首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,172 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,136 阅读
3
【高数】形心计算公式讲解大全
8,750 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,447 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,812 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
55(共79篇)
找到
79
篇与
55
相关的结果
2025-01-09
【FPGA】AXI DMA详解
<DMA简介 ZYNQ DMA简介 三、AXI DMA IP简介 四、AXI DMA参数与接口分析 define RX_INTR_ID XPAR_FABRIC_AXIDMA_0_S2MM_INTROUT_VEC_ID define TX_INTR_ID XPAR_FABRIC_AXIDMA_0_MM2S_INTROUT_VEC_IDXilinx FPGA里面的AXI DMA IP核的简单用法 DMA简介 DMA是一种内存访问技术,允许某些计算机内部的硬件子系统可以独立的直接读写内存,而不需要CPU介入处理,从而不需要CPU的大量中断负载,否则,CPU需要从来源把每一片段的数据复制到寄存器,然后在把他们再次写回到新的地方,在这个时间里,CPU就无法执行其他的任务。 DMA是一种快速数据传送方式,通常用来传送数据量较多的数据块。使用DMA时,CPU向DMA控制器发送一个存储器传输请求,这样当DMA控制器在传输的时候,CPU执行其他的操作,传输完成时DMA以中断的方式通知CPU。 DMA传输过程的示意图为: 图片 DMA的传输过程为: 1、为了配置用DMA传输数据到存储器,处理器(Cortex-A9)发出一条指令。 2、DMA控制器把数据从外设传输到存储器或者从存储器传输到存储器,从而较少CPU处理的事务量。 3、输出传输完成后,向CPU发出一个中断通知DMA传输可以关闭。 为了发起传输事务,DMA控制器必须得到以下信息: (1)、源地址——数据被读出的地址 (2)、目的地址——数据被写入的地址 (3)、传输长度——应传输的字节数 ZYNQ DMA简介 ZYNQ提供了两种DMA,一种是集成在PS中的硬核DMA,另一种是PL中使用的软核AXI DMA IP。 在ARM APU(Application Processor Unit,应用处理单元)设计过程中,已经考虑到大量数据搬移的情况,因此在APU中自带了一个DMA控制器DAMC,这个DMAC驻留在PS内,而且必须通过驻留在内存中的DMA指令编程,这些程序往往需要CPU准备,因此需要部分的CPU参与。DMAC支持多达8个通道,所以多个DMA结构的核可以挂载在单个DMAC上。 DMAC与PL的连接是通过AXI-GP接口,这个接口最高支持到32位宽,这也限制了这种模式下的传输速率,理论上最大为600MB/s,这种模式不占用PL资源,但需要对DMA指令编程,会增加软件的复杂性。 为了获取更高的速率,可以空间换时间,在PL中添加AXI DMA IP core,并利用AXI_HP接口完成高速的数据传输,各种接口的传输比较为: 图片 ZYNQ中ACI_HP接口的分布为: 图片 通过PL的DMA和AXI_HP接口传输方式的拓扑图为: 图片 DMA的数据传输经过S_AXI_HP接口,每一个HP接口都含有控制和数据fifo,这些fifo为大数据量突发传输提供缓冲,使得HP成为理想的高速数据接口。 对DMA的控制或配置通过M_AXI_GP接口(M代表master为PS),传输状态通过中断传达到PS的中断控制器。 对M_AXI_GP0理解是: 在ZYNQ7处理器系统IP core中,在PS-PL Configuration下的AXI Non Secure Enablement下有一个GP Master AXI Interface选项,可选一个M_AXI_GP0接口。 该接口的作用是对PL侧的IP core通过AXI-Lite总线进行配置,如果不仅需要的话直接不使能即可。 图片 图片 三、AXI DMA IP简介 ZYNQ提供了两种DMA,一种是集成在PS中的硬核DMA,另一种是PL中使用的软核AXI DMA IP。 AXI DMA IP核在AXI4-Stream IP接口之间提供高带宽直接存储访问。其可选的scatter gather(SG,链式相关)功能还可以从基于处理器的系统中的中央处理单元(CPU)卸载数据搬运任务。初始化、状态和管理寄存器通过AXI-Lite从接口访问(即数据发出方为PL,PS为Slave),核心功能组成为(这张图很有助于理解DMA中断以及SDK代码,下面会解释): 图片 原图位于AXI_DMA数据手册的第五页。 AXI DMA使用了三种总线,分别是: (1)、AXI Memory Map,用于内存交互,AXI4 Memory Map Read用于从DMA读取,AXI4 Memory Map用于向DMA写入。 (2)、AXI4-Lite同于对寄存器的配置。 (3)、AXI4-Stream接口用于对外设的读写,S2MM(Stream to Memory Mapped,数据流向内存映射)用于对外设读取。AXI_MM2S和AXI_S2MM是AXI_Stream总线,可以发送和接收连续的数据流,无需地址。 AXI DMA提供3种模式: (1)、Direct Register模式:用于在MM2S和S2MM通道上执行简单的DMA传输,小的FPGA资源少。有两个通道:一个从Device到DMA,另一个从DMA到Device。应用程序必须设置缓冲区地址和长度字段以启动相应通道中的传输。 (2)、Scatter/Gather模式:允许在单个DMA事务中将数据传输到多个存储区域传输数据。 (3)、Cyclic DMA模式: 四、AXI DMA参数与接口分析 图片 1、接口分析: (1)、M_AXI_MM2S:DMA的读通道,从DDR中读取数据。受Enable Read Channel控制,表现为M_AXI_MM2S。 (2)、M_AXI_S2MM:DMA的写通道,将数据写入DDR中。受Enable Write Channel控制,表现为M_AXI_S2MM。 (3)、M_AXIS_MM2S:DMA将数据发送到具有stream接口IP。 (4)、S_AXIS_S2MM:DMA将数据从具有Stream接口的IP中将数据读入。 (5)、mm2s_introut:DMA将数据从DDR的映射单元中读出,然后将数据发送到具有Stream接口的IP完成信号。 (6)、s2mm_introut:DMA将数据从具有stream接口的IP中读入,并写入到内存映射单元的完成中断信号。 2、参数分析 图片 (1)、Enable Scatter Gatter Engine 链式DMA操作,取消选中该选项可启用directregister模式操作。 (2)、Enable Micro DMA 改选项会生成高度优化的DMA,资源数量较少,用于传输极少量数据的应用程序。 (3)、Width of Buffer Length Register 根据IP手册pg021,在direct register模式下,此整数值用于指定控制字段缓冲区长度的有效位数,字节数等于2^(width),即字节读取和字节写入的有效长度都是2^(width)。比如宽度设置为26,可传输的字节数为2^(26)字节。(pg021,78页)。 (4)、Address Width 指定地址空间的宽度,默认32。 (5)、Enable Read Channel Memory Map Data Width:AXI MM2S存储映射读取总线的数据位宽,可为32、64、128、256、512、1024。 Stream Data Width:AXI MM2S AXI-Stream数据总线的位宽,该值必须小于等于Memory Map Data Width,可以为8、16、32、64、128、512、1024。 Max Burst Size:最大突发长度设置,指定的是MM2S的AXI4-Memory Map侧的突发周期的最大值,可为2、4、8、16、32、64、128、256。 (6)、Enable Write channel:同Read channel。 3、关于中断的理解 (1)、M_AXI_MM2S:DMA的读通道,从DDR中读取数据。受Enable Read Channel控制,表现为M_AXI_MM2S。 在AXI_DMA ip core的输出信号中,有两个中断信号,分别是s2mm_introut和mm2s_introut,mm指的是Memory Mapped,S指的是Stream。 Memory Map指的是什么?根据AXI DMA的介绍,AXI DMA提供一个介于AXI4 Memory Mapped 与AXI4 Stream IP之间的高带宽DMA: 原话位于IP参考的page5: The AXI DirectMemory Access (AXI DMA) IP core provides high-bandwidth direct memory accessbetween the AXI4 memory mapped and AXI4-Stream IP interfaces. 所以,对于DMA来说,S2MM,就是Stream形式的数据到达DDR映射空间,具体的实现方式是Stream数据流先进入DMA,之后再从DMA到Memeory Mapped。 MM2S是Memory Mapped将数据送入具有AXI Stream接口的IP。 从这里分析mm2s_introut与s2mm_introut信号的区别是分析不出来的,因为数据都是先到DMA,再从DMA发送出去。 在第5页还有一张图,讲述AXI DMA的架构: 图片 分析这张图,DDR内存映射空间的读写都是通过AXI4Memory Map完成的,也就是说s2mm与mm2s的重点不在PS DDR侧,重点在PL侧,当Stream接口的数据将输出传到DMA时候,这个过程叫做DMA的接收,DMA将映射单元的数据写到stream接口的IP,这个过程叫做DMA的发送。 所以!也就可以理解在SDK中将s2mm_introut定义为DMA接收中断,将mm2s_introut定义为发送中断了! 所以以下语句就很容易理解了: // DMA接收通道的中断ID define RX_INTR_ID XPAR_FABRIC_AXIDMA_0_S2MM_INTROUT_VEC_ID define TX_INTR_ID XPAR_FABRIC_AXIDMA_0_MM2S_INTROUT_VEC_ID Xilinx FPGA里面的AXI DMA IP核的简单用法 在FPGA里面,AXI DMA这个IP核的主要作用,就是在Verilog语言和C语言之间传输大批量的数据,使用的通信协议为AXI4-Stream。 Xilinx很多IP核都是基于AXI4-Stream协议的,例如浮点数Floating-point IP核,以及以太网Tri Mode Ethernet MAC IP核。要想将Verilog层面的数据搬运到C语言里面处理,就要使用DMA IP核。 本文以浮点数Floating-point IP核将定点数转换为浮点数为例,详细讲解AXI DMA IP核的使用方法。 浮点数IP核的输入输出数据都是32位,协议均为AXI4-Stream。C语言程序首先将要转换的定点数数据通过DMA发送给浮点数IP核,浮点数IP核转换完成后再通过DMA将单精度浮点数结果发回C语言程序,再通过printf打印出来。 定点数的数据类型为int,小数点定在第四位上,即:XXXXXXX.X。整数部分占28位,小数部分占4位。 转换后浮点数的数据类型为float,可以用printf的%f直接打印出来。 工程下载地址:https://pan.baidu.com/s/1SXppHMdhroFT8vGCIysYTQ(提取码:u7wf) MicroBlaze C语言工程的建法不再赘述,请参阅:https://blog.csdn.net/ZLK1214/article/details/111824576 以读写Floating-point IP核数据为例 图片 首先添加Floating-point IP核,作为DMA的外设端:(主存端为BRAM) 图片 图片 图片 图片 这里要注意一下,一定要勾选上TLAST,否则DMA接收端会出现DMA Internal Error的错误: 图片 下面是Xilinx DMA手册里面对DMA Internal Error错误的描述: 图片 添加AXI DMA IP核: 图片 IP核添加好了,但还没有连线: 图片 点击Run Connection Automation,自动连接DMA的S_AXI_LITE接口: 图片 图片 图片 图片 图片 自动连接浮点数IP核的时钟引脚: 图片 图片 图片 图片 图片 添加BRAM控制器: 图片 图片 最终的连线结果: 图片 修改新建的BRAM的容量为64KB: 图片 图片 最终的地址分配方式: 图片 保存Block Design,然后生成Bitstream: 图片 Bitstream生成后,导出xsa文件: 图片 Vitis Platform工程重新导入xsa文件: 图片 图片 修改C程序(helloworld.c)的代码: (这里面XPAR_BRAM_2_BASEADDR最好改成0xc0000000,因为生成的xparameters.h配置文件里面BRAM号可能有变化) /* * helloworld.c: simple test application * * This application configures UART 16550 to baud rate 9600. * PS7 UART (Zynq) is not initialized by this application, since * bootrom/bsp configures it to baud rate 115200 * * ------------------------------------------------ * | UART TYPE BAUD RATE | * ------------------------------------------------ * uartns550 9600 * uartlite Configurable only in HW design * ps7_uart 115200 (configured by bootrom/bsp) */ #include <stdio.h> #include <xaxidma.h> #include "platform.h" // DMA无法通过AXI Interconnect访问Microblaze本身的BRAM内存 // 只能访问挂接在AXI Interconnect上的内存 #define _countof(arr) (sizeof(arr) / sizeof(*(arr))) typedef struct { int numbers_in[40]; float numbers_out[40]; } BRAM2_Data; static BRAM2_Data *bram2_data = (BRAM2_Data *)XPAR_BRAM_2_BASEADDR; static XAxiDma xaxidma; int main(void) { int i, ret = 0; XAxiDma_Config *xaxidma_cfg; init_platform(); printf("Hello World\n"); printf("Successfully ran Hello World application\n"); // 初始化DMA xaxidma_cfg = XAxiDma_LookupConfig(XPAR_AXIDMA_0_DEVICE_ID); XAxiDma_CfgInitialize(&xaxidma, xaxidma_cfg); ret = XAxiDma_Selftest(&xaxidma); if (ret != XST_SUCCESS) { printf("XAxiDma_Selftest() failed! ret=%d\n", ret); goto err; } // 初始化DMA的输入数据 printf("numbers_in=%p, numbers_out=%p\n", bram2_data->numbers_in, bram2_data->numbers_out); for (i = 0; i < _countof(bram2_data->numbers_in); i++) { bram2_data->numbers_in[i] = 314 * (i + 1); if (i & 1) bram2_data->numbers_in[i] = -bram2_data->numbers_in[i]; } // DMA开始发送数据 (Length参数的单位为字节) ret = XAxiDma_SimpleTransfer(&xaxidma, (uintptr_t)bram2_data->numbers_in, sizeof(bram2_data->numbers_in), XAXIDMA_DMA_TO_DEVICE); if (ret != XST_SUCCESS) { printf("XAxiDma_SimpleTransfer(XAXIDMA_DMA_TO_DEVICE) failed! ret=%d\n", ret); goto err; } // DMA开始接收数据 ret = XAxiDma_SimpleTransfer(&xaxidma, (uintptr_t)bram2_data->numbers_out, sizeof(bram2_data->numbers_out), XAXIDMA_DEVICE_TO_DMA); if (ret != XST_SUCCESS) { printf("XAxiDma_SimpleTransfer(XAXIDMA_DEVICE_TO_DMA) failed! ret=%d\n", ret); goto err; } // 等待DMA发送完毕 i = 0; while (XAxiDma_Busy(&xaxidma, XAXIDMA_DMA_TO_DEVICE)) { i++; if (i == 200000) { // 必须确保DMA访问的内存是直接挂接在AXI Interconnect上的 // 否则这里会报DMA Decode Error的错误 (the address request points to an invalid address) printf("DMA Tx timeout! DMASR=0x%08lx\n", XAxiDma_ReadReg(xaxidma.RegBase + XAXIDMA_TX_OFFSET, XAXIDMA_SR_OFFSET)); goto err; } } printf("DMA Tx complete!\n"); // 等待DMA接收完毕 i = 0; while (XAxiDma_Busy(&xaxidma, XAXIDMA_DEVICE_TO_DMA)) { i++; if (i == 200000) { // floating-point IP核的配置里面一定要把A通道的tlast复选框勾选上, 使输入端和输出端都有tlast信号 // 否则s_axis_s2mm_tlast一直为0, DMA以为数据还没接收完, 就会报DMA Internal Error的错误 // (the incoming packet is bigger than what is specified in the DMA length register) printf("DMA Rx timeout! DMASR=0x%08lx\n", XAxiDma_ReadReg(xaxidma.RegBase + XAXIDMA_RX_OFFSET, XAXIDMA_SR_OFFSET)); goto err; } } printf("DMA Rx complete!\n"); err: for (i = 0; i < _countof(bram2_data->numbers_out); i++) printf("numbers_out[%d]=%f\n", i, bram2_data->numbers_out[i]); cleanup_platform(); return 0; }C程序的运行结果: 图片 图片 接下来讲一下我们刚才禁用掉的Scatter Gather接口的用法。