pc_addr (pc_addr ), .addr (addr ) ); counter m_counter( .clock (inc_pc ), .rst (reset ), .ir_addr (ir_addr ), .load (load_pc ), .pc_addr (pc_addr ) ); endmodule Testbench Testbench包含三个测试程序,这个部分不能综合。 Test1程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 若各条指令正确,应该在地址2E(hex)处,在执行HLT时刻停止。若程序在任何其他位置停止,则必有一条指令运行错误,可以按照注释找到错误的指令。 test1汇编程序:(.pro文件/存放于ROM) //机器码-地址-汇编助记符-注释 @00 //address statement 111_0000 //00 BEGIN: JMP TST_JMP 0011_1100 000_0000 //02 HLT //JMP did not work 0000_0000 000_00000 //04 HLT //JMP did not load PC skiped 0000_0000 101_1100 //06 JMP_OK: LDA DATA 0000_0000 001_00000 //08 SKZ 0000_0000 000_0000 //0a HLT 0000_0000 101_11000 //0C LDA DATA_2 0000_0001 001_00000 //0E SKZ 0000_0000 111_0000 //10 JMP SKZ_OK 001_0100 000_0000 //12 HLT 0000_0000 110_11000 //14 SKZ_OK: STO TEMP 0000_0010 101_11000 //16 LDA DATA_1 0000_0000 110_11000 //18 STO TEMP 0000_0010 101_11000 //1A LDA TEMP 0000_0010 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 100_11000 //20 XOR DATA_2 0000_0001 001_00000 //22 SKZ 0000_0000 111_00000 //24 JMP XOR_OK 0010_1000 000_00000 //26 HLT 0000_0000 100_11000 //28 XOR_OK XOR DATA_2 0000_0001 001_00000 //2A SKZ 0000_0000 000_00000 //2C HLT 0000_0000 000_0000 //2E END 0000_0000 111_00000 //30 JMP BEGIN 0000_0000 @3c 111_00000 //3c TST_JMP IMR OK 0000_0110 000_00000 //3E HLT test1数据文件:(.dat/存放于RAM) /----------------------------------- @00 ///address statement at RAM 00000000 //1800 DATA_1 11111111 //1801 DATA_2 10101010 //1082 TEMPTest2程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 这个程序是用来测试RISC-CPU的高级指令集,若执行正确,应在地址20(hex)处在执行HLT时停止。 test2汇编程序: @00 101_11000 //00 BEGIN 0000_0001 011_11000 //02 AND DATA_3 0000_0010 100_11000 //04 XOR DATA_2 0000_0001 001_00000 //06 SKZ 0000_0000 000_00000 //08 HLT 0000_0000 010_11000 //0A ADD DATA_1 0000_0000 001_00000 //0C SKZ 0000_0000 111_00000 //0E JMP ADD_OK 0001_0010 111_00000 //10 HLT 0000_0000 100_11000 //12 ADD_OK XOR DATA_3 0000_0010 010_11000 //14 ADD DATA_1 0000_0000 110_11000 //16 STO TEMP 0000_0011 101_11000 //18 LDA DATA_1 0000_0000 010_11000 //1A ADD TEMP 0000_0001 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 000_00000 //END HLT 0000_0000 111_00000 //JMP BEGIN 0000_0000test2数据文件: @00 00000001 //1800 DATA_1 10101010 //1801 DATA_2 11111111 //1802 DATA_3 00000000 //1803 TEMPTest3程序 TEST3程序是一个计算0~144的斐波那契数列的程序,用来验证CPU整体功能。 