首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,161 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,123 阅读
3
【高数】形心计算公式讲解大全
8,748 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,444 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,804 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
刘航宇(共304篇)
找到
304
篇与
刘航宇
相关的结果
- 第 7 页
2023-02-23
VLSI设计基础1-数字IC引论:度量指标及版图基础
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 引论1. 数字设计中需解决的问题 2. 集成电路质量评价-重点 3. 数字IC基本概念-重点 4. IC全定制流程 版图基础1. CMOS版图 2. 设计规则检查 3.棍棒图 引论 1. 数字设计中需解决的问题 摩尔定律:技术突破才能推动摩尔定律 特征尺寸:28nm是传统制程和先进制程的分界点 存储器容量:存储器的容量增大,意味着功耗增大,意味着稳定性下降(发热)。如果想要实现更大容量的突破,需要寻找新技术或者新架构使功耗不能超过功耗红线 晶圆尺寸:晶圆尺寸增加,单位硅片数量增加,所需的技术越先进,最终成品芯片价格也越低 技术突破:大直径的硅片可以大大提高成品率 2. 集成电路质量评价-重点 图片 注: ① 是取决于制造工艺复杂行参数,常取值3 ②单位面积缺陷数常取值0.5~1个缺陷/cm² ③芯片成本 $=f(\text { 芯片面积 })^4$ 稳定性与功能性 噪声:电容耦合、电感耦合、地线耦合 ※※※【重点】性能——延时tp、工作频率性能常与时钟周期、时钟频率相关 重点:延时 图片 1、传播延时:输入和输入波形的50%翻转点之间的时间 如图: 定义传播时间tp为 $t_p=\frac{t_{p L H}+t_{p H L}}{2}$ 一般而言, ①TpLH和TpHL不会完全相等 ②如果要求传输延时<t,则意味着TpLH<t并且TpHL<t 图片 图片 2、上升时间tr 3、下降时间tf 功耗和能耗 取决的因素太多了。 常常有:瞬时功耗、峰值功耗(研究电源线尺寸)、平均功耗(研究冷却或者对电池的要求) 3. 数字IC基本概念-重点 电压传输特性VTC(DC传输曲线) 可接受的高电压、低电压区域:VIH和VIL定义为VTC增益=-1的点 噪声容限=min{NMH.NML} NMH=|VOH-VIH| NML=|VIL-VOL| 再生性 保证一个受干扰的信号经过若干个组合逻辑之后依旧回到一个额定电平(高或者低,不是不确定态) 抗干扰能力 方向性 6.扇入和扇出 扇入和扇出个数和一些延迟有关 4. IC全定制流程 图片 版图基础 1. CMOS版图 1、图编辑工具:virtuoso、max 2、工艺层的概念:将cmos使用中难以理解的掩膜转化为一组简单概念化的版图层 3、可伸缩的设计:将版图所有参数定义与$\lambda$,利用EDA工具使之在想要兼容的工艺间转换。如0.25转为0.18。早期的工艺中,这个缩放比例可以达到75%左右,随着如今器件尺寸的减小,该比例只有90%左右了。 不足:①由于不同工艺之间的非线性,线性缩放仅在有限尺寸范围内;②可缩放规则是保守的,结果会使得标准单元尺寸过大或者过小。 4、晶体管的尺寸由W/L指定。 给定一个工艺,最小线宽为2$\lambda$; 图片 5、在版图中,只要多晶硅穿过扩散区,就形成一个晶体管 随着工艺的发展,电源电压VDD呈现下降趋势。 2. 设计规则检查 设计规则检查工具:Calibre DRC 设定规则的目的:可以很容易的把电路的概念转换为硅上的几何关系。 Calibre的规则相当于是行业的标准了。 其规则是基于边(edge)的DRC/LVE工具,所有的计算都是基于边来计算的,其中”边“分为”内边“和”外边“ 常见的三个指令: internal:检查多边形的内边距 external:检查多边形的外边距 enclosure:检查多边形的交迭 3.棍棒图 1、要求:①将棍棒图转为管级电路图、并且写出输出表达式;②将管级电路图转化为棍棒图 2、特点: 仅用象征性的符号表示电路的拓扑结构 不需要标尺寸大小 棍棒图中棍棒的位置很重要 3、棍棒图中的串并联 以下为版图的: 串联: 图片 并联: 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
699
2
RAM与ROM及Verilog实现
概念 RAM(random access memory)即随机存储内存,这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序。 ROM 指的是“只读存储器”,即Read-Only Memory。只读存储器(Read-Only Memory,ROM)以非破坏性读出方式工作,只能读出无法写入信息。信息一旦写入后就固定下来,即使切断电源,信息也不会丢失,所以又称为固定存储器。ROM所存数据通常是装入整机前写入的,整机工作过程中只能读出,不像随机存储器能快速方便地改写存储内容。ROM所存数据稳定 ,断电后所存数据也不会改变,并且结构较简单,使用方便,因而常用于存储各种固定程序和数据。 PROM 指的是“可编程只读存储器”既Programmable Red-Only Memory。这样的产品只允许写入一次,所以也被称为“一次可编程只读存储器”(One Time Progarmming ROM,OTP-ROM)。最初从工厂中制作完成的PROM内部并没有资料,用户可以用专用的编程器将自己的资料写入,但是这种机会只有一次,一旦写入后也无法修改。 EPROM 指的是“可擦写可编程只读存储器”,即Erasable Programmable Read-Only Memory。它的特点是具有可擦除功能,擦除后即可进行再编程,但是缺点是擦除需要使用紫外线照射一定的时间。 EEPROM 指的是“电可擦除可编程只读存储器”,即Electrically Erasable Programmable Read-Only Memory。它的最大优点是可直接用电信号擦除,也可用电信号写入。EEPROM不能取代RAM的原因是其工艺复杂, 耗费的门电路过多,且重编程时间比较长,同时其有效重编程次数也比较低。 Flash memory 指的是“闪存”,所谓“闪存”,它也是一种非易失性的内存,属于EEPROM的改进产品。它的最大特点是必须按块(Block)擦除(每个区块的大小不定,不同厂家的产品有不同的规格), 而EEPROM则可以一次只擦除一个字节(Byte)。目前“闪存”被广泛用在PC机的主板上,用来保存BIOS程序,便于进行程序的升级。其另外一大应用领域是用来作为硬盘的替代品,具有抗震、速度快、无噪声、耗电低的优点,但是将其用来取代RAM就显得不合适,因为RAM需要能够按字节改写,而Flash ROM做不到。 二、编程 1.要求: 编程实现512x8的ROM和RAM。 ROM、RAM至少应该包含的端口包括地址线、数据线、片选线、读写使能端,复位端和时钟端(其中部分信号线只适用于RAM)。 ROM、RAM和总测试模块分别包含在不同的.v文件中。 端口意义: Data: 双向数据总线,用于读写数据。它的宽度由width参数决定。 Addr: 输入地址总线,用于指定要访问的内存单元。它的宽度也由width参数决定,默认为8位。 CS: 输入芯片选择信号,用于使能或禁止模块的读写操作。当CS为1时,模块可以进行读写操作;当CS为0时,模块不响应任何操作。 RWEnable: 输入读写使能信号,用于指定模块的工作模式。