首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,773 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,474 阅读
3
【高数】形心计算公式讲解大全
8,922 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,679 阅读
5
Vivado-FPGA Verilog烧写固化教程
7,438 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
18(共101篇)
找到
101
篇与
18
相关的结果
- 第 2 页
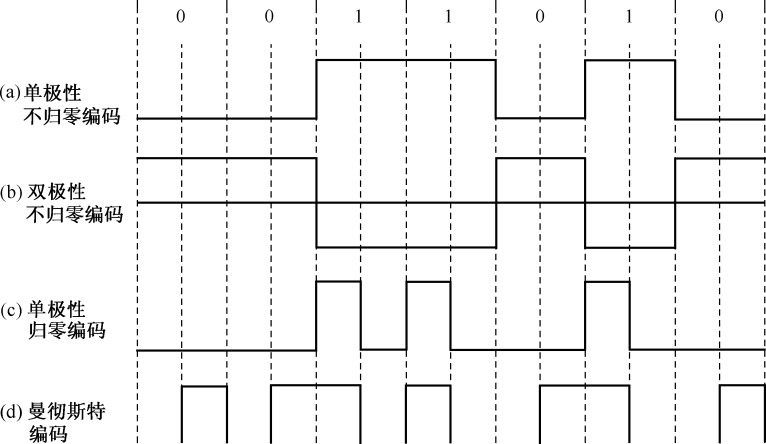
RFID编码简介
信号编码系统包括信源编码和信道编码两大类,器作用是把要传输的信息尽可能的与传输信道相匹配,并提供对信息的某种保护以防止信息受到干扰。信源编码与信源译码的目的是提高信息传输的有效性以及完成模数转换等;信道编码与信道译码的目的是增强信号的抗干扰能力,提高传输的可靠性。 常见的编码方法如下图: 图片 RFID系统常用编码方法: 反向不归零(NRZ)编码 曼彻斯特(Manchester)编码 单极性归零(RZ)编码 差动双相(DBP)编码 密勒(Miller)编码和差动编码 图片 1、反向不归零编码(NRZ,Non Return Zero) 反向不归零编码用高电平表示二进制“1”,低电平表示二进制“0”,如下图所示: 图片 此码型不宜传输,有以下原因 有直流,一般信道难于传输零频附近的频率分量; 接收端判决门限与信号功率有关,不方便使用; 不能直接用来提取位同步信号,因为NRZ中不含有位同步信号频率成分; 要求传输线有一根接地。 注:ISO14443 TYPE B协议中电子标签和阅读器传递数据时均采用NRZ 2、曼彻斯特编码(Manchester) 曼彻斯特编码也被称为分相编码(Split-Phase Coding)。 某比特位的值是由该比特长度内半个比特周期时电平的变化(上升或下降)来表示的,在半个比特周期时的负跳变表示二进制“1”,半个比特周期时的正跳变表示二进制“0”,如下图所示: 图片 曼彻斯特编码的特点 曼彻斯特编码在采用负载波的负载调制或者反向散射调制时,通常用于从电子标签到读写器的数据传输,因为这有利于发现数据传输的错误。这是因为在比特长度内,“没有变化”的状态是不允许的。 当多个标签同时发送的数据位有不同值时,则接收的上升边和下降边互相抵消,导致在整个比特长度内是不间断的负载波信号,由于该状态不允许,所以读写器利用该错误就可以判定碰撞发生的具体位置。 曼彻斯特编码由于跳变都发生在每一个码元中间,接收端可以方便地利用它作为同步时钟。 注: ISO14443 TYPE A协议中电子标签向阅读器传递数据时采用曼彻斯特编码。 ISO18000-6 TYPE B 读写器向电子标签传递数据时采用的是曼彻斯特编码 3、单极性归零编码(Unipolar RZ) 当发码1时发出正电流,但正电流持续的时间短于一个码元的时间宽度,即发出一个窄脉冲 当发码0时,完全不发送电流 单极性归零编码可用来提取位同步信号。 pPbm28I.png图片 4、差动双相编码(DBP) 差动双相编码在半个比特周期中的任意的边沿表示二进制“0”,而没有边沿就是二进制“1”,如下图所示。此外在每个比特周期开始时,电平都要反相。因此,对于接收器来说,位节拍比较容易重建。 pPbmR2t.png图片 5、密勒编码(Miller) 密勒编码在半个比特周期内的任意边沿表示二进制“1”,而经过下一个比特周期中不变的电平表示二进制“0”。一连串的比特周期开始时产生电平交变,如下图所示,因此,对于接收器来说,位节拍也比较容易重建。 pPbmhKf.png图片 pPbm5qS.png图片 6、修正密勒码编码 7、脉冲-间歇编码 对于脉冲—间歇编码来说,在下一脉冲前的暂停持续时间t表示二进制“1”,而下一脉冲前的暂停持续时间2t则表示二进制“0”,如下图所示。 pPbnUoQ.png图片 这种编码方法在电感耦合的射频系统中用于从读写器到电子标签的数据传输,由于脉冲转换时间很短,所以就可以在数据传输过程中保证从读写器的高频场中连续给射频标签供给能量。 8、脉冲位置编码(PPM,Pulse Position Modulation) 脉冲位置编码与上述的脉冲间歇编码类似,不同的是,在脉冲位置编码中,每个数据比特的宽度是一致的。 其中,脉冲在第一个时间段表示“00”,第二个时间段表示“01”, 第三个时间段表示“10”, 第四个时间段表示“11”, 如图所示 pPbnwJs.png图片 注:ISO15693协议中,数据编码采用PPM 9、FM0编码 FM0(即Bi-Phase Space)编码的全称为双相间隔码编码、 工作原理是在一个位窗内采用电平变化来表示逻辑。如果电平从位窗的起始处翻转,则表示逻辑“1”。如果电平除了在位窗的起始处翻转,还在位窗中间翻转则表示逻辑“0”。 pPbn0Wn.png图片 注:ISO18000-6 typeA 由标签向阅读器的数据发送采用FM0编码 10、PIE编码 PIE(Pulse interval encoding)编码的全称为脉冲宽度编码,原理是通过定义脉冲下降沿之间的不同时间宽度来表示数据。 在该标准的规定中,由阅读器发往标签的数据帧由SOF(帧开始信号)、EOF(帧结束信号)、数据0和1组成。在标准中定义了一个名称为“Tari”的时间间隔,也称为基准时间间隔,该时间段为相邻两个脉冲下降沿的时间宽度,持续为25μs。 pPbnBzq.png图片 注:ISO18000-6 typeA 由阅读器向标签的数据发送采用PIE编码 ============================================= 注:选择编码方法的考虑因素 编码方式的选择要考虑电子标签能量的来源 在REID系统中使用的电子标签常常是无源的,而无源标签需要在读写器的通信过程中获得自身的能量供应。为了保证系统的正常工作,信道编码方式必须保证不能中断读写器对电子标签的能量供应。 在RFID系统中,当电子标签是无源标签时,经常要求基带编码在每两个相邻数据位元间具有跳变的特点,这种相邻数据间有跳变的码,不仅可以保证在连续出现“0”时对电子标签的能量供应,而且便于电子标签从接收到的码中提取时钟信息。 编码方式的选择要考虑电子标签的检错的能力 出于保障系统可靠工作的需要,还必须在编码中提供数据一级的校验保护,编码方式应该提供这种功能。可以根据码型的变化来判断是否发生误码或有电子标签冲突发生。 在实际的数据传输中,由于信道中干扰的存在,数据必然会在传输过程中发生错误,这时要求信道编码能够提供一定程度的检测错误的能力。 曼彻斯特编码、差动双向编码、单极性归零编码具有较强的编码检错能力。 编码方式的选择要考虑电子标签时钟的提取 在电子标签芯片中,一般不会有时钟电路,电子标签芯片一般需要在读写器发来的码流中提取时钟。 曼彻斯特编码、密勒编码、差动双向编码容易使电子标签提取时钟。
通信&信息处理
# 通信&射频
# 软件算法
刘航宇
3年前
0
2,528
0
2023-07-21
嵌入式软件-无需排序找数字
题目 示例 解答code1 code2 题目 有1000个整数,每个数字都在1~200之间,数字随机排布。假设不允许你使用任何排序方法将这些整数有序化,你能快速找到从0开始的第450小的数字吗?(从小到大第450位) 示例 输入 - [184, 87, 178, 116, 194, 136, 187, 93, 50, 22, 163, 28, 91, 60, 164, 127, 141, 27, 173, 137, 12, 169, 168, 30, 183, 131, 63, 124, 68, 136, 130, 3, 23, 59, 70, 168, 194, 57, 12, 43, 30, 174, 22, 120, 185, 138, 199, 125, 116, 171, 14, 127, 92, 181, 157, 74, 63, 171, 197, 82, 106, 126, 85, 128, 137, 106, 47, 130, 114, 58, 125, 96, 183, 146, 15, 168, 35, 165, 44, 151, 88, 9, 77, 179, 189, 185, 4, 52, 155, 200, 133, 61, 77, 169, 140, 13, 27, 187, 95, 140, 196, 171, 35, 179, 68, 2, 98, 103, 118, 93, 53, 157, 102, 81, 87, 42, 66, 90, 45, 20, 41, 130, 32, 118, 98, 172, 82, 76, 110, 128, 168, 57, 98, 154, 187, 166, 107, 84, 20, 25, 129, 72, 133, 30, 104, 20, 71, 169, 109, 116, 141, 150, 197, 124, 19, 46, 47, 52, 122, 156, 180, 89, 165, 29, 42, 151, 194, 101, 35, 165, 125, 115, 188, 57, 144, 92, 28, 166, 60, 137, 33, 152, 38, 29, 76, 8, 75, 122, 59, 196, 30, 38, 36, 194, 19, 29, 144, 12, 129, 130, 177, 5, 44, 164, 14, 139, 7, 41, 105, 19, 129, 89, 170, 118, 118, 197, 125, 144, 71, 184, 91, 100, 173, 126, 45, 191, 106, 140, 155, 187, 70, 83, 143, 65, 198, 108, 156, 5, 149, 12, 23, 29, 100, 144, 147, 169, 141, 23, 112, 11, 6, 2, 62, 131, 79, 106, 121, 137, 45, 27, 123, 66, 109, 17, 83, 59, 125, 38, 63, 25, 1, 37, 53, 100, 180, 151, 69, 72, 174, 132, 82, 131, 134, 95, 61, 164, 200, 182, 100, 197, 160, 174, 14, 69, 191, 96, 127, 67, 85, 141, 91, 85, 177, 143, 137, 108, 46, 157, 180, 19, 88, 13, 149, 173, 60, 10, 137, 11, 143, 188, 7, 102, 114, 173, 122, 56, 20, 200, 122, 105, 140, 12, 141, 68, 106, 29, 128, 151, 185, 59, 121, 25, 23, 70, 197, 82, 31, 85, 93, 173, 73, 51, 26, 186, 23, 100, 41, 43, 99, 114, 99, 191, 125, 191, 10, 182, 20, 137, 133, 156, 195, 5, 180, 170, 74, 177, 51, 56, 61, 143, 180, 85, 194, 6, 22, 168, 105, 14, 162, 155, 127, 60, 145, 3, 3, 107, 185, 22, 43, 69, 129, 190, 73, 109, 159, 99, 37, 9, 154, 49, 104, 134, 134, 49, 91, 155, 168, 147, 169, 130, 101, 47, 189, 198, 50, 191, 104, 34, 164, 98, 54, 93, 87, 126, 153, 197, 176, 189, 158, 130, 37, 61, 15, 122, 61, 105, 29, 28, 51, 149, 157, 103, 195, 98, 100, 44, 40, 3, 29, 4, 101, 82, 48, 139, 160, 152, 136, 135, 140, 93, 16, 128, 105, 30, 50, 165, 86, 30, 144, 136, 178, 101, 39, 172, 150, 90, 168, 189, 93, 196, 144, 145, 30, 191, 83, 141, 142, 170, 27, 33, 62, 43, 161, 118, 24, 162, 82, 110, 191, 26, 197, 168, 78, 35, 91, 27, 125, 58, 15, 169, 6, 159, 113, 187, 101, 147, 127, 195, 117, 153, 179, 130, 147, 91, 48, 171, 52, 81, 32, 194, 58, 28, 113, 87, 15, 156, 113, 91, 13, 80, 11, 170, 190, 75, 156, 42, 21, 34, 188, 89, 139, 167, 171, 85, 57, 18, 7, 61, 50, 38, 6, 60, 18, 119, 146, 184, 74, 59, 74, 38, 90, 84, 8, 79, 158, 115, 72, 130, 101, 60, 19, 39, 26, 189, 75, 34, 158, 82, 94, 159, 71, 100, 18, 40, 170, 164, 23, 195, 174, 48, 32, 63, 83, 191, 93, 192, 58, 116, 122, 158, 175, 92, 148, 152, 32, 22, 138, 141, 55, 31, 99, 126, 82, 117, 117, 3, 32, 140, 197, 5, 139, 181, 19, 22, 171, 63, 13, 180, 178, 86, 137, 105, 177, 84, 8, 160, 58, 145, 100, 112, 128, 151, 37, 161, 19, 106, 164, 50, 45, 112, 6, 135, 92, 176, 156, 15, 190, 169, 194, 119, 6, 83, 23, 183, 118, 31, 94, 175, 127, 194, 87, 54, 144, 75, 15, 114, 180, 178, 163, 176, 89, 120, 111, 133, 95, 18, 147, 36, 138, 92, 154, 144, 174, 129, 126, 92, 111, 19, 18, 37, 164, 56, 91, 59, 131, 105, 172, 62, 34, 86, 190, 74, 5, 52, 6, 51, 69, 104, 86, 7, 196, 40, 150, 121, 168, 27, 164, 78, 197, 182, 66, 161, 37, 156, 171, 119, 12, 143, 133, 197, 180, 122, 71, 185, 173, 28, 35, 41, 84, 73, 199, 31, 64, 148, 151, 31, 174, 115, 60, 123, 48, 125, 83, 36, 33, 5, 155, 44, 99, 87, 41, 79, 160, 63, 63, 84, 42, 49, 124, 125, 73, 123, 155, 136, 22, 58, 166, 148, 172, 177, 70, 19, 102, 104, 54, 134, 108, 160, 129, 7, 198, 121, 85, 109, 135, 99, 192, 177, 99, 116, 53, 172, 190, 160, 107, 11, 17, 25, 110, 140, 1, 179, 110, 54, 82, 115, 139, 190, 27, 68, 148, 24, 188, 32, 133, 123, 82, 76, 51, 180, 191, 55, 151, 132, 14, 58, 95, 182, 82, 4, 121, 34, 183, 182, 88, 16, 97, 26, 5, 123, 93, 152, 98, 33, 135, 182, 107, 16, 58, 109, 196, 200, 163, 98, 84, 177, 155, 178, 110, 188, 133, 183, 22, 67, 164, 61, 83, 12, 86, 87, 86, 131, 191, 184, 115, 77, 117, 21, 93, 126, 129, 40, 126, 91, 137, 161, 19, 44, 138, 129, 183, 22, 111, 156, 89, 26, 16, 171, 38, 54, 9, 123, 184, 151, 58, 98, 28, 127, 70, 72, 52, 150, 111, 129, 40, 199, 89, 11, 194, 178, 91, 177, 200, 153, 132, 88, 178, 100, 58, 167, 153, 18, 42, 136, 169, 99, 185, 196, 177, 6, 67, 29, 155, 129, 109, 194, 79, 198, 156, 73, 175, 46, 1, 126, 198, 84, 13, 128, 183, 22] 输出 - 94 解答 解法一:1、不能排序 2、找从0开始的第450位小的数,注意的“从0开始”这句话。