首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,187 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,144 阅读
3
【高数】形心计算公式讲解大全
8,752 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,450 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,818 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
刘航宇(共304篇)
找到
304
篇与
刘航宇
相关的结果
- 第 12 页
2022-04-12
【视频课程】STM32系统开发与protues仿真快速入门课
STM32系统开发与protues仿真快速入门课,上课层次分明,包含gpio与按键开发,中断,定时器,AD/DA转化,传感器,串口通信,远程通信技术,OLED液晶显示等等,由间到难,条理清晰。 如果视频失效,请关注我的哔哩哔哩账号可以免费观看 目录 GPIO&键盘扫描 定时器&OLED 串口&TIM+串口 传感器基础&OLED动态显示传感器原理&ADC基础 OLED动态显示 解决1us实现办法 远程通信&结语串口调试工具 综合视频 GPIO&键盘扫描 定时器&OLED 串口&TIM+串口 传感器基础&OLED动态显示 传感器原理&ADC基础 OLED动态显示 本节OLED配置允许不设置PB12-P15 output,直接基本三步后可以创建工程文件 解决1us实现办法 关于传感器代码移植,可以下载网上开源的驱动文件xx.h和xx.c文件,类似OLED驱动文件一样分别添加到工程文件夹中的Inc和Src中,最后用keill5打开用ADD进行文件添加!此处忘了可以回放第二节课OLED课 delay_ms实现 static inline void delay_ms(uint32_t delay) { HAL_Delay(delay); }delay_us实现 #define CPU_FREQUENCY_MHZ 72 // CPU主频,根据实际进行修改 static void delay_us(uint32_t delay) { int last, curr, val; int temp; while (delay != 0) { temp = delay > 900 ? 900 : delay; last = SysTick->VAL; curr = last - CPU_FREQUENCY_MHZ * temp; if (curr >= 0) { do { val = SysTick->VAL; } while ((val < last) && (val >= curr)); } else { curr += CPU_FREQUENCY_MHZ * 1000; do { val = SysTick->VAL; } while ((val <= last) || (val > curr)); } delay -= temp; } } 远程通信&结语 串口调试工具 串口调试助手 下载地址:https://wwu.lanzoub.com/i1y1g03gtifc 提取码: 综合视频
嵌入式&系统
刘航宇
4年前
0
1,589
15
GNURadio-软件无线电入门教程
目录 第一章 GNURadio 和软件无线电概述1.1什么是 GNU Radio 1.2为什么我们要使用 GNU Radio 1.3关于数字信号处理 1.4GNU Radio 是如何工作的 第二章 GNU Radio 软件安装与配置2.1操作系统的选择 2.2Linux 环境下的直接安装 2.3Linux 下使用PyBOMBS 辅助自动从源码构建 2.4Linux 下手动从源码编译构建请参阅: 2.5Windows 环境下的安装 2.6Mac OS X 环境下的安装 第三章 教程初阶3.1熟悉使用 GNU Radio Companion 第一章 GNURadio 和软件无线电概述 1.1什么是 GNU Radio GNU Radio 是一个软件框架,使用户能够设计、模拟和部署功能强大的软件无线电系统。它是一个高度模块化的,面向“流程图”的框架,带有一个全面的处理模块库,可以轻松组合并构成复杂的信号处理系统的应用程序。 GNU Radio 已用于大量的无线电应用程序。包括音频处理,移动通信,跟踪卫星,雷达系统,GSM,数字无线电等等,所有这些都在计算机软件中使用。 1.2为什么我们要使用 GNU Radio 以前,在开发无线电通信设备时,工程师必须先开发用于接收并处理特定信号的接收机, 来对特定信号传输进行解码或编码。随着数字信号处理与其算法越来越复杂,这些信号处理的平台也变得越来越复杂,通常需要较为高速的 ADC、FPGA 以及能将实时数据串流到计算机平台的连接芯片等,每个系统所对应的硬件平台不一定是一样的,这就带来了巨大的开发成本。通过使用软件无线电(SDR)设备进行模拟信号处理,在相同的硬件平台上可以同时兼容运行各种不同的软件程序,不仅节约了开发成本,也提高了开发新系统的效率。 1.3关于数字信号处理 作为一种软件框架,GNU Radio 通过硬件平台串流的比特数据流输入到计算机中,并在操作系统中运行相应的应用程序以此达到对特性信号进行处理的目的。 我们都知道计算机只能处理数字信号。如何去理解数字信号呢? 简单举个例子:当你想要录制一段人声的时候,说话的人会产生声音信号,该信号由震动导致周围气压发生变化而产生。这样一个时变的物理量就是一种信号。 图片 当空气波到达麦克风时,麦克风将变化的压力转换为电信号,即可变电压 图片 现在我们已经将信号转化为了电信号,在一些模拟系统中,已经可以开始对信号进行处 理。但是对于我们的计算机系统,一个数字的系统,这还远远不够。为了使计算机能够处理这样的数据,我们还需要满足两个条条件:1.是有限点数的 2.是在有限时间之内的 图片 因此,该数字信号可以由称为样本的数字序列表示。采样之间的固定时间间隔直接影响到采样率。提取物理量(电压)并将其转换为数字样本的过程由模数转换器(ADC)完成。相反,我们还有数模转换器(DAC),可从将计算机中提取数字序列转换为模拟信号。 现在我们已经有了一个数字序列,我们的计算机就可以使用它进行各种操作。 图片 同样,电磁波显然也是一种波,它跟声波有许多相同的性质。我们可以用天线将变化的电信号发射出去,这个电信号一般位于一个较高的频率上,可以是数百 KHz 到 GHz。通过使用软件无线电接收机,我们可以接收并对这些信号进行处理,以此进行我们想要的操作。 1.4GNU Radio 是如何工作的 在 GNU Radio 中,为了处理数字信号,我们可以使用简单的流程指示箭头将其连接: l1psgx5b.png图片 在上图中,Signal Source 即为信号源,左边的输入接口可以输入频率参数,右边的输出接口可以输出音频数据流。右边的 Audio Sink 为音频接收器,允许通过扬声器或其他音频设备播放出输入的信号。这就构成了一个十分简单的流程图,点击软件中的运行按钮即可非常简单快捷的编译流程图并运行。 GNU Radio 是一个框架,用于开发这些处理模块并创建流程图。软件自带大量的处理模 块,在这里简单举例一些: Waveform Generators 信号发生器 Constant Source 常数源(可以理解成直流分量) Noise Source 噪声源 Signal Source (e.g. Sine, Square, Saw Tooth) 信号源 Modulators AM Demod AM 解调 Continuous Phase Modulation 连续相位调制 PSK Mod / Demod PSK 调制/解调 GFSK Mod / Demod GFSK 调制/解调 GMSK Mod / Demod GMSK 调制/解调 QAM Mod / Demod QAM 调制/解调 WBFM Receive 宽带 FM 接收机 NBFM Receive 窄带FM 接收机 使用这些模块,我们只需要进行相应的连接操作,就可以快速搭建数字信号处理系统。另外,当然你也可以自己开发新的 block,或者将现有的块与其他软件结合在一起,开发出新的功能。 因此,GNU Radio 主要是用于开发信号处理模块及其交互的软件框架。它带有广泛的标准块库,开发人员可以在其中构建许多系统,是十分方便的软件无线电开发工具。 第二章 GNU Radio 软件安装与配置 GNURadio 的官方 GitHub 页面为 https://github.com/gnuradio/gnuradio。其首页中也明确说明了对于不同操作系统的不同安装方式。 