当RWEnable为1时,模块处于写模式,可以将Data总线上的数据写入到Addr指定的内存单元中;当RWEnable为0时,模块处于读模式,可以将Addr指定的内存单元中的数据输出到Data总线上。 2.设计思路: 512x8的ROM和RAM,至少需要9位地址线和8位数据位。 3.RAM实现代码 //模块声明,指定模块名和端口引脚 module RAM (Data,Addr,CS,RWEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RWEnable,Reset,Clk; //输入信号,分别为芯片选择、读写使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 inout[width-1:0] Data; //双向数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_temp; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为0 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= 0; //将每个内存单元赋值为0 end //写操作条件,当RWEnable为1且CS为1时,将Data总线上的数据写入到Addr指定的内存单元中 else if((RWEnable==1'b1)&&(CS==1'b1)) begin Mem[Addr] <= Data; //将Data总线上的数据赋值给Mem[Addr] end //读操作条件,当RWEnable为0且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_temp中 else if((RWEnable==1'b0)&&(CS==1'b1)) begin Data_temp<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_temp end //其他条件,当CS为0或RWEnable为不确定值时,将Data_temp置为高阻抗状态 else begin Data_temp <= 8'bz; //将Data_temp赋值为高阻抗状态 end end //assign语句,指定Data总线与Data_temp之间的连接关系 assign Data=RWEnable?8'bz:Data_temp; //当RWEnable为1时,Data总线处于高阻抗状态;当RWEnable为0时,Data总线接收Data_temp中的数据 endmodule //模块结束测试代码如下: //模块声明,指定模块名为RAM_TS module RAM_TS; //信号和寄存器的定义,指定与RAM模块相连的端口引脚和内部变量 reg CS_t,RWEnable_t,Reset_t,Clk_t; //芯片选择、读写使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 reg [7:0] Data_temp_t; //用于暂存写入数据的寄存器,也是8位的 //initial块,指定测试RAM模块的过程,只会在仿真开始时执行一次 initial begin RWEnable_t = 1;//w //初始化读写使能信号为1,表示写模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 Data_temp_t = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 Data_temp_t=Addr_t; //将地址总线上的值赋给暂存数据,表示要写入的数据与地址相同 end #70 //延迟70个时间单位后 RWEnable_t = 0;//r //将读写使能信号置为0,表示读模式 Addr_t=0; //将地址总线置为0,表示从第一个内存单元开始读取数据 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //assign语句,指定数据总线与暂存数据之间的连接关系 assign Data_t=RWEnable_t?Data_temp_t:8'bz; always #5 Clk_t=~Clk_t; //实例化一个RAM模块,并且用定义好的信号和寄存器与之相连 RAM myRAM( .Data(Data_t), //将数据总线与RAM模块的Data端口相连 .Addr(Addr_t), //将地址总线与RAM模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与RAM模块的CS端口相连 .RWEnable(RWEnable_t), //将读写使能信号与RAM模块的RWEnable端口相连 .Reset(Reset_t), //将复位信号与RAM模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与RAM模块的Clk端口相连 ); endmodule //模块结束4.RAM仿真测试: ① 数据写入操作 image.png图片 ② 数据读取操作 image.png图片 5.ROM实现代码: RDEnable: 当RDEnable为1时,模块处于读模式,将Addr指定的内存单元中的数据输出到Data总线,当RDEnable为0时,模块处于空闲模式,不对Data驱动。 ROM代码如下: //模块声明,指定模块名和端口引脚 module ROM(Data,Addr,CS,RDEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RDEnable,Reset,Clk; //输入信号,分别为芯片选择、读使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 output [width-1:0] Data; //输出数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_read; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为其地址值 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= i; //将每个内存单元赋值为其地址值 end //读操作条件,当RDEnable为1且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_read中 else if((RDEnable==1'b1)&&(CS==1'b1)) begin Data_read<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_read end //其他条件,当CS为0或RDEnable为不确定值时,将Data_read置为高阻抗状态 else Data_read <= 8'bz; //将Data_read赋值为高阻抗状态 end //assign语句,指定Data总线与Data_read之间的连接关系 assign Data=Data_read; //当RDEnable为1时,Data总线输出Data_read中的数据;当RDEnable为0时,Data总线处于高阻抗状态 endmodule //模块结束测试代码如下: //模块声明,指定模块名为R0M98_TS module R0M_TS; //信号和寄存器的定义,指定与ROM98模块相连的端口引脚和内部变量 reg CS_t,RDEnable_t,Reset_t,Clk_t; //芯片选择、读使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 //initial块,指定测试ROM98模块的过程,只会在仿真开始时执行一次 initial begin