取消禁用后,之前的C代码就不能运行了。 之前没有启用Scatter Gather的时候,我们一次只能提交一个DMA请求,等这个DMA请求的数据传输完毕后,我们才能提交下一个DMA传输请求。 有了Scatter Gather接口,我们就可以一次性提交很多很多DMA请求,然后CPU去干其他的事情。这可以大大提高传输效率。 除此以外,Scatter Gather还可以将多个位于不同内存地址的缓冲区合并成一个AXI4-Stream数据包传输。 下面的示例演示了如何利用Scatter Gather功能批量收发3组数据包。 启用了Scatter Gather后,DMA里面多出了一个M_AXI_SG接口,点击Run Connection Automation,连接到AXI Interconnect上: 图片 图片 Vivado工程Generate Bitstream,然后导出xsa文件。回到Vitis后,必须把Platform工程删了重建,不然XPAR_AXI_DMA_0_INCLUDE_SG的值得不到更新。 图片 图片 图片 原有的C程序不再可用,修改一下程序代码: /* * helloworld.c: simple test application * * This application configures UART 16550 to baud rate 9600. * PS7 UART (Zynq) is not initialized by this application, since * bootrom/bsp configures it to baud rate 115200 * * ------------------------------------------------ * | UART TYPE BAUD RATE | * ------------------------------------------------ * uartns550 9600 * uartlite Configurable only in HW design * ps7_uart 115200 (configured by bootrom/bsp) */ #include <stdio.h> #include <xaxidma.h> #include "platform.h" /* Xilinx的官方例程:C:\Xilinx\Vitis\2020.1\data\embeddedsw\XilinxProcessorIPLib\drivers\axidma_v9_11\examples\xaxidma_example_sg_poll.c */ // DMA无法通过AXI Interconnect访问Microblaze本身的BRAM内存 // 只能访问挂接在AXI Interconnect上的内存 #define _countof(arr) (sizeof(arr) / sizeof(*(arr))) typedef struct { int numbers_in[40]; float numbers_out[40]; } BRAM2_Data; typedef struct { uint8_t txbuf[640]; uint8_t rxbuf[640]; } BRAM2_BdRingBuffer; static BRAM2_Data *bram2_data = (BRAM2_Data *)0xc0000000; static BRAM2_BdRingBuffer *bram2_bdringbuf = (BRAM2_BdRingBuffer *)0xc0008000; static XAxiDma xaxidma; int main(void) { int i, n, ret = 0; XAxiDma_Bd *bd, *p; XAxiDma_BdRing *txring, *rxring; XAxiDma_Config *cfg; init_platform(); printf("Hello World\n"); printf("Successfully ran Hello World application\n"); // 初始化DMA cfg = XAxiDma_LookupConfig(XPAR_AXIDMA_0_DEVICE_ID); XAxiDma_CfgInitialize(&xaxidma, cfg); ret = XAxiDma_Selftest(&xaxidma); if (ret != XST_SUCCESS) { printf("XAxiDma_Selftest() failed! ret=%d\n", ret); goto err; } if (!XAxiDma_HasSg(&xaxidma)) { printf("XPAR_AXI_DMA_0_INCLUDE_SG=%d\n", XPAR_AXI_DMA_0_INCLUDE_SG); printf("Please recreate and build Vitis platform project!\n"); goto err; } // 初始化DMA的输入数据 printf("[0] numbers_in=%p, numbers_out=%p\n", bram2_data[0].numbers_in, bram2_data[0].numbers_out); printf("[1] numbers_in=%p, numbers_out=%p\n", bram2_data[1].numbers_in, bram2_data[1].numbers_out); printf("[2] numbers_in=%p, numbers_out=%p\n", bram2_data[2].numbers_in, bram2_data[2].numbers_out); for (i = 0; i < _countof(bram2_data[0].numbers_in); i++) { bram2_data[0].numbers_in[i] = 314 * (i + 1); bram2_data[1].numbers_in[i] = -141 * (i + 1); bram2_data[2].numbers_in[i] = -2718 * (i + 1); if (i & 1) { bram2_data[0].numbers_in[i] = -bram2_data[0].numbers_in[i]; bram2_data[1].numbers_in[i] = -bram2_data[1].numbers_in[i]; bram2_data[2].numbers_in[i] = -bram2_data[2].numbers_in[i]; } } // 配置DMA发送描述符 txring = XAxiDma_GetTxRing(&xaxidma); n = XAxiDma_BdRingCntCalc(XAXIDMA_BD_MINIMUM_ALIGNMENT, sizeof(bram2_bdringbuf->txbuf)); ret = XAxiDma_BdRingCreate(txring, (uintptr_t)bram2_bdringbuf->txbuf, (uintptr_t)bram2_bdringbuf->txbuf, XAXIDMA_BD_MINIMUM_ALIGNMENT, n); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingCreate(txring) failed! ret=%d\n", ret); goto err; } printf("BdRing Tx count: %d\n", n); ret = XAxiDma_BdRingAlloc(txring, 3, &bd); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingAlloc(txring) failed! ret=%d\n", ret); goto err; } p = bd; for (i = 0; i < 3; i++) { XAxiDma_BdSetBufAddr(p, (uintptr_t)bram2_data[i].numbers_in); XAxiDma_BdSetLength(p, sizeof(bram2_data[i].numbers_in), txring->MaxTransferLen); XAxiDma_BdSetCtrl(p, XAXIDMA_BD_CTRL_TXSOF_MASK | XAXIDMA_BD_CTRL_TXEOF_MASK); XAxiDma_BdSetId(p, i); p = (XAxiDma_Bd *)XAxiDma_BdRingNext(txring, p); } ret = XAxiDma_BdRingToHw(txring, 3, bd); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingToHw(txring) failed! ret=%d\n", ret); goto err; } // 配置DMA接收描述符 rxring = XAxiDma_GetRxRing(&xaxidma); n = XAxiDma_BdRingCntCalc(XAXIDMA_BD_MINIMUM_ALIGNMENT, sizeof(bram2_bdringbuf->rxbuf)); ret = XAxiDma_BdRingCreate(rxring, (uintptr_t)bram2_bdringbuf->rxbuf, (uintptr_t)bram2_bdringbuf->rxbuf, XAXIDMA_BD_MINIMUM_ALIGNMENT, n); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingCreate(rxring) failed! ret=%d\n", ret); goto err; } printf("BdRing Rx count: %d\n", n); ret = XAxiDma_BdRingAlloc(rxring, 3, &bd); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingAlloc(rxring) failed! ret=%d\n", ret); goto err; } p = bd; for (i = 0; i < 3; i++) { XAxiDma_BdSetBufAddr(p, (uintptr_t)bram2_data[i].numbers_out); XAxiDma_BdSetLength(p, sizeof(bram2_data[i].numbers_out), rxring->MaxTransferLen); XAxiDma_BdSetCtrl(p, 0); XAxiDma_BdSetId(p, i); p = (XAxiDma_Bd *)XAxiDma_BdRingNext(rxring, p); } ret = XAxiDma_BdRingToHw(rxring, 3, bd); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingToHw(rxring) failed! ret=%d\n", ret); goto err; } // 开始发送数据 ret = XAxiDma_BdRingStart(txring); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingStart(txring) failed! ret=%d\n", ret); goto err; } // 开始接收数据 ret = XAxiDma_BdRingStart(rxring); if (ret != XST_SUCCESS) { printf("XAxiDma_BdRingStart(rxring) failed! ret=%d\n", ret); goto err; } // 等待收发结束 n = 0; while (n < 6) { // 检查发送是否结束 ret = XAxiDma_BdRingFromHw(txring, XAXIDMA_ALL_BDS, &bd); if (ret != 0) { n += ret; p = bd; for (i = 0; i < ret; i++) { printf("DMA Tx%lu Complete!\n", XAxiDma_BdGetId(p)); p = (XAxiDma_Bd *)XAxiDma_BdRingNext(txring, p); } ret = XAxiDma_BdRingFree(txring, ret, bd); if (ret != XST_SUCCESS) printf("XAxiDma_BdRingFree(txring) failed! ret=%d\n", ret); } // 检查接收是否结束 ret = XAxiDma_BdRingFromHw(rxring, XAXIDMA_ALL_BDS, &bd); if (ret != 0) { n += ret; p = bd; for (i = 0; i < ret; i++) { printf("DMA Rx%lu Complete!\n", XAxiDma_BdGetId(p)); p = (XAxiDma_Bd *)XAxiDma_BdRingNext(rxring, p); } ret = XAxiDma_BdRingFree(rxring, ret, bd); if (ret != XST_SUCCESS) printf("XAxiDma_BdRingFree(rxring) failed! ret=%d\n", ret); } } err: for (i = 0; i < _countof(bram2_data[0].numbers_out); i++) printf("numbers_out[%d]=%f,%f,%f\n", i, bram2_data[0].numbers_out[i], bram2_data[1].numbers_out[i], bram2_data[2].numbers_out[i]); cleanup_platform(); return 0; }图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
1年前
1
4,512
8
通讯等不确定性条件下设计无人机之间的安全距离
引用文章: 简介 1. 研究问题 2. 分离原理介绍 3. 安全半径设计 4. 仿真及实验验证 引用文章: Q. Quan, R. Fu and K. -Y. Cai, "How Far Two UAVs Should Be subject to Communication Uncertainties," in IEEE Transactions on Intelligent Transportation Systems, doi: 10.1109/TITS.2022.3213555. 简介 近年来,无人机技术的快速发展使得低空空域中无人机的数量爆炸增长。碰撞避免作为无人机应用的关键技术,近年来人们已经进行了大量研究,设计出各种方法使得无人机在飞行过程中与障碍物保持一定安全距离(本文将该距离称为无人机的 安全半径)。然而, 在碰撞避免相关研究中,不确定性往往是难以处理的问题。针对不确定性,主流的方法包括对不确定性进行预测,以及在闭环控制中给予补偿。然而,以上方法很依赖于预测及补偿的精准设计,设计不当将有可能导致控制器失效。本研究受地面交通中车辆间安全距离启发,基于对通信不确定性和无人机控制器性能的假设,提出了 安全半径设计和控制器设计的原则 (本文称为 分离原理 )。进一步,安全半径具体通常通过经验预先设计,如果设计得过大或过小将分别影响无人机飞行的高效性及安全性。 如何根据无人机模型及通信不确定性确定其安全半径下界仍然是悬而未决的问题 。利用分离原理,本文研究了 设计阶段(无不确定性)和飞行阶段(受不确定性影响)的无人机安全半径设计 。最后,通过仿真和实验表明了所提方法的有效性。 图片 1. 研究问题 本研究中,无人机与障碍物的运动模型均建模为多旋翼模型,换句话说,我们考虑的障碍物可以等效为另一架多旋翼飞行器。对于多旋翼飞行器而言,其可以获得自身以及障碍物的实时位置和速度。为简单描述起见,本文建模均为二维,类似的建模及分析方法可以扩展到三维情况。 我们首先建立多旋翼的具体控制模型如下。 其中多旋翼的位置和速度分别表示为 ,速度控制模型建立为一阶惯性环节,其时间常数 与无人机的机动性能相关,控制输入 为期望速度。在此基础上,本文定义一种新的滤波位置模型如下。 多旋翼滤波位置的物理意义是根据多旋翼的当前位置、速度及机动能力,对其运动趋势预测。在此基础上,定义多旋翼的安全区域为以滤波位置为圆心的圆形区域,其半径称为安全半径 。对于障碍物,我们类似定义其滤波位置,以及以障碍物滤波位置为圆心的圆形障碍物区域,半径称为障碍物半径 。 图片 进一步,我们针对不确定性做了以下2点假设:(1)无人机和障碍物对自身的三维位置及三维速度估计均存在噪声;(2)无人机在获取障碍物状态信息时,存在通信延迟及丢包。该通信网络模型如下图所示。 图片 本研究中,丢包模型进一步建模为均值模型,且假设估计噪声、通信延迟、丢包均值模型误差均存在上界且上界已知。其数学定义如下: 图片 进一步,本文对无人机的控制器性能做出如下假设:(1)在无不确定性的理想状态下,无人机的控制器可以使无人机和障碍物之间的 真实距离 始终大于给定安全距离;(2)在存在以上不确定性的实际情况中,无人机的控制器可以使无人机和障碍物之间的 估计距离 始终保持给定安全距离。本研究的具体目标是在不确定性上界已知的条件下计算出无人机安全半径的下界。 图片 2. 分离原理介绍 无人机在理想状态下设计的控制器中给定的安全半径值 ,在实际含有不确定性的环境中将转化为估计安全半径 ;直观上理解,将含有不确定性的无人机与障碍物之间的估计位置误差代替真实位置误差作为反馈时,控制器将难以维持给定的安全半径。本研究中, 分离原理具体研究的是不确定性在满足什么条件时无人机的控制器设计和安全半径设计过程可分离 ,也就是估计安全半径和安全半径相等, 成立。分离原理具体数学描述如下: 图片 分离原理中提出的三个条件包括一个充分必要条件(i)以及两个充分条件(ii)和(iii)。其中,条件(i)为理论推导,在实际中难以得到验证,通常可通过条件(ii)和(iii)进行验证。条件(ii)对无人机速度的限制较宽,该式在障碍物主动躲避无人机的条件下容易达成。反之,条件(iii)对无人机速度的限制较苛刻,要求无人机速度严格大于障碍物速度,适用于在障碍物不主动躲避无人机的情况下。以上两种情况的区别如下图所示。 图片 3. 安全半径设计 根据上述分离原理的提出,在分离原理满足的前提下,基于无人机的安全半径模型和通信网络模型,可以进一步设计 合适大小的无人机安全半径 。如前文所述,安全半径设计过大会增加环境的冗余度,设计过小则无法保证飞行过程的安全。在本研究中,给出了在理想情况下以及实际情况下安全半径的下界,分别如下: 图片 4. 仿真及实验验证 仿真及实验验证在仿真中,我们针对单障碍物、多非合作障碍物、多合作障碍物设计了三种场景来验证我们方法的有效性。在实验中,我们使用DJI tello无人机对以上情况进行测试,结果与我们的理论一致。实验视频: https://youtu.be/LkSDPFGa_1E 论文地址 https://rfly.buaa.edu.cn/pdfs/2022/How_far_two_UAVs_should_be_subject_to_communication_uncertainties.pdf
软硬件算法
# 软件算法
刘航宇
2年前
0
940
1
2024-01-20
机器学习/深度学习-训练过程讲解acc/loss/val_acc/val_loss分析