[0-450]这个区间总共有451个数,因此我们需要找的是第451位小的数 开始做题---------------------------------------------------------- 可以利用hash表的特性,使用一个201大小的数组,数组的下标为数据的值,数组的值为数据出现的次数。 可以这么理解 key->代表数据,同时也是数组下标 value->代表数据出现的次数 首先给数组元素初始化为0,也就是每个数据出现的次数都是0。 接着使用循环将每个数据出现的次数添加到数组中 再利用循环将出现的次数累加,如果次数累加到450,就说明找到了第450大的数 code1 /* 1、定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。使用memset函数将所有元素初始化为0。 2、定义一个整型变量i,用来作为循环的计数器。初始化为0。 3、使用while循环遍历数组numbers,对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。同时将i加一,表示下一个数。 4、重新将i赋值为1,表示从第一个数开始计算出现次数之和。 5、定义一个整型变量sum,用来累计前面的数出现的次数之和。初始化为0。 6、使用while循环遍历arr,从下标1开始,对于每个元素,将其加到sum上,然后判断sum是否大于或等于451。如果是,则跳出循环,表示找到了满足条件的数。如果不是,则继续遍历。 7、返回i,表示找到的数。 */ int find(int* numbers, int numbersLen ) { // write code here int arr[201], i=0, sum=0; //定义一个大小为201的整型数组arr,用来存储每个数在数组numbers中出现的次数。定义一个整型变量i,用来作为循环的计数器。定义一个整型变量sum,用来累计前面的数出现的次数之和。 //初始化数组元素 memset(arr,0,sizeof(arr)); //使用memset函数将所有元素初始化为0。 //循环添加每个数据出现的次数 while(i < numbersLen){ //使用while循环遍历数组numbers arr[numbers[i]]++; //对于每个数,将其作为arr的下标,将arr对应的元素加一,表示该数出现了一次。 i++; //同时将i加一,表示下一个数。 } //循环计算次数,当次数超过451次,那就是找到了 i=1; //重新将i赋值为1,表示从第一个数开始计算出现次数之和。 while((sum=sum+arr[i]) < 451){ //使用while循环遍历arr,从下标1开始 i++; //对于每个元素,将其加到sum上,并将i加一。 } return i; //返回i,表示找到的数。 } code2 解法二:因为知道每个数字的大小:1~200,所以无论序列有多少个数字,可以根据一个200行的表,然后统计所有数字出现的频率。 这个思路在硬件设计上常见,即用数字的值代表查表的地址。 /* 1、定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 2、遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 3、定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 4、遍历table,从下标1开始,对于每个元素,将其加到acc上,然后判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。如果不是,则继续遍历。 5、如果遍历完table都没有找到满足条件的数,则返回0。 */ /** * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 * * * @param numbers int整型一维数组 * @param numbersLen int numbers数组长度 * @return int整型 */ int find(int* numbers, int numbersLen ) { // write code here int table[201] = {0}; //定义一个大小为201的整型数组table,用来存储每个数在数组numbers中出现的次数。初始化为0。 for (int i = 0; i < numbersLen; i++) { table[numbers[i]]++; //遍历数组numbers,对于每个数,将其作为table的下标,将table对应的元素加一,表示该数出现了一次。 } int acc = 0; //定义一个整型变量acc,用来累计前面的数出现的次数之和。初始化为0。 for (int i = 1; i < 201; i++) { acc += table[i]; //遍历table,从下标1开始,对于每个元素,将其加到acc上。 if (acc >= 451) return i; //判断acc是否大于或等于451。如果是,则返回当前的下标,表示找到了满足条件的数。 } return 0; //如果遍历完table都没有找到满足条件的数,则返回0。 }
嵌入式&系统
编程&脚本笔记
# 嵌入式
# C/C++
刘航宇
3年前
0
376
0
2023-07-13
反向散射理论与ADG902电路实现
后向散射通信技术,是在天线对信号散射的基础上,采用标签后向散射的方式,通过改变发射端标签的反射系数来实现后向散射通信。无线电波在传输过程中,当通过不同介质时,因为介质阻抗的差异性,会产生反射作用,根据介质材料和阻抗的不同,会产生不同的反射量。因此通过调节天线端口的阻抗匹配度,入射的无线电波就可以产生不同反射量,导致入射信号和反射信号的差异性,也就是反射系数 Γ 。具体表示如下: $$\Gamma=\frac{Z_L-Z_0}{Z_L+Z_0}$$ 式中 Z0表示天线端的特征阻抗,一般是 50 Ω,ZL表示标签端口的输入阻抗,Γ表示入射信号振幅和反射信号振幅的复数比。当Γ=0 时,阻抗匹配,入射信号全部传递,无反射信号的产生;Γ = 1时,标签端的输入阻抗为开路,阻抗失配,入射信号被全部反射,产生幅值相同相位相同的反射信号;Γ = −1时,标签端的输入阻抗为短路状态,阻抗失配,入射信号被全部反射,产生幅值相同相位相反的反射信号。因此,通过改变标签的输入阻抗,产生不同的反射系数,就可以控制无线电波的入射和反射,实现有效信号的传递,这也就是后向散射通信的基本原理。为了实现上述后向散射通信,还需要加载天线端口的控制,结构如下图。通过射频开关来控制两个不同的负载阻抗与天线端口的连接,实现阻抗的匹配和失调,完成信号的入射和反射。当开关在负载 Z1和 Z2间转化时,由于负载阻抗的不同,载波信号在天线端的反射比例也不同,因此就产生了不同的调制载波。在实际通信中,为了达到最优传输质量,通常要使反射信号的差异最大,对应完全反射和完全吸收两种形式。对调制后的反射信号进行解调处理后,就可以得到所传递的基带信号,完成后向散射的通信。采用负载 50 Ω 的完全吸收和负载短路的完全反射两种信号传输差异,来实现后向散射的信息传输。 图片 使用后向散射开关 ADG 902 来实现基带信号对天线状态的控制,ADG 902 电路结构如图 4.12 所示。将数字基带信号的接入 ADG 902 的 CTRL 端,通过数字基带信号的“0”、“1”来控制 ADG 902 的关断和闭合,RF2 端连接射频天线。通过 ADG 902 中开关的关断,来控制天线对外界调制载波的反射和吸收。 注意:RF1接天线,RF2接地也可以,这里读者可自行证明 图片 当逻辑电平 CTRL=0时,S1关断,S2闭合,此时天线接收端口接地,由式可得,Z=0,T=1,载波信号被完全反射;当逻辑电平 CTRL=1 时,S1 闭合,S2 关断,此时天线接收端匹配,载波被完全吸收。
通信&信息处理
# 通信&射频
# 物联网
刘航宇
3年前
1
1,525
1
【转载】Libero SOC Debug教程-片上逻辑分析仪IDENTIFY
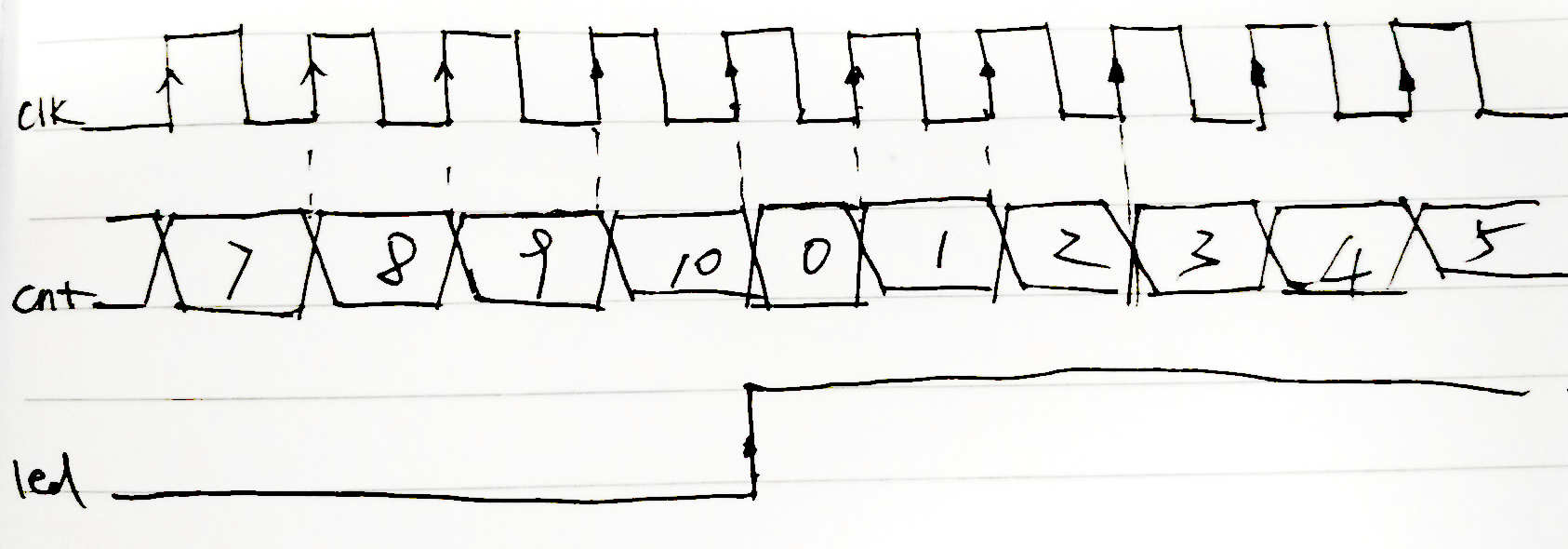
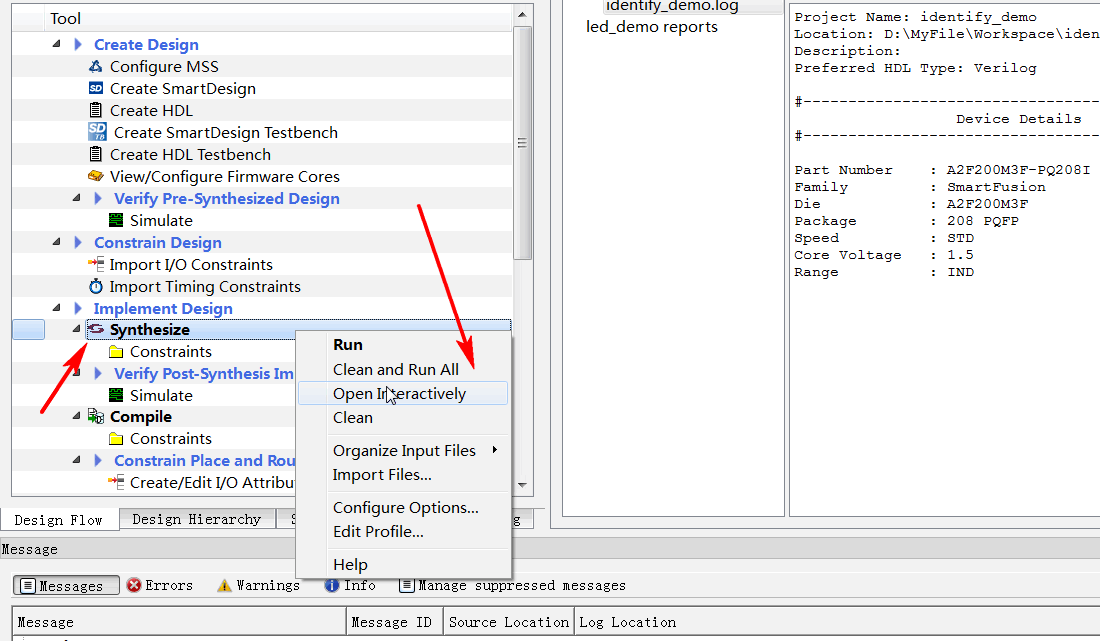
本文转载于https://blog.csdn.net/whik1194/article/details/107074187 FPGA在线调试 关于MICROSEMI片上逻辑分析仪 FPGA片上逻辑分析仪原理 预期效果 0.准备一个创建好的LIBERO工程 1.新建IDENTIFY工程,并添加想要监测的信号 2.管脚分配,编译下载 3.设置触发类型 4.IICE逻辑分析仪核资源占用 原文: 参考: FPGA在线调试 对于嵌入式系统来说,如单片机,进行硬件级程序调试时,通常采用的是JLink/ST-Link调试器,在线调试的方式来获取程序实时运行的状态,可以观察程序运行流程、各种变量的值、中断的触发情况,还可以设置断点、单步运行,方便快速的发现BUG,解决问题。 但是对于FPGA来说,并不是顺序执行的,而是根据每一个Clk并行执行,所以我们不能使用调试器进行单步调试。 FPGA调试需要观察内部信号的值,各个信号之间的时序关系,所以使用逻辑分析仪是最好的调试方式了。 有些FPGA工程,对外的接口,即输入输出,可能只有几个,但是他们之间的逻辑和时序关系非常复杂,所以内部有几十个中间寄存器,程序下载进去了,发现不是我们想要的效果,怎么办?你可能会说,查代码吧!如果这个工程非常简单,你可能只需要耗费几分钟或者几个小时就可以定位代码的问题所在。 但是如果这是一个非常庞大的工程,内部的中间寄存器、信号,几百上千个,各个模块单独软件仿真都正常,整体仿真也正常,就是下载到实际的芯片中运行不正常。你如何进行问题定位?如果再去进行代码审查,这将会消耗非常多的时间。那么如果能在FPGA芯片内部装上一个逻辑分析仪,那不就直接可以看到内部信号的值了,而且还可以看到各个信号之间的时序关系。需求推动技术发展,既然开发者有这个需求,那么FPGA厂商肯定会实现这个功能!下面来一起看一下Microsemi FPGA片上逻辑分析仪的使用方法吧! 关于MICROSEMI片上逻辑分析仪 几大厂商的片上逻辑分析仪: Xilinx厂商ISE开发环境下的ChipScope工具 Altera厂商Quartus开发环境下的SignalTap工具 Lattice厂商Diamod开发环境下的Reveal工具 对于 FPGA 工程师来说,这些都是很熟悉的名字。和以上几大FPGA厂商一样,Microsemi Libero也支持片上逻辑分析仪工具,只不过不是自己家研发的,使用的是Synospsy公司出品的Identify工具,其实,Libero中的综合器synplify也是Synospsy公司的。 根据Synospsy官网的描述:Identify RTL 调试仪,这个调试工具除了支持Microsemi的FPGA产品外,还支持Altera和Xilinx的FPGA产品。 FPGA片上逻辑分析仪原理 Identify片上逻辑分析仪的原理,是通过在FPGA工程中加入一个IICE逻辑分析仪IP核,这个IP核,由控制器和采集器组成,采集器用于采集信号,控制器用于和JTAG调试器连接,并把数据发送到上位机,IICE内部有RAM空间,用于存储触发位置附近的信号,RAM空间的大小,即采样深度,可以自己调整。FPGA工程中加入IICE核,会占用一定的资源,资源占用的大小取决于:采样深度,采样信号的个数,采样信号的触发方式等。 所以综上,FPGA片上逻辑分析仪需要3个组件:片上的IICE逻辑分析仪核、JTAG下载器、上位机。 pC5Uq6e.png图片 JTAG下载器也就是我们下载程序时使用的FlashPro x下载器,上位机软件也就是Identify工具,这个工具已经在安装Libero SoC时一同安装并注册**了。所以不需要安装其他的工具软件,只需要在已经设计好的FPGA公司中,配置一下IIC逻辑分析仪核就可以了。 在已经创建好的Libero工程中,加入IICE逻辑分析仪核,并演示Identify工具的使用。 预期效果 以Microsemi SmartFusion系列的A2F200M3F芯片为例,其他芯片使用操作方法类似。示例工程功能:led每隔10个clk翻转一次为例,演示identify的使用。 identify添加完成之后,把led设置为上升沿触发,会抓取到类似如下的波形。 pChB2qJ.png图片 0.准备一个创建好的LIBERO工程 这里以LED每隔10个时钟周期翻转为例。HDL文件内容: module led_demo( //inputs input clk, input rst_n, //outputs output reg led ); reg [3:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 0; else if(cnt == 10) /* max=10, 0-10 */ cnt <= 0; else cnt <= cnt + 1; end always @ (posedge clk) begin if(!rst_n) led <= 0; else if(cnt == 10) led <= ~led; end endmodule1.新建IDENTIFY工程,并添加想要监测的信号 1.0 先运行Synthesize 1.1 在Synthesize上右键,选择Open Interactively pChr5jO.png图片 1.2 在Synthesis上右键新建一个Identify工程 pChrTDe.png图片 1.3 输入新建的identify工程的名称和保存路径,选择默认的就行。 pChrqUA.png图片 1.4 在新建的identify工程上右键选择identify instrumentor pChsSKS.png图片 1.5 在HDL文件中选择要监测的信号和采样时钟,采样时钟选择Sample Clock,作为触发的信号选择Trigger Only,要监测的信号选择Sample Only,也可以选择Sample and Trigger,这样会占用更多的资源。 pChsG26.png图片 pChsNrD.png图片 设置完成的信号会有标注 pChsgsS.png图片 sample clock 表示采样时钟,所有在 IICE 中添加的信号都会在 sample clock 的边沿进行采样,设为 sample clock 的信号前会出现一个时钟状的图标。 设置为 sample 和 trigger 的信号都将作为被采样信号,区别在于 sample 信号只能被采样,而 trigger 信号可以作为触发采集的条件,当然你可以把一个信号同时设置为 sample 和 trigger 。 1.6 设置采样深度,选择Instrumentor->IICE pChsWZQ.png图片 采样深度最大支持1048576 pChsfaj.png图片 输入采样深度,数值越大,采样时间越长,相应的FPGA资源占用也越多。 