首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,162 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,125 阅读
3
【高数】形心计算公式讲解大全
8,748 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,444 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,805 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
刘航宇(共304篇)
找到
304
篇与
刘航宇
相关的结果
- 第 2 页
泛化能力,过拟合,欠拟合,不收敛,奥卡姆剃刀
泛化能力 欠拟合过拟合与不收敛 解决手段一、模型训练拟合的分类和表现 二、欠拟合 三、过拟合 总结: 泛化能力 泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力,简而言之是在原有的数据集上添加新的数据集,通过训练输出一个合理的结果。学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。 欠拟合过拟合与不收敛 用比较直白的话来讲,就是通过数据训练学习的模型,拿到真实场景去试,这个模型到底行不行,如果达到了一定的要求和标准,它就是行,说明泛化能力好,如果表现很差,说明泛化能力就差。为了更好的理解泛化能力,这里引入三种现象,欠拟合、过拟合以及不收敛。 欠拟合(under-fitting),是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。即,在训练数据集上表现差,在测试集数据也表现差。 过拟合(over-fitting),是指模型在训练集上表现很好,在测试集上效果差。 不收敛(non-convergence),指误差函数一直在振荡,不能趋近一个定值,没有找到局部或者全局最小值。 举个例子来说明下,好比高考数学考试,为了在高考能有个好成绩,高一到高三,好多人会采用“题海战术”来训练自己的做题能力,但高考试卷上的题,都是新题,几乎没有一模一样的题,学生们为了掌握解题规律就不停的刷题,希望最后自己碰到类似的题,能够举一反三,能学以致用,这种规律掌握的适用性,就是泛化能力。 有的人对相似题型的解题规律掌握的很好,并且解题效果也很好,这种就是泛化能力强,这种同学往往数学成绩就好。 有的同学成绩不好,就是泛化能力差,可能有三种情况 1.做了不少题,但没有找到解题规律,不管碰到老题和新题都不会做,这种就是欠拟合。 2.做了很多题,自认为做过的每一类题型的解题规律都掌握了,而且在之前“题海战术”的题目中,确实表现的很好,但是一碰到新的题目,完全就不会,或者做错,这种学生就是那种喜欢死记硬背的,这种就是过拟合。 3.平常也不做题,然后每次一做题就瞎蒙,导致偶尔对,偶尔错,这种就是不收敛。 为了更直观展示,引用了几张图来说明,如下图所示,真实曲线是正弦曲线,蓝色的点是训练数据,红色的线为拟合曲线。 图片 图片 解决手段 在深度学习的模型建立过程中,一般都是用已经产生的数据训练,然后使用训练得到的模型去拟合未来的数据,借此来预测一些东西。在机器学习和深度学习的训练过程中,经常会出现欠拟合和过拟合的现象。训练一开始,模型通常会欠拟合,所以会对模型进行优化,等训练到一定程度后,就需要解决过拟合的问题了。 一、模型训练拟合的分类和表现 如何判断过拟合呢?我们在训练的时候会定义训练误差,验证集误差,测试集误差(即泛化误差)。训练误差总是减少的,而泛化误差一开始会减少,到了一定程度后不减少反而开始增加,这时候便出现了过拟合的现象。 如下图,直观理解,欠拟合就是还没有学习到数据的特征,还有待继续学习,所以此时判断的不准确;而过拟合则是学习的太彻底,以至于把数据的一些不需要的局部特征或者噪声所带来的特征都给学习到了,所以在测试的时候泛化误差也不佳。 图片 从方差和偏差的角度来说,欠拟合就是在训练集上高方差,高偏差,过拟合就是高方差,低偏差。为了更加直观,我们看下面的图 图片 对比上图,图一的拟合并没有把大体的规律给拟合出来,拟合效果不好,这个就是欠拟合,还需要继续学习规律,此时模型简单;图三的拟合过于复杂,拟合的过于细致,以至于拟合了一些没有必要的东西,这样在训练集上效果很好,但放到测试集和验证集就会不好。图二是最好的,把数据的规律拟合出来了,也没有更复杂,更换数据集后也不会效果很差。 在上面的拟合函数中,可以想到,图三过拟合的拟合函数肯定是一个高次函数,其参数个数肯定比图二多,可以说图三的拟合函数比图二要大,模型更加复杂。这也是过拟合的一个判断经验,模型是否过于复杂。另外针对图三,我们把一些高次变量对应的参数值变小,也就相当于把模型变简单了。从这个角度上讲,可以减少参数值,也就是一般模型过拟合,参数值整体比较大。从模型复杂性上讲,可以是: ——模型的参数个数; ——模型的参数值的大小。 个数越多,参数值越大,模型越复杂。 二、欠拟合 欠拟合的表现 有什么方法来判断模型是否欠拟合呢?其实一般都是依靠模型在训练集和验证集上的表现,有一个大概的判断就行了。如果要有一个具体的方法,可以参考机器学中,学习曲线来判断模型是否过拟合,如下图: 图片 欠拟合的解决方案 (1)增加数据特征:欠拟合是由于学习不足导致的,可以考虑添加特征,从数据中挖掘更多的特征,有时候嗨需要对特征进行变换,使用组合特征和高次特征; (2)使用更高级的模型:模型简单也会导致欠拟合,即模型参数过少,结构过于简单,例如线性模型只能拟合一次函数的数据。尝试使用更高级的模型有助于解决欠拟合,增加神经网络的层数,增加参数个数,或者使用更高级的方法; (3)减少正则化参数:正则化参数是用来防止过拟合的,出现欠拟合的情况就要考虑减少正则化参数。 三、过拟合 过拟合的定义 模型在训练集上表现好,但在测试集和验证集上表现很差,这就是过拟合 图片 过拟合的原因 (1)数据量太小 这是很容易产生过拟合的原因。设想我们有一组数据很好的满足了三次函数的规律,但我们只取了一小部分数据进行训练,那么得到的模型很可能是一个线性函数,把这个线性函数用于测试集上,可想而知肯定效果很差。(此时训练集上效果好,测试集效果差) (2)训练集和验证集分布不一致 这也是很大一个原因。训练集上训练出来的模型适合训练集,当把模型应用到一个不一样分布的数据集上,效果肯定大打折扣,这个是显而易见的。 (3)网络模型过于复杂 选择模型算法时,选择了一个复杂度很高的模型,然而数据的规律是很简单的,复杂的模型反而不适用了。 (4)数据质量很差 数据有很多噪声,模型在学习的时候,肯定也会把噪声规律学习到,从而减少了一般性的规律。这个时候模型预测效果也不好。 (5)过度训练 这是同第四个相联系的,只要模型训练时间足够长,那么模型肯定会把一些噪声隐含的规律学习到,这时候降低模型的性能也是显而易见的。 解决方法 (1)降低模型复杂度 处理过拟合的第一步就是降低模型复杂度。为了降低复杂度,我们可以简单地移除层或者减少神经元的数量使得网络规模变小。与此同时,计算神经网络中不同层的输入和输出维度也十分重要。虽然移除层的数量或神经网络的规模并无通用的规定,但如果你的神经网络发生了过拟合,就尝试缩小它的规模。 (2)数据集扩增 在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。 通俗的讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法: ——从数据源头采集更多数据 ——复制原有数据加上噪声 ——重采样 ——根据当前数据集估计数据分布参数,利用该分布产生更多数据(3)数据增强 使用数据增强可以生成多幅相似图像。这可以帮助我们增加数据集从而减少过拟合。因为随着数据量的增加,模型无法过拟合所有样本,因此不得不进行泛化。计算机视觉领域通常的做法有:翻转,平移,旋转,缩放,改变亮度,添加噪声等。 (4)正则化 正则化是指在进行目标函数或者代价函数优化时,在目标函数或者代价函数后面加上一个正则项,一般有L1正则和L2正则等。 L1惩罚项的目的是使权重绝对值最小化,公式如下: 图片 L1惩罚项的目的是使权重的平方最小化,公式如下: 图片 下面对两种正则化方法进行了比较: 图片 如果数据过于复杂以致没有办法进行准确的建模,那么L2是更好的选择,因为它能够学习数据中呈现的内在模式。而当数据足够简单,可以精确建模的话,L1更合适,对于我遇到的大多数计算机视觉问题,L2正则化几乎总是可以给出最好的结果。然而L1不容易受到离群值的影响。所以正确的正则化选项取决于我们想要解决的问题。 总结: 正则项是为了降低模型的复杂度,从而避免模型过分拟合训练数据,包括噪声与异常点。从另一个角度讲,正则化即是假设模型参数服从先验概率,即为模型参数添加先验,只是不同的正则化方式的先验分布是不一样的。这样就规定了参数的分布,使得模型的复杂度降低(试想一下,限定条件多了,是不是模型的复杂度就降低了呢),这样模型对于噪声和异常点的抗干扰性的能力增强,从而提高模型的泛化能力。还有个解释,从贝叶斯学派来看,加了先验,在数据少的时候,先验知识可以防止过拟合;从频率学派来看,正则项限定了参数的取值,从而提高了模型的稳定性,而稳定性强的模型不会过拟合,即控制模型空间。 另外一个角度,过拟合从直观上理解便是,在对训练数据进行拟合时,需要照顾到每个点,从而使得拟合函数波动性非常大,即方差大。在某些小区间里,函数值的变化很剧烈,意味着函数在某些小区间的导数值的绝对值非常大,由于自变量的值在给定的训练数据集中是一定的,因为只有系数足够大,才能保证导数的绝对值足够大,如下图: 图片 另一个解释,规则化项的引入,在训练(最小化cost)的过程中,当某一维的特征所对应的权重过大时,而此时模型的预测和真实数据之间的距离很小,通过规则化项就可以使整体的cost取较大的值,从而,在训练的过程中避免了去选择了那些某一维(或几维)特征权重过大的情况,即过分依赖某一维(或几维)的特征。 L1和L2的区别是,L1正则是拉普拉斯先验,L2正则则是高斯先验。它们都是服从均值为0,协方差为1/λ。当λ=0,即没有先验,没有正则项,则相当于先验分布具有无穷大的协方差,那么这个先验约束则会非常弱,模型为了拟合拟合所有的训练集数据,参数可以变得任意大从而使得模型不稳定,即方差大而偏差小。λ越大,表明先验分布协方差越小,偏差越大,模型越稳定。即,加入正则项是在偏差bias与方差variance之间做平衡tradeoff。下图即为L2与L1正则的区别: 图片 上图中的模型是线性回归,有两个特征,要优化的参数分别是w1和w2,左图的正则化是L2,右图是L1。蓝色线就是优化过程中遇到的等高线,一圈代表一个目标函数值,圆心就是样本观测值(假设一个样本),半径就是误差值,受限条件就是红色边界(就是正则化那部分),二者相交处,才是最优参数。可见右边的最优参数只可能在坐标轴上,所以就会出现0权重参数,使得模型稀疏。 其实拉普拉斯分布和高斯分布是数学家从试验中误差服从什么分布研究得出的。一般直观上的认识是服从均值为0的对称分布,并且误差大的概率低,误差小的概率高,因为拉普拉斯使用拉普拉斯分布对误差的分布进行拟合,如下图: 图片 而拉普拉斯在最高点,即自变量为0处不可导,因为不便于计算,于是高斯在这基础上使用高斯分布对其进行拟合,如下图: 图片 (5)dropout 正则时通过再代价函数后面加上正则项来防止过拟合的。而在神经网络中,有一种方法时通过修改神经网络本身结构实现的,其名为dropout。该方法是对网络进行训练时用的一种技巧,对于如下的三层人工神经网络: 图片 对于上图所示的网络,在训练开始时,随即删除一些(可自己设定概率)隐藏层神经元,即认为这些神经元不存在,同时保持输入层和输出层的个数不变,这样便得到如下的ANN: 图片 然后按照BP学习算法对ANN中的参数进行学习更新(虚线链接的单元不更新,因为认为这些连接元被临时删除了)。这样一次迭代更新便完成了,下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择,这样一直进行,直至训练结束。 这种技术被证明可以减少很多问题的过拟合,这些问题包括图像分类,图像切割,词嵌入,语义匹配等问题。 (6)早停 对模型的训练即是对模型的参数进行更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。 Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算验证集的正确率,当正确率不再提高时,就停止训练。这种做法很符合直观感受,因为正确率都不在提高了,再继续训练也是无益的,只会提高训练的时间。如下图,在几次迭代后,即使训练误差仍然在减少,但测验误差已经开始增加了。 图片 那么该做法的一个重点便是怎样才认为验证准确率validation accurary不再提高了呢?并不是说验证准确率validation accurary一降下来便认为不再提高了,因为可能经过这个Epoch后,正确率降低了,但是随后的Epoch又让正确率又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的验证准确率validation accurary,当连续10次没达到最佳正确率时,认为不再提高了,此时便可以停止迭代。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30…… (7)重新清洗数据 把明显异常的数据剔除。 (8)使用集成学习方法 把多个模型集成在一起,降低单个模型的过拟合风险。