计算loss是会把所有loss层的loss相加。 那么如何选取一个较为理想的medel? 单独观察训练集loss曲线 loss出现NAN 联合观察loss曲线和acc TensorFlow中loss与val_loss、accuracy和val_accuracy含义 震荡修复 计算loss是会把所有loss层的loss相加。 从验证集误差是和测试集误差的角度分析 其实你这个问题就是个伪命题,如果我们刻意的去在训练集上拟合模型,使其准确率达到很高的高度,或者说尽量在验证集合上表现的好,都是相悖的。 因为我们不能为了某一特定数据集来刻意拟合,因为模型预测数据是不一定就在这个训练或者验证集合的空间中。 还有,如果这个model预测集合acc20% 训练集合acc19% (即训练集精度低于测试集精度),那么这个模型肯定是不好的。 还有一点需要注意,就是千万不能为了拟合测试集合而去更改模型,测试集合应该每次都有不同。 那么如何选取一个较为理想的medel? 首先,要有一个期望的准确率,通过不同模型的实验,找到最能接近的; 然后,选定模型后进行参数调优; 那么我们要尽可能的提高model的准确率,同时提高其泛化的能力,不能单一看某一指标,此时可参考 准确率、召回率、虚警率、F1Score等指标综合评判。或者采用多重验证随机划分训练、预测、验证集合,多次随机后找到最优参数。 有时候训练集合误差很低,但是泛化能力极差,产生过拟合, 有时候验证集合误差很低,但是可能验证集合无法代表所有的样本,有特殊性或者其他异常点较多。 所以模型问题不能单一从你这两点来评判。 一般而言,训练集loss < 验证集loss <测试集loss 因为网络 [已见过] 所有训练集samples,故最低。而网络用验证集作为反馈来调节参数,相当于参考了验证集samples中的信息(间接 [已见过])。又因为网络没有任何测试集的信息,所以测试结果一般而言最差。 不过这都不是绝对的,有不符合这个一般现象的task,而我们不可以说哪种情况更“好”。 多数情况验证集上错误率更低一点。因为是选择在验证集上准确率最高的模型来进行测试。考虑到数据的随机性,在验证集上准确率最高的模型在测试集上不一定是最高的,所以算出来的指标通常验证集会比测试集上好一点。 但是实际情况下都有可能,特别是数据量不太大的时候。样本集合的数据也只是近似整体的分布,肯定会有波动。 一个好的网络,二者的差距应该是很低的。但一般情况下因为网络不可避免地存在一定程度上的过拟合,所以肯定是train_loss低于test_lost,但如果低太多,就得考虑是过拟合的问题还是因为样本的特征空间不统一的问题。 一般训练集不大时,最终训练的网络及容易过拟合,也就是说train-loss一定会收敛,但是test-loss不会收敛; 训练时的loss会低于test的loss大概1~2个数量级,通常是10倍左右。 单独观察训练集loss曲线 1)如果你的 learning_rate_policy 是 step 或者其他变化类型的话, loss 曲线可以帮助你选择一个比较合适的 stepsize; 2)如果loss曲线表现出线性(下降缓慢)表明学习率太低; 3)如果loss不再下降,表明学习率太高陷入局部最小值; 4)曲线的宽度和batch size有关,如果宽度太宽,说明相邻batch间的变化太大,应该减小batch size。 可能导致不收敛的问题(如loss为87.3365,loss居高不下等)的解决方案 1)在caffe中可以在solver里面设置:debug_info: true,看看各个层的data和diff是什么值,一般这个时候那些值不是NAN(无效数字)就是INF(无穷大); 2)检查数据标签是否从0开始并且连续; 3)把学习率base_lr调低; 4)数据问题,lmdb生成有误; 5)中间层没有归一化,导致经过几层后,输出的值已经很小了,这个时候再计算梯度就比较尴尬了,可以尝试在各个卷积层后加入BN层和SCALE层; 5)把base_lr调低,然后batchsize也调高; 6)把data层的输入图片进行归一化,就是从0-255归一化到0-1,使用的参数是: transform_param { scale: 0.00390625//像素归一化,1/255 } 7)网络参数太多,网络太深,删掉几层看看,可能因为数据少,需要减少中间层的num_output; 8)记得要shuffle数据,否则数据不够随机,几个batch之间的数据差异很小。 loss出现NAN 1)观察loss值的趋势,如果迭代几次以后一直在增大,最后变成nan,那就是发散了,需要考虑减小训练速率,或者是调整其他参数。 2)数据不能太少,如果太少的话很容易发散" 3)Gradient Clipp 处理gradient之后往后传,一定程度上解决梯度爆炸问题。(但由于有了batch normalization,此方法用的不多) 4)原因可能是训练的时间不够长。 5)可以看一下训练时,网络参数的L2或L1 联合观察loss曲线和acc 1)单独的 loss 曲线能提供的信息很少的,一般会结合测试机上的 accuracy 曲线来判断是否过拟合; 2)关键是要看你在测试集上的acc如何; 3)可以把accuracy和loss的曲线画出来,方便设定stepsize,一般在accuracy和loss都趋于平缓的时候就可以减小lr了; 4)看第一次test时(即iteration 0),loss和精度,如果太差,说明初始点的设置有问题 5)使用caffe时,train时,看见的loss是训练集的;accuracy才是测试集的 6)所谓的过拟合是:loss下降,accuracy也下降 TensorFlow中loss与val_loss、accuracy和val_accuracy含义 图片 loss:训练集损失值 accuracy:训练集准确率 val_loss:测试集损失值 val_accruacy:测试集准确率 以下5种情况可供参考: train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的) train loss 不断下降,test loss趋于不变,说明网络过拟合;(max pool或者正则化) train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset) train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率) train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。(最不好的情况) 震荡修复 验证集曲线震荡 图片 分析原因:训练的batch_size太小 目前batch_size = 64,改成128: 图片 改成200: 图片 可见,增大batch_size 变大,震荡逐渐消失,同时在测试集的acc也提高了。batch_size为200时,训练集acc小于测试集,模型欠拟合,需要继续增大epoch。 总结 增大batchsize的好处有三点: 1)内存的利用率提高了,大矩阵乘法的并行化效率提高。 2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快,但是达到相同精度所需要的epoch数量也越来越多。由于这两种因素的矛盾, batch_Size 增大到某个时候,达到时间上的最优。 3)一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小。 盲目增大的坏处: 1)当数据集太大时,内存撑不住。 2)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。 3)batchsize增大到一定的程度,其确定的下降方向已经基本不再变化。 4)太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。 5)具体的batch size的选取和训练集的样本数目相关。
机器学习
# 机器学习
刘航宇
2年前
0
3,139
2
泛化能力,过拟合,欠拟合,不收敛,奥卡姆剃刀
泛化能力 欠拟合过拟合与不收敛 解决手段一、模型训练拟合的分类和表现 二、欠拟合 三、过拟合 总结: 泛化能力 泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力,简而言之是在原有的数据集上添加新的数据集,通过训练输出一个合理的结果。学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。 欠拟合过拟合与不收敛 用比较直白的话来讲,就是通过数据训练学习的模型,拿到真实场景去试,这个模型到底行不行,如果达到了一定的要求和标准,它就是行,说明泛化能力好,如果表现很差,说明泛化能力就差。为了更好的理解泛化能力,这里引入三种现象,欠拟合、过拟合以及不收敛。 欠拟合(under-fitting),是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。即,在训练数据集上表现差,在测试集数据也表现差。 过拟合(over-fitting),是指模型在训练集上表现很好,在测试集上效果差。 不收敛(non-convergence),指误差函数一直在振荡,不能趋近一个定值,没有找到局部或者全局最小值。 举个例子来说明下,好比高考数学考试,为了在高考能有个好成绩,高一到高三,好多人会采用“题海战术”来训练自己的做题能力,但高考试卷上的题,都是新题,几乎没有一模一样的题,学生们为了掌握解题规律就不停的刷题,希望最后自己碰到类似的题,能够举一反三,能学以致用,这种规律掌握的适用性,就是泛化能力。 有的人对相似题型的解题规律掌握的很好,并且解题效果也很好,这种就是泛化能力强,这种同学往往数学成绩就好。 有的同学成绩不好,就是泛化能力差,可能有三种情况 1.做了不少题,但没有找到解题规律,不管碰到老题和新题都不会做,这种就是欠拟合。 2.做了很多题,自认为做过的每一类题型的解题规律都掌握了,而且在之前“题海战术”的题目中,确实表现的很好,但是一碰到新的题目,完全就不会,或者做错,这种学生就是那种喜欢死记硬背的,这种就是过拟合。 3.平常也不做题,然后每次一做题就瞎蒙,导致偶尔对,偶尔错,这种就是不收敛。 为了更直观展示,引用了几张图来说明,如下图所示,真实曲线是正弦曲线,蓝色的点是训练数据,红色的线为拟合曲线。 图片 图片 解决手段 在深度学习的模型建立过程中,一般都是用已经产生的数据训练,然后使用训练得到的模型去拟合未来的数据,借此来预测一些东西。在机器学习和深度学习的训练过程中,经常会出现欠拟合和过拟合的现象。训练一开始,模型通常会欠拟合,所以会对模型进行优化,等训练到一定程度后,就需要解决过拟合的问题了。 一、模型训练拟合的分类和表现 如何判断过拟合呢?我们在训练的时候会定义训练误差,验证集误差,测试集误差(即泛化误差)。训练误差总是减少的,而泛化误差一开始会减少,到了一定程度后不减少反而开始增加,这时候便出现了过拟合的现象。 如下图,直观理解,欠拟合就是还没有学习到数据的特征,还有待继续学习,所以此时判断的不准确;而过拟合则是学习的太彻底,以至于把数据的一些不需要的局部特征或者噪声所带来的特征都给学习到了,所以在测试的时候泛化误差也不佳。 图片 从方差和偏差的角度来说,欠拟合就是在训练集上高方差,高偏差,过拟合就是高方差,低偏差。为了更加直观,我们看下面的图 图片 对比上图,图一的拟合并没有把大体的规律给拟合出来,拟合效果不好,这个就是欠拟合,还需要继续学习规律,此时模型简单;图三的拟合过于复杂,拟合的过于细致,以至于拟合了一些没有必要的东西,这样在训练集上效果很好,但放到测试集和验证集就会不好。图二是最好的,把数据的规律拟合出来了,也没有更复杂,更换数据集后也不会效果很差。 在上面的拟合函数中,可以想到,图三过拟合的拟合函数肯定是一个高次函数,其参数个数肯定比图二多,可以说图三的拟合函数比图二要大,模型更加复杂。这也是过拟合的一个判断经验,模型是否过于复杂。另外针对图三,我们把一些高次变量对应的参数值变小,也就相当于把模型变简单了。从这个角度上讲,可以减少参数值,也就是一般模型过拟合,参数值整体比较大。从模型复杂性上讲,可以是: ——模型的参数个数; ——模型的参数值的大小。 个数越多,参数值越大,模型越复杂。 二、欠拟合 欠拟合的表现 有什么方法来判断模型是否欠拟合呢?其实一般都是依靠模型在训练集和验证集上的表现,有一个大概的判断就行了。如果要有一个具体的方法,可以参考机器学中,学习曲线来判断模型是否过拟合,如下图: 图片 欠拟合的解决方案 (1)增加数据特征:欠拟合是由于学习不足导致的,可以考虑添加特征,从数据中挖掘更多的特征,有时候嗨需要对特征进行变换,使用组合特征和高次特征; (2)使用更高级的模型:模型简单也会导致欠拟合,即模型参数过少,结构过于简单,例如线性模型只能拟合一次函数的数据。尝试使用更高级的模型有助于解决欠拟合,增加神经网络的层数,增加参数个数,或者使用更高级的方法; (3)减少正则化参数:正则化参数是用来防止过拟合的,出现欠拟合的情况就要考虑减少正则化参数。 三、过拟合 过拟合的定义 模型在训练集上表现好,但在测试集和验证集上表现很差,这就是过拟合 图片 过拟合的原因 (1)数据量太小 这是很容易产生过拟合的原因。设想我们有一组数据很好的满足了三次函数的规律,但我们只取了一小部分数据进行训练,那么得到的模型很可能是一个线性函数,把这个线性函数用于测试集上,可想而知肯定效果很差。(此时训练集上效果好,测试集效果差) (2)训练集和验证集分布不一致 这也是很大一个原因。训练集上训练出来的模型适合训练集,当把模型应用到一个不一样分布的数据集上,效果肯定大打折扣,这个是显而易见的。 (3)网络模型过于复杂 选择模型算法时,选择了一个复杂度很高的模型,然而数据的规律是很简单的,复杂的模型反而不适用了。 (4)数据质量很差 数据有很多噪声,模型在学习的时候,肯定也会把噪声规律学习到,从而减少了一般性的规律。这个时候模型预测效果也不好。 (5)过度训练 这是同第四个相联系的,只要模型训练时间足够长,那么模型肯定会把一些噪声隐含的规律学习到,这时候降低模型的性能也是显而易见的。 解决方法 (1)降低模型复杂度 处理过拟合的第一步就是降低模型复杂度。为了降低复杂度,我们可以简单地移除层或者减少神经元的数量使得网络规模变小。与此同时,计算神经网络中不同层的输入和输出维度也十分重要。虽然移除层的数量或神经网络的规模并无通用的规定,但如果你的神经网络发生了过拟合,就尝试缩小它的规模。 (2)数据集扩增 在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。 通俗的讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法: ——从数据源头采集更多数据 ——复制原有数据加上噪声 ——重采样 ——根据当前数据集估计数据分布参数,利用该分布产生更多数据(3)数据增强 使用数据增强可以生成多幅相似图像。这可以帮助我们增加数据集从而减少过拟合。因为随着数据量的增加,模型无法过拟合所有样本,因此不得不进行泛化。计算机视觉领域通常的做法有:翻转,平移,旋转,缩放,改变亮度,添加噪声等。 (4)正则化 正则化是指在进行目标函数或者代价函数优化时,在目标函数或者代价函数后面加上一个正则项,一般有L1正则和L2正则等。 L1惩罚项的目的是使权重绝对值最小化,公式如下: 图片 L1惩罚项的目的是使权重的平方最小化,公式如下: 图片 下面对两种正则化方法进行了比较: 图片 如果数据过于复杂以致没有办法进行准确的建模,那么L2是更好的选择,因为它能够学习数据中呈现的内在模式。而当数据足够简单,可以精确建模的话,L1更合适,对于我遇到的大多数计算机视觉问题,L2正则化几乎总是可以给出最好的结果。然而L1不容易受到离群值的影响。所以正确的正则化选项取决于我们想要解决的问题。 总结: 正则项是为了降低模型的复杂度,从而避免模型过分拟合训练数据,包括噪声与异常点。从另一个角度讲,正则化即是假设模型参数服从先验概率,即为模型参数添加先验,只是不同的正则化方式的先验分布是不一样的。这样就规定了参数的分布,使得模型的复杂度降低(试想一下,限定条件多了,是不是模型的复杂度就降低了呢),这样模型对于噪声和异常点的抗干扰性的能力增强,从而提高模型的泛化能力。还有个解释,从贝叶斯学派来看,加了先验,在数据少的时候,先验知识可以防止过拟合;从频率学派来看,正则项限定了参数的取值,从而提高了模型的稳定性,而稳定性强的模型不会过拟合,即控制模型空间。 另外一个角度,过拟合从直观上理解便是,在对训练数据进行拟合时,需要照顾到每个点,从而使得拟合函数波动性非常大,即方差大。在某些小区间里,函数值的变化很剧烈,意味着函数在某些小区间的导数值的绝对值非常大,由于自变量的值在给定的训练数据集中是一定的,因为只有系数足够大,才能保证导数的绝对值足够大,如下图: 图片 另一个解释,规则化项的引入,在训练(最小化cost)的过程中,当某一维的特征所对应的权重过大时,而此时模型的预测和真实数据之间的距离很小,通过规则化项就可以使整体的cost取较大的值,从而,在训练的过程中避免了去选择了那些某一维(或几维)特征权重过大的情况,即过分依赖某一维(或几维)的特征。 L1和L2的区别是,L1正则是拉普拉斯先验,L2正则则是高斯先验。它们都是服从均值为0,协方差为1/λ。当λ=0,即没有先验,没有正则项,则相当于先验分布具有无穷大的协方差,那么这个先验约束则会非常弱,模型为了拟合拟合所有的训练集数据,参数可以变得任意大从而使得模型不稳定,即方差大而偏差小。λ越大,表明先验分布协方差越小,偏差越大,模型越稳定。即,加入正则项是在偏差bias与方差variance之间做平衡tradeoff。下图即为L2与L1正则的区别: 图片 上图中的模型是线性回归,有两个特征,要优化的参数分别是w1和w2,左图的正则化是L2,右图是L1。蓝色线就是优化过程中遇到的等高线,一圈代表一个目标函数值,圆心就是样本观测值(假设一个样本),半径就是误差值,受限条件就是红色边界(就是正则化那部分),二者相交处,才是最优参数。可见右边的最优参数只可能在坐标轴上,所以就会出现0权重参数,使得模型稀疏。 其实拉普拉斯分布和高斯分布是数学家从试验中误差服从什么分布研究得出的。一般直观上的认识是服从均值为0的对称分布,并且误差大的概率低,误差小的概率高,因为拉普拉斯使用拉普拉斯分布对误差的分布进行拟合,如下图: 图片 而拉普拉斯在最高点,即自变量为0处不可导,因为不便于计算,于是高斯在这基础上使用高斯分布对其进行拟合,如下图: 图片 (5)dropout 正则时通过再代价函数后面加上正则项来防止过拟合的。而在神经网络中,有一种方法时通过修改神经网络本身结构实现的,其名为dropout。该方法是对网络进行训练时用的一种技巧,对于如下的三层人工神经网络: 图片 对于上图所示的网络,在训练开始时,随即删除一些(可自己设定概率)隐藏层神经元,即认为这些神经元不存在,同时保持输入层和输出层的个数不变,这样便得到如下的ANN: 图片 然后按照BP学习算法对ANN中的参数进行学习更新(虚线链接的单元不更新,因为认为这些连接元被临时删除了)。这样一次迭代更新便完成了,下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择,这样一直进行,直至训练结束。 这种技术被证明可以减少很多问题的过拟合,这些问题包括图像分类,图像切割,词嵌入,语义匹配等问题。 (6)早停 对模型的训练即是对模型的参数进行更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。 Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算验证集的正确率,当正确率不再提高时,就停止训练。这种做法很符合直观感受,因为正确率都不在提高了,再继续训练也是无益的,只会提高训练的时间。如下图,在几次迭代后,即使训练误差仍然在减少,但测验误差已经开始增加了。 图片 那么该做法的一个重点便是怎样才认为验证准确率validation accurary不再提高了呢?并不是说验证准确率validation accurary一降下来便认为不再提高了,因为可能经过这个Epoch后,正确率降低了,但是随后的Epoch又让正确率又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的验证准确率validation accurary,当连续10次没达到最佳正确率时,认为不再提高了,此时便可以停止迭代。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30…… (7)重新清洗数据 把明显异常的数据剔除。 (8)使用集成学习方法 把多个模型集成在一起,降低单个模型的过拟合风险。
机器学习
# 机器学习
刘航宇
2年前
0
1,143
1
2023-12-26
AI: 机器学习必须懂的几个术语:Label、Feature、Model...