RDEnable_t = 1;//r //初始化读使能信号为1,表示读模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 // Data_read_ts = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #10 //延迟10个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //always块,指定时钟信号的变化规律,每隔5个时间单位翻转一次 always #5 Clk_t=~Clk_t; //实例化一个ROM98模块,并且用定义好的信号和寄存器与之相连 ROM myROM( .Data(Data_t), //将数据总线与ROM98模块的Data端口相连 .Addr(Addr_t), //将地址总线与ROM98模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与ROM98模块的CS端口相连 .RDEnable(RDEnable_t), //将读使能信号与ROM98模块的RDEnable端口相连 .Reset(Reset_t), //将复位信号与ROM98模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与ROM98模块的Clk端口相连 ); endmodule //模块结束 6.ROM仿真测试: image.png图片
FPGA&ASIC
VLSI&IC验证
# 体系结构
刘航宇
3年前
0
1,111
2
2023-02-10
FPGA与数字IC设计中接口命名规范
在硬件编程中,接口命名规范也是一个良好的习惯。接口在确定模块划分后需要明确模块的端口以及模块间的数据交互。完成项目模块划分后,可以在确定端口及数据流向时参考使用。本节重点是EN与vld的区别! ` 端口信号规范 ` 信号说明clk模块工作时钟rst_n系统复位信号,低电平有效en门控时钟,请搜索本站关于门控时钟讲解,这是低功耗的设计,EN=0睡眠状态、阻断时钟输入vld数据有效标志指示信号,表示当前的 data 数据有效。注意,vld 不仅表示了数据有效,而且还表示了其有效次数。时钟收到多少个 vld=1,就表示有多少个数据有data数据总线。输入一般名称为 din,输出一般名称为 dout。类似的信号还有 addr,len 等err整个报文错误指示,在 eop=1 且 vld=1 有效时才有效sop报文起始指示信号,用于表示有效报文数据的第一个数据,当 vld=1 时此信号有效eop报文结束指示信号,用于表示有效报文数据的最后一个数据,当 vld=1 时此信号有效rdy模块准备好信号,用于模块之间控制数据发送速度。例如模块 A 发数据给模块 B,则rdy 信号由模块 B 产生,连到模块 A(该信号对于 B 是输出信号,对于 A 是输入信号);B 要确保 rdy 产生正确,当此信号为 1 时,B 一定能接收数据;A 要确保仅在 rdy=1 时才发送图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
478
2
2023-02-09
VCS、Verdi与Makefile使用简介
前期工作 1、.fsdb文件 在使用Makefile文件前,先在测试文件中加入这样一句。 initial begin $fsdbDumpfile("tb.fsdb");//这个是产生名为tb.fsdb的文件 $fsdbDumpvars; end需要注意:对于用于仿真的testbench,需要额外建立一个 initial 块,调用产生有关 fsdb 格式的波形文件: 首先调用 fsdbDumpfile 函数,产生一个叫 .fsdb 的波形文件 然后调用 fsdbDumpvars 函数,声明需要保存那些信号的波形,括号内不加任何参数,则默认全部保存。 2、 filelist.f文件 filelist.f里存放所有需要仿真的.v文件。 创建filelist.f的方法: find -name "*.v" >filelist.f 1. Makefile作用? 编写makefile文件本质上是帮组make如何一键编译,进行批处理,makefile文件包含的规则命令使我们不需要繁琐的操作,提高了开发效率。 Makefile可以根据指定的依赖规则和文件是否有修改来执行命令。常用来编译软件源代码,只需要重新编译修改过的文件,使得编译速度大大加快。 2. Makefile应用 利用Makefile 实现简单的前端设计流程,包括VCS编译,Verdi仿真,DC综合,后续流程待补充。 目录结构 图片 #use "make" for help help: @echo "make help" @echo "make com to compile" @echo "make sim to run simulation" @echo "make clean to delete temporary files" #need to midify design name design_name = div_top fsdb_name = $(design_name).fsdb # use command "make com" to run vsc and product fsdb file com: cd RTL && vcs \ -full64 \ -f flist.f \ -debug_all \ -l com.log \ +v2k \ -P ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/novas.tab ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/pli.a # cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) #simulation:product fsdb file and sim log sim: ./RTL/simv cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) # use verdi to observe the waveform verdi: cd RTL && verdi \ +v2k \ -f flist.f \ -ssf $(fsdb_name) & #use fsdb file # run dc for synthesize syn: cd dc_script && dc_shell -64bit -topographical -f top_syn.tcl | tee -i syn.log #delete all files except .v and makefile clean: #rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v" | grep -v "dc_script"` make -C RTL clean make -C dc_script clean/RTL目录下MakeFile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v"` dc_script目录下Makefile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "script" | grep -v ".