机器学习
# 机器学习
刘航宇
2年前
0
1,142
1
2024-01-11
嵌入式常见知识点
图片 1、线程、进程的区别?最小执行单元是进程还是线程? 2、如何计算一个整数是不是2的n次方? 3、printf的具体实现? 4、什么是大小端?如何区分?有几种方法? 5、new与malloc的区别? 6、程序链接完毕之后分几部分? 7、Linux、Windows与FreeRtos的区别? 8、Linux系统中的中断为什么分为上下两个部分? 9、会快速排序吗?简要说一下? 10、static关键字的作用? 11、extern 关键字的作用? 12、volatile关键字的作用? 13、编译原理分哪几步? 14、内存分区? 15、freertos启动流程? 16、互斥锁与信号量的区别? 17、什么是死锁?死锁产生的原因?如何避免? 18、什么是内存泄漏? 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 21、freertos中EventBits_t是干啥的? 22、freertos使任务切换的方式有哪些? 23、项目中用到网络了吗? 24、了解Socket吗? 25、c++中set是什么? 26、有没有用到C++模板? 27、有没有对代码裁剪的经验 28、freertos系统是买模块时人家配置好的?还是移植的? 29、任务里有两把锁的时候该怎么处理 30、熟悉Shell脚本吗?$和#啥意思? 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。31、知道#error吗? 32、freertos消息队列的的具体实现? 33、堆栈区别? 34、程序存放状态和区别 1、线程、进程的区别?最小执行单元是进程还是线程? 线程和进程都是程序的执行实体,但是它们有以下区别: 进程是操作系统分配资源的基本单位,每个进程都有自己的独立的地址空间,代码段,数据段,堆栈段等。进程之间的切换需要保存和恢复上下文,开销较大。 线程是操作系统调度的基本单位,每个线程都属于某个进程,一个进程可以有多个线程,它们共享进程的地址空间,但是有自己的栈和寄存器。线程之间的切换只需要保存和恢复少量的寄存器,开销较小。 最小的执行单元是线程,因为一个进程至少要有一个线程,而一个线程可以独立运行。 2、如何计算一个整数是不是2的n次方? 一个整数是2的n次方,当且仅当它的二进制表示中只有一个1,其余都是0。例如,23=8=(1000)2 ,只有一个1。所以,我们可以用以下的方法来判断一个整数x是否是2的n次方: 如果x小于等于0,那么它不是2的n次方。 如果x大于0,那么我们可以用位运算的技巧,将x与x-1做按位与,如果结果为0,那么x是2的n次方,否则不是。例如,8&(8−1)=8&7=(1000)2&(0111)2=(0000)2=0 ,所以8是2的n次方。而9&(9−1)=9&8=(1001)2&(1000)2=(1000)2=0 ,所以9不是2的n次方。 3、printf的具体实现? printf是C语言中的一个标准库函数,用于向标准输出流(通常是屏幕)打印格式化的字符串。它的具体实现可能因编译器和操作系统的不同而有所差异,但是一般来说,它的主要步骤如下: 首先,printf会解析第一个参数,也就是格式化字符串,根据其中的转换说明符(如%d, %f, %s等),确定需要打印的数据类型和格式。 然后,printf会从第二个参数开始,依次获取对应的数据,并将其转换为字符串,拼接到格式化字符串的相应位置。如果参数的个数和类型与格式化字符串不匹配,可能会导致错误或未定义的行为。 最后,printf会调用底层的系统函数,将拼接好的字符串写入到标准输出流中,并返回成功写入的字符数。如果发生错误,返回负值。 4、什么是大小端?如何区分?有几种方法? 大小端是指数据在内存中的存储顺序,大端表示高位字节存放在低地址,低位字节存放在高地址,小端表示高位字节存放在高地址,低位字节存放在低地址。例如,一个32位的整数0x12345678,在大端模式下,存储为0x12 0x34 0x56 0x78,而在小端模式下,存储为0x78 0x56 0x34 0x12。 区分大小端的方法有以下几种: 通过联合体(union)的方式,将一个整数和一个字符数组放在同一个联合体中,然后判断字符数组的第一个元素是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过指针的方式,将一个整数的地址赋给一个字符指针,然后判断指针指向的内容是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过位运算的方式,将一个整数右移24位,然后与0xFF做按位与,得到的结果是不是整数的最高字节,如果是,说明是大端,否则是小端。 5、new与malloc的区别? new和malloc都是用于动态分配内存的,但是它们有以下区别: new是C++中的运算符,malloc是C语言中的函数,它们的用法不同。new可以直接分配对象,而malloc只能分配字节,需要强制类型转换。 new会调用对象的构造函数,初始化对象,而malloc只是分配原始的内存空间,不做任何初始化。 new会根据对象的类型,自动计算所需的内存大小,而malloc需要手动指定分配的字节数。 new分配失败时,会抛出异常,而malloc分配失败时,会返回NULL指针。 new对应的释放内存的运算符是delete,而malloc对应的释放内存的函数是free。 6、程序链接完毕之后分几部分? 程序链接完毕之后,一般分为以下几个部分: 代码段(text segment),存放程序的指令和常量。 数据段(data segment),存放程序的全局变量和静态变量。 堆(heap),存放程序动态分配的内存空间。 栈(stack),存放程序的局部变量,函数参数,返回地址等。 BSS段(bss segment),存放程序未初始化的全局变量和静态变量。 7、Linux、Windows与FreeRtos的区别? Linux、Windows和FreeRtos都是操作系统,但是它们有以下区别: Linux是一个开源的,基于Unix的,多用户,多任务,支持多种硬件平台的操作系统,它有很多不同的发行版,如Ubuntu,RedHat,Debian等。Linux适合用于服务器,嵌入式系统,桌面系统等。 Windows是一个闭源的,基于NT内核的,多用户,多任务,主要支持x86和x64架构的操作系统,它有很多不同的版本,如Windows 10,Windows Server,Windows CE等。Windows适合用于桌面系统,移动设备,游戏机等。 FreeRtos是一个开源的,基于微内核的,实时,多任务,支持多种嵌入式平台的操作系统,它有很多不同的移植,如ARM,MIPS,AVR等。FreeRtos适合用于实时控制,物联网,低功耗设备等。 8、Linux系统中的中断为什么分为上下两个部分? Linux系统中的中断为了提高效率和响应时间,分为上半部(top half)和下半部(bottom half)。上半部是指中断处理程序(interrupt handler),它负责处理中断的紧急事务,如保存寄存器,清除中断标志,识别中断源等。下半部是指中断延迟服务程序(interrupt deferred service routine),它负责处理中断的非紧急事务,如数据传输,设备驱动,信号发送等。上半部和下半部的区别如下: 上半部在中断上下文中执行,下半部在进程上下文中执行。 上半部不能被其他中断打断,下半部可以被其他中断打断。 上半部不能睡眠,下半部可以睡眠。 上半部不能调用可能导致阻塞的函数,如malloc,copy_to_user等,下半部可以调用这些函数。 上半部的执行时间应该尽可能短,下半部的执行时间可以较长。 9、会快速排序吗?简要说一下? 快速排序是一种基于分治思想的排序算法,它的基本步骤如下: 从待排序的数组中选择一个元素作为基准(pivot),通常选择第一个或者最后一个元素。 将数组分成两个子数组,一个子数组中的元素都小于或等于基准,另一个子数组中的元素都大于基准,这个过程称为划分(partition)。 对两个子数组递归地进行快速排序,直到子数组的长度为1或0。 将排好序的子数组合并,得到最终的排序结果。 快速排序的平均时间复杂度是O(nlogn) ,最坏情况是O(n^2) ,空间复杂度是O(logn) ,它是一种不稳定的排序算法。 10、static关键字的作用? static是一个修饰符,它可以用于变量和函数,它有以下作用: 用于全局变量,表示该变量只能在本文件中访问,不能被其他文件引用,这样可以避免命名冲突。 用于局部变量,表示该变量的生命周期是整个程序,而不是函数调用结束,这样可以保持变量的值不被销毁。 用于函数,表示该函数只能在本文件中调用,不能被其他文件引用,这样可以提高函数的封装性和安全性。 11、extern 关键字的作用? extern是一个修饰符,它可以用于变量和函数,它有以下作用: 用于变量,表示该变量是在其他文件中定义的,需要在本文件中引用,这样可以避免重复定义。 用于函数,表示该函数是在其他文件中定义的,需要在本文件中声明,这样可以避免隐式声明。 12、volatile关键字的作用? volatile是一个修饰符,它可以用于变量,它有以下作用: 用于变量,表示该变量可能会被外部因素(如中断,多线程,硬件等)改变,需要每次都从内存中读取,而不是从寄存器或缓存中读取,这样可以保证变量的实时性和一致性。 用于变量,表示该变量不会被编译器优化,需要按照程序的顺序执行,而不是进行重排或删除,这样可以避免编译器的干扰。 13、编译原理分哪几步? 编译原理是指将一种高级语言(源语言)的程序转换为另一种低级语言(目标语言)的程序的原理和方法,它一般分为以下几个步骤: 词法分析(lexical analysis),将源程序的字符序列分割成有意义的单词(token)。 语法分析(syntax analysis),将单词序列组织成语法树(parse tree)或抽象语法树(abstract syntax tree),表示程序的结构和语义。 语义分析(semantic analysis),检查程序是否符合语言的语法规则和语义规则,如类型检查,作用域分析等。 中间代码生成(intermediate code generation),将抽象语法树转换为一种中间表示(intermediate representation),如三地址码,四元式,后缀表达式等,便于优化和目标代码生成。 代码优化(code optimization),对中间表示进行一些变换,以提高程序的执行效率,如常量折叠,公共子表达式消除,循环优化,死代码删除等。 目标代码生成(target code generation),将中间表示转换为目标语言的代码,如汇编语言,机器语言等,同时进行一些分配,如寄存器分配,指令选择等。 14、内存分区? 内存分区是指将物理内存划分为若干个逻辑区域,以便于管理和使用。内存分区的方式有以下几种: 固定分区,将内存分为大小相等或不等的若干个区域,每个区域只能装入一个进程,如果进程的大小超过区域的大小,就会产生内部碎片。 动态分区,根据进程的大小和数量,动态地分配和回收内存空间,每个区域可以装入一个或多个进程,如果进程的大小不是区域的整数倍,就会产生外部碎片。 页式分区,将进程的地址空间划分为大小相等的若干个页,将物理内存划分为大小相等的若干个页框,然后将页映射到页框,实现非连续的内存分配,避免了外部碎片,但是可能产生内部碎片。 段式分区,将进程的地址空间划分为大小不等的若干个段,每个段有自己的逻辑地址和属性,然后将段映射到物理内存,实现非连续的内存分配,避免了内部碎片,但是可能产生外部碎片。 段页式分区,将进程的地址空间划分为若干个段,每个段再划分为若干个页,然后将页映射到物理内存的页框,实现非连续的内存分配,避免了内部碎片和外部碎片,但是增加了地址转换的复杂度。 15、freertos启动流程? freertos是一个实时操作系统,它的启动流程一般如下: 首先,执行硬件初始化,如设置时钟,中断,堆栈等。 然后,执行软件初始化,如创建任务,队列,信号量,定时器等。 接着,调用vTaskStartScheduler ()函数,启动调度器,选择优先级最高的就绪任务运行。 最后,当发生中断,延时,阻塞等事件时,调度器会根据算法,如优先级抢占式,时间片轮转式等,切换任务,实现多任务的并发执行。 16、互斥锁与信号量的区别? 互斥锁(mutex)和信号量(semaphore)都是用于实现多任务的同步和互斥的机制,但是它们有以下区别: 互斥锁是一个二元的同步对象,它只有两种状态:锁定和解锁。一个互斥锁只能被一个任务拥有,当一个任务获取互斥锁后,其他任务就不能再获取该互斥锁,直到拥有者释放它。互斥锁通常用于保护临界区的访问,避免数据的不一致。 信号量是一个计数的同步对象,它有一个初始值,表示可用的资源数量。一个信号量可以被多个任务共享,当一个任务获取信号量后,信号量的值减一,表示资源被占用。当信号量的值为零时,表示没有可用的资源,其他任务就要等待,直到有任务释放信号量,信号量的值加一,表示资源被释放。信号量通常用于实现生产者-消费者模型,控制资源的分配和回收。 17、什么是死锁?死锁产生的原因?如何避免? 