2.1操作系统的选择 我个人最推荐使用 Ubuntu18.04 我在这个系统版本上搭建过很多次所需要的环境,没怎么出过问题,使用一直很稳定。19 版本或许可以,我没有尝试过,但是 20 版本一定不可以, 因为有接到过软件报错的情况报告。 2.2Linux 环境下的直接安装 对于GNU Radio,如果只是简单轻度使用我就建议大家直接使用 Linux 的二进制软件包安装。最快捷方便而且最重要不容易出错。根据 GNURadio 官方 GitHub 界面,首先的安装方式也是直接使用 apt 安装。 以下命令适用于 Debian,Ubuntu 及其衍生版本。它将使用 Python2 安装 GNURadio 3.7 版 sudo apt install gnuradio 对于以上操作系统,直接执行这条命令即可安装完成。如果遇到报错建议自行查询报错信息解决。对于其他 Linux 发行版,请查阅: https://wiki.gnuradio.org/index.php/InstallingGR#From_Binaries 2.3Linux 下使用PyBOMBS 辅助自动从源码构建 PyBOMBS 是安装GNURadio 以及相关软件工具的一个快捷工具。你可以使用它来安装各种 SDR 设备所依赖的支持库,绝大部分操作都是全自动的。 PyBOMBS 是方便用来从源代码构建 GNU Radio,UHD 和各种 Out of Tree(OOT)模块,然后将其安装到指定的用户目录中的工具。在使用之前,PyBOMBS 会检测用户的操作系统并在构建的第一阶段加载所有先决条件(可能会出现各种花式报错)。如果你对于自己解决 Linux 环境配置问题不是很有信心,我不建议你使用这种方法安gnuradio。 注意!!:GitHub 中详细描述了安装的步骤,请自行参阅: 项目地址:https://github.com/gnuradio/pybombs 因为它是从源代码安装GNU Radio,所以第五步可能需要一些时间,要进行更快的安装, 请参阅 https://wiki.gnuradio.org/index.php/InstallingGR#Ubuntu_PPA_Installation 2.4Linux 下手动从源码编译构建请参阅: https://wiki.gnuradio.org/index.php/InstallingGR#From_Binaries 2.5Windows 环境下的安装 在 Windows 环境下,官方提供了非正式版的 GNU Radio 3.7 和 3.8 的安装文件,虽然我也不推荐你真的在 Windows 平台运行这个软件,但是它在 Win 平台是真的可以使用的。不管是 USRP 还是 PlutoSDR,有驱动程序的话就可以使用。对于 USRP,可能存在固件版本的问题,按照教程后面的解决办法是可以解决的。 相关的安装软件包在这里下载:http://www.gcndevelopment.com/gnuradio/index.htm 2.6Mac OS X 环境下的安装 你是认真的? 请参阅:https://wiki.gnuradio.org/index.php/MacInstall 第三章 教程初阶 3.1熟悉使用 GNU Radio Companion 学习目的: 使用标准块库创建流程图 了解如何使用检测模块 Sink 调试流程图 了解GNU Radio 中的采样和调节功能 了解如何使用文档找出模块的功能 在本教程中,我们将从简单框图开始,探讨如何使用 GNU Radio 的图形工具GNU Radio Companion(GRC)来创建不同的框图。GRC 是为了简化 GNU Radio 而诞生的,有了它, 我们可以以图形化编程的方式创建 python 脚本,替代了传统的复杂代码编写,进而降低软件无线电编程的入门门槛。 那么我们开始。首先打开终端,输入以下指令。 $ sudo gnuradio-companion或者直接单击软件图标,也是可以运行软件的。 图片 如果你发现不仅应用程序中没有出现软件图标,而且终端也不能打开这个软件,那么你的安装很有可能出现了问题。请检查安装是否存在问题。 这里有一点区别。当你通过终端运行 GRC 时,下图绿色部分的终端会同时在系统终端里显示。而如果直接通过点击软件图标运行则只能在GRC 的终端面板中观察信息。 图片 首先我们来介绍软件界面。总共分为五个部分:库,工具栏,终端,工作区和变量。 红色区域为工具栏部分,放置了平时最常用的工具,比如运行、停止、编译等重要功能按键。 l1psl5it.png图片 新建、打开、保存、关闭 l1q067qo.png图片 打开/关闭变量编辑器、截图、剪切、复制、粘贴、删除选中模块 l1q06j9q.png图片 查看错误信息、编译流程图、执行流程图、停止运行流程图 l1q06to8.png图片 撤销、重做 l1q074k2.png图片 启用选中模块、禁用选中模块、绕过选中模块、反转禁用连接/模块的状态 l1q07e6n.png图片 查找模块、重置模块、打开选中阶梯模块源码 蓝色区域即为我们绘制具体流程图的地方。我们可以将右边灰色部分库中的模块拖入蓝色区域,并且将他们通过箭头连接起来,这样就可以构成一个真正的信号处理系统。 黄色部分显示的是当前框图中所使用到的变量。在蓝色部分的左上角可以看到两个方框, 分别是 Options 与 Variable,这两个是创建工程时就会自动创建的。 在界面的右边灰色区域中,存放了大量可以用于拖拽到流程图中的模块。其中有很大一部分是软件安装时就自带的,如果你安装了其他gnuradio 附属的插件脚本,也会一并显示在框中,通常自行安装的会显示在最后面。 图片 因为模块非常多,因此平时寻找想要的模块时一个一个手动翻找会非常麻烦。此时可 以点击工具架上的放大镜图标,或是输入 Ctrl + f 输入该块的关键字进行检索,就可以更容易的找到这个block。 例如,这里我们输入 sink(接收器),就可以看到包含单词“接收器”的所有块以及将在其中找到每个块的类别。 l1q08cz9.png图片 现在,我们来添加一个名为 QT GUI Time Sink 的块,方法是单击其名称并将其拖动到工作区中,或者双击其名称以将其自动放置在工作区中。 图片 工作区包含构成流程图的所有块,在每个块内部都有不同的块参数,但是,每个新流程图都需要有一个特殊的块,称为“选项块”。让我们双击选项块以检查其属性。 双击opthions 模块可以看到它的具体内容。Options 中包含了工程的特殊参数设置,每个流程图仅允许存在一个这样的选项模块。 图片 上面的 ID,title,author,description,分别表示这个流程图的 ID,标题以及作者和简介。该块的 ID 决定了生成文件的名称和类的名称。例如,一个 ID 为 top_block 的文件将生成文件 top_block.py 和 top_block 类。 Cavans Size 窗口大小控制流程图编辑器的尺寸。窗口大小(宽度,高度)必须介于 (300,300)和(4096,4096)之间。 Generate options 生成选项控制生成的代码的类型。非GUI 流程图应避免使用带有GUI 的组件或图形变量控件。 Run:流程图的运行可由变量控制,以在需要时启动和停止流程图。 Max number of output 最大输出数是流程图中任何方框所允许的最大输出项数;要禁用此功能,将max_nouts 设置为 0 即可。使用此功能可以调整流程图可以显示的最大延迟。 可以注意到另一个关键的东西。我们可以输入信息的字段中存在的不同颜色。这些实际上对应于不同的数据类型,我们将在本教程的后面部分介绍这些数据类型。 GRC 将我们在编辑器中创建的流程图转换为Python 脚本。因此当我们执行流程图时, 实际上是在运行编译好的Python 程序。ID 用于命名该 Python 文件,该文件与.grc 文件保存在同一文件夹内。默认情况下,ID 是默认值,因此它将创建一个名为 default.py 的文 件。更改 ID 可让我们更改保存的文件名,以便更好地管理文件。在 GNUradio 3.8 中,如果不更改默认 ID,则会收到错误消息,因此需要更改此 ID 才能运行流程图。 l1q0acje.png图片 Variable 即变量,它的 ID 是 samp_rate,你可以在框图中的其他地方调用这个变量。 例如: l1q0amjo.png图片 这样这里的数值就会随着该变量的变化而变化。 如果你点进了设置面板的第三个选项卡,就能看到有关这个block 的文档。通常情况下正规的 block 都是会写使用文档的,当然少数自定义的模块可能是没有的。 虽然这些说明是英文的,但是我十分建议大家自己去用谷歌等工具翻译一下这些文档,因为教程不可能每个详细的点都能讲到,有时还是得靠自己查一查的。 l1q0b5kp.png图片 如果我们删除了一个重要的参数,或是填入了什么不正确的参数,以至于我们的框图无法正常运行,那么此时你会看到执行按钮变成灰色不可点击的状态。