首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,213 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,162 阅读
3
【高数】形心计算公式讲解大全
8,765 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,461 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,854 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
嵌入式&系统(共66篇)
找到
66
篇与
嵌入式&系统
相关的结果
2024-07-05
Linux之不使用命令删除文件中的第N行
1.问题描述 2. 解题思路: 3. 代码实现: 1.问题描述 设计一个程序,通过命令行参数接收一个文件名 filename.txt (纯文本文件)和一个整型数字 n,实现从 filename.txt 中删除第 n 行数据。 2. 解题思路: (1) 借助临时文件: 将文件逐行读取,跳过要删除的行,并将其写入临时文件,然后删除源文件,重命名临时文件为源文件,完成删除指定行数据。 (2) 不借助临时文件: 将文件以读写方式打开,读取到要删除行后,通过移动文件指针将文件后面所有行前移一行,但是最后一行会重复,可以通过截断文件操作完成在源文件上删除指定行数据。 (3) 通过sed 或 awk 删除文件指定行 3. 代码实现: (1) 通过 fopen 打开文件借助临时文件删除指定行数据 #filename:ques_15a.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如exit int main(int argc, char *argv[]) { // 检查命令行参数的数量是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 如果不正确,打印用法信息并退出 } char buf[4096]; // 定义一个足够大的字符数组用于读取文件行 int linenum = atoi(argv[2]); // 将命令行参数中的行号转换为整数 FILE *fp = fopen(argv[1], "r"); // 尝试以只读模式打开源文件 FILE *fpt = fopen("temp.txt", "w"); // 创建一个临时文件用于写入 // 如果源文件无法打开,打印错误信息并退出 if (!fp) { printf("File %s not exist!\n", argv[1]); exit(EXIT_FAILURE); } // 检查是否有权限修改源文件 char str[100]; sprintf(str, "%s%s", "test -w ", argv[1]); if (system(str)) { // 如果没有写权限 printf("Can't modify file %s, permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打印错误信息并退出 } int total_line = 0; // 初始化文件总行数计数器 while (fgets(buf, sizeof(buf), fp)) { // 读取文件的每一行 total_line++; } fseek(fp, 0, SEEK_SET); // 将文件指针重置到文件的开头 // 如果要删除的行数大于文件的总行数,打印错误信息并退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int i = 0; // 初始化当前行计数器 while (fgets(buf, sizeof(buf), fp)) { // 再次读取文件的每一行 i++; // 当前行数加1 if (i != linenum) { // 如果当前行不是要删除的行 fputs(buf, fpt); // 将当前行写入临时文件 } } remove(argv[1]); // 删除原始文件 rename("temp.txt", argv[1]); // 将临时文件重命名为原始文件名 // 关闭文件指针 fclose(fp); fclose(fpt); return 0; // 程序正常退出 }(2) 通过 Linux 系统调用 open 打开文件,需要自定义读取一行的函数,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,比如atoi和exit #include <string.h> // 包含字符串操作函数,比如strlen #include <fcntl.h> // 包含文件控制的定义 #include <sys/stat.h> // 包含文件状态的定义 #include <sys/types.h>// 包含各种数据类型 #include <unistd.h> // 包含UNIX标准函数定义 // 函数声明:读取一行文件内容到缓冲区 int readline(int fd, char *buf) { int t = 0; // 用于记录读取的字符数 // 循环读取直到遇到换行符 for (; ;) { read(fd, &buf[t], 1); // 从文件描述符fd读取一个字符到buf t++; // 增加读取的字符数 if (buf[t-1] == '\n') { // 如果读取到换行符 break; // 退出循环 } } return t; // 返回读取的字符数 } // 函数声明:获取文件的大小和行数 int get_file_info(int fd, int *size) { int num = 0; // 记录行数 char ch; // 临时变量用于存储读取的字符 // 循环读取直到文件结束 while (read(fd, &ch, 1) > 0) { (*size)++; // 文件大小加1 if (ch == '\n') { // 如果读取到换行符 num++; // 行数加1 } } return num; // 返回行数 } int main(int argc, char *argv[]) { // 检查命令行参数数量 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出 } int fd; // 文件描述符 char buf[4096]; // 缓冲区 int linenum = atoi(argv[2]); // 将命令行参数转换为整数 // 尝试以读写模式打开文件 fd = open(argv[1], O_RDWR); if (fd < 0) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); // 打开失败时退出 } int size = 0; // 文件大小 // 获取文件的行数和大小 int total_line = get_file_info(fd, &size); // 如果要删除的行数大于文件总行数,退出 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 要删除行的大小 int t = 0; // 当前行的大小 int i = 0; // 当前行数 lseek(fd, 0, SEEK_SET); // 将文件指针移到文件头 // 循环读取文件,直到文件结束 while (read(fd, &buf[0], 1) > 0) { lseek(fd, -1, SEEK_CUR); // 回退一个字符 memset(buf, 0, sizeof(buf)); // 清空缓冲区 readline(fd, buf); // 读取一行到缓冲区 i++; // 行数加1 t = strlen(buf); // 当前行的大小 // 如果当前行是目标行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在目标行之后,将该行前移 if (i > linenum) { lseek(fd, -(s+t), SEEK_CUR); // 移动文件指针 write(fd, buf, strlen(buf)); // 写入当前行 lseek(fd, s, SEEK_CUR); // 移动文件指针 } } ftruncate(fd, size-s); // 截断文件,删除指定行 close(fd); // 关闭文件描述符 return 0; // 正常退出 }(3) 通过 fopen 打开文件,不借助临时文件删除指定行数据 # filename:ques_15b.c #include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含标准库函数,如atoi和exit #include <string.h> // 包含字符串处理函数,如strlen #include <math.h> // 包含数学函数,虽然在这个程序中没有使用 #include <unistd.h> // 包含UNIX标准函数,如truncate int main(int argc, char *argv[]) { // 检查命令行参数个数是否正确 if (argc != 3) { printf("Usage: ./a.out filename num\n"); exit(EXIT_FAILURE); // 参数不正确时退出程序 } int linenum = atoi(argv[2]); // 将命令行中指定的行号转换为整数 char buf[4096]; // 定义缓冲区,用于读取文件内容 // 尝试以读写模式打开文件 FILE *fp = fopen(argv[1], "r+"); // 如果文件无法打开,打印错误信息并退出程序 if (!fp) { printf("Can't open file %s, file not exist or permission denied!\n", argv[1]); exit(EXIT_FAILURE); } int total_line = 0; // 记录文件的总行数 int size = 0; // 记录文件的总大小 // 循环读取文件直到文件末尾,计算总行数和总大小 while (fgets(buf, sizeof(buf), fp)) { size += strlen(buf); // 累加每行的长度 total_line++; // 行数加1 } // 如果要删除的行数大于文件的总行数,打印错误信息并退出程序 if (linenum > total_line) { printf("%d is greater than total_line!\n", linenum); exit(EXIT_FAILURE); } int s = 0; // 记录要删除的行的大小 int t = 0; // 记录当前读取行的大小 int i = 0; // 记录当前行数 fseek(fp, 0L, SEEK_SET); // 将文件指针重置到文件开头 // 再次循环读取文件,准备删除指定行 while (fgets(buf, sizeof(buf), fp)) { i++; // 当前行数加1 t = strlen(buf); // 当前行的长度 // 如果当前行是要删除的行,记录其大小 if (i == linenum) { s = t; } // 如果当前行在要删除的行之后,将其前移 if (i > linenum) { fseek(fp, -(s+t), SEEK_CUR); // 将文件指针移动到正确的位置 fputs(buf, fp); // 写入当前行 fseek(fp, s, SEEK_CUR); // 将文件指针向前移动s个字节 } } // 截断文件,删除指定行 truncate(argv[1], size-s); // 关闭文件指针 fclose(fp); return 0; // 正常退出程序 }(4) 这三个删除文件指定行的函数都需借助临时文件完成
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
362
1
2024-06-27
基础概念:中断、任务、进程、线程、RTOS、Linux
中断 任务 进程 线程 它们之间的区别 RTOS和Linux的区别 中断、任务、进程和线程是计算机科学和操作系统中的基本概念,它们在多任务操作和资源管理中扮演着重要的角色。下面是这些概念的简要解释以及它们之间的区别: 中断 中断是硬件或软件发出的信号,用来通知CPU暂停当前的工作,转而去执行一个特殊的程序(中断处理程序)。中断可以是外部的,比如来自硬件设备的信号,或者是内部的,比如软件生成的信号。中断机制允许操作系统响应外部事件,如用户输入或硬件状态变化。 任务 在某些操作系统中,任务是一个抽象概念,用来表示一个执行单元,它可以是一个进程或者线程。任务通常指的是需要操作系统调度和资源管理的执行流。 进程 进程是操作系统分配资源和调度的基本单位。每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程状态和执行的资源。进程可以包含一个或多个线程。 线程 线程是进程中的一个实体,是CPU调度和执行的单位。线程共享所属进程的资源,但拥有自己的堆栈和程序计数器。线程比进程更轻量级,创建和切换的开销更小。 它们之间的区别 资源分配:进程是资源分配的最小单位,线程则不是。 执行:进程是执行程序的实例,线程是进程中的实际执行流。 地址空间:进程有独立的地址空间,线程共享进程的地址空间。 创建开销:进程的创建开销通常大于线程。 通信:线程间可以通过共享内存进行通信,进程间通信需要使用IPC(进程间通信)机制。 RTOS和Linux的区别 RTOS(实时操作系统)和Linux是两种不同类型的操作系统,它们在设计目标和特性上有所区别: 设计目标: RTOS:设计用于需要快速、可预测响应的系统,如嵌入式系统、工业控制等。 Linux:是一个通用操作系统,主要用于桌面、服务器、移动设备等。 实时性: RTOS:提供确定的响应时间,可以保证任务在指定的时间内得到处理。 Linux:虽然可以配置为实时系统,但通常不具备RTOS的严格实时性。 调度策略: RTOS:通常使用基于优先级的抢占式调度。 Linux:使用完全公平调度器(CFS)进行调度,可以配置为实时调度。 内存管理: RTOS:通常有简单的内存管理机制,适合资源受限的环境。 Linux:具有复杂的内存管理机制,支持虚拟内存和内存共享。 应用场景: RTOS:适用于对实时性要求高、资源受限的场合。 Linux:适用于需要高度灵活性和扩展性的场合。 开源和社区支持: RTOS:有些RTOS是开源的,但社区规模通常小于Linux。 Linux:是一个开源项目,拥有庞大的社区和开发者支持。 总的来说,RTOS和Linux各有优势,选择哪个系统取决于应用的具体需求。RTOS适合对实时性要求极高的场景,而Linux适合需要高度灵活性和功能丰富的环境。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
779
1
Socket通信-Linux系统中C语言实现TCP/UDP图片和文件传输
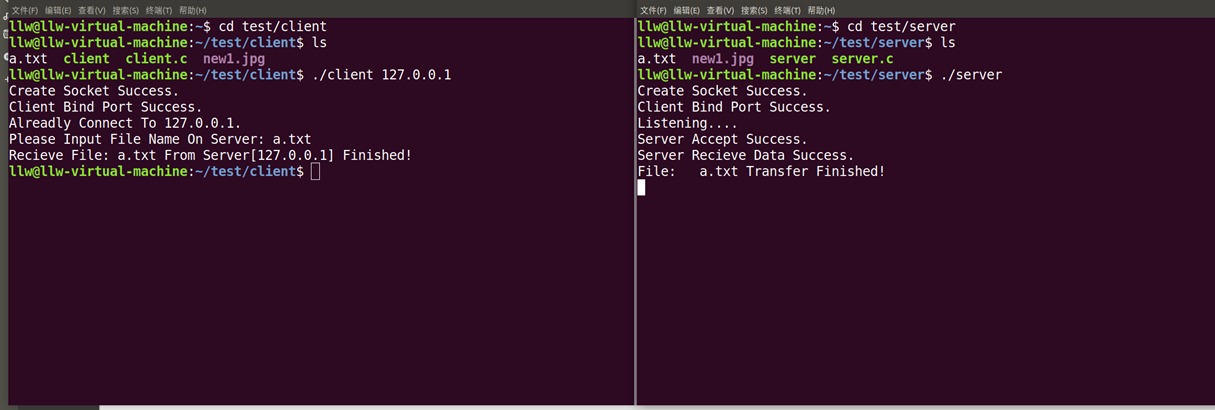