test3汇编程序: @00 101_11000 //00 LOOP:LDA FN2 0000_0001 110_11000 //02 STO TEMP 0000_0010 010_11000 //04 ADD FN1 0000_0000 110_11000 //06 STO FN2 0000_0001 101_11000 //08 VLDA TEMP 0000_0010 110_11000 //0A STO FN1 0000_0000 100_11000 //0C XOR LIMIT 0000_0011 001_00000 //0E SKZ 0000_0000 111_00000 //10 JMP LOOP 0000_0000 000_00000 //12 DONE HLT 0000_0000test3数据文件: @00 00000001 //1800 FN1 00000000 //1801 FN2 00000000 //1802 TEMP 10010000 //1803 LIMIT完整的testbench Verilog代码: // Description: RISC-CPU 测试程序 // ----------------------------------------------------------------------------- `include "RISC_CPU.v" `include "ram.v" `include "rom.v" `include "addr_decode.v" `timescale 1ns/1ns `define PERIOD 100 // matches clk_gen.v module cputop_tb; reg [( 3 * 8 ): 0 ] mnemonic; // array that holds 3 8 bits ASCII characters reg [ 12 : 0 ] PC_addr, IR_addr; reg reset_req, clock; wire [ 12 : 0 ] ir_addr, pc_addr; // for post simulation. wire [ 12 : 0 ] addr; wire [ 7 : 0 ] data; wire [ 2 : 0 ] opcode; // for post simulation. wire fetch; // for post simulation. wire rd, wr, halt, ram_sel, rom_sel; integer test; //-----------------DIGITAL LOGIC---------------------- RISC_CPU t_cpu (.clk( clock ),.reset( reset_req ),.halt( halt ),.rd( rd ),.wr( wr ),.addr( addr ),.data( data ),.opcode( opcode ),.fetch( fetch ),.ir_addr( ir_addr ),.pc_addr( pc_addr )); ram t_ram (.addr ( addr [ 9 : 0 ]),.read ( rd ),.write ( wr ),.ena ( ram_sel ),.data ( data )); rom t_rom (.addr ( addr ),.read ( rd ), .ena ( rom_sel ),.data ( data )); addr_decode t_addr_decoder (.addr( addr ),.ram_sel( ram_sel ),.rom_sel( rom_sel )); //-------------------SIMULATION------------------------- initial begin clock = 0; // display time in nanoseconds $timeformat ( -9, 1, "ns", 12 ); display_debug_message; sys_reset; test1; $stop; test2; $stop; test3; $finish; // simulation is finished here. end // initial task display_debug_message; begin $display ("\n************************************************" ); $display ( "* THE FOLLOWING DEBUG TASK ARE AVAILABLE: *" ); $display ( "* \"test1;\" to load the 1st diagnostic program. *"); $display ( "* \"test2;\" to load the 2nd diagnostic program. *"); $display ( "* \"test3;\" to load the Fibonacci program. *"); $display ( "************************************************\n"); end endtask // display_debug_message task test1; begin test = 0; disable MONITOR; $readmemb ("test1.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test1.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 1; #14800; sys_reset; end endtask // test1 task test2; begin test = 0; disable MONITOR; $readmemb ("test2.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test2.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 2; #11600; sys_reset; end endtask // test2 task test3; begin test = 0; disable MONITOR; $readmemb ("test3.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test3.