pChsqLF.png图片 1.7 选择Run->Run pChsOZ4.png图片 或者直接点击主界面的Run按钮 pChsjo9.png图片 1.8 编译完成之后,保存退出。 pChsxiR.png图片 2.管脚分配,编译下载 2.1 和正常流程一样,管脚分配,编译下载。可以看到JTAG部分的管脚已经被IICE逻辑分析仪核使用了 pChyiLD.png图片 2.2 在Identify Debug Design上右键,选择Open Interactively,打开identify工具 pChymWt.png图片 3.设置触发类型 3.1 选择要触发的信号,和触发类型,这里我选择的是led,上升沿触发。 pChyYYn.png图片 3.2 连接FlashPro下载器,点击小人图标,启动抓取,满足触发条件自动停止。 pChy6YR.png图片 D:/identify_demo/synthesis$ run -iice {IICE} INFO: run -iice IICE INFO: Info: Attempting to connect to: usb Info: Type: FlashPro4 Info: ID: 08152 Info: Connection: usb2.0 Info: Revision: UndefRev INFO: Checking communication with the Microsemi_BuiltinJTAG cable and the hardware INFO: The hardware is responding correctly INFO: Auto-detecting the device chain INFO: Device at chain position 1 is "A2F200M3F" INFO: IICE 'IICE' configured, waiting for trigger INFO: IICE 'IICE' Trigger detected, downloading samples INFO: notify -notify INFO: waveform viewer INFO: waveform viewer INFO: write vcd -iice IICE -comment {Identify created VCD dump} -gtkwave -noequiv IICE.vcd D:/identify_demo/synthesis$ 3.3 右侧黄色的显示就是触发瞬间时信号的值。右键可以改变数据格式。 pChyO6f.png图片 3.4 选择Debugger preferences可以设置采样时钟的周期,用于后面波形的时间测量 pChyz7Q.png图片 3.5 设置采样时钟的周期 pCh6Chn.png图片 3.6 点击波形按钮,在GTKWave中打开抓取到的波形。 pCh6kcV.png图片 3.7 可以按住左键拖动测量时间差 pCh6uN9.png图片 3.8 还可以给每个通道设置不同的颜色,和显示方式。 pCh6Q91.png图片 4.IICE逻辑分析仪核资源占用 IICE逻辑分析仪核占用的主要是逻辑资源和RAM资源,可以看到资源占用还是很多的。 图片 图片 原文: https://blog.csdn.net/whik1194/article/details/107074187 参考: https://zhuanlan.zhihu.com/p/88314552 https://www.synopsys.com/zh-cn/implementation-and-signoff/fpga-based-design/identify-rtl-debugger.html http://training.eeworld.com.cn/video/1059 https://www.microsemi.com/document-portal/doc_view/132760-synopsys-identify-me-h-2013-03m-sp1-user-guide
嵌入式&系统
FPGA&ASIC
# ASIC/FPGA
# 嵌入式
刘航宇
3年前
2
3,056
2
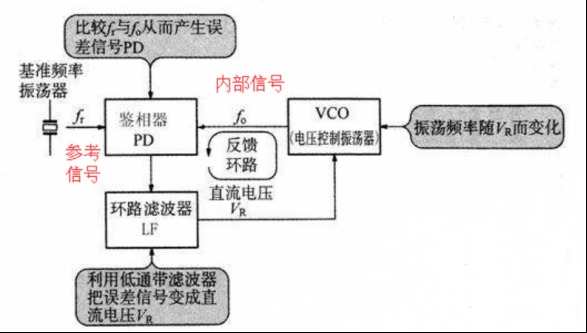
数字锁相环(DPLL)研究与设计
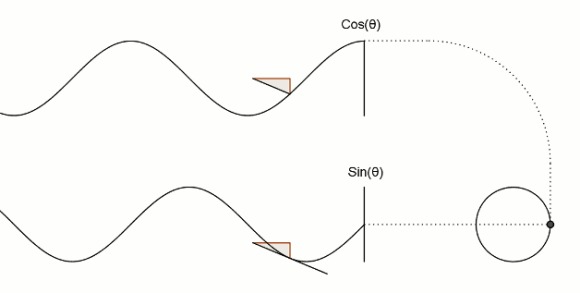
前言 工程代码下载 锁相环的原理和组成 数字锁相环的原理和组成 数字鉴相器设计DPD 数字振荡器(DCO) 数字缓冲器(DB) 数字锁相环(DPLL)的实现 电路硬件与性能评估 前言 随着数字电路技术的发展,数字锁相环在调制解调、频率合成、FM 立体声解码、彩色副载波同步、图象处理等各个方面得到了广泛的应用。数字锁相环不仅吸收了数字电路可靠性高、体积小、价格低等优点,还解决了模拟锁相环的直流零点漂移、器件饱和及易受电源和环境温度变化等缺点,此外还具有对离散样值的实时处理能力,已成为锁相技术发展的方向。 所谓数字PLL,就是指应用于数字系统的PLL,也就是说数字PLL中的各个模块都是以数字器件来实现的,是一个数字的电路。 数字锁相环的优点是电路最简单有效,可采用没有压控的晶振,降低了成本,提高了晶振的稳定性。但缺点是和模拟锁相环一样,一旦失去基准频率,输出频率立刻跳回振荡器本身的频率;另外还有一个缺点,就是当进行频率调整的时候,输出频率会产生抖动,频差越大,抖动会越大于密,不利于某些场合的应用。随着大规模、超高速的数字集成电路的发展,为数字锁相环路的研究与应用提供了广阔空间。由于晶体振荡器和数字调整技术的加盟,可以在不降低振荡器的频率稳定度的情况下,加大频率的跟踪范围,从而提高整个环路工作的稳定性与可靠性。 简单的说有两个不同来源的信号:一个信号是参考信号,这个信号一般是由芯片的晶振得到的信号,它具有信号的稳定性较好等优点,但是其频率是固定不变的。另一个信号是由芯片或者模块内部的压控振荡器得到的。这种由压控振荡器得到的信号可以是某范围内的任意频率的信号,但是这种信号的稳定型较差,容易受到外界干扰。 那么在实际使用过程中,我们需要一种频率能够变化的,同时质量较好的信号;或者对于一块芯片,我们需要不同的模块的内部时钟(这种时钟可以是压控振荡器产生)都能参考一个总的时钟来进行同步,从而避免两个模块内部时钟的差异而产生的数据传输的漂移等问题。因此,如何将压控振荡器得到的信号能够具有晶振信号的信号质量呢? 那就是通过PLL锁相环来实现,如图1所示。只要压控振荡器产生的时钟(下称输入信号)是参考信号的整数倍(或者整除倍),那么就能将输入信号先进行分频,后得到与参考信号频率相同的时钟,将分频后的信号和参考信号进行比较,从而使分频后的信号和参考信号保持相同的稳定的频率和相位。被分频后的信号稳定,也就是间接的表示输入信号的稳定。从而我们得到了一个频率在一定范围内可变的稳定的信号。 有上述可以看出,锁相环具有以下功能: (1)能够将一个信号和另一参考信号同步; (2)当这个信号是输出信号分频后得到的信号,PLL就能够得到参考信号的倍频信号(实际上倍频器很多都是利用了这个功能); (3)当输入信号频率可变、分频系数可变时,PLL就能够得到在频率一定范围内稳定信号。 图片 工程代码下载 DPLL 下载地址:https://wwek.lanzoub.com/iJLd5102ig6j 提取码: 锁相环的原理和组成 锁相环(PLL)的作用我们已经大概了解了,其最主要功能的实现,是在于如何将两个频率不同、相位差始终在变化的信号,变成两个相同频率、相同相位的信号。 这里引入一个概念,首先我们都知道,对于三角函数,只有两个同频率的三角函数才能比较其相位差。但这里的相位差是指两个正弦函数的初始相位差。而实际上根据三角函数的欧拉定义的理解来看,我们可以把三角函数看做是在某个圆上逆时针运动的点到x轴的距离。那么频率就是点在圆上运动的角速度,频率越大,其运动的角速度越大。相位就是点在圆上的位置,而初始相位就是点在圆上开始运动时的位置。当两个点的运动角速度相同时,我们可以得到两个点的初始位置差,就是两个正弦函数频率相同时,得到初始相位差。这个差值在运动过程中一直是不变的。但是当两个点运动角速度不同时,我们去看它的初始位置差是没有意义的,因为两个点的位置差是一直在变的,而初始位置差只是一个开始的位置差,是个不变的量,所以说对于频率不同的三角函数,我们讨论起初始相位差是没有意义的。但是不代表不能比较某一时刻两个点的位置。也就是相位差,相位是存在的。 图片 现在我们假设两个点在圆上赛跑,如图3所示,我们想让这两个点角速度相等。那么有一个办法就是以一个点为参考,参考点角速度不变,另一个点是速度可变点。每过一段时间,观察另一个点到参考点的位置,是在前,还是在后。如果在前,就让另一个点速度慢一点;如果在后,就让另一个点速度快一点。就这样不断调整另一个点的角速度,直到每次观察两个点都处于相同的位置。这样我们就可以认为这两个点达到了相同的速度。这种方法就是利用反馈调节来实现两个信号的同频同相。也就是锁相环(PLL)的实现原理。 首先通过一个鉴相器来得到两个信号之间的相位差。并根据相位差输出电压信号。然后通过滤波器稳压后得到稳定的电压信号,该信号驱动压控振荡器得到新的频率的信号。当两个信号存在相位差时,电压信号就会改变,从而使受控信号不断变化。直到当两个信号没有相位差时,电压信号不再改变,从而使受控信号保持当前频率,这时,受控信号不再变化了,就叫做受控信号被锁定了。 由上所述,一个锁相环由鉴相器、滤波器、振荡器三部分组成。外部输入是参考信号,内部输入和总的输出是受控信号。 数字锁相环的原理和组成 在数字电路中,原来模拟信号正弦波、余弦波的频率和相位变成了0和1的脉冲信号,那么我们如何理解数字信号中的频率和相位呢?对于脉冲信号来说,我们可以把频率理解为在某固定时间内脉冲出现的个数,为了方便表示,我们把上升沿的出现视为脉冲的出现,把相邻两个脉冲出现的时间t求倒数,就得到了该信号在这个时刻处的信号频率。而对于相位,相位差就是指,存在两个脉冲信号,以一个脉冲信号为参考,在其出现脉冲后,到另一个信号出现脉冲之间的时间差就是相位差,当另一个信号脉冲晚于参考信号脉冲出现的时间,称之为另一个信号的相位滞后于参考信号。当另一个信号的脉冲出现在参考信号之前,称之为另一个信号的相位提前于参考信号。 上述是一种较为简单的描述方式,适合初识脉冲信号的读者理解。而实际上,对于脉冲信号的频率、相位等问题,严格来说这样理解有一点点问题,但是对于我们来搭建数字锁相环DPLL来说足够了。其实这种三角函数和信号之间的转化,其根本的原理来源于傅里叶变换,从而我们对一个时间域上的信号(例如脉冲信号)可以进行频率域(其代表的三角函数的合成)上的分析。 我们知道了在数字电路中,脉冲信号也有了频率和相位的属性。那么我们的参考信号是以来时钟源的固定频率的信号,因为信号的质量比较好,所以该信号两个脉冲之间的时间差均是相同的,误差很小。我们在参考信号出现上升沿时,观察受控信号此时的状态。如果受控信号为高电平,我们就认为此时受控信号超前于参考信号;反之,如果受控信号是低电平,则认为此时的受控信号滞后于参考信号。当出现超前状态时,鉴相器会输出一个超前信号,超前信号会作用于振荡器,使得振荡器发出的受控信号频率降低。而滞后信号会使振荡器发出的受控信号频率升高,从而实现受控信号频率的反馈调节。 如图4所示,当参考信号出现上升沿时,受控信号为低电平,此时输出一个滞后信号。(由于模块只在时钟为上升沿时触发,所以超前信号的触发延迟了半个时钟周期) 图片 由此我们能够大概了解了数字锁相环中如何看待脉冲信号的频率和相位,如何处理得到相位差以及相位差如何在锁相环中起作用来实现信号频率的反馈控制。同模拟的锁相环(PLL)类似,数字锁相环(DPLL)也是由:数字鉴相器(Digital Phase Detector)、数字缓冲器(Digital Buffer)、数字振荡器(Digital Controlled Oscillator)三个模块构成,其外部输入为参考信号,内部输入和输出为受控信号。下面我们就来具体讨论如何用verilog实现各个模块。 数字鉴相器设计DPD 实现一个数字锁相环(DPLL),最重要的部分就是实现数字鉴相器(DPD)和数字振荡器(DF)。并且,这两个模块并不是独立存在的,而是说,数字振荡器的实现方式和数字振荡器的实现方式相互影响。所以只有两个模块共同设计,才能较好的实现一个数字锁相环的功能。 首先我们来具体讨论一下一个数字鉴相器应该具有那些功能和特性: 顾名思义,数字鉴相器就是能够鉴别两个数字信号相位的差别,并通过信号将这种差别表示出来。由上文我们已经知道了,对于两个矩形方波信号,其相位差可以看做是两个信号先后出现上升沿(或下降沿)之间的时间差。为了方便表示,假设以其中一个信号作为参考信号,另一个信号为受控信号,当参考信号出现上升沿(或下降沿)时,观察另一个信号是否已经出现了上升沿(或下降沿)。 如果还未出现上升沿(或下降沿),则叫做“受控信号滞后于参考信号”,或者简称“滞后”;如果已经出现了上升沿(或下降沿),则叫做“受控信号提前于参考信号”,或者简称“提前”。 而判断上升沿(或下降沿)是否已经出现,方法就是看当参考信号出现上升沿时,受控信号是1还是0:当受控信号为0,表示上升沿还没出现,所以是“滞后”;当受控信号为1,表示上升沿已经出现,所以是“提前”。对于下降沿也是按照同样的方法考虑。 图片 目前为止,我们已经有两个输入,参考信号和受控信号;两个输出,滞后信号和提前信号。如何通过verilog实现上述的输入输出关系呢?首先先讲异或与门,通过图4的描述,我们可以很容易看出来:滞后信号是参考信号与受控信号先异或,异或的结果和受控信号相与得到;提前信号是参考信号与受控信号先异或,异或的结果和参考信号相与得到。再加上一个RST的复位信号,我们可以得到如下图5电路: 图片 根据这个关系,来调节受控信号的频率,从而使受控信号的频率和参考信号最终相同。 再考虑,如果按照上述方法调节,当受控信号和参考信号频率相差很大时,就会出现刚开始有一段时间,受控信号的频率是不断变化,不可预知的。这样的调节效果实时性并不好,需要时间来稳定。因此读者想到,如果能够在参考信号出现上升沿时,就让受控信号也出现上升沿,相当于两个人在赛跑时,当一个人从起点出发时,无论另一个人在哪,强制让另一个人也回到原点,两个人一起从原点出发。这样就能使受控信号和参考信号强制达到相同的频率,只是此时受控信号的占空比不是50%。然后再根据滞后和提前信号,调节受控信号的占空比,从而最终达到50%的占空比。 按照这种方法,鉴相器就需要一个信号输出来表示上升沿的出现。再考虑到电路中的总的时钟源,我们这里采用触发的方法来实现。同时将上述的异或与门加入到代码中可以得到数字鉴相器的代码。但是在实际运用过程中发现,可能存在着受控信号先出现上升沿,从而过早的出现了提前或者滞后信号,导致数字振荡器的计数器上限呈现一个周期变化的不可控的数值的情况。为了避免这种情况,需要仔细考虑参考信号和受控信号如何生成提前和滞后信号这个问题,而不是简单的用异或来实现。如图6表示这种关系。 图片 按照上述代码写出来的数字鉴相器,具有更好的性能。根据这个表格,通过类似状态机的方法,来实现提前信号和滞后信号的输出。 数字振荡器(DCO) 现在我们已经构造出来了一个数字鉴相器,接下来我们将继续探讨如何实现一个数字振荡器(DCO)。 实现一个固定脉冲频率的信号,我们可以通过已知的时钟源,分频得到一定频率范围内的脉冲。具体实现方法就是通过计数器的方式,当出现时钟脉冲时,计数器+1,计数器上限就是分频系数,当计数器的数小于上限的1/2时,输出1,当计数器的数大于上限的1/2时,输出0,当计数器的数超过上限时,计数器归零。这样就能实现对时钟源的分频。 根据上述方法,只要改变计数器的上下限,就能改变分频系数,从而改变输出信号的频率。再参考上文受控信号和滞后提前信号的关系,我们就能通过根据滞后提前信号,改变计数器上下限,来实现对受控信号频率的控制。当计数器上限增加时,分频系数增加,频率减小;当计数器上限减小时,分频系数减小,频率增加;因此有: 滞后信号——>受控信号的频率小——>增加受控信号的频率——>计数器上限减小 提前信号——>受控信号的频率大——>减小受控信号的频率——>计数器上限增加 此外根据上述对上升沿触发同步的说法,当出现上升沿触发信号时,受控信号应强制产生上升沿,即受控信号强制从该脉冲周期的开始处开始,即计数器的数回到0从新开始计数。 综上所述,再加上复位信号,一个数字振荡器的所有构成就有了。到这里,一个数字锁相环(DPLL)其实就已经能够实现了,因为数字滤波器(DB)只是让受控信号的抗干扰能力更强,如图所示是仿真后的结果: 图片 数字缓冲器(DB) 下面再介绍一下数字缓冲器,来使受控信号的抗干扰能力更强。前面我们知道了,持续一个时钟周期的提前信号或者滞后信号能够使数字振荡器的计数器上限加一或者减一。当我的预设的数字振荡器的计数器上限与实际的参考信号的频率对应的计数器上限两个数值相差很大时,就有可能出现锁相环调节时间过长等现象。为了解决这种情况,如果能够让原来持续一个周期的提前信号或滞后信号成倍数的增加,变成持续n个周期的提前信号或者滞后信号,就能够使数字振荡器的计数器上限修改更快,从而更快的到达参考频率附近。但是相应的,受控信号的频率精度就会降低。也就是说,牺牲精度,追求速度。 同时考虑另外一种情况,如果我对速度要求不高,但是对于精度要求较高,同时在信号传输过程中可能存在干扰,导致接收到的提前信号或滞后信号不是完全真实的信号,此时就可以通过一个累加器,只有接受到n个周期的提前信号,或者滞后信号,才对数字振荡器输出一个进位信号或者借位信号,此时数字振荡器的计数器上限才只加减1,这样就能有效的提高精度,减少信号干扰带来的影响。但是这种做法牺牲了数字锁相换锁定的时间。 综上所述,一个时钟周期的提前或滞后信号,对应n个时钟周期的借位或进位信号,是提高锁定速度,降低锁定精度。想法,n个时钟周期的提前或滞后信号,对应一个时钟周期的借位或进位信号,是提高锁定精度,降低锁定速度。因此在实际运用中,应该按照自己的工程需要,合理选择比值。 上述过程的实现方法,是通过一个计数器,当接收到一个提前或滞后信号时,计数器加a,当输出一个进位或借位信号时,计数器减b,调节a和b的比值,就能实现上述过程。 数字缓冲器的仿真效果: 1、分时效果 图片 2、倍时效果 图片 数字锁相环(DPLL)的实现 所有的子模块都已经实现了,剩下的数字锁相环的实现,根据实际的要求,将上述几个模块进行例化就行。例化后的测试结果如图9所示,可以看到受控信号逐渐与参考信号对齐达到锁相环效果。 图片 为了方便起见,对输出信号进行2分频,再次观察输出结果,输出相当于2倍频了,成功完成PD、DCO、Divider等模块正确设计。 图片 电路硬件与性能评估 图11为电路硬件图从图中可以看出各模块的连接关系,每个模块由基本门电路构成。通过性能优化后的的电路如图12所示。 图片 利用SMIC180nm工艺进行电路综合, 时序报告:周期2ns 图片 面积报告:2119um2 图片 功耗报告:uw级别 图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