此时报错信息按钮亮起,并且在出现错误的block 上,它的名称出现了红色的高亮显示。 l1q0bis5.png图片 你可以点击这个按钮,就可以看到存在问题的错误信息。 l1q0bsmb.png图片 在错误信息中,详细指出了错误出现的位置(如果看不懂就用翻译工具翻译一下,不过英语这么差我建议你直接放弃,这玩意高中生都能看懂。#日常劝退)我们只需要按照报错信息所提示的位置:模块-top block-选项中的一个参数:max_nouts l1q0c3uy.png图片 双击打开这个模块,就可以看到在模块中也存在同样的错误信息提示位于正下方。 l1q0cmos.png图片 错误明确指出,在这个输入框中数值“”不能被接受,因为这里必须填写的是一个数字, 我们填写数字 0 进去后点击确定,即可发现错误信息已经消失。执行按钮也亮起,说明框图无明显错误,可以正常运行。 现在,我们对如何找到块,如何将它们添加到工作区以及如何编辑块属性有了更好的了解,下面我们随意以几个 block 组成一个框图来进行简单的演示。 刚才我们拖入了 QT GUI Time Sink 这个模块,这是个图形接收器,可以同时显示多个信号。接下来我们搜索并向流程图中添加 Signal Source(信号源)模块,和 Throttle(节气门)模块,有关这几个模块详细的说明将在之后的教程中详细讲解,现在只需知道此块会限制流程图的某些数据即可,以确保它不会占用 100%CPU 资源导致电脑直接卡到裂开。 l1q0daor.png图片 “生成流程图”,“ 执行流程图”和“终止流程图”的快捷键分别为 F5,F6 和 F7。你可以在我们刚刚提到的工具架上点击这些按钮,或者直接按快捷键来进行相关的操作。当你按下生成流程图按钮之后,软件就会自动将你刚才绘制的流程图转化为一个 python 脚本文件。单击执行流程图按钮之后,就可以看到以下运行结果。 l1q0dl85.png图片 如果你不想运行了,只要点击终止流程图即可停止当前运行的程序。这样我们的第一个流程图就成功运行了。这是一个从信号源产生信号,经过限流器限制后输出到 time sink 进行接收并显示到屏幕上的操作。 你可以注意到这里有两根数据曲线被绘制出来,他们都来自于 Data 0,蓝色的曲线为Re(实部),红色部分为 Im(虚部)。 如果你根本不知道Re 和 Im 是什么个玩意儿,那么我建议你先学习下我们电子通信类专业的一门必修课程《复变函数》,这将会对你的系统性学习产生很大的帮助。 l1q0e32p.png图片 (有意思的是这两个信号的相位差正好为 ,这对于我们的零中频(Zero-IF)接收/发 2 射机有至关重要的意义,不过这个咱们以后有机会再提。) 在这个流程图中,我们很轻松的就把所有的block 连起来了,轻松的离谱你不觉得吗? 没有出现任何头疼的问题或是错误。那么有没有会出现错误的情形呢?当然有,而且经常会有。 Source IO size "8" does not match sink IO size "4". 源 IO 大小“ 8”与接收器 IO 大小“ 4”不匹配。 这似乎是一个和数据类型有关的报错。既然出现了这个错误,那么就说明我们还没有搞懂框图输入输出的数据类型到底是个什么玩意儿。那么现在就让我们点击软件上方的 help,这里面有对于数据类型的说明。 图片 图片 (最上面那个棕色的看的不是很清楚,不过这问题不大,你用鼠标把它选中高亮就能看清了。) 我们可以看到在许多编程语言中都可以看到的常见数据类型。在我们刚才搭建的流程图中,你可以注意到所有连接的模块端口均是蓝色的,这代表当前所传输的数据为Complex Float 32 类型,这意味着它们同时包含实部和虚部,并且每一个都是 Float 32 类型。我们可以推断出,当“Time Sink 时间接收器”采集到这样一个Complex 的数据类型时, 它将在两个不同的通道上同时输出实部和虚部的图像,也就是我们刚才看到的红蓝两种颜色的图像了。 现在进入其 Signal Source 的属性面板,并更改“输出类型”参数,将信号源更改为浮点型输出。此时我们传输的数据流是一个普通的 32 位浮点数。 图片 图片 可以看到现在我们所有连接的点均变成了橘色,(当然 throttle 也要调整,别问我为什么它还是蓝色的),这也就说明了目前数据类型均匹配,当然刚才出现的报错也就消失了。 图片 有同学发现 throttle 的输出连接了两个 block。不同的节点之间是可以支持多条同样的数据链路的,这是非常方便的一点,也是绝大部分图形化编程界面都具有的功能。可以注意到刚才的两条线此时变成了只有一条线,这是因为我们刚刚修改了数据类型。 现在让我们来尝试一些更复杂的框图吧。 图片 运行结果如下: 图片
通信&信息处理
# 软件无线电
刘航宇
4年前
0
5,720
6
2022-04-07
STM32CubeMX 软件安装明细教程
STM32CubeMX 软件的安装分为三个部分: 1-安装 JRE,JAVA 运行环境。 2-安装 STM32CubeMX 软件。 3-安装芯片的固件支持包,也就是 HAL 库。 清单:请依据清单进行复制在网上查对应版本下载(推荐用必应搜索) 1、JRE-8u201-windows-x64:64 位的 JRE 安装文件。 参考下载地址: https://www.java.com/zh_CN/download/windows-64bit.jsp(尽量安装最新版 64 位的Java) 2、en.stm32cubemx_v5-5-0:STM32CubeMX V5.50 安装文件。(可以最新版,STM32CubeMX 官网上可以免费下载) 3、STM32Cube_FW_F1_V1.8.0:STM32F1 系列芯片的固件支持包 V1.80。 4、STM32Cube_FW_L1_V1.9.0:STM32L1 系列芯片的固件支持包 V1.90。 目录 第 1 部分:安装 JRE。 第 2 部分:安装 STM32CubeMX 5.50 第 3 部分:安装固件支持包 第 1 部分:安装 JRE。 【01】点击“jre-8u201-windows-x64.exe”可执行文件,在欢迎界面中,点击“安装”按 钮开始安装 64 位的 JRE(注意:如果电脑操作系统为 32 位,请安装 32 位的 JRE)。 图片 【02】点击“确定”按钮,接受软件安装许可。 图片 【03】等待 JRE 安装完成。 图片 【04】 点击“关闭”按钮,结束安装程序,JRE 安装完成。 图片 第 2 部分:安装 STM32CubeMX 5.50 【01】 点击“en.stm32cubemx_v5-5-0”文件夹中的“SetupSTM32CubeMX-5.5.0.exe”, 即可开始安装 STM32CubeMX 5.50 版本,点击“Next”进入下一个界面。 图片 【02】 接受安装许可协议,点击“Next”进入下一个界面。 图片 【03】 把 2 个选项都勾选,才能点击“Next”进入下一个界面进行后续的安装。 图片 【04】指定安装路径,一般默认即可,点击“Next”,会弹出一个创建文件夹的消息框。 图片 【05】 在弹出的消息框中,点击“确定”进入下一个安装界面。 图片 【06】 在快捷图标的配置界面中,保持默认即可,点击“Next”进 图片 【07】 点击“Next”,开始安装软件,等待安装完成。 图片 【08】 点击“Next”,你将会看到安装完成的界面,点击“Done”结束安装程序。 图片 第 3 部分:安装固件支持包 【01】 点击桌面上“STM32CubeMX”快捷图标,打开该软件。 图片 【02】 点击“Help”菜单中的“Manage embedded software packages”菜单项。 图片 【03】 在弹出的“Embedded Software Packages Manager”对话框中,可以看到 ST 公司的各个 STM32 系列微处理器,展开某一系列的微处理器就可看到你可以获取的固件支持包的版本和大小。对于没有安装的固件支持包,其左侧的小方框是空白的,如果安装成功的 固件支持包,改小方框内部则填充为浅绿色。 在该对话框中,你可以通过左下角的“From Loacal…”按钮进行导入本地离线包,或者通过“From Url…”按钮进行在线下载解压安装。 选一个最新的库也可以的,安装只需要点击安装那个单词!安装完毕后就结束了可以听课了! 报错看这个: https://blog.csdn.net/it_angel_/article/details/104442217 图片 【04】 在本教程中采用的是最方便快捷的安装方式-解压离线包。 首先创建一个文件夹,用来存放你已经下载并解压好的芯片固件支持包,例如:在 C 盘下创建名为“STM32Cube_FW”的文件夹,并将解压后的固件支持包拷贝过来。 图片 【05】 在 STM32CubeMX 主界面中点击“Help” 菜单中的“Updater Settings”菜单项。 图片 【06】 在弹出的“Updater Settings”对话框中,你看到固件支持包保存的默认路径。 图片 【07】 点击默认路径右边的“Browse”按钮,指定到我们下载并压缩好的固件支持包保存的文件夹位置,即 C 盘下的“STM32Cube_FW”的文件夹。 图片 【08】 点击“OK”即可完成固件支持包的安装。 再次打开“Embedded Software Packages Manager”对话框,此时,你将看到已经安装好的芯片固件支持包左侧的小方框里面填充满了浅绿色,同时显示你安装的版本号。 至此,整个 STM32CubeMX 的软件安装完成。 图片