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 3; #94000; sys_reset; end endtask // test1 task sys_reset; begin reset_req = 0; #( `PERIOD * 0.7 ) reset_req = 1; #( 1.5 * `PERIOD ) reset_req = 0; end endtask // sys_reset //--------------------------MONITOR-------------------------------- always@( test ) begin: MONITOR case( test ) 1: begin // display results when running test 1 $display("\n*** RUNNING CPU test 1 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 1 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 1 @ t_cpu.pc_addr end 2: begin // display results when running test 2 $display("\n*** RUNNING CPU test 2 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 2 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 2 @ t_cpu.pc_addr end 3: begin // display results when running test 3 $display("\n*** RUNNING CPU test 3 - An Executable Program **************"); $display("***** This program should calculate the fibonacci *************"); $display("\n TIME FIBONACCI NUMBER "); $display(" ------ -----------------_ "); while( test == 3 ) begin wait( t_cpu.opcode == 3'h 1 ) // display Fib. No. at end of program loop $strobe("%t %d", $time, t_ram.ram [ 10'h 2 ]); wait( t_cpu.opcode != 3'h 1 ); end // while test == 3 end endcase // test end // MONITOR: always@ test //-------------------------HALT------------------------------- always@( posedge halt ) begin // STOP when HALT intruction decoded #500 $display("\n******************************************"); $display( "** A HALT INSTRUCTION WAS PROCESSED !!! **"); $display( "******************************************"); end // always@ posedge halt //-----------------------CLOCK & MNEMONIC------------------------- always#(`PERIOD / 2 ) clock = ~ clock; always@( t_cpu.opcode ) begin // get an ASCII mnemonic for each opcode case( t_cpu.opcode ) 3'b 000 : mnemonic = "HLT"; 3'b 001 : mnemonic = "SKZ"; 3'b 010 : mnemonic = "ADD"; 3'b 011 : mnemonic = "AND"; 3'b 100 : mnemonic = "XOR"; 3'b 101 : mnemonic = "LDA"; 3'b 110 : mnemonic = "STO"; 3'b 111 : mnemonic = "JMP"; default : mnemonic = "???"; endcase end endmodule $ readmemb ( "test1. pro" ,t_ rom. . memory ); $ readmemb ( "testl. dat",t_ ram_ . ram); 即可把编译好的汇编机器码装人虚拟ROM,把需要参加运算的数据装人虚拟RAM就可以开始仿真。上面语句中的第一项为打开的文件名,后一项为系统层次管理下的ROM模块和RAM模块中的存储器memory和ram。源代码&脚本 隐藏内容,请前往内页查看详情 前仿真结果 test1 图片 test2 图片 test3 图片 图片 DC后仿真 采用SMIC180工艺在典型环境下进行测试 时序报告: 图片 面积报告: 图片 功耗报告: 图片 综合电路图: 图片 图片 图片 总结 该项目更加偏向于教学练习,CPU也是数字IC的重要研究方向,对此感兴趣的同学可以找点论文和开源资料进行学习。可以进一步优化如流水线、运算单元,扩展成SOC系统等。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# SOC设计
刘航宇
3年前
15
2,127
6
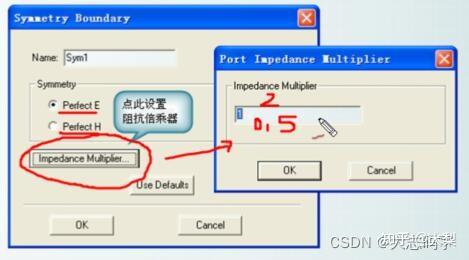
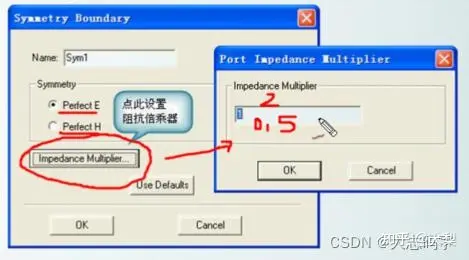
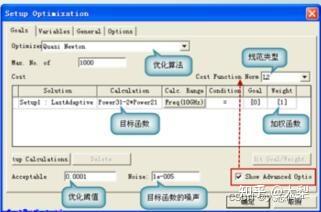
HFSS软件笔记
