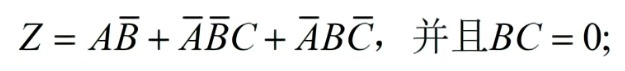首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,925 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,523 阅读
3
【高数】形心计算公式讲解大全
8,978 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,730 阅读
5
Vivado-FPGA Verilog烧写固化教程
7,566 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
刘航宇(共305篇)
找到
305
篇与
刘航宇
相关的结果
- 第 4 页
此内容被密码保护
加密文章,请前往内页查看详情
我的随笔
刘航宇
3年前
0
123
2
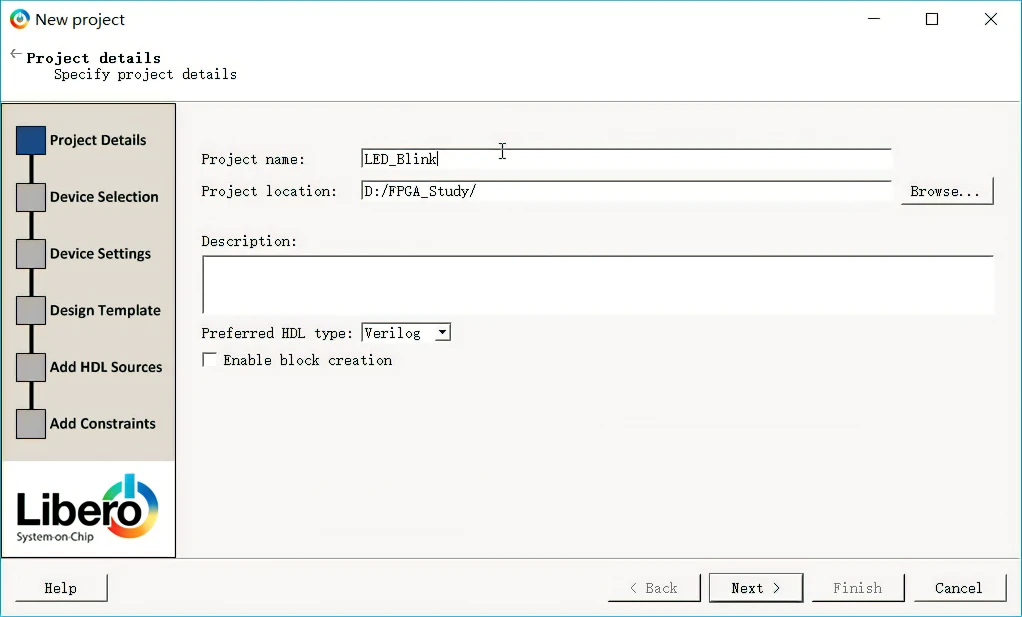
Microsemi Libero SOC使用示例—建立点灯工程
嵌入式开发中的Hello World,点灯是再也基础不过的实验了,通过点灯实验,可以了解芯片GPIO的控制和开发环境IDE新建工程的流程,对于FPGA来说,每个IO口几乎一样,所以本篇文章主要学习一下如何基于Microsemi Libero集成开发环境建立一个示例工程,让一个LED以500ms的频率闪烁,以Microsemi SmartFusion系列FPGA——A2F200M3F为例,Microsemi其他系列FPGA芯片过程类似。 准备工作软件准备: 硬件准备: 新建工程的主要步骤1.新建工程 2.添加设计文件 3.仿真验证 4.管脚分配 5.程序下载 Microsemi FPGA的Flash结构 准备工作 工欲利其事,必先利其器,充分的准备工作很有必要。 软件准备: Microsemi Libero SoC集成开发环境,并已经成功注册,软件版本推荐V11.8或更高版本。 硬件准备: Microsemi FPGA开发板,主控芯片A2F200M3F-PQ208,其他型号芯片类似。 Flash Pro 4或Flash Pro5下载器,用于给FPGA芯片下载程序和调试。 新建工程的主要步骤 新建工程,选择芯片型号等 新建设计,使用Verilog编写点灯模块。 仿真验证,对编写的点灯模块进行时序仿真,来验证是否满足设计需求。 综合、管脚分配、布局、布线。 生成程序文件,连接开发板,使用FlashPro下载程序到芯片内,观察现象是否和设计的一致。 1.新建工程 和大多数IDE一样,选择Project -> New Project,新建一个工程。 image.png图片 输入工程名称LED_Blink,选择工程存放的路径,工程名称和路径不要有中文字符和空格,选择源文件的类型Verilog或者VHDL。 image.png图片 选择芯片型号,这里选择Microsemi SmartFusion系列下的A2F200M3F芯片,PQ208封装,把鼠标放在所选芯片上,可以查看芯片的详细参数:封装、速度等级、温度范围,内核电压、Flash ROM大小、用户IO数目、RAM大小、Flash ROM大小,ARM Cortex-M3 SoC的外设配置等详细的参数。 图片 选择IO的电平标准,不同的电平标准,高低电平的电压范围是不同的,这里选择默认的LVTTL。 图片 是否创建MSS模块,MSS里有PLL和ARM Cortex-M3的使用,以后用到PLL和ARM核时再添加,这里先不选择,以后需要也可以再创建。 图片 是否导入已经存在的HDL文件,如果已经有一些写好的模块,可以在这里直接导入。 图片 是否导入已经存在的管脚约束文件,这里选择不添加,我们会在后面通过图形化工具来指定管脚。 图片 到这里,工程就创建完成了,然后会在存储路径下生成一个和工程名称一样的文件夹,工程相关的所以文件都存放在这里。主要包括以下几个文件夹: 图片 具体每个文件夹存放的是什么文件,我们在以后的文章再详细介绍。以上的工程配置在创建完工程之后,也可以再次更改,可以通过Project->Project Setting查看或更改配置: 图片 或者通过点击如下图标来进入配置界面: 图片 弹出如下窗口,和新建工程是一样的,可以更改FPGA的型号,但只限于同一个系列内。 2.添加设计文件 Microsemi Libero开发环境支持HDL方式和SmarDesign方式来创建设计,HDL方式支持VerilogHDL和VHDL两种硬件描述语言,而SmartDesign方式和Xilinx的Schematic原理图方式是一样的,是通过图形化的方式来对各个模块之间的连接方式进行编辑,两种方式都可以完成设计。由于本实验功能简单,所以以使用Verilog文件为例。 创建Verilog文件 创建Verilog文件有多种方式,可以直接双击左侧菜单中的Create Design->Create HDL 图片 或者点击File->New->HDL,这两种方式都可以创建一个Verilog设计文件,这里选择Verilog文件。 图片 输入模块名称:led_driver,不用添加.v后缀名,Libero软件会自动添加。 源代码: module led_driver( //input input clk, //clk=2MHz input rst_n, //0=reset //output output reg led ); parameter T_500MS = 999999; //1M reg [31:0] cnt; always @ (posedge clk) begin if(!rst_n) cnt <= 32'b0; else if(cnt >= T_500MS) cnt <= 32'b0; else //cnt < T_500MS cnt <= cnt + 32'b1; end always @ (posedge clk) begin if(!rst_n) led <= 1'b1; else if(cnt >= T_500MS) led <= ~led; end endmodule可以看到,代码非常的简单,定义一个计数器,系统时钟为2MHz=500ns,500ms=1M个时钟周期,当计数到500ms时,LED翻转闪烁。 3.仿真验证 编写完成,之后,点击对号进行语法检查,如果没有语法错误就可以进行时序仿真了。 新建Testbench文件 底部切换到Design Hierarchy选项卡,在led模块上右键选择Create Testbechch创建仿真文件,选择HDL格式。 图片 给创建的testbench文件名一般为模块名后加_tb,这里为:led_driver_tb,因为我们的板子外部晶体为2M,所以这里系统时钟周期为500ns,这个也可以在文件中更改。 图片 点击OK之后,可以看到,Libero软件已经为我们生成了一些基本代码,包括输入端口的定义,系统时钟的产生,输入信号的初始化等等。我们只需要再增加几行即可。 `timescale 1ns/100ps module led_driver_tb; parameter SYSCLK_PERIOD = 500;// 2MHZ reg SYSCLK; reg NSYSRESET; wire led; //add output reg initial begin SYSCLK = 1'b0; NSYSRESET = 1'b0; end initial begin #(SYSCLK_PERIOD * 10 ) NSYSRESET = 1'b0; //add system reset #(SYSCLK_PERIOD * 100 ) NSYSRESET = 1'b1; //add system set end always @(SYSCLK) //generate system clock #(SYSCLK_PERIOD / 2.0) SYSCLK <= !SYSCLK; led_driver led_driver_0 ( // Inputs .clk(SYSCLK), .rst_n(NSYSRESET), // Outputs .led(led ) //add port // Inouts ); endmodule仿真代码也非常简单,输入信号初始化,NSYSRESET在10个时钟周期之后拉低,100个时钟周期之后拉高。 使用ModelSim进行时序仿真 仿真代码语法检查无误后,可以进行ModelSim自动仿真,在安装Libero时,已经默认安装了ModelSim仿真软件,并和Libero进行了关联。直接双击Simulate,Libero会自动打开ModelSim。 图片 可以看到输入输出信号,已经为我们添加好了: 图片 先点击复位按钮,复位系统,然后设置要运行的时间,由于设计的是500ms闪烁一次,这里我们先运行2s,即2000ms,在ModelSim中2秒已经算是很长的时间了,然后点击时间右边的运行按钮,耐心等待,停止之后就会看到led按500ms变化一次的波形了,如下图所示,可以再添加一个cnt信号到波形观察窗口,可以看到cnt周期性的变化。 图片 使用2个光标的精确测量,可以看出,led每隔500ms翻转一次,说明程序功能是正确的。 4.管脚分配 与STM32等MCU不同,FPGA的引脚配置非常灵活,如STM32只有固定的几个引脚才能作为定时器PWM输出,而FPGA通过管脚分配可以设置任意一个IO口输出PWM,而且使用起来非常灵活,这也是FPGA和MCU的一个区别,当然其他的功能,如串口外设,SPI外设等等,都可以根据需要自己用HDL代码来实现,非常方便。 时序仿真正常之后,就可以进行管脚分配了,即把模块的输入输出端口,真正的分配到芯片实际的引脚上,毕竟我们的代码是要运行在真正的芯片上的。 打开引脚配置图形化界面 双击Create/Edit I/O Attributes,打开图形化配置界面,在打开之前,Libero会先进行综合(Synthesize)、编译(Complie),当都运行通过时,才会打开配置界面。 图片 分配管脚 管脚可视化配置工具使用起来非常简单:引脚号指定、IO的电平标准,内部上下拉等等,非常直观。把时钟、复位、LED这些管脚分配到开发板原理图中对应的引脚,在分配完成之后,可以点击左上角的commit and check进行检查。 图片 在分配完成之后,为了以后方便查看已经分配的引脚,可以导出一个pdc引脚约束文件,选择Designer窗口下的File->Export->Constraint File,会导出一个led_driver.pdc文件,保存在工程目录下的constraint文件夹。 图片 一些特殊管脚的处理 SmartFusion系列的FPGA芯片,在分配个别引脚,如35-39、43-47这些引脚时,直接不能分配,这些引脚属于MSS_FIO特殊引脚,具体怎么配置为通用IO,可以查看下一篇文章。而新一代的SmartFusion 2系列的FPGA芯片则没有这种情况。 5.程序下载 管脚分配完成之后,连接FlashPro下载器和开发板的JTAG接口,关闭Designer窗口,选择Program Device,耐心等待几分钟,如果连接正常,会在右侧输出编程信息:擦除、验证、编程等操作,下载完成之后,就会看到板子上的LED闪烁起来了。 Microsemi FPGA的Flash结构 和Altera、Xilinx不同,Microsemi FPGA在下载程序时,并不是下载程序到SPI Flash,而是直接下载到FPGA内部的。目前,FPGA 市场占有率最高的两大公司Xilinx和Altera 生产的 FPGA 都是基于 SRAM 工艺的,需要在使用时外接一个片外存储器以保存程序。上电时,FPGA 将外部存储器中的数据读入片内 RAM,完成配置后,进入工作状态;掉电后 FPGA 恢复为白片,内部逻辑消失。这样 FPGA 不仅能反复使用,还无需专门的 FPGA编程器,只需通用的 EPROM、PROM 编程器即可。而Microsemi的SmartFusion、SmartFusion2、ProASICS3、ProASIC3E系列基于Flash结构,具备反复擦写和掉电后内容非易失性, 因此基于Flash结构的FPGA同时具备了SRAM结构的灵活性和反熔丝结构的可靠性,这种技术是最近几年发展起来的新型FPGA实现工艺,目前实现的成本还偏高,没有得到大规模的应用。 示例工程下载 基于Libero V11.8.2.4的工程下载: LED_Blink.rar 下载地址:https://wcc-blog.oss-cn-beijing.aliyuncs.com/Libero/Libero-2/LED_Blink.rar 提取码:
嵌入式&系统
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# 嵌入式
# SOC设计
刘航宇
3年前
0
1,919
2
2023-05-29
Windows安装Jupyter Notebook及机器学习的库
Jupyter Notebook安装(Windows) 下载Jupyter Notebook (1)打开cmd(如果没有把Python安装目录添加到Path,需要切换到Python安装目录的Scripts目录下); (2)输入pip install jupyter;(推荐在外网环境下安装) 2.库安装 下载下面文件 requirements.txt 下载地址:https://wwek.lanzoub.com/iLI2S0xm6a3a 提取码: 然后执行: pip3 install -r requirements.txt 启动Juypter Notebook (1)命令行窗口输入jupyter notebook;浏览器会打开Jupyter Notebook窗口,说明Jupyter Notebook安装成功。 (2) 配置Jupyter Notebook 1、行窗口输入jupyter notebook --generate-config,会发现C:\Users\用户名\ .jupyter下多出了一个配置文件jupyter_notebook_config.py; image.png图片 2、这个配置文件,找到下面这句#c.NotebookApp.notebook_dir = ''。 可以把它修改成c.NotebookApp.notebook_dir = 'D:\jupyter-notebook',当然具体的目录由自己创建的文件夹决定(需要自己创建)。 配置文件修改完成后,以后在jupyter notebook中写的代码都会保存在该目录下。现在重新启动jupyter notebook,就进入了新的工作目录; 5.添加代码自动补全功能(可选) (1)打开cmd,输入pip install jupyter_contrib_nbextensions,等待安装成功; (2)安装完之后需要配置nbextension(配置前要确保已关闭jupyter notebook),在cmd中输入jupyter contrib nbextension install --user --skip-running-check,等待配置成功; (3)在前两步成功的情况下,启动jupyter notebook,会发现在选项栏中多出了Nbextension的选项,点开该选项,并勾选Hinterland,即可添加代码自动补全功能。 image.png图片
机器学习
# 机器学习
刘航宇
3年前
0
452
1