刘航宇
4年前
2
3,099
15
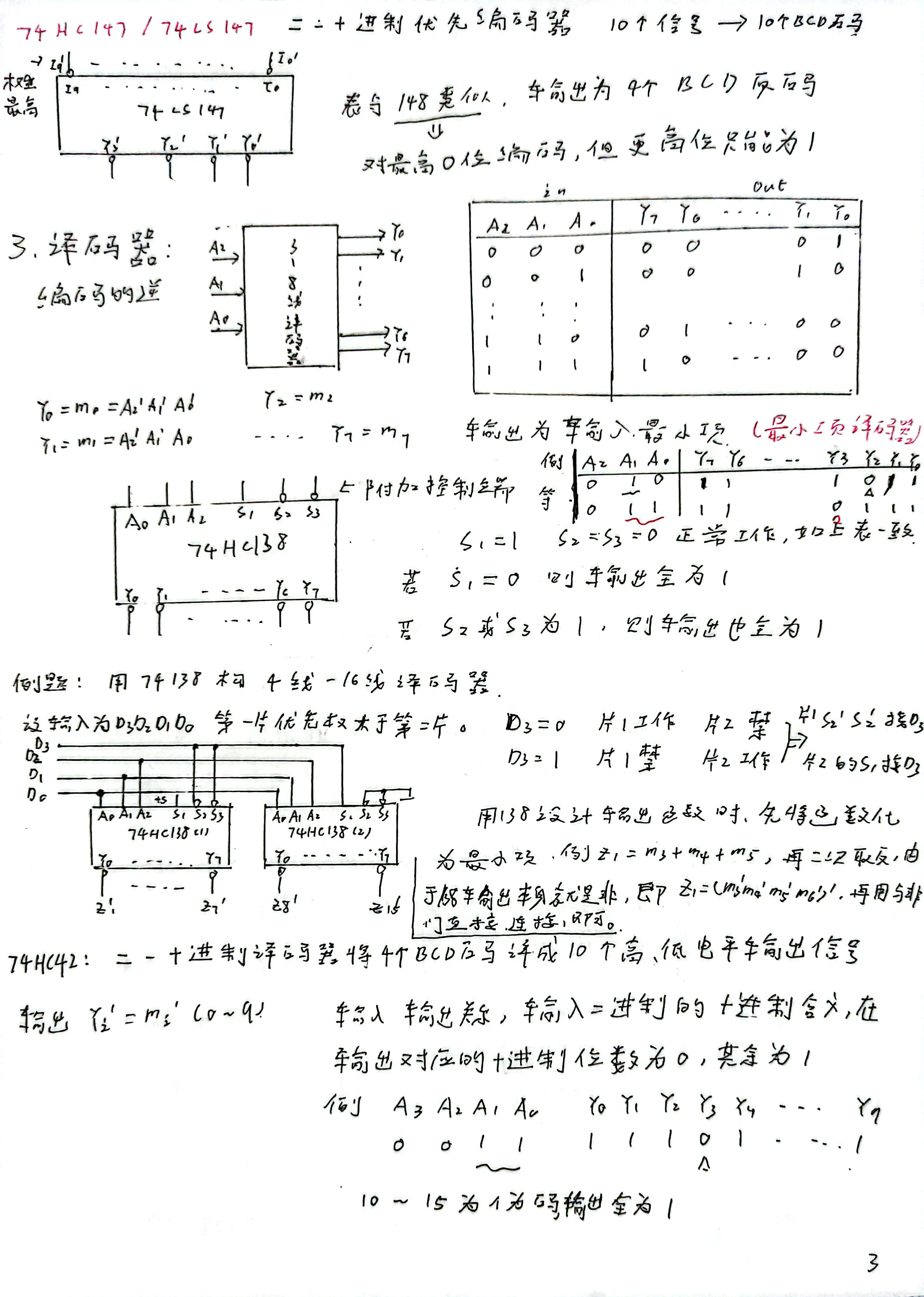
西北大学数字电子技术个人考研笔记
西北大学843、849历年真题 下载地址:https://wwek.lanzoue.com/ip1gv2m1mg3c 提取码: 警告 若个人或辅导机构 擅自复制本文直接或间接盈利 、请向我举报,举报方式见下面,本人以 著作权法 追查! 本站域名由sciarm.com更变为ee.ac.cn 和下文页面中信息不冲突 举报方式 1.邮箱hyliu@ee.ac.cn 2.点击博客中留言或私聊都可
嵌入式&系统
# 电子线路
刘航宇
4年前
0
1,556
20
2022-04-07
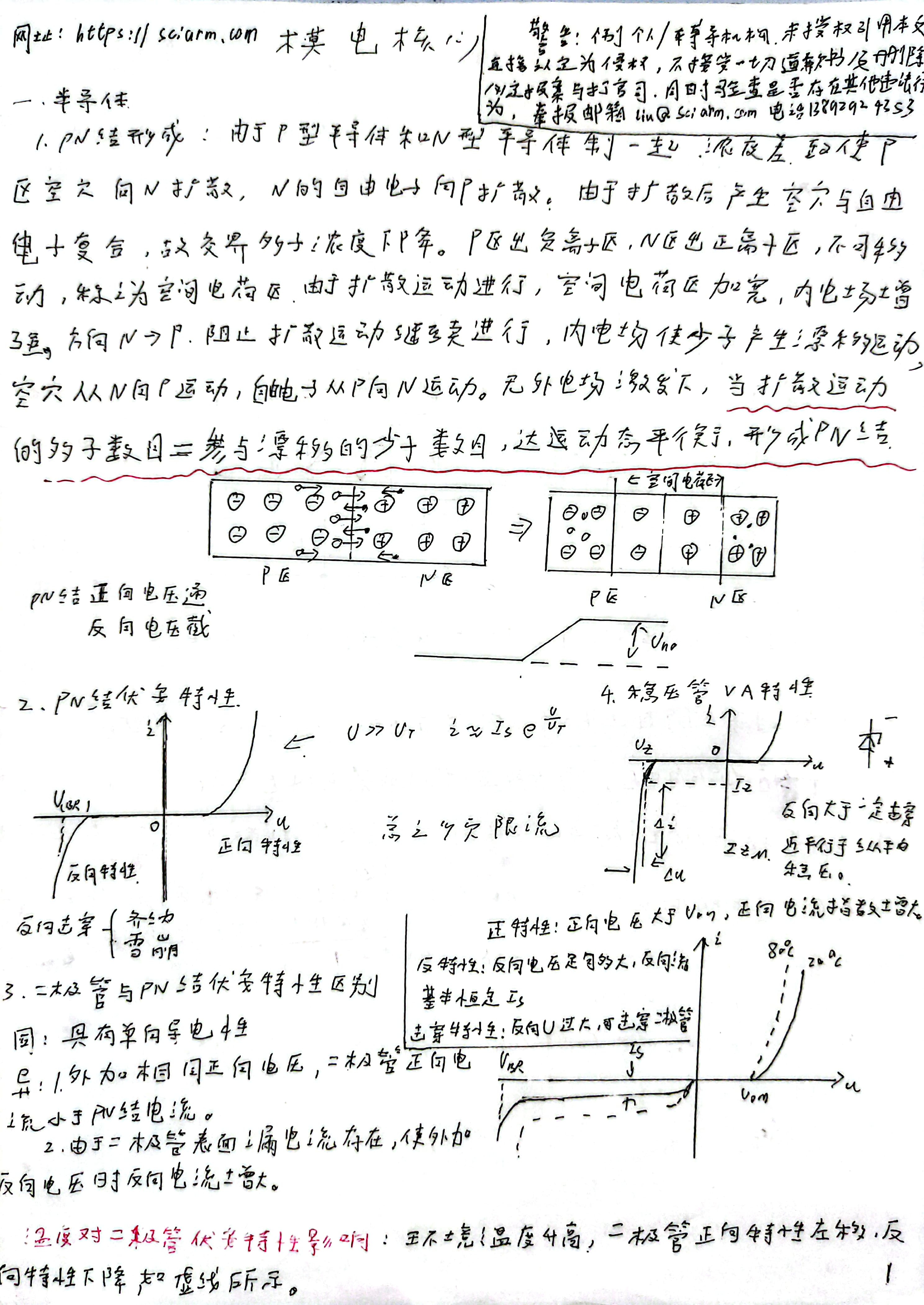
西北大学模拟电子技术个人考研笔记
西北大学843、849历年真题 下载地址:https://wwek.lanzoue.com/ip1gv2m1mg3c 提取码: 警告 若个人或辅导机构 擅自复制本文直接或间接盈利 、请向我举报,举报方式见下面,本人以 著作权法 追查到底!同时核查该机构/个人 是否有非法出书情况 、是否有 出版权与书号 , 一并交于公安机关追查 ! 本站域名由sciarm.com更变为ee.ac.cn 和下文页面中信息不冲突 举报方式-请携带证据举报 1.邮箱hyliu@ee.ac.cn 2.点击博客中留言或私聊都可
嵌入式&系统
我的随笔
# 电子线路
刘航宇
4年前
0
1,855
32
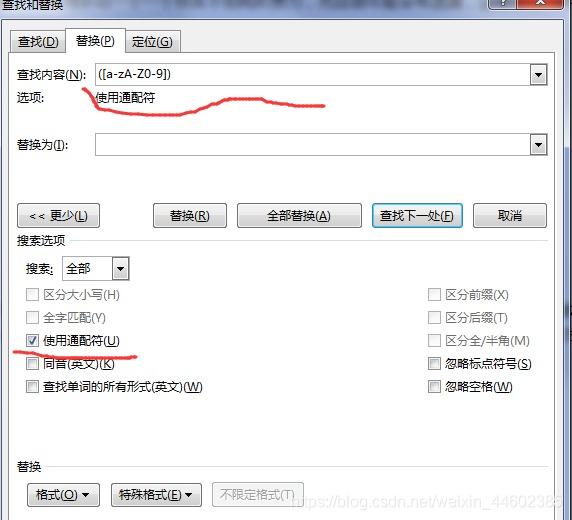
论文写作中如何把word里面所有数字和字母替换为新罗马字体
在比较正式的论文写作中,这些英文和数字的格式要求是Time New Roman。 1、在word中点击替换,或者使用快捷键Ctrl+H打开“查找和替换”窗口。 2、在查找内容中输入“([A-Z0-9]) ”(不包括引号,但包括小括号),这个意思是替换所有大写字母和数字,如果要替换小写字母,则输入为“([a-zA-Z0-9])”。然后点“更多”,勾选 “ 使用通配符“鼠标点击“替换为” 后面的白框 同理带有中括号的角标可以输入“[*]”进行替换 图片 3、点击格式下拉选项–选择字体 选择西文格式中的“Time New Roman ”或者其他你想要的格式,然后点击确定就可以了 图片 图片
写作办公
# 写作技巧
刘航宇
4年前
0
10,144
5
2022-04-03
【美文】想见的人,别等待
图片 城南花开,思念渐浓。 春风吹醒了一草一木,也吹动了一颗藏满爱意的心。 若你问我,人间四月,最想见谁。 答案只能是你。 在碧波荡漾的湖边,在桃花飞舞的林间,在每一个清晨,每一个黄昏,都想与喜欢的人见上一面。 像朱生豪写的:“醒来觉得甚是爱你”。 有的人,一眼万年,有的爱,经久不衰。 春天的浪漫,不在于樱花美,杏花娇,而在于这山与水,是与你见的,这星与月,是与你共赏。 听闻:花的飘零,会被芬芳的泥土滋养;雨的坠落,会被温柔的湖水接住。 世间的每个人,每种爱,都有最后的归宿。不是在时光的这头,就是在时光的那头。 你看这人间四月,花已开好,春林初盛。 想见的人,别等待,即使风尘仆仆,也要赶路去见,即使大雨倾盆,也要打伞去见。
励志美文
刘航宇
4年前
0
346
3
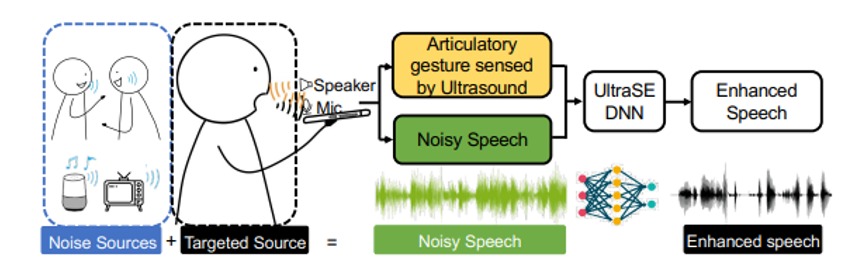
UltraSE: Single-Channel Speech Enhancement Using Ultrasound阅读感悟
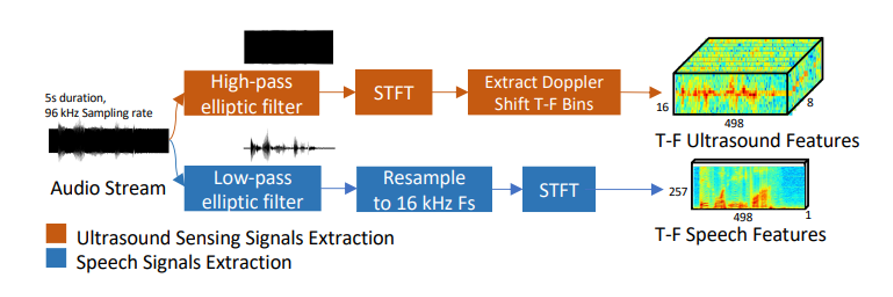
目录 一、论文基本信息 二、论文主要内容2.1 研究的背景 2.2 研究的目标 2.4 困难与拟解决对策, 2.5 技术优势 2.6 研究技术简述 2.6.1 ULTRASE DNN 模型概述2.6.2 基于 CGAN 的跨模态训练 2.6.3 ULTRASE 实现 2.7 研究验证2.7.1 微基准比较 2.7.2 消融研究 2.7.3 系统效率 2.8 文章结论 三、阅读理解与心得 参考文献 一、论文基本信息 作者 :孙科(加州大学圣地亚哥分校); 张新宇(加州大学圣地亚哥分校) 出版源 :第27届移动计算和网络国际会议论文集2021年10月第160-173页 摘要 :鲁棒语音增强被认为是音频处理的圣杯,也是人机交互的关键要求。用单通道、纯音频方法解决这个任务仍然是一项艰巨的挑战,尤其是在涉及相互竞争的扬声器和背景噪声混合的实际场景中。在本文中,我们提出了UltraSE,它使用超声波传感作为一种补充模式,将所需说话者的声音从干扰和噪声中分离出来。UltraSE使用商用移动设备(例如智能手机)发射超声波并捕捉说话者发音手势的反射。 它引入了一种多模态、多领域的深度学习框架来融合超声多普勒特征和可听语音频谱图。此外,它还利用一个基于跨模态相似性测量网络的经过对抗性训练的鉴别器来学习两种异质特征模式之间的相关性。我们实验验证了UltraSE同时提高了语音清晰度和质量,并且大大优于最先进的解决方案。 二、论文主要内容 2.1 研究的背景 人类听觉系统非常有能力在干扰扬声器和噪音的混合中挑选出语音源,这仍然是机器听觉的基本挑战。在当今人机交互和人机交互的数字通信系统的激增下,但这个问题仍然存在。示例:移动VoIP、语音命令、现场语音的后期制作等。语音分离与增强(SSE)的相关研究问题通常被认为是音频处理的圣杯。经典解决方案需要依赖先验知识(即每个扬声器的特征工程)或[1] 定向麦克风阵列来将所需的源与环境声音隔离开来。在过去的几年里,深度学习技术已经激增并显着推进了该领域,实现了单麦克风扬声器独立SSE。在分离2个净语音的混合物时,最先进的解决方案已证明平均音频质量提高了约 10 dB。然而,超过2个扬声器与背景噪声混合的具有挑战性的情况很少受到关注。最近的一个初步测试表明,现有的深度学习模型在这种情况下通常表现不佳,因为非结构化背景噪声损害了它们识别语音流中可分离结构的能力。此外,现有的纯音频方法无法解决标签排列问题,即将模型输出与所需的说话者相关联。视听算法利用说话者面部的视频记录来同时解决SSE和排列问题。然而,在特定视角和可调节照明条件下对相机的需求限制了它们的实际可用性[2]。 2.2 研究的目标 利用超声传感作为一种补充方式,将所需的说话者语音与噪声和干扰分开。 这种方法称为 UltraSE,适用于配备单个麦克风和扬声器的商品移动设备(例如智能手机)。 图1说明了该文的基本思想。在录音过程中,UltraSE 不断发出听不见的超声波,该超声波由靠近智能手机的说话者的发音(嘴唇运动)调制。 因此,麦克风记录的信号既包含可听见的声音,也包含听不见的反射。如图1 所示,虽然可听声音(“绿色”)混合了目标清晰的语音(“黑色”)和其他干扰以及背景噪声(“蓝色”),但听不见的反射(“橙色”)仅捕捉目标用户与清晰语音相关的发音手势动作。UltraSE采用DNN框架捕捉这种相关性,并对可听声音进行去噪 图片 图1:UltraSE 针对用户手持智能手机在嘈杂环境中录制语音的场景。UltraSE 使用超声波传感作为一种补充方式,将所需说话者的声音与干扰分开。 2.4 困难与拟解决对策, 问题一:尽管存在干扰,如何通过超声波描述发音姿势?捕捉精细的发音手势是一项挑战,因为它们速度快(80厘米/秒),位移小(小于5厘米)。此外,由于谐波和硬件伪影,语音和超声波之间存在相互干扰 解决对策:充分利用了超声波的优势,即高采样率和与时间域中清晰语音的完美对齐。作者设计了发射超声波形来捕获短期高分辨率多普勒频谱图,并采用一次性发射体积校准来减少跨模态干扰。 问题二:如何设计一个 DNN 模型来融合这两种模态并表示它们的相关性?没有现有方法能够解决作为 UltraSE 基础的跨模态降噪问题,即使用一种模态(超声波)来重建受噪声/干扰污染的另一种模态(语音)。 解决对策:由于两种模态的物理特征特征不同,我们设计了一个双流 DNN 架构来处理每个模态,并设计一个自注意力机制来融合它们。 此外,作者提出了一种基于条件 GAN (cGAN) 的训练模型,该模型具有新颖的跨模态相似性测量网络,以实现这种能力。 