目录 一、HFSS中的边界条件(Boundaries) 二、HFSS中的激励方式(Excitation) 三、求解类型和求解设置 四、HFSS中的变量和Optimetrics模块的使用 五、HFSS的数据后处理 六、天线问题的数据后处理 # HFSS软件学习笔记 一、HFSS中的边界条件(Boundaries) 边界条件定义了求解区域的边界以及不同物体交界处的电磁场特性,是求解麦克斯韦方程的基础。 只有在假定场矢量是单值、有界、并且沿空间连续分布的前提下,微分形式的麦克斯韦方程组才是有效的;而在求解区域的边界、不同介质的交界处和场源处,场矢量是不连续的,那么场的导数也就失去了意义。边界条件就是定义跨越不连续边界处的电磁场的特性,因此,正确地理解、定义并设置边界条件,是正确使用HFSS仿真分析电磁场场特性的前提。 边界条件的类型: 理想导体边界(Perfect E) 电场矢量垂直于物体表面,有两种边界被自动设为理想导体边界条件: 1、任何与背景相关联的物体表面将被自动定义为理想导体边界,并命名为outer边界 2、材料设为PEC(理想电导体)的物体表面被自动定义为理想导体边界,并命名为smental 理想磁边界/自然边界(Perfect H) 电场矢量与物体表面相切,磁场矢量与物体表面垂直。 自然边界(Natural):当理想导体边界和理想磁边界出现交叠时,理想磁边界也称为自然边界 注意:在理想导体边界上叠加理想磁边界将去掉理想导体边界的特性,相当于在理想导体表面开个口,允许电场穿过。 有限导体边界(Finite Conductivity) 有耗导体/非理性导体边界条件,电场垂直于物体表面,在电磁波的传播方向上电场会愈来愈小 用户需要设置的参数:导电率和导磁率 注意:当物体的材料设置为非理想导体(如铜、铝等金属材料)时,其表面自动定义为有限导体边界条件。 辐射边界(Radiation) 用于模拟开放的自由空间,模拟波辐射到空间的无限远处的情况,常用于天线问题的分析。当结构中包含辐射边界条件时,HFSS会自动计算结构的远区场。(使用Perfect H边界条件模拟开放空间时,不会计算远区场) 辐射边界条件是自由空间的近似,这种近似的准确程度取决于波的传播方向与辐射边界之间的角度,以及辐射源与边界之间的距离。辐射边界在各个方向上距离辐射体一般不小于1/4个波长。 对称边界(Symmetry) 模拟理想电壁或理想磁壁对称面,应用对称边界可以构造结构时仅构造一部分,减小结构的尺寸和设计的复杂性,缩短计算时间。 定义对称平面时,需要遵循以下原则: 1、对称平面必须暴露在背景中 2、对称面必须定义在平面表面上,不能定义在曲面上 3、在一个问题上最多只能定义三个正交对称面 决定对称面的类型: 1、如果电场垂直于对称面且对称,使用理想电壁对称面 2、如果磁场垂直于对称面且对称,使用理想磁壁对称面 此外使用对称边界条件需要设置阻抗乘法器: 1、理想电壁对称面将结构分为两部分时,只有一半的电压值和一半的能量被计算,由Zpu=U*U/P计算出的阻抗也只有真实值的一半,所以需要定义2倍的阻抗乘法器。 2、理想磁壁对称面将结构分为两部分时,只有一半的能量被计算,而电压保持不变,由Zpu=U*U/P计算出的阻抗是真实值的2倍,所以需要定义0.5倍的阻抗乘法器。图片 图片 在这里插入图片描述 阻抗边界(Impedance) 用于模拟已知阻抗的边界表面,如薄膜电阻表面;表面的阻抗Zs=Rs+jXs。 阻抗的计算: number of "Square"=Length(in direction of current flow)/Width Impedance per Square=Desired Lumped Impedance/number of square 集总RLC边界(Lumped RLC) 类似于阻抗边界条件,利用用户提供的R、L、C值计算出对应的阻抗值 与阻抗边界不同的是,集总RLC边界不需要提供以Ohms/Square为单位的电阻和电抗,而是要给出R、L和C的真实值;之后HFSS就能确定任意频率下集总RLC边界以Ohms/Square为单位的阻抗。 分层阻抗边界条件(Layered Impedance) 分层阻抗边界条件是用多层结构将物体表面模拟为一个阻抗表面,其效果与阻抗边界条件相同; 与阻抗边界条件不同的是,对于分层阻抗边界条件,HFSS是根据输入的分层结构数据和表面粗糙度来计算表面电阻和表面电抗的。 分层边界条件不支持快速扫频。 无限地平面(Infinite Ground Plane) 在设置理想导体边界、有限导体边界或阻抗边界时有"Infinite Ground Plane"复选框。 将有限大的边界表面模拟成无限大地平面的作用,设置无限大平面边界后,在后处理中会影响近区、远区辐射场的计算。 定义无限大平面时,需要满足以下条件: 1、必须暴露在背景上 2、必须定义在平面上、 3、无限大平面和对称面的总数不超过3个 4、所有无限大地平面和对称面必须相互垂直 主从边界(Master and slave) 简称为关联边界条件LBC,主要用于模拟平面周期性结构表面,例如阵列天线。 包括主边界条件(Master)和从边界条件(Slave),总是成对出现,且主边界表面和从边界表面的形状、大小和方向完全相同,主边界表面和从边界表面上的电场存在一定的相位差,该相位差就是周期性结构相邻单元之间存在的相位差。 定义主从边界表面时,用户需要正确设置U、V坐标系,保证主从边界表面大小和方向完全一致。 理想匹配层(PML) 理想匹配层,是能够完全吸收入射电磁波的假想各项异性材料边界。理想匹配层有两种典型的应用:一是用于外场问题中的自由空间截断,二是用于导波问题中的吸收负载。 对于导波的吸收负载,理想匹配层模拟导波结构均匀地延申到无穷远处。 对于自由空间截断地情况,理想匹配层地作用类似于辐射边界条件,PML表面能够完全吸收入射过来地电磁波。和辐射边界条件相比,理想匹配层因为能够完全吸收入射的电磁波,零反射,因此计算结果更精确;同时理想匹配层表面可以距离辐射体更近(差不过十分之一个波长即可),不需要像辐射边界表面一般需要距离辐射体大约四分之一个波长。二、HFSS中的激励方式(Excitation) HFSS中,激励是一种定义在三维物体表面或者二维物体上的激励源,这种激励源可以是电磁波激励、电压源或者电流源,激励端口是一种允许能量进入或流出几何结构的特殊边界条件类型。 激励类型: 波端口(Wave Port) 默认情况下,所有三维物体和背景之间的接触面都是理想导体边界,没有能量可以进出;波端口设置在背景上,用作模型的激励源并提供一个能量进入/流出的窗口。波端口一般设置在背景平面上,不允许端口平面弯曲。 波端口模式(modes):对于给定横截面的波导或传输线,特定频率下有一系列的解满足相应的边界条件和麦克斯韦方程组,每个解都称之为一种模式,或者说一种波形。通常,模式是根据电场和磁场沿导波系统传输方向上有无分量这一情况来命名的,假设导波系统沿z轴放置,上述分量是指z向的电场分量Ez和磁场分量Hz。 对于Ez=0、Hz=0一类的模,称之为横电磁模,即TEM模; 对于Ez=0、Hz不为0一类模,称之为横电模,即TE模; 对于Ez不为0、Hz=0一类的模,称之为横磁模,即TM模。 端口校准:波端口必须被校准以确保一致的结果;校准的目的有两个,确定场的方向、设置电压的积分路径。 