TCP实现1.服务端 2.客户端 二、UDP实现1.服务端 2.客户端 TCP实现 传输控制协议(TCP,Transmission Control Protocol) 是为了在不可靠的互联网络上提供可靠的端到端字节流而专门设计的一个传输协议。TCP是因特网中的传输层协议,使用三次握手协议建立连接。当主动方发出SYN连接请求后,等待对方回答SYN+ACK,并最终对对方的 SYN 执行 ACK 确认。这种建立连接的方法可以防止产生错误的连接,TCP使用的流量控制协议是可变大小的滑动窗口协议。 1.服务端 基于TCP协议的socket的server端程序编程步骤: 1、建立socket ,使用socket() 2、绑定socket ,使用bind() 3、打开listening socket,使用listen() 4、等待client连接请求,使用accept() 5、收到连接请求,确定连接成功后,使用输入,输出函数recv(),send()与client端互传信息 6、关闭socket,使用close() 服务端代码server.c /*server.c*/ #include<netinet/in.h> #include<sys/types.h> #include<sys/socket.h> #include<stdio.h> #include<stdlib.h> #include<string.h> #define SERVER_PORT 5678 //端口号 #define LENGTH_OF_LISTEN_QUEUE 20 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { // 设置一个socket地址结构server_addr,代表服务器ip地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htons(INADDR_ANY); server_addr.sin_port = htons(SERVER_PORT); // 创建用于流协议(TCP)socket,用server_socket代表服务器向客户端提供服务的接口 int server_socket = socket(PF_INET, SOCK_STREAM, 0); if (server_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把socket和socket地址结构绑定 if (bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr))) { printf("Server Bind Port: %d Failed!\n", SERVER_PORT); exit(1); } else printf("Client Bind Port Success.\n"); // server_socket用于监听 if (listen(server_socket, LENGTH_OF_LISTEN_QUEUE)) { printf("Server Listen Failed!\n"); exit(1); } else printf("Listening....\n"); // 服务器始终监听 while(1) { // 定义客户端的socket地址结构client_addr,当收到来自客户端的请求后,调用accept // 接受此请求,同时将client端的地址和端口等信息写入client_addr中 struct sockaddr_in client_addr; socklen_t length = sizeof(client_addr); // 接受一个从client端到达server端的连接请求,将客户端的信息保存在client_addr中 // 如果没有连接请求,则一直等待直到有连接请求为止,这是accept函数的特性 // accpet返回一个新的socket,这个socket用来与此次连接到server的client进行通信 // 这里的new_server_socket代表了这个通信通道 int new_server_socket = accept(server_socket, (struct sockaddr*)&client_addr, &length); if (new_server_socket < 0) { printf("Server Accept Failed!\n"); break; } else printf("Server Accept Success.\n"); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); length = recv(new_server_socket, buffer, BUFFER_SIZE, 0); if (length < 0) { printf("Server Recieve Data Failed!\n"); break; } else printf("Server Recieve Data Success.\n"); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); strncpy(file_name, buffer, strlen(buffer) > FILE_NAME_MAX_SIZE ? FILE_NAME_MAX_SIZE : strlen(buffer)); FILE *fp = fopen(file_name, "r"); //获取文件操作符 if (fp == NULL) { printf("File:\t%s Not Found!\n", file_name); } else { bzero(buffer, BUFFER_SIZE); int file_block_length = 0; while( (file_block_length = fread(buffer, sizeof(char), BUFFER_SIZE, fp)) > 0) { // 发送buffer中的字符串到new_server_socket,实际上就是发送给客户端 if (send(new_server_socket, buffer, file_block_length, 0) < 0) { printf("Send File:\t%s Failed!\n", file_name); break; } bzero(buffer, sizeof(buffer)); } fclose(fp); printf("File:\t%s Transfer Finished!\n", file_name); } close(new_server_socket); } close(server_socket); return 0; } 2.客户端 基于TCP协议的socket的Client程序编程步骤: 1、建立socket,使用socket() 2、通知server请求连接,使用connect() 3、若连接成功,就使用输入输出函数recv(),send()与server互传信息 4、关闭socket,使用close() 客户端代码client.c /*client.c*/ #include<netinet/in.h> // for sockaddr_in #include<sys/types.h> // for socket #include<sys/socket.h> // for socket #include<stdio.h> // for printf #include<stdlib.h> // for exit #include<string.h> // for bzero #define SERVER_PORT 5678 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { if (argc != 2) //判断有没有输入服务器ip { printf("Usage: ./%s ServerIPAddress\n", argv[0]); exit(1); } // 设置一个socket地址结构client_addr, 代表客户机的ip地址和端口 struct sockaddr_in client_addr; bzero(&client_addr, sizeof(client_addr)); client_addr.sin_family = AF_INET; // internet协议族IPv4 client_addr.sin_addr.s_addr = htons(INADDR_ANY); // INADDR_ANY表示自动获取本机地址 client_addr.sin_port = htons(0); // auto allocated, 让系统自动分配一个空闲端口 // 创建用于internet的流协议(TCP)类型socket,用client_socket代表客户端socket int client_socket = socket(AF_INET, SOCK_STREAM, 0); if (client_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把客户端的socket和客户端的socket地址结构绑定 if (bind(client_socket, (struct sockaddr*)&client_addr, sizeof(client_addr))) { printf("Client Bind Port Failed!\n"); exit(1); } else printf("Client Bind Port Success.\n"); // 设置一个socket地址结构server_addr,代表服务器的internet地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; // 服务器的IP地址来自程序的参数 if (inet_aton(argv[1], &server_addr.sin_addr) == 0) { printf("Server IP Address Error!\n"); exit(1); } server_addr.sin_port = htons(SERVER_PORT); int server_addr_length = sizeof(server_addr); // 向服务器发起连接请求,连接成功后client_socket代表客户端和服务器端的一个socket连接 if (connect(client_socket, (struct sockaddr*)&server_addr, server_addr_length) < 0) { printf("Can Not Connect To %s!\n", argv[1]); exit(1); } else printf("Alreadly Connect To %s.\n", argv[1]); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); printf("Please Input File Name On Server: "); scanf("%s", file_name); char buffer[BUFFER_SIZE];//缓存区 bzero(buffer, sizeof(buffer)); strncpy(buffer, file_name, strlen(file_name) > BUFFER_SIZE ? BUFFER_SIZE : strlen(file_name)); // 向服务器发送buffer中的数据,此时buffer中存放的是客户端需要接收的文件的名字 send(client_socket, buffer, BUFFER_SIZE, 0); // send , sendto(), recv(),recvfrom() FILE *fp = fopen(file_name, "w"); if (fp == NULL) { printf("File: %s Can Not Open To Write!\n", file_name); exit(1); } // 从服务器端接收数据到buffer中 bzero(buffer, sizeof(buffer)); int length = 0; while(length = recv(client_socket, buffer, BUFFER_SIZE, 0)) { if (length < 0) { printf("Recieve Data From Server %s Failed!\n", argv[1]); break; } int write_length = fwrite(buffer, sizeof(char), length, fp); if (write_length < length) { printf("File:\t%s Write Failed!\n", file_name); break; } bzero(buffer, BUFFER_SIZE); } printf("Recieve File: %s From Server[%s] Finished!\n", file_name, argv[1]); // 传输完毕,关闭socket fclose(fp); close(client_socket); return 0; } 如图,客户端(左)从服务端(右)下载文件/图片: 图片 二、UDP实现 UDP(User Datagram Protocol) 全称是用户数据报协议,是一种非面向连接的协议,这种协议并不能保证我们的网络程序的连接是可靠的。 1.服务端 基于UDP协议的socket的server编程步骤: 1、建立socket,使用socket() 2、绑定socket,使用bind() 3、以recvfrom()函数接收发送端传来的数据(使用recvfrom函数 时需设置非阻塞,以免程序卡在此处) 4、关闭socket,使用close() /*server.c*/ #include<netinet/in.h> #include<sys/types.h> #include<sys/socket.h> #include<stdio.h> #include<stdlib.h> #include<string.h> #define SERVER_PORT 5678 //端口号 #define LENGTH_OF_LISTEN_QUEUE 20 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { // 设置一个socket地址结构server_addr,代表服务器internet的地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htons(INADDR_ANY); server_addr.sin_port = htons(SERVER_PORT); // create a stream socket // 创建用于internet的流协议(UDP)socket,用server_socket代表服务器向客户端提供服务的接口 int server_socket = socket(PF_INET, SOCK_DGRAM, 0); if (server_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } else printf("Create Socket Success.\n"); // 把socket和socket地址结构绑定 if (bind(server_socket, (struct sockaddr*)&server_addr, sizeof(server_addr))) { printf("Server Bind Port: %d Failed!\n", SERVER_PORT); exit(1); } else printf("Server Bind Port Success.\n"); printf("Waiting......\n"); // 服务器端一直运行用以持续为客户端提供服务 while(1) { // 接受此请求,同时将client端的地址和端口等信息写入client_addr中 struct sockaddr_in client_addr; int length = 0; int addrlen = sizeof(client_addr); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); length = recvfrom(server_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&client_addr,&addrlen); if (length < 0) { printf("Server Recieve Data Failed!\n"); break; } char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); strncpy(file_name, buffer, strlen(buffer) > FILE_NAME_MAX_SIZE ? FILE_NAME_MAX_SIZE : strlen(buffer)); FILE *fp = fopen(file_name, "r"); if (fp == NULL) { printf("File:\t%s Not Found!\n", file_name); } else { bzero(buffer, BUFFER_SIZE); int file_block_length = 0; while( (file_block_length = fread(buffer, sizeof(char), BUFFER_SIZE, fp)) > 0) { // 发送buffer中的字符串到server_socket,实际上就是发送给客户端 if (sendto(server_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&client_addr,addrlen) < 0) { printf("Send File:\t%s Failed!\n", file_name); break; } bzero(buffer, sizeof(buffer)); } fclose(fp); printf("File:\t%s Transfer Finished!\n", file_name); } } close(server_socket); return 0; }2.客户端 基于UDP协议的socket的client端编程步骤: 1、建立Socket,使socket() 2、用sendto()函数向接收端发送数据。 