问题三:如何提高增强语音的清晰度和质量? 解决对策:时频 (T-F) 频谱图的幅度对于语音清晰度至关重要,而相位决定了语音质量。作者将 UltraSE 扩展为两阶段多域 DNN 架构,该架构优先优化 T-F 域中的清晰度,然后在T域中重构相位以提高语音质量。根据经验观察,我们将多模态融合网络置于 T-F 域内,即发音手势与语音清晰度更相关。 2.5 技术优势 纯音频语音增强:利用T-F 域方法、T域方法和多领域方法对非语音噪声表现出可接受的性能,但它们仍然无法处理涉及多个干扰。为了解决此类语音分离问题,Deep clustering 为每个源训练语音嵌入,然后使用聚类算法将它们分离。PIT在训练过程中迭代地改变源的排列,以训练一个排列不变的语音分离模型。这些方法仍然需要先验地知道说话人的数量,并且不适用于超过3个说话人加上噪声的情况。此外,标签排列问题仍然存在——它们可以分离多个语音源,但不能自动识别哪个来自目标说话者,这可能会阻碍某些机器操作的后端任务(例如,智能手机上的语音助手)。UltraSE克服了所有这些缺陷。 多模态语音增强为了解决排列问题:视听(AV)方法使用对象面部的视频记录作为音频的提示,有许多缺点。例如除了麦克风之外,他们还需要一个额外的摄像头,在良好的光照条件下指向拍摄对象的脸部,这在许多典型用例中是不方便的,甚至是不可行的。此外,相机在许多对隐私敏感的地方无法使用。前人探索了使用超声作为增强语音的补充方式的想法。然而,这些作品都需要特殊的超声波硬件。相比之下,UltraSE 只需要智能手机上的单个音频通道,并克服了模态之间的相互干扰等实际挑战。此外,他们使用传统的方法,即非负矩阵分解和非线性回归,只显示了对环境噪声的语音增强性能,而不是语音干扰。UltraSE 通过设计多模态多域 DNN 框架进一步突破了这一想法的极限,以实现与视听方法类似的语音分离和增强性能。 无需设备的超声波传感:无设备超声波传感技术可以利用商品移动设备上的扬声器和麦克风来跟踪附近物体的距离/方向变化。最先进的超声波手势跟踪方案可以达到毫米级的精度。 除了位置和手势跟踪,最近的研究还尝试使用超声波传感进行唇读[41]。 然而,由于空间分辨率不足,它们只适合粗略的传感应用,相比之下,UltraSE 率先展示了超声波传感可以作为一种补充方式来解决鸡尾酒会问题并将语音增强提升到一个新的水平。 2.6 研究技术简述 UltraSE 代表了首个使 SSE 性能接近多通道解决方案的纯音频方法,同时克服了标签排列问题。下面简述出三个重要技术贡献: • 作者设计了一个多模态多域 DNN 框架,用于单通道语音增强,融合了超声和语音特征,同时提高了语音清晰度和质量。 2.6.1 ULTRASE DNN 模型概述 第一步是从原始信号创建 DNN 输入特征。然后,我们设计一个两阶段、多模态、多域的 DNN 模型,该模型包括三个关键模块,简述如下。 T-F 域多模态振幅网络模块通过使用语音和超声波作为输入来生成幅度理想比率掩码 (aIRM),即净和噪声频谱图的幅度之间的比率。它由两个子网组成。 子网 (i) 双流特征嵌入:我们的模型首先使用嘈杂语音的 T-F 频谱图和并发超声多普勒频谱图作为输入。然后,我们设计了一个双流特征嵌入架构,将不同的模态转换到相同的特征空间,同时保持它们的时域对齐。 子网 (ii) 语音和超声融合网络:然后,我们在频率维度上连接每个流的特征。进一步应用自我注意机制来融合级联特征图,让多模态信息相互“串扰”。融合的特征随后被送入 BiLSTM 层,然后是三个 FC 层。结果输出是一个幅度掩模,它与原始噪声幅度谱图相乘以生成幅度增强的T-F 谱图。 图片 图2:UltraSE的多模态多域 DNN 设计概览。卷积层表示法:Channels@Kernel size 如图3说明了DNN 输入特征的预处理步骤工作流程。 l1ev5znd.png图片 图3:DNN 输入特征设计 l1ev76fq.png图片 图4:UltraSE基于cGAN的跨模态训练概览 基于cGAN 的跨模式训练,如图 4 所示,我们设计了一种基于 cGAN 的训练方法,以进一步去噪幅度增强的T-F频谱图。在我们的cGAN 模型中,生成器就是上面的 T-F 域多模态幅度网络;鉴别器被设计成鉴别增强的频谱图是否对应于超声传感特征。T 域相位网络。我们使用iSTFT(一个固定的 1D 卷积层)将幅度增强的 T-F 频谱图转换为T域波形。为了微调增强信号的相位,我们设计了一个编码器-解码器架构来重建相位以接近 T 域中的净语音。 • 作者设计了一个基于cGAN 的跨模态训练模型,该模型有效地捕捉了超声和语音之间的相关性以进行多模态去噪。 2.6.2 基于 CGAN 的跨模态训练 UltraSE 的基本问题是多模态降噪,即使用一种模态(超声波)来恢复被噪声/干扰污染的另一种模态(语音)。前者感知分辨率低,但无干扰,与后者相关。尽管我们有意保持两者之间的时间对齐,但很难强制多模态融合网络“理解”这种多模态相关性,因为传统的损失函数(例如MSE)只能训练网络来清理端到端的TF频谱。 因此,我们提出了一种基于 cGAN 的训练方法,该方法隐含地将跨模态相关性的最大化本身作为训练目标。 任何GAN设计中的一个关键要素是定义鉴别器使用的相似度度量。与在相同类型特征之间进行比较的传统 GAN 应用程序(例如图像生成)不同,我们的跨模态 cGAN 需要区分增强的 TF 语音频谱图是否与超声多普勒频谱图匹配(即,它们是“真实的”还是“假”对)。 我们提出了一个跨模式的 Siemese 神经网络来应对这一挑战。Siamese 神经网络使用共享权重和模型架构,同时在两个不同的输入向量上协同工作以计算可比较的输出向量。它传统上用于测量来自相同模态的两个输入之间的相似性,例如,两个图像。为了启用跨模态连体神经网络,我们创建了两个独立的子网络(图7),旨在分别表征语音和超声的时频域特征之间的对应关系。基本架构下,这两个输入是一个 CNN-LSTM 模型。 由于人类语音在 F 域中包含谐波和空间关系,因此语音 CNN 子网络使用扩张卷积进行频域上下聚合。超声传感的多普勒频移主要包含局部特征。因此,超声 CNN 子网络仅包含传统的卷积层。在卷积之后,使用 Bi-LSTM 层来学习两种模式的长期时域信息。 最后,引入三个全连接(FC)层来分别学习两个可比较的输出向量。 我们强调,这种跨模态设计不共享架构和参数,这与传统的 Siamese 网络不同。 l1ev87c1.png图片 图5:跨模态相似性测量网络的输出 PDF 图5显示了输出的概率密度函数 (PDF),其中较小的值表示较高的相似性。很明显他输出的真对和假对的PDF完美分离,这意味着我们的相似性测量网络可以有效地区分一对语音和超声输入是否由相同的发音姿势生成。 • 我们收集了一个新的语音数据集——UltraSpeech,并与最先进的解决方案相比验证了 UltraSE 的性能。 2.6.3 ULTRASE 实现 传统的语音数据集只包含原始语音,没有超声波传感信号。为了评估 UltraSE,我们创建了一个名为 UltraSpeech 的新数据集,其中包含两者。 数据收集:我们招募了20名流利的英语人士(4名女性,16 名男性,平均年龄 25 岁)来收集 UltraSpeech 数据集。每个参与者被要求在安静的环境中使用 2 种典型的电话持有方式(“电话”模式和“走向麦克风”模式,如图8(b)所示)在 TIMIT 语音语料库[3]中说出至少300个句子。同时,我们使用定制的 Android 应用程序 UltraRecord,通过智能手机底部的扬声器和麦克风以 96 kHz 的采样率发出超声波信号并捕获音频片段。 请注意,我们不限制用户将智能手机与嘴巴保持特定距离。总的来说,我们为每种握持方式收集了8k 5秒净的语音片段。我们遵循现有的 SSE 工作,合成混合生成嘈杂的语音数据集。干扰语音来自 TIMIT 数据集,其中包含 6300 个不同的英语句子,由 630 位说话者生成,总共持续 3.5 小时。环境噪声数据集来自 AudioSet,其中包含来自现实生活的526种噪声类型的超过170万个10秒片段,包括广泛的人类和动物声音、乐器和流派以及日常生活中常见的噪声。此外,我们生成了一个训练集,其中干扰语音和净语音来自同一个说话者。 这被广泛认为是 SSE [4] 最具挑战性的案例,因为干扰具有与所需语音无法区分的相同听觉模式。 我们将其添加到训练数据集中,以强制模型利用除了听觉特征之外的超声特征。我们的训练数据集包含由三星 Galaxy S8 智能手机收集的 15 名参与者的净语音。每个参与者的净语音都混合了 20 种不同的噪音设置。 对于每个噪声设置,干扰扬声器的数量 ? 均匀分布在 [0,4]中,SNR 均匀分布在 [−9, 6] dB(平均为 -1.5 dB)中。训练数据总共包含 120k 5 秒的嘈杂语音片段(300 小时)。 l1evaw7s.png图片 l1evbffv.png图片 我们在 Pytorch 中实现了 UltraSE DNN模型。