死锁是指多个任务因为争夺有限的资源而相互等待,导致无法继续执行的现象。死锁产生的原因一般有以下四个必要条件: 互斥条件,指每个资源只能被一个任务拥有,其他任务不能访问。 占有且等待条件,指一个任务已经占有了至少一个资源,但是又申请了其他已经被占有的资源,同时不释放自己已经占有的资源。 不可抢占条件,指一个任务占有的资源不能被其他任务强行剥夺,只能由占有者主动释放。 循环等待条件,指多个任务形成一个环路,每个任务都在等待下一个任务占有的资源。 避免死锁的方法有以下几种: 破坏互斥条件,使用非互斥的资源,如可复制的资源,或者使用软件技术,如事务,来实现对资源的虚拟访问。 破坏占有且等待条件,要求一个任务在申请资源时,必须一次性申请所有需要的资源,或者在申请新的资源时,必须先释放已经占有的资源。 破坏不可抢占条件,允许一个任务在占有资源时,被其他任务抢占,或者主动释放资源,以满足其他任务的需求。 破坏循环等待条件,给每个资源分配一个优先级,要求一个任务只能申请优先级高于或等于自己已经占有的资源的资源,或者按照一定的顺序申请资源,避免形成环路。 18、什么是内存泄漏? 内存泄漏是指程序在运行过程中,动态分配了一些内存空间,但是没有及时释放,导致这些内存空间无法被其他程序使用,造成内存的浪费和紧张。内存泄漏可能会导致程序的性能下降,甚至崩溃。 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 系统死机是指系统无法响应用户的输入,或者出现异常的错误,导致系统无法正常运行。排查系统死机的原因有以下几种方法: 通过日志文件,查看系统在死机前的运行状态,是否有异常的信息,如错误码,警告,断言等,以及死机的时间,位置,频率等,从而定位可能的问题源。 通过调试工具,如gdb,lldb等,对系统进行调试,查看系统的内存,寄存器,堆栈,断点等,分析系统的运行流程,发现潜在的错误,如内存泄漏,空指针,死锁等。 通过测试工具,如valgrind,asan等,对系统进行测试,检测系统的内存管理,性能,覆盖率等,发现系统的缺陷,如内存错误,资源泄漏,性能瓶颈等。 通过代码审查,对系统的代码进行分析,检查代码的风格,规范,逻辑,注释等,发现代码的不合理,不一致,不完善等,提高代码的质量,可读性,可维护性等。 通过重现问题,对系统的死机现象进行复现,观察系统的表现,输入,输出等,找出问题的触发条件,规律,范围等,缩小问题的范围,提高问题的可解决性。 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 同一类型的结构体定义两个变量,不能用内存大小来比较判断两者一样,因为内存大小只能反映结构体的占用空间,而不能反映结构体的内容。例如,以下两个结构体变量的内存大小都是8字节,但是它们的内容是不一样的: struct Point { int x; int y; }; struct Point p1 = {1, 2}; struct Point p2 = {3, 4}; 如果要比较两个结构体变量是否一样,需要逐个比较它们的成员,或者使用memcmp函数比较它们的内存内容。例如: // 逐个比较 if (p1.x == p2.x && p1.y == p2.y) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); } // 使用memcmp比较 if (memcmp(&p1, &p2, sizeof(struct Point)) == 0) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); }21、freertos中EventBits_t是干啥的? EventBits_t是一个数据类型,它用于表示事件标志组(event group)中的每个位的状态,每个位可以表示一个事件的发生或者一个条件的满足。EventBits_t通常是一个无符号整数,它可以使用位运算来设置,清除,读取或等待事件标志。 22、freertos使任务切换的方式有哪些? freertos使任务切换的方式有以下几种: 时间片轮转法,按照任务的优先级和时间片的长度,依次轮流执行每个就绪任务,当一个任务的时间片用完或者主动放弃时,切换到下一个任务。 优先级抢占法,按照任务的优先级,总是执行优先级最高的就绪任务,当有更高优先级的任务就绪时,立即抢占当前任务,切换到更高优先级的任务。 混合法,结合时间片轮转法和优先级抢占法,对于同一优先级的任务,使用时间片轮转法,对于不同优先级的任务,使用优先级抢占法,实现任务的公平性和效率。 23、项目中用到网络了吗? 这个问题的答案取决于你的项目的具体情况,如果你的项目需要与其他设备或服务器进行通信,或者需要访问互联网上的资源,那么你的项目就用到了网络。如果你的项目只是在本地运行,不需要与外界交互,那么你的项目就没有用到网络。 24、了解Socket吗? Socket是一种通信机制,它可以实现不同进程或不同设备之间的数据交换。Socket通常基于TCP/IP协议,提供了可靠的,双向的,面向连接的通信服务。Socket的基本操作包括创建,绑定,监听,连接,发送,接收,关闭等。Socket的编程接口通常是一组函数或类,不同的编程语言或平台可能有不同的实现,如C语言的socket.h,Java语言的java.net.Socket等。 25、c++中set是什么? set是C++标准模板库(STL)中的一个容器,它可以存储一组不重复的元素,并且按照一定的顺序排列。set的元素可以是任意类型,但是必须支持比较操作,如<,==等。set的底层实现通常是红黑树,所以它的插入,删除,查找等操作的时间复杂度都是O(logn) ,其中n是元素的个数。set的优点是可以快速地检查一个元素是否存在,以及保持元素的有序性。set的缺点是不能存储重复的元素,以及不能直接访问元素,只能通过迭代器遍历。 26、有没有用到C++模板? C++模板是一种泛型编程的技术,它可以让程序员定义一种通用的模式,然后根据不同的类型或参数,生成不同的代码,从而实现代码的复用和抽象。C++模板有两种,一种是函数模板,用于定义通用的函数,另一种是类模板,用于定义通用的类。例如,以下是一个函数模板,用于比较两个值的大小: template <typename T> T max(T x, T y) { return (x > y) ? x : y; } 我有用过C++模板,它们可以让我的代码更简洁,更灵活,更高效。我用过STL中的一些类模板,如vector,map,set等,也用过自己定义的一些函数模板和类模板,来实现一些通用的算法和数据结构。 27、有没有对代码裁剪的经验 代码裁剪是指对代码进行优化,删除不必要的或冗余的代码,减少代码的体积和复杂度,提高代码的可读性和可维护性。代码裁剪的目的是为了提高程序的性能,节省内存空间,降低编译时间,避免错误和漏洞等。 我有对代码裁剪的经验,我用过一些工具和方法来进行代码裁剪,如: 使用编译器的优化选项,如-Os,-O3等,让编译器自动进行一些代码裁剪,如常量折叠,死代码删除,循环展开等。 使用代码分析工具,如lint,coverity等,检查代码的质量,发现代码的缺陷,如未使用的变量,函数,参数等,以及代码的风格,规范,注释等,然后根据工具的建议,修改或删除代码。 使用代码重构工具,如refactor,eclipse等,对代码进行重构,改善代码的结构,设计,逻辑等,消除代码的冗余,重复,复杂等,提高代码的可读性,可维护性,可扩展性等。 使用代码压缩工具,如upx,gzip等,对代码进行压缩,减少代码的体积,提高代码的传输速度,节省存储空间等。 28、freertos系统是买模块时人家配置好的?还是移植的? freertos系统是一个开源的,可移植的,实时的操作系统,它可以运行在多种嵌入式平台上,如ARM,MIPS,AVR等。freertos系统不是买模块时人家配置好的,而是需要根据不同的硬件和需求进行移植和定制的。移植freertos系统的步骤一般如下: 下载freertos的源码,选择合适的移植层,如portable/GCC/ARM_CM3等,根据目标平台的特性,修改一些配置参数,如configCPU_CLOCK_HZ,configTICK_RATE_HZ等。 编写启动代码,如设置时钟,中断,堆栈等,调用vPortStartFirstTask ()函数,启动第一个任务。 编写应用代码,如创建任务,队列,信号量,定时器等,调用vTaskStartScheduler ()函数,启动调度器。 编译,链接,下载,调试代码,检查系统的运行情况,如任务切换,中断响应,内存管理等。 29、任务里有两把锁的时候该怎么处理 任务里有两把锁的时候,可能会出现死锁的问题,即两个或多个任务因为互相等待对方占有的锁而无法继续执行。处理任务里有两把锁的时候,有以下几种方法: 避免使用两把锁,如果可能的话,尽量使用一把锁来保护临界区,或者使用其他同步机制,如信号量,事件标志等,来实现任务之间的协作。 按照一定的顺序获取和释放锁,如果必须使用两把锁,那么要求所有的任务都按照相同的顺序获取和释放锁,避免形成循环等待的条件。 使用超时机制,如果一个任务在获取锁时,发现锁已经被占用,那么不要无限期地等待,而是设置一个超时时间,如果超时时间到了,还没有获取到锁,那么就放弃获取,释放已经占有的锁,然后重新尝试或者执行其他操作。 使用优先级继承机制,如果一个任务在获取锁时,发现锁已经被占用,那么就把自己的优先级赋给占有锁的任务,让占有锁的任务尽快执行完毕,释放锁,然后恢复原来的优先级,这样可以避免优先级反转的问题。 30、熟悉Shell脚本吗?$和#啥意思? Shell脚本是一种用于控制Unix或Linux系统的命令行解释器,它可以实现一些自动化的任务,如文件操作,文本处理,程序运行等。Shell脚本的语法和结构类似于C语言,但是更加简洁和灵活。Shell脚本的文件名通常以.sh为后缀,例如test.sh。 $和#是Shell脚本中的两个特殊符号,它们有以下含义: $表示变量的引用,可以用来获取或设置变量的值,例如x=10,echo $x,表示将10赋值给变量x,然后打印x的值。 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。 31、知道#error吗? 、#error是一个预处理指令,它可以用来在编译时产生一个错误信息,中断编译过程。#error通常用来检查一些条件,如宏定义,平台,版本等,如果不满足条件,就提示错误,防止编译出错的代码。例如: #ifdef __linux__ #error This code is not compatible with Linux #endif 这段代码表示如果定义了__linux__宏,就产生一个错误信息,表示这段代码不兼容Linux系统。 32、freertos消息队列的的具体实现? freertos消息队列是一种用于实现任务之间或任务与中断之间的异步通信的机制,它可以存储一组有序的消息,每个消息可以是任意类型的数据。freertos消息队列的具体实现如下: 消息队列是一个结构体,它包含了一些成员,如队列的头指针,尾指针,长度,容量,锁,信号量等,用来管理队列的状态和操作。 消息队列的存储空间是一个数组,它可以是静态分配的或动态分配的,它的大小要能够容纳队列的最大容量乘以每个消息的大小。 消息队列的操作有以下几种,如创建,删除,发送,接收等,它们都是通过调用一些API函数来实现的,如xQueueCreate,vQueueDelete,xQueueSend,xQueueReceive等。 消息队列的操作都是原子的,即在操作过程中,不会被其他任务或中断打断,这是通过使用临界区或中断屏蔽来实现的,以保证队列的一致性和完整性。 消息队列的操作都是阻塞的,即如果队列满了,就不能发送消息,如果队列空了,就不能接收消息,这是通过使用信号量来实现的,以实现任务的同步和等待。 33、堆栈区别? 堆(heap)和栈(stack)都是程序运行时使用的内存空间,但是它们有以下区别: 堆是动态分配的,程序员可以自由地申请和释放堆上的内存空间,堆的大小受到物理内存的限制,堆上的内存空间的地址是不连续的。 栈是静态分配的,编译器会自动地分配和回收栈上的内存空间,栈的大小受到操作系统的限制,栈上的内存空间的地址是连续的。 堆是全局共享的,堆上的内存空间可以被任何函数或模块访问,堆上的内存空间的生命周期是由程序员控制的,如果不及时释放,可能会导致内存泄漏。 栈是局部私有的,栈上的内存空间只能被当前函数或模块访问,栈上的内存空间的生命周期是由编译器控制的,当函数调用结束时,栈上的内存空间就会被自动释放。 34、程序存放状态和区别 程序存放状态是指程序在运行过程中的不同阶段,它有以下几种: 新建状态,指程序刚刚被创建,还没有被加载到内存中,等待调度器的调度。 就绪状态,指程序已经被加载到内存中,已经分配了必要的资源,等待处理器的分配。 运行状态,指程序已经被分配了处理器,正在执行程序的指令。 阻塞状态,指程序在执行过程中,因为等待某些事件的发生,如输入输出,信号量,中断等,而暂时停止执行,释放处理器,等待事件的完成。 终止状态,指程序已经执行完毕,或者因为某些原因,如错误,异常,中断等,而被终止,释放内存和资源,从系统中消失。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
617
4
2023-12-26
AI: 机器学习必须懂的几个术语:Label、Feature、Model...