1.标签 Label 2.特征 Feature 3.样本 Example3.1有标签样本(labeled): 3.2无标签样本(unlabeled): 4.模型 Model 5.回归 Regression 6.分类 Classification 7.机器学习算法地图 1.标签 Label 标签:所预测的东东实际是什么(可理解为结论),如线性回归中的 y 变量,如分类问题中图片中是猫是狗(或图片中狗的种类)、房子未来的价格、音频中的单词等等任何事物,都属于Label。 (如一组图片,已经表明了哪些是狗,哪些是猫,这里Label就是分类问题中每一个类) 图片 2.特征 Feature 特征是事物固有属性,可理解为做出某个判断的依据,如人的特征有长相、衣服、行为动作等等,一个事物可以有N多特征,这些组成了事物的特性,作为机器学习中识别、学习的基本依据。 图片 特征是机器学习模型的输入变量。如线性回归中的 x 变量。 图片 例如在垃圾邮件分类问题中,特征可能包括: 电子邮件中是否包含 “ 广告、贷款、交易” 等短语 电子邮件文本中的字词 发件人的地址 发送电子邮件的时段 其中机器学习重要步骤:特征提取就是通过多种方式,对数据的特征数据进行提取。一般,特征数据越多,训练的机器学习模型就会越精确,但处理难度也越大。 3.样本 Example 样本是指一组或几组数据,样本一般作为训练数据来训练模型 样本分为以下两类: 有标签样本 无标签样本 3.1有标签样本(labeled): 同时包含特征和标签 图片 在监督学习中利用数据做训练时,有标签数据/样本(Labeled data)或叫有/无标记数据,就是指有没有将数据归为要预测的类别。 例如以下房价数据集: 图片 其中包含特征:卧室数量等,最右边一列是标签:房价中间值 (注,因为该问题要预测未来房价走势,所以Label就是某条房屋数据中的房价) 3.2无标签样本(unlabeled): 包含特征,但不包含标签 如以下数据集: 去掉了Label,但是一样有用(如用在测试训练后的模型,即训练好模型后,输入该数据,那到预测后的房价与原标签进行比较,得到模型误差) 图片 4.模型 Model 模型定义了特征与标签之间的关系,就是我们机器学习的一组数据关系表示,也是我们学习机器学习的核心 例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。 模型生命周期的两个重要阶段: 训练 Training是指创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。 训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值 推断 Inference是指将训练后的模型应用于无标签样本。也就是说,使用经过训练的模型做出有用的预测 (y’)。 例如,模型训练好后,就可以使用模型进行Inference ,可以针对新的无标签样本预测房价medianHouseValue。 图片 5.回归 Regression 回归就是我们数学学习的线性方程,是一种经典函数逼近算法。 在机器学习中,就是根据数据集,建立一个线性方程组,能够无线逼近数据集中的数据点,是一种基于已有数据关系实现预测的算法。 回归模型可预测连续值(线性) 例如,回归模型做出的预测可回答如下问题: 某小区房价的趋势? 用户点击此广告的概率是多少? 图片 当机器学习模型最终目标(模型输出)是求一个具体数值时,例如房价的模型输出为25000,则大多数可以通过回归问题来解决。 线性回归的好处在与模型简单,计算速度快,方便应用在分布式系统对大数据进行处理。 线性回归还有个姐妹:逻辑回归(Logistic Regression),主要应用在分类领域 6.分类 Classification 顾名思义,分类模型可用来预测离散值 例如,分类模型做出的预测可回答如下问题: 是/否问题,某个指定电子邮件是垃圾邮件还是非垃圾邮件? 图片是动物还是人? 垃圾分类 图片 当机器学习模型最终目标(模型输出)是布尔或一定范围的数时,例如判断一张图片是不是人,模型输出0/1:0不是,1是;又例如垃圾分类,模型输出1-10之间的整数,1代表生活垃圾,2代表厨余垃圾。。等等,这类需求则大多数可以通过分类问题来解决。 7.机器学习算法地图 机器学习算法多种多样,许多情况下,建模和算法设计是Designer所选择的,具体采用哪种算法也没有一定要求,根据实际具体问题具体分析。 图片
机器学习
# 机器学习
刘航宇
3年前
0
1,153
2
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
502
0
2023-11-20
超声模块HC_SR04基本原理与FPGA、STM32应用
HC-SR04硬件概述 接口定义: 模式选择: 测量操作: FPGA实现超声测距模块代码 ifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" endif / HCSR04_H_ / include "hc-sr04.h" include "hc-sr04.h" include "printf.h" HC-SR04 硬件概述 HC-SR04超声波距离传感器的核心是两个超声波传感器。一个用作发射器,将电信号转换为40 KHz超声波脉冲。接收器监听发射的脉冲。如果接收到它们,它将产生一个输出脉冲,其宽度可用于确定脉冲传播的距离。就是如此简单! 该传感器体积小,易于在任何机器人项目中使用,并提供2厘米至600厘米(约1英寸至13英尺)之间出色的非接触范围检测,精度为3mm。 图片 接口定义: 图片 模式选择: 图片 测量操作: 一:GPIO模式 图片 外部MCU给模块Trig脚一个大于10uS的高电平脉冲;模块会给出一个与距离等比的高电平脉冲信号,可根据脉宽时间“T” 算出: 距离=T*C/2 (C为声速) 声速温度公式:c=(331.45+0.61t/℃)m•s-1 (其中330.45是在0℃) 0℃声速: 330.45M/S 20℃声速: 342.62M/S 40℃声速: 354.85M/S0℃-40℃声速误差7%左右。实际应用,如果需要精确距离值,必需要考虑温度影响,做温度补偿。 二:UART模式 UART 模式波特率设置: 9600 N 1 图片 连接串口。外部MCU或PC发命令0XA0,模块完成测距后发3个返回距离 数据,BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 三:IIC模式 IIC地址: 0X57 IIC传输格式: 写数据: 图片 读数据: 图片 命令格式: 图片 向模块写入0X01,模块开始测距;等待200mS(模块最大测距时间) 以上。直接读出3个距离数据。BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 FPGA实现超声测距 本次测距教程一律按基本原理实现,至于UART、ICC测距原理可以网上查询 FPGA 产生周期性的 TRIG 脉冲信号,使得超声波模块周期性发出测距脉冲,当这些脉冲发出后遇到障碍物返回,超声波模块将返回的脉冲处理整形后返回给 FPGA,即 ECHO 信号。我们通过对 ECHO 信号的高脉冲保持时间就可以推算出超声波脉冲和障碍物之间的距离。 本实例的功能如图三所示,FPGA 产生 10us 脉冲 TRIG 给超声波测距模块,然后以 10us 为单位计算超声波测距模块返回的回响信号 ECHO 的高电平保持时间。ECHO 的高电平保持时间通过一定的换算后可以得到障碍物和超声波测距模块之间的距离(由距离公式计算&进制换算模块实现),我们将最终获得的以 mm 为单位的距离信息显示在 4 位数码管上。 图片 模块代码 1、vlg_en模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 15:24:01 * @Email: hyliu@ee.ac.cn * @Descripttion: 板子时钟转化1us * @Last Modified time: 2023-11-20 15:24:01 */ //1us/50ns=20 module vlg_1us#(parameter P_CLK_PERIORD = 50) //i_clk的时钟周期50ns,20MHZ ( input i_clk, input i_rst_n, output reg o_clk //时钟周期1us ); parameter NUM_DIV = 20;// (1MHZ = 1us,20MHZ/20 = 1MHZ) reg [3:0] cnt; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) begin cnt <= 4'd0; o_clk <= 1'b0; end else if(cnt == NUM_DIV/2 - 1) begin cnt <= 4'b0; o_clk <= ~o_clk; end else cnt <= cnt + 1'b1; end endmodule2、vlg_trig模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 16:50:44 * @Email: hyliu@ee.ac.cn * @Descripttion: 产生10us的触发超声信号 * @Last Modified time: 2023-11-20 16:50:44 */ module vlg_trig ( input i_rst_n, input clk_1us, //1us output reg o_trig ); reg[17:0] r_tricnt; //200ms的周期计数 1us一个单位 always @(posedge clk_1us or negedge i_rst_n)begin if(!i_rst_n) r_tricnt <= 18'd0; else if((r_tricnt == 18'd199999)) r_tricnt <= 18'd0; else r_tricnt <= r_tricnt + 1'b1; end //产生保持10us的高脉冲o_tring信号 always @(posedge clk_1us or negedge i_rst_n) begin if(!i_rst_n) o_trig<=1'b0; else if((r_tricnt > 18'd0) && (r_tricnt <= 18'd10)) o_trig <= 1'b1; //不从0开始0~9,防止出现不到10us的波干扰 else o_trig <= 1'b0; end endmodule3、vlg_echo模块 module vlg_echo ( input i_clk, //1us input i_rst_n, input i_clk_1us, input i_echo, output reg[15:0] o_t_us ); reg[1:0] r_echo; wire pos_echo,neg_echo; reg r_cnt_en; reg[15:0] r_echo_cnt; //对i_echo信号同步处理,获取边沿检测信号,产生计数使能信号r_cnt_en always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_echo <= 2'd0; else r_echo <= {r_echo[0],i_echo}; //设置两个寄存器进行打拍寄存 end assign pos_echo = r_echo[0] & ~r_echo[1]; //现状态是1上状态是0,就是上升沿 assign neg_echo = ~r_echo[0] & r_echo[1]; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_cnt_en <= 1'b0; else if(pos_echo) r_cnt_en <= 1'b1; else if(neg_echo) r_cnt_en <= 1'b0; else r_cnt_en <= r_cnt_en; end //对i_echo信号的高脉冲计时,以us为单位 always @(posedge i_clk_1us or negedge i_rst_n) begin if(!i_rst_n) r_echo_cnt <= 1'b0; else if(r_cnt_en) r_echo_cnt <= r_echo_cnt + 1'b1; else r_echo_cnt <= 1'b0; end //在下降沿对计数最大值进行保存 always @(negedge i_clk or negedge i_rst_n) begin if(!i_rst_n) o_t_us <= 16'd0; else if(neg_echo) o_t_us <= r_echo_cnt; else o_t_us <= o_t_us; end endmodule 4、顶层模块例化/* @Author: Hangyu Liu @Date: 2023-11-23 17:16:40 @Email: hyliu@ee.ac.cn @Descripttion:HR04驱动模块 @Last Modified time: 2023-11-23 17:16:40 */ module vlg_design ( input i_clk, //200MHZ input i_rst_n, input i_echo, //这是超声模块给的输入 output o_trig, output wire[15:0] w_t_us); wire clk_20MHZ; clk_div_20MHZ UU( .i_clk(i_clk), .i_rst_n(i_rst_n), .clk_div(clk_20MHZ)); localparam P_CLK_PERIORD = 50; wire clk_1us; //使能时钟产生模块 vlg_1us #( .P_CLK_PERIORD(P_CLK_PERIORD) //i_clk的时钟周期50ns,20MHZ)U1( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .o_clk(clk_1us)); //产生超声波测距模块的触发信号o_trig vlg_trig U2( .i_rst_n(i_rst_n), .clk_1us(clk_1us), .o_trig(o_trig)); //超声波测距模块的回响信号i_echo的高电平时间采集 vlg_echo U3( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .i_clk_1us(clk_1us), .i_echo(i_echo), .o_t_us(w_t_us)); endmodule ## STM32(Cubemax)实现超声波测距 ### CubeMX配置STM32 1 时钟配置 这里我用的是STM32F103C8T6的核心板,时钟配置如下图,我用了8MHz的HSE,HCLK调到了最大值72MHz  2 设置输入捕获的定时器 设置定时器TIM2每1us向上计数一次,通道4为上升沿捕获并连接到超声波模块的ECHO引脚,记得开启定时器中断(涉及到捕获中断+定时器溢出中断)。  3 触发引脚 PB10接到了HC-SR04的TIRG触发引脚,默认输出低电平  4 串口配置 还要开启一个串口,以便通过串口查看测距结果  ### 编写代码 hc-sr04.hifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" typedef struct { uint8_t edge_state; uint16_t tim_overflow_counter; uint32_t prescaler; uint32_t period; uint32_t t1; // 上升沿时间 uint32_t t2; // 下降沿时间 uint32_t high_level_us; // 高电平持续时间 float distance; TIM_TypeDef* instance;uint32_t ic_tim_ch; HAL_TIM_ActiveChannel active_channel;}Hcsr04InfoTypeDef; extern Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel); /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start(); /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim); /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim); /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read(); endif / HCSR04_H_ / hc-sr04.cinclude "hc-sr04.h" Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel) { /--------[ Configure The HCSR04 IC Timer Channel ] / // MX_TIM2_Init(); // cubemx中配置 Hcsr04Info.prescaler = htim->Init.Prescaler; // 72-1 Hcsr04Info.period = htim->Init.Period; // 65535 Hcsr04Info.instance = htim->Instance; // TIM2 Hcsr04Info.ic_tim_ch = Channel; if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_1) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_1; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_2) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_2; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_3) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_3; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} /--------[ Start The ICU Channel ]-------/ HAL_TIM_Base_Start_IT(htim); HAL_TIM_IC_Start_IT(htim, Channel); } /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start() { HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_SET); DelayUs(10); // 10us以上 HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_RESET); } /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim) { if(htim->Instance == Hcsr04Info.instance) // TIM2 { Hcsr04Info.tim_overflow_counter++;} } /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim) { if((htim->Instance == Hcsr04Info.instance) && (htim->Channel == Hcsr04Info.active_channel)) { if(Hcsr04Info.edge_state == 0) // 捕获上升沿 { // 得到上升沿开始时间T1,并更改输入捕获为下降沿 Hcsr04Info.t1 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_FALLING); Hcsr04Info.tim_overflow_counter = 0; // 定时器溢出计数器清零 Hcsr04Info.edge_state = 1; // 上升沿、下降沿捕获标志位 } else if(Hcsr04Info.edge_state == 1) // 捕获下降沿 { // 捕获下降沿时间T2,并计算高电平时间 Hcsr04Info.t2 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); Hcsr04Info.t2 += Hcsr04Info.tim_overflow_counter * Hcsr04Info.period; // 需要考虑定时器溢出中断 Hcsr04Info.high_level_us = Hcsr04Info.t2 - Hcsr04Info.t1; // 高电平持续时间 = 下降沿时间点 - 上升沿时间点 // 计算距离 Hcsr04Info.distance = (Hcsr04Info.high_level_us / 1000000.0) * 340.0 / 2.0 * 100.0; // 重新开启上升沿捕获 Hcsr04Info.edge_state = 0; // 一次采集完毕,清零 __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_RISING); }} } /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read() { // 测距结果限幅 if(Hcsr04Info.distance >= 450) { Hcsr04Info.distance = 450;} return Hcsr04Info.distance; } main.c 1、引用对应的头文件/ USER CODE BEGIN Includes / include "hc-sr04.h" include "printf.h" / USER CODE END Includes / 2、200ms测距一次/** @brief The application entry point. @retval int */ int main(void) { / USER CODE BEGIN 1 / / USER CODE END 1 / / MCU Configuration--------------------------------------------------------/ / Reset of all peripherals, Initializes the Flash interface and the Systick. / HAL_Init(); / USER CODE BEGIN Init / / USER CODE END Init / / Configure the system clock / SystemClock_Config(); / USER CODE BEGIN SysInit / / USER CODE END SysInit / / Initialize all configured peripherals / MX_GPIO_Init(); MX_TIM2_Init(); MX_USART1_UART_Init(); / USER CODE BEGIN 2 / DelayInit(72); Hcsr04Init(&htim2, TIM_CHANNEL_4); // 超声波模块初始化 Hcsr04Start(); // 开启超声波模块测距 printf("hc-sr04 start!\r\n"); / USER CODE END 2 / / Infinite loop / / USER CODE BEGIN WHILE / while (1) { // 打印测距结果 printf("distance:%.1f cm\r\n", Hcsr04Read()); Hcsr04Start(); DelayMs(200); // 测距周期200ms /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */} / USER CODE END 3 / } 3、重定义定时器的中断服务函数/ USER CODE BEGIN 4 / /** @description: 定时器输出捕获中断 @param {TIM_HandleTypeDef} *htim @return {*} */ void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim) { Hcsr04TimIcIsr(htim); } /** @description: 定时器溢出中断 @param {*} @return {*} */ void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef* htim) { Hcsr04TimOverflowIsr(htim); } / USER CODE END 4 / 4、串口打印结果