*.tcl"` make com :调用vcs编译 make sim:调用vcs仿真 make verdi 波形,shifrt+l可刷新重新编译结果 make clean 删除所有子目录下的临时生成文件 详细命令 执行“make vcs” 编译仿真 执行“make verdi” 打开波形 verdi常用快捷键 ctrl+w: 添加信号到波形图 h: 在波形窗口显示详细的信号名(路径) File>save signal,命名*.rc,下次直接打开rc文件就行 c/t: 修改信号的颜色(t可以直接切换颜色) 在波形窗口显示状态机的名字: 在rtl窗口,tools>Extract internative FSM ,可选first stage(仅展开目前所指定的FSM state),all stage (展开所有的FSM state) 改变颜色填充波形: Tools>waveform>view options>waveformpane> paint waveform with specified color/pattern 在rtl窗口按x: 标注出信号的值 z: 缩小波形窗口 Z: 放大波形窗口 f: 全屏 l: 上一个视图 L: 重新加载设计波形或文件 n: 向前查找 N: 向后查找 ctrl+→: 向右移动半屏 ctrl+←: 向左移动半屏 双击信号波形: 跳转到rtl中信号位置,并高亮新号 b: 跳到波形图开头 e: 跳到波形图尾部 2.不使用Makefile直接执行 vcs -R -f flist.f -full64 -fsdb -l name.log verdi -f flist.f -ssf name.fsdb 图片
编程&脚本笔记
EDA&虚拟机
# EDA&虚拟机
# Makefile
刘航宇
3年前
0
1,505
2
IC设计技巧-流水线设计
流水线概述 如下图为工厂流水线,工厂流水线就是将一个工作(比如生产一个产品)分成多个细分工作,在生产流水线上由多个不同的人分步完成。这个待完成的产品在流水线上一级一级往下传递。 图片 比如完成一个产品,需要8道工序,每道工序需要10s,那么流水线启动后,不间断工作的话,第一个产品虽然要80s才完成,但是接下来每10s就能产出一个产品。使得速度大大提高。当然这也增加了人员等资源的付出。 对于电路的流水线设计思想与上述思想异曲同工,也是以付出增加资源消耗为代价,去提高电路运算速度。 流水线设计实例 这里以一个简单的8位无符号数全加器的设计为实例来进行讲解,实现 assign {c_out,data_out [7:0]} = a[7:0] + b[7:0] +c_in c_out 为进位位。如果有数字电路常识的人都知道,利用一块组合逻辑电路去做8位的加法,其速度肯定比做2位的加法慢。因此这里可以采用4级流水线设计,每一级只做两位的加法操作,当流水线一启动后,除第一个加法运算之外,后面每经过一个2位加法器的延时,就会得到一个结果。 整体结构如下,每一级通过in_valid,o_valid信号交互,分别代表每一级的输入输出有效信号。 图片 第一级:做最低两位与进位位的加法操作,并将运算结果和未做运算的高六位传给下一级。 图片 第二级:做2,3两位与上一级加法器的进位位的加法操作,并将本级运算结果和未做运算的高4位传给下一级。 图片 第三级:做4,5两位与进位位的加法操作,并将运算结果和未做运算的高2位传给下一级。 图片 第四级:做最高两位与上一级加法器输出的进位位的加法操作,并将结果组合输出。 图片 仿真结果如下 如图,当整体模块in_valid有效时,送进去的数据a=1,b=5,c_in=1;故经过四个周期后,o_valid信号拉高,同时获得运算结果data_out=7。(本设计的流水线每级延时为一个时钟周期)后续输出信号7、9、10显然是间隔2个周期延迟,而不是延迟4周期、8周期逐个输出 图片 总结 流水线就是通过将一个大的组合逻辑划分成分步运算的多个小组合逻辑来运算,从而达到提高速度的目的。 在设计流水线的时候,我们一般要尽量使得每级运算所需要的时间差不多,从而做到流水匹配,提高效率。因为流水线的速度由运算最慢的那一级电路决定。
FPGA&ASIC
VLSI&IC验证
# VLSI
# ASIC/FPGA
刘航宇
3年前
0
545
1
2023-02-08
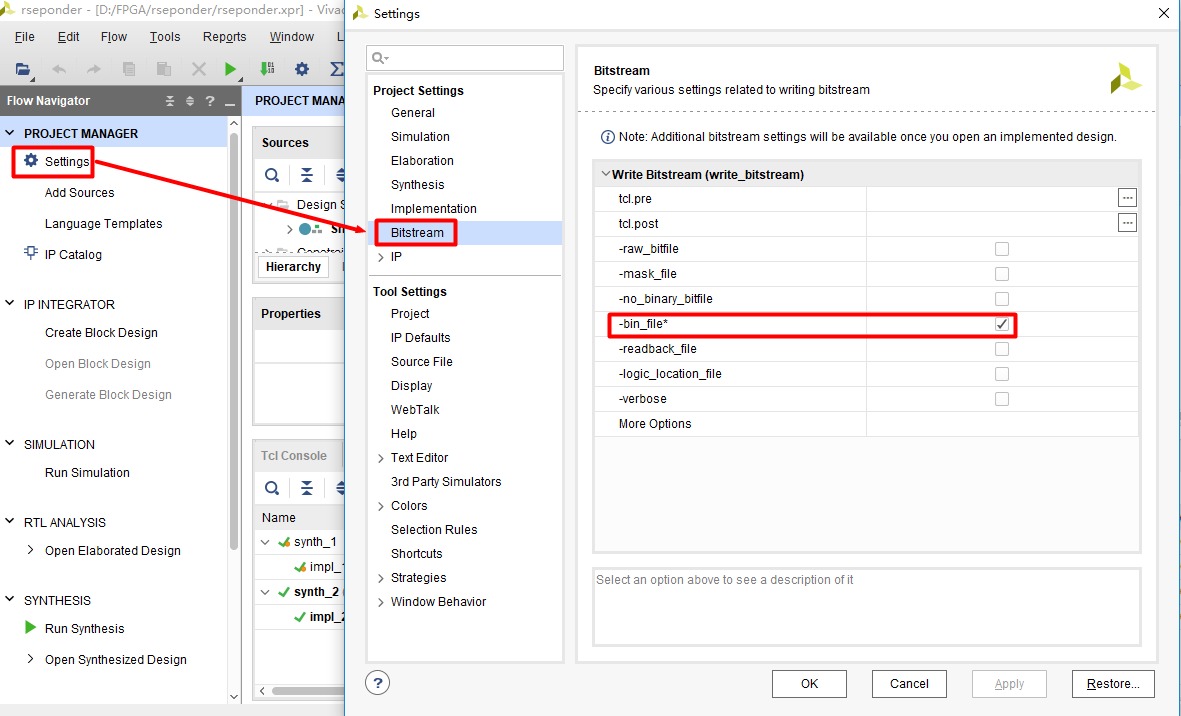
Vivado-FPGA Verilog烧写固化教程
Vivado里程序固化详细教程 编者注:初玩FPGA开发板,我们都会遇到这种情况,每次事先写好的程序编译成功后,下载到板子里,输出结果十分赏心悦目,随着掉电之后,程序也就随之消失,再次上电,又要重新编译下载程序,十分麻烦,不是我们想看到的结果。所以学会固化程序十分重要!下面就来说说如何固化程序。 目的简介:将FPGA的配置文件(固化用的配置文件是二进制文件,仅bin文件)烧写到板载Flash中,实现上电自启动,完成程序固化。 目录 Vivado里程序固化详细教程 法1:烧录bin文件 法二烧mcs文件 法1:烧录bin文件 过程步骤: 1)在Vivado软件里找到Settings设置选项,进入,点击Bitstream选项,将 bin_file 勾上,点击 OK 图片 2)点击 generate bitstream (可以分步进行,Run Synthesis—Run implementation— genereate bitstream),生成 bit 文件和 bin 文件。 图片 3)点击 open hardware manager,连接板子 图片 4)在Hardware面板中右击FPGA器件(xc7a35t_0),选择Add Configuration Memery Device。 图片 5)在弹出的添加配置存储器的界面中,找到板载的Flash存储器型号,点击OK,完成添加。这里开发板flash型号是( n25q64 )选择3.3v。 图片 6)添加完成后,Vivado会提示添加完成,是否立即配置存储器。点击OK,进入配置存储器的界面,开始将二进制bin文件烧写到外部配置flash存储器中。 图片 提醒:如果配置存储器的界面突然找不到,可以右击flash存储器,点击Program Configuration Memory Device,会出现存储器的配置界面。 图片 7)找到二进制bin文件,选中,进行代码烧写, 实现上电自启动,完成程序固化。 图片 选择好烧写的二进制文件,选中后点击 OK,将代码烧录到 flash,。其他设置可以保持默认 提醒:二进制文件路径为:project_name\project_name.runs\impl_1\xxx.bin。 或project_name \project_name.runs\impl_2\xxx.bin。 (project_name根据用户工程进行修改)。点击OK,烧写二进制文件。 由于需要擦除存储器原有数据,校验,以及烧写等几步,所以配置时间可能会稍微久一点。完成后,点击OK。 这样FPGA硬件程序就固化到外部配置存储器中了,下次上电就可以通过QSPI自启动。需要注意的是板载的配置跳线帽需要设置到QSPI模式。 法二烧mcs文件 第一步:先综合,然后打开综合设计 图片 第二步:点击Tools—Edit Device Properties(注意,必须按照第一步打开综合后的设计,才能找到这个选项),然后配置相应参数。 图片 可以选择压缩bit流,这样后面固化时会快一些。 图片 选择合适的固化速率,可以适当设置高一些(默认是3MHZ),因为固化本身比较慢;设置SPI 的bus width,因为flash使用的是QSPI,也即SPI4x(后面还会设置此参数),所以这里要设置为4 图片 选择编程模式,因为我们是将程序固化到flash中,以后上电自动从flash读取程序,所以这里要勾选上。JTAG是一直且默认勾选的。 图片 点击OK进行下一步。 第三步:生成bit流 第四步:生成.mcs内存配置文件 图片 图片 点击OK,即可在指定的路径下生成所需的.mcs文件 第五步:打开硬件管理器,连接开发板。 图片 第六步:往flash下载.mcs文件 图片 图片 点击OK,然后出现下面的界面,等待下载完成即可。 图片 第七步:断电重启 注意: 一定要注意将自己开发板上设置编程模式的跳线帽跳到QSPI模式。还有就是固化完成后,不会立即运行程序,需要断电重启,此时开发板会自动从flash读取程序并运行。这样以后每次上电都会自动加载并运行这段程序,除非再次固化别的程序!!!