1.标签 Label 2.特征 Feature 3.样本 Example3.1有标签样本(labeled): 3.2无标签样本(unlabeled): 4.模型 Model 5.回归 Regression 6.分类 Classification 7.机器学习算法地图 1.标签 Label 标签:所预测的东东实际是什么(可理解为结论),如线性回归中的 y 变量,如分类问题中图片中是猫是狗(或图片中狗的种类)、房子未来的价格、音频中的单词等等任何事物,都属于Label。 (如一组图片,已经表明了哪些是狗,哪些是猫,这里Label就是分类问题中每一个类) 图片 2.特征 Feature 特征是事物固有属性,可理解为做出某个判断的依据,如人的特征有长相、衣服、行为动作等等,一个事物可以有N多特征,这些组成了事物的特性,作为机器学习中识别、学习的基本依据。 图片 特征是机器学习模型的输入变量。如线性回归中的 x 变量。 图片 例如在垃圾邮件分类问题中,特征可能包括: 电子邮件中是否包含 “ 广告、贷款、交易” 等短语 电子邮件文本中的字词 发件人的地址 发送电子邮件的时段 其中机器学习重要步骤:特征提取就是通过多种方式,对数据的特征数据进行提取。一般,特征数据越多,训练的机器学习模型就会越精确,但处理难度也越大。 3.样本 Example 样本是指一组或几组数据,样本一般作为训练数据来训练模型 样本分为以下两类: 有标签样本 无标签样本 3.1有标签样本(labeled): 同时包含特征和标签 图片 在监督学习中利用数据做训练时,有标签数据/样本(Labeled data)或叫有/无标记数据,就是指有没有将数据归为要预测的类别。 例如以下房价数据集: 图片 其中包含特征:卧室数量等,最右边一列是标签:房价中间值 (注,因为该问题要预测未来房价走势,所以Label就是某条房屋数据中的房价) 3.2无标签样本(unlabeled): 包含特征,但不包含标签 如以下数据集: 去掉了Label,但是一样有用(如用在测试训练后的模型,即训练好模型后,输入该数据,那到预测后的房价与原标签进行比较,得到模型误差) 图片 4.模型 Model 模型定义了特征与标签之间的关系,就是我们机器学习的一组数据关系表示,也是我们学习机器学习的核心 例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。 模型生命周期的两个重要阶段: 训练 Training是指创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。 训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值 推断 Inference是指将训练后的模型应用于无标签样本。也就是说,使用经过训练的模型做出有用的预测 (y’)。 例如,模型训练好后,就可以使用模型进行Inference ,可以针对新的无标签样本预测房价medianHouseValue。 图片 5.回归 Regression 回归就是我们数学学习的线性方程,是一种经典函数逼近算法。 在机器学习中,就是根据数据集,建立一个线性方程组,能够无线逼近数据集中的数据点,是一种基于已有数据关系实现预测的算法。 回归模型可预测连续值(线性) 例如,回归模型做出的预测可回答如下问题: 某小区房价的趋势? 用户点击此广告的概率是多少? 图片 当机器学习模型最终目标(模型输出)是求一个具体数值时,例如房价的模型输出为25000,则大多数可以通过回归问题来解决。 线性回归的好处在与模型简单,计算速度快,方便应用在分布式系统对大数据进行处理。 线性回归还有个姐妹:逻辑回归(Logistic Regression),主要应用在分类领域 6.分类 Classification 顾名思义,分类模型可用来预测离散值 例如,分类模型做出的预测可回答如下问题: 是/否问题,某个指定电子邮件是垃圾邮件还是非垃圾邮件? 图片是动物还是人? 垃圾分类 图片 当机器学习模型最终目标(模型输出)是布尔或一定范围的数时,例如判断一张图片是不是人,模型输出0/1:0不是,1是;又例如垃圾分类,模型输出1-10之间的整数,1代表生活垃圾,2代表厨余垃圾。。等等,这类需求则大多数可以通过分类问题来解决。 7.机器学习算法地图 机器学习算法多种多样,许多情况下,建模和算法设计是Designer所选择的,具体采用哪种算法也没有一定要求,根据实际具体问题具体分析。 图片
机器学习
# 机器学习
刘航宇
3年前
0
1,153
2
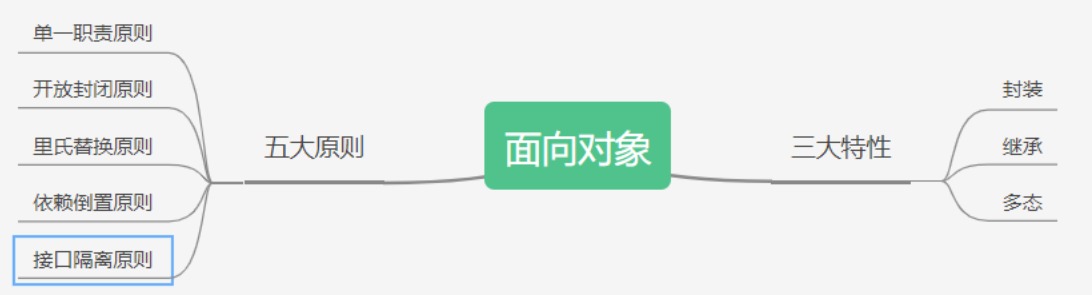
面向对象在编程中的概念
前言 那么究竟什么是面向对象呢?面向过程 面向对象 面向对象的三大特性封装 继承 多态 面向对象的五大基本原则单一职责原则(Single-Responsibility Principle) 开放封闭原则(Open-Closed principle) 里氏替换原则(Liskov-Substitution Principle) 依赖倒置原则(Dependecy-Inversion Principle) 接口隔离原则(Interface-Segregation Principle) 面向对象编程的用途 面向对象编程的应用领域 前言 在刚接触java、C++、Python语言的时候,就知道这是一门面向对象的语言。学不好java的原因找到了,面向对象的语言,没有对象怎么学 ::(狗头) 图片 那么究竟什么是面向对象呢? 面向对象,Object Oriented Programming,简称为OOP。说到面向对象,不得不提一嘴面向过程。 面向过程 面向过程是一种自顶而下的编程模式。 把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。 举个生活中的例子,假如你想吃红烧肉,你需要买肉,买调料,洗肉,切肉,烧肉,装盘。 需要我们具体每一步去实现,每个步骤相互协调,最终盛出来的才是正宗好吃的红烧肉。 面向对象 面向对象就是将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。 还是你想吃红烧肉这个例子,不过这次不同的是你发现了一家餐馆里有红烧肉这道菜,你要做的只是去点菜,就可以吃到红烧肉。 针不戳,针不戳,面向对象针不戳,你不用再去关心红烧肉繁琐的制作流程,就能吃到美味的红烧肉。 我们接着往下看 图片 面向对象的三大特性 封装 封装就是把客观的事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类进行信息的隐藏。简单的说就是:封装使对象的设计者与对象的使用者分开,使用者只要知道对象可以做什么就可以了,不需要知道具体是怎么实现的。封装可以有助于提高类和系统的安全性 这里有点像FPGA的IP了,电子人懂! 继承 当多个类中存在相同属性和行为时,将这些内容就可以抽取到一个单独的类中,使得多个类无需再定义这些属性和行为,只需继承那个类即可。通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类” 多态 多态同一个行为具有多个不同表现形式或形态的能力。是指一个类实例(对象)的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。 菜鸟教程中的例子就很形象 现实中,比如我们按下 F1 键这个动作: 如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档; 如果当前在 Word 下弹出的就是 Word 帮助; 在 Windows 下弹出的就是 Windows 帮助和支持。 同一个事件发生在不同的对象上会产生不同的结果。 面向对象的五大基本原则 单一职责原则(Single-Responsibility Principle) 简而言之,就是一个类最好只有一个能引起变化的原因,只做一件事,单一职责原则可以看做是低耦合高内聚思想的延伸,提高高内聚来减少引起变化的原因。 开放封闭原则(Open-Closed principle) 简而言之,就是软件实体应该是可扩展的,但是不可修改。因为修改程序有可能会对原来的程序造成错误。即对扩展开放,对修改封闭 里氏替换原则(Liskov-Substitution Principle) 简而言之,就是子类一定可以替换父类,子类包含其基类(父类)的功能 依赖倒置原则(Dependecy-Inversion Principle) 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。依赖于抽象即对接口编程,不要对实现编程 接口隔离原则(Interface-Segregation Principle) 图片 简而言之,就是使用多个小的专门的接口,而不要使用一个大的总接口。例如将一个房子再分割成卧室,厨房,厕所等等,而不是将所有功能放在一起 面向对象编程的用途 使用封装(信息隐藏)可以对外部隐藏数据 使用继承可以重用代码 使用多态可以重载操作符/方法/函数,即相同的函数名或操作符名称可用于多种任务 数据抽象可以用抽象实现 项目易于迁移(可以从小项目转换成大项目) 同一项目分工 软件复杂性可控 面向对象编程的应用领域 人工智能与专家系统 企业级应用 神经网络与并行编程 办公自动化系统
编程&脚本笔记
# 软件算法
# C/C++
刘航宇
3年前
0
435
3
2023-12-20
【嵌软】STM32的4种开发方式介绍
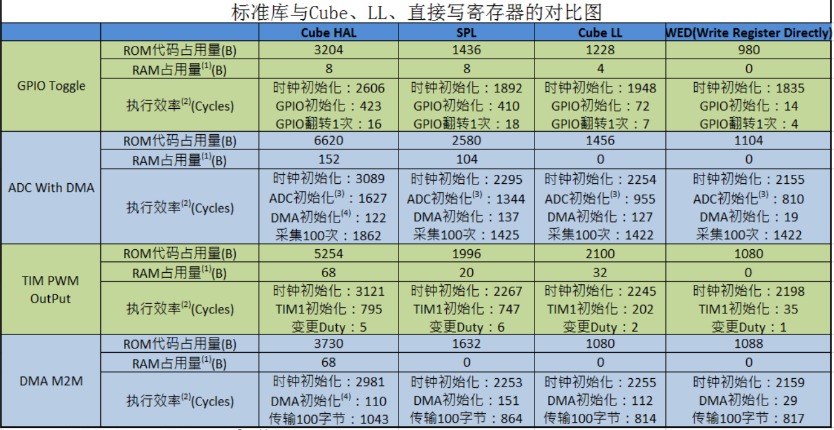
与FPGA一样,STM32也属于板级开发,可适用于大多数计算场合,但神经网络这种需要大量并行计算的需求难以满足。 STM32的开发主要指的是通过程序实现功能,ST官方提供的开发方式来说从远及近分别是: 1、直接读写寄存器 2、标准外设驱动库 SPL 3、硬件抽象层库 HAL库 4、底层库 LL库 四种开发方式各有优缺点,可以参考ST官方的测试与说明: 图片 标准外设库:这是ST官方提供的一套固件库,包含了STM32所有外设的驱动函数,可以方便地调用。它的优点是稳定、兼容、易用,缺点是占用资源较多,效率较低,更新较慢。 寄存器操作:这是直接对STM32的寄存器进行读写的方式,可以实现最底层的控制。它的优点是占用资源最少,效率最高,缺点是难度较大,需要熟悉寄存器的功能和位定义,不利于移植。 HAL库:这是ST官方推出的一套新的固件库,基于硬件抽象层(Hardware Abstraction Layer)的思想,提供了更加简洁和统一的接口。它的优点是支持多种IDE,更新较快,易于移植,缺点是文档较少,兼容性较差,有些BUG。CubeMX:这是ST官方提供的一套图形化的配置工具,可以自动生成HAL库的代码,还可以集成一些中间件和应用层的功能。它的优点是操作简单,功能强大,缺点是生成的代码较冗余,不易修改,有些功能不完善。 直接读写寄存器 开发是最慢的,可移植性最差,基本不推荐使用,只有个别对时间或是内存要求特别高、或者在写操作系统调度器时才需要直接读写寄存器; 标准外设驱动库 是ST最开始提供的库(国内的教程也很多是依据题库出的),现在已经被ST放弃了; HAL库 和 LL库 是近几年推出的库,结合 STM32CubeIDE 使用非常方便, HAL库 性能较差、在STM32系列芯片中可移植性好, LL库 性能好、可移植性差。
嵌入式&系统
# 嵌入式
# C/C++
刘航宇
3年前
0
1,163
3
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
502
0
2023-12-11
大疆题解:跨时钟域脉冲信号处理—脉冲同步器(快到慢)
问题描述 题解1.1 电路波形图 1.2 代码 注意 问题描述 sig_a 是 clka(300M)时钟域的一个单时钟脉冲信号(高电平持续一个时钟clka周期),请设计脉冲同步电路,将sig_a信号同步到时钟域 clkb(100M)中,产生sig_b单时钟脉冲信号(高电平持续一个时钟clkb周期)输出。请用 Verilog 代码描述。 clka时钟域脉冲之间的间隔很大,无需考虑脉冲间隔太小的问题。 电路的接口如下图所示: 图片 题解 1.1 电路波形图 图片 如上图所述,aclk快时钟域发送的信号signal_a,慢时钟域的时钟bclk根本就采集不到,此时不能使用打两拍的方式,要想办法转换思路, 如果能够让同步于快时钟域aclk下的脉冲信号signal_a变长到可以让慢时钟域bclk检测到,那么这个问题就可以完美解决了。 所以先将快时钟域clka下的脉冲信号signal_a,在快时钟域clka的作用下,变为沿信号,产生一个名为adata的中间变量来作为脉冲信号signal_a的沿信号。如上图所示,每当快时钟域aclk检测到signal_a脉冲信号为高时,让adata信号取反,使得signal_a的第一个脉冲变为adata信号的上升沿,signal_a的第二个脉冲变为adata信号的下降沿,后面如果Signal_a信号还有脉冲依然是变为adata信号的上升沿和下降沿。 巧妙的利用将“脉冲信号”转化为“沿信号”的思想就可以使慢时钟域的时钟bclk检测到同步于快时钟域aclk且将脉冲信号signal_a转化为沿信号adata, 相当于是把同步于快时钟域aclk的脉冲信号signal_a进行了展宽处理,这样我们就把快时钟域aclk的脉冲信号signal_a通过adata信号“沿”的形式在慢时钟域bclk中得到了保留。 接着,我们再对adata信号做打两拍的处理就可以将adata信号同步到慢时钟域clkb中了。bdata0信号是adata信号在慢时钟域bclk下打的第一拍,bdata1信号是adata信号在慢速时钟域bclk下打第二拍,bdata1就是同步于慢速时钟域bclk的稳定信号。 最后,采用 边沿检测 的方法,将变为bdata1信号的“沿”再转化为脉冲信号,这里我们使用的方法是采用异或门。需要注意的是不能直接使用bdata0和bdata1来产生沿标志信号,因为bdata0信号的不稳定性可能会导致产生的沿信号也不稳定,所以需要将bdata1信号再打一拍,产生signal_b信号。 1.2 代码 //快时钟数据同步 module pulse_detect( input clka , input clkb , input rst_n , input sig_a , output sig_b ); wire sig_a; reg adata; reg bdata0; reg bdata1; reg bdata2; always @(posedge clka or negedge rst_n) begin if(~rst_n) begin adata <= 1'd0; end else begin adata <= adata ^ sig_a; end end always @(posedge clkb or negedge rst_n) begin if(~rst_n) begin bdata0 <= 1'd0; bdata1 <= 1'd0; bdata2 <= 1'd0; end else begin bdata0 <= adata; bdata1 <= bdata0; bdata2 <= bdata1; end end assign sig_b = bdata1 ^ bdata2; endmodule注意 signal_a是两个脉冲,但是使用“脉冲同步”同步到bclk时钟域确只有一个脉冲了,在使用“脉冲同步”时应注意这一点。所以,脉冲同步一般适用于单比特信号从快时钟域传递慢时钟域的场景。
FPGA&ASIC
# ASIC/FPGA
# Verilog
刘航宇
3年前
0
970
3
2023-11-20
超声模块HC_SR04基本原理与FPGA、STM32应用
HC-SR04硬件概述 接口定义: 模式选择: 测量操作: FPGA实现超声测距模块代码 ifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" endif / HCSR04_H_ / include "hc-sr04.h" include "hc-sr04.h" include "printf.h" HC-SR04 硬件概述 HC-SR04超声波距离传感器的核心是两个超声波传感器。一个用作发射器,将电信号转换为40 KHz超声波脉冲。接收器监听发射的脉冲。如果接收到它们,它将产生一个输出脉冲,其宽度可用于确定脉冲传播的距离。就是如此简单! 该传感器体积小,易于在任何机器人项目中使用,并提供2厘米至600厘米(约1英寸至13英尺)之间出色的非接触范围检测,精度为3mm。 图片 接口定义: 图片 模式选择: 图片 测量操作: 一:GPIO模式 图片 外部MCU给模块Trig脚一个大于10uS的高电平脉冲;模块会给出一个与距离等比的高电平脉冲信号,可根据脉宽时间“T” 算出: 距离=T*C/2 (C为声速) 声速温度公式:c=(331.45+0.61t/℃)m•s-1 (其中330.45是在0℃) 0℃声速: 330.45M/S 20℃声速: 342.62M/S 40℃声速: 354.85M/S0℃-40℃声速误差7%左右。实际应用,如果需要精确距离值,必需要考虑温度影响,做温度补偿。 二:UART模式 UART 模式波特率设置: 9600 N 1 图片 连接串口。外部MCU或PC发命令0XA0,模块完成测距后发3个返回距离 数据,BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 三:IIC模式 IIC地址: 0X57 IIC传输格式: 写数据: 图片 读数据: 图片 命令格式: 图片 向模块写入0X01,模块开始测距;等待200mS(模块最大测距时间) 以上。直接读出3个距离数据。BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 FPGA实现超声测距 本次测距教程一律按基本原理实现,至于UART、ICC测距原理可以网上查询 FPGA 产生周期性的 TRIG 脉冲信号,使得超声波模块周期性发出测距脉冲,当这些脉冲发出后遇到障碍物返回,超声波模块将返回的脉冲处理整形后返回给 FPGA,即 ECHO 信号。我们通过对 ECHO 信号的高脉冲保持时间就可以推算出超声波脉冲和障碍物之间的距离。 本实例的功能如图三所示,FPGA 产生 10us 脉冲 TRIG 给超声波测距模块,然后以 10us 为单位计算超声波测距模块返回的回响信号 ECHO 的高电平保持时间。ECHO 的高电平保持时间通过一定的换算后可以得到障碍物和超声波测距模块之间的距离(由距离公式计算&进制换算模块实现),我们将最终获得的以 mm 为单位的距离信息显示在 4 位数码管上。 