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
0
1,302
2
嵌入式/SOC开发利器-ZYNQ简介与入门
ZYNQ是什么? ZYNQ为什么厉害 ZYNQ的结构 开发工具 ZYNQ开发流程 ZYNQ是什么? 这是一款由Xilinx公司开发的集成了ARM处理器和FPGA可编程逻辑的片上系统(SoC)芯片。ZYNQ7000有多个型号,根据处理器核心数和FPGA系列的不同,可以应用于多种领域,如图像处理,通信,嵌入式系统等。 ZYNQ中国人读法 “zingke”、“任克”,“Soc”,英文全称叫 System on one Chip ,也就是片上系统的意思。没有微机基础的同学可能不明白什么叫Soc,但是你可以细细琢磨一下,我们的手机和台式电脑的不同,你就可以理解Soc的内含了。 传统计算机是将CPU,内存,GPU,南北桥焊接在印刷电路板上,各个组件之间是分立的。但是Soc则将CPU和各种外设集中到一块芯片上,集合成一个系统,因此像手机这种使用了Soc芯片的这种微机可以做的很轻薄,我们可以说,Soc是未来微机发展的一个趋势,我之前遇见过的像什么全志的A33就是典型的Soc。 ZYNQ为什么厉害 就在于它是一块可编程的Soc。其内部往往有处理器硬核和一些定制外设,并且外设当中有一个很厉害的玩意:PL,即可编程逻辑模块,也就是我们一般意义上的FPGA,所以简单理解ZYNQ就是“ 单片机 + FPGA “,它既可以执行代码程序,也可以实现FPGA。因此我们设计ZYNQ就是在做Soc设计。 ZYNQ的结构 我们先来开一下简化版的模型 图片 上面的模型细致低展开后就是下图的样子: 图片 图是 ZYNQ 7000的结构图,大体分为PS(Processing System)和 PL(Programmable Logic)两部分,其中的PS部分主要是由双核APU和外围的一些外设组成,说实话很像单片机的结构,而外围的PL则类似FPGA,并且两者通过AXI接口进行互联以实现功能. 重点介绍一下APU,应用处理单元:Application Processing Unit,位于PS(processing system)中,包括一个单核或者双核的cortex-A9处理器,处理器连接一个512KB的共享L2cache,每个处理器都有一个32KB的高速L1 cache,A9支持虚拟内存和32bit arm 指令。APU中的A9处理器由可配置的MP组成,MP包含SCU(snoop control unit:监控控制单元)单元,这个单元主要负责获取两个处理器的L1 cache和ACP(accelerator coherency port:加速器相关接口) PL的一致性。应用单元还有一个低延迟的片上memory,与L2 cache并行的,ACP(加速器接口)是PL与APU通信接口,该接口是PL作为主机的AXI协议的接口,最多支持64bit位宽,PL通过ACP接口访问L2 cache 和片上memory,同时保持和L1 cache的内存一致性。L2 cache 可以访问 DDR 控制,这个ddr 控制器是专用的,大大降低内存读写的延迟APU 还包括一个32bit的看门狗,一个64bit的全局定时器,APU 架构图如下所示: 图片 开发工具 在Vivado 19.2之前,我们开发Zynq需要三样必须的软件: Vivado SDK PetaLinux 其中Vivado用来开发硬件平台,SDK开发软件,PetaLinux则制作配套的Linux系统。可能有些人还有用到HLS ,即VIvado HLS 或者Vitis HLS;其中Vivado HLS 2020.1将是Vivado HLS的最后一个版本,取而代之的是VitisHLS。 到了Vivado 19.2之后,事情发生了变化。为了方便大家理解,我愿意称之这些软件成了为Vitis 家族的各个部分,原来的SDK被Vitis IDE取代,Vivado导出的 .hdf 文件被 .xsa文件代替,用来给vitis平台使用。因此我们需要的开发Zynq 最基本的软件变成了 Vivado Vitis IDE PetaLinux 各软件发挥的作用和之前的差不多,不过除了上面提到的四款软件外,Vitis家族还有 Vitis AI 等组件,他们共同组成了所谓的“Vitis™ Unified Software Platform ”,从发展趋势来看,这些开发软件应该会逐步的统一,入门的同学也不会再一头雾水地纠结 Vitis 和 Vivado 的区别和联系了。 ZYNQ开发流程 ZYNQ类似于一个 单片机 + FPGA的结构,其实我觉得如果大家接触过一些 Soc就会更好地理解ZYNQ的作用,就例如全志A33这块Soc,它是一块ASIC,不可以通过编程来对芯片的硬件进行重设计的。 图片 我们可以看到,灰色部分的外设都是固定的,像什么摄像头接口,什么视频接口都是设计好的,定制化的好处就使得总体比较高效,制造成本也低;但是如果我要运用到其它场景下,比如说我需要多个摄像头,那这块芯片就不再适合了(硬件控制的上限就是前后两颗摄像头) 而ZYNQ的意义相当于只给你定制的蓝色部分,也就是处理器内核,灰色的部分都可以通过FPGA实现,这让电子工程师们可以快速开发出各种各样有针对性的Soc;当然了,看过我第一篇博客的同学都知道,其实固定的硬核不止只有处理器内核,其实还有串口和内存控制器之类的外设,这其实是追寻一种固定和变化之间的平衡。 咱们把话说回ZYNQ的开发上来。 图片 ZYNQ的开发流程分为硬件和软件两部分,在SDK之前的属于硬件开发,也就是我们常说的PL部分的开发,而SDK后就属于软件部分的开发了,类似单片机,属于PS部分。当然现在最新的Vitis IDE已经取代了SDK,所以后半部分一般在SDK中进行。 PL部分的开发包括对 嵌入式最小系统的构建,以及FPGA外设的设计两个方面。我觉得要转变的一个思维是,我们现在不是在开发一个什么SDRAM控制器,什么IIC协议控制器,我们在开发的是一个小型的微机系统!因此嵌入式最小系统的设计是我们的核心。 首先,在IP INTEGRATOR中我们要创建BLOCK DESIGN。 图片 IP是用来进行 Embedded System Design ,也就是咱们常说的嵌入式系统设计。也就是咱们上面说的嵌入式最小系统的设计。 图片 大家可以看到,一个最小的系统其实不需要PL参与的,PL可以作为PS的一个外设使用,或者是自己做自己的事情,仅仅作为一个PL工作。既然是外设,当然是可用可不用的,毕竟咱们有好多的外设可以在Block Design 中直接配置使用,即下图绿色部分。 图片 配置好嵌入式系统后,咱们根据需要进行PL部分的设计。这里涉及一个问题,那就是PS和PL之间的数据传输方式有哪些: 中断 IO方式:MIO EMIO GPIO BRAM或FIFO或EMIF AXI DMA:PS通过AXI-lite向AXI DMA发送指令,AXI DMA通过HP通路和DDR交换数据,PL通过AXI-S读写DMA的数据。 等等。。。 可以看出,其实两个部分的交互方式还是很多的,以后咱们遇到一个说一个。 在Vivado端完成对嵌入式系统的设计后,我们就要进入Vitis IDE 端进行软件的开发。 图片 Vitis IDE简单来说流程一般是:新建一个工程,选择Platform ,也就是我们之前在Vivado中生成的 XSA文件,然后添加文件,进行开发。我相信使用过Keil 5的同学们应该心中对文件目录结构应该更胸有成竹,Src文件夹中存放的是源文件。 代码编写完之后是编译,编译完就是下载了。不过这里要注意以下,如果我们使用了PL的资源,那么在下载软件编译生成的 elf 文件之前,需要先下载硬件设计过程中生成的 bitstream 文件,对 PL 部分进行配置。 最后就是验证工作了,上述的流程是普通的ZYNQ开发流程;玩的花一点的同学可能是直接上Linux操作系统,这部分等后面我接触到了再说吧! 其实我觉得ZYNQ入门简单,精通的话需要大量的知识储备,但也不是不可能,开发ZYNQ相比于做单片机开发肯定路子会更广一些,向上可以做IC设计,向下嵌入式、单片机什么的工作也能胜任。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# 嵌入式
# SOC设计
刘航宇
3年前
0
4,049
4
2023-11-01
机器学习/深度学习-10个激活函数详解
图片 综述 1. Sigmoid 激活函数 2. Tanh / 双曲正切激活函数 3. ReLU 激活函数 4. Leaky ReLU 5. ELU 6. PReLU(Parametric ReLU) 7. Softmax 8. Swish 9. Maxout 10. Softplus 综述 激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。 在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式,本文概述了深度学习中常见的十种激活函数及其优缺点。 首先我们来了解一下人工神经元的工作原理,大致如下: 图片 上述过程的数学可视化过程如下图所示: 图片 1. Sigmoid 激活函数 lofj8ajx.png图片 Sigmoid 函数的图像看起来像一个 S 形曲线。 函数表达式如下: $$\[\mathrm{f(z)=1/(1+e^{\wedge}-z)}\]$$ 在什么情况下适合使用 Sigmoid 激活函数呢? Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化; 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适; 梯度平滑,避免「跳跃」的输出值; 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率; 明确的预测,即非常接近 1 或 0。 Sigmoid 激活函数有哪些缺点? 倾向于梯度消失; 函数输出不是以 0 为中心的,这会降低权重更新的效率; Sigmoid 函数执行指数运算,计算机运行得较慢。 2. Tanh / 双曲正切激活函数 图片 tanh 激活函数的图像也是 S 形,表达式如下: $$f(x)=tanh(x)=\frac{2}{1+e^{-2x}}-1$$ tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。 图片 首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好; 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。 注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。 3. ReLU 激活函数 图片 ReLU 激活函数图像如上图所示,函数表达式如下: 图片 ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点: 当输入为正时,不存在梯度饱和问题。 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快 当然,它也有缺点: Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题; 我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。 4. Leaky ReLU 它是一种专门设计用于解决 Dead ReLU 问题的激活函数: 图片 ReLU vs Leaky ReLU 为什么 Leaky ReLU 比 ReLU 更好? $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 1、Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题; 2、leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右; 3、Leaky ReLU 的函数范围是(负无穷到正无穷)。 注意:从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。 5. ELU 图片 ELU vs Leaky ReLU vs ReLU ELU 的提出也解决了 ReLU 的问题。与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零。均值激活接近于零可以使学习更快,因为它们使梯度更接近自然梯度。 图片 显然,ELU 具有 ReLU 的所有优点,并且: 没有 Dead ReLU 问题,输出的平均值接近 0,以 0 为中心; ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习; ELU 在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。 一个小问题是它的计算强度更高。与 Leaky ReLU 类似,尽管理论上比 ReLU 要好,但目前在实践中没有充分的证据表明 ELU 总是比 ReLU 好。 6. PReLU(Parametric ReLU) 图片 PReLU 也是 ReLU 的改进版本: $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 看一下 PReLU 的公式:参数α通常为 0 到 1 之间的数字,并且通常相对较小。 如果 a_i= 0,则 f 变为 ReLU 如果 a_i> 0,则 f 变为 leaky ReLU 如果 a_i 是可学习的参数,则 f 变为 PReLU PReLU 的优点如下: 在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU 问题。 与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。 7. Softmax 图片 Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。 图片 Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。 Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。 Softmax 激活函数的主要缺点是: 在零点不可微; 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。 8. Swish 图片 函数表达式:y = x * sigmoid (x) Swish 的设计受到了 LSTM 和高速网络中 gating 的 sigmoid 函数使用的启发。我们使用相同的 gating 值来简化 gating 机制,这称为 self-gating。 self-gating 的优点在于它只需要简单的标量输入,而普通的 gating 则需要多个标量输入。这使得诸如 Swish 之类的 self-gated 激活函数能够轻松替换以单个标量为输入的激活函数(例如 ReLU),而无需更改隐藏容量或参数数量。 Swish 激活函数的主要优点如下: 「无界性」有助于防止慢速训练期间,梯度逐渐接近 0 并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决); 导数恒 > 0; 平滑度在优化和泛化中起了重要作用。 9. Maxout 图片 在 Maxout 层,激活函数是输入的最大值,因此只有 2 个 maxout 节点的多层感知机就可以拟合任意的凸函数。 单个 Maxout 节点可以解释为对一个实值函数进行分段线性近似 (PWL) ,其中函数图上任意两点之间的线段位于图(凸函数)的上方。 $ReLU=\max\bigl(0,x\bigr),\mathrm{abs}\bigl(x\bigr)=\max\bigl(x,-x\bigr)$ Maxout 也可以对 d 维向量(V)实现: 图片 假设两个凸函数 h_1(x) 和 h_2(x),由两个 Maxout 节点近似化,函数 g(x) 是连续的 PWL 函数。 $$g\bigl(x\bigr)=h_1\bigl(x\bigr)-h_2\bigl(x\bigr)$$ 因此,由两个 Maxout 节点组成的 Maxout 层可以很好地近似任何连续函数。 图片 10. Softplus 图片 Softplus 函数:f(x)= ln(1 + exp x) Softplus 的导数为 f ′(x)=exp(x) / ( 1+exp x ) = 1/ (1 +exp(−x )) ,也称为 logistic / sigmoid 函数。 Softplus 函数类似于 ReLU 函数,但是相对较平滑,像 ReLU 一样是单侧抑制。它的接受范围很广:(0, + inf)。
机器学习
# 机器学习
# 软件算法
# DL/ML
刘航宇
3年前
0
604
0
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
335
0
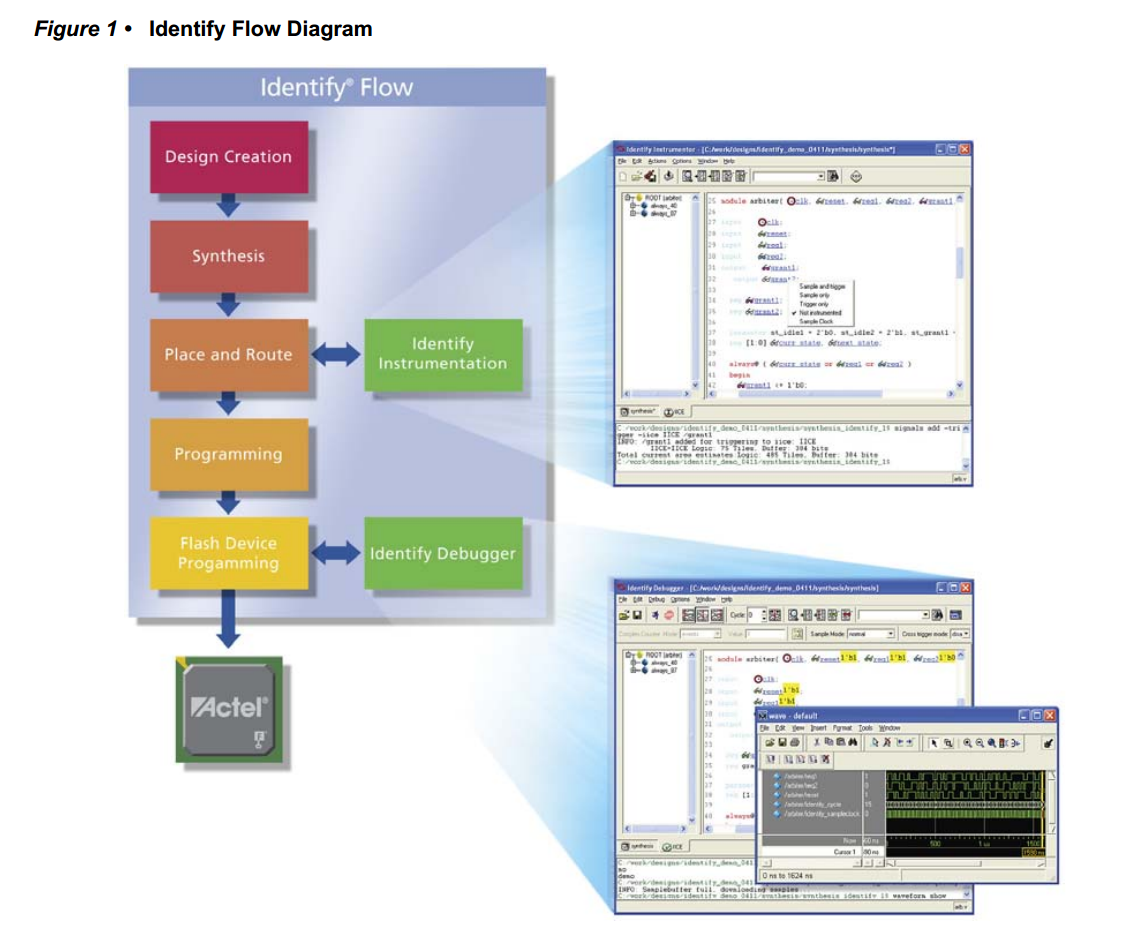
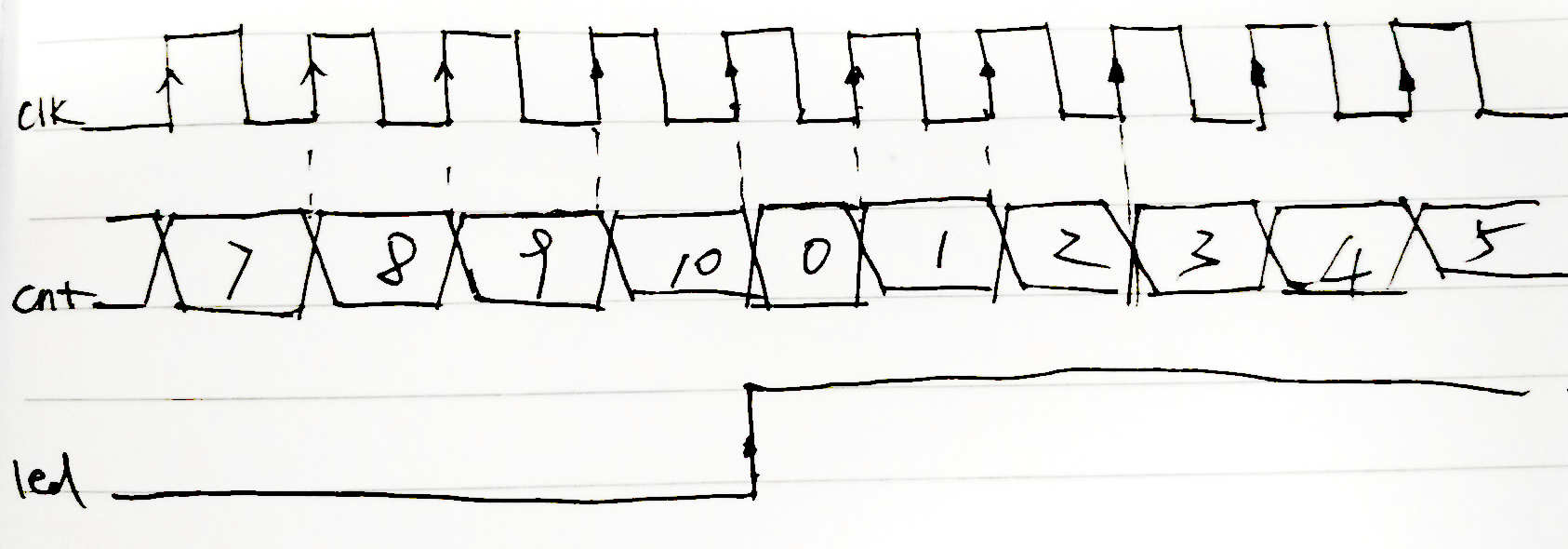
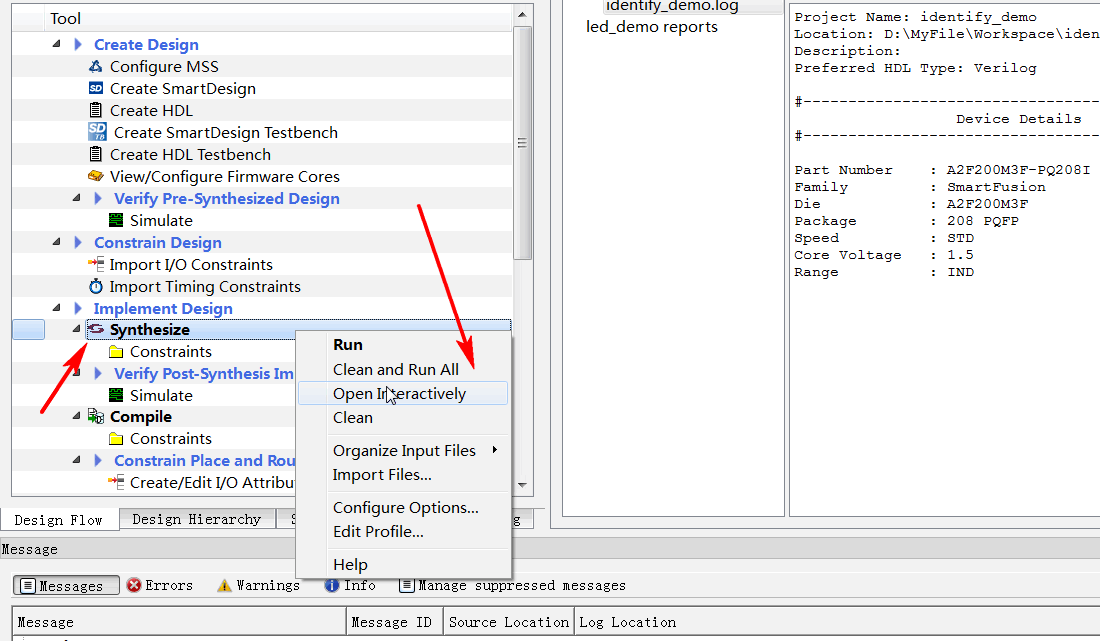
【转载】Libero SOC Debug教程-片上逻辑分析仪IDENTIFY
本文转载于https://blog.csdn.net/whik1194/article/details/107074187 FPGA在线调试 关于MICROSEMI片上逻辑分析仪 FPGA片上逻辑分析仪原理 预期效果 0.准备一个创建好的LIBERO工程 1.新建IDENTIFY工程,并添加想要监测的信号 2.管脚分配,编译下载 3.设置触发类型 4.IICE逻辑分析仪核资源占用 原文: 参考: FPGA在线调试 对于嵌入式系统来说,如单片机,进行硬件级程序调试时,通常采用的是JLink/ST-Link调试器,在线调试的方式来获取程序实时运行的状态,可以观察程序运行流程、各种变量的值、中断的触发情况,还可以设置断点、单步运行,方便快速的发现BUG,解决问题。 但是对于FPGA来说,并不是顺序执行的,而是根据每一个Clk并行执行,所以我们不能使用调试器进行单步调试。 FPGA调试需要观察内部信号的值,各个信号之间的时序关系,所以使用逻辑分析仪是最好的调试方式了。 有些FPGA工程,对外的接口,即输入输出,可能只有几个,但是他们之间的逻辑和时序关系非常复杂,所以内部有几十个中间寄存器,程序下载进去了,发现不是我们想要的效果,怎么办?你可能会说,查代码吧!如果这个工程非常简单,你可能只需要耗费几分钟或者几个小时就可以定位代码的问题所在。 但是如果这是一个非常庞大的工程,内部的中间寄存器、信号,几百上千个,各个模块单独软件仿真都正常,整体仿真也正常,就是下载到实际的芯片中运行不正常。你如何进行问题定位?如果再去进行代码审查,这将会消耗非常多的时间。那么如果能在FPGA芯片内部装上一个逻辑分析仪,那不就直接可以看到内部信号的值了,而且还可以看到各个信号之间的时序关系。需求推动技术发展,既然开发者有这个需求,那么FPGA厂商肯定会实现这个功能!下面来一起看一下Microsemi FPGA片上逻辑分析仪的使用方法吧! 关于MICROSEMI片上逻辑分析仪 几大厂商的片上逻辑分析仪: Xilinx厂商ISE开发环境下的ChipScope工具 Altera厂商Quartus开发环境下的SignalTap工具 Lattice厂商Diamod开发环境下的Reveal工具 对于 FPGA 工程师来说,这些都是很熟悉的名字。和以上几大FPGA厂商一样,Microsemi Libero也支持片上逻辑分析仪工具,只不过不是自己家研发的,使用的是Synospsy公司出品的Identify工具,其实,Libero中的综合器synplify也是Synospsy公司的。 根据Synospsy官网的描述:Identify RTL 调试仪,这个调试工具除了支持Microsemi的FPGA产品外,还支持Altera和Xilinx的FPGA产品。 FPGA片上逻辑分析仪原理 Identify片上逻辑分析仪的原理,是通过在FPGA工程中加入一个IICE逻辑分析仪IP核,这个IP核,由控制器和采集器组成,采集器用于采集信号,控制器用于和JTAG调试器连接,并把数据发送到上位机,IICE内部有RAM空间,用于存储触发位置附近的信号,RAM空间的大小,即采样深度,可以自己调整。FPGA工程中加入IICE核,会占用一定的资源,资源占用的大小取决于:采样深度,采样信号的个数,采样信号的触发方式等。 所以综上,FPGA片上逻辑分析仪需要3个组件:片上的IICE逻辑分析仪核、JTAG下载器、上位机。 pC5Uq6e.png图片 JTAG下载器也就是我们下载程序时使用的FlashPro x下载器,上位机软件也就是Identify工具,这个工具已经在安装Libero SoC时一同安装并注册**了。所以不需要安装其他的工具软件,只需要在已经设计好的FPGA公司中,配置一下IIC逻辑分析仪核就可以了。 在已经创建好的Libero工程中,加入IICE逻辑分析仪核,并演示Identify工具的使用。 