特征图的维度和每一层的参数如图 2、6、7 和表 1、2、3所示。除了最后一层应用了sigmoid 之外,ReLU 激活跟随所有层。对于训练,我们使用 Adam 优化器,初始学习率为 1? − 04,每 5 个 epoch 下降25%,总共 20 个 epoch。UltraSE有15.5M和3.1M参数用于第一阶段和第二阶段 DNN。 2.7 研究验证 2.7.1 微基准比较 在本节中,我们的默认测试数据集包括另外 5 名参与者在“Towards mic”模式下的净语音,使用三星 S8 收集。我们的测试环境包括 6 种不同的干扰加噪声设置:1? +?、2? +?、3? +?、> 3? +?、2?(“s”和“a”表示干扰扬声器和环境噪声)和最难的情况 >= 2 个同说话者干扰加上噪声 (>= 2?? + ?)。 噪声语音信号的 SNR 水平均匀分布在 [−9, 6] dB 中。 UltraSE 的所有结果都来自从训练数据集生成的单个模型。我们将 UltraSE 与 4 种最先进的 SSE 方法进行比较,PHASEN [5](TF 域方法)、SEGAN(T 域方法)、AVSPEECH (视听方法)、Conv-TasNet(语音分离法)。为了公平比较,我们重新实现了 PHASEN、SEGAN 和 Conv-TasNet,并在 UltraSpeech 数据集上训练和测试它们。PHASEN 和 SEGAN 只使用 1? + ? 训练集,因为它们是为语音增强而不是分离而设计的。PHASEN 和 SEGAN 在 1? + ?(见表 4)下的结果与原始工作相似,这表明了我们实现的正确性。对于语音分离方法,即 Conv-TasNet,我们首先在“2?”环境中对其进行训练和评估,以检查我们实现的正确性。 然后,我们使用“2? + ?”数据集以 2 位说话者的净语音作为基本事实来训练模型,并在表 4 中比较其他环境中的结果。对于AVSPEECH,由于我们的数据集没有录像,我们直接使用[6]中的结果作为基线。 l1evc762.png图片 与最先进的语音增强方法相比,UltraSE 显着提高了嘈杂和多说话人环境中的语音质量和清晰度。表4显示了在 [−9, 6] dB 范围内均匀分布的所有输入 SNR 水平下的测试结果。UltraSE 在所有4个指标上均优于 PHASEN 和 SEGAN。在 1? + ? 环境中,UltraSE 实现了平均 17.25 SiSNR (18.75 ΔSiSNR) 和 3.50 PESQ。在具有多扬声器干扰的其他环境中,超声传感模式的作用更为突出,在2个基线上分别平均提高了 6.04 dB 和 9.77 dB 的 SiSNR。即使对于最困难的情况 >= 2?? + ?,UltraSE 仍可实现 8.97 dB SiSNR 和 2.52 PESQ。 此外,UltraSE 的性能略高于AVSPEECH,这可能是因为超声波特征的采样时间粒度比视频帧更精细,并且可以更好地与语音信号对齐。 大多数现有的语音分离方法只能在有限数量的干扰说话者(2∼3)和没有环境噪声的情况下工作[29,30,73,76]。 如表4所示,当使用“2? + ?”数据集训练 Conv-TasNet 时,Conv-TasNet 在“2? + ?”和“2?”设置中取得了良好的性能,但在其他复杂的设置中表现不佳 环境。 相比之下,在 > 3? + ? 设置下,UltraSE 优于 Conv-TasNet 约 6 dB 的 SDR 或 SiSNR,STOI 为 10%,PESQ 为 24%。 l1evcov7.png图片 图8中的散点图显示了测试数据集中每个句子的输入和输出 SiSNR,其中包括所有 6 个环境。UltraSE 在不同环境和句子中始终如一地实现高性能,平均 14.75 dB SiSNR 增益。 即使在 -9 dB 输入的最坏情况下,增强型语音平均达到 8.86 dB SiSNR。 2.7.2 消融研究 我们进行了消融研究,以更好地了解 UltraSE 中不同设计组件的性能。 这里的测试数据集包括除了“>= 2?? + ?”之外的所有环境,这在实践中并不常见。 表 5 总结了结果。 l1evdhei.png图片 “No T domain”表示没有“T do-main波形语音增强”的DNN模型。 结果表明,该模块几乎不影响 STOI,这是一种语音清晰度指标。 但它有助于分别获得 0.46 dB SDR、0.58 dB SiSNR、0.12 PESQ,这证明它可以进一步提高 T-F 域多模态网络,生成语音的感知质量。 “No cGAN”表示没有“基于 cGAN 的跨模态模型训练”的模型。 应用 cGAN 时,所有指标都显着提高,因为我们的 cGAN 设计迫使网络学习超声和语音之间的相关性,这是 UltraSE 设计背后的关键原则。 “No Fusion Network”是指超声和语音信号的特征图在时频域中直接拼接,没有融合块。 性能略有下降,因为融合块有助于多模态特征相互“串扰”。 “No Ultrasound”表示网络开头没有超声流的网络。 结果变得接近于没有超声传感的传统语音增强方法,例如,PHASEN。 2.7.3 系统效率 时间消耗:我们评估 UltraSE 在 3 个平台上的运行时处理延迟,包括 NVIDIA GTX 2020 (GPU)、Intel i9-9980 3.00GHz (CPU) 和配备 Qual comm Snapdragon 835 CPU 的三星 Galaxy S8 (手机)。前两个对应于 UltraSE 被卸载到受信任的云或边缘服务器的情况。 表6总结了结果。GPU 服务器仅经历 14.85 毫秒的延迟,这对于 VoIP 应用程序来说是可以接受的(最多 150 毫秒 [7])。 智能手机外壳是使用三星 Galaxy S8 上的 Pytorch Mobile [8] 测量的。请注意,最新版本的 Pytorch Mobile [8] 仅支持单 CPU 处理,没有任何 GPU/NPU 支持。 因此,延迟相对较高(处理 5 秒语音需要 25.08 秒),这仅适用于离线处理应用程序,例如音频消息和录音。有大量关于提高智能手机 DNN 效率的文献 [9],表明使用移动 GPU/NPU 可以减少 50 倍以上的延迟。 我们将为我们未来的工作探索这些解决方案。 另请注意,由于使用了 Bi-LSTM 块,UltraSE 需要以 5 秒为单位处理输入。 这意味着它的 SSE 在 5 秒的初始引导期后开始生效。 l1eve81q.png图片 能耗:我们的实验表明,典型的智能手机(Samsung S8)可以连续使用 UltraSE 录制语音,同时发射超声波信号 60.57 小时(不显示)。 我们使用 Android Profiler [80] 进行的测量显示 UltraSE 的 CPU 负载平均为 48.7%,功耗为在 0 到 3 之间的“1”级别。当卸载到服务器时,计算能量消耗变得可以忽略不计。 唯一的开销是 UltraSE 需要将原始的 48/96 kHz 采样率的音频流上传到服务器,然后从服务器下载增强的语音。我们的实验表明,三星 S8 可以在卸载模式下连续运行 UltraSE 并通过 WiFi 上传/下载音频流 10.82 小时。服务器卸载可能会引发其他问题,例如安全性,但这超出了我们当前工作的范围。 2.7.4 泛化采样频率 通过 96 kHz 采样率数据集训练的 UltraSE 模型可直接用于增强以 48 kHz 采样率记录的测试语音。只要超声传感特征的 FFT 窗口长度和跳跃长度分别保持 85 ms 和 10 ms,48 kHz 采样率的特征分辨率与 96 kHz 采样率的情况相同。表5 显示在 96 kHz 采样率训练模型上测试 48/ 96 kHz 采样率数据集时性能下降可忽略不计。 l1evf1bn.png图片 图8:发音手势的 SNR。 握持方式:在“电话通话”模式下(图 8(a)),用户的面部部分遮挡了超声波信号,因此我们训练了一个与“朝向麦克风”模式不同的模型(图 8(c))。 UltraSE 可以使用智能手机内置的基于 IMU 的握持方式检测算法自动选择模型 [81]。 我们的实验表明,在 -1.5 dB 平均输入 SNR 下,由于遮挡,“电话呼叫”(12.47 dB SiSNR)的性能略低于“Towards mic”(13.12 dB SiSNR)。 我们进一步评估了每个模型在不同嘴到麦克风距离下的灵敏度。 图8(b) 和图 8(d) 显示了超声的平均 SNR (SNR?) 与增强语音的 SiSNR。 对于两种握持方式,???? 远远超过 10 dB,语音 SiSNR 在 20 cm 距离内保持在 12 dB 左右。 实验表明,只要嘴到麦克风的距离保持在 20 厘米以内,UltraSE 模型的性能就会始终如一。 运动干扰:我们测量来自 3 种主要运动伪影的干扰影响,即呼吸、手势和行走。 