图片 模块代码 1、vlg_en模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 15:24:01 * @Email: hyliu@ee.ac.cn * @Descripttion: 板子时钟转化1us * @Last Modified time: 2023-11-20 15:24:01 */ //1us/50ns=20 module vlg_1us#(parameter P_CLK_PERIORD = 50) //i_clk的时钟周期50ns,20MHZ ( input i_clk, input i_rst_n, output reg o_clk //时钟周期1us ); parameter NUM_DIV = 20;// (1MHZ = 1us,20MHZ/20 = 1MHZ) reg [3:0] cnt; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) begin cnt <= 4'd0; o_clk <= 1'b0; end else if(cnt == NUM_DIV/2 - 1) begin cnt <= 4'b0; o_clk <= ~o_clk; end else cnt <= cnt + 1'b1; end endmodule2、vlg_trig模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 16:50:44 * @Email: hyliu@ee.ac.cn * @Descripttion: 产生10us的触发超声信号 * @Last Modified time: 2023-11-20 16:50:44 */ module vlg_trig ( input i_rst_n, input clk_1us, //1us output reg o_trig ); reg[17:0] r_tricnt; //200ms的周期计数 1us一个单位 always @(posedge clk_1us or negedge i_rst_n)begin if(!i_rst_n) r_tricnt <= 18'd0; else if((r_tricnt == 18'd199999)) r_tricnt <= 18'd0; else r_tricnt <= r_tricnt + 1'b1; end //产生保持10us的高脉冲o_tring信号 always @(posedge clk_1us or negedge i_rst_n) begin if(!i_rst_n) o_trig<=1'b0; else if((r_tricnt > 18'd0) && (r_tricnt <= 18'd10)) o_trig <= 1'b1; //不从0开始0~9,防止出现不到10us的波干扰 else o_trig <= 1'b0; end endmodule3、vlg_echo模块 module vlg_echo ( input i_clk, //1us input i_rst_n, input i_clk_1us, input i_echo, output reg[15:0] o_t_us ); reg[1:0] r_echo; wire pos_echo,neg_echo; reg r_cnt_en; reg[15:0] r_echo_cnt; //对i_echo信号同步处理,获取边沿检测信号,产生计数使能信号r_cnt_en always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_echo <= 2'd0; else r_echo <= {r_echo[0],i_echo}; //设置两个寄存器进行打拍寄存 end assign pos_echo = r_echo[0] & ~r_echo[1]; //现状态是1上状态是0,就是上升沿 assign neg_echo = ~r_echo[0] & r_echo[1]; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_cnt_en <= 1'b0; else if(pos_echo) r_cnt_en <= 1'b1; else if(neg_echo) r_cnt_en <= 1'b0; else r_cnt_en <= r_cnt_en; end //对i_echo信号的高脉冲计时,以us为单位 always @(posedge i_clk_1us or negedge i_rst_n) begin if(!i_rst_n) r_echo_cnt <= 1'b0; else if(r_cnt_en) r_echo_cnt <= r_echo_cnt + 1'b1; else r_echo_cnt <= 1'b0; end //在下降沿对计数最大值进行保存 always @(negedge i_clk or negedge i_rst_n) begin if(!i_rst_n) o_t_us <= 16'd0; else if(neg_echo) o_t_us <= r_echo_cnt; else o_t_us <= o_t_us; end endmodule 4、顶层模块例化/* @Author: Hangyu Liu @Date: 2023-11-23 17:16:40 @Email: hyliu@ee.ac.cn @Descripttion:HR04驱动模块 @Last Modified time: 2023-11-23 17:16:40 */ module vlg_design ( input i_clk, //200MHZ input i_rst_n, input i_echo, //这是超声模块给的输入 output o_trig, output wire[15:0] w_t_us); wire clk_20MHZ; clk_div_20MHZ UU( .i_clk(i_clk), .i_rst_n(i_rst_n), .clk_div(clk_20MHZ)); localparam P_CLK_PERIORD = 50; wire clk_1us; //使能时钟产生模块 vlg_1us #( .P_CLK_PERIORD(P_CLK_PERIORD) //i_clk的时钟周期50ns,20MHZ)U1( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .o_clk(clk_1us)); //产生超声波测距模块的触发信号o_trig vlg_trig U2( .i_rst_n(i_rst_n), .clk_1us(clk_1us), .o_trig(o_trig)); //超声波测距模块的回响信号i_echo的高电平时间采集 vlg_echo U3( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .i_clk_1us(clk_1us), .i_echo(i_echo), .o_t_us(w_t_us)); endmodule ## STM32(Cubemax)实现超声波测距 ### CubeMX配置STM32 1 时钟配置 这里我用的是STM32F103C8T6的核心板,时钟配置如下图,我用了8MHz的HSE,HCLK调到了最大值72MHz  2 设置输入捕获的定时器 设置定时器TIM2每1us向上计数一次,通道4为上升沿捕获并连接到超声波模块的ECHO引脚,记得开启定时器中断(涉及到捕获中断+定时器溢出中断)。  3 触发引脚 PB10接到了HC-SR04的TIRG触发引脚,默认输出低电平  4 串口配置 还要开启一个串口,以便通过串口查看测距结果  ### 编写代码 hc-sr04.hifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" typedef struct { uint8_t edge_state; uint16_t tim_overflow_counter; uint32_t prescaler; uint32_t period; uint32_t t1; // 上升沿时间 uint32_t t2; // 下降沿时间 uint32_t high_level_us; // 高电平持续时间 float distance; TIM_TypeDef* instance;uint32_t ic_tim_ch; HAL_TIM_ActiveChannel active_channel;}Hcsr04InfoTypeDef; extern Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel); /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start(); /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim); /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim); /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read(); endif / HCSR04_H_ / hc-sr04.cinclude "hc-sr04.h" Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel) { /--------[ Configure The HCSR04 IC Timer Channel ] / // MX_TIM2_Init(); // cubemx中配置 Hcsr04Info.prescaler = htim->Init.Prescaler; // 72-1 Hcsr04Info.period = htim->Init.Period; // 65535 Hcsr04Info.instance = htim->Instance; // TIM2 Hcsr04Info.ic_tim_ch = Channel; if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_1) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_1; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_2) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_2; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_3) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_3; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} /--------[ Start The ICU Channel ]-------/ HAL_TIM_Base_Start_IT(htim); HAL_TIM_IC_Start_IT(htim, Channel); } /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start() { HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_SET); DelayUs(10); // 10us以上 HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_RESET); } /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim) { if(htim->Instance == Hcsr04Info.instance) // TIM2 { Hcsr04Info.tim_overflow_counter++;} } /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim) { if((htim->Instance == Hcsr04Info.instance) && (htim->Channel == Hcsr04Info.active_channel)) { if(Hcsr04Info.edge_state == 0) // 捕获上升沿 { // 得到上升沿开始时间T1,并更改输入捕获为下降沿 Hcsr04Info.t1 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_FALLING); Hcsr04Info.tim_overflow_counter = 0; // 定时器溢出计数器清零 Hcsr04Info.edge_state = 1; // 上升沿、下降沿捕获标志位 } else if(Hcsr04Info.edge_state == 1) // 捕获下降沿 { // 捕获下降沿时间T2,并计算高电平时间 Hcsr04Info.t2 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); Hcsr04Info.t2 += Hcsr04Info.tim_overflow_counter * Hcsr04Info.period; // 需要考虑定时器溢出中断 Hcsr04Info.high_level_us = Hcsr04Info.t2 - Hcsr04Info.t1; // 高电平持续时间 = 下降沿时间点 - 上升沿时间点 // 计算距离 Hcsr04Info.distance = (Hcsr04Info.high_level_us / 1000000.0) * 340.0 / 2.0 * 100.0; // 重新开启上升沿捕获 Hcsr04Info.edge_state = 0; // 一次采集完毕,清零 __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_RISING); }} } /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read() { // 测距结果限幅 if(Hcsr04Info.distance >= 450) { Hcsr04Info.distance = 450;} return Hcsr04Info.distance; } main.c 1、引用对应的头文件/ USER CODE BEGIN Includes / include "hc-sr04.h" include "printf.h" / USER CODE END Includes / 2、200ms测距一次/** @brief The application entry point. @retval int */ int main(void) { / USER CODE BEGIN 1 / / USER CODE END 1 / / MCU Configuration--------------------------------------------------------/ / Reset of all peripherals, Initializes the Flash interface and the Systick. / HAL_Init(); / USER CODE BEGIN Init / / USER CODE END Init / / Configure the system clock / SystemClock_Config(); / USER CODE BEGIN SysInit / / USER CODE END SysInit / / Initialize all configured peripherals / MX_GPIO_Init(); MX_TIM2_Init(); MX_USART1_UART_Init(); / USER CODE BEGIN 2 / DelayInit(72); Hcsr04Init(&htim2, TIM_CHANNEL_4); // 超声波模块初始化 Hcsr04Start(); // 开启超声波模块测距 printf("hc-sr04 start!\r\n"); / USER CODE END 2 / / Infinite loop / / USER CODE BEGIN WHILE / while (1) { // 打印测距结果 printf("distance:%.1f cm\r\n", Hcsr04Read()); Hcsr04Start(); DelayMs(200); // 测距周期200ms /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */} / USER CODE END 3 / } 3、重定义定时器的中断服务函数/ USER CODE BEGIN 4 / /** @description: 定时器输出捕获中断 @param {TIM_HandleTypeDef} *htim @return {*} */ void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim) { Hcsr04TimIcIsr(htim); } /** @description: 定时器溢出中断 @param {*} @return {*} */ void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef* htim) { Hcsr04TimOverflowIsr(htim); } / USER CODE END 4 / 4、串口打印结果
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
0
1,301
2
嵌入式/SOC开发利器-ZYNQ简介与入门