FPGA&ASIC
EDA&虚拟机
刘航宇
3年前
0
6,804
6
TCL脚本语言用法简介
前言(TCL综述) TCL(Tool Command Language)是一种解释执行的脚本语言(Scripting Language)。 它提供了 通用的编程能力:支持变量、过程和控制结构;同时 TCL还拥有一个功能强大的固有的核心命令集。 由于TCL的解释器是用一个C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作一个C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,可以很容易就在C\C++应用程序中嵌入TCL,而且每个应用程序都可以根据自己的需要对TCL语言进行扩展。我们可以针对某一特定应用领域对TCL语言的核心命令集进行扩展,加入适合于自己的应用领域的扩展命令,如果需要,甚至可以加入新的控制结构,TCL解释器将把扩展命令和扩展控制结构与固有命令和固有控制结构同等看待。扩展后的TCL语言将可以继承TCL 核心部分的所有功能,包括核心命令、控制结构、数据类型、对过程的支持等。根据需要,我们甚至可以屏蔽掉TCL的某些固有命令和固有控制结构。通过对TCL的扩展、继承或屏蔽,用户用不着象平时定义一种计算机语言那样对词法、语法、语义、语用等各方面加以定义,就可以方便的为自己的应用领域提供一种功能完备的脚本语言。 TCL良好的可扩展性使得它能很好地适应产品测试的需要,测试任务常常会由于设计和需求的改变而迅速改变,往往让测试人员疲于应付。利用TCL的可扩展性,测试人员就可以迅速继承多种新技术,并针对产品新特点迅速推出扩展TCL命令集,以用于产品的测试中,可以较容易跟上设计需求的变化。 另外,因为TCL是一种比C\C++ 语言有着更高抽象层次的语言,使用TCL可以在一种更高的层次上编写程序,它屏蔽掉了编写C\C++程序时必须涉及到的一些较为烦琐的细节,可以大大地提高开发测试例的速度。而且, 使用TCL语言写的测试例脚本,即使作了修改,也用不着重新编译就可以调用TCL解释器直接执行。可以省却不少时间。TCL 目前已成为自动测试中事实上的标准。 目录 前言(TCL综述) 语法脚本,命令和单词符号 置换(substitution) 变量置换variable subtitution 命令置换command substitution反斜杠置换backslash substitution 双引号和花括号 变量简单变量 数组 append和incr expr List concat lindex llength linsert lreplace lrange lappend lsearch 控制流 if 循环命令:while 、for 、 foreach while for break和continue命令 switch source 过程(procedure) 附录(Tcl的安装) 直接打开终端(terminal),输入 sudo apt install tcl即可进行安装,这里的截图是笔者安装成功后的实例。 图片 之后输入tclsh即可 语法 脚本,命令和单词符号 一个TCL脚本可以包含一个或多个命令。命令之间必须用换行符或分号隔开,下面的两个脚本都是合法的: set a 1 set b 2 或使用分号隔开 set a 1;set b 2TCL解释器对一个命令的求值过程分为两部分:分析和执行。在分析阶段,TCL 解释器运用规则把命令分成一个个独立的单词,同时进行必要的置换(substitution); 在执行阶段,TCL 解释器会把第一个单词当作命令名,并查看这个命令是否有定义,如果有定义就激活这个命令对应的C/C++过程,并把所有的单词作为参数传递给该命令过程,让命令过程进行处理。 置换(substitution) TCL解释器在分析命令时,把所有的命令参数都当作字符串看待,例如: %set x 10 //定义变量x,并把x的值赋为10 10 %set y x+100 //y的值是x+100,而不是我们期望的110 x+100上例的第二个命令中,x被看作字符串x+100的一部分,如果我们想使用x的值’10’ ,就必须告诉 TCL解释器:我们在这里期望的是变量x的值,而非字符’x’。怎么告诉TCL解释器呢,这就要用到TCL语言中提供的置换功能。置换功能分为三种.TCL提供三种形式的置换:变量置换、命令置换和反斜杠置换。每种置换都会导致一个或多个单词本身被其他的值所代替。置换可以发生在包括命令名在内的每一个单词中,而且置换可以嵌套。 变量置换variable subtitution 变量置换由一个$符号标记,变量置换会导致变量的值插入一个单词中。例如之前的一个例子 %set x 10 //定义变量x,并把x的值赋为10 10 %set y x+100 //y的值是x+100,而不是我们期望的110 x+100 %set y $x+100 //y的值是我们期望的110 110命令置换command substitution 命令置换是由[]括起来的TCL命令及其参数,命令置换会导致某一个命令的所有或部分单词被另一个命令的结果所代替。例如: %set y [expr $x+100] 110这里当TCL解释器遇到字符’[‘时,它就会把随后的expr作为一个命令名,从而激活与expr对应的C/C++过程,并把expr和变量置换后得到的10+100传递给该命令过程进行处理。 反斜杠置换backslash substitution TCL语言中的反斜杠置换类似于C语言中反斜杠的用法,主要用于在单词符号中插入诸如换行符、空格、[、$等被TCL解释器当作特殊符号对待的字符。 %set msg money\ \$3333\ \nArray\ a\[2] //这个命令的执行结果为: money $3333 Array a[2]双引号和花括号 除了使用反斜杠外,TCL提供另外两种方法来使得解释器把分隔符和置换符等特殊字符当作普通字符,而不作特殊处理,这就要使用双引号和花括号({})。 TCL解释器对双引号中的各种分隔符将不作处理,但是对换行符 及$和[]两种置换符会照常处理。而在花括号中,所有特殊字符都将成为普通字符,失去其特殊意义,TCL解释器不会对其作特殊处理。 %set y "$x ddd" 100 ddd %set y {/n$x [expr 10+100]} /n$x [expr 10+100]注释 TCL中的注释符是#,#和直到所在行结尾的所有字符都被TCL看作注释,TCL解释器对注释将不作任何处理。不过,要注意的是,#必须出现在TCL解释器期望命令的第一个字符出现的地方,才被当作注释。 %set a 100 # Not a comment wrong # args: should be "set varName ?newValue?" %set b 101 ; # this is a comment 101变量 变量分为简单变量和数组 简单变量 一个 TCL 的简单变量包含两个部分:名字和值。名字和值都可以是任意字符串。 % set a 2 2 set a.1 4 4 % set b $a.1 2.1在最后一个命令行,我们希望把变量a.1的值付给b,但是TCL解释器在分析时只把$符号之后直到第一个不是字母、数字或下划线的字符(这里是’.’)之间的单词符号(这里是’a’)当作要被置换的变量的名字,所以TCL解释器把a置换成2,然后把字符串“2.1”付给变量b。这显然与我们的初衷不同。 当然,如果变量名中有不是字母、数字或下划线的字符,又要用置换,可以用花括号把变量名括起来。例如: %set b ${a.1} 4数组 数组是一些元素的集合。TCL的数组和普通计算机语言中的数组有很大的区别。在TCL中,不能单独声明一个数组,数组只能和数组元素一起声明。数组中,数组元素的名字包含两部分:数组名和数组中元素的名字,TCL中数组元素的名字(下标〕可以为任何字符串。 例如: set day(monday) 1 set day(tuesday) 2 set a monday set day(monday) 1 set b $day(monday) //b 的值为 1 ,即 day(monday) 的值。 