3、关闭socket,使用close()函数 /*client.c*/ #include<netinet/in.h> // for sockaddr_in #include<sys/types.h> // for socket #include<sys/socket.h> // for socket #include<stdio.h> // for printf #include<stdlib.h> // for exit #include<string.h> // for bzero #include <fcntl.h> #include <unistd.h> #include <sys/time.h> #define SERVER_PORT 5678 #define BUFFER_SIZE 1024 #define FILE_NAME_MAX_SIZE 512 int main(int argc, char **argv) { if (argc != 2) { printf("Usage: ./%s ServerIPAddress\n", argv[0]); exit(1); } // 设置一个socket地址结构client_addr, 代表客户机的internet地址和端口 struct sockaddr_in client_addr; bzero(&client_addr, sizeof(client_addr)); client_addr.sin_family = AF_INET; // internet协议族 client_addr.sin_addr.s_addr = htons(INADDR_ANY); // INADDR_ANY表示自动获取本机地址 client_addr.sin_port = htons(0); // auto allocated, 让系统自动分配一个空闲端口 // 创建用于internet的流协议(TCP)类型socket,用client_socket代表客户端socket int client_socket = socket(AF_INET, SOCK_DGRAM, 0); if (client_socket < 0) { printf("Create Socket Failed!\n"); exit(1); } // 设置超时,防止recvfrom()函数阻塞 struct timeval timeout; timeout.tv_sec = 1;//秒 timeout.tv_usec = 0;//微秒 if (setsockopt(client_socket, SOL_SOCKET, SO_RCVTIMEO, &timeout, sizeof(timeout)) == -1) { perror("setsockopt failed:"); } // 把客户端的socket和客户端的socket地址结构绑定 if (bind(client_socket, (struct sockaddr*)&client_addr, sizeof(client_addr))) { printf("Client Bind Port Failed!\n"); exit(1); } // 设置一个socket地址结构server_addr,代表服务器的internet地址和端口 struct sockaddr_in server_addr; bzero(&server_addr, sizeof(server_addr)); server_addr.sin_family = AF_INET; // 服务器的IP地址来自程序的参数 if (inet_aton(argv[1], &server_addr.sin_addr) == 0) { printf("Server IP Address Error!\n"); exit(1); } server_addr.sin_port = htons(SERVER_PORT); int server_addr_length = sizeof(server_addr); char file_name[FILE_NAME_MAX_SIZE + 1]; bzero(file_name, sizeof(file_name)); printf("Please Input File Name On Server: "); scanf("%s", file_name); char buffer[BUFFER_SIZE]; bzero(buffer, sizeof(buffer)); strncpy(buffer, file_name, strlen(file_name) > BUFFER_SIZE ? BUFFER_SIZE : strlen(file_name)); // 向服务器发送buffer中的数据,此时buffer中存放的是客户端需要接收的文件的名字 if( sendto(client_socket, buffer, BUFFER_SIZE, 0,(struct sockaddr *)&server_addr,server_addr_length) ) printf("Waiting receive %s from server....\n",file_name); FILE *fp = fopen(file_name, "w"); if (fp == NULL) { printf("File:\t%s Can Not Open To Write!\n", file_name); exit(1); } // 从服务器端接收数据到buffer中 bzero(buffer, sizeof(buffer)); int length = 0; //length = recvfrom(client_socket, buffer, BUFFER_SIZE, 0, (struct sockaddr*)&server_addr, &server_addr_length)//非阻塞 while( length = recvfrom(client_socket, buffer, BUFFER_SIZE, 0, (struct sockaddr*)&server_addr, &server_addr_length)) { if (length < 0) { //printf("Recieve Data From Server %s Failed!\n", argv[1]); break; } int write_length = fwrite(buffer, sizeof(char), length, fp); if (write_length < length) { printf("File: %s Write Failed!\n", file_name); break; } bzero(buffer, BUFFER_SIZE); } printf("Receive File: %s From Server[%s] Finished!\n", file_name, argv[1]); // 传输完毕,关闭socket fclose(fp); close(client_socket); return 0; } 如图,客户端(左)从服务端(右)下载文件/图片: 图片 注:使用recvfrom函数 时需设置非阻塞,以免程序卡住。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
625
0
2024-01-11
嵌入式常见知识点
图片 1、线程、进程的区别?最小执行单元是进程还是线程? 2、如何计算一个整数是不是2的n次方? 3、printf的具体实现? 4、什么是大小端?如何区分?有几种方法? 5、new与malloc的区别? 6、程序链接完毕之后分几部分? 7、Linux、Windows与FreeRtos的区别? 8、Linux系统中的中断为什么分为上下两个部分? 9、会快速排序吗?简要说一下? 10、static关键字的作用? 11、extern 关键字的作用? 12、volatile关键字的作用? 13、编译原理分哪几步? 14、内存分区? 15、freertos启动流程? 16、互斥锁与信号量的区别? 17、什么是死锁?死锁产生的原因?如何避免? 18、什么是内存泄漏? 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 21、freertos中EventBits_t是干啥的? 22、freertos使任务切换的方式有哪些? 23、项目中用到网络了吗? 24、了解Socket吗? 25、c++中set是什么? 26、有没有用到C++模板? 27、有没有对代码裁剪的经验 28、freertos系统是买模块时人家配置好的?还是移植的? 29、任务里有两把锁的时候该怎么处理 30、熟悉Shell脚本吗?$和#啥意思? 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。31、知道#error吗? 32、freertos消息队列的的具体实现? 33、堆栈区别? 34、程序存放状态和区别 1、线程、进程的区别?最小执行单元是进程还是线程? 线程和进程都是程序的执行实体,但是它们有以下区别: 进程是操作系统分配资源的基本单位,每个进程都有自己的独立的地址空间,代码段,数据段,堆栈段等。进程之间的切换需要保存和恢复上下文,开销较大。 线程是操作系统调度的基本单位,每个线程都属于某个进程,一个进程可以有多个线程,它们共享进程的地址空间,但是有自己的栈和寄存器。线程之间的切换只需要保存和恢复少量的寄存器,开销较小。 最小的执行单元是线程,因为一个进程至少要有一个线程,而一个线程可以独立运行。 2、如何计算一个整数是不是2的n次方? 一个整数是2的n次方,当且仅当它的二进制表示中只有一个1,其余都是0。例如,23=8=(1000)2 ,只有一个1。所以,我们可以用以下的方法来判断一个整数x是否是2的n次方: 如果x小于等于0,那么它不是2的n次方。 如果x大于0,那么我们可以用位运算的技巧,将x与x-1做按位与,如果结果为0,那么x是2的n次方,否则不是。例如,8&(8−1)=8&7=(1000)2&(0111)2=(0000)2=0 ,所以8是2的n次方。而9&(9−1)=9&8=(1001)2&(1000)2=(1000)2=0 ,所以9不是2的n次方。 3、printf的具体实现? printf是C语言中的一个标准库函数,用于向标准输出流(通常是屏幕)打印格式化的字符串。它的具体实现可能因编译器和操作系统的不同而有所差异,但是一般来说,它的主要步骤如下: 首先,printf会解析第一个参数,也就是格式化字符串,根据其中的转换说明符(如%d, %f, %s等),确定需要打印的数据类型和格式。 然后,printf会从第二个参数开始,依次获取对应的数据,并将其转换为字符串,拼接到格式化字符串的相应位置。如果参数的个数和类型与格式化字符串不匹配,可能会导致错误或未定义的行为。 最后,printf会调用底层的系统函数,将拼接好的字符串写入到标准输出流中,并返回成功写入的字符数。如果发生错误,返回负值。 4、什么是大小端?如何区分?有几种方法? 大小端是指数据在内存中的存储顺序,大端表示高位字节存放在低地址,低位字节存放在高地址,小端表示高位字节存放在高地址,低位字节存放在低地址。例如,一个32位的整数0x12345678,在大端模式下,存储为0x12 0x34 0x56 0x78,而在小端模式下,存储为0x78 0x56 0x34 0x12。 区分大小端的方法有以下几种: 通过联合体(union)的方式,将一个整数和一个字符数组放在同一个联合体中,然后判断字符数组的第一个元素是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过指针的方式,将一个整数的地址赋给一个字符指针,然后判断指针指向的内容是不是整数的最低字节,如果是,说明是小端,否则是大端。 通过位运算的方式,将一个整数右移24位,然后与0xFF做按位与,得到的结果是不是整数的最高字节,如果是,说明是大端,否则是小端。 5、new与malloc的区别? new和malloc都是用于动态分配内存的,但是它们有以下区别: new是C++中的运算符,malloc是C语言中的函数,它们的用法不同。new可以直接分配对象,而malloc只能分配字节,需要强制类型转换。 new会调用对象的构造函数,初始化对象,而malloc只是分配原始的内存空间,不做任何初始化。 new会根据对象的类型,自动计算所需的内存大小,而malloc需要手动指定分配的字节数。 new分配失败时,会抛出异常,而malloc分配失败时,会返回NULL指针。 new对应的释放内存的运算符是delete,而malloc对应的释放内存的函数是free。 6、程序链接完毕之后分几部分? 程序链接完毕之后,一般分为以下几个部分: 代码段(text segment),存放程序的指令和常量。 数据段(data segment),存放程序的全局变量和静态变量。 堆(heap),存放程序动态分配的内存空间。 栈(stack),存放程序的局部变量,函数参数,返回地址等。 BSS段(bss segment),存放程序未初始化的全局变量和静态变量。 7、Linux、Windows与FreeRtos的区别? Linux、Windows和FreeRtos都是操作系统,但是它们有以下区别: Linux是一个开源的,基于Unix的,多用户,多任务,支持多种硬件平台的操作系统,它有很多不同的发行版,如Ubuntu,RedHat,Debian等。Linux适合用于服务器,嵌入式系统,桌面系统等。 Windows是一个闭源的,基于NT内核的,多用户,多任务,主要支持x86和x64架构的操作系统,它有很多不同的版本,如Windows 10,Windows Server,Windows CE等。Windows适合用于桌面系统,移动设备,游戏机等。 FreeRtos是一个开源的,基于微内核的,实时,多任务,支持多种嵌入式平台的操作系统,它有很多不同的移植,如ARM,MIPS,AVR等。FreeRtos适合用于实时控制,物联网,低功耗设备等。 8、Linux系统中的中断为什么分为上下两个部分? Linux系统中的中断为了提高效率和响应时间,分为上半部(top half)和下半部(bottom half)。上半部是指中断处理程序(interrupt handler),它负责处理中断的紧急事务,如保存寄存器,清除中断标志,识别中断源等。下半部是指中断延迟服务程序(interrupt deferred service routine),它负责处理中断的非紧急事务,如数据传输,设备驱动,信号发送等。上半部和下半部的区别如下: 上半部在中断上下文中执行,下半部在进程上下文中执行。 上半部不能被其他中断打断,下半部可以被其他中断打断。 上半部不能睡眠,下半部可以睡眠。 上半部不能调用可能导致阻塞的函数,如malloc,copy_to_user等,下半部可以调用这些函数。 上半部的执行时间应该尽可能短,下半部的执行时间可以较长。 9、会快速排序吗?简要说一下? 快速排序是一种基于分治思想的排序算法,它的基本步骤如下: 从待排序的数组中选择一个元素作为基准(pivot),通常选择第一个或者最后一个元素。 将数组分成两个子数组,一个子数组中的元素都小于或等于基准,另一个子数组中的元素都大于基准,这个过程称为划分(partition)。 对两个子数组递归地进行快速排序,直到子数组的长度为1或0。 将排好序的子数组合并,得到最终的排序结果。 快速排序的平均时间复杂度是O(nlogn) ,最坏情况是O(n^2) ,空间复杂度是O(logn) ,它是一种不稳定的排序算法。 10、static关键字的作用? static是一个修饰符,它可以用于变量和函数,它有以下作用: 用于全局变量,表示该变量只能在本文件中访问,不能被其他文件引用,这样可以避免命名冲突。 用于局部变量,表示该变量的生命周期是整个程序,而不是函数调用结束,这样可以保持变量的值不被销毁。 用于函数,表示该函数只能在本文件中调用,不能被其他文件引用,这样可以提高函数的封装性和安全性。 11、extern 关键字的作用? extern是一个修饰符,它可以用于变量和函数,它有以下作用: 用于变量,表示该变量是在其他文件中定义的,需要在本文件中引用,这样可以避免重复定义。 用于函数,表示该函数是在其他文件中定义的,需要在本文件中声明,这样可以避免隐式声明。 12、volatile关键字的作用? volatile是一个修饰符,它可以用于变量,它有以下作用: 用于变量,表示该变量可能会被外部因素(如中断,多线程,硬件等)改变,需要每次都从内存中读取,而不是从寄存器或缓存中读取,这样可以保证变量的实时性和一致性。 用于变量,表示该变量不会被编译器优化,需要按照程序的顺序执行,而不是进行重排或删除,这样可以避免编译器的干扰。 13、编译原理分哪几步? 编译原理是指将一种高级语言(源语言)的程序转换为另一种低级语言(目标语言)的程序的原理和方法,它一般分为以下几个步骤: 词法分析(lexical analysis),将源程序的字符序列分割成有意义的单词(token)。 语法分析(syntax analysis),将单词序列组织成语法树(parse tree)或抽象语法树(abstract syntax tree),表示程序的结构和语义。 语义分析(semantic analysis),检查程序是否符合语言的语法规则和语义规则,如类型检查,作用域分析等。 中间代码生成(intermediate code generation),将抽象语法树转换为一种中间表示(intermediate representation),如三地址码,四元式,后缀表达式等,便于优化和目标代码生成。 