1
3,878
3
2023-06-20
Microsemi Libero SOC常见问题-FPGA全局网络的设置
问题描述 最近在一个FPGA工程中分配rst_n引脚时,发现rst_n引脚类型为CLKBUF,而不是常用的INBUF,在分配完引脚commit检查报错,提示需要连接到全局网络引脚上。 Running Global Checker... Error:PLC002:No legal assignment exists for global net rst.n_c. Info:Uhlocking the driver or removing the region constraint for net rst nc may help to satisfy Error:PLC005:Automat ic global net placement failed. 尝试忽略这个错误,直接进行编译,在布局布线时又报错。 Error: PLC002: No legal assignment exists for global net rst_n_c. Error: PLC005: Automatic global net placement failed. Error: Failure when executing Tcl script. [ Line 18 ] 尝试取消引脚锁定LOCK,再次commit检查成功,编译下载正常,但是功能不对,再次打开引脚分配界面,发现是rst_n对应的引脚并不是我设置的那个,看来是CLKBUF的原因。 问题分析 网络上搜索一些资料后,发现是在一些工程中会出现这个问题,如果rst_n信号连接了许多IP核,和很多自己写的模块,这样rst_n就需要很强的驱动能力,即扇出能力(Fan Out),而且布线会很长,所以在分配管脚时,IDE自动添加了CLKBUF,来提供更大的驱动能力和更小的延时。那么什么是FPGA的全局时钟网络资源呢? FPGA全局布线资源简介 我们知道FPGA的资源主要由以下几部分组成: 可编程输入输出单元(IOB) 基本可编程逻辑单元(CLB) 数字时钟管理模块(DCM) 嵌入块式RAM(BRAM) 丰富的布线资源 内嵌专用硬件 模块。 我们重点介绍布线资源,FPGA中布线的长度和工艺决定着信号在的驱动能力和传输速度。FPGA的布线资源可大概分为4类: 全局布线资源:芯片内部全局时钟和全局复位/置位的布线 长线资源:完成芯片Bank间的高速信号和第二全局时钟信号的布线 短线资源:完成基本逻辑单元之间的逻辑互连和布线 分布式布线资源:用于专有时钟、复位等控制信号线。 一般设计中,我们不需要直接参与布线资源的分配,IDE中的布局布线器(Place and Route)可以根据输入逻辑网表的拓扑结构,和用户设定的约束条件来自动的选择布线资源。 其中全局布线资源具有最强的驱动能力和最小的延时,但是只能限制在全局管脚上,厂商会特殊设计这部分资源,如Xilinx FPGA中的全局时钟资源一般使用全铜层工艺实现,并设计了专门时钟缓冲和驱动结构,从而使全局时钟到达芯片内部的所有可配置逻辑单元(CLB)、I/O单元(IOB)和选择性块RAM(Block Select ROM)的时延和抖动都为最小。 一般全局布线资源都是针对输入信号来说的,如果IDE自动把rst_n引脚优化为了全局网络,而硬件电路设计上却把rst_n分配到了普通管脚上,那么就很麻烦了,要么牺牲全局网络的优势,手动将全局网络改为普通网络,要么为了利用全局网络的优势,修改电路,重新分配硬件引脚。所以如果一些关键的信号确定了,如时钟、复位等,产品迭代修改电路时,不要轻易调整这些关键引脚。 Microsemi FPGA的全局布线资源 Microsemi FPGA的全局时钟管脚编号,我们可以通过官方Datasheet来找到,在手册中关于全局IO的命名规则上,有如下介绍: 即只有管脚名称为GFA0/1/2,GFB0/1/2,GFC0/1/2,GCA0/1/2,GCB0/1/2,GCC0/1/2(共18个)才支持全局网络分配,而且,如果使用了GFA0引脚作为全局输入引脚,那么GFA1和GFA2都不能再作为全局网络了,其他GFC等同理,这一点在设计电路时要特别注意。 对于Microsemi SmartFusion系列FPGA芯片A2F200M3F-PQ208来说,只有7个,分别是:GFA0-15、GFA1-14、GFA2-13、GCA0-145、GCA1-146、GCC2-151、GCA2-153,引脚分配如下图所示: 所以在设计A2F200M3F-PQ208硬件电路时,时钟和复位信号尽量分配在这些管脚上,以获得硬件性能的最大效率。 这些全局引脚的延时时间都是非常小的,具体的时间参数可以从数据手册上获得。 全局网络改为普通输入 像文章开头介绍的情况,IDE自动把rst_n设置为全局网络,而实际硬件却不是全局引脚,应该怎么修改为普通输入呢?即CLKBUF改为普通的INBUF?网络上zlg的教程中使用的是版本较低的Libero IDE 8.0,新版的Libero SoC改动非常大,文中介绍的修改sdc文件的方法已经不能使用了,这里提供新的修改方法——调用INBUF IP Core的方式。 这里官方已经考虑到了,在官方提供的INBUF IP Core可以把CLKBUF改为INBUF。 在Catalog搜索框中输入:INBUF,可以看到这里也提供了LVDS信号专用的IP Core。 拖动到SmartDesign中进行连接 或者在源文件中直接例化的方式调用INBUF Core: INBUF INBUF_0( // Inputs .PAD ( rst_n ), // Outputs .Y ( rst_n_Y ) );这两种方法都是一样的。添加完成之后,再进行管脚分配,可以看到rst_n已经是普通的INBUF类型了,可以进行普通管脚的分配,而且commit检查也是没有错误的。 普通输入上全局网络 如果布局布线器没有把我们要的信号上全局网络,如本工程的CLK信号,IDE自动生成的是INBUF类型,我们想让他变成CLKBUF,即全局网络,来获取最大的驱动能力和最小的延时。那么应该怎么办呢? 这里同样要使用到一个IP Core,和INBUF类似,这个IP Core的名称是CLKBUF,同样是在Catalog目录中搜索:CLKBUF,可以看到有CLKBUF开头的很多Core,这里同样也提供了LVDS信号专用的IP Core。 可以直接拖动Core到SmartDesign图形编辑窗口: 或者是在源文件中以直接例化的方式调用: CLKBUF CLKBUF_0( // Inputs .PAD ( CLKA ), // Outputs .Y ( CLKA_Y ) );这两种方式都是一样的,添加完成之后,再进行管脚分配,可以看到CLKA已经是全局网络了,只能分配在全局管脚上。 总结 对于不同厂家的FPGA,让某个信号上全局网络的方法都不尽相同,如Xilinx的FPGA是通过BUFG Core来让信号上全局网络,而且还有带使能端的全局缓冲 BUFGCE , BUFGMUX 的应用更为灵活,有2个输入,可通过选择端选择输出哪一个。所以,信号的全局缓冲设置要根据不同厂商Core的不同来使用。
嵌入式&系统
FPGA&ASIC
IP&SOC设计
# 嵌入式
刘航宇
3年前
0
1,544
3
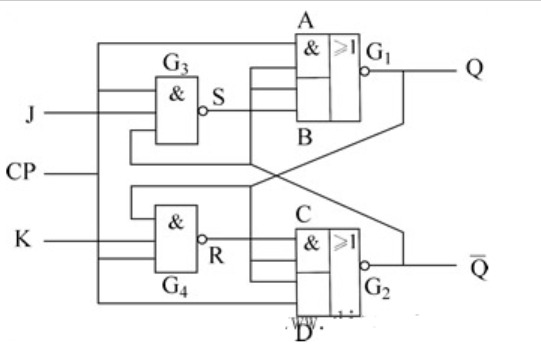
【电路基础】ASIC角度练习JK触发器&RS触发器
由于本电路极其简单,原理不做解释 目录 JK触发器真值表 硬件描述语言 JK触发器时序 JK触发器电路图 JK触发器性能--SMIC180nm工艺 RS触发器真值表 RS硬件描述语言 RS触发器时序 RS触发器电路图 RS触发器性能--SMIC180nm工艺 JK触发器 真值表 图片 硬件描述语言 代码 //边沿JK触发器-时序逻辑 //作者:刘航宇 2023/4/15 //Email:hyliu@ee.ac.cn module jk_trigger(clk,j,k,q,qb); input clk,j,k; output q,qb; reg q; wire qb; always @(posedge clk) begin case ({j,k}) 2'b00: q<=1; //jk=00,保持 2'b01: q<=1'b0; //jk=01,则触发器置0 2'b10: q<=1'b1; //jk=10,则触发器置1 2'b11: q<=~q; //11,翻转 //组合逻辑中,为避免生成锁存器,好的代码风格是if语句都加上else,case语句都加上default。 //时序逻辑中,“若无必要,尽量不加else和default”——以减小数据翻转机会,低功耗。 //故此处不写default endcase end assign qb = ~q; endmodule测试文件 //jk触发器测试文件 `timescale 1ns/1ps module jk_trigger_tb; reg j,k,clk;//输入reg是因为要initial wire q,qb; always begin #5 clk = ~clk; end //初始化 //下面这个产生fsdb是Synopsys VCS&Makefile脚本会用到,如果你用Medelsim仿真请删掉这个initial语句以免报错 initial begin $fsdbDumpfile("tb.fsdb");//这个是产生名为tb.fsdb的文件 $fsdbDumpvars; end initial begin clk = 0; j = 1'b0; k = 1'b0;//保持 #30 begin j=1'b0;k=1'b1; end //置0 #20 begin j=1'b1;k=1'b0; end //置1 #20 begin j=1'b0;k=1'b0; end //保持 #20 begin j=1'b1;k=1'b1; end //翻转 #200 $finish; end jk_trigger u1(.j(j),.k(k),.clk(clk),.q(q),.qb(qb)); endmoduleJK触发器时序 上升沿触发,可以看到时序完全正确 图片 JK触发器电路图 图片 之所以这样综合电路综合出一个D触发器,是考虑标准单元库的面积与时序的折中,标准单元相当于基本晶体管搭建而成,比如反相器占用2个晶体管,与非门占用4个晶体管,具体不在赘叙。 图片 图片 JK触发器性能--SMIC180nm工艺 图片 RS触发器 真值表 图片 RS硬件描述语言 代码 //边沿JK触发器-时序逻辑 //作者:刘航宇 2023/4/15 //Email:hyliu@ee.ac.cn module rs_trigger( input wire clk,r,s, output reg q, output wire qb ); always @(posedge clk) begin case ({r,s}) 2'b00: q<=q; //r,s同时为低电平,触发器保持状态不变 2'b01: q<=1'b1; //触发器置1 2'b10: q<=1'b0; //触发器置0 2'b11: q<=1'bx; //不定态 endcase end assign qb = ~q; endmodule测试代码 `timescale 1ns/1ps module rs_trigger_tb(); reg clk,r,s; wire q,qb; always begin #5 clk = ~clk; end //初始化 initial begin clk = 0; r = 1'b0; s = 1'b0;//保持 #30 r=1'b0;s=1'b1; //置1 #20 r=1'b1;s=1'b0; //置0 #20 r=1'b0;s=1'b0; //保持 #20 r=1'b1;s=1'b1; //禁止 #200 $stop; end rs_trigger u2(.clk(clk),.r(r),.s(s),.q(q),.qb(qb)); endmoduleRS触发器时序 上升沿触发,可以看到时序完全正确 图片 RS触发器电路图 image.png图片 image.png图片 image.png图片 RS触发器性能--SMIC180nm工艺 image.png图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
1,492
2
【硬件算法进阶】Verilog实现802.3 CRC-32校验运算电路
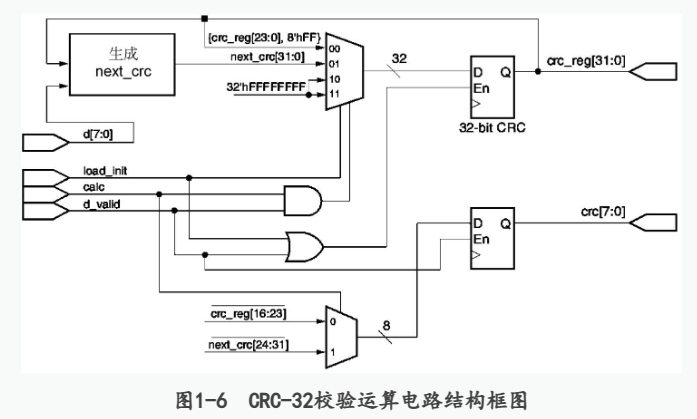