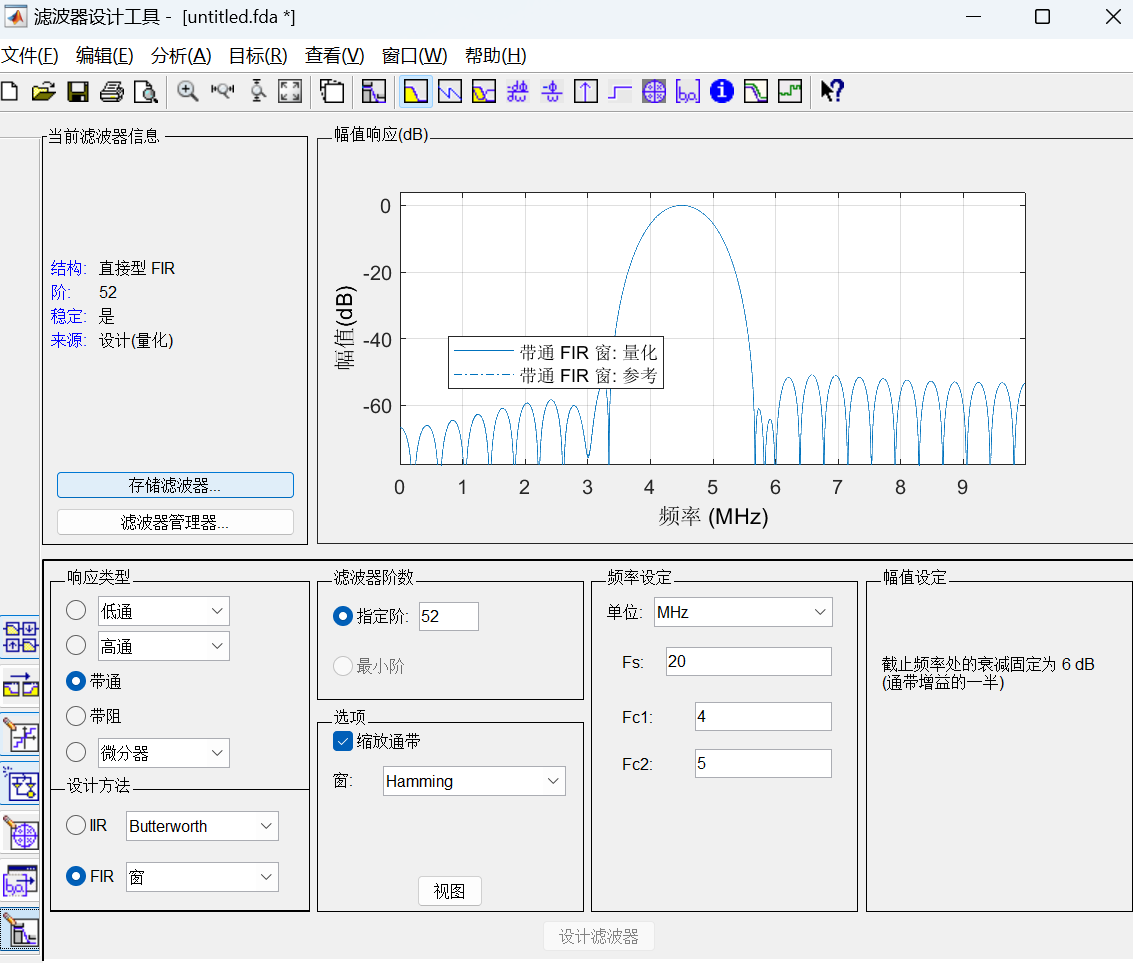
FPGA&Matlab联合开发之滤波器模块(带通滤波器为例)
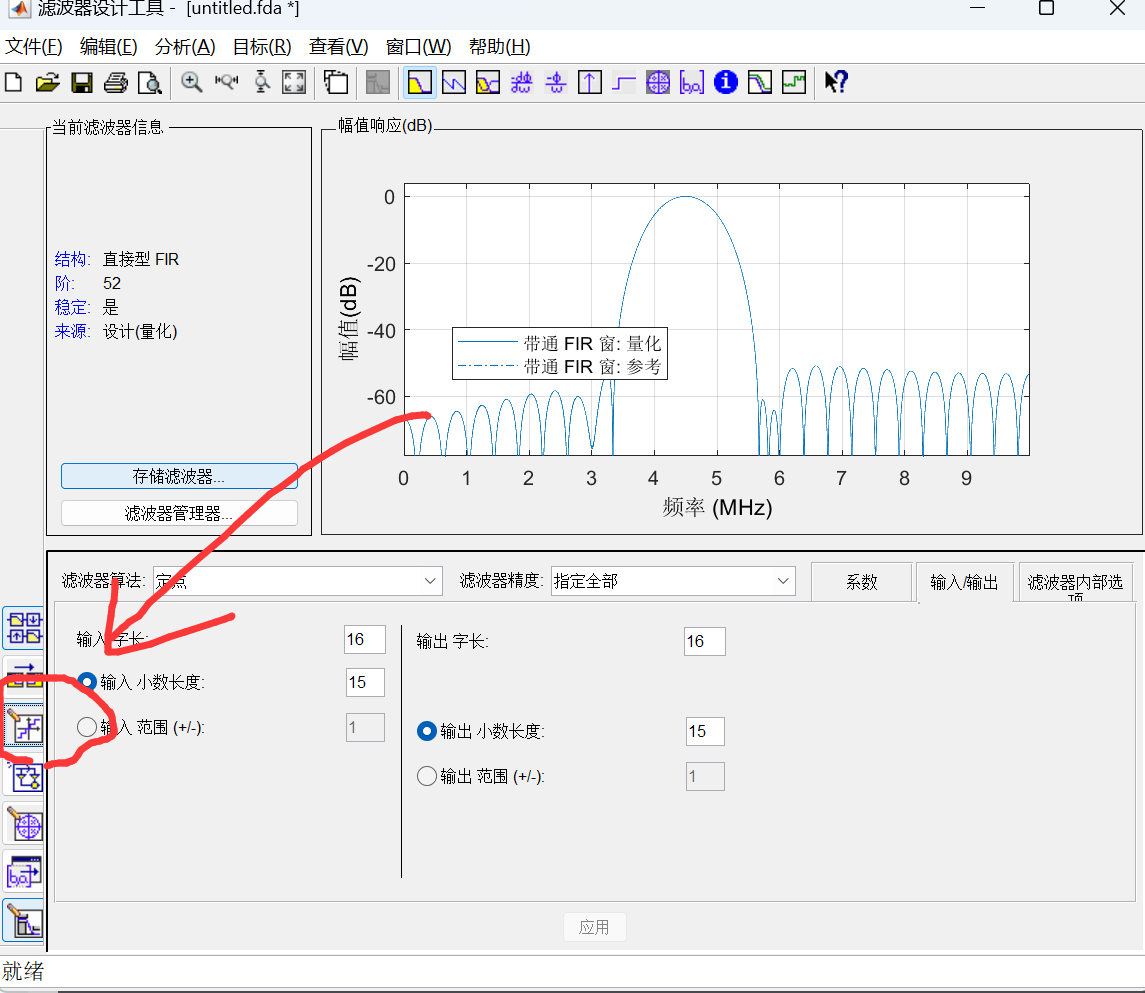
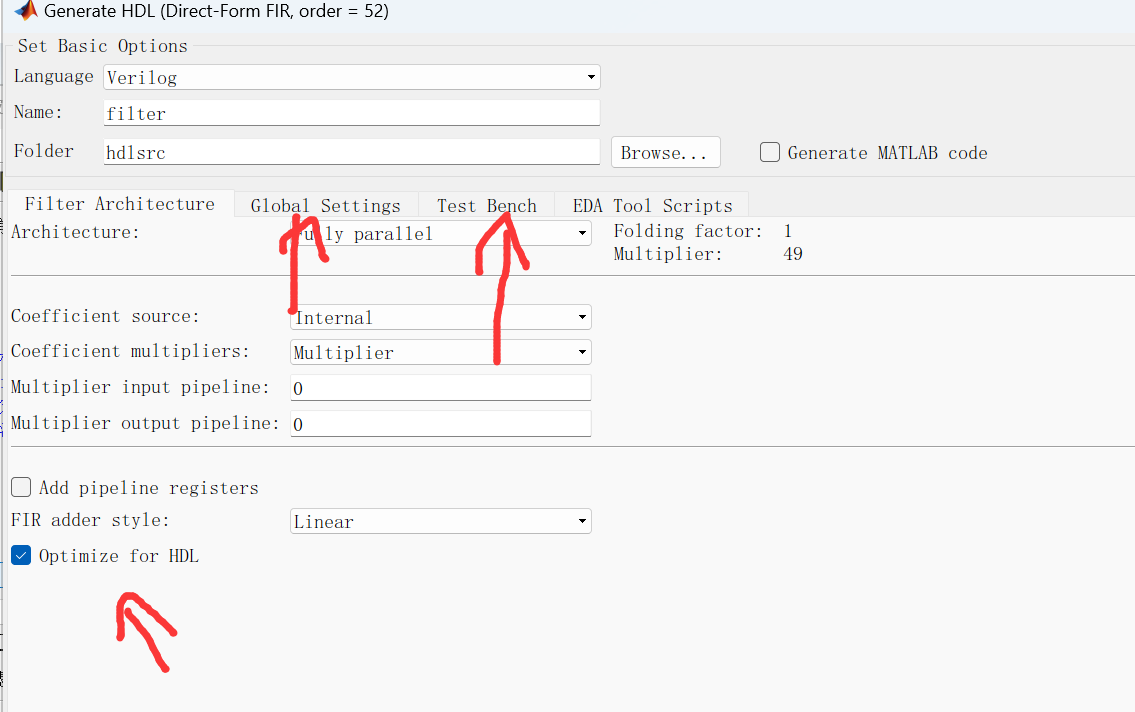
在通信或者信号处理中,数字滤波器是非常重要的模块,前面有关博文中提到FIR滤波器的一步步Verilog设计,如https://ee.ac.cn/index.php/archives/511.html 本文以带通滤波器为例,利用Matlab进行高效开发 目录 MATLAB生成低通滤波器设计步骤: Modelsim仿真上述文件 MATLAB生成低通滤波器设计步骤: (1)在MATLAB命令窗口中输入“filterDesigner”或“fdatool”出现如下对话框 image.png图片 设置FIR滤波器为和需要的阶数滤波器,选择窗函数的类型为海明窗函数,海明窗函数可以得到旁瓣更小的效果,能量更加集中在主瓣中 设置带通滤波器的上下截至频率分别为4MHz 和 5MHz (2)量化输入输出,点击工作栏左边的量化选项,即“set quantization parameters”选项,选择定点,设置输入字长为8,其他选择默认,如下图示: image.png图片 (3)根据自己需求,细化一些配置。这里不难探索 设置完成后,点击Targets中Generate HDL,选择生成Verilog 代码,设置路径,MATLAB即可生成设计好的滤波器Verilog HDL 代码以及测试文件: image.png图片 (4)根据需求,配置输出.v文件的全局信号、测试文件,点击生成,生成后,Matlab主页面会提示.v生成的文件路径 Modelsim仿真上述文件 image.png图片 可以看到输入信号在4MHZ~5MHZ备保留,设计无误。需要注意一点,一般Modelsim仿真输出波形都是离散的01信号,这里需要配置一下,在上图被选中的信号中,在左侧右键鼠标。 右击,format,analog(automatic); 右击,radix,decimal; 这两个步骤完成之后,就出现上图模拟信号的效果
嵌入式&系统
FPGA&ASIC
通信&信息处理
软硬件算法
# ASIC/FPGA
# 信号处理
# 硬件算法
刘航宇
3年前
0
667
2
2023-05-15
机器学习代码实现:线性回归与岭回归
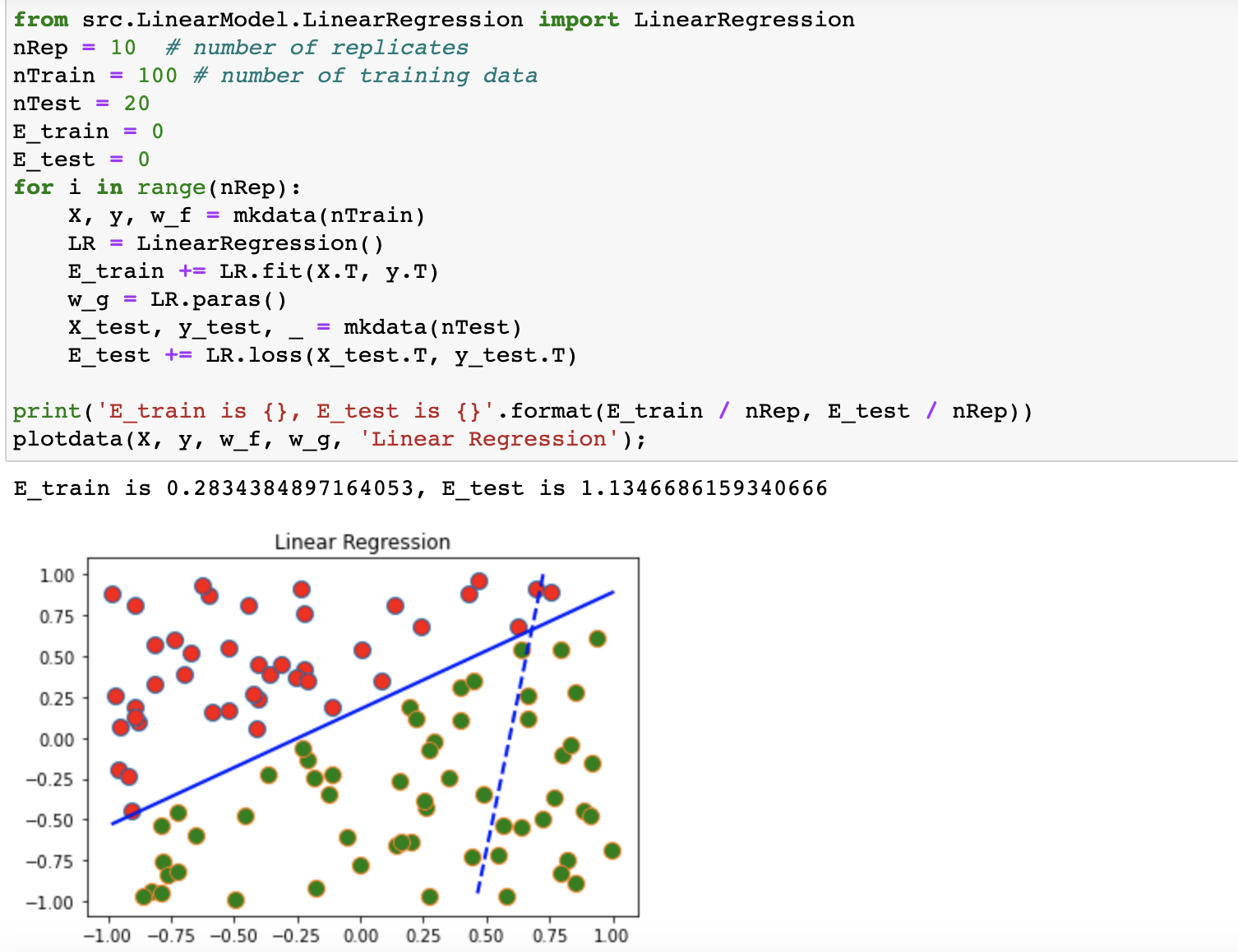
1.线性回归模型 线性回归模型是最简单的一种线性模型,模型的形式就是: $y=W^T x+b$ 我们可以通过对原本的输入向量x扩增一个为1的维度将参数W和b统一成一个参数W,即模型变成了 $y=W^T x$ 这里的W是原本两个参数合并之后的而其损失函数的形式是残差平方损失RSS $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)$ 我们很容易就可以通过求导得到线性回归模型的关于W的梯度 $\nabla_W L=\frac{1}{m} \sum_{i=1}^m\left(W^T x_i-y_i\right) x_i=\frac{1}{m} X^T\left(W^T X-y\right)$ 这样一来我们就可以通过梯度下降的方式来训练参数W,可以用下面的公式表示 $W:=W-\alpha \frac{1}{m} X^T\left(W^T X-y\right)$ 但实际上线性模型的参数W可以直接求解出,即: $W=\left(X^T X\right)^{-1} X^T y$ 2.线性回归的编程实现 具体代码中的参数的形式可能和上面的公式推导略有区别,我们实现了一个LinearRegression的类,包含fit,predict和loss三个主要的方法,fit方法就是求解线性模型的过程,这里我们直接使用了正规方程来解 class LinearRegression: def fit(self, X: np.ndarray, y: np.ndarray) -> float: N, D = X.shape # 将每个样本的特征增加一个维度,用1表示,使得bias和weight可以一起计算 # 这里在输入的样本矩阵X末尾增加一列来给每个样本的特征向量增加一个维度 # 现在X变成了N*(D+1)维的矩阵了 expand_X = np.column_stack((X, np.ones((N, 1)))) self.w = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X)), expand_X.T), y) return self.loss(X, y)predict实际上就是将输入的矩阵X放到模型中进行计算得到对应的结果,loss给出了损失函数的计算方式: def loss(self, X: np.ndarray, y: np.ndarray): """ 线性回归模型使用的是RSS损失函数 :param X:需要预测的特征矩阵X,维度是N*D :param y:标签label :return: """ delta = y - self.predict(X) total_loss = np.sum(delta ** 2) / X.shape[0] return total_loss3.岭回归Ridge Regression与代码实现 岭回归实际上就是一种使用了正则项的线性回归模型,也就是在损失函数上加上了正则项来控制参数的规模,即: $L=\frac{1}{2 m} \sum_{i=1}^m\left(W^T x_i-y_i\right)^2+\lambda\|W\|_2=\frac{1}{2 m}\left(W^T X-y\right)^T\left(W^T X-y\right)+\lambda W^T W$ 因此最终的模型的正规方程就变成了: $W=\left(X^T X+\lambda I\right)^{-1} X^T y$ 这里的\lambda是待定的正则项参数,可以根据情况选定,岭回归模型训练的具体代码如下 class RidgeRegression: def fit(self, X: np.ndarray, y: np.ndarray): N, D = X.shape I = np.identity(D + 1) I[D][D] = 0 expand_X = np.column_stack((X, np.ones((N, 1)))) self.W = np.matmul(np.matmul(np.linalg.inv(np.matmul(expand_X.T, expand_X) + self.reg * I), expand_X.T), y) return self.loss(X, y)4.数据集实验 这里使用了随机生成的二位数据点来对线性模型进行测试,测试结果如下: image.png图片 线性模型测试结果 岭回归也使用同样的代码进行测试。
机器学习
软硬件算法
# 机器学习
# 软件算法
刘航宇
3年前
0
361
1
联发科2024年数字IC设计验证实习生考题解析
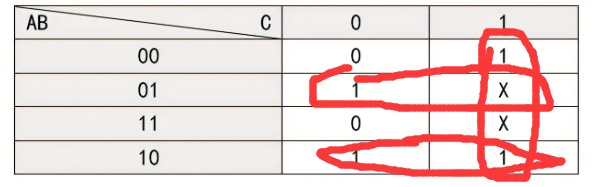
总体而言难度中等偏上,如有错误欢迎指正,考察感觉更像是考察嵌入式工程师(有STM32、FPGA基础就很轻松):有数电、模电、python、verilog、C语言、SOC系统等基础知识,可以看到其实很对口电子信息类专业如电子信息、微电子、通信工程、电子科学、集成电路等专业,没有考察模集如果考模集大部分人要G,数集也没考,可能太底层了与工业界需求有偏差,数集在笔试面试中我认为如果考,可能考时序与功耗部分。这里的Round-Robin算法很值得学习。 目录 1、(20分)逻辑化简: 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 3、(10分)智力题 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 1、(20分)逻辑化简: 图片 (1)列出真值表 (2)列出其卡诺图 (3)写出Z的最简表达式 答:卡诺图:卡诺图画完后勾1就完事了 提示:约束项的一般形式为:与或式 = 0 (如果不是此种形式,化为此种形式);如此题的BC = 0;或者AB +CD = 0;ABC + CD = 0;等等。BC=0(即B=1,且C=1)对应的格子画X。 图片 图片 2、(5分)ASIC flow 中综合工具的作用是什么?综合的时候需要SDC文件进行约束,请列举3条SDC的语法。 答:ASIC flow 中综合工具的作用是将RTL级的硬件描述语言转换为与特定工艺库相匹配的门级网表,同时进行优化以满足时序、面积和功耗等约束。 综合的时候需要SDC文件进行约束,SDC文件是一种基于Tcl的格式,用于指定设计的时序约束34。SDC文件中的常用时序约束语法有: create_clock -name <clock_name> -period <clock_period> [get_ports <clock_port>] 用于创建时钟源并指定时钟周期。 set_input_delay -clock <clock_name> <delay_value> [get_ports <input_port>] 用于指定输入端口相对于时钟源的延迟。 set_output_delay -clock <clock_name> <delay_value> [get_ports <output_port>] 用于指定输出端口相对于时钟源的延迟。 set_clock_uncertainty -setup <setup_value> -hold <hold_value> <clock_name> 用于指定时钟源的不确定性,包括建立时间和保持时间。 set_false_path -from [get_ports <source_port>] -to [get_ports <destination_port>] 用于指定不需要进行时序分析的路径。 set_multicycle_path -setup -from [get_clocks <source_clock>] -to [get_clocks <destination_clock>] <cycle_number> 用于指定多周期路径,即源时钟和目标时钟之间有多个周期的时间差。3、(10分)智力题 (1)2 12 1112 3112 132112 ,下一个数?给理由; 答:第一个数是2,第二个数是12,表示前一个数有1个2;第三个数是1112,表示前一个数有1个1和1个2;以此类推。所以,下一个数是1113122112,表示前一个数有1个1,1个3,2个1和2个2 (2)有一个小偷费劲力气进入到了银行的金库里。在金库里他找到了一百个箱子,每一个箱子里都装满了金币。不过,只有一个箱子里装的是真的金币,剩下的99个箱子里都是假的。真假金币的外形和质感完全一样,任何人都无法通过肉眼分辨出来。它们只有一个区别:真金币每一个重量为101克,而假金币的重量是100克。在金库里有一个电子秤,它可以准确地测量出任何物品的重量,精确到克。但很不幸的是,这个电子秤和银行的报警系统相连接,只要被使用一次就会立刻失效。请问,小偷怎么做才能只使用一次电子秤就找到装着真金币的箱子呢? 答:小偷可以这样做:从第一个箱子里拿出1个金币,从第二个箱子里拿出2个金币,从第三个箱子里拿出3个金币,以此类推,直到从第一百个箱子里拿出100个金币。然后,把所有拿出来的金币放在电子秤上,测量它们的总重量。如果所有的金币都是假的,那么总重量应该是5050克(等于1+2+3+…+100)。如果有一个箱子里是真的金币,那么总重量会比5050克多出一些。这个多出来的部分就是真金币的数量乘以1克。例如,如果第十一个箱子里是真的金币,那么总重量会比5050克多出11克,因为从第十一个箱子里拿出了11个真金币。所以,小偷只要看电子秤上显示的数字减去5050,就能知道哪个箱子里是真的金币了。 4、(10分)选择参与过的任一个项目,简述项目内容以及流程,讲述您在项目中承担的任务,挑一项你认为难的地方并阐述解决方案。 答:优先答ASIC的设计与验证项目,其次是FPGA项目(如基于FPGA的图像处理、天线阵、雷达、加速器等等),其它项目不要答。 5、(5分)用python写一个冒泡排序的函数以及测试程序。 # 定义冒泡排序函数 def bubble_sort(lst): # 获取列表长度 n = len(lst) # 遍历列表n-1次 for i in range(n-1): # 设置一个标志,用于判断是否发生交换 swapped = False # 遍历未排序的部分 for j in range(n-1-i): # 如果前一个元素大于后一个元素,交换位置 if lst[j] > lst[j+1]: lst[j], lst[j+1] = lst[j+1], lst[j] # 标志设为True,表示发生了交换 swapped = True # 如果没有发生交换,说明列表已经有序,提前结束循环 if not swapped: break # 返回排序后的列表 return lst # 定义测试程序 # 创建一个乱序的列表 lst = [5, 3, 8, 2, 9, 1, 4, 7, 6] # 打印原始列表 print("Original list:", lst) # 调用冒泡排序函数,对列表进行排序 lst = bubble_sort(lst) # 打印排序后的列表 print("Sorted list:", lst)结果图 image.png图片 6、(15分)用Verilog 写一个 Round Robin 仲裁器。模块端口如下: input clock; input reset_b; input [N-1:0] request; input [N-1] lock; output [N-1] grant; //one-hot此处的 lock 输入信号,表示请求方收到了仲裁许可,在对应的lock拉低之前,仲裁器不可以开启新的仲裁。(可简单理解为仲裁器占用) 该题要求参数化编程,在模块例化时可调整参数。也即是说你不能写一个固定参数,比如N=8的模块。 参考波形图: image.png图片 答: Round-Robin算法:当有多个设备同时想占用同一个资源时,需要仲裁器通过某种调度算法决定不同设备使用资源的先后顺序。 Round Robin算法就是其中一种调度算法,其思路是,当多个仲裁请求(request)送给仲裁器时,仲裁器通过轮询的方式分时给不同的设备返回许可(grant),当一个requestor 得到了grant许可之后,它的优先级在接下来的仲裁中就变成了最低,当同时有多个requestor的时候,grant可以依次给到每个requestor,即使之前高优先级的requestor再次有新的request,也会等前面的requestor都grant之后再轮到它。由此看出,Round Robin算法是一种公平的算法,它避免了当最高优先级的requestor不断有新的request时,具有最高优先级的requestor一直占用资源,导致其他requestor无法占用资源的阻塞现象。 在verilog设计中,如何实现呢?假设request是位宽是6,最高位是第5位,最低位是第0位,默认低比特位具有高优先级。 1.首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1。 