代码优化(code optimization),对中间表示进行一些变换,以提高程序的执行效率,如常量折叠,公共子表达式消除,循环优化,死代码删除等。 目标代码生成(target code generation),将中间表示转换为目标语言的代码,如汇编语言,机器语言等,同时进行一些分配,如寄存器分配,指令选择等。 14、内存分区? 内存分区是指将物理内存划分为若干个逻辑区域,以便于管理和使用。内存分区的方式有以下几种: 固定分区,将内存分为大小相等或不等的若干个区域,每个区域只能装入一个进程,如果进程的大小超过区域的大小,就会产生内部碎片。 动态分区,根据进程的大小和数量,动态地分配和回收内存空间,每个区域可以装入一个或多个进程,如果进程的大小不是区域的整数倍,就会产生外部碎片。 页式分区,将进程的地址空间划分为大小相等的若干个页,将物理内存划分为大小相等的若干个页框,然后将页映射到页框,实现非连续的内存分配,避免了外部碎片,但是可能产生内部碎片。 段式分区,将进程的地址空间划分为大小不等的若干个段,每个段有自己的逻辑地址和属性,然后将段映射到物理内存,实现非连续的内存分配,避免了内部碎片,但是可能产生外部碎片。 段页式分区,将进程的地址空间划分为若干个段,每个段再划分为若干个页,然后将页映射到物理内存的页框,实现非连续的内存分配,避免了内部碎片和外部碎片,但是增加了地址转换的复杂度。 15、freertos启动流程? freertos是一个实时操作系统,它的启动流程一般如下: 首先,执行硬件初始化,如设置时钟,中断,堆栈等。 然后,执行软件初始化,如创建任务,队列,信号量,定时器等。 接着,调用vTaskStartScheduler ()函数,启动调度器,选择优先级最高的就绪任务运行。 最后,当发生中断,延时,阻塞等事件时,调度器会根据算法,如优先级抢占式,时间片轮转式等,切换任务,实现多任务的并发执行。 16、互斥锁与信号量的区别? 互斥锁(mutex)和信号量(semaphore)都是用于实现多任务的同步和互斥的机制,但是它们有以下区别: 互斥锁是一个二元的同步对象,它只有两种状态:锁定和解锁。一个互斥锁只能被一个任务拥有,当一个任务获取互斥锁后,其他任务就不能再获取该互斥锁,直到拥有者释放它。互斥锁通常用于保护临界区的访问,避免数据的不一致。 信号量是一个计数的同步对象,它有一个初始值,表示可用的资源数量。一个信号量可以被多个任务共享,当一个任务获取信号量后,信号量的值减一,表示资源被占用。当信号量的值为零时,表示没有可用的资源,其他任务就要等待,直到有任务释放信号量,信号量的值加一,表示资源被释放。信号量通常用于实现生产者-消费者模型,控制资源的分配和回收。 17、什么是死锁?死锁产生的原因?如何避免? 死锁是指多个任务因为争夺有限的资源而相互等待,导致无法继续执行的现象。死锁产生的原因一般有以下四个必要条件: 互斥条件,指每个资源只能被一个任务拥有,其他任务不能访问。 占有且等待条件,指一个任务已经占有了至少一个资源,但是又申请了其他已经被占有的资源,同时不释放自己已经占有的资源。 不可抢占条件,指一个任务占有的资源不能被其他任务强行剥夺,只能由占有者主动释放。 循环等待条件,指多个任务形成一个环路,每个任务都在等待下一个任务占有的资源。 避免死锁的方法有以下几种: 破坏互斥条件,使用非互斥的资源,如可复制的资源,或者使用软件技术,如事务,来实现对资源的虚拟访问。 破坏占有且等待条件,要求一个任务在申请资源时,必须一次性申请所有需要的资源,或者在申请新的资源时,必须先释放已经占有的资源。 破坏不可抢占条件,允许一个任务在占有资源时,被其他任务抢占,或者主动释放资源,以满足其他任务的需求。 破坏循环等待条件,给每个资源分配一个优先级,要求一个任务只能申请优先级高于或等于自己已经占有的资源的资源,或者按照一定的顺序申请资源,避免形成环路。 18、什么是内存泄漏? 内存泄漏是指程序在运行过程中,动态分配了一些内存空间,但是没有及时释放,导致这些内存空间无法被其他程序使用,造成内存的浪费和紧张。内存泄漏可能会导致程序的性能下降,甚至崩溃。 19、系统死机了怎么排查原因?逐一看代码?工程量太大了吧? 系统死机是指系统无法响应用户的输入,或者出现异常的错误,导致系统无法正常运行。排查系统死机的原因有以下几种方法: 通过日志文件,查看系统在死机前的运行状态,是否有异常的信息,如错误码,警告,断言等,以及死机的时间,位置,频率等,从而定位可能的问题源。 通过调试工具,如gdb,lldb等,对系统进行调试,查看系统的内存,寄存器,堆栈,断点等,分析系统的运行流程,发现潜在的错误,如内存泄漏,空指针,死锁等。 通过测试工具,如valgrind,asan等,对系统进行测试,检测系统的内存管理,性能,覆盖率等,发现系统的缺陷,如内存错误,资源泄漏,性能瓶颈等。 通过代码审查,对系统的代码进行分析,检查代码的风格,规范,逻辑,注释等,发现代码的不合理,不一致,不完善等,提高代码的质量,可读性,可维护性等。 通过重现问题,对系统的死机现象进行复现,观察系统的表现,输入,输出等,找出问题的触发条件,规律,范围等,缩小问题的范围,提高问题的可解决性。 20、同一类型的结构体定义两个变量能用内存大小来比较判断两者一样吗?(没懂) 同一类型的结构体定义两个变量,不能用内存大小来比较判断两者一样,因为内存大小只能反映结构体的占用空间,而不能反映结构体的内容。例如,以下两个结构体变量的内存大小都是8字节,但是它们的内容是不一样的: struct Point { int x; int y; }; struct Point p1 = {1, 2}; struct Point p2 = {3, 4}; 如果要比较两个结构体变量是否一样,需要逐个比较它们的成员,或者使用memcmp函数比较它们的内存内容。例如: // 逐个比较 if (p1.x == p2.x && p1.y == p2.y) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); } // 使用memcmp比较 if (memcmp(&p1, &p2, sizeof(struct Point)) == 0) { printf("p1 and p2 are equal\n"); } else { printf("p1 and p2 are not equal\n"); }21、freertos中EventBits_t是干啥的? EventBits_t是一个数据类型,它用于表示事件标志组(event group)中的每个位的状态,每个位可以表示一个事件的发生或者一个条件的满足。EventBits_t通常是一个无符号整数,它可以使用位运算来设置,清除,读取或等待事件标志。 22、freertos使任务切换的方式有哪些? freertos使任务切换的方式有以下几种: 时间片轮转法,按照任务的优先级和时间片的长度,依次轮流执行每个就绪任务,当一个任务的时间片用完或者主动放弃时,切换到下一个任务。 优先级抢占法,按照任务的优先级,总是执行优先级最高的就绪任务,当有更高优先级的任务就绪时,立即抢占当前任务,切换到更高优先级的任务。 混合法,结合时间片轮转法和优先级抢占法,对于同一优先级的任务,使用时间片轮转法,对于不同优先级的任务,使用优先级抢占法,实现任务的公平性和效率。 23、项目中用到网络了吗? 这个问题的答案取决于你的项目的具体情况,如果你的项目需要与其他设备或服务器进行通信,或者需要访问互联网上的资源,那么你的项目就用到了网络。如果你的项目只是在本地运行,不需要与外界交互,那么你的项目就没有用到网络。 24、了解Socket吗? Socket是一种通信机制,它可以实现不同进程或不同设备之间的数据交换。Socket通常基于TCP/IP协议,提供了可靠的,双向的,面向连接的通信服务。Socket的基本操作包括创建,绑定,监听,连接,发送,接收,关闭等。Socket的编程接口通常是一组函数或类,不同的编程语言或平台可能有不同的实现,如C语言的socket.h,Java语言的java.net.Socket等。 25、c++中set是什么? set是C++标准模板库(STL)中的一个容器,它可以存储一组不重复的元素,并且按照一定的顺序排列。set的元素可以是任意类型,但是必须支持比较操作,如<,==等。set的底层实现通常是红黑树,所以它的插入,删除,查找等操作的时间复杂度都是O(logn) ,其中n是元素的个数。set的优点是可以快速地检查一个元素是否存在,以及保持元素的有序性。set的缺点是不能存储重复的元素,以及不能直接访问元素,只能通过迭代器遍历。 26、有没有用到C++模板? C++模板是一种泛型编程的技术,它可以让程序员定义一种通用的模式,然后根据不同的类型或参数,生成不同的代码,从而实现代码的复用和抽象。C++模板有两种,一种是函数模板,用于定义通用的函数,另一种是类模板,用于定义通用的类。例如,以下是一个函数模板,用于比较两个值的大小: template <typename T> T max(T x, T y) { return (x > y) ? x : y; } 我有用过C++模板,它们可以让我的代码更简洁,更灵活,更高效。我用过STL中的一些类模板,如vector,map,set等,也用过自己定义的一些函数模板和类模板,来实现一些通用的算法和数据结构。 27、有没有对代码裁剪的经验 代码裁剪是指对代码进行优化,删除不必要的或冗余的代码,减少代码的体积和复杂度,提高代码的可读性和可维护性。代码裁剪的目的是为了提高程序的性能,节省内存空间,降低编译时间,避免错误和漏洞等。 我有对代码裁剪的经验,我用过一些工具和方法来进行代码裁剪,如: 使用编译器的优化选项,如-Os,-O3等,让编译器自动进行一些代码裁剪,如常量折叠,死代码删除,循环展开等。 使用代码分析工具,如lint,coverity等,检查代码的质量,发现代码的缺陷,如未使用的变量,函数,参数等,以及代码的风格,规范,注释等,然后根据工具的建议,修改或删除代码。 使用代码重构工具,如refactor,eclipse等,对代码进行重构,改善代码的结构,设计,逻辑等,消除代码的冗余,重复,复杂等,提高代码的可读性,可维护性,可扩展性等。 使用代码压缩工具,如upx,gzip等,对代码进行压缩,减少代码的体积,提高代码的传输速度,节省存储空间等。 28、freertos系统是买模块时人家配置好的?还是移植的? freertos系统是一个开源的,可移植的,实时的操作系统,它可以运行在多种嵌入式平台上,如ARM,MIPS,AVR等。freertos系统不是买模块时人家配置好的,而是需要根据不同的硬件和需求进行移植和定制的。移植freertos系统的步骤一般如下: 下载freertos的源码,选择合适的移植层,如portable/GCC/ARM_CM3等,根据目标平台的特性,修改一些配置参数,如configCPU_CLOCK_HZ,configTICK_RATE_HZ等。 编写启动代码,如设置时钟,中断,堆栈等,调用vPortStartFirstTask ()函数,启动第一个任务。 编写应用代码,如创建任务,队列,信号量,定时器等,调用vTaskStartScheduler ()函数,启动调度器。 编译,链接,下载,调试代码,检查系统的运行情况,如任务切换,中断响应,内存管理等。 29、任务里有两把锁的时候该怎么处理 任务里有两把锁的时候,可能会出现死锁的问题,即两个或多个任务因为互相等待对方占有的锁而无法继续执行。处理任务里有两把锁的时候,有以下几种方法: 避免使用两把锁,如果可能的话,尽量使用一把锁来保护临界区,或者使用其他同步机制,如信号量,事件标志等,来实现任务之间的协作。 按照一定的顺序获取和释放锁,如果必须使用两把锁,那么要求所有的任务都按照相同的顺序获取和释放锁,避免形成循环等待的条件。 使用超时机制,如果一个任务在获取锁时,发现锁已经被占用,那么不要无限期地等待,而是设置一个超时时间,如果超时时间到了,还没有获取到锁,那么就放弃获取,释放已经占有的锁,然后重新尝试或者执行其他操作。 使用优先级继承机制,如果一个任务在获取锁时,发现锁已经被占用,那么就把自己的优先级赋给占有锁的任务,让占有锁的任务尽快执行完毕,释放锁,然后恢复原来的优先级,这样可以避免优先级反转的问题。 30、熟悉Shell脚本吗?$和#啥意思? Shell脚本是一种用于控制Unix或Linux系统的命令行解释器,它可以实现一些自动化的任务,如文件操作,文本处理,程序运行等。Shell脚本的语法和结构类似于C语言,但是更加简洁和灵活。Shell脚本的文件名通常以.sh为后缀,例如test.sh。 $和#是Shell脚本中的两个特殊符号,它们有以下含义: $表示变量的引用,可以用来获取或设置变量的值,例如x=10,echo $x,表示将10赋值给变量x,然后打印x的值。 表示注释的开始,可以用来对代码进行说明,不会被执行,例如#echo hello,#这是一个注释,表示打印hello,后面的内容是一个注释。 31、知道#error吗? 、#error是一个预处理指令,它可以用来在编译时产生一个错误信息,中断编译过程。#error通常用来检查一些条件,如宏定义,平台,版本等,如果不满足条件,就提示错误,防止编译出错的代码。例如: #ifdef __linux__ #error This code is not compatible with Linux #endif 这段代码表示如果定义了__linux__宏,就产生一个错误信息,表示这段代码不兼容Linux系统。 32、freertos消息队列的的具体实现? freertos消息队列是一种用于实现任务之间或任务与中断之间的异步通信的机制,它可以存储一组有序的消息,每个消息可以是任意类型的数据。freertos消息队列的具体实现如下: 消息队列是一个结构体,它包含了一些成员,如队列的头指针,尾指针,长度,容量,锁,信号量等,用来管理队列的状态和操作。 消息队列的存储空间是一个数组,它可以是静态分配的或动态分配的,它的大小要能够容纳队列的最大容量乘以每个消息的大小。 消息队列的操作有以下几种,如创建,删除,发送,接收等,它们都是通过调用一些API函数来实现的,如xQueueCreate,vQueueDelete,xQueueSend,xQueueReceive等。 消息队列的操作都是原子的,即在操作过程中,不会被其他任务或中断打断,这是通过使用临界区或中断屏蔽来实现的,以保证队列的一致性和完整性。 消息队列的操作都是阻塞的,即如果队列满了,就不能发送消息,如果队列空了,就不能接收消息,这是通过使用信号量来实现的,以实现任务的同步和等待。 33、堆栈区别? 堆(heap)和栈(stack)都是程序运行时使用的内存空间,但是它们有以下区别: 堆是动态分配的,程序员可以自由地申请和释放堆上的内存空间,堆的大小受到物理内存的限制,堆上的内存空间的地址是不连续的。 栈是静态分配的,编译器会自动地分配和回收栈上的内存空间,栈的大小受到操作系统的限制,栈上的内存空间的地址是连续的。 堆是全局共享的,堆上的内存空间可以被任何函数或模块访问,堆上的内存空间的生命周期是由程序员控制的,如果不及时释放,可能会导致内存泄漏。 栈是局部私有的,栈上的内存空间只能被当前函数或模块访问,栈上的内存空间的生命周期是由编译器控制的,当函数调用结束时,栈上的内存空间就会被自动释放。 34、程序存放状态和区别 程序存放状态是指程序在运行过程中的不同阶段,它有以下几种: 新建状态,指程序刚刚被创建,还没有被加载到内存中,等待调度器的调度。 就绪状态,指程序已经被加载到内存中,已经分配了必要的资源,等待处理器的分配。 运行状态,指程序已经被分配了处理器,正在执行程序的指令。 阻塞状态,指程序在执行过程中,因为等待某些事件的发生,如输入输出,信号量,中断等,而暂时停止执行,释放处理器,等待事件的完成。 终止状态,指程序已经执行完毕,或者因为某些原因,如错误,异常,中断等,而被终止,释放内存和资源,从系统中消失。
嵌入式&系统
# 嵌入式
刘航宇
2年前
0
624
4
2023-12-20
【嵌软】STM32的4种开发方式介绍
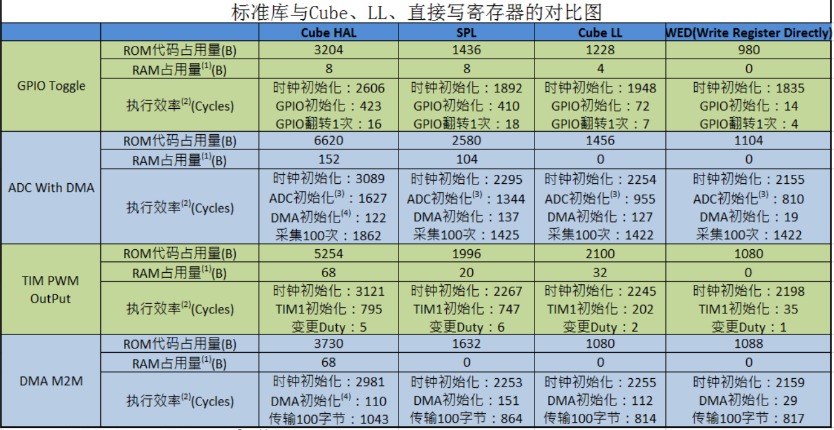
与FPGA一样,STM32也属于板级开发,可适用于大多数计算场合,但神经网络这种需要大量并行计算的需求难以满足。 STM32的开发主要指的是通过程序实现功能,ST官方提供的开发方式来说从远及近分别是: 1、直接读写寄存器 2、标准外设驱动库 SPL 3、硬件抽象层库 HAL库 4、底层库 LL库 四种开发方式各有优缺点,可以参考ST官方的测试与说明: 图片 标准外设库:这是ST官方提供的一套固件库,包含了STM32所有外设的驱动函数,可以方便地调用。它的优点是稳定、兼容、易用,缺点是占用资源较多,效率较低,更新较慢。 寄存器操作:这是直接对STM32的寄存器进行读写的方式,可以实现最底层的控制。它的优点是占用资源最少,效率最高,缺点是难度较大,需要熟悉寄存器的功能和位定义,不利于移植。 HAL库:这是ST官方推出的一套新的固件库,基于硬件抽象层(Hardware Abstraction Layer)的思想,提供了更加简洁和统一的接口。它的优点是支持多种IDE,更新较快,易于移植,缺点是文档较少,兼容性较差,有些BUG。CubeMX:这是ST官方提供的一套图形化的配置工具,可以自动生成HAL库的代码,还可以集成一些中间件和应用层的功能。它的优点是操作简单,功能强大,缺点是生成的代码较冗余,不易修改,有些功能不完善。 直接读写寄存器 开发是最慢的,可移植性最差,基本不推荐使用,只有个别对时间或是内存要求特别高、或者在写操作系统调度器时才需要直接读写寄存器; 标准外设驱动库 是ST最开始提供的库(国内的教程也很多是依据题库出的),现在已经被ST放弃了; HAL库 和 LL库 是近几年推出的库,结合 STM32CubeIDE 使用非常方便, HAL库 性能较差、在STM32系列芯片中可移植性好, LL库 性能好、可移植性差。