ZYNQ是什么? ZYNQ为什么厉害 ZYNQ的结构 开发工具 ZYNQ开发流程 ZYNQ是什么? 这是一款由Xilinx公司开发的集成了ARM处理器和FPGA可编程逻辑的片上系统(SoC)芯片。ZYNQ7000有多个型号,根据处理器核心数和FPGA系列的不同,可以应用于多种领域,如图像处理,通信,嵌入式系统等。 ZYNQ中国人读法 “zingke”、“任克”,“Soc”,英文全称叫 System on one Chip ,也就是片上系统的意思。没有微机基础的同学可能不明白什么叫Soc,但是你可以细细琢磨一下,我们的手机和台式电脑的不同,你就可以理解Soc的内含了。 传统计算机是将CPU,内存,GPU,南北桥焊接在印刷电路板上,各个组件之间是分立的。但是Soc则将CPU和各种外设集中到一块芯片上,集合成一个系统,因此像手机这种使用了Soc芯片的这种微机可以做的很轻薄,我们可以说,Soc是未来微机发展的一个趋势,我之前遇见过的像什么全志的A33就是典型的Soc。 ZYNQ为什么厉害 就在于它是一块可编程的Soc。其内部往往有处理器硬核和一些定制外设,并且外设当中有一个很厉害的玩意:PL,即可编程逻辑模块,也就是我们一般意义上的FPGA,所以简单理解ZYNQ就是“ 单片机 + FPGA “,它既可以执行代码程序,也可以实现FPGA。因此我们设计ZYNQ就是在做Soc设计。 ZYNQ的结构 我们先来开一下简化版的模型 图片 上面的模型细致低展开后就是下图的样子: 图片 图是 ZYNQ 7000的结构图,大体分为PS(Processing System)和 PL(Programmable Logic)两部分,其中的PS部分主要是由双核APU和外围的一些外设组成,说实话很像单片机的结构,而外围的PL则类似FPGA,并且两者通过AXI接口进行互联以实现功能. 重点介绍一下APU,应用处理单元:Application Processing Unit,位于PS(processing system)中,包括一个单核或者双核的cortex-A9处理器,处理器连接一个512KB的共享L2cache,每个处理器都有一个32KB的高速L1 cache,A9支持虚拟内存和32bit arm 指令。APU中的A9处理器由可配置的MP组成,MP包含SCU(snoop control unit:监控控制单元)单元,这个单元主要负责获取两个处理器的L1 cache和ACP(accelerator coherency port:加速器相关接口) PL的一致性。应用单元还有一个低延迟的片上memory,与L2 cache并行的,ACP(加速器接口)是PL与APU通信接口,该接口是PL作为主机的AXI协议的接口,最多支持64bit位宽,PL通过ACP接口访问L2 cache 和片上memory,同时保持和L1 cache的内存一致性。L2 cache 可以访问 DDR 控制,这个ddr 控制器是专用的,大大降低内存读写的延迟APU 还包括一个32bit的看门狗,一个64bit的全局定时器,APU 架构图如下所示: 图片 开发工具 在Vivado 19.2之前,我们开发Zynq需要三样必须的软件: Vivado SDK PetaLinux 其中Vivado用来开发硬件平台,SDK开发软件,PetaLinux则制作配套的Linux系统。可能有些人还有用到HLS ,即VIvado HLS 或者Vitis HLS;其中Vivado HLS 2020.1将是Vivado HLS的最后一个版本,取而代之的是VitisHLS。 到了Vivado 19.2之后,事情发生了变化。为了方便大家理解,我愿意称之这些软件成了为Vitis 家族的各个部分,原来的SDK被Vitis IDE取代,Vivado导出的 .hdf 文件被 .xsa文件代替,用来给vitis平台使用。因此我们需要的开发Zynq 最基本的软件变成了 Vivado Vitis IDE PetaLinux 各软件发挥的作用和之前的差不多,不过除了上面提到的四款软件外,Vitis家族还有 Vitis AI 等组件,他们共同组成了所谓的“Vitis™ Unified Software Platform ”,从发展趋势来看,这些开发软件应该会逐步的统一,入门的同学也不会再一头雾水地纠结 Vitis 和 Vivado 的区别和联系了。 ZYNQ开发流程 ZYNQ类似于一个 单片机 + FPGA的结构,其实我觉得如果大家接触过一些 Soc就会更好地理解ZYNQ的作用,就例如全志A33这块Soc,它是一块ASIC,不可以通过编程来对芯片的硬件进行重设计的。 图片 我们可以看到,灰色部分的外设都是固定的,像什么摄像头接口,什么视频接口都是设计好的,定制化的好处就使得总体比较高效,制造成本也低;但是如果我要运用到其它场景下,比如说我需要多个摄像头,那这块芯片就不再适合了(硬件控制的上限就是前后两颗摄像头) 而ZYNQ的意义相当于只给你定制的蓝色部分,也就是处理器内核,灰色的部分都可以通过FPGA实现,这让电子工程师们可以快速开发出各种各样有针对性的Soc;当然了,看过我第一篇博客的同学都知道,其实固定的硬核不止只有处理器内核,其实还有串口和内存控制器之类的外设,这其实是追寻一种固定和变化之间的平衡。 咱们把话说回ZYNQ的开发上来。 图片 ZYNQ的开发流程分为硬件和软件两部分,在SDK之前的属于硬件开发,也就是我们常说的PL部分的开发,而SDK后就属于软件部分的开发了,类似单片机,属于PS部分。当然现在最新的Vitis IDE已经取代了SDK,所以后半部分一般在SDK中进行。 PL部分的开发包括对 嵌入式最小系统的构建,以及FPGA外设的设计两个方面。我觉得要转变的一个思维是,我们现在不是在开发一个什么SDRAM控制器,什么IIC协议控制器,我们在开发的是一个小型的微机系统!因此嵌入式最小系统的设计是我们的核心。 首先,在IP INTEGRATOR中我们要创建BLOCK DESIGN。 图片 IP是用来进行 Embedded System Design ,也就是咱们常说的嵌入式系统设计。也就是咱们上面说的嵌入式最小系统的设计。 图片 大家可以看到,一个最小的系统其实不需要PL参与的,PL可以作为PS的一个外设使用,或者是自己做自己的事情,仅仅作为一个PL工作。既然是外设,当然是可用可不用的,毕竟咱们有好多的外设可以在Block Design 中直接配置使用,即下图绿色部分。 图片 配置好嵌入式系统后,咱们根据需要进行PL部分的设计。这里涉及一个问题,那就是PS和PL之间的数据传输方式有哪些: 中断 IO方式:MIO EMIO GPIO BRAM或FIFO或EMIF AXI DMA:PS通过AXI-lite向AXI DMA发送指令,AXI DMA通过HP通路和DDR交换数据,PL通过AXI-S读写DMA的数据。 等等。。。 可以看出,其实两个部分的交互方式还是很多的,以后咱们遇到一个说一个。 在Vivado端完成对嵌入式系统的设计后,我们就要进入Vitis IDE 端进行软件的开发。 图片 Vitis IDE简单来说流程一般是:新建一个工程,选择Platform ,也就是我们之前在Vivado中生成的 XSA文件,然后添加文件,进行开发。我相信使用过Keil 5的同学们应该心中对文件目录结构应该更胸有成竹,Src文件夹中存放的是源文件。 代码编写完之后是编译,编译完就是下载了。不过这里要注意以下,如果我们使用了PL的资源,那么在下载软件编译生成的 elf 文件之前,需要先下载硬件设计过程中生成的 bitstream 文件,对 PL 部分进行配置。 最后就是验证工作了,上述的流程是普通的ZYNQ开发流程;玩的花一点的同学可能是直接上Linux操作系统,这部分等后面我接触到了再说吧! 其实我觉得ZYNQ入门简单,精通的话需要大量的知识储备,但也不是不可能,开发ZYNQ相比于做单片机开发肯定路子会更广一些,向上可以做IC设计,向下嵌入式、单片机什么的工作也能胜任。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# 嵌入式
# SOC设计
刘航宇
3年前
0
4,044
4
2023-11-01
机器学习/深度学习-10个激活函数详解
图片 综述 1. Sigmoid 激活函数 2. Tanh / 双曲正切激活函数 3. ReLU 激活函数 4. Leaky ReLU 5. ELU 6. PReLU(Parametric ReLU) 7. Softmax 8. Swish 9. Maxout 10. Softplus 综述 激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。 在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式,本文概述了深度学习中常见的十种激活函数及其优缺点。 首先我们来了解一下人工神经元的工作原理,大致如下: 图片 上述过程的数学可视化过程如下图所示: 图片 1. Sigmoid 激活函数 lofj8ajx.png图片 Sigmoid 函数的图像看起来像一个 S 形曲线。 函数表达式如下: $$\[\mathrm{f(z)=1/(1+e^{\wedge}-z)}\]$$ 在什么情况下适合使用 Sigmoid 激活函数呢? Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化; 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适; 梯度平滑,避免「跳跃」的输出值; 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率; 明确的预测,即非常接近 1 或 0。 Sigmoid 激活函数有哪些缺点? 倾向于梯度消失; 函数输出不是以 0 为中心的,这会降低权重更新的效率; Sigmoid 函数执行指数运算,计算机运行得较慢。 2. Tanh / 双曲正切激活函数 图片 tanh 激活函数的图像也是 S 形,表达式如下: $$f(x)=tanh(x)=\frac{2}{1+e^{-2x}}-1$$ tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。 图片 首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好; 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。 注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。 3. ReLU 激活函数 图片 ReLU 激活函数图像如上图所示,函数表达式如下: 图片 ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点: 当输入为正时,不存在梯度饱和问题。 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快 当然,它也有缺点: Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题; 我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。 4. Leaky ReLU 它是一种专门设计用于解决 Dead ReLU 问题的激活函数: 图片 ReLU vs Leaky ReLU 为什么 Leaky ReLU 比 ReLU 更好? $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 1、Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题; 2、leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右; 3、Leaky ReLU 的函数范围是(负无穷到正无穷)。 注意:从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。 5. ELU 图片 ELU vs Leaky ReLU vs ReLU ELU 的提出也解决了 ReLU 的问题。与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零。均值激活接近于零可以使学习更快,因为它们使梯度更接近自然梯度。 图片 显然,ELU 具有 ReLU 的所有优点,并且: 没有 Dead ReLU 问题,输出的平均值接近 0,以 0 为中心; ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习; ELU 在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。 一个小问题是它的计算强度更高。与 Leaky ReLU 类似,尽管理论上比 ReLU 要好,但目前在实践中没有充分的证据表明 ELU 总是比 ReLU 好。 6. PReLU(Parametric ReLU) 图片 PReLU 也是 ReLU 的改进版本: $$f(y_i)=\begin{cases}y_i,&\text{if }y_i>0\\a_iy_i,&\text{if }y_i\leq0\end{cases}.$$ 看一下 PReLU 的公式:参数α通常为 0 到 1 之间的数字,并且通常相对较小。 如果 a_i= 0,则 f 变为 ReLU 如果 a_i> 0,则 f 变为 leaky ReLU 如果 a_i 是可学习的参数,则 f 变为 PReLU PReLU 的优点如下: 在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU 问题。 与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。 7. Softmax 图片 Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。 图片 Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。 Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。 Softmax 激活函数的主要缺点是: 在零点不可微; 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。 8. Swish 图片 函数表达式:y = x * sigmoid (x) Swish 的设计受到了 LSTM 和高速网络中 gating 的 sigmoid 函数使用的启发。我们使用相同的 gating 值来简化 gating 机制,这称为 self-gating。 self-gating 的优点在于它只需要简单的标量输入,而普通的 gating 则需要多个标量输入。这使得诸如 Swish 之类的 self-gated 激活函数能够轻松替换以单个标量为输入的激活函数(例如 ReLU),而无需更改隐藏容量或参数数量。 Swish 激活函数的主要优点如下: 「无界性」有助于防止慢速训练期间,梯度逐渐接近 0 并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决); 导数恒 > 0; 平滑度在优化和泛化中起了重要作用。 9. Maxout 图片 在 Maxout 层,激活函数是输入的最大值,因此只有 2 个 maxout 节点的多层感知机就可以拟合任意的凸函数。 单个 Maxout 节点可以解释为对一个实值函数进行分段线性近似 (PWL) ,其中函数图上任意两点之间的线段位于图(凸函数)的上方。 $ReLU=\max\bigl(0,x\bigr),\mathrm{abs}\bigl(x\bigr)=\max\bigl(x,-x\bigr)$ Maxout 也可以对 d 维向量(V)实现: 图片 假设两个凸函数 h_1(x) 和 h_2(x),由两个 Maxout 节点近似化,函数 g(x) 是连续的 PWL 函数。 $$g\bigl(x\bigr)=h_1\bigl(x\bigr)-h_2\bigl(x\bigr)$$ 因此,由两个 Maxout 节点组成的 Maxout 层可以很好地近似任何连续函数。 图片 10. Softplus 图片 Softplus 函数:f(x)= ln(1 + exp x) Softplus 的导数为 f ′(x)=exp(x) / ( 1+exp x ) = 1/ (1 +exp(−x )) ,也称为 logistic / sigmoid 函数。 Softplus 函数类似于 ReLU 函数,但是相对较平滑,像 ReLU 一样是单侧抑制。它的接受范围很广:(0, + inf)。
机器学习
# 机器学习
# 软件算法
# DL/ML
刘航宇
3年前
0
603
0
Python-BP神经网络实现单特征多分类
不同于图像处理,神经网络在处理其他不少领域,常常需要单特征分类,本例实现同半径的圆进行多分类(3分类),特征即为圆的半径。 输入层12节点,一个6节点的隐藏层,输出层3个节点。 1.目标 2.开发环境 3.准备数据 4.处理数据 5.构建BP神经网络 总结 1.目标 通过BP算法实现对不同半径的圆的分类。 2.开发环境 Python3.10;jupyter notebook 3.准备数据 目的: 生成3类圆在第一象限内的坐标(圆心都是原点) 第1类:半径范围为1~10,分类标识为‘0’ 第2类:半径范围为10~20,分类标识为‘1’ 第3类:半径范围为20~30,分类标识为‘2’ 代码如下:data_generate.py import numpy as np import math import random import csv # 只生成第一象限内的坐标即可。每个圆生成12个坐标(x,y),相当于12个特征维度 def generate_circle(lower, upper): # 圆在第一象限内的坐标 data_ur = np.zeros(shape=(12, 2)) # 在上下限范围内,随机产生一个值作为半径 radius = random.randint(int(lower), int(upper)) # 在0~90度内,每隔7.5度取一次坐标,正好取12次 angles = np.arange(0, 0.5 * np.pi, 1 / 24 * np.pi) for i in range(12): temp_ur = np.zeros(2) x = round(radius * math.cos(angles[i]), 2) y = round(radius * math.sin(angles[i]), 2) temp_ur[0] = x temp_ur[1] = y data_ur[i] = temp_ur return data_ur, label # 将坐标保存到CSV文件中 def save2csv(data, batch, label): out = open("D:\\circles.csv", 'a', newline='') csv_write = csv.writer(out, dialect='excel') length = int(data.size / 2) for i in range(length): string = str(data[i][0]) + ',' + str(data[i][1]) + ',' + str(batch) + ',' + str(label) temp = string.split(',') csv_write.writerow(temp) out.close() if __name__ == "__main__": ''' 生成3类圆,标签(label)分别为:0、1、2 第1类圆的半径下限为1,上限为10 第2类圆的半径下限为10,上限为20 第3类圆的半径下限为20,上限为30 圆心都为原点 ''' lower = [1, 10, 20] # 半径随机值的下限 upper = [10, 20, 30] # 半径随机值的上限 label = ['0', '1', '2'] # 种类的标签 for i in range(len(label)): # 每类数据生成50组 for j in range(50): data, label = generate_circle(lower[i], upper[i]) batch = 50 * i + j + 1 # 数据的批次,用来区分每个坐标是属于哪个圆的 save2csv(data, batch, label[i])共3类圆,每类生成50个圆,每个圆 有12个坐标,因此在输出文件D:\circles.csv中总共有3×50×12=1800行数据: 图片 通过生成的坐标绘制散点图如下: 图片 图中蓝色的点是label为0的圆,绿色的点是label为1的圆,红色的点是label为2的圆。 4.处理数据 目标: 根据第3步获得的坐标,计算每个圆的半径(勾股定理)作为神经网络的输入。 