端口平移(Deembed):是指平移端口的位置,查看其对计算结果的影响;选中使用端口平移功能,只影响数据后处理,HFSS不会重新进行仿真计算。HFSS端口平移中正数表示参考平面向模型内部移动,负数则是向外延申。 终端线(Terminal):对于终端驱动的求解类型,终端的S参数反映的是波端口节点电压和电流的线性叠加,通过波端口处的节点电流和电压可以计算出端口的阻抗和S参数矩阵。 集总端口(Lumped Por) 集总端口激励和波端口激励是HFSS中最常用的两种激励方式。 集总端口激励类似于传统的波端口,与波端口不同的是集总端口可以设置在物体模型内部,且用户需要设定端口阻抗;集总端口直接在端口处计算S参数,设定的端口阻抗即为集总端口上S参数的参考阻抗;另外集总端口不计算端口处的传播常数,因此集总端口无法进行端口平移操作。 集总端口激励的尺寸大小要比波端口小 Floquet端口(Floquet Port) 与波端口的求解方式类似,Floquet端口求解的反射和传输系数能够以S参数的形式显示。使用Floquet端口激励并结合周期性边界,能够像传统波导端口激励一样轻松的分析周期型结构的电磁特性,从而避免了场求解器复杂的后处理过程。 入射波(Incident Wave) 是用户设置的朝某一特定方向传播的电磁波,其等相位面与传播方向垂直;入射波照射到器件表面和器件表面的夹角称为入射角。入射波激励常用于雷达反射截面(RCS)问题的计算。 需要设置的参数有:波的传播方向(Poynting Vector)、电场的强度和方向。 电压源激励(Voltage) 电压源激励定义在两层导体之间的平面上,用理想电压源来表示该平面上的电场激励。 电压源激励时需要设置的参数有:电压的幅度、相位和电场的方向。 注意:电压源激励所在的平面必须远小于工作波长,且平面上的电场是恒定电场;电压源激励是理想的源,没有内阻,因此后处理时不会输出S参数。 电流源激励(Current) 电流源激励定义于导体表面或者导体表面的缝隙上,用理想电流源来表示该平面上激励。 电流源激励需要设定的参数有:导体表面缝隙的电流幅度、相位和方向。 注意:电流源激励所在的平面/缝隙必须小于工作波长,且平面/缝隙上的电流是恒定的;电流源激励是理想的源,没有内阻,因此后处理时不会输出S参数。 磁偏置激励(Magnetic Bias) 创建一个铁氧体材料时,必须通过设置磁偏置激励来定义网格的内部偏置场;该偏置场使得铁氧体中的磁性偶极子规则排列,产生一个非零的磁矩。 如果应用的偏置场时均匀的,张量坐标系可以通过旋转全局坐标系来设置 如果应用的偏置场时非均匀的,不允许旋转全局坐标来设置张量坐标系三、求解类型和求解设置 1、HFSS中有三种求解类型:模式驱动求解(Driven Model)、终端驱动求解(Driven Terminal)和本征模求解(Eigenmode) 模式驱动求解类型:以模式为基础计算S参数,根据导波内各模式场的入射功率和反射功率来计算S参数矩阵的解。 终端驱动求解类型:以终端为基础计算导体传输线端口的S参数;此时,根据传输线终端的电压和电流来计算S参数矩阵的解。 本征模式求解类型:本征模式求解器主要用于谐振问题的设计与分析,可以用于计算谐振结构的谐振频率和谐振频率处对应的场,也可以用于计算谐振腔体的无载Q值。 应用本征模式求解时注意: 不需要设置激励方式 不能定义辐射边界条件 不能进行扫频分析 不能包含铁氧体材料 只有场解结果,没有S参数求解结果2、自适应网格剖分:在分析对象内部搜索误差最大的区域并进行网格的细化,每次网格细化过程中网格增加百分比由用户事先设置,完成一次细化过程后,重新计算并搜索误差最大的区域,然后判断误差是否满足设置的收敛条件。如果满足收敛条件,则完成网格剖分;如果不满足收敛条件,继续下一次网格细化过程,直到满足收敛条件或者达到设置的最大迭代次数为止。 3、求解频率(网格自适应剖分频率)的选择 HFSS计算时自适应网格剖分是在用户设定的单一频点上进行的,网格剖分完成后,同一个求解设置项下其他频点的求解都是基于前面设定频点上所完成的网格划分。自适应频率设置越高,网格剖分就越细,网格个数就越多,计算结果也相应地更加准确,但同时计算过程中所占用地计算机内存也就越高,计算所花费地时间也越长。 下面给出几个常用问题类别的自适应频率的选择: 点频或窄带问题:对于点频或者窄带问题,自适应网格剖分直接选择工作频率。 宽带问题:对于宽带问题,应该选择最高频率作为自适应网格剖分频率。 滤波器问题:对于滤波器问题,由于阻带内电场只存在于断口处,所以自适应频率选择在通带内的高频段。 快速扫频问题:对于快速扫频问题,典型的做法就是选择中心频率作为自适应频率。 高速数字信号:对于高速数字信号完整性分析问题,需要借助转折频率(Knee Frequency)来决定自适应网格剖分频率 4、扫频分析 离散扫频(Discrete):是在频带内的指定频点处计算S参数和场解。例如,指定频带范围为1~2GHz、步长为0.25GHz,则会计算在1GHz、1.25GHz、1.5GHz、1.75GHz、2GHz频点处的S参数和场解。默认情况下,使用离散扫频只保存最后计算频率点的场解。如果希望保存指定的所有频率点的场解,需要选中设置对话框中Save Fields复选框。 快速扫频(Fast):采用ALPS算法,在很宽的频带范围内搜寻处传输函数的全部零、极点。快速扫频适用于谐振问题和高Q值问题的分析,可以得到场在谐振点附近行为的精确描述。使用快速扫频,一般选择频带中心频率作为自适应网格剖分频率进行网格剖分,计算出该频点的S参数和场分布,然后使用基于ALPS算法的求解器从中心频率处的S参数解和场解来外推整个频带范围的S参数和场解。使用快速扫频,计算时只会求解中心频点处的场解,但在数据后处理时整个扫频范围内的任意频点的场都可以显示。 插值扫频(Interpolating):插值扫频使用二分法来计算整个频段内的S参数和场解。使用插值扫频,HFSS自适应选择场解的频率点,并计算相邻两个频点之间的解的误差,找出最大误差,当两点之间的最大误差达到指定的误差收敛标准或者达到了设定的最大频点数目后,扫描完成;其他频率点上的S参数和场解由内插给出。 四、HFSS中的变量和Optimetrics模块的使用 HFSS不仅能够提供常规的电磁分析,还能够提供优化分析、参数扫描分析、灵敏度分析和统计分析等功能。这些功能都集中在HFSS中的Optimetrics模块中。要使用Optimetrics模块的这些分析和设计功能。首先需要定义和添加相关变量。 