嵌入式&系统
# 嵌入式
# C/C++
刘航宇
3年前
0
1,165
3
2023-12-11
华为C++算法-识别有效的IP地址和掩码并进行分类统计
问题 注意: 输入描述: 输出描述: 示例 需要注意的细节 思路 具体实现 代码 问题 请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。 所有的IP地址划分为 A,B,C,D,E五类 A类地址从1.0.0.0到126.255.255.255; B类地址从128.0.0.0到191.255.255.255; C类地址从192.0.0.0到223.255.255.255; D类地址从224.0.0.0到239.255.255.255; E类地址从240.0.0.0到255.255.255.255 私网IP范围是: 从10.0.0.0到10.255.255.255 从172.16.0.0到172.31.255.255 从192.168.0.0到192.168.255.255 子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码) (注意二进制下全是1或者全是0均为非法子网掩码) 注意: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 私有IP地址和A,B,C,D,E类地址是不冲突的 输入描述: 多行字符串。每行一个IP地址和掩码,用~隔开。 输出描述: 统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。 示例 输入: 10.70.44.68~255.254.255.0 1.0.0.1~255.0.0.0 192.168.0.2~255.255.255.0 19..0.~255.255.255.0 输出: 1 0 1 0 0 2 1 说明: 10.70.44.68~255.254.255.0的子网掩码非法,19..0.~255.255.255.0的IP地址非法,所以错误IP地址或错误掩码的计数为2; 1.0.0.1~255.0.0.0是无误的A类地址; 192.168.0.2~255.255.255.0是无误的C类地址且是私有IP; 所以最终的结果为1 0 1 0 0 2 1 示例2 输入: 0.201.56.50~255.255.111.255 127.201.56.50~255.255.111.255 输出: 0 0 0 0 0 0 0 说明: 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略 需要注意的细节 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略 私有IP地址和A,B,C,D,E类地址是不冲突的,也就是说需要同时+1 如果子网掩码是非法的,则不再需要查看IP地址 全零【0.0.0.0】或者全一【255.255.255.255】的子网掩码也是非法的 思路 按行读取输入,根据字符‘~’ 将IP地址与子网掩码分开 查看子网掩码是否合法。 合法,则继续检查IP地址 非法,则相应统计项+1,继续下一行的读入 查看IP地址是否合法 合法,查看IP地址属于哪一类,是否是私有ip地址;相应统计项+1 非法,相应统计项+1 具体实现 判断IP地址是否合法,如果满足下列条件之一即为非法地址 数字段数不为4 存在空段,即【192..1.0】这种 某个段的数字大于255 判断子网掩码是否合法,如果满足下列条件之一即为非法掩码 不是一个合格的IP地址 在二进制下,不满足前面连续是1,然后全是0 在二进制下,全为0或全为1 如何判断一个掩码地址是不是满足前面连续是1,然后全是0? 将掩码地址转换为32位无符号整型,假设这个数为b。如果此时b为0,则为非法掩码 将b按位取反后+1。如果此时b为1,则b原来是二进制全1,非法掩码 如果b和b-1做按位与运算后为0,则说明是合法掩码,否则为非法掩码 代码 注意getline函数可以指定分割字符串的字符 // 引入输入输出流、字符串、字符串流和向量等头文件 #include<iostream> #include<string> #include<sstream> #include<vector> // 使用标准命名空间 using namespace std; // 定义一个函数,判断一个字符串是否是合法的IP地址 bool judge_ip(string ip){ // 定义一个整数变量,记录IP地址的段数 int j = 0; // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 使用循环,以'.'为分隔符,获取IP地址的每一段 while(getline(iss,seg,'.')) // 如果段数加一大于4,或者该段为空,或者该段的数值大于255,说明不是合法的IP地址,返回false if(++j > 4 || seg.empty() || stoi(seg) > 255) return false; // 如果循环结束后,段数等于4,说明是合法的IP地址,返回true return j == 4; } // 定义一个函数,判断一个字符串是否是私有的IP地址 bool is_private(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个整数向量,用于存储IP地址的每一段的数值 vector<int> v; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,存入向量中 while(getline(iss,seg,'.')) v.push_back(stoi(seg)); // 如果IP地址的第一段等于10,说明是私有的IP地址,返回true if(v[0] == 10) return true; // 如果IP地址的第一段等于172,并且第二段在16到31之间,说明是私有的IP地址,返回true if(v[0] == 172 && (v[1] >= 16 && v[1] <= 31)) return true; // 如果IP地址的第一段等于192,并且第二段等于168,说明是私有的IP地址,返回true if(v[0] == 192 && v[1] == 168) return true; // 如果以上条件都不满足,说明不是私有的IP地址,返回false return false; } // 定义一个函数,判断一个字符串是否是合法的子网掩码 bool is_mask(string ip){ // 定义一个字符串流对象,用于分割IP地址 istringstream iss(ip); // 定义一个字符串变量,用于存储IP地址的每一段 string seg; // 定义一个无符号整数变量,用于存储IP地址的二进制表示 unsigned b = 0; // 使用循环,以'.'为分隔符,获取IP地址的每一段,并将其转换为整数,左移8位后与b进行按位或运算,得到IP地址的二进制表示 while(getline(iss,seg,'.')) b = (b << 8) + stoi(seg); // 如果b等于0,说明不是合法的子网掩码,返回false if(!b) return false; // 将b按位取反后加一,得到b的补码 b = ~b + 1; // 如果b等于1,说明不是合法的子网掩码,返回false if(b == 1) return false; // 如果b与b减一进行按位与运算,结果等于0,说明b只有一个1,说明是合法的子网掩码,返回true if((b & (b-1)) == 0) return true; // 如果以上条件都不满足,说明不是合法的子网掩码,返回false return false; } // 定义主函数 int main(){ // 定义一个字符串变量,用于存储输入的IP地址和子网掩码 string input; // 定义七个整数变量,用于统计A、B、C、D、E类地址、错误地址和私有地址的个数 int a = 0,b = 0,c = 0,d = 0,e = 0,err = 0,p = 0; // 使用循环,读取输入的IP地址和子网掩码,直到输入结束 while(cin >> input){ // 定义一个字符串流对象,用于分割IP地址和子网掩码 istringstream is(input); // 定义一个字符串变量,用于存储IP地址或子网掩码 string add; // 定义一个字符串向量,用于存储IP地址和子网掩码 vector<string> v; // 使用循环,以'~'为分隔符,获取IP地址和子网掩码,并存入向量中 while(getline(is,add,'~')) v.push_back(add); // 如果IP地址或子网掩码不合法,错误地址的个数加一 if(!judge_ip(v[1]) || !is_mask(v[1])) err++; else{ // 如果IP地址不合法,错误地址的个数加一 if(!judge_ip(v[0])) err++; else{ // 获取IP地址的第一段的数值 int first = stoi(v[0].substr(0,v[0].find_first_of('.'))); // 如果IP地址是私有的,私有地址的个数加一 if(is_private(v[0])) p++; // 根据IP地址的第一段的数值,判断IP地址的类别,并相应的类别的个数加一 if(first > 0 && first <127) a++; else if(first > 127 && first <192) b++; else if(first > 191 && first <224) c++; else if(first > 223 && first <240) d++; else if(first > 239 && first <256) e++; } } } // 输出A、B、C、D、E类地址、错误地址和私有地址的个数 cout << a << " " << b << " " << c << " " << d << " " << e << " " << err << " " << p << endl; // 返回0,表示程序正常结束 return 0; }
嵌入式&系统
编程&脚本笔记
软硬件算法
# 嵌入式
# 笔试面试
# C/C++
刘航宇
3年前
0
505
0
2023-11-20
超声模块HC_SR04基本原理与FPGA、STM32应用
HC-SR04硬件概述 接口定义: 模式选择: 测量操作: FPGA实现超声测距模块代码 ifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" endif / HCSR04_H_ / include "hc-sr04.h" include "hc-sr04.h" include "printf.h" HC-SR04 硬件概述 HC-SR04超声波距离传感器的核心是两个超声波传感器。一个用作发射器,将电信号转换为40 KHz超声波脉冲。接收器监听发射的脉冲。如果接收到它们,它将产生一个输出脉冲,其宽度可用于确定脉冲传播的距离。就是如此简单! 该传感器体积小,易于在任何机器人项目中使用,并提供2厘米至600厘米(约1英寸至13英尺)之间出色的非接触范围检测,精度为3mm。 图片 接口定义: 图片 模式选择: 图片 测量操作: 一:GPIO模式 图片 外部MCU给模块Trig脚一个大于10uS的高电平脉冲;模块会给出一个与距离等比的高电平脉冲信号,可根据脉宽时间“T” 算出: 距离=T*C/2 (C为声速) 声速温度公式:c=(331.45+0.61t/℃)m•s-1 (其中330.45是在0℃) 0℃声速: 330.45M/S 20℃声速: 342.62M/S 40℃声速: 354.85M/S0℃-40℃声速误差7%左右。实际应用,如果需要精确距离值,必需要考虑温度影响,做温度补偿。 二:UART模式 UART 模式波特率设置: 9600 N 1 图片 连接串口。外部MCU或PC发命令0XA0,模块完成测距后发3个返回距离 数据,BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 三:IIC模式 IIC地址: 0X57 IIC传输格式: 写数据: 图片 读数据: 图片 命令格式: 图片 向模块写入0X01,模块开始测距;等待200mS(模块最大测距时间) 以上。直接读出3个距离数据。BYTE_H,BYTE_M与BYTE_L。 距离计算方式如下(单位mm): 距离=((BYTE_H<<16)+(BYTE_M<<8)+ BYTE_L)/1000 FPGA实现超声测距 本次测距教程一律按基本原理实现,至于UART、ICC测距原理可以网上查询 FPGA 产生周期性的 TRIG 脉冲信号,使得超声波模块周期性发出测距脉冲,当这些脉冲发出后遇到障碍物返回,超声波模块将返回的脉冲处理整形后返回给 FPGA,即 ECHO 信号。我们通过对 ECHO 信号的高脉冲保持时间就可以推算出超声波脉冲和障碍物之间的距离。 本实例的功能如图三所示,FPGA 产生 10us 脉冲 TRIG 给超声波测距模块,然后以 10us 为单位计算超声波测距模块返回的回响信号 ECHO 的高电平保持时间。ECHO 的高电平保持时间通过一定的换算后可以得到障碍物和超声波测距模块之间的距离(由距离公式计算&进制换算模块实现),我们将最终获得的以 mm 为单位的距离信息显示在 4 位数码管上。 图片 模块代码 1、vlg_en模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 15:24:01 * @Email: hyliu@ee.ac.cn * @Descripttion: 板子时钟转化1us * @Last Modified time: 2023-11-20 15:24:01 */ //1us/50ns=20 module vlg_1us#(parameter P_CLK_PERIORD = 50) //i_clk的时钟周期50ns,20MHZ ( input i_clk, input i_rst_n, output reg o_clk //时钟周期1us ); parameter NUM_DIV = 20;// (1MHZ = 1us,20MHZ/20 = 1MHZ) reg [3:0] cnt; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) begin cnt <= 4'd0; o_clk <= 1'b0; end else if(cnt == NUM_DIV/2 - 1) begin cnt <= 4'b0; o_clk <= ~o_clk; end else cnt <= cnt + 1'b1; end endmodule2、vlg_trig模块 /* * @Author: Hangyu Liu * @Date: 2023-11-20 16:50:44 * @Email: hyliu@ee.ac.cn * @Descripttion: 产生10us的触发超声信号 * @Last Modified time: 2023-11-20 16:50:44 */ module vlg_trig ( input i_rst_n, input clk_1us, //1us output reg o_trig ); reg[17:0] r_tricnt; //200ms的周期计数 1us一个单位 always @(posedge clk_1us or negedge i_rst_n)begin if(!i_rst_n) r_tricnt <= 18'd0; else if((r_tricnt == 18'd199999)) r_tricnt <= 18'd0; else r_tricnt <= r_tricnt + 1'b1; end //产生保持10us的高脉冲o_tring信号 always @(posedge clk_1us or negedge i_rst_n) begin if(!i_rst_n) o_trig<=1'b0; else if((r_tricnt > 18'd0) && (r_tricnt <= 18'd10)) o_trig <= 1'b1; //不从0开始0~9,防止出现不到10us的波干扰 else o_trig <= 1'b0; end endmodule3、vlg_echo模块 module vlg_echo ( input i_clk, //1us input i_rst_n, input i_clk_1us, input