2.在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持,这个操作可以利用掩码111000和request相与实现得到。 得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 3.通过第二步得到第2位到第0位被屏蔽的request_new信号,判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位,则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 // 功能: // -1- Round Robin 仲裁器 // -2- 仲裁请求个数N可变 // -3- 加入lock机制(类似握手) // -4- 复位时的最高优先级定为 0 ,次优先级:1 -> 2 …… -> N-2 -> N-1 `timescale 1ns / 1ps module RoundRobinArbiter #( parameter N = 4 //仲裁请求个数 )( input clock, input reset_b, input [N-1:0] request, input [N-1:0] lock, output reg [N-1:0] grant//one-hot ); // 模块内部参数 localparam IDLE = 3'b001;// 复位进入空闲状态,接收并处理系统的初次仲裁请求 localparam WAIT_REQ_GRANT = 3'b010;// 等待后续仲裁请求到来,并进行仲裁 localparam WAIT_LOCK = 3'b100;// 等待LOCK拉低 // 模块内部信号 reg [2:0] R_STATUS; //请求状态 reg [N-1:0] R_MASK; //掩码 wire [N-1:0] W_REQ_MASKED; assign W_REQ_MASKED = request & R_MASK; //屏蔽低位 always @ (posedge clock) begin if(~reset_b) begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end else begin case(R_STATUS) IDLE: begin if(|request) //首次仲裁请求,不全为0 begin R_STATUS <= WAIT_LOCK; //首先需要找到request中优先级最高的比特位,对优先级最高的比特位给出许可信号。 //这一步可以通过request和它的2的补码按位与。这是因为一个数和它的补码相与,得到的结果是一个独热码,独热码为1的那一位是这个数最低的1 grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); //得到掩码的方法是,对第一步的许可信号grant-1,再与grant本身相或,相或的结果再取反。 end else begin R_STATUS <= IDLE; end end WAIT_REQ_GRANT://处理后续的仲裁请求 begin if(|request) begin R_STATUS <= WAIT_LOCK; //在下一轮仲裁中,已经被仲裁许可的比特位变成了最低优先级,而未被仲裁许可的比特位将会被仲裁。 //因此对第一步中给出许可的比特位(假设是第2位)以及它的低比特位进行屏蔽,对request中的第5位到第3位进行保持 //这个操作可以利用掩码111000和request相与实现得到。 if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end //通过第二步得到第2位到第0位被屏蔽的request_new信号, //判断request_new是否为全0信号,如果是全0信号,代表此时不存在需要被仲裁的比特位,则返回第一步:找到request中优先级最高的比特位, //对优先级最高的比特位给出许可信号,然后进行第二步。如果request_new不是全0信号,代表存在未被仲裁的比特位, //则找到request_new中优先级最高的比特位,对优先级最高的比特位给出许可信号,然后进行第二步。 WAIT_LOCK: begin if(|(lock & grant)) //未释放仲裁器 begin R_STATUS <= WAIT_LOCK; end else if(|request) //释放的同时存在仲裁请求 begin R_STATUS <= WAIT_LOCK; if(|(request & R_MASK))//不全为零 begin grant <= W_REQ_MASKED & ((~W_REQ_MASKED)+1); R_MASK <= ~((W_REQ_MASKED & ((~W_REQ_MASKED)+1))-1 | (W_REQ_MASKED & ((~W_REQ_MASKED)+1))); end else begin grant <= request & ((~request)+1); R_MASK <= ~((request & ((~request)+1))-1 | (request & ((~request)+1))); end end else begin R_STATUS <= WAIT_REQ_GRANT; grant <= 0; R_MASK <= 0; end end default: begin R_STATUS <= IDLE; R_MASK <= 0; grant <= 0; end endcase end end endmodule测试代码 `timescale 1ns / 1ps module RoundRobinArbiter_tb; parameter N = 4; // 可以在测试时调整参数 // 定义测试信号 reg clock; reg reset_b; reg [N-1:0] request; reg [N-1:0] lock; wire [N-1:0] grant; // 定义时钟信号 initial clock = 0; always #10 clock = ~clock; // 实例化仲裁器模块 RoundRobinArbiter #( .N(N) ) inst_RoundRobinArbiter ( .clock (clock), .reset_b (reset_b), .request (request), .lock (lock), .grant (grant) ); // 定义时钟周期和初始值 initial begin reset_b <= 1'b0; request <= 0; lock <= 0; end // 定义请求和锁定信号的变化 initial begin #20; reset_b <= 1'b1; @(posedge clock) request <= 2; lock <= 2; @(posedge clock) request <= 0; @(posedge clock) request <= 5; lock <= 7; @(posedge clock) lock <= 5; @(posedge clock) request <= 1; @(posedge clock) lock <= 1; @(posedge clock) request <= 0; @(posedge clock) lock <= 0; #1000 $stop; // 测试结束 end // 显示测试结果和波形图 initial begin $monitor("Time=%t, clock=%b, reset_b=%b, request=%b, lock=%b, grant=%b", $time, clock, reset_b, request, lock, grant); $dumpfile("RoundRobinArbiter_tb.vcd"); $dumpvars(0,RoundRobinArbiter_tb); end endmodule结果: image.png图片 如果对波形图无法理解可以看此博文 https://blog.csdn.net/m0_49540263/article/details/114967443 7、(15分)关于DMA寄存器配置,DMA寄存器(地址 0x81050010)表: image.png图片 image.png图片 Type 表示读写类型。Reset 表示复位值。 写一个C函数 void dma_driver(void),按步骤完成以下需求: 分配DMA所需的源地址(0x30) 分配DMA所需的目的地址(0x300) 设置传输128 Byte 数据 开始DMA传输 等待DMA传输结束 答: // 假设有以下宏定义 #define DMA_REG 0x81050010 // DMA控制寄存器的地址 #define DMA_SRC_ADDR 0x30 // DMA源地址 #define DMA_DST_ADDR 0x300 // DMA目的地址 #define DMA_SIZE 128 // DMA传输大小 #define DMA_START 1 // DMA开始传输的标志位 // 定义C函数 void dma_driver(void) void dma_driver(void) { // 定义一个指向DMA控制寄存器的指针 volatile uint32_t *dma_reg = (volatile uint32_t *)DMA_REG; // 清空DMA控制寄存器的值 *dma_reg = 0; // 设置DMA源地址,目的地址和传输大小 *dma_reg |= (DMA_SRC_ADDR << 2) | (DMA_DST_ADDR << 13) | (DMA_SIZE << 24); // 开始DMA传输 *dma_reg |= DMA_START; // 等待DMA传输结束 while (*dma_reg & DMA_START) { // 可以在这里做一些其他的事情,比如打印日志或者检查错误 // printf("Waiting for DMA to finish...\n"); // check_error(); } }官方一点的表达:DMA,全称为:Direct Memory Access,即直接存储器访问。直接存储器存取( DMA )用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须 CPU 干预,数据可以通过 DMA 快速地移动,这就节省了 CPU 的资源来做其他操作。典型的例子就是移动一个外部内存的区块到芯片内部更快的内存区。像是这样的操作并没有让处理器工作拖延,反而可以被重新排程去处理其他的工作。DMA 传输对于高效能嵌入式系统算法和网络是很重要的。DMA 传输方式无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场的过程,通过硬件为 RAM 与 I/O 设备开辟一条直接传送数据的通路, 能使 CPU 的效率大为提高。 8、(20分)二阶带通滤波器,利用RC组件搭建,通带范围 1kHz~30kHz ,两个电阻 R 均为10kΩ ,问两个电容容值多少? 答:第一步首得知道二阶带通(RC)滤波器的电路长啥样,高、低通组合一下就是带通,自己思考一下高、低通组合:如串联或并联,会得到带通还是带组? 电路图: H___H21L__E34_WC@43F1_8.jpg图片 这个一看就是总传递函数=A1*A2(模电二阶有源或无源滤波器绝对有) _LIYXIHR_08YNK__EV8SXDH.jpg图片 然后化简 X25LO__~TXMGO59LTLV@9S9.jpg图片 根据推导得到的表达式,对于 jwRC2 ,这一项,当 w 趋于无穷大时,uo/ui 趋于零。那么高频的临界点就是 wRC2 = 1+2C2/C1;(此时忽略低频项1/jwRC1) 同理,对于低频项 1 /jwRC1, w 趋于无穷小时,uo/ui 趋于零 ,那么低频的临界点就是 1/wRC1 = 1+2C2/C1;然后解二元一次方程两个电容就被解出来了 这里提供一种更简单方法: 二阶带通滤波器的中心频率 f0 和品质因数 Q 可以用下面的公式计算: image.png图片 已知 R1 = R2 = 10kΩ,f0 = (1kHz + 30kHz) / 2 = 15.5kHz,Q = f0 / (30kHz - 1kHz) = 0.54,代入上面的公式,可以求得: image.png图片 这是一个二元一次方程组,可以用任意方法求解,例如消元法或代入法。为了方便起见,我们假设 C1 和 C2 的值相近,那么可以近似地认为 C1 = C2 = 3.45nF。这样就得到了两个电容的容值。当然,也可以选择其他的电容值,只要满足上面的方程组即可。
FPGA&ASIC
软硬件算法
# 笔试面试
刘航宇
3年前
0
2,100
9
2023-04-17
MIMO波束赋形技术简介
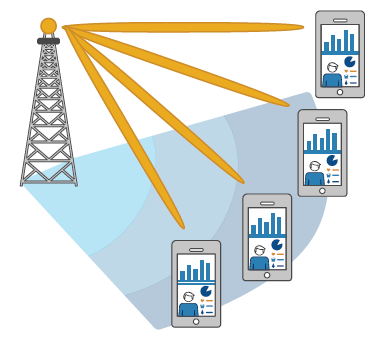
目录 前言 波束赋形分类 阵列天线 混合波束赋形 总结 参考文献: 前言 在MIMO系统中,波束赋形技术通过调整每个天线阵元上的信号进行加权求和,使天线波束指向某个特定的方向,即将天线能量集中指向某个特定的用户。 d6fb0a3cc8e32c0af0b75df51c853948.png图片 波束赋形分类 根据波束赋形发生位置的不同,波束赋形技术分为模拟波束赋形(AnalogBeamforming, ABF)技术和数字波束赋形(Digital Beamforming, DBF)技术。 4a28f76d72a4df8e47e74e783c80ae1f.png图片 在数字基带之前即时域范围内形成波束,称作数字波束赋形; 在模拟基带之前即频域范围内形成波束,称作模拟波束赋形。 数字波束赋形结构中,每根天线对应的一条射频(RF)链路,产生波束时多条RF链路共同参与,因此可以实现多个数据流共同传输。数字波束赋形使用复杂的硬件结构,可以灵活的调整相位和幅度,产生准确的波束。对于天线数量众多时,导致整个结构的硬件实现非常复杂,成本很高。 模拟波束赋形技术使用成本比较低的模拟移相器,只能调整相位而不能调整幅度,产生波束不一定准确。模拟波束赋形,具有简单的硬件结构,实现成本低,没有多条RF链路,只能传输单数据流 阵列天线 阵列天线实现功能是对多列电磁波进行叠加,不同天线位置会产生不同的电磁波辐射,因此,波束赋形技术与天线位置和摆放有密切关系。 阵列天线包括线阵天线和面阵天线两种 afef214955805f1abe5b1b4a20eee39f.png图片 线阵天线是指所有天线阵元分布在一条直线上,或者所有天线阵元分布在一个圆周上,阵元与阵元的间隔可以是等距的或不等距的; 面阵天线是指所有天线阵元以某个点为中心分布在一个矩形面上,或者所有天线阵元分布在一个圆面上,同样,阵元与阵元的间隔可以是等距的或不等距的。 对于F大线数量较多的情况,天线阵列可能会扩展到三维空间,也是未米人线架构设计的一个方向。 混合波束赋形 数字波束赋形可以产生精确的波束,但是每根天线映射一条RF链路,从硬件实现和成本考虑,该技术适用于天线数量较少的系统。 对于天线数量较多的系统,可以使用实现成本较低的模拟波束赋形,可能导致波束不准确,增益效果不是很好。 7970fc6d2b411b56dab8bc2ab3ff71e9.png图片 因此,对于大规模MIMO系统,结合两者优点,提出了一种混合波束赋形技术,希望在满足硬件条件下,使其增益尽可能达到全数字波束赋形的效果。 在较小的面积内拥有大量天线单元使实现高波束成形增益变得切实可行。具有高度方向性的波束有助于抵消较高工作频率下增加的路径损耗,因为波束将功率控制在特定方向上。 2e760e3d1161bacec0599f6b4fe0d4d9.png图片 总结 Simulink和Matlab联合仿真,能够设计并且仿真单个天线,天线阵列,MIMO波束成型系统。对于雷达、5G等方向,有着重要意义。当然,工具不仅仅只有这一个,ADS也能设计从射频波束混合系统,到天线阵列的仿真。 参考文献: [1]使用Matlab进行5G开发