循环冗余校验(Cyclic Redundancy Check,CRC)是通信中常用的差错检测编码方式,其基本工作原理是根据输入的信息位(信息码元),按照给定的生成多项式产生校验位(校验码元),并一起传送到接收端。在接收端,接收电路按照相同的规则对接收数据进行计算并生成本地的校验位,然后与收到的校验位进行对比,如果二者不同,则说明传输过程中发生了错误,否则说明传输是正确的。带有CRC校验结果的数据帧结构如表1-2所示。 image.png图片 CRC检验位生成与检测工作包括以下基本步骤。 image.png图片 图1-6是一个并行CRC-32校验运算电路。图中的d[7:0]是输入的用户数据,它是按照字节的方式输入的。load_ini是在对一个新的数据包开始校验计算之前对电路进行初始化的控制信号,经过初始化后,电路内部32比特寄存器的值改变为全1。calc是电路运算指示信号,在整个数据帧输入和CRC校验结果输出的过程中其都应该保持有效(高电平有效)。d_valid为1时表示当前输入的是需要进行校验运算的有效数据。crc[7:0]是电路输出的CRC校验运算结果,它是按照字节方式,在有效数据输入完成后开始输出的,一共有4个有效字节。crc_reg[31:0]是内部寄存器的值,具体使用时不需要该输出。 image.png图片 并行计算的思想,输入数据S要并行输入到G(x)系数为1的支路中,输入数据从输入端按高到低逐bit输入,就可以实现。 假如被除数是2位的数据S[1:0]=01,多项式是10011,x4 +x+1。在CRC校验里面,习惯省略最高位的1,多项式用0011表示。那么S除以0011的模二运算数字电路结构为: image.png图片 其中d1~ d4是寄存器输入;q1~q4是寄存器输出。寄存器需要赋初值,一般赋全1或全0。 d1=S[1]^q4; d2= S[1]^ q1^q4; d3=q2; d4=q3。 经过一次移位后: q1=d1= S[1]^q4; q2= d2= S[1]^ q1^q4; q3= d3=q2; q4= d4=q3。 此时有: d1=S[0]^q3; d2= S[0]^ S[1]^ q4^q3; d3= S[1]^ q1^q4; d4= q2。 令c[3:0]={q4,q3,q2,q1},d[3:0]={d4,d3,d2,d1},那么d就是最终的运算结果表达式,如下 d[3]=c[1]; d[2]= S[1]^ c[0]^c[3]; d[1]= S[0]^ S[1]^ c[3]^ c[2]; d[0]= S[0]^ c[2]。 令c的初值为0,则01对0011的模二除法的余数为0011。 再比如多项式为x5 +x3 +x+1,简记式为01011,其数字电路结构为: image.png图片 输入数据S要全部输入完,寄存器得到的结果才是最后的结果。同理可推导出其他多项式和输入数据的情况。 对于循环检验,这里举个例子,如果数据是10bit*100个包,则每次输入10bit得到校验码后,该检验码为下次数据计算时寄存器D的初值,如此反复计算得到最后的检验码添加到整个数据后面即可,而不需要每个数据包后面都添加检验码。 下面是以太网循环冗余校验电路的设计代码: module crc32_8023( clk, reset, d, load_init, calc, d_valid, crc_reg, crc ); input clk; input reset; input [7:0] d; input load_init; input calc; input d_valid; output reg [31:0] crc_reg; output reg [7:0] crc; wire [2:0] ctl; wire [31:0] next_crc; wire [31:0] i; assign i = crc_reg; assign ctl = {load_init,calc,d_valid}; always @(posedge clk or posedge reset) begin if(reset) crc_reg <= 32'hffffffff; else begin case (ctl) //{load_init,calc,d_vaild} 3'b000,3'b010: begin crc_reg <= crc_reg; crc <= crc;end 3'b001: begin crc_reg <= {crc_reg[23:0],8'hff}; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b011: begin crc_reg <= next_crc[31:0]; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end 3'b100,3'b110: begin crc_reg <= 32'hffffffff; crc <= crc; end 3'b101: begin crc_reg <= 32'hffffffff; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b111: begin crc_reg <= 32'hffffffff; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end endcase end end assign next_crc[0] = d[7]^i[24]^d[1]^i[30]; //d+i=31 assign next_crc[1] = d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[30]^i[31]; assign next_crc[2] = d[5]^d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[26]^i[30]^i[31]; assign next_crc[3] = d[4]^d[5]^d[6]^d[0]^i[25]^i[26]^i[27]^i[31]; assign next_crc[4] = d[3]^d[4]^d[5]^d[7]^d[1]^i[24]^i[26]^i[27]^i[28]^i[30]; assign next_crc[5] = d[0]^d[1]^d[2]^d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[29]^i[30]^i[31]; assign next_crc[6] = d[0]^d[1]^d[2]^d[3]^d[5]^d[6]^i[25]^i[26]^i[28]^i[29]^i[30]^i[31]; assign next_crc[7] = d[0]^d[2]^d[4]^d[5]^d[7]^i[24]^i[26]^i[27]^i[29]^i[31]; assign next_crc[8] = d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[0]; //每项多出i[i],i=0、1、2...23 assign next_crc[9] = d[2]^d[3]^d[5]^d[6]^i[1]^i[25]^i[26]^i[28]^i[29]; assign next_crc[10] =d[2]^d[4]^d[5]^d[7]^i[2]^i[24]^i[26]^ i[27]^i[29]; assign next_crc[11] =i[3]^d[3]^i[28]^d[4]^i[27]^d[6]^i[25]^d[7]^i[24]; assign next_crc[12] =d[1]^d[2]^d[3]^d[5]^d[6]^d[7]^i[4]^i[24]^i[25]^i[26]^i[28]^i[29]^i[30]; assign next_crc[13] =d[0]^d[1]^d[2]^d[4]^d[5]^d[6]^i[5]^i[25]^i[26]^i[27]^i[29]^i[30]^i[31]; assign next_crc[14] =d[0]^d[1]^d[3]^d[4]^d[5]^i[6]^i[26]^i[27]^i[28]^i[30]^i[31]; assign next_crc[15] =d[0]^d[2]^d[3]^d[4]^i[7]^i[27]^i[28]^i[29]^i[31]; assign next_crc[16] =d[2]^d[3]^d[7]^i[8]^i[24]^i[28]^i[29]; assign next_crc[17] =d[1]^d[2]^d[6]^i[9]^i[25]^i[29]^i[30]; assign next_crc[18] =d[0]^d[1]^d[5]^i[10]^i[26]^i[30]^i[31]; assign next_crc[19] =d[0]^d[4]^i[11]^i[27]^i[31]; assign next_crc[20] =d[3]^i[12]^i[28]; assign next_crc[21] =d[2]^i[13]^i[29]; assign next_crc[22] =d[7]^i[14]^i[24]; assign next_crc[23] =d[1]^d[6]^d[7]^i[15]^i[24]^i[25]^i[30]; assign next_crc[24] =d[0]^d[5]^d[6]^i[16]^i[25]^i[26]^i[31]; assign next_crc[25] =d[4]^d[5]^i[17]^i[26]^i[27]; assign next_crc[26] =d[1]^d[3]^d[4]^d[7]^i[18]^i[28]^i[27]^i[24]^i[30]; assign next_crc[27] =d[0]^d[2]^d[3]^d[6]^i[19]^i[29]^i[28]^i[25]^i[31]; assign next_crc[28] =d[1]^d[2]^d[5]^i[20]^i[30]^i[29]^i[26]; assign next_crc[29] =d[0]^d[1]^d[4]^i[21]^i[31]^i[30]^i[27]; assign next_crc[30] =d[0]^d[3]^i[22]^i[31]^i[28]; assign next_crc[31] =d[2]^i[23]^i[29]; endmodule测试代码 `timescale 1ns/1ns module crc_test(); reg clk, reset; reg [7:0] d; reg load_init; reg calc; reg data_valid; wire [31:0] crc_reg; wire [7:0] crc; initial begin clk=0; reset=0; load_init=0; calc=0; data_valid=0; d=0; end always begin #10 clk=1; #10 clk=0; end always begin crc_reset; crc_cal; end task crc_reset; begin reset=1; repeat(2)@(posedge clk); #5; reset=0; repeat(2)@(posedge clk); end endtask task crc_cal; begin repeat(5) @ (posedge clk); //通过losd_init=1 对CRC计算电路进行初始化 #5; load_init= 1; repeat(1)@ (posedge clk); //设置1oad_init=0,data_valid= 1,calc=1 //开始对输人数据进行CRC校验运算 #5; load_init= 0; data_valid=1; calc=1; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hcc; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hdd; repeat(1)@ (posedge clk); //设置load_init=0,data_valid=1,calc=0 //停止对数据进行CRC校验运算,开始输出 //计算结果 #5; data_valid=1; calc=0; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hee; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hdd; repeat(1)@ (posedge clk); #5; data_valid=0; repeat(10)@ (posedge clk); end endtask crc32_8023 my_crc_test(.clk(clk),.reset(reset),.d(d),.load_init(load_init),.calc(calc),.d_valid(data_valid),.crc_reg(crc_reg),.crc(crc)); endmodule图1-7是电路的仿真结果。图中①是电路进行CRC校验计算之前对电路进行初始化操作的过程,经过初始化之后,crc_reg内部数值为全1。②是对输入数据aa-> bb-> cc-> dd进行运算操作的过程,此时calc和data_valid均为1。③是输出计算结果的过程,CRC校验运算结果a7、01、b4和55先后被输出。 图片 图片 在接收方向上,可以采用相同的电路进行校验检查,判断是否在传输过程中发生了差错。具体工作时,可以边接收用户数据边进行校验运算,当一个完整的MAC帧接收完成后(此时接收数据帧中的校验结果也参加了校验运算),如果当前校验电路的crc_reg值为0xC704DD7B(对于以太网中使用的CRC-32校验,无论原始数据是什么,正确接收时校验和都是此固定数值),说明没有发生错误,否则说明MAC帧有错。 CRC-32校验值的作用是用于检测数据传输或存储中的错误。发送数据时,会根据数据内容生成简短的校验和,并将其与数据一起发送。接收数据时,将再次生成校验和并将其与发送的校验和进行比较。如果两者相等,则没有数据损坏。如果两者不相等,则说明数据在传输或存储过程中发生了改变,可能是由于噪声、干扰、故障或恶意篡改等原因造成的。 CRC-32校验值可以有效地检测出数据中的随机错误,但是不能保证检测出所有的错误。例如,如果数据中有偶数个比特发生了翻转,那么CRC-32校验值可能不会改变,从而无法发现错误。因此,CRC-32校验值只能作为一种辅助的错误检测手段,不能完全依赖它来保证数据的正确性和完整性。 相关工具 如果不理解推导过程的话,可以由相关工具帮忙计算出结果和得到Verilog代码: CRC校验Verilog代码生成链接:http://outputlogic.com/?page_id=321 CRC校验计算工具链接:http://www.ip33.com/crc.html,这个工具只能计算16bit为一个数据包的数据,如果数据包为10bit等之类的就不太适用 在线计算器使用举例 报文 : 1011001 (0x59) 生成多项式 : g(x) = x^4 + x^3 + 1 CRC : 1010 ( 0xa) CRC计算结果截图: image.png图片 参考文献 Verilog HDL算法与电路设计-乔庐峰
FPGA&ASIC
软硬件算法
# ASIC/FPGA
# 硬件算法
刘航宇
3年前
0
2,211
3
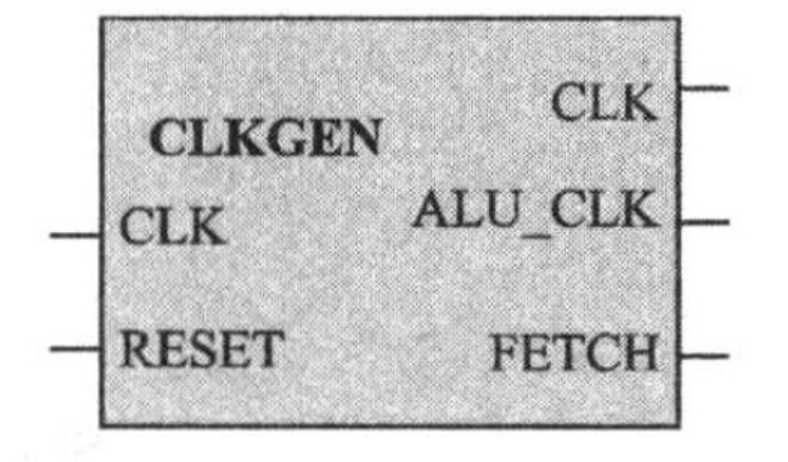
【IC/CPU设计】极简的RISC_CPU设计
CPU为SOC系统的核心环节,该项目来自于夏宇闻老师的经典教材——《Verilog 数字系统设计教程》,通过此练习方便数字ICer更好的入门 本次项目实践环境: 前仿: Modelsim 综合: Design Compile 目录 CPU简介 整体结构时钟发生器 指令寄存器 累加器 算术运算器数据控制器 地址多路器 程序计数器 状态控制器&主状态机 外围模块地址译码器 RAM ROM 顶层模块 TestbenchTest1程序 Test3程序 完整的testbench 源代码&脚本 前仿真结果 DC后仿真 总结 CPU简介 CPU(Central Processing Unit),中文全称中央处理器,作为四大U之首(CPU/GPU/TPU/NPU),是计算机系统的运算和控制核心,也是当今数字系统中不可或缺的组成部分。CPU自诞生到如今发展超过50年,借助冯诺依曼体系,CPU掀起一股又一股的科技浪潮。RISC作为精简了指令集的CPU,除了指令更加简洁,还拥有简单合理的内部结构,从而提高了运算速度。 CPU工作的5个阶段: (1)取指(IF,Instruction Fetch),将指令从存储器取出到指令寄存器。每取一条指令,程序计数器自加一。 (2)译指(ID,Instruction Decode),对取出的指令按照规定格式进行拆分和译码。 (3)执行(EX,Execute),执行具体指令操作。 (4)访问存储(MEM,Memory),根据指令访问存储、完成存储和读取。 (5)写回(WB,Write Back),将计算结果写回到存储器。 CPU内部关键结构: (1)算术逻辑运算器(ALU); (2)累加器; (3)程序计数器; (4)指令寄存器和译码器; (5)时序和控制部件。 RISC_CPU内部结构和Verilog实现 本项目中的RISC_CPU一共有9个模块组成,具体如下: (1)时钟发生器; (2)指令寄存器; (3)累加器; (4)算术逻辑运算单元; (5)数据控制器; (6)状态控制器; (7)主状态机; (8)程序计数器; (9)地址多路器。 整体结构 图片 时钟发生器 模块图: image.png图片 端口描述: reset是高电平复位信号; clk是外部时钟信号; fetch是控制信号,是clk的八分频信号;fetch为高电平时,触发执行指令以及地址多路器输出指令地址和数据地址。 alu_ena是算术逻辑运算单元的使能信号。 图片 可以看到alu_ena提前fetch高电平一个clk周期,fetch是clk的8分频信号。 