代码如下:data_process.py import csv import math def process(file_name): # 要读取的CSV文件 csv_file = csv.reader(open(file_name, encoding='utf-8')) # 要生成的CSV文件 out_file = open("D:\\circles_data.csv", 'a', newline='') csv_write = csv.writer(out_file, dialect='excel') # 将csv_file每一行的圆坐标取出,如果是同一批次的(同一个圆),则写入到out_file的一行中 rows = [row for row in csv_file] current_batch = 'unknown' current_label = 'unknown' data_list = [] for r in rows: # 将无关字符都替换为空格 temp_string = str(r).replace('[', '').replace(']', '').replace('\'', '') # 将字符串以逗号分隔 item = str(temp_string).split(',') # 分别取出x轴坐标、y轴坐标、批次、标签 x = float(item[0]) y = float(item[1]) batch = item[2] label = item[3] # 如果是同一批次(同一个圆),则都放入data_list中 if current_batch == batch: # 根据勾股定理计算半径 distance = math.sqrt(pow(x, 2) + pow(y, 2)) data_list.append(distance) # 如果不是同一批次(同一个圆),则在末尾加上标签后,作为一行写入输出文件 else: if len(data_list) != 0: # 这个地方需注意一下,最后的标签用3列来表示,而不是一列 if label.strip() == '0': data_list.append(1) data_list.append(0) data_list.append(0) elif label.strip() == '1': data_list.append(0) data_list.append(1) data_list.append(0) else: data_list.append(0) data_list.append(0) data_list.append(1) result_string = str(data_list).replace('[', '').replace(']', '').replace('\'', '').strip() csv_write.writerow(result_string.split(',')) # 清空data_list,继续写入下一个批次 data_list.clear() distance = math.sqrt(pow(x, 2) + pow(y, 2)) data_list.append(distance) current_batch = batch current_label = label # 确保最后一个批次的数据能写入 if current_label.strip() == '0': data_list.append(1) data_list.append(0) data_list.append(0) elif current_label.strip() == '1': data_list.append(0) data_list.append(1) data_list.append(0) else: data_list.append(0) data_list.append(0) data_list.append(1) result_string = str(data_list).replace('[', '').replace(']', '').replace('\'', '').strip() csv_write.writerow(result_string.split(',')) # 关闭输出文件 out_file.close() if __name__ == "__main__": process('D:\\circles.csv')需要注意的是,生成的CSV文件共有15列,前12列为坐标对应的半径值,最后三列组合起来表示分类(label): 图片 (1,0,0)表示类型为“0”的圆,(0,1,0)表示类型为“1”的圆,(0,0,1)表示类型为“2”的圆,这样做的目的是为了下一步使用神经网络时处理起来方便。 5.构建BP神经网络 上一步处理好的数据可以作为训练数据,命名为:circles_data_training.csv 重复第3步和第4步,可以生成另一批数据作为测试数据,命名为:circles_data_test.csv 当然,也可以手动划分出训练数据和测试数据。 训练数据和测试数据在输入时,做了矩阵的转置,将列转置为行。 代码如下:data_analysis_bpnn.py import pandas as pd import numpy as np import datetime from sklearn.utils import shuffle # 1.初始化参数 def initialize_parameters(n_x, n_h, n_y): np.random.seed(2) # 权重和偏置矩阵 w1 = np.random.randn(n_h, n_x) * 0.01 b1 = np.zeros(shape=(n_h, 1)) w2 = np.random.randn(n_y, n_h) * 0.01 b2 = np.zeros(shape=(n_y, 1)) # 通过字典存储参数 parameters = {'w1': w1, 'b1': b1, 'w2': w2, 'b2': b2} return parameters # 2.前向传播 def forward_propagation(X, parameters): w1 = parameters['w1'] b1 = parameters['b1'] w2 = parameters['w2'] b2 = parameters['b2'] # 通过前向传播来计算a2 z1 = np.dot(w1, X) + b1 # 这个地方需注意矩阵加法:虽然(w1*X)和b1的维度不同,但可以相加 a1 = np.tanh(z1) # 使用tanh作为第一层的激活函数 z2 = np.dot(w2, a1) + b2 a2 = 1 / (1 + np.exp(-z2)) # 使用sigmoid作为第二层的激活函数 # 通过字典存储参数 cache = {'z1': z1, 'a1': a1, 'z2': z2, 'a2': a2} return a2, cache # 3.计算代价函数 def compute_cost(a2, Y, parameters): m = Y.shape[1] # Y的列数即为总的样本数 # 采用交叉熵(cross-entropy)作为代价函数 logprobs = np.multiply(np.log(a2), Y) + np.multiply((1 - Y), np.log(1 - a2)) cost = - np.sum(logprobs) / m return cost # 4.反向传播(计算代价函数的导数) def backward_propagation(parameters, cache, X, Y): m = Y.shape[1] w2 = parameters['w2'] a1 = cache['a1'] a2 = cache['a2'] # 反向传播,计算dw1、db1、dw2、db2 dz2 = a2 - Y dw2 = (1 / m) * np.dot(dz2, a1.T) db2 = (1 / m) * np.sum(dz2, axis=1, keepdims=True) dz1 = np.multiply(np.dot(w2.T, dz2), 1 - np.power(a1, 2)) dw1 = (1 / m) * np.dot(dz1, X.T) db1 = (1 / m) * np.sum(dz1, axis=1, keepdims=True) grads = {'dw1': dw1, 'db1': db1, 'dw2': dw2, 'db2': db2} return grads # 5.更新参数 def update_parameters(parameters, grads, learning_rate=0.0075): w1 = parameters['w1'] b1 = parameters['b1'] w2 = parameters['w2'] b2 = parameters['b2'] dw1 = grads['dw1'] db1 = grads['db1'] dw2 = grads['dw2'] db2 = grads['db2'] # 更新参数 w1 = w1 - dw1 * learning_rate b1 = b1 - db1 * learning_rate w2 = w2 - dw2 * learning_rate b2 = b2 - db2 * learning_rate parameters = {'w1': w1, 'b1': b1, 'w2': w2, 'b2': b2} return parameters # 建立神经网络 def nn_model(X, Y, n_h, n_input, n_output, num_iterations=10000, print_cost=False): np.random.seed(3) n_x = n_input # 输入层节点数 n_y = n_output # 输出层节点数 # 1.初始化参数 parameters = initialize_parameters(n_x, n_h, n_y) # 梯度下降循环 for i in range(0, num_iterations): # 2.前向传播 a2, cache = forward_propagation(X, parameters) # 3.计算代价函数 cost = compute_cost(a2, Y, parameters) # 4.反向传播 grads = backward_propagation(parameters, cache, X, Y) # 5.更新参数 parameters = update_parameters(parameters, grads) # 每1000次迭代,输出一次代价函数 if print_cost and i % 1000 == 0: print('迭代第%i次,代价函数为:%f' % (i, cost)) return parameters # 对模型进行测试 def predict(parameters, x_test, y_test): w1 = parameters['w1'] b1 = parameters['b1'] w2 = parameters['w2'] b2 = parameters['b2'] z1 = np.dot(w1, x_test) + b1 a1 = np.tanh(z1) z2 = np.dot(w2, a1) + b2 a2 = 1 / (1 + np.exp(-z2)) # 结果的维度 n_rows = y_test.shape[0] n_cols = y_test.shape[1] # 预测值结果存储 output = np.empty(shape=(n_rows, n_cols), dtype=int) # 取出每条测试数据的预测结果 for i in range(n_cols): # 将每条测试数据的预测结果(概率)存为一个行向量 temp = np.zeros(shape=n_rows) for j in range(n_rows): temp[j] = a2[j][i] # 将每条结果(概率)从小到大排序,并获得相应下标 sorted_dist = np.argsort(temp) length = len(sorted_dist) # 将概率最大的置为1,其它置为0 for k in range(length): if k == sorted_dist[length - 1]: output[k][i] = 1 else: output[k][i] = 0 print('预测结果:') print(output) print('真实结果:') print(y_test) count = 0 for k in range(0, n_cols): if output[0][k] == y_test[0][k] and output[1][k] == y_test[1][k] and output[2][k] == y_test[2][k]: count = count + 1 acc = count / int(y_test.shape[1]) * 100 print('准确率:%.2f%%' % acc) if __name__ == "__main__": # 读取数据 data_set = pd.read_csv('D:\\circles_data_training.csv', header=None) data_set = shuffle(data_set) # 打乱数据的输入顺序 # 取出“特征”和“标签”,并做了转置,将列转置为行 X = data_set.ix[:, 0:11].values.T # 前12列是特征 Y = data_set.ix[:, 12:14].values.T # 后3列是标签 Y = Y.astype('uint8') # 开始训练 start_time = datetime.datetime.now() # 输入12个节点,隐层6个节点,输出3个节点,迭代10000次 parameters = nn_model(X, Y, n_h=6, n_input=12, n_output=3, num_iterations=10000, print_cost=True) end_time = datetime.datetime.now() print("用时:" + str((end_time - start_time).seconds) + 's' + str(round((end_time - start_time).microseconds / 1000)) + 'ms') # 对模型进行测试 data_test = pd.read_csv('D:\\circles_data_test.csv', header=None) x_test = data_test.ix[:, 0:11].values.T y_test = data_test.ix[:, 12:14].values.T y_test = y_test.astype('uint8') predict(parameters, x_test, y_test)码中需要注意的几个关键参数: learning_rate=0.0075,学习率(可调) n_h=6,隐藏层节点数(可调) n_input=12,输入层节点数 n_output=3,输出层节点数 num_iterations=10000,迭代次数(可调) 另外,对于predict(parameters, x_test, y_test)函数需要说明一下: a2矩阵是最终的预测结果,但是是以概率的形式表示的(可以打印看一下)。通过比较3个类的概率,选出概率最大的那个置为1,其它两个置为0,形成output矩阵。 运行结果: 图片 上图中第一红框表示神经网络预测出的分类结果,第二个红框表示测试集中真实的分类((1,0,0)表示这个圆属于类型“0”)。 每次运行时,正确率可能不一样,最高能达到100%。通过调整刚才提到的关键参数中的学习率、隐藏层节点数、迭代次数可以提高正确率。 总结 神经网络的输入为12个半径值,输出结果为一个3维向量,其中置1的位就是对应的分类。 在实际应用中,12个半径值对应12个特征,3维向量表示能分3类。只要根据实际应用的需要修改特征数和分类数即可将上述程序应用于不同分类场景。
机器学习
# 机器学习
刘航宇
3年前
0
408
1
2023-10-15
DL-神经网络的正向传播与反向传播
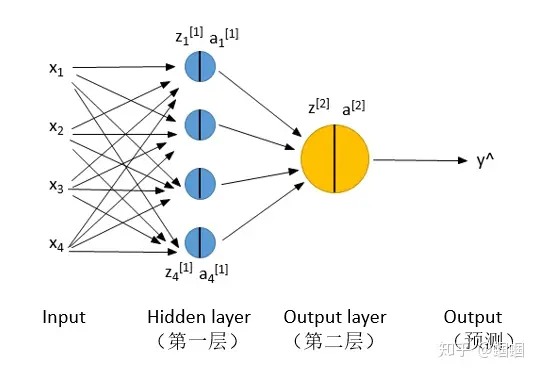