1、HFSS中变量的定义和使用 (1)HFSS中有两种类型的变量:工程变量(Project Variables)和设计变量/本地变量(Local Variables) 工程变量和设计变量的区别: 工程变量前面有一个"$"前缀,以和本地变量区分 工程变量作用区间是整个Project,本地变量作用区间是所在的Design 物体模型尺寸、物体的材料属性(工程变量)等都可以使用变量来表示。 (2)变量的定义 变量名:可以由数字、字母或下划线组成。每个变量在定义时都必须赋一个初始值,变量值可以是数值、数学表达式或者数学函数,也可以是数组、矩阵或者行列式。 添加/删除变量:工程变量和设计变量操作不同 添加和删除工程变量:Project > Project Variables 或者 [Project Tree] Project > Project Variables 打开 Project Properties 对话框 添加和删除设计变量:HFSS > Design Properties 或者 [Project Tree] Design > Design Properties 打开 Design Properties 对话框 在设计过程中,也可以直接输入未定义的变量代替设计参数,输入未定义的变量后,HFSS会自动弹出添加变量的对话框 2、Optimetrics模块的功能介绍 Optimetrics是集成在HFSS中的优化设计模块,该模块通过自动分析设计参数的变化对求解结果的影响,HFSS中Optimetrics模块能够提供如下分析设计功能: 参数扫描分析(Parametric) 参数扫描分析功能可以用来分析物体的性能随着指定变量的变化而变化的关系,在优化设计之前一般使用参数扫描分析功能来确定被优化变量的合理变化区间 参数扫描分析步骤: 首先需要定义变量并添加求解设置项 HFSS > Optimetrices > Add Parametric...弹出 Setup Sweep Analysis 对话框,添加扫描变量 或选中Project Manager 中的 Optimetrics,单击右键 Add > Parametric,弹出 Setup Sweep Analysis 对话框,添加扫描变量 设置好扫面变量后,点击”Analyze“就可以进行参数扫描分析 查看分析结果 优化设计(Optimization) 优化设计是HFSS软件结合Optimetrics模块根据特定的优化算法在所有可能的设计变化中寻找出一个满足设计要求的值的过程 优化设计的过程: 首先需要明确设计要求或设计目标 然后用户根据设计要求创建初始结构模型(Nominal Design)、定义设计变量并构造目标函数 最后指定优化算法进行优化。 图片 图片 在这里插入图片描述 调谐分析(Tuning) 调谐分析功能是改变变量值的同时实时显示对求解结果的影响程度 HFSS中的调谐分析功能是用户在手动改变变量值得同时能实时显示求解结果 图片 图片 在这里插入图片描述 灵敏度分析(Sensitivity) 灵敏度定义为电磁特性/求解结果的变化与电路参数的变化的比值,使用HFSS进行电磁分析时S参数是很常用的一个分析结果。灵敏度分析功能是用来分析设计参数的微小变化对求解结果的影响程度 统计分析(Statistical) 统计分析功能是利用统计学的观点来研究设计参数容差对求解结果的影响,常用的方法是蒙特卡洛法 图片 图片 在这里插入图片描述 五、HFSS的数据后处理 使用HFSS进行电磁问题的求解分析过程中以及完成求解分析之后,利用数据后处理功能能够直观地给出问题地各种求解信息和求解结果。 1、求解信息数据(Solution Data) HFSS > Results > Solution Data 命令,或者右键单机工程树Results节点,从弹出菜单中选择Solution Data命令,可以打开求解信息对话框,显示各种求解信息。 2、Results数值结果 (1)显示方式 HFSS后处理模块能够以多种方式来显示分析数值结果,这些数值结果地显示方式包括:(右击Results > Create Model Solution Data Report) Rectangular Plot:直角坐标图形显示 Rectangular Stacked Plot Polar Plot:极坐标图像显示 Data Table:数据列表显示 Smith Chart: 史密斯圆图显示 3D Rectangular Plot:三维直角坐标 3D Polar Plot:三维球坐标图形显示 Radiation Pattern:辐射方向图 (2)参数类型 模式驱动求解: Output Variables:用户自定义的输出变量 S Parameter:散射参数 Y Parameter:导纳参数 Z Parameter:阻抗参数 VSWR:电压驻波比 Gamma:传播常数 Port Zo:端口特征阻抗 Active S Parameter Active Y Parameter Active Z Parameter Active VSWR 终端驱动求解: Output Variables:用户自定义的输出变量 S Parameter:散射参数 Y Parameter:导纳参数 Z Parameter:阻抗参数 VSWR:电压驻波比 Power:功率 Voltage Transform matrix:电压传输矩阵 Terminal Port Zo:端口特征阻抗 Active S Parameter Active Y Parameter Active Z Parameter Active VSWR (3)输出变量 右键单击工程树下的Result节点,从弹出菜单中选择Output Variables命令,便可打开输出变量的定义对话框 3、Field Overlays场分布图 在HFSS求解完成之后可以通过右击 Field Overlays 来查看电场、磁场、电流密度、坡印廷矢量等场分布图。 (1)电场E Mag_E:电场幅度瞬时值 ComplexMag_E:电场幅度有效值 Vector_E:电场矢量 (2)磁场H Mag_H:磁场幅度瞬时值 ComplexMag_H:磁场幅度有效值 Vector_H:磁场矢量 (3)电流密度J Mag_Jvol:体电流密度瞬时值 ComplexMag_Jvol:体电流密度有效值 Vector_Jvol:体电流密度矢量 Mag_Jsurf:面电流密度瞬时值 ComplexMag_Jsurf:面电流密度有效值 Vector_Jsurf:面电流密度矢量 (4)其他 Vector_RealPoynting:坡印廷矢量 Local\_SAR和Average\_SAR:局部SAR值和平均SAR值 六、天线问题的数据后处理 1、天线方向图 创建天线的方向图:Results > Create Model Solution Data Report > 3D Polar Plot 天线的辐射场在固定距离上随球坐标系的角坐标 θ 、φ 分布的图形被称为辐射方向图,简称方向图。方向图通常在远区场确定。用辐射场强表示的方向图称为场强方向图,用辐射功率密度表示的方向图称为功率方向图。 2、天线性能参数 右击Radiation,创建好查看天线性能参数:右击天线辐射方向图 > Compute Antenna Parameters Incident Power:输入功率 HFSS中输入功率是指定义的端口激励功率 Acceptable Power:净输入功率 净输入功率是指世纪流入天线端口的输入功率,如果分别使用 Pacc 和 Pinc 表示净输入功率和输入功率,对于只有一个传输模式的单端口天线,有: 图片 Radiated Power:辐射功率 辐射功率是指经由天线辐射到自由空间里的电磁能量,天线的辐射功率可以用坡印廷矢量的曲面积分来计算: 图片 Radiation Efficiency:辐射效率 辐射效率是辐射功率和净输入功率的比值 图片 Max U:最大辐射强度 辐射强度U是指每单位立体角内天线辐射出的功率,Max U是辐射强度的最大值 图片 η 自由空间中的波阻抗为 377Ω,r 为远区场点与天线之间的距离 Peak Directivity:方向性系数 天线的方向性系数是指在相同的辐射功率和相同的距离的情况下,天线在最大辐射方向上的辐射功率密度与无方向性天线在该方向上的辐射功率密度的比值图片 Peak Gain:天线增益 天线增益是指在相同的净输入功率和相同距离的情况下,天线在最大辐射方向上的辐射功率密度与无方向性天线在该方向上的辐射功率密度的比值图片 Peak Realized Gain:最大实际增益 天线的最大实际增益是指在相同的输入功率和相同距离的情况下,天线在最大辐射方向上的辐射功率密度与无方向性天线在该方向上的辐射功率密度的比值 Front to back Ration:前后向比 又称为轴比(Axis Ratio),指方向图中前后瓣的最大比值,代表天线的极化程度 3、天线阵的处理 由相同的天线单元构成的天线阵的方向图等于单个天线单元的方向图与阵因子的乘积。其中,阵因子取决于天线单元之间的振幅、相位差和相对位置,与天线的类型、尺寸无关。在HFSS中,可以定义天线阵元排列结构和激励方式,然后通过仿真分析分析单个天线单元的方向图等天线参数和阵因子来仿真分析整个天线阵列的方向图等天线参数。HFSS支持两种天线阵列类型:规则排列的均匀天线阵列(Regular Uniform Array)和用户自定义排列(Custom Array)。 其中用户自定义阵列:允许用户使用文本文件自定义阵因子信息,然后导入到HFSS软件中,HFSS计算得到阵因子。用户自定义阵列允许更大的灵活性,可以构造天线阵元在空间任意分布的天线阵列。
通信&信息处理
# 天线设计
刘航宇
3年前
0
5,411
2
AMBA--AHB总线协议介绍(一)
1、AHB总线概述 AHB:Advanced High-performance Bus,即高级高性能总线。AHB总线是SOC芯片中应用最为广泛的片上总线。下图是一个典型的基于AMBA AHB总线的微控制器系统: 图片 SOC架构 图片 基于AMBA AHB的设计中可以包含一个或多个总线主机,通常一个系统里至少包含一个处理器和一个测试接口;DMA和DSP作为总线主机同样是比较常见的。 典型的AHB总线设计包括一下几个部分: (1)AHB主机:主机可以通过提供地址和控制信息发起读写操作;同一时刻总线上只允许一个主机占用总线。 (2)AHB从机:从机需在给定的地址空间范围内响应总线上的读或写操作;从机通过信号将成功、失败、等待数据传输等信息返回至有效的主机。 (3)AHB仲裁器:总线仲裁器确保同一时刻只有一个主机被允许发起传输。所有的AHB总线都必须包含一个仲裁器,即使是在单主机总线系统中。 (4)AHB译码器:译码器的作用是对传输中的地址信号进行译码,并提供给从机一个选择信号。所有的AHB总线中都必须包含一个中央译码器。 2、总线互联 AMBA AHB总线协议被设计为一个使用中央多路选择器的互联方案,如下表: 图片 基于这种方案,所有的主机在需要发起传输时,都可以驱动地址和控制信号,由仲裁器决定哪一个主机的地址和控制信号(写传输时包含写数据信号)连通到总线上的所有从机。同时总线需要一个中央译码器,用于控制读数据和应答信号的多路数据选择器,该多路数据选择器用于选择传输中涉及的从机的相关信号。 3、AHB信号 AHB信号以字母H作为前缀,如下表所示 NameWidthSourceDescriptionHCLK1bit时钟源总线所有传输都基于此时钟,所有信号的时序都与时钟上升沿有关HRESETn1bit复位控制器总线复位信号,总线上唯一低电平有效的信号HADDR32bit主机32位地址总线HTRANS2bit主机表明当前传输的类型HSIZE2bit主机表明传输的大小,典型的是字节(8-bit)、 半字(16-bit)、字(32-bit), 协议允许最大传输大小是1024 bitHWRITE1bit主机传输写信号,高电平表示写传输,低电平表示读传输HBURST3bit主机有自己的HBURST信号有自己的HBURST信号HPROT4bit主机保护控制信号。主要应用于期望实现某些程度的保护级别的模块中HWDATA32bit主机写传输数据。要求最低位宽位32位HSELx1bit译码器从机选择信号,每个AHB从机都有自己的HSEL信号,该信号有效时,表明选中相应从机HRDATA32bit从机读数据总线,用于读操作期间从机向主机传输数据HREADY1bit从机该信号为高时,表明总线传输完成。也可以拉低该信号用以扩展传输HRESP2bit从机传输响应信号。