set c $day($a) //c 的值为 1 ,即 day(monday) 的值。其他命令 unset % unset a b day(monday)上面的语句中删除了变量a、b和数组元素day(monday),但是数组day并没有删除,其他元素还存在,要删除整个数组,只需给出数组的名字。 append和incr 这两个命令提供了改变变量的值的简单手段。 append命令把文本加到一个变量的后面,例如: % set txt hello hello % append txt "! How are you" hello! How are youincr命令把一个变量值加上一个整数。incr要求变量原来的值和新加的值都必须是整数。 expr 可以进行基本的数学函数计算 %expr 1 + 2*3 7List list这个概念在TCL中是用来表示集合的。TCL中list是由一堆元素组成的有序集合,list可以嵌套定 义,list每个元素可以是任意字符串,也可以是list。下面都是TCL中的合法的list: {} //空list {a b c d} {a {b c} d} //list可以嵌套list是TCL中比较重要的一种数据结构,对于编写复杂的脚本有很大的帮助 list 语法: list ? value value…? 这个命令生成一个list,list的元素就是所有的value。例: % list 1 2 {3 4} 1 2 {3 4}使用置换将其相结合 % set a {1 2 3 4 {1 2}} 1 2 3 4 {1 2} % puts $a 1 2 3 4 {1 2}concat 语法:concat list ?list…? 这个命令把多个list合成一个list,每个list变成新list的一个元素。 % set a {1 2 3} 1 2 3 % set b {4 5 6} 4 5 6 % concat $a $b 1 2 3 4 5 6lindex 语法:lindex list index 返回list的第index个(0-based)元素。例: % lindex {1 2 {3 4}} 2 3 4llength 语法:llength list 返回list的元素个数。例 % llength {1 2 {3 4}} 3 % set a {1 2 3} 1 2 3 % llength $a 3linsert 语法:linsert list index value ?value…? 返回一个新串,新串是把所有的value参数值插入list的第index个(0-based)元素之前得到。例: % linsert {1 2 {3 4}} 1 7 8 {9 10} 1 7 8 {9 10} 2 {3 4} % linsert {1 2 {3 4}} 1 {1 2 3 {4 5}} 1 {1 2 3 {4 5}} 2 {3 4} % set a {1 2 3} 1 2 3 % linsert $a 1 {2 3 4} 1 {2 3 4} 2 3lreplace 语法:lreplace list first last ?value value …? 返回一个新串,新串是把list的第firs (0-based)t到第last 个(0-based)元素用所有的value参数替换得到的。如果没有value参数,就表示删除第first到第last个元素。例: % lreplace {1 7 8 {9 10} 2 {3 4}} 3 3 1 7 8 2 {3 4} % lreplace {1 7 8 2 {3 4}} 4 4 4 5 6 1 7 8 2 4 5 6 % set a {1 2 3} 1 2 3 % lreplace $a 1 2 4 5 6 7 1 4 5 6 7 % lreplace $a 1 end 1lrange 语法:lrange list first last 返回list的第first (0-based)到第last (0-based)元素组成的串,如果last的值是end。就是从第first个直到串的最后。 例: % lrange {1 7 8 2 4 5 6} 3 end 2 4 5 6 % set a {1 2 3} 1 2 3 % lrange $a 0 end 1 2 3lappend 语法:lappend varname value ?value…? 把每个value的值作为一个元素附加到变量varname后面,并返回变量的新值,如果varname不存在,就生成这个变量。例: % set a {1 2 3} 1 2 3 % lappend a 4 5 6 1 2 3 4 5 6lsearch 语法:lsearch ?-exact? ?-glob? ?-regexp? list pattern 返回list中第一个匹配模式pattern的元素的索引,如果找不到匹配就返回-1。-exact、-glob、 -regexp是三种模式匹配的技术。-exact表示精确匹配;-glob的匹配方式和string match命令的匹配方式相同;-regexp表示正规表达式匹配。缺省时使用-glob匹配。例: % set a { how are you } how are you % lsearch $a y* 2 % lsearch $a y? -1-all 返回一个列表,返回的列表中的数值就是字符在列表中的位置 默认全局匹配,返回第一个字符在列表中的位置,其位缺省状态 % lsearch {a b c d e} c 2 % lsearch -all {a b c a b c} c 2 5 % lsearch {a b c d c} c 2匹配不到返回-1 % lsearch {a b c d e} g -1控制流 主要是对于所有的控制流,包括 if、while、for、foreach、switch、break、continue 等以及过程, if 语法: if test1 body1 ?elseif test2 body2 elseif…. ? ?else bodyn? TCL先把test1当作一个表达式求值,如果值非0,则把body1当作一个脚本执行并返回所得值,否则把test2当作一个表达式求值,如果值非0,则把body2当作一个脚本执行并返回所得值……。例如: if { $x>0 } { ..... }elseif{ $x==1 } { ..... }elseif { $x==2 } { .... }else{ ..... }if { $x<0 } { puts "x is smaller than zero" } elseif {$x==1} { puts "x is equal 1" } elseif {$x==2} { puts "x is equal 2" } else { puts "x is other" } 这里需要注意的是, if 和{之间应该有一个空格,否则TCL解释器会把’if{‘作为一个整体当作一个命令名,从而导致错误。 ‘{‘一定要写在上一行,因为如果不这样,TCL 解释器会认为if命令在换行符处已结 束,下一行会被当成新的命令,从而导致错误的结果需要将}{ 分开写, 否则会报错extra characters after close-brace 循环命令:while 、for 、 foreach while 语法为: while test body 参数test是一个表达式,body是一个脚本,如果表达式的值非0,就运行脚本,直到表达式为0才停止循环,此时while命令中断并返回一个空字符串。 