预期效果 以Microsemi SmartFusion系列的A2F200M3F芯片为例,其他芯片使用操作方法类似。示例工程功能:led每隔10个clk翻转一次为例,演示identify的使用。 identify添加完成之后,把led设置为上升沿触发,会抓取到类似如下的波形。 pChB2qJ.png图片 0.准备一个创建好的LIBERO工程 这里以LED每隔10个时钟周期翻转为例。HDL文件内容: module led_demo( //inputs input clk, input rst_n, //outputs output reg led ); reg [3:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 0; else if(cnt == 10) /* max=10, 0-10 */ cnt <= 0; else cnt <= cnt + 1; end always @ (posedge clk) begin if(!rst_n) led <= 0; else if(cnt == 10) led <= ~led; end endmodule1.新建IDENTIFY工程,并添加想要监测的信号 1.0 先运行Synthesize 1.1 在Synthesize上右键,选择Open Interactively pChr5jO.png图片 1.2 在Synthesis上右键新建一个Identify工程 pChrTDe.png图片 1.3 输入新建的identify工程的名称和保存路径,选择默认的就行。 pChrqUA.png图片 1.4 在新建的identify工程上右键选择identify instrumentor pChsSKS.png图片 1.5 在HDL文件中选择要监测的信号和采样时钟,采样时钟选择Sample Clock,作为触发的信号选择Trigger Only,要监测的信号选择Sample Only,也可以选择Sample and Trigger,这样会占用更多的资源。 pChsG26.png图片 pChsNrD.png图片 设置完成的信号会有标注 pChsgsS.png图片 sample clock 表示采样时钟,所有在 IICE 中添加的信号都会在 sample clock 的边沿进行采样,设为 sample clock 的信号前会出现一个时钟状的图标。 设置为 sample 和 trigger 的信号都将作为被采样信号,区别在于 sample 信号只能被采样,而 trigger 信号可以作为触发采集的条件,当然你可以把一个信号同时设置为 sample 和 trigger 。 1.6 设置采样深度,选择Instrumentor->IICE pChsWZQ.png图片 采样深度最大支持1048576 pChsfaj.png图片 输入采样深度,数值越大,采样时间越长,相应的FPGA资源占用也越多。 pChsqLF.png图片 1.7 选择Run->Run pChsOZ4.png图片 或者直接点击主界面的Run按钮 pChsjo9.png图片 1.8 编译完成之后,保存退出。 pChsxiR.png图片 2.管脚分配,编译下载 2.1 和正常流程一样,管脚分配,编译下载。可以看到JTAG部分的管脚已经被IICE逻辑分析仪核使用了 pChyiLD.png图片 2.2 在Identify Debug Design上右键,选择Open Interactively,打开identify工具 pChymWt.png图片 3.设置触发类型 3.1 选择要触发的信号,和触发类型,这里我选择的是led,上升沿触发。 pChyYYn.png图片 3.2 连接FlashPro下载器,点击小人图标,启动抓取,满足触发条件自动停止。 pChy6YR.png图片 D:/identify_demo/synthesis$ run -iice {IICE} INFO: run -iice IICE INFO: Info: Attempting to connect to: usb Info: Type: FlashPro4 Info: ID: 08152 Info: Connection: usb2.0 Info: Revision: UndefRev INFO: Checking communication with the Microsemi_BuiltinJTAG cable and the hardware INFO: The hardware is responding correctly INFO: Auto-detecting the device chain INFO: Device at chain position 1 is "A2F200M3F" INFO: IICE 'IICE' configured, waiting for trigger INFO: IICE 'IICE' Trigger detected, downloading samples INFO: notify -notify INFO: waveform viewer INFO: waveform viewer INFO: write vcd -iice IICE -comment {Identify created VCD dump} -gtkwave -noequiv IICE.vcd D:/identify_demo/synthesis$ 3.3 右侧黄色的显示就是触发瞬间时信号的值。右键可以改变数据格式。 pChyO6f.png图片 3.4 选择Debugger preferences可以设置采样时钟的周期,用于后面波形的时间测量 pChyz7Q.png图片 3.5 设置采样时钟的周期 pCh6Chn.png图片 3.6 点击波形按钮,在GTKWave中打开抓取到的波形。 pCh6kcV.png图片 3.7 可以按住左键拖动测量时间差 pCh6uN9.png图片 3.8 还可以给每个通道设置不同的颜色,和显示方式。 pCh6Q91.png图片 4.IICE逻辑分析仪核资源占用 IICE逻辑分析仪核占用的主要是逻辑资源和RAM资源,可以看到资源占用还是很多的。 图片 图片 原文: https://blog.csdn.net/whik1194/article/details/107074187 参考: https://zhuanlan.zhihu.com/p/88314552 https://www.synopsys.com/zh-cn/implementation-and-signoff/fpga-based-design/identify-rtl-debugger.html http://training.eeworld.com.cn/video/1059 https://www.microsemi.com/document-portal/doc_view/132760-synopsys-identify-me-h-2013-03m-sp1-user-guide
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
2
2,879
2
2023-07-10
Verilog实现AMBA--AHB To APB Bridge
1、APB桥 2、读传输 3、写传输 4、背靠背传输 5、AHB_to_APB Bridge的Verilog实现 6、仿真 1、APB桥 APB桥是AMBA APB总线上的唯一主机,也是AMBA AHB的一个从机。下图表示了APB桥接口信号: 图片 APB Bridge将AHB传输转成APB传输并实现一下功能: (1)对锁存的地址进行译码并产生选择信号PSELx,在传输过程中只有一个选择信号可以被激活。 也就是选择出唯一 一个APB从设备以进行读写动作。 (2)写操作时:负责将AHB送来的数据送上APB总线。 (3)读操作时:负责将APB的数据送上AHB系统总线。 (4)产生一时序选通信号PENABLE来作为数据传递时的启动信号 2、读传输 下图表示了APB到AHB的读传输: 图片 传输开始于AHB总线上的T1时刻,在T2时刻地址信息被APB采样,如果传输目标是外设总线,那么这个地址就会被译码成选择信号发给外设,T2即为APB总线的SETUP周期,T3为APB的ENABLE周期,PENABLE信号拉高。在该周期内,外设必须提供读数据,通常情况下,读数据直接AHB读数据总线上,总线主机在T4时刻对读数据进行采样。 在频率很高的情况下,在ENABLE CYCLE中可能数据不能够直接映射到AHB总线,需要在APB桥中在T4的时候打插入一个额外的等待周期,并在T5的时候才被AHB主采样。虽然需要多一个等待周期(一共2个),但是由于频率提升了因此总的性能也提升了。 下图表示了一个读突发传输,所有的传输都只有一个等待周期 图片 3、写传输 下图表示了一个写传输: 图片 APB总线上的单块数据写操作不需要等待周期。 APB桥负责对地址和数据进行采样,并在写操作的过程中保持它们的值。 下图表示了一个写突发传输: 图片 虽然第一个传输可以零等待完成,但后续每一个传输都需要插入一个等待状态。 APB桥需要两个地址寄存器,以便在当前传输进行时,锁存下一次传输的地址。 4、背靠背传输 下图表示了一个背靠背传输,顺序为写、读、写、读: 如果写操作之后跟随着读操作,那么需要 3 个等待周期来完成这个读操作。通常的情况下,不会有读操作之后紧跟着写操作的发生,因为两者之间 CPU 会进行指令读取,并且指令存储器也不太可能挂在在APB总线上。 图片 下面以ARM DesignStart项目提供的软件包里的AHB转APB桥的代码,对其进行学习与仿真,以深入理解APB桥的实现方法,该转换桥比较简单,实现的是一对一的转换,也可以配合APB slave multiplexer模块,实现一对多的方式(主要依靠APB高位地址译码得到各个从机的PSEL信号)。如果想学习APB系统总线,可以参考Synopsys公司的DW_APB IP,该IP最多可支持16个APB从机,并支持所有的突发传输类型。 5、AHB_to_APB Bridge的Verilog实现 `timescale 1ns / 1ps module ahb_to_apb #( // Parameter to define address width // 16 = 2^16 = 64KB APB address space parameter ADDRWIDTH = 16, parameter REGISTER_RDATA = 1, parameter REGISTER_WDATA = 0 ) ( //---------------------------------- // IO Declarations //---------------------------------- input wire HCLK, // Clock input wire HRESETn, // Reset input wire PCLKEN, // APB clock enable signal input wire HSEL, // Device select input wire [ADDRWIDTH-1:0] HADDR, // Address input wire [1:0] HTRANS, // Transfer control input wire [2:0] HSIZE, // Transfer size input wire [3:0] HPROT, // Protection control input wire HWRITE, // Write control input wire HREADY, // Transfer phase done input wire [31:0] HWDATA, // Write data output reg HREADYOUT, // Device ready output wire [31:0] HRDATA, // Read data output output wire HRESP, // Device response // APB Output output wire [ADDRWIDTH-1:0] PADDR, // APB Address output wire PENABLE, // APB Enable output wire PWRITE, // APB Write output wire [3:0] PSTRB, // APB Byte Strobe output wire [2:0] PPROT, // APB Prot output wire [31:0] PWDATA, // APB write data output wire PSEL, // APB Select output wire APBACTIVE, // APB bus is active, for clock gating of APB bus // APB Input input wire [31:0] PRDATA, // Read data for each APB slave input wire PREADY, // Ready for each APB slave input wire PSLVERR // Error state for each APB slave ); //---------------------------------- // Variable Declarations //---------------------------------- reg [ADDRWIDTH-3:0] addr_reg; // Address sample register reg wr_reg; // Write control sample register reg [2:0] state_reg; // State for finite state machine reg [3:0] pstrb_reg; // Byte lane strobe register wire [3:0] pstrb_nxt; // Byte lane strobe next state reg [1:0] pprot_reg; // PPROT register wire [1:0] pprot_nxt; // PPROT register next state wire apb_select; // APB bridge is selected wire apb_tran_end; // Transfer is completed on APB reg [2:0] next_state; // Next state for finite state machine reg [31:0] rwdata_reg; // Read/Write data sample register wire reg_rdata_cfg; // REGISTER_RDATA paramater wire reg_wdata_cfg; // REGISTER_WDATA paramater reg sample_wdata_reg; // Control signal to sample HWDATA //---------------------------------- // Local Parameter Declarations //---------------------------------- // State machine localparam ST_BITS = 3; localparam [ST_BITS-1:0] ST_IDLE = 3'b000; // Idle waiting for transaction localparam [ST_BITS-1:0] ST_APB_WAIT = 3'b001; // Wait APB transfer localparam [ST_BITS-1:0] ST_APB_TRNF = 3'b010; // Start APB transfer localparam [ST_BITS-1:0] ST_APB_TRNF2 = 3'b011; // Second APB transfer cycle localparam [ST_BITS-1:0] ST_APB_ENDOK = 3'b100; // Ending cycle for OKAY localparam [ST_BITS-1:0] ST_APB_ERR1 = 3'b101; // First cycle for Error response localparam [ST_BITS-1:0] ST_APB_ERR2 = 3'b110; // Second cycle for Error response localparam [ST_BITS-1:0] ST_ILLEGAL = 3'b111; // Illegal state //---------------------------------- // Start of Main Code //---------------------------------- // Configuration signal assign reg_rdata_cfg = (REGISTER_RDATA == 0) ? 1'b0 : 1'b1; assign reg_wdata_cfg = (REGISTER_WDATA == 0) ? 1'b0 : 1'b1; // Generate APB bridge select assign apb_select = HSEL & HTRANS[1] & HREADY; // Generate APB transfer ended assign apb_tran_end = (state_reg == 3'b011) & PREADY; assign pprot_nxt[0] = HPROT[1]; // (0) Normal, (1) Privileged assign pprot_nxt[1] = ~HPROT[0]; // (0) Data, (1) Instruction // Byte strobe generation // - Only enable for write operations // - For word write transfers (HSIZE[1]=1), all byte strobes are 1 // - For hword write transfers (HSIZE[0]=1), check HADDR[1] // - For byte write transfers, check HADDR[1:0] assign pstrb_nxt[0] = HWRITE & ((HSIZE[1])|((HSIZE[0])&(~HADDR[1]))|(HADDR[1:0]==2'b00)); assign pstrb_nxt[1] = HWRITE & ((HSIZE[1])|((HSIZE[0])&(~HADDR[1]))|(HADDR[1:0]==2'b01)); assign pstrb_nxt[2] = HWRITE & ((HSIZE[1])|((HSIZE[0])&( HADDR[1]))|(HADDR[1:0]==2'b10)); assign pstrb_nxt[3] = HWRITE & ((HSIZE[1])|((HSIZE[0])&( HADDR[1]))|(HADDR[1:0]==2'b11)); // Sample control signals always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) begin addr_reg <= {(ADDRWIDTH-2){1'b0}}; wr_reg <= 1'b0; pprot_reg <= {2{1'b0}}; pstrb_reg <= {4{1'b0}}; end else if (apb_select) begin // Capture transfer information at the end of AHB address phase addr_reg <= HADDR[ADDRWIDTH-1:2]; wr_reg <= HWRITE; pprot_reg <= pprot_nxt; pstrb_reg <= pstrb_nxt; end end // Sample write data control signal // Assert after write address phase, deassert after PCLKEN=1 wire sample_wdata_set = apb_select & HWRITE & reg_wdata_cfg; wire sample_wdata_clr = sample_wdata_reg & PCLKEN; always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) sample_wdata_reg <= 1'b0; else if (sample_wdata_set | sample_wdata_clr) sample_wdata_reg <= sample_wdata_set; end // Generate next state for FSM // Note : case 3'b111 is not used. The design has been checked that // this illegal state cannot be entered using formal verification. always @(state_reg or PREADY or PSLVERR or apb_select or reg_rdata_cfg or PCLKEN or reg_wdata_cfg or HWRITE) begin case (state_reg) // Idle ST_IDLE : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end // Transfer announced on AHB, but PCLKEN was low, so waiting ST_APB_WAIT : begin if (PCLKEN) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high end // First APB transfer cycle ST_APB_TRNF : begin if (PCLKEN) next_state = ST_APB_TRNF2; // Change to second cycle of APB transfer else next_state = ST_APB_TRNF; // Change to state-2 end // Second APB transfer cycle ST_APB_TRNF2 : begin if (PREADY & PSLVERR & PCLKEN) // Error received - Generate two cycle // Error response on AHB by next_state = ST_APB_ERR1; // Changing to state-5 and 6 else if (PREADY & (~PSLVERR) & PCLKEN) begin // Okay received if (reg_rdata_cfg) // Registered version