通信&信息处理
# 通信&射频
刘航宇
3年前
0
1,623
2
【电路基础】ASIC角度练习JK触发器&RS触发器
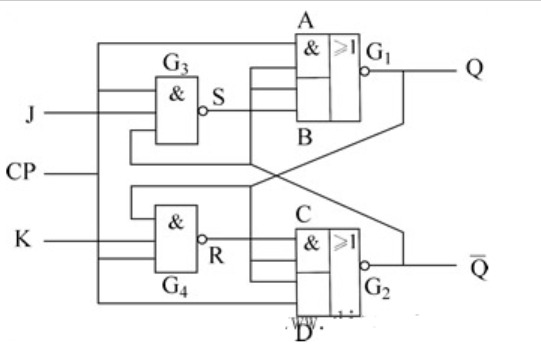
由于本电路极其简单,原理不做解释 目录 JK触发器真值表 硬件描述语言 JK触发器时序 JK触发器电路图 JK触发器性能--SMIC180nm工艺 RS触发器真值表 RS硬件描述语言 RS触发器时序 RS触发器电路图 RS触发器性能--SMIC180nm工艺 JK触发器 真值表 图片 硬件描述语言 代码 //边沿JK触发器-时序逻辑 //作者:刘航宇 2023/4/15 //Email:hyliu@ee.ac.cn module jk_trigger(clk,j,k,q,qb); input clk,j,k; output q,qb; reg q; wire qb; always @(posedge clk) begin case ({j,k}) 2'b00: q<=1; //jk=00,保持 2'b01: q<=1'b0; //jk=01,则触发器置0 2'b10: q<=1'b1; //jk=10,则触发器置1 2'b11: q<=~q; //11,翻转 //组合逻辑中,为避免生成锁存器,好的代码风格是if语句都加上else,case语句都加上default。 //时序逻辑中,“若无必要,尽量不加else和default”——以减小数据翻转机会,低功耗。 //故此处不写default endcase end assign qb = ~q; endmodule测试文件 //jk触发器测试文件 `timescale 1ns/1ps module jk_trigger_tb; reg j,k,clk;//输入reg是因为要initial wire q,qb; always begin #5 clk = ~clk; end //初始化 //下面这个产生fsdb是Synopsys VCS&Makefile脚本会用到,如果你用Medelsim仿真请删掉这个initial语句以免报错 initial begin $fsdbDumpfile("tb.fsdb");//这个是产生名为tb.fsdb的文件 $fsdbDumpvars; end initial begin clk = 0; j = 1'b0; k = 1'b0;//保持 #30 begin j=1'b0;k=1'b1; end //置0 #20 begin j=1'b1;k=1'b0; end //置1 #20 begin j=1'b0;k=1'b0; end //保持 #20 begin j=1'b1;k=1'b1; end //翻转 #200 $finish; end jk_trigger u1(.j(j),.k(k),.clk(clk),.q(q),.qb(qb)); endmoduleJK触发器时序 上升沿触发,可以看到时序完全正确 图片 JK触发器电路图 图片 之所以这样综合电路综合出一个D触发器,是考虑标准单元库的面积与时序的折中,标准单元相当于基本晶体管搭建而成,比如反相器占用2个晶体管,与非门占用4个晶体管,具体不在赘叙。 图片 图片 JK触发器性能--SMIC180nm工艺 图片 RS触发器 真值表 图片 RS硬件描述语言 代码 //边沿JK触发器-时序逻辑 //作者:刘航宇 2023/4/15 //Email:hyliu@ee.ac.cn module rs_trigger( input wire clk,r,s, output reg q, output wire qb ); always @(posedge clk) begin case ({r,s}) 2'b00: q<=q; //r,s同时为低电平,触发器保持状态不变 2'b01: q<=1'b1; //触发器置1 2'b10: q<=1'b0; //触发器置0 2'b11: q<=1'bx; //不定态 endcase end assign qb = ~q; endmodule测试代码 `timescale 1ns/1ps module rs_trigger_tb(); reg clk,r,s; wire q,qb; always begin #5 clk = ~clk; end //初始化 initial begin clk = 0; r = 1'b0; s = 1'b0;//保持 #30 r=1'b0;s=1'b1; //置1 #20 r=1'b1;s=1'b0; //置0 #20 r=1'b0;s=1'b0; //保持 #20 r=1'b1;s=1'b1; //禁止 #200 $stop; end rs_trigger u2(.clk(clk),.r(r),.s(s),.q(q),.qb(qb)); endmoduleRS触发器时序 上升沿触发,可以看到时序完全正确 图片 RS触发器电路图 image.png图片 image.png图片 image.png图片 RS触发器性能--SMIC180nm工艺 image.png图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
1,505
2
2023-04-12
浅谈如何学好IC验证
要成为一名IC验证工程师,一定要懂一些设计,如果都不清楚自己在验什么东西,后面的工作也都无从谈起了。所以在时间足够的情况下,最好从最基础的数字电路知识开始学习,之后是 Verilog → SystemVerilog → UVM 这样一个顺序,需要具备以下一些能力: 掌握数字电路和Verilog的基础知识,了解芯片设计的流程和结构。 学习SystemVerilog和UVM等验证语言和方法学,能够搭建和使用验证环境,构建测试用例和激励场景。 熟悉Linux操作系统和常用的EDA工具,能够使用脚本语言如Perl或Python进行自动化测试。 能够阅读和理解设计规格,分析设计功能和边界条件,设计有效的覆盖率和断言。 能够对设计缺陷进行调试和修改建议,与设计工程师进行沟通和协作。 不断学习新的协议、技术和验证方法,提高验证效率和质量。 图片 学习UVM的方法有很多,但是一般来说,需要具备以下几个方面的知识: SystemVerilog的基础语法和面向对象编程的概念,如类、继承、多态等。 UVM的基本构架和组件,如test、env、agent、driver、monitor、sequencer、sequence等,以及它们之间的连接和通信机制。 UVM的高级功能和技巧,如factory、callback、register model、coverage等,以及如何使用它们来提高验证效率和可重用性。 UVM的实际应用和案例分析,如如何搭建一个完整的UVM验证环境,如何编写不同类型的测试用例,如何处理异常情况等。 为了学习UVM,可以参考以下一些资源: Verification Academy是一个提供免费在线课程和视频的网站,其中有专门针对UVM的基础和进阶课程,以及一些实例代码和演示。 https://verificationacademy.com/courses/uvm-basics UVM实战是一本中文书籍,介绍了UVM的基本概念和方法,以及一些常见的验证场景和技巧。 UVM Cookbook3是一个在线文档,提供了UVM的各种知识点和示例代码,可以作为一个参考手册。 https://www.cnblogs.com/dpc525/p/5047032.html
我的随笔
VLSI&IC验证
刘航宇
3年前
0
823
4
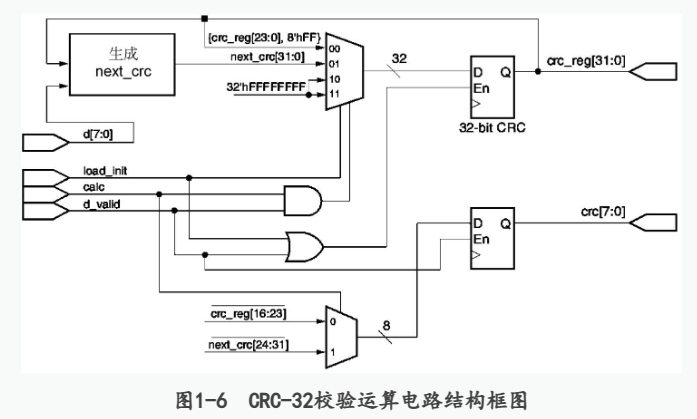
【硬件算法进阶】Verilog实现802.3 CRC-32校验运算电路
循环冗余校验(Cyclic Redundancy Check,CRC)是通信中常用的差错检测编码方式,其基本工作原理是根据输入的信息位(信息码元),按照给定的生成多项式产生校验位(校验码元),并一起传送到接收端。在接收端,接收电路按照相同的规则对接收数据进行计算并生成本地的校验位,然后与收到的校验位进行对比,如果二者不同,则说明传输过程中发生了错误,否则说明传输是正确的。带有CRC校验结果的数据帧结构如表1-2所示。 image.png图片 CRC检验位生成与检测工作包括以下基本步骤。 image.png图片 图1-6是一个并行CRC-32校验运算电路。图中的d[7:0]是输入的用户数据,它是按照字节的方式输入的。load_ini是在对一个新的数据包开始校验计算之前对电路进行初始化的控制信号,经过初始化后,电路内部32比特寄存器的值改变为全1。calc是电路运算指示信号,在整个数据帧输入和CRC校验结果输出的过程中其都应该保持有效(高电平有效)。d_valid为1时表示当前输入的是需要进行校验运算的有效数据。crc[7:0]是电路输出的CRC校验运算结果,它是按照字节方式,在有效数据输入完成后开始输出的,一共有4个有效字节。crc_reg[31:0]是内部寄存器的值,具体使用时不需要该输出。 image.png图片 并行计算的思想,输入数据S要并行输入到G(x)系数为1的支路中,输入数据从输入端按高到低逐bit输入,就可以实现。 假如被除数是2位的数据S[1:0]=01,多项式是10011,x4 +x+1。在CRC校验里面,习惯省略最高位的1,多项式用0011表示。那么S除以0011的模二运算数字电路结构为: image.png图片 其中d1~ d4是寄存器输入;q1~q4是寄存器输出。寄存器需要赋初值,一般赋全1或全0。 d1=S[1]^q4; d2= S[1]^ q1^q4; d3=q2; d4=q3。 经过一次移位后: q1=d1= S[1]^q4; q2= d2= S[1]^ q1^q4; q3= d3=q2; q4= d4=q3。 此时有: d1=S[0]^q3; d2= S[0]^ S[1]^ q4^q3; d3= S[1]^ q1^q4; d4= q2。 令c[3:0]={q4,q3,q2,q1},d[3:0]={d4,d3,d2,d1},那么d就是最终的运算结果表达式,如下 d[3]=c[1]; d[2]= S[1]^ c[0]^c[3]; d[1]= S[0]^ S[1]^ c[3]^ c[2]; d[0]= S[0]^ c[2]。 令c的初值为0,则01对0011的模二除法的余数为0011。 再比如多项式为x5 +x3 +x+1,简记式为01011,其数字电路结构为: image.png图片 输入数据S要全部输入完,寄存器得到的结果才是最后的结果。同理可推导出其他多项式和输入数据的情况。 对于循环检验,这里举个例子,如果数据是10bit*100个包,则每次输入10bit得到校验码后,该检验码为下次数据计算时寄存器D的初值,如此反复计算得到最后的检验码添加到整个数据后面即可,而不需要每个数据包后面都添加检验码。 下面是以太网循环冗余校验电路的设计代码: module crc32_8023( clk, reset, d, load_init, calc, d_valid, crc_reg, crc ); input clk; input reset; input [7:0] d; input load_init; input calc; input d_valid; output reg [31:0] crc_reg; output reg [7:0] crc; wire [2:0] ctl; wire [31:0] next_crc; wire [31:0] i; assign i = crc_reg; assign ctl = {load_init,calc,d_valid}; always @(posedge clk or posedge reset) begin if(reset) crc_reg <= 32'hffffffff; else begin case (ctl) //{load_init,calc,d_vaild} 3'b000,3'b010: begin crc_reg <= crc_reg; crc <= crc;end 3'b001: begin crc_reg <= {crc_reg[23:0],8'hff}; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b011: begin crc_reg <= next_crc[31:0]; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end 3'b100,3'b110: begin crc_reg <= 32'hffffffff; crc <= crc; end 3'b101: begin crc_reg <= 32'hffffffff; crc <= ~{crc_reg[16],crc_reg[17],crc_reg[18],crc_reg[19],crc_reg[20],crc_reg[21],crc_reg[22],crc_reg[23]}; //crc <= ~ crc_reg[16:23]; end 3'b111: begin crc_reg <= 32'hffffffff; crc <= ~{next_crc[24],next_crc[25],next_crc[26],next_crc[27],next_crc[28],next_crc[29],next_crc[30],next_crc[31]}; //crc <= ~ next_crc[24:31]; end endcase end end assign next_crc[0] = d[7]^i[24]^d[1]^i[30]; //d+i=31 assign next_crc[1] = d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[30]^i[31]; assign next_crc[2] = d[5]^d[6]^d[0]^d[7]^d[1]^i[24]^i[25]^i[26]^i[30]^i[31]; assign next_crc[3] = d[4]^d[5]^d[6]^d[0]^i[25]^i[26]^i[27]^i[31]; assign next_crc[4] = d[3]^d[4]^d[5]^d[7]^d[1]^i[24]^i[26]^i[27]^i[28]^i[30]; assign next_crc[5] = d[0]^d[1]^d[2]^d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[29]^i[30]^i[31]; assign