Verilog代码: // Description: RISC——CPU 时钟发生器 // ----------------------------------------------------------------------------- module clk_gen ( input clk , // Clock input reset , // High level reset output reg fetch , // 8 frequency division output reg alu_ena // Arithmetic enable ); reg [7:0] state; //One-piece state machine parameter S1 = 8'b0000_0001, S2 = 8'b0000_0010, S3 = 8'b0000_0100, S4 = 8'b0000_1000, S5 = 8'b0001_0000, S6 = 8'b0010_0000, S7 = 8'b0100_0000, S8 = 8'b1000_0000, idle = 8'b0000_0000; always@(posedge clk)begin if(reset)begin fetch <= 0; alu_ena <= 0; state <= idle; end else begin case(state) S1: begin alu_ena <= 1; state <= S2; end S2: begin alu_ena <= 0; state <= S3; end S3: begin fetch <= 1; state <=S4; end S4: begin state <= S5; end S5: state <= S6; S6: state <= S7; S7: begin fetch <= 0; state <= S8; end S8: begin state <= S1; end idle: state <= S1; default: state <=idle; endcase end end endmodule指令寄存器 模块图: 图片 端口描述: 寄存器是将数据总线送来的指令存入高8位或低8位寄存器中。 ena信号用来控制是否寄存。 每条指令为两个字节,16位,高3位是操作码,低13位是地址(CPU地址总线为13位,寻址空间为8K字节)。 本设计的数据总线为8位,每条指令需要取两次,先取高8位,再取低8位。 Verilog代码: // Description: RISC—CPU 指令寄存器 // ----------------------------------------------------------------------------- module register ( input [7:0] data , input clk , input rst , input ena , output reg [15:0] opc_iraddr ); reg state ; // always@( posedge clk ) begin if( rst ) begin opc_iraddr <= 16'b 0000_0000_0000_0000; state <= 1'b 0; end // if rst // If load_ir from machine actived, load instruction data from rom in 2 clock periods. // Load high 8 bits first, and then low 8 bits. else if( ena ) begin case( state ) 1'b0 : begin opc_iraddr [ 15 : 8 ] <= data; state <= 1; end 1'b1 : begin opc_iraddr [ 7 : 0 ] <= data; state <= 0; end default : begin opc_iraddr [ 15 : 0 ] <= 16'bxxxx_xxxx_xxxx_xxxx; state <= 1'bx; end endcase // state end // else if ena else state <= 1'b0; end endmodule 累加器 模块图: 图片 端口描述: 累加器用于存放当前结果,ena信号有效时,在clk上升沿输出数据总线的数据。 // Description: RISC-CPU 累加器模块 // ----------------------------------------------------------------------------- module accum ( input clk , // Clock input ena , // Enable input rst , // Asynchronous reset active high input [7:0] data , // Data bus output reg [7:0] accum ); always@(posedge clk)begin if(rst) accum <= 8'b0000_0000;//Reset else if(ena) accum <= data; end endmodule 算术运算器 模块图: image.png图片 端口描述: 算术逻辑运算单元可以根据输入的操作码分别实现相应的加、与、异或、跳转等基本操作运算。 本单元支持8种操作运算。 opcode用来选择计算模式 data是数据输入 accum是累加器输出 alu_ena是模块使能信号 clk是系统时钟 Verilog代码: // Description: RISC-CPU 算术运算器 // ----------------------------------------------------------------------------- module alu ( input clk , // Clock input alu_ena , // Enable input [2:0] opcode , // High three bits are used as opcodes input [7:0] data , // data input [7:0] accum , // accum out output reg [7:0] alu_out , output zero ); parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always @(posedge clk) begin if(alu_ena) begin casex(opcode)//操作码来自指令寄存器的输出 opc_iaddr(15..0)的第三位 HLT: alu_out <= accum ; SKZ: alu_out <= accum ; ADD: alu_out <= data + accum ; ANDD: alu_out <= data & accum ; XORR: alu_out <= data ^ accum ; LDA : alu_out <= data ; STO : alu_out <= accum ; JMP : alu_out <= accum ; default: alu_out <= 8'bxxxx_xxxx ; endcase end end assign zero = !accum; endmodule 数据控制器 模块图: image.png图片 端口描述: 数据控制器的作用是控制累加器的数据输出,数据总线是分时复用的,会根据当前状态传输指令或者数据。 数据只在往RAM区或者端口写时才允许输出,否则呈现高阻态。 in是8bit数据输入 data_ena是使能信号 data是8bit数据输出 Verilog代码: // Description: RISC-CPU 数据控制器 // ----------------------------------------------------------------------------- module datactl ( input [7:0] in , // Data input input data_ena , // Data Enable output wire [7:0] data // Data output ); assign data = (data_ena )? in: 8'bzzzz_zzzz ; endmodule 地址多路器 模块图: image.png图片 端口描述: 用于选择输出地址是PC(程序计数)地址还是数据/端口地址。每个指令周期的前4个时钟周期用于从ROM种读取指令,输出的是PC地址;后四个时钟周期用于对RAM或端口读写。 地址多路器和数据控制器实现的功能十分相似。 fetch信号用来控制地址输出,高电平输出pc_addr ,低电平输出ir_addr ; pc_addr 指令地址; ir_addr ram或端口地址。 Verilog代码: // Description: RISC-CPU 地址多路器 // ----------------------------------------------------------------------------- module adr ( input fetch , // enable input [12:0] ir_addr , // input [12:0] pc_addr , // output wire [12:0] addr ); assign addr = fetch? pc_addr :ir_addr ; endmodule 程序计数器 模块图: image.png图片 端口描述: 程序计数器用来提供指令地址,指令按照地址顺序存放在存储器中。包含两种生成途径: (1)顺序执行的情况 (2)需要改变顺序,例如JMP指令 rst复位信号,高电平时地址清零; clock 时钟信号,系统时钟; ir_addr目标地址,当加载信号有效时输出此地址; pc_addr程序计数器地址 load地址装载信号 Verilog代码: // Description: RISC-CPU 程序计数器 // ----------------------------------------------------------------------------- module counter ( input [12:0] ir_addr , // program address input load , // Load up signal input clock , // CLock input rst , // Reset output reg [12:0] pc_addr // insert program address ); always@(posedge clock or posedge rst) begin if(rst) pc_addr <= 13'b0_0000_0000_0000; else if(load) pc_addr <= ir_addr; else pc_addr <= pc_addr + 1; end endmodule 状态控制器&主状态机 模块图: image.png图片 (图左边)状态机端口描述: 状态控制器接收复位信号rst,rst有效,控制输出ena为0,fetch有效控制ena为1。 // Description: RISC-CPU 状态控制器 // ----------------------------------------------------------------------------- module machinectl ( input clk , // Clock input rst , // Asynchronous reset input fetch , // Asynchronous reset active low output reg ena // Enable ); always@(posedge clk)begin if(rst) ena <= 0; else if(fetch) ena <=1; end endmodule (图右边)主状态端口描述: 主状态机是CPU的控制核心,用于产生一系列控制信号。 指令周期由8个时钟周期组成,每个时钟周期都要完成固定的操作。 (1)第0个时钟,CPU状态控制器的输出rd和load_ir 为高电平,其余为低电平。指令寄存器寄存由ROM送来的高8位指令代码。 (2)第1个时钟,与上一个时钟相比只是inc_pc从0变为1,故PC增1,ROM送来低8位指令代码,指令寄存器寄存该8位指令代码。 (3)第2个时钟,空操作。 (4)第3个时钟,PC增1,指向下一条指令。 操作符为HLT,输出信号HLT为高。 操作符不为HLT,除PC增1外,其余控制线输出为0. (5)第4个时钟,操作。 操作符为AND,ADD,XOR或LDA,读取相应地址的数据; 操作符为JMP,将目的地址送给程序计数器; 操作符为STO,输出累加器数据。 (6)第5个时钟,若操作符为ANDD,ADD或者XORR,算术运算器完成相应的计算; 操作符为LDA,就把数据通过算术运算器送给累加器; 操作符为SKZ,先判断累加器的值是否为0,若为0,PC加1,否则保持原值; 操作符为JMP,锁存目的地址; 操作符为STO,将数据写入地址处。 (7)第6个时钟,空操作。 (8)第7个时钟,若操作符为SKZ且累加器为0,则PC值再加1,跳过一条指令,否则PC无变化。 // Description: RISC-CPU 主状态机 // ----------------------------------------------------------------------------- module machine ( input clk , // Clock input ena , // Clock Enable input zero , // Asynchronous reset active low input [2:0] opcode , // OP code output reg inc_pc , // output reg load_acc , // output reg load_pc , // output reg rd , // output reg wr , // output reg load_ir , // output reg datactl_ena , // output reg halt ); reg [2:0] state ; //parameter parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always@(negedge clk) begin if(!ena) //收到复位信号rst,进行复位操作 begin state <= 3'b000; {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else ctl_cycle; end //------- task ctl_cycle ------- task ctl_cycle; begin casex(state) 3'b000: //load high 8bits in struction begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b001; end 3'b001://pc increased by one then load low 8bits instruction begin {inc_pc,load_acc,load_pc,rd} <= 4'b1001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b010; end 3'b010: //idle begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b011; end 3'b011: //next instruction address setup 分析指令开始点 begin if(opcode == HLT)//指令为暂停HLT begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0001; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b100; end 3'b100: //fetch oprand begin if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b101; end 3'b101://operation begin if(opcode == ADD || opcode == ANDD ||opcode ==XORR ||opcode == LDA)//过一个时钟后与累加器的内存进行运算 begin {inc_pc,load_acc,load_pc,rd} <= 4'b0101; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == SKZ && zero == 1)// & and && begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin//过一个时钟后吧wr变为1,写到RAM中 {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b1010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b110; end 3'b110: begin if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b111; end 3'b111: begin if(opcode == SKZ && zero == 1) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b000; end default: begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b000; end endcase end endtask endmodule 外围模块 为了对RISC-CPU进行测试,需要对ROM、RAM和地址译码器进行设计。 