i_echo, output reg[15:0] o_t_us ); reg[1:0] r_echo; wire pos_echo,neg_echo; reg r_cnt_en; reg[15:0] r_echo_cnt; //对i_echo信号同步处理,获取边沿检测信号,产生计数使能信号r_cnt_en always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_echo <= 2'd0; else r_echo <= {r_echo[0],i_echo}; //设置两个寄存器进行打拍寄存 end assign pos_echo = r_echo[0] & ~r_echo[1]; //现状态是1上状态是0,就是上升沿 assign neg_echo = ~r_echo[0] & r_echo[1]; always @(posedge i_clk or negedge i_rst_n) begin if(!i_rst_n) r_cnt_en <= 1'b0; else if(pos_echo) r_cnt_en <= 1'b1; else if(neg_echo) r_cnt_en <= 1'b0; else r_cnt_en <= r_cnt_en; end //对i_echo信号的高脉冲计时,以us为单位 always @(posedge i_clk_1us or negedge i_rst_n) begin if(!i_rst_n) r_echo_cnt <= 1'b0; else if(r_cnt_en) r_echo_cnt <= r_echo_cnt + 1'b1; else r_echo_cnt <= 1'b0; end //在下降沿对计数最大值进行保存 always @(negedge i_clk or negedge i_rst_n) begin if(!i_rst_n) o_t_us <= 16'd0; else if(neg_echo) o_t_us <= r_echo_cnt; else o_t_us <= o_t_us; end endmodule 4、顶层模块例化/* @Author: Hangyu Liu @Date: 2023-11-23 17:16:40 @Email: hyliu@ee.ac.cn @Descripttion:HR04驱动模块 @Last Modified time: 2023-11-23 17:16:40 */ module vlg_design ( input i_clk, //200MHZ input i_rst_n, input i_echo, //这是超声模块给的输入 output o_trig, output wire[15:0] w_t_us); wire clk_20MHZ; clk_div_20MHZ UU( .i_clk(i_clk), .i_rst_n(i_rst_n), .clk_div(clk_20MHZ)); localparam P_CLK_PERIORD = 50; wire clk_1us; //使能时钟产生模块 vlg_1us #( .P_CLK_PERIORD(P_CLK_PERIORD) //i_clk的时钟周期50ns,20MHZ)U1( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .o_clk(clk_1us)); //产生超声波测距模块的触发信号o_trig vlg_trig U2( .i_rst_n(i_rst_n), .clk_1us(clk_1us), .o_trig(o_trig)); //超声波测距模块的回响信号i_echo的高电平时间采集 vlg_echo U3( .i_clk(clk_20MHZ), .i_rst_n(i_rst_n), .i_clk_1us(clk_1us), .i_echo(i_echo), .o_t_us(w_t_us)); endmodule ## STM32(Cubemax)实现超声波测距 ### CubeMX配置STM32 1 时钟配置 这里我用的是STM32F103C8T6的核心板,时钟配置如下图,我用了8MHz的HSE,HCLK调到了最大值72MHz  2 设置输入捕获的定时器 设置定时器TIM2每1us向上计数一次,通道4为上升沿捕获并连接到超声波模块的ECHO引脚,记得开启定时器中断(涉及到捕获中断+定时器溢出中断)。  3 触发引脚 PB10接到了HC-SR04的TIRG触发引脚,默认输出低电平  4 串口配置 还要开启一个串口,以便通过串口查看测距结果  ### 编写代码 hc-sr04.hifndef HCSR04_H_ define HCSR04_H_ include "main.h" include "delay.h" typedef struct { uint8_t edge_state; uint16_t tim_overflow_counter; uint32_t prescaler; uint32_t period; uint32_t t1; // 上升沿时间 uint32_t t2; // 下降沿时间 uint32_t high_level_us; // 高电平持续时间 float distance; TIM_TypeDef* instance;uint32_t ic_tim_ch; HAL_TIM_ActiveChannel active_channel;}Hcsr04InfoTypeDef; extern Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel); /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start(); /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim); /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim); /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read(); endif / HCSR04_H_ / hc-sr04.cinclude "hc-sr04.h" Hcsr04InfoTypeDef Hcsr04Info; /** @description: 超声波模块的输入捕获定时器通道初始化 @param {TIM_HandleTypeDef} *htim @param {uint32_t} Channel @return {*} */ void Hcsr04Init(TIM_HandleTypeDef *htim, uint32_t Channel) { /--------[ Configure The HCSR04 IC Timer Channel ] / // MX_TIM2_Init(); // cubemx中配置 Hcsr04Info.prescaler = htim->Init.Prescaler; // 72-1 Hcsr04Info.period = htim->Init.Period; // 65535 Hcsr04Info.instance = htim->Instance; // TIM2 Hcsr04Info.ic_tim_ch = Channel; if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_1) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_1; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_2) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_2; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_3) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_3; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} else if(Hcsr04Info.ic_tim_ch == TIM_CHANNEL_4) { Hcsr04Info.active_channel = HAL_TIM_ACTIVE_CHANNEL_4; // TIM_CHANNEL_4} /--------[ Start The ICU Channel ]-------/ HAL_TIM_Base_Start_IT(htim); HAL_TIM_IC_Start_IT(htim, Channel); } /** @description: HC-SR04触发 @param {*} @return {*} */ void Hcsr04Start() { HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_SET); DelayUs(10); // 10us以上 HAL_GPIO_WritePin(TRIG_GPIO_Port, TRIG_Pin, GPIO_PIN_RESET); } /** @description: 定时器计数溢出中断处理函数 @param {} main.c中重定义void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimOverflowIsr(TIM_HandleTypeDef *htim) { if(htim->Instance == Hcsr04Info.instance) // TIM2 { Hcsr04Info.tim_overflow_counter++;} } /** @description: 输入捕获计算高电平时间->距离 @param {} main.c中重定义void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef htim) @return {*} */ void Hcsr04TimIcIsr(TIM_HandleTypeDef* htim) { if((htim->Instance == Hcsr04Info.instance) && (htim->Channel == Hcsr04Info.active_channel)) { if(Hcsr04Info.edge_state == 0) // 捕获上升沿 { // 得到上升沿开始时间T1,并更改输入捕获为下降沿 Hcsr04Info.t1 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_FALLING); Hcsr04Info.tim_overflow_counter = 0; // 定时器溢出计数器清零 Hcsr04Info.edge_state = 1; // 上升沿、下降沿捕获标志位 } else if(Hcsr04Info.edge_state == 1) // 捕获下降沿 { // 捕获下降沿时间T2,并计算高电平时间 Hcsr04Info.t2 = HAL_TIM_ReadCapturedValue(htim, Hcsr04Info.ic_tim_ch); Hcsr04Info.t2 += Hcsr04Info.tim_overflow_counter * Hcsr04Info.period; // 需要考虑定时器溢出中断 Hcsr04Info.high_level_us = Hcsr04Info.t2 - Hcsr04Info.t1; // 高电平持续时间 = 下降沿时间点 - 上升沿时间点 // 计算距离 Hcsr04Info.distance = (Hcsr04Info.high_level_us / 1000000.0) * 340.0 / 2.0 * 100.0; // 重新开启上升沿捕获 Hcsr04Info.edge_state = 0; // 一次采集完毕,清零 __HAL_TIM_SET_CAPTUREPOLARITY(htim, Hcsr04Info.ic_tim_ch, TIM_INPUTCHANNELPOLARITY_RISING); }} } /** @description: 读取距离 @param {*} @return {*} */ float Hcsr04Read() { // 测距结果限幅 if(Hcsr04Info.distance >= 450) { Hcsr04Info.distance = 450;} return Hcsr04Info.distance; } main.c 1、引用对应的头文件/ USER CODE BEGIN Includes / include "hc-sr04.h" include "printf.h" / USER CODE END Includes / 2、200ms测距一次/** @brief The application entry point. @retval int */ int main(void) { / USER CODE BEGIN 1 / / USER CODE END 1 / / MCU Configuration--------------------------------------------------------/ / Reset of all peripherals, Initializes the Flash interface and the Systick. / HAL_Init(); / USER CODE BEGIN Init / / USER CODE END Init / / Configure the system clock / SystemClock_Config(); / USER CODE BEGIN SysInit / / USER CODE END SysInit / / Initialize all configured peripherals / MX_GPIO_Init(); MX_TIM2_Init(); MX_USART1_UART_Init(); / USER CODE BEGIN 2 / DelayInit(72); Hcsr04Init(&htim2, TIM_CHANNEL_4); // 超声波模块初始化 Hcsr04Start(); // 开启超声波模块测距 printf("hc-sr04 start!\r\n"); / USER CODE END 2 / / Infinite loop / / USER CODE BEGIN WHILE / while (1) { // 打印测距结果 printf("distance:%.1f cm\r\n", Hcsr04Read()); Hcsr04Start(); DelayMs(200); // 测距周期200ms /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */} / USER CODE END 3 / } 3、重定义定时器的中断服务函数/ USER CODE BEGIN 4 / /** @description: 定时器输出捕获中断 @param {TIM_HandleTypeDef} *htim @return {*} */ void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim) { Hcsr04TimIcIsr(htim); } /** @description: 定时器溢出中断 @param {*} @return {*} */ void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef* htim) { Hcsr04TimOverflowIsr(htim); } / USER CODE END 4 / 4、串口打印结果
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
0
1,309
2
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
340
0
2023-07-19
嵌入式软件-基于C语言小端转大端