next_crc[6] = d[0]^d[1]^d[2]^d[3]^d[5]^d[6]^i[25]^i[26]^i[28]^i[29]^i[30]^i[31]; assign next_crc[7] = d[0]^d[2]^d[4]^d[5]^d[7]^i[24]^i[26]^i[27]^i[29]^i[31]; assign next_crc[8] = d[3]^d[4]^d[6]^d[7]^i[24]^i[25]^i[27]^i[28]^i[0]; //每项多出i[i],i=0、1、2...23 assign next_crc[9] = d[2]^d[3]^d[5]^d[6]^i[1]^i[25]^i[26]^i[28]^i[29]; assign next_crc[10] =d[2]^d[4]^d[5]^d[7]^i[2]^i[24]^i[26]^ i[27]^i[29]; assign next_crc[11] =i[3]^d[3]^i[28]^d[4]^i[27]^d[6]^i[25]^d[7]^i[24]; assign next_crc[12] =d[1]^d[2]^d[3]^d[5]^d[6]^d[7]^i[4]^i[24]^i[25]^i[26]^i[28]^i[29]^i[30]; assign next_crc[13] =d[0]^d[1]^d[2]^d[4]^d[5]^d[6]^i[5]^i[25]^i[26]^i[27]^i[29]^i[30]^i[31]; assign next_crc[14] =d[0]^d[1]^d[3]^d[4]^d[5]^i[6]^i[26]^i[27]^i[28]^i[30]^i[31]; assign next_crc[15] =d[0]^d[2]^d[3]^d[4]^i[7]^i[27]^i[28]^i[29]^i[31]; assign next_crc[16] =d[2]^d[3]^d[7]^i[8]^i[24]^i[28]^i[29]; assign next_crc[17] =d[1]^d[2]^d[6]^i[9]^i[25]^i[29]^i[30]; assign next_crc[18] =d[0]^d[1]^d[5]^i[10]^i[26]^i[30]^i[31]; assign next_crc[19] =d[0]^d[4]^i[11]^i[27]^i[31]; assign next_crc[20] =d[3]^i[12]^i[28]; assign next_crc[21] =d[2]^i[13]^i[29]; assign next_crc[22] =d[7]^i[14]^i[24]; assign next_crc[23] =d[1]^d[6]^d[7]^i[15]^i[24]^i[25]^i[30]; assign next_crc[24] =d[0]^d[5]^d[6]^i[16]^i[25]^i[26]^i[31]; assign next_crc[25] =d[4]^d[5]^i[17]^i[26]^i[27]; assign next_crc[26] =d[1]^d[3]^d[4]^d[7]^i[18]^i[28]^i[27]^i[24]^i[30]; assign next_crc[27] =d[0]^d[2]^d[3]^d[6]^i[19]^i[29]^i[28]^i[25]^i[31]; assign next_crc[28] =d[1]^d[2]^d[5]^i[20]^i[30]^i[29]^i[26]; assign next_crc[29] =d[0]^d[1]^d[4]^i[21]^i[31]^i[30]^i[27]; assign next_crc[30] =d[0]^d[3]^i[22]^i[31]^i[28]; assign next_crc[31] =d[2]^i[23]^i[29]; endmodule测试代码 `timescale 1ns/1ns module crc_test(); reg clk, reset; reg [7:0] d; reg load_init; reg calc; reg data_valid; wire [31:0] crc_reg; wire [7:0] crc; initial begin clk=0; reset=0; load_init=0; calc=0; data_valid=0; d=0; end always begin #10 clk=1; #10 clk=0; end always begin crc_reset; crc_cal; end task crc_reset; begin reset=1; repeat(2)@(posedge clk); #5; reset=0; repeat(2)@(posedge clk); end endtask task crc_cal; begin repeat(5) @ (posedge clk); //通过losd_init=1 对CRC计算电路进行初始化 #5; load_init= 1; repeat(1)@ (posedge clk); //设置1oad_init=0,data_valid= 1,calc=1 //开始对输人数据进行CRC校验运算 #5; load_init= 0; data_valid=1; calc=1; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hcc; repeat(1)@ (posedge clk); #5; data_valid=1; calc=1; d=8'hdd; repeat(1)@ (posedge clk); //设置load_init=0,data_valid=1,calc=0 //停止对数据进行CRC校验运算,开始输出 //计算结果 #5; data_valid=1; calc=0; d=8'haa; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hbb; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hee; repeat(1)@ (posedge clk); #5; data_valid=1; calc=0; d=8'hdd; repeat(1)@ (posedge clk); #5; data_valid=0; repeat(10)@ (posedge clk); end endtask crc32_8023 my_crc_test(.clk(clk),.reset(reset),.d(d),.load_init(load_init),.calc(calc),.d_valid(data_valid),.crc_reg(crc_reg),.crc(crc)); endmodule图1-7是电路的仿真结果。图中①是电路进行CRC校验计算之前对电路进行初始化操作的过程,经过初始化之后,crc_reg内部数值为全1。②是对输入数据aa-> bb-> cc-> dd进行运算操作的过程,此时calc和data_valid均为1。③是输出计算结果的过程,CRC校验运算结果a7、01、b4和55先后被输出。 图片 图片 在接收方向上,可以采用相同的电路进行校验检查,判断是否在传输过程中发生了差错。具体工作时,可以边接收用户数据边进行校验运算,当一个完整的MAC帧接收完成后(此时接收数据帧中的校验结果也参加了校验运算),如果当前校验电路的crc_reg值为0xC704DD7B(对于以太网中使用的CRC-32校验,无论原始数据是什么,正确接收时校验和都是此固定数值),说明没有发生错误,否则说明MAC帧有错。 CRC-32校验值的作用是用于检测数据传输或存储中的错误。发送数据时,会根据数据内容生成简短的校验和,并将其与数据一起发送。接收数据时,将再次生成校验和并将其与发送的校验和进行比较。如果两者相等,则没有数据损坏。如果两者不相等,则说明数据在传输或存储过程中发生了改变,可能是由于噪声、干扰、故障或恶意篡改等原因造成的。 CRC-32校验值可以有效地检测出数据中的随机错误,但是不能保证检测出所有的错误。例如,如果数据中有偶数个比特发生了翻转,那么CRC-32校验值可能不会改变,从而无法发现错误。因此,CRC-32校验值只能作为一种辅助的错误检测手段,不能完全依赖它来保证数据的正确性和完整性。 相关工具 如果不理解推导过程的话,可以由相关工具帮忙计算出结果和得到Verilog代码: CRC校验Verilog代码生成链接:http://outputlogic.com/?page_id=321 CRC校验计算工具链接:http://www.ip33.com/crc.html,这个工具只能计算16bit为一个数据包的数据,如果数据包为10bit等之类的就不太适用 在线计算器使用举例 报文 : 1011001 (0x59) 生成多项式 : g(x) = x^4 + x^3 + 1 CRC : 1010 ( 0xa) CRC计算结果截图: image.png图片 参考文献 Verilog HDL算法与电路设计-乔庐峰
FPGA&ASIC
软硬件算法
# ASIC/FPGA
# 硬件算法
刘航宇
3年前
0
2,230
3
2023-04-11
Design Compile(DC)优化性、高性能性综合
compile_ultra 具体使用方法参考DC manual compile_ultra跟compile一样,是进行编译的命令。compile_ultra命令适用于时序要求比较严格,高性能的设计。使用该命令可以得到更好的延迟质量( delay QoR ),特别适用于高性能的算术电路优化。该命令非常容易使用,它自动设置所有所需的选项和变量。下面是这个命令的一些介绍: compile_ultra命令包含了以时间为中心的优化算法,在编辑过程中使用的算法有: A、以时间为驱动的高级优化(Timing driven high-level optimization); B、 为算术运算选择适当的宏单元结构; C、从DesignWare库中选择最好的数据通路实现电路; D、映射宽扇入(Wide-fanin)门以减少逻辑级数; E、积极进取地使用逻辑复制进行负载隔离; F、在关键路径自动取消层次划分(Auto-ungrouping of hierarchies)。 compile_ultra命令支持DFT流程,此外compile_ultra命令非常简单易用,它的开关选项有: -scan :做可测试(DFT)编辑; -no_autoungroup :关掉自动取消划分特性; -no_boundary_optimization :不作边界优化; -no_uniquify : 加速含多次例化模块的设计的运行时间 -area_high_effort_script : 面积优化 -timinq_high_effort_script : 时序优化 上面的开关部分说明如下所示: 使用compile_ultra命令时,如使用下面变量的设置,所有的DesignWare层次自动地被取消: set compile_ultra_ungroup_dw true (默认值为true) 也就是说,你调用的一个加法器和一个乘法器,本来他们是以IP核的形式,或者说是以模块的形式进行综合的,但是设置了上面那么变量之后,综合后那个模块的界面就没有了,你不知道哪些门电路是加法器的,哪些是乘法器的。 使用compile_ultra命令时,使用下面的变量设置,如果设计中有一些模块的规模小于或等于变量的值,模块层次被自动取消: set compile_auto_ungroup_delay_num_cells 100(默认值=500) 也就是说,假设你有一个模块A是一个小的乘法器,并且调用了模块B,一个模块B是一个小的加法器,使用没有设置这条命令的情况综合,那么我们可以看到模块A中乘法器对应的门电路是哪些,同样也可以看到模块B的加法器是由哪些门电路构成的,模块A和模块B之间有层次、有界限;当设置上面的那条命令之后,我们就看不到模块A或者模块B之间的层次关系了,也看不到乘法器是由哪些门电路构成,或者说你看到了某一个与门,但是你并不知道它是构成乘法器的还是构成加法器的。
EDA&虚拟机
# EDA&虚拟机
刘航宇
3年前
0
1,143
2
【IC/CPU设计】极简的RISC_CPU设计
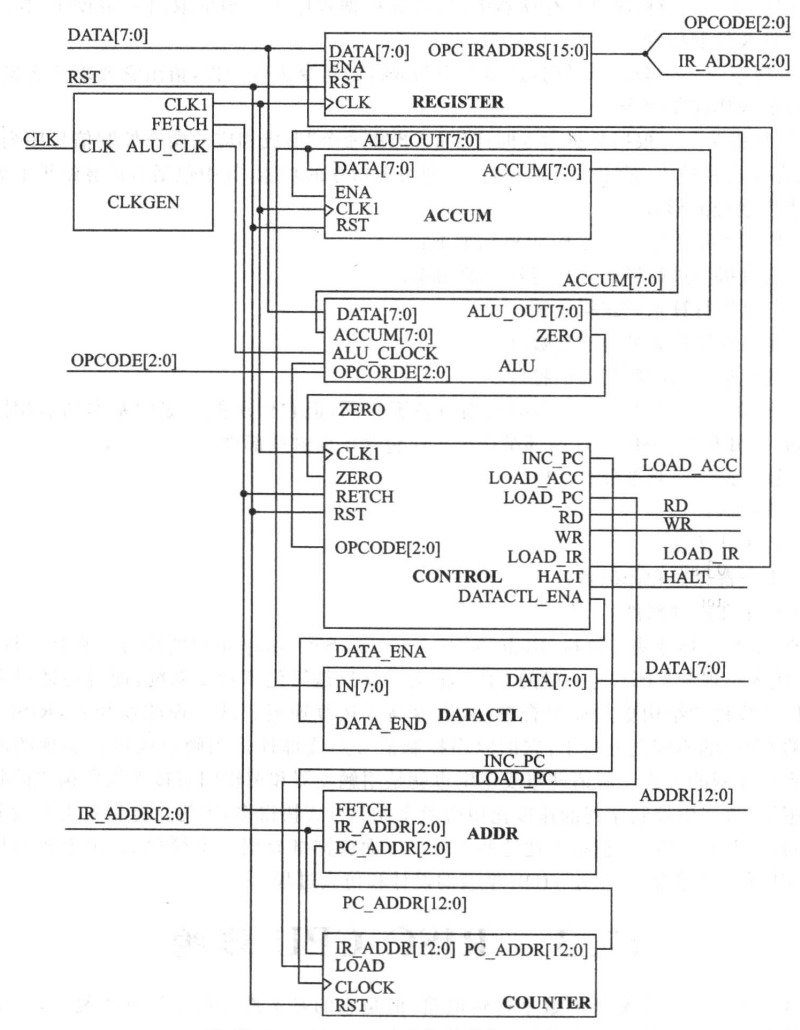
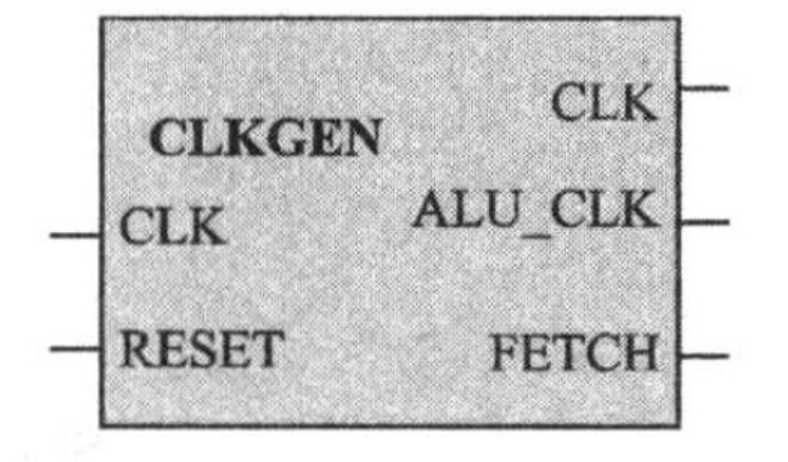
CPU为SOC系统的核心环节,该项目来自于夏宇闻老师的经典教材——《Verilog 数字系统设计教程》,通过此练习方便数字ICer更好的入门 本次项目实践环境: 前仿: Modelsim 综合: Design Compile 目录 CPU简介 整体结构时钟发生器 指令寄存器 累加器 算术运算器数据控制器 地址多路器 程序计数器 状态控制器&主状态机 外围模块地址译码器 RAM ROM 顶层模块 TestbenchTest1程序 Test3程序 完整的testbench 源代码&脚本 前仿真结果 DC后仿真 总结 CPU简介 CPU(Central Processing Unit),中文全称中央处理器,作为四大U之首(CPU/GPU/TPU/NPU),是计算机系统的运算和控制核心,也是当今数字系统中不可或缺的组成部分。CPU自诞生到如今发展超过50年,借助冯诺依曼体系,CPU掀起一股又一股的科技浪潮。RISC作为精简了指令集的CPU,除了指令更加简洁,还拥有简单合理的内部结构,从而提高了运算速度。 CPU工作的5个阶段: (1)取指(IF,Instruction Fetch),将指令从存储器取出到指令寄存器。每取一条指令,程序计数器自加一。 (2)译指(ID,Instruction Decode),对取出的指令按照规定格式进行拆分和译码。 (3)执行(EX,Execute),执行具体指令操作。 (4)访问存储(MEM,Memory),根据指令访问存储、完成存储和读取。 (5)写回(WB,Write Back),将计算结果写回到存储器。 CPU内部关键结构: (1)算术逻辑运算器(ALU); (2)累加器; (3)程序计数器; (4)指令寄存器和译码器; (5)时序和控制部件。 RISC_CPU内部结构和Verilog实现 本项目中的RISC_CPU一共有9个模块组成,具体如下: (1)时钟发生器; (2)指令寄存器; (3)累加器; (4)算术逻辑运算单元; (5)数据控制器; (6)状态控制器; (7)主状态机; (8)程序计数器; (9)地址多路器。 整体结构 图片 时钟发生器 模块图: image.png图片 端口描述: reset是高电平复位信号; clk是外部时钟信号; fetch是控制信号,是clk的八分频信号;fetch为高电平时,触发执行指令以及地址多路器输出指令地址和数据地址。 alu_ena是算术逻辑运算单元的使能信号。 图片 可以看到alu_ena提前fetch高电平一个clk周期,fetch是clk的8分频信号。 