例如:假设变量 a 是一个链表,下面的脚本把a 的值复制到b: % #首先生成一个集合 % set a {1 2 3 4} 1 2 3 4 % set b " " % #计算生成集合的长度(从0开始这里需要减去1例如:0-3一共有四个数) % set i [expr [llength $a] -1] 3 #接下来进行判断,将集合a中的元素全部按顺序写入b中 % while {$i>=0} { #思考执行该行代码替换会有怎样的结果打印出来 #lappend b [lindex $a $i] lappend b [lindex $a [expr [llength $a] - 1 - $i]] incr i -1 } #打印观察结果 % puts $b 1 2 3 4对代码进行分析 set 变量a为一个list,b为一个空list 然后计算列表里有几个元素,将其减一后的值赋值给i,这里减一的目的是从零开始计数会多一个 开始进行循环,首先i的值是4大于0,表达式为真,开始执行脚本。 脚本为将数组a的第i个位置的元素添加到b list 里,然后给i减一同时进行下一次判断即可。 最后输出b的值 for 语法为: for init test reinit body 参数init是一个初始化脚本,第二个参数test是一个表达式,用来决定循环什么时候中断,第三个参数reinit是一个重新初始化的脚本,第四个参数body也是脚本,代表循环体。下例与上例作用相同:(注意这里复制打印顺序的不同) % set a {1 2 3 4} 1 2 3 4 % set b " " % for {set i [expr [llength $a] -1]} {$i>=0} {incr i -1} { lappend b [lindex $a $i] } % puts $b 4 3 2 1例 % for {set i 0} {$i<4} {incr i} { puts "I is: $i " } I is: 0 I is: 1 I is: 2 I is: 3 foreach 这个命令有两种语法形式 1, foreach varName list body 第一个参数varName是一个变量,第二个参数list 是一个表(有序集合),第三个参数body是循环体。每次取得链表的一个元素,都会执行循环体一次。 下例与上例作用相同: % set a {1 2 3 4} 1 2 3 4 % set b " " % foreach i $a { set b [linsert $b 0 $i] } % puts $b 4 3 2 1% foreach var {a b c d e f} { puts $var } a b c d e f2, foreach varlist1 list1 ?varlist2 list2 ...? Body 这种形式包含了第一种形式。第一个参数varlist1是一个循环变量列表,第二个参数是一个列表list1,varlist1中的变量会分别取list1中的值。body参数是循环体。 ?varlist2 list2 …?表示可以有多个变量列表和列表对出现。例如: set x {} foreach {i j} {a b c d e f} { lappend x $j $i }这时总共有三次循环,x的值为”b a d c f e”。 % foreach i {a b c} j {d e f g} { puts $i puts $j } a d b e c f gset x {} foreach i {a b c} j {d e f g} { lappend x $i $j }这时总共有四次循环, x的值为”a d b e c f {} g set x {} foreach i {a b c} {j k} {d e f g} { lappend x $i $j $k }这时总共有三次循环,x的值为”a d e b f g c {} {}”。 例子: 图片 break和continue命令 在循环体中,可以用break和continue命令中断循环。其中break命令结束整个循环过程,并从循环中跳出,continue只是结束本次循环 这里有一个特别好的例子 说明:这里首先进行给一个list,然后使用foreach循环进行写入数据当遇见break时候直接退出了循环,而continue仅仅只是跳出此次循环继续向b里写入数 % set b {} % set a {1 2 3 4 5} 1 2 3 4 5 % foreach i $a { if {$i == 4} break set b [linsert $b 0 $i] } % puts $b 3 2 1% set b {} % set a {1 2 3 4 5} 1 2 3 4 5 % foreach i $a { if {$i == 4} continue set b [linsert $b 0 $i] } % puts $b 5 3 2 1switch 和 C 语言中 switch 语句一样,TCL 中的 switch 命令也可以由 if 命令实现。只是书写起来较为烦琐。 switch 命令的语法为: switch ? options? string { pattern body ? pattern body …?} 注意这里进行的是字符匹配 图片 set x a; set t1 0;set t2 0;set t3 0; switch $x { a - b {incr t1} c {incr t2} default {incr t3} } puts "t1=$t1,t2=$t2,t3=$t3"x=a时执行的是t1加2 其中 a 的后面跟一个’-’表示使用和下一个模式相同的脚本。default 表示匹配任意值。一旦switch 命令 找到一个模式匹配,就执行相应的脚本,并返回脚本的值,作为 switch 命令的返回值。 source source 命令读一个文件并把这个文件的内容作为一个脚本进行求值 以上边的switch第一段代码为例 使用VIM新建一个文件,写入文件后保存退出 vim switch1.tcl键入wish然后输入source switch1.tcl 图片 过程(procedure) TCL 支持过程的定义和调用,在 TCL 中,过程可以看作是用 TCL 脚本实现的命令,效果与 TCL的固有命令相似。我们可以在任何时候使用 proc 命令定义自己的过程,TCL 中的过程类似于 C中的函数。 TCL 中过程是由 proc 命令产生的: 例如: % proc add {x y } {expr $x+$y} roc 命令的第一个参数是你要定义的过程的名字,第二个参数是过程的参数列表,参数之间用空格隔开,第三个参数是一个 TCL 脚本,代表过程体。 proc 生成一个新的命令,可以象固有命令一样调用: % add 1 2 3
编程&脚本笔记
# TCL脚本
刘航宇
3年前
0
1,676
0
2023-01-31
RHEL7/CentOS7 VM软件中无法显示共享文件问题解决方案
问题: 图片 Linux下共享文件夹的默认路径为 /mnt/hgfs,所以 cd /mnt/hgfs 进入到共享文件夹下, ls 查看刚设置好的共享文件夹是否显示,如若不显示,进行以下操作: 1:输入命令 yum -y install open-vm-tools 安装工具 2:输入命令 vmhgfs-fuse .host:/ /mnt/hgfs 完成设置 设置完成后,cd /mnt/hgfs 进入该目录下ls查看共享文件夹是否显示,或者重启cd /mnt/hgfs 再ls查看。 图片 3.虚拟机重启后发现还是不能显示,执行如下命令 vmhgfs-fuse .host:/ /mnt/hgfs -o nonempty -o allow_other
EDA&虚拟机
# EDA&虚拟机
刘航宇
3年前
0
647
3
2023-01-29
CSA&4-2压缩器电路设计及verilog代码