next_state = ST_APB_ENDOK; // Generate okay response in state 4 else // Non-registered version next_state = {2'b00, apb_select}; // Terminate transfer end else // Slave not ready next_state = ST_APB_TRNF2; // Unchange end // Ending cycle for OKAY (registered response) ST_APB_ENDOK : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end // First cycle for Error response ST_APB_ERR1 : next_state = ST_APB_ERR2; // Goto 2nd cycle of error response // Second cycle for Error response ST_APB_ERR2 : begin if (PCLKEN & apb_select & ~(reg_wdata_cfg & HWRITE)) next_state = ST_APB_TRNF; // Start APB transfer in next cycle else if (apb_select) next_state = ST_APB_WAIT; // Wait for start of APB transfer at PCLKEN high else next_state = ST_IDLE; // Remain idle end default : // Not used next_state = 3'bxxx; // X-Propagation endcase end // Registering state machine always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) state_reg <= 3'b000; else state_reg <= next_state; end // Sample PRDATA or HWDATA always @(posedge HCLK or negedge HRESETn) begin if (~HRESETn) rwdata_reg <= {32{1'b0}}; else if (sample_wdata_reg & reg_wdata_cfg & PCLKEN) rwdata_reg <= HWDATA; else if (apb_tran_end & reg_rdata_cfg & PCLKEN) rwdata_reg <= PRDATA; end // Connect outputs to top level assign PADDR = {addr_reg, 2'b00}; // from sample register assign PWRITE = wr_reg; // from sample register // From sample register or from HWDATA directly assign PWDATA = (reg_wdata_cfg) ? rwdata_reg : HWDATA; assign PSEL = (state_reg == ST_APB_TRNF) | (state_reg == ST_APB_TRNF2); assign PENABLE = (state_reg == ST_APB_TRNF2); assign PPROT = {pprot_reg[1], 1'b0, pprot_reg[0]}; assign PSTRB = pstrb_reg[3:0]; // Generate HREADYOUT always @(state_reg or reg_rdata_cfg or PREADY or PSLVERR or PCLKEN) begin case (state_reg) ST_IDLE : HREADYOUT = 1'b1; // Idle ST_APB_WAIT : HREADYOUT = 1'b0; // Transfer announced on AHB, but PCLKEN was low, so waiting ST_APB_TRNF : HREADYOUT = 1'b0; // First APB transfer cycle // Second APB transfer cycle: // if Non-registered feedback version, and APB transfer completed without error // Then response with ready immediately. If registered feedback version, // wait until state_reg == ST_APB_ENDOK ST_APB_TRNF2 : HREADYOUT = (~reg_rdata_cfg) & PREADY & (~PSLVERR) & PCLKEN; ST_APB_ENDOK : HREADYOUT = reg_rdata_cfg; // Ending cycle for OKAY (registered response only) ST_APB_ERR1 : HREADYOUT = 1'b0; // First cycle for Error response ST_APB_ERR2 : HREADYOUT = 1'b1; // Second cycle for Error response default : HREADYOUT = 1'bx; // x propagation (note :3'b111 is illegal state) endcase end // From sample register or from PRDATA directly assign HRDATA = (reg_rdata_cfg) ? rwdata_reg : PRDATA; assign HRESP = (state_reg == ST_APB_ERR1) | (state_reg == ST_APB_ERR2); assign APBACTIVE = (HSEL & HTRANS[1]) | (|state_reg); endmodule使用的测试用例和AHB从机的测试用例基本一样,首先是顶层: `timescale 1ns / 1ps module top_tb(); //---------------------------------- // Local Parameter Declarations //---------------------------------- localparam AHB_CLK_PERIOD = 5; // Assuming AHB CLK to be 100MHz localparam SIZE_IN_BYTES = 2048; localparam ADDRWIDTH = 32; //---------------------------------- // Variable Declarations //---------------------------------- reg HCLK = 0; wire HWRITE; wire [1:0] HTRANS; wire [2:0] HSIZE; wire [2:0] HBURST; wire HREADYIN; wire [31:0] HADDR; wire [3:0] HPROT; wire [31:0] HWDATA; wire HREADYOUT; wire [1:0] HRESP; wire [31:0] HRDATA; reg HRESETn; wire HREADY; wire [ADDRWIDTH-1:0] PADDR; // APB Address wire PENABLE; // APB Enable wire PWRITE; // APB Write wire [31:0] PWDATA; // APB write data wire PSEL; // APB Select wire PREADY; wire PSLVERR; wire [2:0] PPROT; wire [3:0] PSTRB; wire [31:0] PRDATA; //---------------------------------- // Start of Main Code //---------------------------------- assign HREADY = HREADYOUT; //----------------------------------------------------------------------- // Generate HCLK //----------------------------------------------------------------------- always #AHB_CLK_PERIOD HCLK <= ~HCLK; //----------------------------------------------------------------------- // Generate HRESETn //----------------------------------------------------------------------- initial begin HRESETn = 1'b0; repeat(5) @(posedge HCLK); HRESETn = 1'b1; end ahb_master #( .START_ADDR (32'h0), .DEPTH_IN_BYTES (SIZE_IN_BYTES) ) u_ahb_master ( .HRESETn (HRESETn), .HCLK (HCLK), .HADDR (HADDR), .HPROT (HPROT), .HTRANS (HTRANS), .HWRITE (HWRITE), .HSIZE (HSIZE), .HBURST (HBURST), .HWDATA (HWDATA), .HRDATA (HRDATA), .HRESP (HRESP), .HREADY (HREADYOUT) ); ahb_to_apb #( .ADDRWIDTH (ADDRWIDTH), .REGISTER_RDATA (0), .REGISTER_WDATA (0) ) u_ahb_to_apb( .HCLK (HCLK), .HRESETn (HRESETn), .PCLKEN (1'b1), .HSEL (1'b1), .HADDR (HADDR), .HTRANS (HTRANS), .HSIZE (HSIZE), .HPROT (HPROT), .HWRITE (HWRITE), .HREADY (HREADY), .HWDATA (HWDATA), .HREADYOUT (HREADYOUT), .HRDATA (HRDATA), .HRESP (HRESP), .PADDR (PADDR), .PENABLE (PENABLE), .PWRITE (PWRITE), .PREADY (PREADY), .PSLVERR (PSLVERR), .PSTRB (PSTRB), .PPROT (PPROT), .PWDATA (PWDATA), .PSEL (PSEL), .APBACTIVE (APBACTIVE), .PRDATA (PRDATA) ); apb_mem #( .P_SLV_ID (0), .ADDRWIDTH (ADDRWIDTH), .P_SIZE_IN_BYTES (SIZE_IN_BYTES), .P_DELAY (0) ) u_apb_mem ( `ifdef AMBA_APB3 .PREADY (PREADY), .PSLVERR (PSLVERR), `endif `ifdef AMBA_APB4 .PSTRB (PSTRB), .PPROT (PPROT), `endif .PRESETn (HRESETn), .PCLK (HCLK), .PSEL (PSEL), .PENABLE (PENABLE), .PADDR (PADDR), .PWRITE (PWRITE), .PRDATA (PRDATA), .PWDATA (PWDATA) ); `ifdef VCS initial begin $fsdbDumpfile("top_tb.fsdb"); $fsdbDumpvars; end initial begin `ifdef DUMP_VPD $vcdpluson(); `endif end `endif endmodule然后是AHB master的功能模型: `timescale 1ns / 1ps `define SINGLE_TEST `define BURST_TEST module ahb_master #( //---------------------------------- // Paramter Declarations //---------------------------------- parameter START_ADDR = 0, parameter DEPTH_IN_BYTES = 32'h100, parameter END_ADDR = START_ADDR+DEPTH_IN_BYTES-1 ) ( //---------------------------------- // IO Declarations //---------------------------------- input wire HRESETn, input wire HCLK, output reg [31:0] HADDR, output reg [1:0] HTRANS, output reg HWRITE, output reg [2:0] HSIZE, output reg [2:0] HBURST, output reg [3:0] HPROT, output reg [31:0] HWDATA, input wire [31:0] HRDATA, input wire [1:0] HRESP, input wire HREADY ); //---------------------------------- // Variable Declarations //---------------------------------- reg [31:0] data_burst[0:1023]; //---------------------------------- // Start of Main Code //---------------------------------- initial begin HADDR = 0; HTRANS = 0; HPROT = 0; HWRITE = 0; HSIZE = 0; HBURST = 0; HWDATA = 0; while(HRESETn === 1'bx) @(posedge HCLK); while(HRESETn === 1'b1) @(posedge HCLK); while(HRESETn === 1'b0) @(posedge HCLK); `ifdef SINGLE_TEST repeat(3) @(posedge HCLK); memory_test(START_ADDR, END_ADDR, 1); memory_test(START_ADDR, END_ADDR, 2); memory_test(START_ADDR, END_ADDR, 4); `endif `ifdef BURST_TEST repeat(5) @(posedge HCLK); memory_test_burst(START_ADDR, END_ADDR, 1); memory_test_burst(START_ADDR, END_ADDR, 2); memory_test_burst(START_ADDR, END_ADDR, 4); memory_test_burst(START_ADDR, END_ADDR, 6); memory_test_burst(START_ADDR, END_ADDR, 8); memory_test_burst(START_ADDR, END_ADDR, 10); memory_test_burst(START_ADDR, END_ADDR, 16); memory_test_burst(START_ADDR, END_ADDR, 32); memory_test_burst(START_ADDR, END_ADDR, 64); memory_test_burst(START_ADDR, END_ADDR, 128); memory_test_burst(START_ADDR, END_ADDR, 255); repeat(5) @(posedge HCLK); `endif $finish(2); end //----------------------------------------------------------------------- // Single transfer test //----------------------------------------------------------------------- task memory_test; input [31:0] start; // start address input [31:0] finish; // end address input [2:0] size; // data size: 1, 2, 4 integer i; integer error; reg [31:0] data; reg [31:0] gen; reg [31:0] got; reg [31:0] reposit[START_ADDR:END_ADDR]; begin $display("%m: read-after-write test with %d-byte access", size); error = 0; gen = $random(7); for (i = start; i < (finish-size+1); i = i + size) begin gen = $random & ~32'b0; data = align(i, gen, size); ahb_write(i, size, data); ahb_read(i, size, got); got = align(i, got, size); if (got !== data) begin $display("[%10d] %m A:%x D:%x, but %x expected", $time, i, got, data); error = error + 1; end end if (error == 0) $display("[%10d] %m OK: from %x to %x", $time, start, finish); $display("%m read-all-after-write-all with %d-byte access", size); error = 0; gen = $random(1); for (i = start; i < (finish-size+1); i = i + size) begin gen = {$random} & ~32'b0; data = align(i, gen, size); reposit[i] = data; ahb_write(i, size, data); end for (i = start; i < (finish-size+1); i = i + size) begin data = reposit[i]; ahb_read(i, size, got); got = align(i, got, size); if (got !