在“朝向麦克风”和“打电话”模式下,分别在嘴巴距离麦克风 15 厘米和 2 厘米时进行了实验。(i) 呼吸频率 (~30 bpm) 远小于关节运动 (> 10 Hz),因此它对 UltraSE 的影响可以忽略不计。(ii) 手势引入与关节运动相似的多普勒效应 [36, 40, 51],这可能造成不可忽视的干扰。我们在推动手势干扰下测量关节手势的 SNR?。 SNR? 在 0° 到 90° 的 7 个不同角度每 2 cm 处进行采样,步长为 15°,靠近用户的嘴。 图 13 显示了“朝向麦克风”模式下 SNR? 的空间分布 [82]。 只要手势距离嘴巴 > 25 厘米(这在日常使用场景中很常见),SNR? 就会保持在 10 dB 以上,这对于 UltraSE 来说已经足够了(图 8)。 麦克风阵列可用于聚焦用户的嘴部区域以进一步减轻干扰 [40],但这超出了 UltraSE 的范围。我们省略了“电话通话”模式,因为麦克风离嘴更近,并且感应 SNR? 保持较高。(iii) 当其他人走近(0.8 m 远)时,我们发现 SNR? 几乎没有受到影响,因为超声音量相对较低,并且用户的嘴更近。 总体而言,发音手势的 SNR? 足够高(> 10 dB),并且 UltraSE 模型在日常使用场景中不受运动伪影的影响。 智能手机的概括:不同的智能手机可能有不同的扬声器麦克风布局。 例如,三星 S8、LG G8S ThinQ 和 VIVO X20 的底部麦克风和扬声器之间的距离分别为 5 毫米、25 毫米和 25 毫米。扬声器和麦克风的高频响应也可能因手机型号而异[83]。 将三星 S8 数据集训练的 DNN 模型直接应用到 LG G8S ThinQ 和 VIVO X20 时,增强语音的 SiSNR 分别变为 9.21 dB 和 9.53 dB。低于同款手机壳13.21 dB),但仍高于无超声传感的 SiSNR(7.68 dB)。 为了保持最佳性能,一种直接的方法是为每个电话模型执行一次训练数据收集。 或者,我们可以使用涵盖典型硬件配置的各种智能手机来丰富 UltraSpeech 数据集。 这留给我们以后的工作。 l1evfc20.png图片 真实环境使用实验:我们要求用户在 4 个不同的真实世界环境中使用 UltraSE,即 1) 带有排气扇和流水噪音的浴室环境(平均 75 dBA); 2)有电视噪音的客厅环境(平均55分贝); 3) 有谈话噪音的室内会议环境(平均 60 dBA); 4) 有车辆噪音的室外路边环境(平均 60 dBA)。 与合成嘈杂语音不同,我们无法在这些场景中捕获真实净的语音并评估 SDR、SiSNR、STOI 和 PESQ 等指标。 因此,为了评估 UltraSE 在实际使用中的性能,我们使用 ASR 单词错误率???=(?+?+?)/? 作为指标,其中?、?、?和?是替换、删除的数量 ,插入,目标用户的口语总数。 具体来说,我们要求用户在 TIMIT 语音语料库中跨不同环境说出至少 50 个句子。 图 9 显示了在不同环境中使用和不使用 UltraSE 的WER。 在非语音噪声环境下,即浴室和路边,UltraSE 略微提高了 ASR 语音识别率,因为 ASR 本身具有减轻背景环境噪声干扰的能力。 在语音嘈杂的环境中,即客厅和会议室,WER 高于 100%,因为非目标用户的语音引入了许多词插入和替换。UltraSE 在这种情况下取得了显着的改进,因为它能够通过使用超声波感应将所需的说话者语音与噪声分开。 2.8 文章结论 超声波传感可以作为解决鸡尾酒会问题的补充方式。UltraSE系统引入了通用DNN机制来实现这些功能,例如,多模态多域融合网络和基于新型跨模态连体网络的基于cGAN的训练模型。UltraSE指向了一个新的方向,它融合了无线传感能力,将机器感知提升到一个新的水平。 三、阅读理解与心得 作者提出了UltraSE,它使用超声波传感作为一种补充模式,将所需说话者的声音从干扰和噪声中分离出来。UltraSE使用商用移动设备发射超声波并捕捉说话者发音手势的反射。它引入了一种多模态、多领域的深度学习框架来融合超声多普勒特征和可听语音频谱图。并且利用一个基于跨模态相似性测量网络的经过对抗性训练的鉴别器来学习两种异质特征模式之间的相关性。最后实验验证了UltraSE同时提高了语音清晰度和质量,并且优于当下先进的解决方案。 作者在第一二节分别介绍了该技术的背景与优势,中间章节介绍技术路线,最后就微观基准比较、消融研究、系统效率与泛化采样频率四个方面对实验进行评估得出超声波传感可以作为解决鸡尾酒会问题的补充方式。UltraSE 系统引入了通用 DNN 机制来实现此类功能,融合了无线传感功能,将机器感知提升到一个新的水平。但是在实验分析中不乏存在一个小问题,在系统延时上UltraSE 需要以 5 s 的片段处理输入,这意味着其SSE在5秒的初始引导期后开始生效,如果设备不支持GPU / NPU话,延迟将会很高大于可接受的范围了,基于此这将是进一步研究的对象。 通过本次阅读,使我对电子与通信技术了解了不少,让我懂得专业基本素养及其重要,一方面是专业知识的积累,另一方是英语水平的训练。今后要养成不断阅读文献的习惯,将输入更好的转化为输出,同时在阅读文献方面要做到四知,一、“知事”,了解所读论文的研究内容和研究结果,即英文中的“What had been done? What was the result”。通过阅读摘要(Abstract)或概要(Summary),可以知道研究结果,即知道“What”;而参读全文则可以知道实验方法和策略,即知道“How”。二、“知人”,学会了解研究人员以及他或他们所在研究机构等背景资料。三、“知因”,阅读一篇文章时,有三个问题需要我们思考。一是,为什么研究者能够想到做这个研究。一是,研究者为什么这样设计实验。另一个就是,如果让我们来做,我们会怎样设计我们的研究。四、“知短”,不是所有的研究论文是完美的,许多实验设计可以改进。至于所引出的未解决的问题,更是无穷尽,“真理不是绝对的”。 参考文献 [1] Quan Wang, Hannah Muckenhirn, Kevin Wilson, Prashant Sridhar, Zelin Wu, John Hershey, Rif A Saurous, Ron J Weiss, Ye Jia, and Ignacio Lopez Moreno. Voice filter: Targeted voice separation by speaker-conditioned spectrogram masking. In Proceedings of Interspeech, 2019. [2] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. My lips are concealed: Audio-visual speech enhancement through obstructions. In Proceedings of Interspeech, 2019. [3] John S Garofolo et al. Darpa timit acoustic-phonetic speech database. National Institute of Standards and Technology (NIST), 1988. [4] Aviv Gabbay, Asaph Shamir, and Shmuel Peleg. Visual speech enhancement. In Proceedings of Interspeech, 2018. [5] Dacheng Yin, Chong Luo, Zhiwei Xiong, and Wenjun Zeng. Phasen: A phaseand-harmonics-aware speech enhancement network. In Proceedings of AAAI, 2020. [6] Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. In Proceedings of ACM SIGGRAPH, 2018. [7] Chris Lewis and Steve Pickavance. Implementing quality of service over cisco mpls vpns. Selecting MPLS VPN Services, 2006 [8] Pytorch Mobile, 2020. https://pytorch.org/mobile/home/. [9] Siqi Wang, Anuj Pathania, and Tulika Mitra. Neural network inference on mobile socs. IEEE Design & Test, 2020.