神经网络简述 前向传播 反向传播 四、深层神经网络(Deep Neural Network) 1.单个神经元 2.由神经元组成的神经网络 3.目标函数 4.求解损失函数对某个权值的梯度 5.反向传播算法Backpropgation 5.2 计算一个梯度 5.3 反向传播误差 6.优化示例 神经网络简述 神经网络,就是在Logistic regression的基础上增加了一个或几个隐层(hidden layer),下面展示的是一个最最最简单的神经网络,只有两层: 两层神经网络 图片 需要注意的是,上面的图是“两层”,而不是三层或者四层,输入和输出不算层! 这里,我们先规定一下记号(Notation): z是x和w、b线性运算的结果,z=wx+b; a是z的激活值; 下标的1,2,3,4代表该层的第i个神经元(unit); 上标的[1],[2]等代表当前是第几层。 y^代表模型的输出,y才是真实值,也就是标签 另外,有一点经常搞混: 上图中的x1,x2,x3,x4不是代表4个样本!而是一个样本的四个特征(4个维度的值)! 你如果有m个样本,代表要把上图的过程重复m次: 图片 神经网络的“两个传播”: 前向传播(Forward Propagation)前向传播就是从input,经过一层层的layer,不断计算每一层的z和a,最后得到输出y^ 的过程,计算出了y^,就可以根据它和真实值y的差别来计算损失(loss)。 反向传播(Backward Propagation)反向传播就是根据损失函数L(y^,y)来反方向地计算每一层的z、a、w、b的偏导数(梯度),从而更新参数。 前向传播和反向传播: 图片 每经过一次前向传播和反向传播之后,参数就更新一次,然后用新的参数再次循环上面的过程。这就是神经网络训练的整个过程。 前向传播 如果用for循环一个样本一个样本的计算,显然太慢,是使用Vectorization,把m个样本压缩成一个向量X来计算,同样的把z、a都进行向量化处理得到Z、A,这样就可以对m的样本同时进行表示和计算了。不熟悉的朋友可以看这里: 这样,我们用公式在表示一下我们的两层神经网络的前向传播过程: Layer 1:Z[1] = W[1]·X + b[1]A[1] = σ(Z[1]) Layer 2:Z[2] = W[2]·A[1] + b[2]A[2] = σ(Z[2]) 而我们知道,X其实就是A[0],所以不难看出:每一层的计算都是一样的: Layer i:Z[i] = W[i]·A[i-1] + b[i]A[i] = σ(Z[i]) (注:σ是sigmoid函数) 因此,其实不管我们神经网络有几层,都是将上面过程的重复。 对于 损失函数,就跟Logistic regression中的一样,使用 “交叉熵(cross-entropy)”,公式就是 二分类问题:L(y^,y) = -[y·log(y^ )+(1-y)·log(1-y^ )]- 多分类问题:L=-Σy(j)·y^(j) 这个是每个样本的loss,我们一般还要计算整个样本集的loss,也称为cost,用J表示,J就是L的平均: J(W,b) = 1/m·ΣL(y^(i),y(i)) 上面的求Z、A、L、J的过程就是正向传播。 反向传播 反向传播说白了根据根据J的公式对W和b求偏导,也就是求梯度。因为我们需要用梯度下降法来对参数进行更新,而更新就需要梯度。 但是,根据求偏导的链式法则我们知道,第l层的参数的梯度,需要通过l+1层的梯度来求得,因此我们求导的过程是“反向”的,这也就是为什么叫“反向传播”。 具体求导的过程,这里就不赘述了。像各种 深度学习框架TensorFlow、Keras,它们都是 只需要我们自己构建正向传播过程, 反向传播的过程是自动完成的,所以大家也确实不用操这个心。 进行了反向传播之后,我们就可以根据每一层的参数的梯度来更新参数了,更新了之后,重复正向、反向传播的过程,就可以不断训练学习更好的参数了。 四、深层神经网络(Deep Neural Network) 前面的讲解都是拿一个两层的很浅的神经网络为例的。 深层神经网络也没什么神秘,就是多了几个/几十个/上百个hidden layers罢了。 可以用一个简单的示意图表示: 深层神经网络: 图片 注意,在深层神经网络中,我们在中间层使用了 “ReLU”激活函数,而不是sigmoid函数了,只有在最后的输出层才使用了sigmoid函数,这是因为 ReLU函数在求梯度的时候更快,还可以一定程度上防止梯度消失现象,因此在深层的网络中常常采用。 关于深层神经网络,我们有必要再详细的观察一下它的结构,尤其是 每一层的各个变量的维度,毕竟我们在搭建模型的时候,维度至关重要。 图片 我们设: 总共有m个样本,问题为二分类问题(即y为0,1); 网络总共有L层,当前层为l层(l=1,2,...,L); 第l层的单元数为n[l];那么下面参数或变量的维度为: W[l]:(n[l],n[l-1])(该层的单元数,上层的单元数) b[l]:(n[l],1) z[l]:(n[l],1) Z[l]:(n[l],m) a[l]:(n[l],1) A[l]:(n[l],m) X:(n[0],m) Y:(1,m) 可能有人问,为什么 W和b的维度里面没有m? 因为 W和b对每个样本都是一样的,所有样本采用同一套参数(W,b), 而Z和A就不一样了,虽然计算时的参数一样,但是样本不一样的话,计算结果也不一样,所以维度中有m。 深度神经网络的正向传播、反向传播和前面写的2层的神经网络类似,就是多了几层,然后中间的激活函数由sigmoid变为ReLU了。 1.单个神经元 神经网络是由一系列神经元组成的模型,每一个神经元实际上做得事情就是实现非线性变换。 如下图就是一个神经元的结构: 图片 神经元将两个部分:上一层的输出(x1,x2,....,xn)与权重(w1,w2,....,wn),对应相乘相加,然后再加上一个偏置 b之后的值经过激活函数处理后完成非线性变换。 记 z = w ⋅ x + b ,a=σ(z),则 z 是神经元非线性变换之前的结果,这部分仅仅是一个简单的线性函数。σ 是Sigmod激活函数,该函数可以将无穷区间内的数映射到(-1,1)的范围内。a 是神经元将 z z 进行非线性变换之后的结果。 Sigmod函数图像如下图 $$\mathrm{sigmod(x)=\frac{1}{1+e^{-x}}}$$ 图片 因此,结果 a 就等于: 图片 这里再强调一遍,神经元的本质就是做非线性变换 2.由神经元组成的神经网络 神经元可以理解成一个函数,神经网络就是由很多个非线性变换的神经元组成的模型,因此神经网络可以理解成是一个非常复杂的复合函数。 图片 对于上图中的网络: (x1,x2,....,xn)为n维输入向量 Wij,表示后一层低i个神经元与前一层第j个神经元之间的权值 z = Wx + b是没有经过激活函数非线性变换之前的结果 a=σ(z),是 z 经过激活函数非线性变换之后的结果 \mathrm{s=U^Ta},为网络最终的输出结果。 3.目标函数 以折页损失为目标函数: $$\mathrm{minmizeJ}=\max(\Delta+s_{c}-s,0)$$ 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 一般来说,学习算法的学习过程就是优化调整参数,使得损失函数,或者说预测结果和实际结果的误差减小。BP算法其实是一个双向算法,包含两个步骤: 1.正向传递输入信息,得到 Loss 值。 2.反向传播误差,从而由优化算法来调整网络权值。 4.求解损失函数对某个权值的梯度 图片 其中$\mathrm{s_c=U^T\sigma(Wx_c+b),s=U^T\sigma(Wx+b)}$。一般可以把$\Delta$固定下来,比如设为1或者10。 对于上面的图, 假设图中指示出的网络中的某个权值 w$_\mathrm{jk}^\mathrm{l}$ 发生了一个小的改变 $\Delta w_\mathrm{jk}^\mathrm{l}$ , 假设网络最终损失函数的输出为$\mathbb{C}$,则 C 应该是关于 $\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 的一个复合函数。 所谓复合函数,就是把 $\mathbb{C}$ 看成因变量,则$\mathrm{w}_\mathrm{jk}^{\mathrm{l}}$ 可以看成导致 C 改变的自变量, 比如假设有一个复 合函数 $\mathrm{y=f(g(x))}$,则 y 就好比这里的$\mathbb{C}$ , x 就好比$\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}$, w$_{jk}^{\mathrm{l}}$ 每经过一层网络可以看成是经过某个函数的处理。而下面求写的时候都用偏导数, 是因为虽然我们这里只关注了一个 w$_\mathrm{jk}^{\mathrm{l}}$,但是实际上网络中的每一个 w 都可以看成一个 x。 显然,这个$\Delta w_\mathrm{jk}^\mathrm{l}$的变化会引起下一层直接与其相连的一个神经元,以及下一层之后所有神经元直到 最终输出 C 的变化, 如图中蓝线标记的就是该权值变化的影响传播路径。 把 C 的改变记为 $\Delta\mathbb{C}$, 则根据高等数学中导数的知识可以得到: 则神经元 a$_\mathrm{j}^1$ 下面一层第 q 个与其相连的神经元 a$_{\mathrm{q}}^{1+1}$ 的变化为: $$ \Delta\mathrm{a_q^{1+1}}\approx\frac{\partial\mathrm{a_q^{1+1}}}{\partial\mathrm{a_j^1}}\Delta\mathrm{a_j^1} $$将 $(2)$ 代入 (3) 可以得到: $$ \Delta\mathrm{a_{q}^{l+1}}\:\approx\:\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\:\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\:\Delta\mathrm{w_{jk}^{l}} $$假设从 $\mathrm{a_j}^1$ 到 C的一条路径为$\mathrm{a_j}^1,\mathrm{a_q}^{1+1},...,\mathrm{a_n}^{\mathrm{L-1}},\mathrm{a_m}^{\mathrm{L}}$,则在该条路径上 C 的变化量 $\Delta C$ 为: $$\Delta\mathrm{C}\approx\frac{\partial\mathrm{C}}{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}\frac{\partial\mathrm{a}_\mathrm{m}^\mathrm{L}}{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}\frac{\partial\mathrm{a}_\mathrm{n}^\mathrm{L-1}}{\partial\mathrm{a}_\mathrm{p}^\mathrm{L-2}}[USD3P]\frac{\partial\mathrm{a}_\mathrm{q}^\mathrm{l+1}}{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}\frac{\partial\mathrm{a}_\mathrm{j}^\mathrm{l}}{\partial\mathrm{w}_\mathrm{jk}^\mathrm{l}}\Delta\mathrm{w}_\mathrm{jk}^\mathrm{l}$$ 至此,我们已经得到了一条路径上的变化量, 其实本质就是链式求导法则,或者说是复合函数求导法则。那么整个的变化量就县把所有可能链路上的变化量加起来: $$\Delta\mathrm{C}\approx\sum_{\mathrm{minp[USD3P]q}}\frac{\partial\mathrm{C}}{\partial\mathrm{a_{m}^{L}}}\frac{\partial\mathrm{a_{m}^{L}}}{\partial\mathrm{a_{n}^{L-1}}}\frac{\partial\mathrm{a_{n}^{L-1}}}{\partial\mathrm{a_{p}^{L-2}}}[USD3P]\frac{\partial\mathrm{a_{q}^{l+1}}}{\partial\mathrm{a_{j}^{l}}}\frac{\partial\mathrm{a_{j}^{l}}}{\partial\mathrm{w_{jk}^{l}}}\Delta\mathrm{w_{jk}^{l}}$$ $$\begin{aligned}\text{则 C 对某个权值 w}_{\mathrm{jk}}^{\dagger}&\text{的梯度为:}\\&\frac{\partial\mathrm{C}}{\partial\mathrm{w}_{\mathrm{jk}}^{\dagger}}\approx\sum_{\mathrm{nmp},<0}\frac{\partial\mathrm{C}}{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}\frac{\partial\mathrm{a}_{\mathrm{m}}^{\mathrm{L}}}{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}\frac{\partial\mathrm{a}_{\mathrm{n}}^{\mathrm{L}-1}}{\partial\mathrm{a}_{\mathrm{p}}^{\mathrm{L}-2}}[USD3P]\frac{\partial\mathrm{a}_{\mathrm{q}}^{\mathrm{l}+1}}{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}\frac{\partial\mathrm{a}_{\mathrm{j}}^{\mathrm{l}}}{\partial\mathrm{w}_{\mathrm{jk}}^{\mathrm{l}}}\end{aligned}$$ 到这里从数学分析的角度来说,我们可以知道这个梯度是可以计算和求解的。 总结: 1.每两个神经元之间是由一条边连接的,这个边就是一个权重值,它是后一个神经元 z 部分,也就是未经激活函数非线性变换之前的结果对前一个神经元的 a 部分,也就是经激活函数非线性变换之后的结果的偏导数。 2.一条链路上所有偏导数的乘积就是这条路径的变化量。 3.所有路径变化量之和就是整个损失函数的变化量。 5.反向传播算法Backpropgation 5.1 明确一些定义 图片 对于上面的神经网络, 首先明确下面一些定义: 图片 5.2 计算一个梯度 假设损失函数为:J=(1+sc −s) 来计第一下 $\frac{\partial\mathrm{J}}{\partial\mathrm{W}_{14}^{(1)}}$,由于 s 是网络的输出, $\frac{\partial\mathrm{J}}{\partial\mathrm{s}}=-1$, 所以只需要计算$\frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}$ 即可。 而由于 s 激活函数就是1, 所以有: $$ \mathrm{s=a_1^{(3)}=z_1^{(3)}=W_{11}^{(2)}a_1^{(2)}+W_{12}^{(2)}a_2^{(2)}} $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial(\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}+\mathrm{W}_{12}^{(2)}\mathrm{a}_{2}^{(2)})}{\partial\mathrm{W}_{14}^{(1)}} $$图片 所以: $$\frac{\partial s}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{W}_{11}^{(2)}\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}$$ 由于图片代入公式(9)可以得到 $$\begin{gathered} \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{W}_{11}^{(2)}\frac{\partial\mathrm{a}_{1}^{(2)}}{\partial\mathrm{z}_{1}^{(2)}}\frac{\partial\mathrm{z}_{1}^{(2)}}{\partial\mathrm{W}_{14}^{(1)}1} \ =\operatorname{W}_{11}^{(2)}\mathfrak{\sigma}^{\prime}(\mathfrak{z}_{1}^{(2)})\frac{\partial(\mathfrak{b}_{1}^{(1)}+\sum_{\mathrm{k}}\mathfrak{a}_{\mathrm{k}}^{(1)}\mathfrak{W}_{1\text{k}} ^ { ( 1 ) })}{\partial\mathrm{W}_{14}^{(1)}} \end{gathered}$$ $$ \text{公式}(10)中\frac{\partial(\mathrm{h}_{1}^{(1)}+\sum_{k}a_{k}^{(1)}W_{1k}^{(1)})}{\partial\mathrm{W}_{14}^{(1)}}=\mathrm{a}_{4}^{(1)}。 $$此外还有一个更重要的变换, 同样的方法可以求出: $$ \frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}=\mathrm{W}_{11}^{(2)}\mathrm{\sigma}^{\prime}(\mathrm{z}_1^{(2)}) $$$$ \frac{\partial\mathrm{s}}{\partial\mathrm{W}_{14}^{(1)}}=\frac{\partial\mathrm{J}}{\partial\mathrm{z}_1^{(2)}}\mathrm{a}_4^{(1)}=\delta_1^{(2)}\mathrm{a}_4^{(1)} $$并且结合前面对 $\delta_\mathrm{j}^{(\mathrm{k})}$ 的定义,公式 (10) 可以写成: 所以损失函数对任离一个网络权伯的梯度可以弓成两个值相乘的形式。对于$\mathrm{a}_4^{(1)}$,它是网络前向传递过程中的一个神经元的输出, 我们当然可以在网络前向传递的时候将它保存下来。而对于 $\delta_1^{(2)}$,它是反向传播过来的梯度,也就是 J 对 z 的梯度, 下面来者如何通过后面神经元的 $\delta_{\mathrm{i}}^{(\mathrm{k})}$ 反向传播得到 前一个神经元处的 $\delta_\mathrm{j}^{(k-1)}$ 。 5.3 反向传播误差 到这里需要注意,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,可以使用比如随机梯度下降算法等来进行学习。 反向传播算法传播的是误差,传播方向是从最后一层依次往前,这是一个迭代的过程。在上面的过程中,我们求得了损失函数对于某个权值的梯度,通过该处的梯度值,可以将其向前传播,得到前一个结点的梯度。 图片 $(k-1)$ 例如对于上面的图, 假设已经求出 z$^{(\mathrm{k})}$ 处的柠伊卡$^{(\mathrm{k})}$,则行误差仅照某杀连接路径, 传递到 $\mathrm{a_j}^{[\mathrm{l}]}$ per 处,则该处的梯度为$\delta_{\mathrm{i}}^{(\mathrm{k})}W_{\mathrm{ij}}^{(\mathrm{k}-1)}$。实际上这只是一条路径, $\mathrm{a_j}^{(\mathrm{k-1})}$处可能会收到很多个不同的误差, 例如下面该神经元后面有两条权值 边的情况: 图片 这个时候只要把它们相加就好了,所以 a$_{\mathrm{j}}^{(\mathrm{k}-1)}$处,则该处的梯度为$\sum_{\mathrm{i}}\delta_{\mathrm{i}}^{(\mathrm{k})}\mathrm{W}_{\mathrm{ij}}^{(\mathrm{k}-1)}$。 图片 6.优化示例 再次说一下,反向传播仅指用于计算梯度的方法,它并不是用于神经网络的整个学习算法。通过反向传播算法算法得到梯度之后,还需要使用比如随机梯度下降算法等来进行学习。 在上面的过程中, 我们通过反向传播弹法求解出了任意一个$z_j^{(\mathrm{i})}$处的梯度$\delta_j^{(\mathrm{i})}$,为什么是$z_j^{(\mathrm{i})}$而不是$a_j^{(\mathrm{i})}$,因为$z_j^{(\mathrm{i})}$前面就是连接它的w,以随机梯度下降算法为例,w的优化方法为: $$\mathrm{w_{ijnew}^{(1)}=w_{ijold}^{(1)}-\eta\cdot\frac{\partial J}{\partial w_{ij}^{(1)}}=w_{ijold}^{(1)}-\eta\cdot\delta_{i}^{(1+1)}\cdot a_{j}^{(1)}}$$
机器学习
# DL/ML
刘航宇
3年前
0
580
2
上一页
1
2
3
...
26
下一页