提供四种响应OKAY、ERROR、RETRY、SPLITAMBA AHB也需要一些信号用于支持多主机总线操作,其中一些仲裁信号需要点对点连接: NameWidthSourceDescriptionHBUSREQx1bit主机主机x发送至仲裁器的总线请求信号,总线系统中最多有16个主机,每个主机都有一个HBUSREQ信号HLOCKx1bit主机该信号为高时,表示主机x发起锁定传输HGRANTx1bit仲裁器表明主机x在当前总线上拥有最高的优先级,当HREADY信号为高时,地址/控制信号的所有权将发生变化,故主机x需在HREADY与HGRANTx信号同时为高时,获得总线控制权HMASTER4bit仲裁器表明哪一个主机当前拥有地址/控制信号的所有权HMASTLOCK1bit仲裁器表明当前传输为锁定顺序传输,此信号与HMASTER具有相同时序HSPLITx16bit从机用于指示仲裁器,哪一个主机可以继续完成分块传输4、AMBA AHB操作概述 在一次AHB传输开始之前,主机必须被授予总线访问权。这个过程起始于主机向仲裁器发出一个总线请求,由仲裁器决定该主机何时被授予总线使用权。被授权的主机通过驱动地址和控制信号来发起一次AHB传输,这些信号提供了地址、传输方向、传输宽度等信息,以及会表明当前传输是否为突发传输的一部分。AHB支持两种形式的突发传输: (1)增量突发,在地址边界不进行回环; (2)回环突发,在特定地址边界回环 写数据总线用于将数据从主机发送到从机,读数据总线用于将数据从从机传输到主机。 每次数据传输包含: (1)一个地址和控制周期; (2)一个或多个数据周期 由于地址不支持扩展,所以所有的从机必须在地址周期内采样地址,而数据可以通过HREADY信号进行扩展延长,当HREADY信号为低,总线将插入等待状态,以此提供从机额外的采样数据或者提供数据的时间。 在传输中,从机使用应答信号HRESP[1:0]来表示传输状态: (1)OKAY:OKAY响应表示传输正常,且当HREADY信号为高时,表示传输成功; (2)ERROR:ERROR响应表示发生了传输错误,并且传输失败; (3)RETRY and SPLIT:RETRY和SPLIT都表示当前传输未能即刻完成,但是主机应继续尝试传输 一般而言,仲裁器授权另一个主机前,允许当前被授权主机完成突发传输。然而,为了避免过多的仲裁延迟(当前主机占用过多总线周期),总线可以打断一个突发传输,在这种情况下,主机必须重新申请总线,以完成后续的突发传输。 5、基本传输 一个AHB传输包含两个部分: (1)地址相位,仅包含一个时钟周期; (2)数据相位,可以使用HREADY信号,维持多个时钟周期 下图表示了一个无等待状态的简单传输: 图片 在无等待的简单传输中,主机在HCLK的上升沿驱动地址和控制信号到总线上,在下一个时钟上升沿时,从机对地址和控制信号进行采样,从机采样得到地址和控制信息后,可以驱动应答信号给与主机适当的响应,主机在第三个时钟的上升沿对应答信号进行采样。 这个简单的例子演示了在不同的时钟周期地址和数据相位是怎样产生的。实际上,当前传输的地址相位都对应于前一次传输的数据相位,这种地址和数据交叠现象,是总线能够进行流水线传输的基础,这样不仅能够获得更高的传输性能,也能为从机进行响应提供充足的时间。 从机可以在数据相位中,插入等待状态,以此获得更多得时间来完成传输: 图片 注意: (1)在写传输中,主机需要在整个扩展周期内保持写数据信号稳定 (2)在读传输中,从机没必要提供有效数据,知道传输结束时 当传输以这种方式做扩展时,将对下一个传输的地址相位产生一个扩展的副作用,如下图所示: 图片 该图表示了三个不相关的地址A、B、C上的传输,图中地址A和C的传输都没有等待状态,地址B的传输通过HREADY信号的拉低插入了一个等待的数据相位,这样导致了地址C传输的地址相位进行了扩展。 6、传输类型 AHB传输类型可以分为四种,通过HTRANS[1:0]的取值来划分: HTRANSTypeDescription00IDLE表明没有数据传输的要求。IDLE 用于主机被授予总线,但不希望进行数据传输的情况。对于IDLE传输,从机必须提供一个零等待的OKAY应答,并且忽略该传输01BUSYBUSY传输类型允许主机在突发传输中插入空闲周期。表明主机正在进行突发传输,但下次传输不能立即有效。当主机使用BUSY传输类型时,地址和控制信号必须对应突发中的下一次传输。从机必须提供一个零等待的OKAY应答,并且忽略该传输。10NONSEQ表示突发传输中的第一次传输或者非突发的单次传输,地址和控制信号与前次传输无关.11SEQ突发传输中剩余的传输时连续的,地址和前一次传输是相关的,当前地址值等于前一次传输的地址值加上传输大小(字节), 控制信息和前一次传输相同。在回环的突发传输中,传输的地址在地址边界处回环,回环值的大小等于传输大小(字节) 乘以传输次数(4、8或16) )下图是一个不同传输类型的例子: 图片 从图中可以看出: 第一个传输为以此突发传输的开始(T1),所以其传输类型为NONSEQ; 主机不能立刻执行突发传输中的第二次传输,所以使用了BUSY的传输类型(T2)来延迟下一次传输的开始,注意此时地址已经时下次传输的地址,控制信号和下次传输保持一致,主机只插入了一个BUSY,所以T3执行第二次传输; 主机执行第三次传输(T4),由于从机将HREADY信号拉低,插入了一个等待周期,引起地址相位的扩展; T6周期完成第三次传输,T7周期完成第四次传输(图中T8边沿)。 7、突发操作 AMBA AHB协议定义了4、8和16拍的突发,未定义长度的突发传输以及单次传输;协议支持增量和回环的突发方式。 增量突发方式访问连续地址空间,每次传输的地址是前一次传输地址增加一个增量偏移; 回环突发中,如果传输的其实地址并未和突发中的字节总数对齐,则突发传输地址将在达到边界处回环。例如:一个4拍回环突发的字(4字节)访问将在16字节的边界处回环,如果传输的起始地址为0x34,那么突发中将包含4个地址:0x34,0x38,0x3C,0x30。 AMBA AHB 有8种突发操作,使用信号HBRUST[2:0]表示: HTRANSTypeDescription000SINGLE单一传输001INCR未指定长度的增量突发010WRAP44拍回环突发011INCR44拍增量突发100WRAP88拍回环突发101INCR88拍增量突发110WRAP1616拍回环突发111INCR1616拍增量突发突发不能超过1K的地址边界,所以主机尽量不要发起将要跨过地址边界的定长的增量突发。 一次突发传输的数据总量,等于节拍数乘以每拍包含的字节数。所以突发传输必须将地址边界和数据大小对齐,例如,字传输必须对齐到字地址边界,即A[1:0]=00;半字传输必须对齐到半字地址边界,即A[0]=0。
IP&SOC设计
# SOC设计
刘航宇
3年前
0
1,824
2
1
2
...
4
下一页