意义 题目 示例 解答1.char指针,按字节替换 2.利用union联合体共用内存空间特性,使用char数组来改变 3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 4. 使用预定义好的宏函数 意义 大端小端转化对嵌入式系统有意义,因为不同的处理器或者通信协议可能采用不同的字节序来存储或者传输数据。字节序是指一个多字节数据在内存中的存放顺序,它有两种主要的形式: 大端:最高有效位(MSB)存放在最低的内存地址,最低有效位(LSB)存放在最高的内存地址。 小端:最低有效位(LSB)存放在最低的内存地址,最高有效位(MSB)存放在最高的内存地址。 例如,一个32位的整数0x12345678,在大端系统中,它的内存布局是: pC703EF.png图片 而在小端系统中,它的内存布局是: pC70G4J.png图片 如果一个嵌入式系统需要和不同字节序的设备或者网络进行交互,就需要进行字节序的转换,否则会导致数据错误或者通信失败。例如,TCP/IP协议族中的所有层都采用大端字节序来表示数据包头中的16位或32位的值,如IP地址、包长、校验和等。如果一个嵌入式系统使用小端字节序的处理器,并且想要建立一个TCP连接,就需要将IP地址等信息从小端转换为大端再发送出去,否则对方无法正确解析。 题目 输入一个数字n,假设它是以小端模式保存在机器的,请将其转换为大端方式保存时的值。 示例 输入:1 返回值:16777216 解答 1.char指针,按字节替换 /* * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here int tmp = 0x00000000; //开辟新的int空间用于接收转化结果 unsigned char *p = &tmp, *q = &n; p[0] = q[3]; p[1] = q[2]; p[2] = q[1]; p[3] = q[0]; return tmp; }2.利用union联合体共用内存空间特性,使用char数组来改变 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ typedef union { int i; unsigned char c[4] } inc_u; int convert(int n ) { // write code here inc_u x; //这里也可以用新开辟空间进行置换 x.i = n; //利用按位异或运算可叠加、可还原性 x.c[0] ^= x.c[3], x.c[3] ^= x.c[0], x.c[0] ^= x.c[3]; //首尾两字节对调 x.c[1] ^= x.c[2], x.c[2] ^= x.c[1], x.c[1] ^= x.c[2]; //中间两字节对调 return x.i; /* 按位<<到正确位置,并用|拼装 return (x.c[0]<<24)|(x.c[1]<<16)|(x.c[2]<<8)|x.c[3]; */ }3. 使用按位与运算保留以获取每个字节,然后按位左移到正确位置并拼接 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return (((n & 0xff000000)>>24) | ((n & 0x00ff0000)>>8 ) | ((n & 0x0000ff00)<<8 ) | ((n & 0x000000ff)<<24); //按位与时,遇0清零,遇1保留 ); }4. 使用预定义好的宏函数 本条方法参考 https://www.codeproject.com/Articles/4804/Basic-concepts-on-Endianness 文中提到网络上常用的套接字接口(socket API)指定了一种称为网络字节顺序的标准字节顺序,这个顺序其实就是大端模式;而当时,同时代的 x86 系列主机反而是小端模式。所以就促使产生了如: ntohs() convert Network order TO Host order in Short (16 bit 大转小); ntohl() convert Network order TO Host order in Long (32 bit 大转小); htons() convert Host order TO Network order in Short (16 bit 小转大); htonl() convert Host order TO Network order in Long (32 bit 小转大). 所以我们这里使用 32 bit 小转大的 htonl() 宏函数来解决这个问题。 /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param n int整型 * @return int整型 */ int convert(int n ) { // write code here return htonl(n); ); }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
511
1
【转载】Libero SOC Debug教程-片上逻辑分析仪IDENTIFY
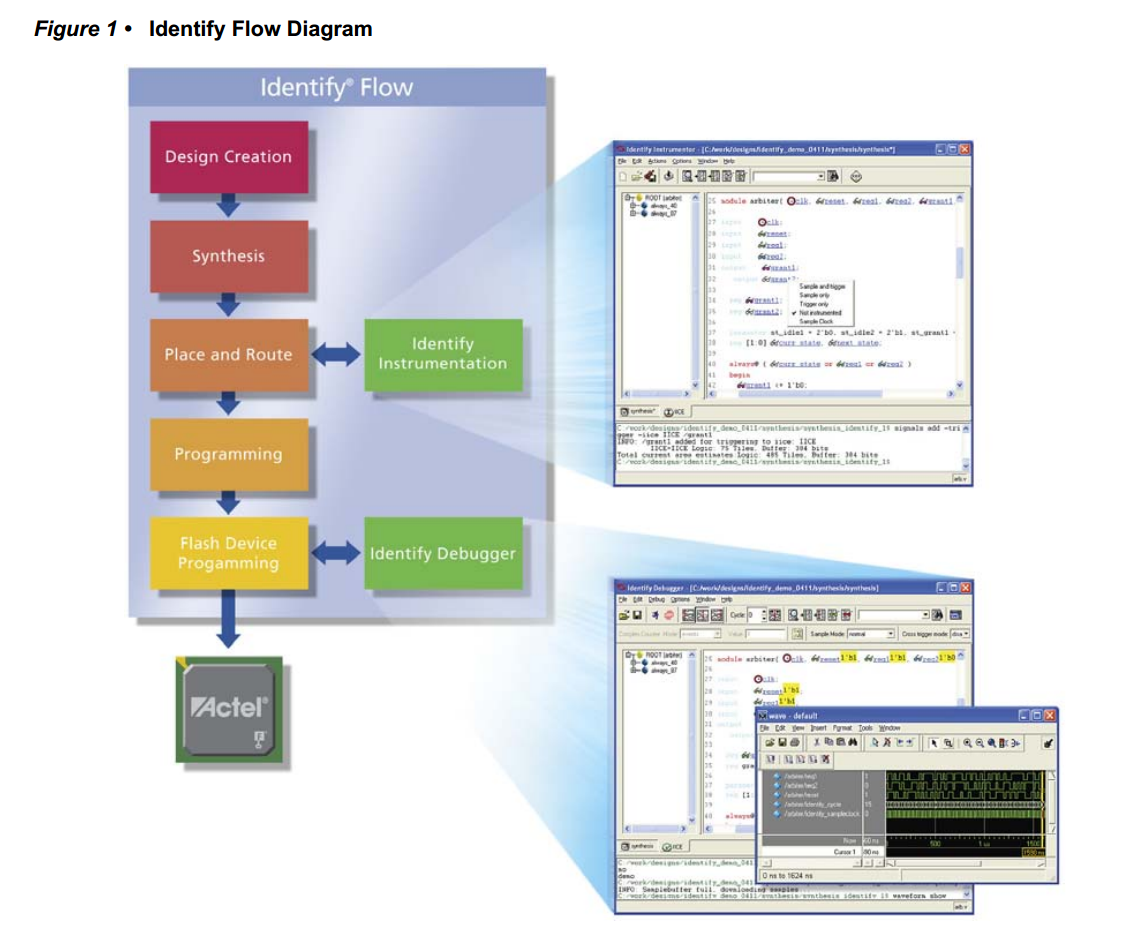
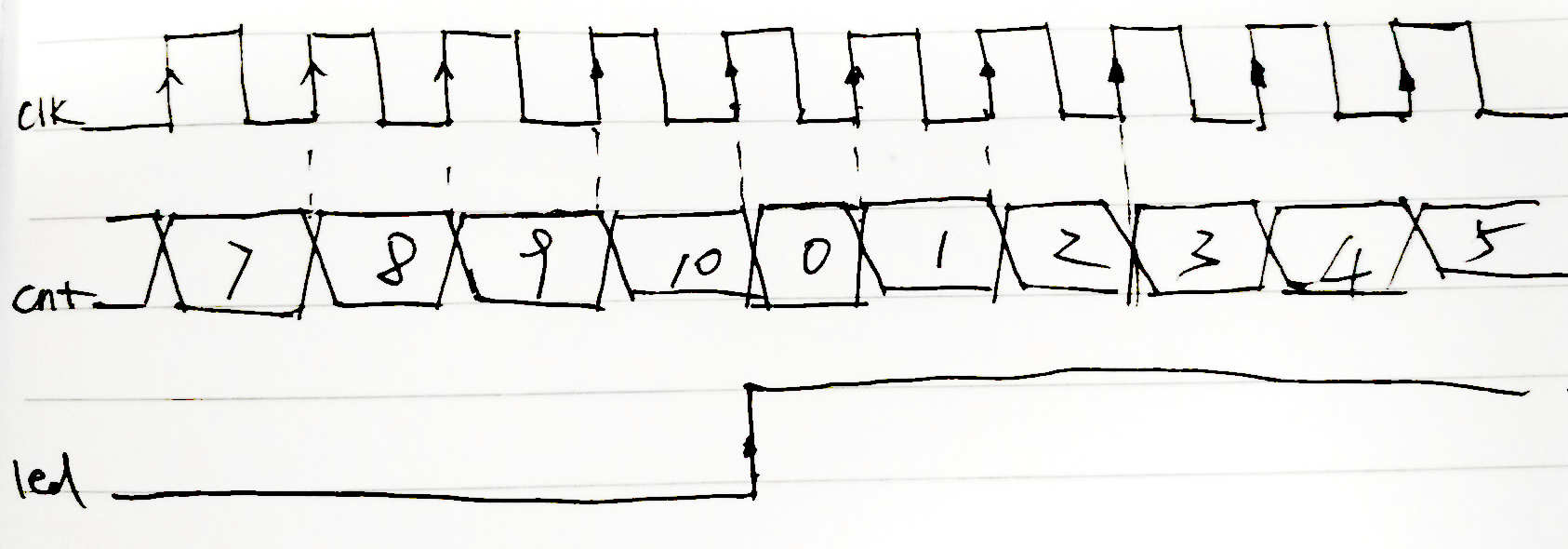
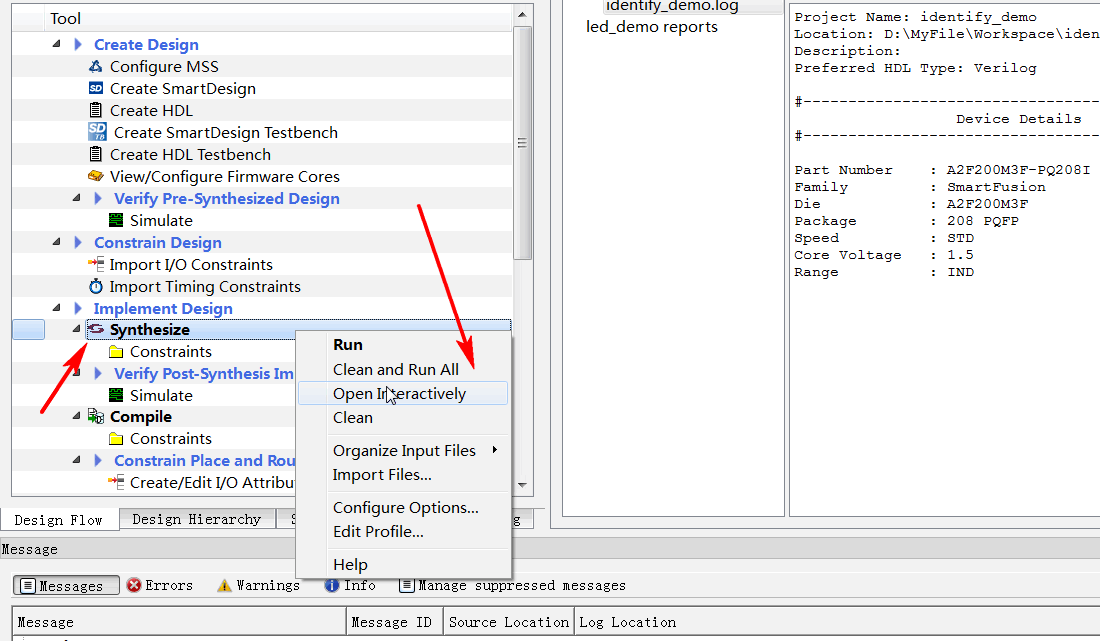
本文转载于https://blog.csdn.net/whik1194/article/details/107074187 FPGA在线调试 关于MICROSEMI片上逻辑分析仪 FPGA片上逻辑分析仪原理 预期效果 0.准备一个创建好的LIBERO工程 1.新建IDENTIFY工程,并添加想要监测的信号 2.管脚分配,编译下载 3.设置触发类型 4.IICE逻辑分析仪核资源占用 原文: 参考: FPGA在线调试 对于嵌入式系统来说,如单片机,进行硬件级程序调试时,通常采用的是JLink/ST-Link调试器,在线调试的方式来获取程序实时运行的状态,可以观察程序运行流程、各种变量的值、中断的触发情况,还可以设置断点、单步运行,方便快速的发现BUG,解决问题。 但是对于FPGA来说,并不是顺序执行的,而是根据每一个Clk并行执行,所以我们不能使用调试器进行单步调试。 FPGA调试需要观察内部信号的值,各个信号之间的时序关系,所以使用逻辑分析仪是最好的调试方式了。 有些FPGA工程,对外的接口,即输入输出,可能只有几个,但是他们之间的逻辑和时序关系非常复杂,所以内部有几十个中间寄存器,程序下载进去了,发现不是我们想要的效果,怎么办?你可能会说,查代码吧!如果这个工程非常简单,你可能只需要耗费几分钟或者几个小时就可以定位代码的问题所在。 但是如果这是一个非常庞大的工程,内部的中间寄存器、信号,几百上千个,各个模块单独软件仿真都正常,整体仿真也正常,就是下载到实际的芯片中运行不正常。你如何进行问题定位?如果再去进行代码审查,这将会消耗非常多的时间。那么如果能在FPGA芯片内部装上一个逻辑分析仪,那不就直接可以看到内部信号的值了,而且还可以看到各个信号之间的时序关系。需求推动技术发展,既然开发者有这个需求,那么FPGA厂商肯定会实现这个功能!下面来一起看一下Microsemi FPGA片上逻辑分析仪的使用方法吧! 关于MICROSEMI片上逻辑分析仪 几大厂商的片上逻辑分析仪: Xilinx厂商ISE开发环境下的ChipScope工具 Altera厂商Quartus开发环境下的SignalTap工具 Lattice厂商Diamod开发环境下的Reveal工具 对于 FPGA 工程师来说,这些都是很熟悉的名字。和以上几大FPGA厂商一样,Microsemi Libero也支持片上逻辑分析仪工具,只不过不是自己家研发的,使用的是Synospsy公司出品的Identify工具,其实,Libero中的综合器synplify也是Synospsy公司的。 根据Synospsy官网的描述:Identify RTL 调试仪,这个调试工具除了支持Microsemi的FPGA产品外,还支持Altera和Xilinx的FPGA产品。 FPGA片上逻辑分析仪原理 Identify片上逻辑分析仪的原理,是通过在FPGA工程中加入一个IICE逻辑分析仪IP核,这个IP核,由控制器和采集器组成,采集器用于采集信号,控制器用于和JTAG调试器连接,并把数据发送到上位机,IICE内部有RAM空间,用于存储触发位置附近的信号,RAM空间的大小,即采样深度,可以自己调整。FPGA工程中加入IICE核,会占用一定的资源,资源占用的大小取决于:采样深度,采样信号的个数,采样信号的触发方式等。 所以综上,FPGA片上逻辑分析仪需要3个组件:片上的IICE逻辑分析仪核、JTAG下载器、上位机。 pC5Uq6e.png图片 JTAG下载器也就是我们下载程序时使用的FlashPro x下载器,上位机软件也就是Identify工具,这个工具已经在安装Libero SoC时一同安装并注册**了。所以不需要安装其他的工具软件,只需要在已经设计好的FPGA公司中,配置一下IIC逻辑分析仪核就可以了。 在已经创建好的Libero工程中,加入IICE逻辑分析仪核,并演示Identify工具的使用。 预期效果 以Microsemi SmartFusion系列的A2F200M3F芯片为例,其他芯片使用操作方法类似。示例工程功能:led每隔10个clk翻转一次为例,演示identify的使用。 identify添加完成之后,把led设置为上升沿触发,会抓取到类似如下的波形。 pChB2qJ.png图片 0.准备一个创建好的LIBERO工程 这里以LED每隔10个时钟周期翻转为例。HDL文件内容: module led_demo( //inputs input clk, input rst_n, //outputs output reg led ); reg [3:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 0; else if(cnt == 10) /* max=10, 0-10 */ cnt <= 0; else cnt <= cnt + 1; end always @ (posedge clk) begin if(!rst_n) led <= 0; else if(cnt == 10) led <= ~led; end endmodule1.新建IDENTIFY工程,并添加想要监测的信号 1.0 先运行Synthesize 1.1 在Synthesize上右键,选择Open Interactively pChr5jO.png图片 1.2 在Synthesis上右键新建一个Identify工程 pChrTDe.png图片 1.3 输入新建的identify工程的名称和保存路径,选择默认的就行。 pChrqUA.png图片 1.4 在新建的identify工程上右键选择identify instrumentor pChsSKS.png图片 1.5 在HDL文件中选择要监测的信号和采样时钟,采样时钟选择Sample Clock,作为触发的信号选择Trigger Only,要监测的信号选择Sample Only,也可以选择Sample and Trigger,这样会占用更多的资源。 pChsG26.png图片 pChsNrD.png图片 设置完成的信号会有标注 pChsgsS.png图片 sample clock 表示采样时钟,所有在 IICE 中添加的信号都会在 sample clock 的边沿进行采样,设为 sample clock 的信号前会出现一个时钟状的图标。 设置为 sample 和 trigger 的信号都将作为被采样信号,区别在于 sample 信号只能被采样,而 trigger 信号可以作为触发采集的条件,当然你可以把一个信号同时设置为 sample 和 trigger 。 1.6 设置采样深度,选择Instrumentor->IICE pChsWZQ.png图片 采样深度最大支持1048576 pChsfaj.png图片 输入采样深度,数值越大,采样时间越长,相应的FPGA资源占用也越多。 pChsqLF.png图片 1.7 选择Run->Run pChsOZ4.png图片 或者直接点击主界面的Run按钮 pChsjo9.png图片 1.8 编译完成之后,保存退出。 pChsxiR.png图片 2.管脚分配,编译下载 2.1 和正常流程一样,管脚分配,编译下载。可以看到JTAG部分的管脚已经被IICE逻辑分析仪核使用了 pChyiLD.png图片 2.2 在Identify Debug Design上右键,选择Open Interactively,打开identify工具 pChymWt.png图片 3.设置触发类型 3.1 选择要触发的信号,和触发类型,这里我选择的是led,上升沿触发。 pChyYYn.png图片 3.2 连接FlashPro下载器,点击小人图标,启动抓取,满足触发条件自动停止。 pChy6YR.png图片 D:/identify_demo/synthesis$ run -iice {IICE} INFO: run -iice IICE INFO: Info: Attempting to connect to: usb Info: Type: FlashPro4 Info: ID: 08152 Info: Connection: usb2.0 Info: Revision: UndefRev INFO: Checking communication with the Microsemi_BuiltinJTAG cable and the hardware INFO: The hardware is responding correctly INFO: Auto-detecting the device chain INFO: Device at chain position 1 is "A2F200M3F" INFO: IICE 'IICE' configured, waiting for trigger INFO: IICE 'IICE' Trigger detected, downloading samples INFO: notify -notify INFO: waveform viewer INFO: waveform viewer INFO: write vcd -iice IICE -comment {Identify created VCD dump} -gtkwave -noequiv IICE.vcd D:/identify_demo/synthesis$ 3.3 右侧黄色的显示就是触发瞬间时信号的值。右键可以改变数据格式。 pChyO6f.png图片 3.4 选择Debugger preferences可以设置采样时钟的周期,用于后面波形的时间测量 pChyz7Q.png图片 3.5 设置采样时钟的周期 pCh6Chn.png图片 3.6 点击波形按钮,在GTKWave中打开抓取到的波形。 pCh6kcV.png图片 3.7 可以按住左键拖动测量时间差 pCh6uN9.png图片 3.8 还可以给每个通道设置不同的颜色,和显示方式。 pCh6Q91.png图片 4.IICE逻辑分析仪核资源占用 IICE逻辑分析仪核占用的主要是逻辑资源和RAM资源,可以看到资源占用还是很多的。 图片 图片 原文: https://blog.csdn.net/whik1194/article/details/107074187 参考: https://zhuanlan.zhihu.com/p/88314552 https://www.synopsys.com/zh-cn/implementation-and-signoff/fpga-based-design/identify-rtl-debugger.html http://training.eeworld.com.cn/video/1059 https://www.microsemi.com/document-portal/doc_view/132760-synopsys-identify-me-h-2013-03m-sp1-user-guide
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
2
2,904
2
2023-06-20
Microsemi Libero SOC常见问题-FPGA全局网络的设置