刘航宇
4年前
1
1,072
1
2022-03-30
西北大学843&849备考小经验
目录 843&849历年真题 下载地址:https://wwu.lanzoub.com/i3si90ai9k3g 提取码: 正文 本人22考研已经上岸西北大学电子科学与技术专业 图片 本文不会长篇大论,节省彼此时间,不建议天天看经验贴,有这时间建议做个题跑个步比啥都好。 英语和政治篇 英语和政治篇不多叙述、我相信这个难不倒大家,过线肯定能过,多年国家线分数线尚未超过40,精简回答政治7、8月起每天1-2小时,英语前期单词后期真题,真题建议做到2刷。 数学篇 本人数学这次没发挥好105分,,本人正式备考在7月份开始考研,时间短,那么这么短时间如何提高数学与专业课呢?答案就是不断做题,看视频是次要的本人由于起步晚,直接不看视频就做题,不会就翻书查答案,再不行就看对应知识点,一下节省了好几个月时间。咳咳,不建议大家学我。数学前期建议选任何一本考研书都可,1800不建议因为答案非最简答案,很多同学看不懂原因是这个思路有问题,不是最简思路,并非见到极限我就用泰勒!9月前完成强化,强化方式1.强化卷、2.题目少的习题册(张、汤、李都有)选一个精做,别欺骗自己只求数量、不求质量那是害人!9月-10月先做各机构的模拟题,先不要做真题,模拟题做多少是多少!10月-12月中旬做真题,数一必须后期真题,真题每年有好多以前考过的类型你在二刷时候就能发现22年、21年、20年、19年等等都有很多和19xx年、200x年很类似题目,千万别后期光刷模拟题质量不是一个层次哦!第一个月2天1张卷子第一天做完第二天改错吃透,第二个月1天1份,最后半月二刷1天2份根据程度只刷错题也行一定一定要吃透!历年真题。。我们偶数年吃透考个100+不是问题,奇数年吃透110+不是问题。数学就是题海战术和反复吃透,真题很重要有可能就从1987年起刷2次,真题错题能做到我遇到必会就是一个反反复复克服定势思维的过程。 专业篇 不要迷信押题卷,我们这一届843、849也没几个报班、还有有些微博网上讲题的老师水平,emmm我不评价!? ,我考研期间都 免费 给别人讲了一些题,我相信学弟学妹应该也需要学习那么就挂出来吧,如下所示 集成运放深度理解讲解 专业课如何学? 1.前期(7、8月左右)看上海交大模电视频、认真做笔记,有空课后题 2.数电呢?数电再模电之后学、数电可以看书自学23456章很重要,课后题必做,比如逻辑代数,编码、译码器,寄存器,计数器,加法器这些等等 视频课后题9月中旬前建议完成 3.后期9月中旬后,建议好好研究真题?学长可以免费提供我的个人笔记 4.真题建议做到二刷、吃透,最后1个月看自己笔记和书本和做过的习题即可,基本没有什么大问题的 迷茫指导 结语 西北大学很好,老师也很强,希望各位学弟学妹都能上岸,加油!考研过程最忌讳形式主义、自我感动,合理规划,适合自己是最总要的,我的仅仅是个提示,不要老是看这些,7月前有时间多多锻炼一下身体,西北大学目前843、849在211考研中难度不是很大,既然选择了认真对待肯定没问题!学长希望大家都能上岸,一战成硕! 免费笔记入口 模拟电子技术 数字电子技术
我的随笔
刘航宇
4年前
0
1,180
15
【夜读】“别熬夜了,好吗”
这里是深夜治愈所,我和你的治愈星球 看过有句话说:“别说你一无所长,熬夜玩手机你是一把好手。”诙谐又戳心。 前段时间,有个面向年轻人的睡眠调查,结果显示,只有10.3%的人能在23点前入睡,超过80%的人会熬到凌晨才入睡。 不知道正在看文章的你,是不是也有熬夜的习惯呢? 当然会有人说,自己熬夜是因为工作加班。 也确实看到过有数据显示:近90%的职场人都难以逃脱加班的命运。 甚至其中有四分之一的人,加班的频率是每天。 我们都知道,熬夜有害健康,但很少有人能做到不熬夜。 越来越多的年轻人白天开始保温杯泡枸杞,各种养生,花很多钱买面膜和护肤品,却因为熬夜,把前面的所有努力一键归零。 今天就要来和你说说,怎样克服熬夜的习惯。 网络上有个问题是:“坚持每天早睡,你发生了什么变化?” 有个网友的回答获得了很多点赞,他说:“我发现早睡后必然早起,然后生活里没有游戏、没有夜宵。 黑眼圈少了,时间多了,不会迟到了,每天都有时间好好吃早餐。” 图片 一年前,我在准备一个资格考试的时候,就尝到过早睡甜头。 当时,因为每天白天都有满满当当的工作,所以晚上下班回家已经非常疲惫,一看书就会想打瞌睡,勉强能挤得出时间学习,但精力却跟不上。 一开始挺发愁的,很担心自己的状态通过不了考试。 有一天晚上,实在太累了,就像要不先睡,明天早两个小时起来学习好了。 结果第二天起来竟然精神异常充沛,而且一大早特别安静,学习效率异常的高。 就这样我每天早睡早起,学习的时候状态都很好,没请假,不耽误工作的情况下也通过了考试。 最近有个话题#睡前玩手机8分钟 兴奋超1小时#就冲上过热搜。 有医学专家研究发现,眼睛只要受到手机等屏幕发出的蓝光刺激8分钟,就会导致身体持续兴奋超过1小时,造成生物钟紊乱。 睡觉前过度使用手机,不但损伤视力,还会使人入睡困难。 特别是睡觉前还在追剧、刷短视频或者打游戏的,越玩越停不下来,然后越难入睡,最后变成了恶性循环。 图片 年初很火的电视剧《人世间》里周蓉的扮演者宋佳,就曾在一次节目中透露,自己保持良好的身体和工作状态,都得益于好的睡眠习惯。 她睡觉时从不把手机带进卧室,睡前不看手机、不玩游戏、不看资讯,正是因为这些好习惯保证了好的睡眠质量。 所以有人说: 不透支睡眠,科学制定属于自己的起床和睡觉时间,好好睡觉,是善待自己的开始,也是热爱生活的体现。 最后,给大家推荐几个戒掉熬夜的小妙招: 1.睡前少玩手机和电脑、平板等电子设备,避免蓝光刺激大脑兴奋而难以入眠。 2.睡前洗个热水澡或者泡个脚,能使人心态放松。喝杯热牛奶也是不错的选择,牛奶中含有的色氨酸可以让人产生疲倦欲睡感。但别通过酒精催眠,酒精伤肝,而且代谢很容易让人在后半夜醒来,影响睡眠质量。 3.养成良好作息,形成生物钟,到点了就有困意,该起床时就别赖床。 4.白天提高工作效率,别把太多工作留到晚上。晚上工作反而容易让大脑更兴奋,特别是熬夜工作,越熬越兴奋,后来想睡都睡不着。所以如果能提早规划,尽量白天就科学高效地把工作完成。 图片 5.晚餐前适量运动,或者晚餐后散散步,可以让身体保持微疲劳状态,让人容易产生困意。当然避免睡前大量运动。 6.除了该睡觉时,不要长时间待在床上,也尽量不要在床上做其它事情,比如躺床上看电视、听音乐、看书等。 这样可以建立身体和床之间的条件反射,即身体沾到床就出现困意,需要我们把床当成唯一睡觉的地方。 当然,很多听众跟我说,睡前收听我们的《深夜治愈所》节目,也可以催眠哦。睡不着的夜晚欢迎来找我。 从今晚开始,早点睡觉,别熬夜了,好吗。
励志美文
刘航宇
4年前
0
548
6
2022-03-13
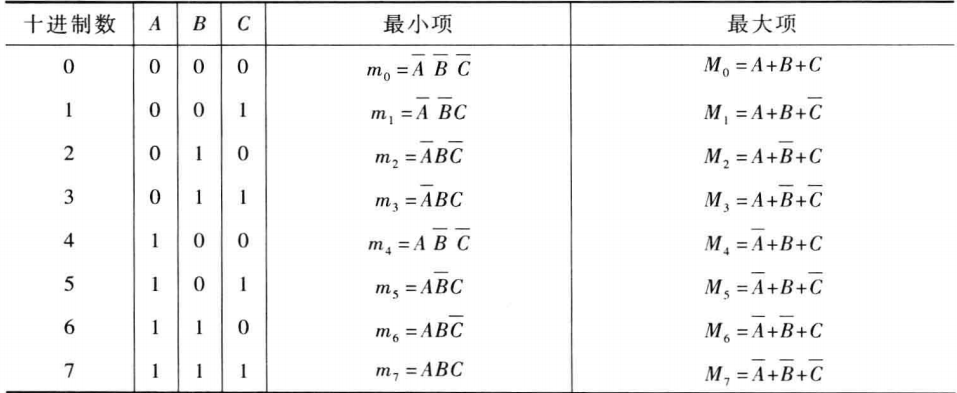
数字电路基础-最大项与最小项
目录 1.定义 2.性质 3.关系 1.定义 最小项:n个变量的逻辑乘,即与形式,每个变量以原变量或者反变量的形式出现一次。n个变量共有2n个最小项。用m表示,如ABC,表示为m0。 最大项:n个变量的逻辑和,即或形式,每个变量以原变量或者反变量的形式出现一次。n个变量共有2n个最大项。用M表示,如A+B+C,表示为M0。 如下为三变量最小项和最大项的表示方法: 图片 2.性质 对于n个变量来说,若给定这些变量确定的值,那么2n个最小项中仅有一组值为1,其余全为0;2n个最大项中仅有一组值为0,其余全为1. 全部最小项之和恒等于1;全部最大项之积恒等于0。(可由第一条性质中看出) 任意两个最小项之积等于0;任意两个最大项之和等于1。(可由第一条性质中看出) 若干个最小项的和等于其余最小项和的反。简单可以记做为卡诺图上分成两部分,他们之间为反关系。 3.关系 最小项的反是最大项,最大项的反是最小项。 图片
嵌入式&系统
刘航宇
4年前
0
1,940
6
【美文】平常烟火,珍惜一段春色
习惯了,一个人早晨的时候去呼吸新鲜的空气,公园散步,与早起的人们一起,沿着一湾清水,走在幽静的小路上,鸟鸣啾啾,春意缓归,也是惬意。 散步回来,一杯牛奶,几片面包,也就打发了自己。 隔着窗,萧瑟凋零的草木重新焕发生机,醒来时,已是春光乍泄。 光阴似箭,走过曾经的时光,拥抱春天,当最后一片雪花飘落,风霜雨雪便是人生的足迹,一步一步走向美好。 春已至,站在春天里,遥看春色渐暖,浅淡颜色,渐渐有了模样,物候秩序,水墨丹青细细描摹。 枝头的蓓蕾藏,期待着花期,用自己的方式,各自准备着给春天的厚礼。 图片 苏醒的枝蔓,缓缓伸展着腰肢,春意盎然,只是时间问题,那些醉人的风景和迷人的姿态,慢慢的,都会一一到达。 时光不老,却是又重返青春,跟着流云,掠过一帧一帧的花影,在疏影横斜的背景里,日子可以走的亦是轻松,沿着季节的方向,明媚着未来的路途。 凝眸春风过处,款款春意盎然恣意,似淡墨染成的画卷。许多时候,一点灵犀,便是曼妙,在蕾枝之间彼此守护。 就如某种默契,无需言说即可心领神会。就如岁月的枝头,只要春风一来,无论静默多久,都会开出鲜艳的花瓣,释放出一分欢喜和几分明媚。 那画卷里,风景旖旎,千丝万缕细枝,沿途摇暖了一季风景,眸中清寒,也是时光里的潋滟,春来时,轻轻翻开一个个冬天埋下的伏笔,瞬间花苞炸裂,芳菲开遍。 图片 平淡的事情,用心感悟才有了意味深长,万千风景,用心了才是清欢有味。 在最美的时光里,安静知足,对任何喜欢的人或事都学会有所期待,耐心等待,无需刻意,只是顺其自然,只怕不经意间就失去平淡的光泽。 在春天的希望里,看似水流年,看绿肥红瘦,淡然之间,让生命有了柔和的温度。 春在路上,花在枝上,所有的美好都在心上,努力过好自己的日子,冷暖之间,各自安好。 心怀美好,用一份付出与努力,善待自己,接纳生活,摈弃杂念,别让鸡零狗碎的事情,耗尽你对美好生活的向往。 守住生命与自然的本色,自然而然,以淡泊宁静的心态去面对现实,无需仰视枝头的花朵,生活还需简单明了,只是珍爱,与这尘世和睦相处,再多一份心头的默契,如此,甚好。 图片 不念过往,不惧将来,我们无须铭记或者忘记,每一段岁月都是值得拥有的,你曾经拥有过的,都是最好的时光。 活在当下,你看,春风春雨春烟,让山河有了温柔的气息,一花一草一木都是春天的美丽。 平淡日子,让自己安静下来,用最美心情接受春天得到来,缘之所寄,是淡淡时光;一往而深,深情之处,平淡生活也是春天。
励志美文
刘航宇
4年前
1
878
5
上一页
1
...
11
12
13
...
26
下一页