地址译码器 模块说明: 地址译码器用于产生选通信号,选通ROM或者RAM 1FFFH —— 1800H RAM(范围):1_1xxx_xxxx_xxxx 17FFH —— 0000H ROM(范围):0_xxxx_xxxx_xxxx+1_0xxx_xxxx_xxxx Verilog代码: // Description: RISC-CPU 地址译码器 // ----------------------------------------------------------------------------- module addr_decode ( input [12:0] addr , // Address output reg ram_sel , // Ram sel output reg rom_sel // Rom sel ); always@(addr)begin casex(addr) 13'b1_1xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b01; 13'b0_xxxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; 13'b1_0xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; default: {rom_sel,ram_sel} <= 2'b00; endcase end endmodule RAM 模块说明: RAM用于存放临时数据,可读可写。 Verilog代码: // Description: RISC-CPU RAM模块 // ----------------------------------------------------------------------------- module ram ( input ena , // Enable input read , // read Enable input write , // write Enable inout wire [7:0] data , // data input [9:0] addr // address ); reg [7:0] ram [10'h3ff:0] ; assign data = (read && ena )? ram[addr]:8'h zz; always@(posedge write) begin ram[addr] <= data; end endmodule ROM 模块说明: RAM用于存放只读数据。 Verilog代码: // Description: RISC-CPU ROM模块 // ----------------------------------------------------------------------------- module rom ( input [12:0] addr , input read , input ena , output wire [7:0] data ); reg [7:0] memory [13'h1ff:0]; assign data = (read && ena)? memory[addr]:8'b zzzz_zzzz; endmodule 顶层模块 模块图: 图片 图片 Verilog代码: // Description: RISC-CPU 顶层模块 // ----------------------------------------------------------------------------- //`include "clk_gen.v" //`include "accum.v" //`include "adr.v" //`include "alu.v" //`include "machine.v" //`include "counter.v" //`include "machinectl.v" //`iclude "machine.v" //`include "register.v" //`include "datactl.v" module RISC_CPU ( input clk , input reset , output wire rd , output wire wr , output wire halt , output wire fetch , //addr output wire [12:0] addr , output wire [12:0] ir_addr , output wire [12:0] pc_addr , inout wire [7:0] data , //op output wire [2:0] opcode ); wire [7:0] alu_out ; wire [7:0] accum ; wire zero ; wire inc_pc ; wire load_acc ; wire load_pc ; wire load_ir ; wire data_ena ; wire contr_ena ; wire alu_ena ; //inst clk_gen mclk_gen( .clk (clk ), .reset (reset ), .fetch (fetch ), .alu_ena (alu_ena ) ); register m_register( .data (data ), .ena (load_ir ), .rst (reset ), .clk (clk ), .opc_iraddr ({opcode,ir_addr} ) ); accum m_accum( .data (alu_out ), .ena (load_acc ), .clk (clk ), .rst (reset ), .accum (accum ) ); alu m_alu( .data (data ), .accum (accum ), .clk (clk ), .alu_ena (alu_ena ), .opcode (opcode ), .alu_out (alu_out ), .zero (zero ) ); machinectl m_machinectl( .clk (clk ), .rst (reset ), .fetch (fetch ), .ena (contr_ena ) ); machine m_machine( .inc_pc (inc_pc ), .load_acc (load_acc ), .load_pc (load_pc ), .rd (rd ), .wr (wr ), .load_ir (load_ir ), .clk (clk ), .datactl_ena(data_ena ), .halt (halt ), .zero (zero ), .ena (contr_ena ), .opcode (opcode ) ); datactl m_datactl( .in (alu_out ), .data_ena (data_ena ), .data (data ) ); adr m_adr( .fetch (fetch ), .ir_addr (ir_addr ), .pc_addr (pc_addr ), .addr (addr ) ); counter m_counter( .clock (inc_pc ), .rst (reset ), .ir_addr (ir_addr ), .load (load_pc ), .pc_addr (pc_addr ) ); endmodule Testbench Testbench包含三个测试程序,这个部分不能综合。 Test1程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 若各条指令正确,应该在地址2E(hex)处,在执行HLT时刻停止。若程序在任何其他位置停止,则必有一条指令运行错误,可以按照注释找到错误的指令。 test1汇编程序:(.pro文件/存放于ROM) //机器码-地址-汇编助记符-注释 @00 //address statement 111_0000 //00 BEGIN: JMP TST_JMP 0011_1100 000_0000 //02 HLT //JMP did not work 0000_0000 000_00000 //04 HLT //JMP did not load PC skiped 0000_0000 101_1100 //06 JMP_OK: LDA DATA 0000_0000 001_00000 //08 SKZ 0000_0000 000_0000 //0a HLT 0000_0000 101_11000 //0C LDA DATA_2 0000_0001 001_00000 //0E SKZ 0000_0000 111_0000 //10 JMP SKZ_OK 001_0100 000_0000 //12 HLT 0000_0000 110_11000 //14 SKZ_OK: STO TEMP 0000_0010 101_11000 //16 LDA DATA_1 0000_0000 110_11000 //18 STO TEMP 0000_0010 101_11000 //1A LDA TEMP 0000_0010 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 100_11000 //20 XOR DATA_2 0000_0001 001_00000 //22 SKZ 0000_0000 111_00000 //24 JMP XOR_OK 0010_1000 000_00000 //26 HLT 0000_0000 100_11000 //28 XOR_OK XOR DATA_2 0000_0001 001_00000 //2A SKZ 0000_0000 000_00000 //2C HLT 0000_0000 000_0000 //2E END 0000_0000 111_00000 //30 JMP BEGIN 0000_0000 @3c 111_00000 //3c TST_JMP IMR OK 0000_0110 000_00000 //3E HLT test1数据文件:(.dat/存放于RAM) /----------------------------------- @00 ///address statement at RAM 00000000 //1800 DATA_1 11111111 //1801 DATA_2 10101010 //1082 TEMPTest2程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 这个程序是用来测试RISC-CPU的高级指令集,若执行正确,应在地址20(hex)处在执行HLT时停止。 test2汇编程序: @00 101_11000 //00 BEGIN 0000_0001 011_11000 //02 AND DATA_3 0000_0010 100_11000 //04 XOR DATA_2 0000_0001 001_00000 //06 SKZ 0000_0000 000_00000 //08 HLT 0000_0000 010_11000 //0A ADD DATA_1 0000_0000 001_00000 //0C SKZ 0000_0000 111_00000 //0E JMP ADD_OK 0001_0010 111_00000 //10 HLT 0000_0000 100_11000 //12 ADD_OK XOR DATA_3 0000_0010 010_11000 //14 ADD DATA_1 0000_0000 110_11000 //16 STO TEMP 0000_0011 101_11000 //18 LDA DATA_1 0000_0000 010_11000 //1A ADD TEMP 0000_0001 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 000_00000 //END HLT 0000_0000 111_00000 //JMP BEGIN 0000_0000test2数据文件: @00 00000001 //1800 DATA_1 10101010 //1801 DATA_2 11111111 //1802 DATA_3 00000000 //1803 TEMPTest3程序 TEST3程序是一个计算0~144的斐波那契数列的程序,用来验证CPU整体功能。 