问题描述 最近在一个FPGA工程中分配rst_n引脚时,发现rst_n引脚类型为CLKBUF,而不是常用的INBUF,在分配完引脚commit检查报错,提示需要连接到全局网络引脚上。 Running Global Checker... Error:PLC002:No legal assignment exists for global net rst.n_c. Info:Uhlocking the driver or removing the region constraint for net rst nc may help to satisfy Error:PLC005:Automat ic global net placement failed. 尝试忽略这个错误,直接进行编译,在布局布线时又报错。 Error: PLC002: No legal assignment exists for global net rst_n_c. Error: PLC005: Automatic global net placement failed. Error: Failure when executing Tcl script. [ Line 18 ] 尝试取消引脚锁定LOCK,再次commit检查成功,编译下载正常,但是功能不对,再次打开引脚分配界面,发现是rst_n对应的引脚并不是我设置的那个,看来是CLKBUF的原因。 问题分析 网络上搜索一些资料后,发现是在一些工程中会出现这个问题,如果rst_n信号连接了许多IP核,和很多自己写的模块,这样rst_n就需要很强的驱动能力,即扇出能力(Fan Out),而且布线会很长,所以在分配管脚时,IDE自动添加了CLKBUF,来提供更大的驱动能力和更小的延时。那么什么是FPGA的全局时钟网络资源呢? FPGA全局布线资源简介 我们知道FPGA的资源主要由以下几部分组成: 可编程输入输出单元(IOB) 基本可编程逻辑单元(CLB) 数字时钟管理模块(DCM) 嵌入块式RAM(BRAM) 丰富的布线资源 内嵌专用硬件 模块。 我们重点介绍布线资源,FPGA中布线的长度和工艺决定着信号在的驱动能力和传输速度。FPGA的布线资源可大概分为4类: 全局布线资源:芯片内部全局时钟和全局复位/置位的布线 长线资源:完成芯片Bank间的高速信号和第二全局时钟信号的布线 短线资源:完成基本逻辑单元之间的逻辑互连和布线 分布式布线资源:用于专有时钟、复位等控制信号线。 一般设计中,我们不需要直接参与布线资源的分配,IDE中的布局布线器(Place and Route)可以根据输入逻辑网表的拓扑结构,和用户设定的约束条件来自动的选择布线资源。 其中全局布线资源具有最强的驱动能力和最小的延时,但是只能限制在全局管脚上,厂商会特殊设计这部分资源,如Xilinx FPGA中的全局时钟资源一般使用全铜层工艺实现,并设计了专门时钟缓冲和驱动结构,从而使全局时钟到达芯片内部的所有可配置逻辑单元(CLB)、I/O单元(IOB)和选择性块RAM(Block Select ROM)的时延和抖动都为最小。 一般全局布线资源都是针对输入信号来说的,如果IDE自动把rst_n引脚优化为了全局网络,而硬件电路设计上却把rst_n分配到了普通管脚上,那么就很麻烦了,要么牺牲全局网络的优势,手动将全局网络改为普通网络,要么为了利用全局网络的优势,修改电路,重新分配硬件引脚。所以如果一些关键的信号确定了,如时钟、复位等,产品迭代修改电路时,不要轻易调整这些关键引脚。 Microsemi FPGA的全局布线资源 Microsemi FPGA的全局时钟管脚编号,我们可以通过官方Datasheet来找到,在手册中关于全局IO的命名规则上,有如下介绍: 即只有管脚名称为GFA0/1/2,GFB0/1/2,GFC0/1/2,GCA0/1/2,GCB0/1/2,GCC0/1/2(共18个)才支持全局网络分配,而且,如果使用了GFA0引脚作为全局输入引脚,那么GFA1和GFA2都不能再作为全局网络了,其他GFC等同理,这一点在设计电路时要特别注意。 对于Microsemi SmartFusion系列FPGA芯片A2F200M3F-PQ208来说,只有7个,分别是:GFA0-15、GFA1-14、GFA2-13、GCA0-145、GCA1-146、GCC2-151、GCA2-153,引脚分配如下图所示: 所以在设计A2F200M3F-PQ208硬件电路时,时钟和复位信号尽量分配在这些管脚上,以获得硬件性能的最大效率。 这些全局引脚的延时时间都是非常小的,具体的时间参数可以从数据手册上获得。 全局网络改为普通输入 像文章开头介绍的情况,IDE自动把rst_n设置为全局网络,而实际硬件却不是全局引脚,应该怎么修改为普通输入呢?即CLKBUF改为普通的INBUF?网络上zlg的教程中使用的是版本较低的Libero IDE 8.0,新版的Libero SoC改动非常大,文中介绍的修改sdc文件的方法已经不能使用了,这里提供新的修改方法——调用INBUF IP Core的方式。 这里官方已经考虑到了,在官方提供的INBUF IP Core可以把CLKBUF改为INBUF。 在Catalog搜索框中输入:INBUF,可以看到这里也提供了LVDS信号专用的IP Core。 拖动到SmartDesign中进行连接 或者在源文件中直接例化的方式调用INBUF Core: INBUF INBUF_0( // Inputs .PAD ( rst_n ), // Outputs .Y ( rst_n_Y ) );这两种方法都是一样的。添加完成之后,再进行管脚分配,可以看到rst_n已经是普通的INBUF类型了,可以进行普通管脚的分配,而且commit检查也是没有错误的。 普通输入上全局网络 如果布局布线器没有把我们要的信号上全局网络,如本工程的CLK信号,IDE自动生成的是INBUF类型,我们想让他变成CLKBUF,即全局网络,来获取最大的驱动能力和最小的延时。那么应该怎么办呢? 这里同样要使用到一个IP Core,和INBUF类似,这个IP Core的名称是CLKBUF,同样是在Catalog目录中搜索:CLKBUF,可以看到有CLKBUF开头的很多Core,这里同样也提供了LVDS信号专用的IP Core。 可以直接拖动Core到SmartDesign图形编辑窗口: 或者是在源文件中以直接例化的方式调用: CLKBUF CLKBUF_0( // Inputs .PAD ( CLKA ), // Outputs .Y ( CLKA_Y ) );这两种方式都是一样的,添加完成之后,再进行管脚分配,可以看到CLKA已经是全局网络了,只能分配在全局管脚上。 总结 对于不同厂家的FPGA,让某个信号上全局网络的方法都不尽相同,如Xilinx的FPGA是通过BUFG Core来让信号上全局网络,而且还有带使能端的全局缓冲 BUFGCE , BUFGMUX 的应用更为灵活,有2个输入,可通过选择端选择输出哪一个。所以,信号的全局缓冲设置要根据不同厂商Core的不同来使用。
嵌入式&系统
FPGA&ASIC
IP&SOC设计
# 嵌入式
刘航宇
3年前
0
1,477
3
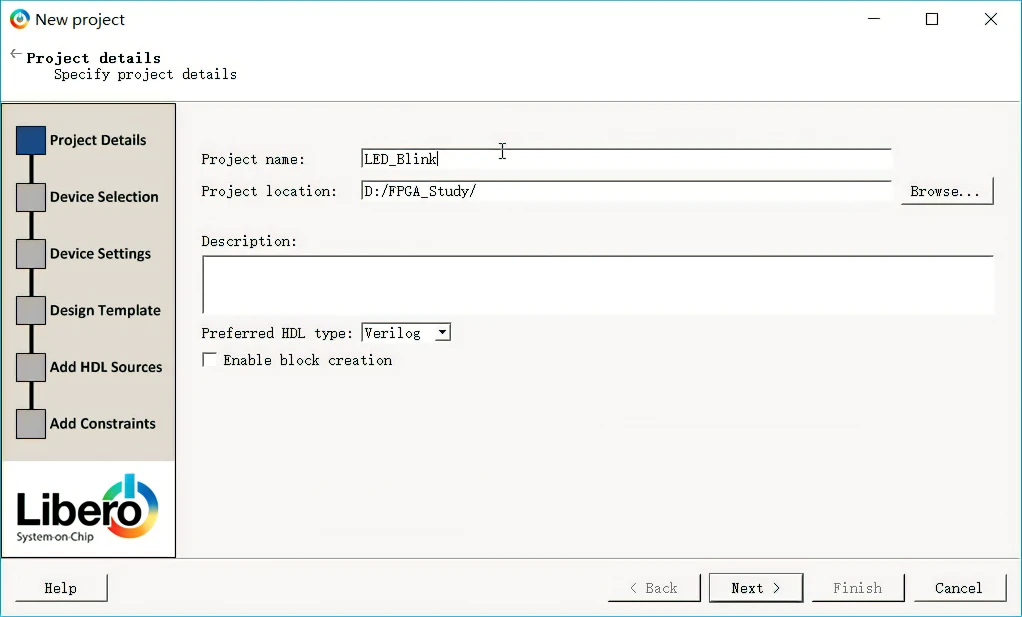
Microsemi Libero SOC使用示例—建立点灯工程
嵌入式开发中的Hello World,点灯是再也基础不过的实验了,通过点灯实验,可以了解芯片GPIO的控制和开发环境IDE新建工程的流程,对于FPGA来说,每个IO口几乎一样,所以本篇文章主要学习一下如何基于Microsemi Libero集成开发环境建立一个示例工程,让一个LED以500ms的频率闪烁,以Microsemi SmartFusion系列FPGA——A2F200M3F为例,Microsemi其他系列FPGA芯片过程类似。 准备工作软件准备: 硬件准备: 新建工程的主要步骤1.新建工程 2.添加设计文件 3.仿真验证 4.管脚分配 5.程序下载 Microsemi FPGA的Flash结构 准备工作 工欲利其事,必先利其器,充分的准备工作很有必要。 软件准备: Microsemi Libero SoC集成开发环境,并已经成功注册,软件版本推荐V11.8或更高版本。 硬件准备: Microsemi FPGA开发板,主控芯片A2F200M3F-PQ208,其他型号芯片类似。 Flash Pro 4或Flash Pro5下载器,用于给FPGA芯片下载程序和调试。 新建工程的主要步骤 新建工程,选择芯片型号等 新建设计,使用Verilog编写点灯模块。 仿真验证,对编写的点灯模块进行时序仿真,来验证是否满足设计需求。 综合、管脚分配、布局、布线。 生成程序文件,连接开发板,使用FlashPro下载程序到芯片内,观察现象是否和设计的一致。 1.新建工程 和大多数IDE一样,选择Project -> New Project,新建一个工程。 image.png图片 输入工程名称LED_Blink,选择工程存放的路径,工程名称和路径不要有中文字符和空格,选择源文件的类型Verilog或者VHDL。 image.png图片 选择芯片型号,这里选择Microsemi SmartFusion系列下的A2F200M3F芯片,PQ208封装,把鼠标放在所选芯片上,可以查看芯片的详细参数:封装、速度等级、温度范围,内核电压、Flash ROM大小、用户IO数目、RAM大小、Flash ROM大小,ARM Cortex-M3 SoC的外设配置等详细的参数。 图片 选择IO的电平标准,不同的电平标准,高低电平的电压范围是不同的,这里选择默认的LVTTL。 图片 是否创建MSS模块,MSS里有PLL和ARM Cortex-M3的使用,以后用到PLL和ARM核时再添加,这里先不选择,以后需要也可以再创建。 图片 是否导入已经存在的HDL文件,如果已经有一些写好的模块,可以在这里直接导入。 图片 是否导入已经存在的管脚约束文件,这里选择不添加,我们会在后面通过图形化工具来指定管脚。 图片 到这里,工程就创建完成了,然后会在存储路径下生成一个和工程名称一样的文件夹,工程相关的所以文件都存放在这里。主要包括以下几个文件夹: 图片 具体每个文件夹存放的是什么文件,我们在以后的文章再详细介绍。以上的工程配置在创建完工程之后,也可以再次更改,可以通过Project->Project Setting查看或更改配置: 图片 或者通过点击如下图标来进入配置界面: 图片 弹出如下窗口,和新建工程是一样的,可以更改FPGA的型号,但只限于同一个系列内。 2.添加设计文件 Microsemi Libero开发环境支持HDL方式和SmarDesign方式来创建设计,HDL方式支持VerilogHDL和VHDL两种硬件描述语言,而SmartDesign方式和Xilinx的Schematic原理图方式是一样的,是通过图形化的方式来对各个模块之间的连接方式进行编辑,两种方式都可以完成设计。由于本实验功能简单,所以以使用Verilog文件为例。 创建Verilog文件 创建Verilog文件有多种方式,可以直接双击左侧菜单中的Create Design->Create HDL 图片 或者点击File->New->HDL,这两种方式都可以创建一个Verilog设计文件,这里选择Verilog文件。 图片 输入模块名称:led_driver,不用添加.v后缀名,Libero软件会自动添加。 源代码: module led_driver( //input input clk, //clk=2MHz input rst_n, //0=reset //output output reg led ); parameter T_500MS = 999999; //1M reg [31:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 32'b0; else if(cnt >= T_500MS) cnt <= 32'b0; else //cnt < T_500MS cnt <= cnt + 32'b1; end always @ (posedge clk) begin if(!rst_n) led <= 1'b1; else if(cnt >= T_500MS) led <= ~led; end endmodule可以看到,代码非常的简单,定义一个计数器,系统时钟为2MHz=500ns,500ms=1M个时钟周期,当计数到500ms时,LED翻转闪烁。 3.仿真验证 编写完成,之后,点击对号进行语法检查,如果没有语法错误就可以进行时序仿真了。 新建Testbench文件 底部切换到Design Hierarchy选项卡,在led模块上右键选择Create Testbechch创建仿真文件,选择HDL格式。 图片 给创建的testbench文件名一般为模块名后加_tb,这里为:led_driver_tb,因为我们的板子外部晶体为2M,所以这里系统时钟周期为500ns,这个也可以在文件中更改。 图片 点击OK之后,可以看到,Libero软件已经为我们生成了一些基本代码,包括输入端口的定义,系统时钟的产生,输入信号的初始化等等。我们只需要再增加几行即可。 `timescale 1ns/100ps module led_driver_tb; parameter SYSCLK_PERIOD = 500;// 2MHZ reg SYSCLK; reg NSYSRESET; wire led; //add output reg initial begin SYSCLK = 1'b0; NSYSRESET = 1'b0; end initial begin #(SYSCLK_PERIOD * 10 ) NSYSRESET = 1'b0; //add system reset #(SYSCLK_PERIOD * 100 ) NSYSRESET = 1'b1; //add system set end always @(SYSCLK) //generate system clock #(SYSCLK_PERIOD / 2.0) SYSCLK <= !SYSCLK; led_driver led_driver_0 ( // Inputs .clk(SYSCLK), .rst_n(NSYSRESET), // Outputs .led(led ) //add port // Inouts ); endmodule仿真代码也非常简单,输入信号初始化,NSYSRESET在10个时钟周期之后拉低,100个时钟周期之后拉高。 使用ModelSim进行时序仿真 仿真代码语法检查无误后,可以进行ModelSim自动仿真,在安装Libero时,已经默认安装了ModelSim仿真软件,并和Libero进行了关联。直接双击Simulate,Libero会自动打开ModelSim。 图片 可以看到输入输出信号,已经为我们添加好了: 图片 先点击复位按钮,复位系统,然后设置要运行的时间,由于设计的是500ms闪烁一次,这里我们先运行2s,即2000ms,在ModelSim中2秒已经算是很长的时间了,然后点击时间右边的运行按钮,耐心等待,停止之后就会看到led按500ms变化一次的波形了,如下图所示,可以再添加一个cnt信号到波形观察窗口,可以看到cnt周期性的变化。 图片 使用2个光标的精确测量,可以看出,led每隔500ms翻转一次,说明程序功能是正确的。 4.管脚分配 与STM32等MCU不同,FPGA的引脚配置非常灵活,如STM32只有固定的几个引脚才能作为定时器PWM输出,而FPGA通过管脚分配可以设置任意一个IO口输出PWM,而且使用起来非常灵活,这也是FPGA和MCU的一个区别,当然其他的功能,如串口外设,SPI外设等等,都可以根据需要自己用HDL代码来实现,非常方便。 时序仿真正常之后,就可以进行管脚分配了,即把模块的输入输出端口,真正的分配到芯片实际的引脚上,毕竟我们的代码是要运行在真正的芯片上的。 打开引脚配置图形化界面 双击Create/Edit I/O Attributes,打开图形化配置界面,在打开之前,Libero会先进行综合(Synthesize)、编译(Complie),当都运行通过时,才会打开配置界面。 图片 分配管脚 管脚可视化配置工具使用起来非常简单:引脚号指定、IO的电平标准,内部上下拉等等,非常直观。把时钟、复位、LED这些管脚分配到开发板原理图中对应的引脚,在分配完成之后,可以点击左上角的commit and check进行检查。 图片 在分配完成之后,为了以后方便查看已经分配的引脚,可以导出一个pdc引脚约束文件,选择Designer窗口下的File->Export->Constraint File,会导出一个led_driver.pdc文件,保存在工程目录下的constraint文件夹。 图片 一些特殊管脚的处理 SmartFusion系列的FPGA芯片,在分配个别引脚,如35-39、43-47这些引脚时,直接不能分配,这些引脚属于MSS_FIO特殊引脚,具体怎么配置为通用IO,可以查看下一篇文章。而新一代的SmartFusion 2系列的FPGA芯片则没有这种情况。 5.程序下载 管脚分配完成之后,连接FlashPro下载器和开发板的JTAG接口,关闭Designer窗口,选择Program Device,耐心等待几分钟,如果连接正常,会在右侧输出编程信息:擦除、验证、编程等操作,下载完成之后,就会看到板子上的LED闪烁起来了。 Microsemi FPGA的Flash结构 和Altera、Xilinx不同,Microsemi FPGA在下载程序时,并不是下载程序到SPI Flash,而是直接下载到FPGA内部的。目前,FPGA 市场占有率最高的两大公司Xilinx和Altera 生产的 FPGA 都是基于 SRAM 工艺的,需要在使用时外接一个片外存储器以保存程序。上电时,FPGA 将外部存储器中的数据读入片内 RAM,完成配置后,进入工作状态;掉电后 FPGA 恢复为白片,内部逻辑消失。这样 FPGA 不仅能反复使用,还无需专门的 FPGA编程器,只需通用的 EPROM、PROM 编程器即可。而Microsemi的SmartFusion、SmartFusion2、ProASICS3、ProASIC3E系列基于Flash结构,具备反复擦写和掉电后内容非易失性, 因此基于Flash结构的FPGA同时具备了SRAM结构的灵活性和反熔丝结构的可靠性,这种技术是最近几年发展起来的新型FPGA实现工艺,目前实现的成本还偏高,没有得到大规模的应用。 示例工程下载 基于Libero V11.8.2.4的工程下载: LED_Blink.rar 下载地址:https://wcc-blog.oss-cn-beijing.aliyuncs.com/Libero/Libero-2/LED_Blink.rar 提取码:
嵌入式&系统
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# 嵌入式
# SOC设计
刘航宇
3年前
0
1,792
2
1
2
...
6
下一页