== data) begin $display("[%10d] %m A:%x D:%x, but %x expected", $time, i, got, data); error = error + 1; end end if (error == 0) $display("[%10d] %m OK: from %x to %x", $time, start, finish); end endtask //----------------------------------------------------------------------- // Burst transfer test //----------------------------------------------------------------------- task memory_test_burst; input [31:0] start; // start address input [31:0] finish; // end address input [7:0] leng; // burst length integer i; integer j; integer k; integer r; integer error; reg [31:0] data; reg [31:0] gen; reg [31:0] got; reg [31:0] reposit[0:1023]; integer seed; begin $display("[%10d] %m: read-all-after-write-all burst test with %d-beat access", $time, leng); error = 0; seed = 111; gen = $random(seed); k = 0; if (finish > (start+leng*4)) begin for (i = start; i < (finish-(leng*4)+1); i = i + leng*4) begin for (j = 0; j < leng; j = j + 1) begin data_burst[j] = $random; reposit[j+k*leng] = data_burst[j]; end @(posedge HCLK); ahb_write_burst(i, leng); k = k + 1; end gen = $random(seed); k = 0; for (i = start; i < (finish-(leng*4)+1); i = i + leng*4) begin @(posedge HCLK); ahb_read_burst(i, leng); for (j = 0; j < leng; j = j + 1) begin if (data_burst[j] != reposit[j+k*leng]) begin error = error+1; $display("[%10d] %m A=%hh D=%hh, but %hh expected", $time, i+j*leng, data_burst[j], reposit[j+k*leng]); end end k = k + 1; r = $random & 8'h0F; repeat(r) @(posedge HCLK); end if (error == 0) $display("%m %d-length burst read-after-write OK: from %hh to %hh",leng, start, finish); end else begin $display("%m %d-length burst read-after-write from %hh to %hh ???",leng, start, finish); end end endtask //----------------------------------------------------------------------- // As AMBA AHB bus uses non-justified data bus scheme, data should be // aligned according to the address. //----------------------------------------------------------------------- function [31:0] align; input [ 1:0] addr; input [31:0] data; input [ 2:0] size; // num of bytes begin `ifdef BIG_ENDIAN case (size) 1 : case (addr[1:0]) 0 : align = data & 32'hFF00_0000; 1 : align = data & 32'h00FF_0000; 2 : align = data & 32'h0000_FF00; 3 : align = data & 32'h0000_00FF; endcase 2 : case (addr[1]) 0 : align = data & 32'hFFFF_0000; 1 : align = data & 32'h0000_FFFF; endcase 4 : align = data&32'hFFFF_FFFF; default : $display($time,,"%m ERROR %d-byte not supported for size", size); endcase `else case (size) 1 : case (addr[1:0]) 0 : align = data & 32'h0000_00FF; 1 : align = data & 32'h0000_FF00; 2 : align = data & 32'h00FF_0000; 3 : align = data & 32'hFF00_0000; endcase 2 : case (addr[1]) 0 : align = data & 32'h0000_FFFF; 1 : align = data & 32'hFFFF_0000; endcase 4 : align = data&32'hFFFF_FFFF; default : $display($time,,"%m ERROR %d-byte not supported for size", size); endcase `endif end endfunction `include "ahb_transaction_tasks.v" endmoduleahb_transaction_tasks.v文件如下: `ifndef __AHB_TRANSACTION_TASKS_V__ `define __AHB_TRANSACTION_TASKS_V__ //----------------------------------------------------------------------- // AHB Read Task //----------------------------------------------------------------------- task ahb_read; input [31:0] address; input [2:0] size; output [31:0] data; begin @(posedge HCLK); HADDR <= #1 address; HPROT <= #1 4'b0001; // DATA HTRANS <= #1 2'b10; // NONSEQ; HBURST <= #1 3'b000; // SINGLE; HWRITE <= #1 1'b0; // READ; case (size) 1 : HSIZE <= #1 3'b000; // BYTE; 2 : HSIZE <= #1 3'b001; // HWORD; 4 : HSIZE <= #1 3'b010; // WORD; default : $display($time,, "ERROR: unsupported transfer size: %d-byte", size); endcase @(posedge HCLK); while (HREADY !== 1'b1) @(posedge HCLK); HTRANS <= #1 2'b0; // IDLE @(posedge HCLK); while (HREADY === 0) @(posedge HCLK); data = HRDATA; // must be blocking if (HRESP != 2'b00) $display($time,, "ERROR: non OK response for read"); @(posedge HCLK); end endtask //----------------------------------------------------------------------- // AHB Write Task //----------------------------------------------------------------------- task ahb_write; input [31:0] address; input [2:0] size; input [31:0] data; begin @(posedge HCLK); HADDR <= #1 address; HPROT <= #1 4'b0001; // DATA HTRANS <= #1 2'b10; // NONSEQ HBURST <= #1 3'b000; // SINGLE HWRITE <= #1 1'b1; // WRITE case (size) 1 : HSIZE <= #1 3'b000; // BYTE 2 : HSIZE <= #1 3'b001; // HWORD 4 : HSIZE <= #1 3'b010; // WORD default : $display($time,, "ERROR: unsupported transfer size: %d-byte", size); endcase @(posedge HCLK); while (HREADY !== 1) @(posedge HCLK); HWDATA <= #1 data; HTRANS <= #1 2'b0; // IDLE @(posedge HCLK); while (HREADY === 0) @(posedge HCLK); if (HRESP != 2'b00) $display($time,, "ERROR: non OK response write"); @(posedge HCLK); end endtask //----------------------------------------------------------------------- // AHB Read Burst Task //----------------------------------------------------------------------- task ahb_read_burst; input [31:0] addr; input [31:0] leng; integer i; integer ln; integer k; begin k = 0; @(posedge HCLK); HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR ln = leng; end HWRITE <= #1 1'b0; // READ HSIZE <= #1 3'b010; // WORD @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); while (leng > 0) begin for (i = 0; i < ln-1; i = i + 1) begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b11; // SEQ; @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); data_burst[k%1024] <= HRDATA; k = k + 1; end leng = leng - ln; if (leng == 0) begin HADDR <= #1 0; HTRANS <= #1 0; HBURST <= #1 0; HWRITE <= #1 0; HSIZE <= #1 0; end else begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR1 ln = leng; end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); data_burst[k%1024] = HRDATA; // must be blocking k = k + 1; end end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); data_burst[k%1024] = HRDATA; // must be blocking end endtask //----------------------------------------------------------------------- // AHB Write Burst Task // It takes suitable burst first and then incremental. //----------------------------------------------------------------------- task ahb_write_burst; input [31:0] addr; input [31:0] leng; integer i; integer j; integer ln; begin j = 0; ln = 0; @(posedge HCLK); while (leng > 0) begin HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b10; // NONSEQ if (leng >= 16) begin HBURST <= #1 3'b111; // INCR16 ln = 16; end else if (leng >= 8) begin HBURST <= #1 3'b101; // INCR8 ln = 8; end else if (leng >= 4) begin HBURST <= #1 3'b011; // INCR4 ln = 4; end else begin HBURST <= #1 3'b001; // INCR ln = leng; end HWRITE <= #1 1'b1; // WRITE HSIZE <= #1 3'b010; // WORD for (i = 0; i < ln-1; i = i + 1) begin @(posedge HCLK); while (HREADY == 1'b0) @(posedge HCLK); HWDATA <= #1 data_burst[(j+i)%1024]; HADDR <= #1 addr; addr = addr + 4; HTRANS <= #1 2'b11; // SEQ; while (HREADY == 1'b0) @(posedge HCLK); end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); HWDATA <= #1 data_burst[(j+i)%1024]; if (ln == leng) begin HADDR <= #1 0; HTRANS <= #1 0; HBURST <= #1 0; HWRITE <= #1 0; HSIZE <= #1 0; end leng = leng - ln; j = j + ln; end @(posedge HCLK); while (HREADY == 0) @(posedge HCLK); if (HRESP != 2'b00) begin // OKAY $display($time,, "ERROR: non OK response write"); end `ifdef DEBUG $display($time,, "INFO: write(%x, %d, %x)", addr, size, data); `endif HWDATA <= #1 0; @(posedge HCLK); end endtask `endif还需要一个APB的从机模块: `timescale 1ns / 1ps `define AMBA_APB3 `define AMBA_APB4 module apb_mem #( parameter P_SLV_ID = 0, parameter ADDRWIDTH = 32, parameter P_SIZE_IN_BYTES = 1024, // memory depth parameter P_DELAY = 0 // reponse delay ) ( //---------------------------------- // IO Declarations //---------------------------------- `ifdef AMBA_APB3 output wire PREADY, output wire PSLVERR, `endif `ifdef AMBA_APB4 input wire [2:0] PPROT, input wire [3:0] PSTRB, `endif input wire PRESETn, input wire PCLK, input wire PSEL, input wire PENABLE, input wire [ADDRWIDTH-1:0] PADDR, input wire PWRITE, output reg [31:0] PRDATA = 32'h0, input wire [31:0] PWDATA ); //---------------------------------- // Local Parameter Declarations //---------------------------------- localparam DEPTH = (P_SIZE_IN_BYTES+3)/4; localparam AW = logb2(P_SIZE_IN_BYTES); //---------------------------------- // Variable Declarations //---------------------------------- `ifndef AMBA_APB3 wire PREADY; `else assign PSLVERR = 1'b0; `endif `ifndef AMBA_APB4 wire [3:0] PSTRB = 4'hF; `endif reg [7:0] mem0[0:DEPTH-1]; reg [7:0] mem1[0:DEPTH-1]; reg [7:0] mem2[0:DEPTH-1]; reg [7:0] mem3[0:DEPTH-1]; wire [AW-3:0] TA = PADDR[AW-1:2]; //---------------------------------- // Start of Main Code //---------------------------------- //-------------------------------------------------------------------------- // write transfer // ____ ____ ____ // PCLK ___| |____| |____| |_ // ____ ___________________ _____ // PADDR ____X__A________________X_____ // ____ ___________________ _____ // PWDATA ____X__DW_______________X_____ // ___________________ // PWRITE ____| |_____ // ___________________ // PSEL ____| |_____ // _________ // PENABLE ______________| |_____ //-------------------------------------------------------------------------- always @(posedge PCLK) begin if (PRESETn & PSEL & PENABLE & PWRITE & PREADY) begin if (PSTRB[0]) mem0[TA] <= PWDATA[ 7: 0]; if (PSTRB[1]) mem1[TA] <= PWDATA[15: 8]; if (PSTRB[2]) mem2[TA] <= PWDATA[23:16]; if (PSTRB[3]) mem3[TA] <= PWDATA[31:24]; end end //-------------------------------------------------------------------------- // read // ____ ____ ____ // PCLK ___| |____| |____| |_ // ____ ___________________ _____ // PADDR ____X__A________________X_____ // ____ _________ _____ // PRDATA ____XXXXXXXXXXX__DR_____X_____ // ____ _____ // PWRITE ____|___________________|_____ // ___________________ // PSEL ____| |_____ // _________ // PENABLE ______________| |_____ //-------------------------------------------------------------------------- always @(posedge PCLK) begin if (PRESETn & PSEL & ~PENABLE & ~PWRITE) begin PRDATA[ 7: 0] <= mem0[TA]; PRDATA[15: 8] <= mem1[TA]; PRDATA[23:16] <= mem2[TA]; PRDATA[31:24] <= mem3[TA]; end end `ifdef AMBA_APB3 localparam ST_IDLE = 'h0, ST_CNT = 'h1, ST_WAIT = 'h2; reg [7:0] count; reg ready; reg [1:0] state=ST_IDLE; assign PREADY = (P_DELAY == 0) ? 1'b1 : ready; always @(posedge PCLK or negedge PRESETn) begin if (PRESETn == 1'b0) begin count <= 'h0; ready <= 'b1; state <= ST_IDLE; end else begin case (state) ST_IDLE : begin if (PSEL && (P_DELAY > 0)) begin ready <= 1'b0; count <= 'h1; state <= ST_CNT; end else begin ready <= 1'b1; end end // ST_IDLE ST_CNT : begin count <= count + 1; if (count >= P_DELAY) begin count <= 'h0; ready <= 1'b1; state <= ST_WAIT; end end // ST_CNT ST_WAIT : begin ready <= 1'b1; state <= ST_IDLE; end // ST_WAIT default : begin ready <= 1'b1; state <= ST_IDLE; end endcase end // if end // always `else assign PREADY = 1'b1; `endif // Calculate log-base2 function integer logb2; input [31:0] value; reg [31:0] tmp; begin tmp = value - 1; for (logb2 = 0; tmp > 0; logb2 = logb2 + 1) tmp = tmp >> 1; end endfunction // synopsys translate_off `ifdef RIGOR always @(posedge PCLK or negedge PRESETn) begin if (PRESETn == 1'b0) begin end else begin if (PSEL & PENABLE) begin if (TA >= DEPTH) $display($time,,"%m: ERROR: out-of-bound 0x%x", PADDR); end end end `endif // synopsys translate_on endmodule6、仿真 用VCS进行仿真,打印信息如下 图片 可见仿真完全正确,这里也只是做了AHB总线的单一传输和各种长度的增量突发,回环突发未涉及(对APB桥来说,它并不关心HBURST的信号值)。 下面挂两张仿真截图: 单一传输,先写后读: 图片 突发传输,先写完,再读完 图片
IP&SOC设计
# SOC设计
刘航宇
3年前
1
1,438
1
1
2
...
7
下一页