Verilog代码: // Description: RISC——CPU 时钟发生器 // ----------------------------------------------------------------------------- module clk_gen ( input clk , // Clock input reset , // High level reset output reg fetch , // 8 frequency division output reg alu_ena // Arithmetic enable ); reg [7:0] state; //One-piece state machine parameter S1 = 8'b0000_0001, S2 = 8'b0000_0010, S3 = 8'b0000_0100, S4 = 8'b0000_1000, S5 = 8'b0001_0000, S6 = 8'b0010_0000, S7 = 8'b0100_0000, S8 = 8'b1000_0000, idle = 8'b0000_0000; always@(posedge clk)begin if(reset)begin fetch <= 0; alu_ena <= 0; state <= idle; end else begin case(state) S1: begin alu_ena <= 1; state <= S2; end S2: begin alu_ena <= 0; state <= S3; end S3: begin fetch <= 1; state <=S4; end S4: begin state <= S5; end S5: state <= S6; S6: state <= S7; S7: begin fetch <= 0; state <= S8; end S8: begin state <= S1; end idle: state <= S1; default: state <=idle; endcase end end endmodule指令寄存器 模块图: 图片 端口描述: 寄存器是将数据总线送来的指令存入高8位或低8位寄存器中。 ena信号用来控制是否寄存。 每条指令为两个字节,16位,高3位是操作码,低13位是地址(CPU地址总线为13位,寻址空间为8K字节)。 本设计的数据总线为8位,每条指令需要取两次,先取高8位,再取低8位。 Verilog代码: // Description: RISC—CPU 指令寄存器 // ----------------------------------------------------------------------------- module register ( input [7:0] data , input clk , input rst , input ena , output reg [15:0] opc_iraddr ); reg state ; // always@( posedge clk ) begin if( rst ) begin opc_iraddr <= 16'b 0000_0000_0000_0000; state <= 1'b 0; end // if rst // If load_ir from machine actived, load instruction data from rom in 2 clock periods. // Load high 8 bits first, and then low 8 bits. else if( ena ) begin case( state ) 1'b0 : begin opc_iraddr [ 15 : 8 ] <= data; state <= 1; end 1'b1 : begin opc_iraddr [ 7 : 0 ] <= data; state <= 0; end default : begin opc_iraddr [ 15 : 0 ] <= 16'bxxxx_xxxx_xxxx_xxxx; state <= 1'bx; end endcase // state end // else if ena else state <= 1'b0; end endmodule 累加器 模块图: 图片 端口描述: 累加器用于存放当前结果,ena信号有效时,在clk上升沿输出数据总线的数据。 // Description: RISC-CPU 累加器模块 // ----------------------------------------------------------------------------- module accum ( input clk , // Clock input ena , // Enable input rst , // Asynchronous reset active high input [7:0] data , // Data bus output reg [7:0] accum ); always@(posedge clk)begin if(rst) accum <= 8'b0000_0000;//Reset else if(ena) accum <= data; end endmodule 算术运算器 模块图: image.png图片 端口描述: 算术逻辑运算单元可以根据输入的操作码分别实现相应的加、与、异或、跳转等基本操作运算。 本单元支持8种操作运算。 opcode用来选择计算模式 data是数据输入 accum是累加器输出 alu_ena是模块使能信号 clk是系统时钟 Verilog代码: // Description: RISC-CPU 算术运算器 // ----------------------------------------------------------------------------- module alu ( input clk , // Clock input alu_ena , // Enable input [2:0] opcode , // High three bits are used as opcodes input [7:0] data , // data input [7:0] accum , // accum out output reg [7:0] alu_out , output zero ); parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always @(posedge clk) begin if(alu_ena) begin casex(opcode)//操作码来自指令寄存器的输出 opc_iaddr(15..0)的第三位 HLT: alu_out <= accum ; SKZ: alu_out <= accum ; ADD: alu_out <= data + accum ; ANDD: alu_out <= data & accum ; XORR: alu_out <= data ^ accum ; LDA : alu_out <= data ; STO : alu_out <= accum ; JMP : alu_out <= accum ; default: alu_out <= 8'bxxxx_xxxx ; endcase end end assign zero = !accum; endmodule 数据控制器 模块图: image.png图片 端口描述: 数据控制器的作用是控制累加器的数据输出,数据总线是分时复用的,会根据当前状态传输指令或者数据。 数据只在往RAM区或者端口写时才允许输出,否则呈现高阻态。 in是8bit数据输入 data_ena是使能信号 data是8bit数据输出 Verilog代码: // Description: RISC-CPU 数据控制器 // ----------------------------------------------------------------------------- module datactl ( input [7:0] in , // Data input input data_ena , // Data Enable output wire [7:0] data // Data output ); assign data = (data_ena )? in: 8'bzzzz_zzzz ; endmodule 地址多路器 模块图: image.png图片 端口描述: 用于选择输出地址是PC(程序计数)地址还是数据/端口地址。每个指令周期的前4个时钟周期用于从ROM种读取指令,输出的是PC地址;后四个时钟周期用于对RAM或端口读写。 地址多路器和数据控制器实现的功能十分相似。 fetch信号用来控制地址输出,高电平输出pc_addr ,低电平输出ir_addr ; pc_addr 指令地址; ir_addr ram或端口地址。 Verilog代码: // Description: RISC-CPU 地址多路器 // ----------------------------------------------------------------------------- module adr ( input fetch , // enable input [12:0] ir_addr , // input [12:0] pc_addr , // output wire [12:0] addr ); assign addr = fetch? pc_addr :ir_addr ; endmodule 程序计数器 模块图: image.png图片 端口描述: 程序计数器用来提供指令地址,指令按照地址顺序存放在存储器中。包含两种生成途径: (1)顺序执行的情况 (2)需要改变顺序,例如JMP指令 rst复位信号,高电平时地址清零; clock 时钟信号,系统时钟; ir_addr目标地址,当加载信号有效时输出此地址; pc_addr程序计数器地址 load地址装载信号 Verilog代码: // Description: RISC-CPU 程序计数器 // ----------------------------------------------------------------------------- module counter ( input [12:0] ir_addr , // program address input load , // Load up signal input clock , // CLock input rst , // Reset output reg [12:0] pc_addr // insert program address ); always@(posedge clock or posedge rst) begin if(rst) pc_addr <= 13'b0_0000_0000_0000; else if(load) pc_addr <= ir_addr; else pc_addr <= pc_addr + 1; end endmodule 状态控制器&主状态机 模块图: image.png图片 (图左边)状态机端口描述: 状态控制器接收复位信号rst,rst有效,控制输出ena为0,fetch有效控制ena为1。 // Description: RISC-CPU 状态控制器 // ----------------------------------------------------------------------------- module machinectl ( input clk , // Clock input rst , // Asynchronous reset input fetch , // Asynchronous reset active low output reg ena // Enable ); always@(posedge clk)begin if(rst) ena <= 0; else if(fetch) ena <=1; end endmodule (图右边)主状态端口描述: 主状态机是CPU的控制核心,用于产生一系列控制信号。 指令周期由8个时钟周期组成,每个时钟周期都要完成固定的操作。 (1)第0个时钟,CPU状态控制器的输出rd和load_ir 为高电平,其余为低电平。指令寄存器寄存由ROM送来的高8位指令代码。 (2)第1个时钟,与上一个时钟相比只是inc_pc从0变为1,故PC增1,ROM送来低8位指令代码,指令寄存器寄存该8位指令代码。 (3)第2个时钟,空操作。 (4)第3个时钟,PC增1,指向下一条指令。 操作符为HLT,输出信号HLT为高。 操作符不为HLT,除PC增1外,其余控制线输出为0. (5)第4个时钟,操作。 操作符为AND,ADD,XOR或LDA,读取相应地址的数据; 操作符为JMP,将目的地址送给程序计数器; 操作符为STO,输出累加器数据。 (6)第5个时钟,若操作符为ANDD,ADD或者XORR,算术运算器完成相应的计算; 操作符为LDA,就把数据通过算术运算器送给累加器; 操作符为SKZ,先判断累加器的值是否为0,若为0,PC加1,否则保持原值; 操作符为JMP,锁存目的地址; 操作符为STO,将数据写入地址处。 (7)第6个时钟,空操作。 (8)第7个时钟,若操作符为SKZ且累加器为0,则PC值再加1,跳过一条指令,否则PC无变化。 // Description: RISC-CPU 主状态机 // ----------------------------------------------------------------------------- module machine ( input clk , // Clock input ena , // Clock Enable input zero , // Asynchronous reset active low input [2:0] opcode , // OP code output reg inc_pc , // output reg load_acc , // output reg load_pc , // output reg rd , // output reg wr , // output reg load_ir , // output reg datactl_ena , // output reg halt ); reg [2:0] state ; //parameter parameter HLT = 3'b000 , SKZ = 3'b001 , ADD = 3'b010 , ANDD = 3'b011 , XORR = 3'b100 , LDA = 3'b101 , STO = 3'b110 , JMP = 3'b111 ; always@(negedge clk) begin if(!ena) //收到复位信号rst,进行复位操作 begin state <= 3'b000; {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else ctl_cycle; end //------- task ctl_cycle ------- task ctl_cycle; begin casex(state) 3'b000: //load high 8bits in struction begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b001; end 3'b001://pc increased by one then load low 8bits instruction begin {inc_pc,load_acc,load_pc,rd} <= 4'b1001; {wr,load_ir,datactl_ena,halt} <= 4'b0100; state <= 3'b010; end 3'b010: //idle begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b011; end 3'b011: //next instruction address setup 分析指令开始点 begin if(opcode == HLT)//指令为暂停HLT begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0001; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b100; end 3'b100: //fetch oprand begin if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b101; end 3'b101://operation begin if(opcode == ADD || opcode == ANDD ||opcode ==XORR ||opcode == LDA)//过一个时钟后与累加器的内存进行运算 begin {inc_pc,load_acc,load_pc,rd} <= 4'b0101; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == SKZ && zero == 1)// & and && begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == JMP) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1010; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else if(opcode == STO) begin//过一个时钟后吧wr变为1,写到RAM中 {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b1010; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b110; end 3'b110: begin if(opcode == STO) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0010; end else if(opcode == ADD || opcode == ANDD || opcode == XORR || opcode == LDA) begin {inc_pc,load_acc,load_pc,rd} <= 4'b0001; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b111; end 3'b111: begin if(opcode == SKZ && zero == 1) begin {inc_pc,load_acc,load_pc,rd} <= 4'b1000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end else begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; end state <= 3'b000; end default: begin {inc_pc,load_acc,load_pc,rd} <= 4'b0000; {wr,load_ir,datactl_ena,halt} <= 4'b0000; state <= 3'b000; end endcase end endtask endmodule 外围模块 为了对RISC-CPU进行测试,需要对ROM、RAM和地址译码器进行设计。 地址译码器 模块说明: 地址译码器用于产生选通信号,选通ROM或者RAM 1FFFH —— 1800H RAM(范围):1_1xxx_xxxx_xxxx 17FFH —— 0000H ROM(范围):0_xxxx_xxxx_xxxx+1_0xxx_xxxx_xxxx Verilog代码: // Description: RISC-CPU 地址译码器 // ----------------------------------------------------------------------------- module addr_decode ( input [12:0] addr , // Address output reg ram_sel , // Ram sel output reg rom_sel // Rom sel ); always@(addr)begin casex(addr) 13'b1_1xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b01; 13'b0_xxxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; 13'b1_0xxx_xxxx_xxxx:{rom_sel,ram_sel} <= 2'b10; default: {rom_sel,ram_sel} <= 2'b00; endcase end endmodule RAM 模块说明: RAM用于存放临时数据,可读可写。 Verilog代码: // Description: RISC-CPU RAM模块 // ----------------------------------------------------------------------------- module ram ( input ena , // Enable input read , // read Enable input write , // write Enable inout wire [7:0] data , // data input [9:0] addr // address ); reg [7:0] ram [10'h3ff:0] ; assign data = (read && ena )? ram[addr]:8'h zz; always@(posedge write) begin ram[addr] <= data; end endmodule ROM 模块说明: RAM用于存放只读数据。 Verilog代码: // Description: RISC-CPU ROM模块 // ----------------------------------------------------------------------------- module rom ( input [12:0] addr , input read , input ena , output wire [7:0] data ); reg [7:0] memory [13'h1ff:0]; assign data = (read && ena)? memory[addr]:8'b zzzz_zzzz; endmodule 顶层模块 模块图: 图片 图片 Verilog代码: // Description: RISC-CPU 顶层模块 // ----------------------------------------------------------------------------- //`include "clk_gen.v" //`include "accum.v" //`include "adr.v" //`include "alu.v" //`include "machine.v" //`include "counter.v" //`include "machinectl.v" //`iclude "machine.v" //`include "register.v" //`include "datactl.v" module RISC_CPU ( input clk , input reset , output wire rd , output wire wr , output wire halt , output wire fetch , //addr output wire [12:0] addr , output wire [12:0] ir_addr , output wire [12:0] pc_addr , inout wire [7:0] data , //op output wire [2:0] opcode ); wire [7:0] alu_out ; wire [7:0] accum ; wire zero ; wire inc_pc ; wire load_acc ; wire load_pc ; wire load_ir ; wire data_ena ; wire contr_ena ; wire alu_ena ; //inst clk_gen mclk_gen( .clk (clk ), .reset (reset ), .fetch (fetch ), .alu_ena (alu_ena ) ); register m_register( .data (data ), .ena (load_ir ), .rst (reset ), .clk (clk ), .opc_iraddr ({opcode,ir_addr} ) ); accum m_accum( .data (alu_out ), .ena (load_acc ), .clk (clk ), .rst (reset ), .accum (accum ) ); alu m_alu( .data (data ), .accum (accum ), .clk (clk ), .alu_ena (alu_ena ), .opcode (opcode ), .alu_out (alu_out ), .zero (zero ) ); machinectl m_machinectl( .clk (clk ), .rst (reset ), .fetch (fetch ), .ena (contr_ena ) ); machine m_machine( .inc_pc (inc_pc ), .load_acc (load_acc ), .load_pc (load_pc ), .rd (rd ), .wr (wr ), .load_ir (load_ir ), .clk (clk ), .datactl_ena(data_ena ), .halt (halt ), .zero (zero ), .ena (contr_ena ), .opcode (opcode ) ); datactl m_datactl( .in (alu_out ), .data_ena (data_ena ), .data (data ) ); adr m_adr( .fetch (fetch ), .ir_addr (ir_addr ), .pc_addr (pc_addr ), .addr (addr ) ); counter m_counter( .clock (inc_pc ), .rst (reset ), .ir_addr (ir_addr ), .load (load_pc ), .pc_addr (pc_addr ) ); endmodule Testbench Testbench包含三个测试程序,这个部分不能综合。 Test1程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 若各条指令正确,应该在地址2E(hex)处,在执行HLT时刻停止。若程序在任何其他位置停止,则必有一条指令运行错误,可以按照注释找到错误的指令。 test1汇编程序:(.pro文件/存放于ROM) //机器码-地址-汇编助记符-注释 @00 //address statement 111_0000 //00 BEGIN: JMP TST_JMP 0011_1100 000_0000 //02 HLT //JMP did not work 0000_0000 000_00000 //04 HLT //JMP did not load PC skiped 0000_0000 101_1100 //06 JMP_OK: LDA DATA 0000_0000 001_00000 //08 SKZ 0000_0000 000_0000 //0a HLT 0000_0000 101_11000 //0C LDA DATA_2 0000_0001 001_00000 //0E SKZ 0000_0000 111_0000 //10 JMP SKZ_OK 001_0100 000_0000 //12 HLT 0000_0000 110_11000 //14 SKZ_OK: STO TEMP 0000_0010 101_11000 //16 LDA DATA_1 0000_0000 110_11000 //18 STO TEMP 0000_0010 101_11000 //1A LDA TEMP 0000_0010 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 100_11000 //20 XOR DATA_2 0000_0001 001_00000 //22 SKZ 0000_0000 111_00000 //24 JMP XOR_OK 0010_1000 000_00000 //26 HLT 0000_0000 100_11000 //28 XOR_OK XOR DATA_2 0000_0001 001_00000 //2A SKZ 0000_0000 000_00000 //2C HLT 0000_0000 000_0000 //2E END 0000_0000 111_00000 //30 JMP BEGIN 0000_0000 @3c 111_00000 //3c TST_JMP IMR OK 0000_0110 000_00000 //3E HLT test1数据文件:(.dat/存放于RAM) /----------------------------------- @00 ///address statement at RAM 00000000 //1800 DATA_1 11111111 //1801 DATA_2 10101010 //1082 TEMPTest2程序 TEST1程序用于验证RISC-CPU的逻辑功能,根据汇编语言由人工编译的。 这个程序是用来测试RISC-CPU的高级指令集,若执行正确,应在地址20(hex)处在执行HLT时停止。 