test3汇编程序: @00 101_11000 //00 LOOP:LDA FN2 0000_0001 110_11000 //02 STO TEMP 0000_0010 010_11000 //04 ADD FN1 0000_0000 110_11000 //06 STO FN2 0000_0001 101_11000 //08 VLDA TEMP 0000_0010 110_11000 //0A STO FN1 0000_0000 100_11000 //0C XOR LIMIT 0000_0011 001_00000 //0E SKZ 0000_0000 111_00000 //10 JMP LOOP 0000_0000 000_00000 //12 DONE HLT 0000_0000test3数据文件: @00 00000001 //1800 FN1 00000000 //1801 FN2 00000000 //1802 TEMP 10010000 //1803 LIMIT完整的testbench Verilog代码: // Description: RISC-CPU 测试程序 // ----------------------------------------------------------------------------- `include "RISC_CPU.v" `include "ram.v" `include "rom.v" `include "addr_decode.v" `timescale 1ns/1ns `define PERIOD 100 // matches clk_gen.v module cputop_tb; reg [( 3 * 8 ): 0 ] mnemonic; // array that holds 3 8 bits ASCII characters reg [ 12 : 0 ] PC_addr, IR_addr; reg reset_req, clock; wire [ 12 : 0 ] ir_addr, pc_addr; // for post simulation. wire [ 12 : 0 ] addr; wire [ 7 : 0 ] data; wire [ 2 : 0 ] opcode; // for post simulation. wire fetch; // for post simulation. wire rd, wr, halt, ram_sel, rom_sel; integer test; //-----------------DIGITAL LOGIC---------------------- RISC_CPU t_cpu (.clk( clock ),.reset( reset_req ),.halt( halt ),.rd( rd ),.wr( wr ),.addr( addr ),.data( data ),.opcode( opcode ),.fetch( fetch ),.ir_addr( ir_addr ),.pc_addr( pc_addr )); ram t_ram (.addr ( addr [ 9 : 0 ]),.read ( rd ),.write ( wr ),.ena ( ram_sel ),.data ( data )); rom t_rom (.addr ( addr ),.read ( rd ), .ena ( rom_sel ),.data ( data )); addr_decode t_addr_decoder (.addr( addr ),.ram_sel( ram_sel ),.rom_sel( rom_sel )); //-------------------SIMULATION------------------------- initial begin clock = 0; // display time in nanoseconds $timeformat ( -9, 1, "ns", 12 ); display_debug_message; sys_reset; test1; $stop; test2; $stop; test3; $finish; // simulation is finished here. end // initial task display_debug_message; begin $display ("\n************************************************" ); $display ( "* THE FOLLOWING DEBUG TASK ARE AVAILABLE: *" ); $display ( "* \"test1;\" to load the 1st diagnostic program. *"); $display ( "* \"test2;\" to load the 2nd diagnostic program. *"); $display ( "* \"test3;\" to load the Fibonacci program. *"); $display ( "************************************************\n"); end endtask // display_debug_message task test1; begin test = 0; disable MONITOR; $readmemb ("test1.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test1.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 1; #14800; sys_reset; end endtask // test1 task test2; begin test = 0; disable MONITOR; $readmemb ("test2.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test2.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 2; #11600; sys_reset; end endtask // test2 task test3; begin test = 0; disable MONITOR; $readmemb ("test3.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test3.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 3; #94000; sys_reset; end endtask // test1 task sys_reset; begin reset_req = 0; #( `PERIOD * 0.7 ) reset_req = 1; #( 1.5 * `PERIOD ) reset_req = 0; end endtask // sys_reset //--------------------------MONITOR-------------------------------- always@( test ) begin: MONITOR case( test ) 1: begin // display results when running test 1 $display("\n*** RUNNING CPU test 1 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 1 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 1 @ t_cpu.pc_addr end 2: begin // display results when running test 2 $display("\n*** RUNNING CPU test 2 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 2 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 2 @ t_cpu.pc_addr end 3: begin // display results when running test 3 $display("\n*** RUNNING CPU test 3 - An Executable Program **************"); $display("***** This program should calculate the fibonacci *************"); $display("\n TIME FIBONACCI NUMBER "); $display(" ------ -----------------_ "); while( test == 3 ) begin wait( t_cpu.opcode == 3'h 1 ) // display Fib. No. at end of program loop $strobe("%t %d", $time, t_ram.ram [ 10'h 2 ]); wait( t_cpu.opcode != 3'h 1 ); end // while test == 3 end endcase // test end // MONITOR: always@ test //-------------------------HALT------------------------------- always@( posedge halt ) begin // STOP when HALT intruction decoded #500 $display("\n******************************************"); $display( "** A HALT INSTRUCTION WAS PROCESSED !!! **"); $display( "******************************************"); end // always@ posedge halt //-----------------------CLOCK & MNEMONIC------------------------- always#(`PERIOD / 2 ) clock = ~ clock; always@( t_cpu.opcode ) begin // get an ASCII mnemonic for each opcode case( t_cpu.opcode ) 3'b 000 : mnemonic = "HLT"; 3'b 001 : mnemonic = "SKZ"; 3'b 010 : mnemonic = "ADD"; 3'b 011 : mnemonic = "AND"; 3'b 100 : mnemonic = "XOR"; 3'b 101 : mnemonic = "LDA"; 3'b 110 : mnemonic = "STO"; 3'b 111 : mnemonic = "JMP"; default : mnemonic = "???"; endcase end endmodule $ readmemb ( "test1. pro" ,t_ rom. . memory ); $ readmemb ( "testl. dat",t_ ram_ . ram); 即可把编译好的汇编机器码装人虚拟ROM,把需要参加运算的数据装人虚拟RAM就可以开始仿真。上面语句中的第一项为打开的文件名,后一项为系统层次管理下的ROM模块和RAM模块中的存储器memory和ram。源代码&脚本 隐藏内容,请前往内页查看详情 前仿真结果 test1 图片 test2 图片 test3 图片 图片 DC后仿真 采用SMIC180工艺在典型环境下进行测试 时序报告: 图片 面积报告: 图片 功耗报告: 图片 综合电路图: 图片 图片 图片 总结 该项目更加偏向于教学练习,CPU也是数字IC的重要研究方向,对此感兴趣的同学可以找点论文和开源资料进行学习。可以进一步优化如流水线、运算单元,扩展成SOC系统等。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# SOC设计
刘航宇
3年前
15
2,091
6
3~4月的花花,浅浅的记录一下~
最近在长安区遇到的3~4月的花花,浅浅的记录一下~ 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片 图片
我的随笔
# 随笔
刘航宇
3年前
1
551
4
2023-03-21
IC/SOC封装类型与对应成本关系
根据引脚引出的不同,封装可分为外围和阵列封装。根据有无封装连线分为有连接线的( Wire Bond)和倒装片(Flip-chip) 封装。其中,外围封装形式有DIP、PLCC、QFP、SOP等,如图14-23所示。此类封装的优点是价格便宜,板级可靠性比较高。但是其电性能和热性能较差,并且受到I/O引脚数目的限制,如PQFP (Plastic Quad Flat Package,塑料四边引脚扁平封装),I/O 引脚数目也只能达到208~240个。 图片 阵列封装包括有连线的BGA和无连线的Flip-chip BGA等,如图14-24 所示。此类封装的优点是I/O密度高,板级集成的成品率高,但是价格相对较高。 图片 (1) BGA封装 BGA封装技术的出现是封装技术的一大突破,它是近几年来推动封装市场的强有力的技术之一,BGA封装一改传统的封装结构,将引线从封装基板的底部以阵列球的方式引出,这样不仅可以安排更多的IO,而且大大提高了封装密度,改进了电性能。如果它再采用MCP (多芯片模块)封装或倒装片技术,有望进一步提高产 品的速度和降低复杂性。 目前, BGA封装按照基板的种类,主要分为PBGA (塑封BGA)、CBGA (陶瓷BGA)、TBGA (载带BGA)、MBGA (金属BGA)等。图14-25以PBGA为例进行说明,PBGA中的焊球做在 PWB基板上,基板是BT多层布线基板(2~4层),封装采用的焊球材料为共晶或准共晶Pb-Sn 合金、焊球和封装体的连接不需要另外的焊料。 图片 (2)倒装片封装(Flip Chip Packages) 倒装片技术是一种先进的,非常有前途的集成电路封装技术。封装倒装片是一一种由 IBM公司最先使用的先进封装技术,它是利用倒装技术将芯片直接装入一- 个封装体内。倒装片封装可以是单芯片也可以是多芯片形式,其发展历史已将近40年,主要在手持或移动电子产品中使用广泛。一般芯片都是面朝上安装互连,而此类技术则是芯片面朝下,芯片上的焊区直接与基板上的焊区互连,如图14-26所示。因此,倒装封装的互连线非常短,由互连线产生的电容、电阻和电感也比其他封装形式小得多,具有较高的电性能和热性能。此外,采用此类封装的芯片焊区可面阵布局,更适于多I/O数的VLSI芯片使用。当然,倒装技术也有不足之处,如芯片面朝下安装互连,给工艺操作带来一定难度一焊 点检查困难,板级可靠性需要解决,费用也偏高。 图片 (3)多芯片封装(MCP, Multi Chip Package) 多芯片封装是20世纪90年代兴起的- -种混合微电子组装技术,它是在高密度多层布线基板上,将若干裸芯片IC组装和互连,构成更复杂的或具有子系统功能的高级电子组件,常见的有Flash+MCU、Flash+MCU+SRAM、 SRAM+MCU和Analog IC+Digital IC+Memory等组合。图14-27 所示为MCP封装的示意图。 图片 目前,MCP多采用IC芯片叠层放置,可大大节约基板的面积,其主要特点是布线密度高,互连线短,体积小,重量轻和性能高等。但是由于封装了多块芯片,使得良品率有所下降,并且测试相对较困难,测试成本也很高。
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
1,215
2
2023-03-18
【优惠活动】26考研西北大学电子信息类专业全程班
pEVCsrd.png图片 26考研专业全程班优惠活动来啦! 所有课程https://edu.ee.ac.cn/ 奖品内容 活动内容 兑奖条件 声明&收奖方式 赠送资料 26考研西北大学843班(学习通上课):https://mooc1.chaoxing.com/course/249631535.html 课程二维码: m6eq51qr.png图片 目录 奖品内容 活动时间5.6日~5.20日 💻 特等奖奖优惠150元 📱 一等奖优惠100元 💿 二等奖优惠80元 📗 三等奖优惠50元 ✉ 四等奖优惠30元 只要参与98%概率中奖任何一个 兑奖成功后当日有效 活动内容 点开下面2个网页任何一个都可,然后点击分享到QQ空间或微信朋友圈,配上文案:西北大学843电子信息类考研全程班,有需要可以了解,QQ群:519462257。 任选一个 网页一 https://mooc1.chaoxing.com/course/249631535.html 网页二 https://edu.ee.ac.cn/ 兑奖条件 1、转发后需要获得至少5个人的点赞 2、转发后3天内不可删除转发消息,否则取消兑奖资格 3、完成后凭截图参与抽奖 声明&收奖方式 满足活动条件后请将截图发至以下任一核实地方 1、截图发至QQ:2091645818/微信:eecslab 2、截图上传至评论区 发送上面二个任意一个都可以,核实后奖品会立刻发放 每人仅能参与1次,中奖额度与赞数无关,达到最低要求即可 图片 西北大学26考研班:包含数电、模电、 电路 三科知识点讲解、划重点、送初复试资料、真题模拟题带刷带练、 复试指导等 拟定课时不低于90课时,课时更新中课程链接: 点击进入课程 赠送资料 西北大学843、849历年真题 下载地址:https://wwek.lanzoue.com/ip1gv2m1mg3c 提取码: 免费笔记入口 模拟电子技术 数字电子技术
我的随笔
刘航宇
3年前
18
1,915
7
上一页
1
2
3
...
9
下一页