test2汇编程序: @00 101_11000 //00 BEGIN 0000_0001 011_11000 //02 AND DATA_3 0000_0010 100_11000 //04 XOR DATA_2 0000_0001 001_00000 //06 SKZ 0000_0000 000_00000 //08 HLT 0000_0000 010_11000 //0A ADD DATA_1 0000_0000 001_00000 //0C SKZ 0000_0000 111_00000 //0E JMP ADD_OK 0001_0010 111_00000 //10 HLT 0000_0000 100_11000 //12 ADD_OK XOR DATA_3 0000_0010 010_11000 //14 ADD DATA_1 0000_0000 110_11000 //16 STO TEMP 0000_0011 101_11000 //18 LDA DATA_1 0000_0000 010_11000 //1A ADD TEMP 0000_0001 001_00000 //1C SKZ 0000_0000 000_00000 //1E HLT 0000_0000 000_00000 //END HLT 0000_0000 111_00000 //JMP BEGIN 0000_0000test2数据文件: @00 00000001 //1800 DATA_1 10101010 //1801 DATA_2 11111111 //1802 DATA_3 00000000 //1803 TEMPTest3程序 TEST3程序是一个计算0~144的斐波那契数列的程序,用来验证CPU整体功能。 test3汇编程序: @00 101_11000 //00 LOOP:LDA FN2 0000_0001 110_11000 //02 STO TEMP 0000_0010 010_11000 //04 ADD FN1 0000_0000 110_11000 //06 STO FN2 0000_0001 101_11000 //08 VLDA TEMP 0000_0010 110_11000 //0A STO FN1 0000_0000 100_11000 //0C XOR LIMIT 0000_0011 001_00000 //0E SKZ 0000_0000 111_00000 //10 JMP LOOP 0000_0000 000_00000 //12 DONE HLT 0000_0000test3数据文件: @00 00000001 //1800 FN1 00000000 //1801 FN2 00000000 //1802 TEMP 10010000 //1803 LIMIT完整的testbench Verilog代码: // Description: RISC-CPU 测试程序 // ----------------------------------------------------------------------------- `include "RISC_CPU.v" `include "ram.v" `include "rom.v" `include "addr_decode.v" `timescale 1ns/1ns `define PERIOD 100 // matches clk_gen.v module cputop_tb; reg [( 3 * 8 ): 0 ] mnemonic; // array that holds 3 8 bits ASCII characters reg [ 12 : 0 ] PC_addr, IR_addr; reg reset_req, clock; wire [ 12 : 0 ] ir_addr, pc_addr; // for post simulation. wire [ 12 : 0 ] addr; wire [ 7 : 0 ] data; wire [ 2 : 0 ] opcode; // for post simulation. wire fetch; // for post simulation. wire rd, wr, halt, ram_sel, rom_sel; integer test; //-----------------DIGITAL LOGIC---------------------- RISC_CPU t_cpu (.clk( clock ),.reset( reset_req ),.halt( halt ),.rd( rd ),.wr( wr ),.addr( addr ),.data( data ),.opcode( opcode ),.fetch( fetch ),.ir_addr( ir_addr ),.pc_addr( pc_addr )); ram t_ram (.addr ( addr [ 9 : 0 ]),.read ( rd ),.write ( wr ),.ena ( ram_sel ),.data ( data )); rom t_rom (.addr ( addr ),.read ( rd ), .ena ( rom_sel ),.data ( data )); addr_decode t_addr_decoder (.addr( addr ),.ram_sel( ram_sel ),.rom_sel( rom_sel )); //-------------------SIMULATION------------------------- initial begin clock = 0; // display time in nanoseconds $timeformat ( -9, 1, "ns", 12 ); display_debug_message; sys_reset; test1; $stop; test2; $stop; test3; $finish; // simulation is finished here. end // initial task display_debug_message; begin $display ("\n************************************************" ); $display ( "* THE FOLLOWING DEBUG TASK ARE AVAILABLE: *" ); $display ( "* \"test1;\" to load the 1st diagnostic program. *"); $display ( "* \"test2;\" to load the 2nd diagnostic program. *"); $display ( "* \"test3;\" to load the Fibonacci program. *"); $display ( "************************************************\n"); end endtask // display_debug_message task test1; begin test = 0; disable MONITOR; $readmemb ("test1.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test1.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 1; #14800; sys_reset; end endtask // test1 task test2; begin test = 0; disable MONITOR; $readmemb ("test2.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test2.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 2; #11600; sys_reset; end endtask // test2 task test3; begin test = 0; disable MONITOR; $readmemb ("test3.pro", t_rom.memory ); $display ("rom loaded successfully!"); $readmemb ("test3.dat", t_ram.ram ); $display ("ram loaded successfully!"); #1 test = 3; #94000; sys_reset; end endtask // test1 task sys_reset; begin reset_req = 0; #( `PERIOD * 0.7 ) reset_req = 1; #( 1.5 * `PERIOD ) reset_req = 0; end endtask // sys_reset //--------------------------MONITOR-------------------------------- always@( test ) begin: MONITOR case( test ) 1: begin // display results when running test 1 $display("\n*** RUNNING CPU test 1 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 1 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 1 @ t_cpu.pc_addr end 2: begin // display results when running test 2 $display("\n*** RUNNING CPU test 2 - The Basic CPU Diagnostic Program ***"); $display("\n TIME PC INSTR ADDR DATA "); $display(" ------ ---- ------- ------ ------ "); while( test == 2 )@( t_cpu.pc_addr ) begin // fixed if(( t_cpu.pc_addr % 2 == 1 )&&( t_cpu.fetch == 1 )) begin // fixed #60 PC_addr <= t_cpu.pc_addr - 1; IR_addr <= t_cpu.ir_addr; #340 $strobe("%t %h %s %h %h", $time, PC_addr, mnemonic, IR_addr, data ); // Here data has been changed t_cpu.m_register.data end // if t_cpu.pc_addr % 2 == 1 && t_cpu.fetch == 1 end // while test == 2 @ t_cpu.pc_addr end 3: begin // display results when running test 3 $display("\n*** RUNNING CPU test 3 - An Executable Program **************"); $display("***** This program should calculate the fibonacci *************"); $display("\n TIME FIBONACCI NUMBER "); $display(" ------ -----------------_ "); while( test == 3 ) begin wait( t_cpu.opcode == 3'h 1 ) // display Fib. No. at end of program loop $strobe("%t %d", $time, t_ram.ram [ 10'h 2 ]); wait( t_cpu.opcode != 3'h 1 ); end // while test == 3 end endcase // test end // MONITOR: always@ test //-------------------------HALT------------------------------- always@( posedge halt ) begin // STOP when HALT intruction decoded #500 $display("\n******************************************"); $display( "** A HALT INSTRUCTION WAS PROCESSED !!! **"); $display( "******************************************"); end // always@ posedge halt //-----------------------CLOCK & MNEMONIC------------------------- always#(`PERIOD / 2 ) clock = ~ clock; always@( t_cpu.opcode ) begin // get an ASCII mnemonic for each opcode case( t_cpu.opcode ) 3'b 000 : mnemonic = "HLT"; 3'b 001 : mnemonic = "SKZ"; 3'b 010 : mnemonic = "ADD"; 3'b 011 : mnemonic = "AND"; 3'b 100 : mnemonic = "XOR"; 3'b 101 : mnemonic = "LDA"; 3'b 110 : mnemonic = "STO"; 3'b 111 : mnemonic = "JMP"; default : mnemonic = "???"; endcase end endmodule $ readmemb ( "test1. pro" ,t_ rom. . memory ); $ readmemb ( "testl. dat",t_ ram_ . ram); 即可把编译好的汇编机器码装人虚拟ROM,把需要参加运算的数据装人虚拟RAM就可以开始仿真。上面语句中的第一项为打开的文件名,后一项为系统层次管理下的ROM模块和RAM模块中的存储器memory和ram。源代码&脚本 隐藏内容,请前往内页查看详情 前仿真结果 test1 图片 test2 图片 test3 图片 图片 DC后仿真 采用SMIC180工艺在典型环境下进行测试 时序报告: 图片 面积报告: 图片 功耗报告: 图片 综合电路图: 图片 图片 图片 总结 该项目更加偏向于教学练习,CPU也是数字IC的重要研究方向,对此感兴趣的同学可以找点论文和开源资料进行学习。可以进一步优化如流水线、运算单元,扩展成SOC系统等。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# SOC设计
刘航宇
3年前
15
2,120
6
上一页
1
...
3
4
5
...
26
下一页