进位保留加法器和4-2压缩加法器是加法阵列中主要采用基本单元 目录 CSA-保留进位加法器 32计数器/32压缩器 5-3计数器/53压缩器 4-2压缩器 Verilog代码 CSA-保留进位加法器 保留进位加法器( carry-save-adder)即为一位全加器 逻辑表达式: \begin{aligned} & S_i=A_i \oplus B_i \oplus C_{i-1} \ & C_i=A_i B_i+C_{i-1}\left(A_i+B_i\right) \end{aligned} CSA电路结构图 图片 图片 如果把保留进位加法器的进位端输出到下一级 图片 这样第一级的延时为一个进位保留加法器的延时 32计数器/32压缩器 此进位保留加法器输入3个一位的数据A、B、Ci; 输出两个1位的数据D、Co。 代数运算式如下: Co*2+D=A+B+Ci ●非常明显,保留进位加法器为一计数器--计算输入信号中“1”的个数,计数值由Co、D指示,且: ●Co权值为2; A、B、Ci、D权值为1。 ●其逻辑表达式如下: \begin{aligned} & D=A @ B @ C i \ & C o=A \& B \# A \& C i \# C i \& A \end{aligned} 5-3计数器/53压缩器 ●CSA将3个数据转换成2个数据为3-2计数器,如果能把5个数据转换成3个数据则称之为5-3计数器。 ●它有五个输入端: I0、I1、I2、I3、Ci; 三个输出端: D、C、Co。 ●代数运算式如下: $$ D+C * 2+C_0 * 2=10+11+12+13+C i $$即: I0、 l1、 12、13、Ci、D权值为1; C、Co权值为2。 其真值表如下页: 图片 图片 有数据表示优化后的结构可以减小门延时,传统结构为2个CSA延时,而优化后的延时大约为1.5个CSA延时 4-2压缩器 ●如果连续的两个高低位5-3计数器之间Ci和Co级联的话,则称为4-2压缩加法器 ●如下图 图片 42压缩加法器 图片 ●对于更多位的部分积也有其他的一些结构树,结构的选取要考虑到电路结构的规整 性对后端布局的影响。 ●左边延时比较小但结构不规整。右边正好相反有时候会选取一些折中的结构。 Verilog代码 //----------------------------------------------------------------------- //module : compressor42 //Description : The function of this module is to compress the partial product //----------------------------------------------------------------------- //author : li hangyu //Email : hyliu@ee.ac.cn //time : 01/28, 2023 //----------------------------------------------------------------------- `timescale 1ns/1ps module compressor42 ( in1,in2,in3,in4,cin,out1,out2,cout ); parameter length = 8; input [length*2-1 : 0] in1,in2,in3,in4; input cin; output [length*2 : 0] out1,out2; output cout; wire [length*2-1 : 0] w1,w2,w3; assign w1 = in1 ^ in2 ^ in3 ^ in4; assign w2 = (in1 & in2) | (in3 & in4); assign w3 = (in1 | in2) & (in3 | in4); assign out2 = { w1[length*2-1] , w1} ^ {w3 , cin}; assign cout = w3[length*2-1]; assign out1 = ({ w1[length*2-1] , w1} & {w3 , cin}) | (( ~{w1[length*2-1] , w1}) & { w2[length*2-1] , w2}); endmodule
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,047
12
VLSI设计-基于Cadence的16位超前进位加法器设计
目录 一、设计内容 视频介绍 二、设计目标 三、实验原理1位全加器原理 2超前进位加法器原理 四、实验过程和结果1、1位改进型全加器 2、4位超前进位加法器 3、16位超前进位加法器 4、16位超前进位加法器的优化 五、版图 一、设计内容 完成一个 16 位的超前进位加法器模块设计。 视频介绍 二、设计目标 本设计的主要目标是在电路速度尽可能高的条件下减小芯片的面积与功耗。首先考虑电路的逻辑优化,再考虑逻辑门、逻辑模块和电路的结构设计、最后在版图的布局与布线及面积优化方面进行考虑。 三、实验原理 1位全加器原理 全加器的求和输出信号和进位信号,定义为输入变量A、B、C的两种组合布尔函数: 求和输出信号 = A ⊕ B ⊕ C 进位信号 = AB + AC + BC 实现这两个函数的门级电路如下图。并不是单独实现这两个函数,而是用进位信号来产生求和输出信号。这样可以减少电路的复杂度,因此节省了芯片面积。 图片 上述全加器电路可以用作一般的n位二进制加法器的基本组合模块,它允许两个n位的二进制数作为输入,在输出端产生二进制和。最简单的n位加法器可由全加器串联构成,这里每级加法器实现两位加法运算,产生相应求和位,再将进位输出传到下一级。这样串联的加法器结构称为并行加法器,但其整体速度明显受限于进位链中进位信号的延迟。因此,为了能够减少从最低有效位到最高有效位的最坏情况进位传播延时,最终选择的电路是十六位超前加法器。 2超前进位加法器原理 超前进位加法器的结构如下图。超前进位加法器的每一位由一个改进型全加器产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,产生的等式为: $g_i=A_i B_i$ $p_i=A_i+B_i$ 改进的全加器的进位输出可由一个进位信号和一个进位传输信号计算得出,因此进位信号可改写为: $C_{i+1}=g_i+p_i C_i$ 式中可以看出,当gi = 1(Ai = Bi = 1)时,产生进位;当pi = 1(Ai =1或Bi = 1)时,传输进位输入,这两种情况都使得进位输出是1。近似可以得到i+2和i+3级的进位输出如下: 图片 下图为一个四位超前进位加法器的结构图。信号经过pi和gi产生一级时延,经过计算C产生一级时延,则A,B输入一旦产生,首先经过两级时延算出第1轮进位值C’不过这个值是不正确的。C’再次送入加法器,进行第2轮2级时延的计算,算出第2轮进位值C,这一次是正确的进位值。这里的4个4位超前进位加法器仍是串行的,所以一次计算经过4级加法器,一级加法器有2级时延,因此1次计算一共经过8级时延,相比串行加法器里的16级时延,速度提高很多。 图片 四、实验过程和结果 1、1位改进型全加器 (1)1位改进型全加器电路 将原始的一位全加器进行改进,使其产生一个进位信号gi和一个进位传播信号pi,其中全加器的输入为Ai和Bi,得到如下电路图。 图片 (2)1位改进型全加器逻辑验证 在cadence中将导出改进型1位全加器的cdl文件,并编写1bit.sp文件用Hspice进行仿真验证。仿真结果如下图所示,输入信号a、b、c都为脉冲信号,即下图中第一条和第二条曲线,输出信号s为第三条曲线,由图像可知逻辑功能正确,说明改进型一位全加器电路逻辑没有问题。 图片 2、4位超前进位加法器 (1)4位超前进位加法器电路 将1位改进型全加器连接成如下图的4位超前进位加法器,其中电路内部每一个进位信号不是进位传播得到,而使用进位信号和进位传播信号同时计算得到。 图片 (2)4位超前进位加法器逻辑验证 在cadence中将导出4位超前进位加法器的cdl文件,并编写4bit.sp文件用Hspice进行仿真验证。仿真结果如下图。 在sp文件中对B0,B1,B2,B3都输入5V高电平,对A1,A2,A3输入0V低电平,其中A0,C0输入脉冲信号,这样最终的结果S0,S1,S2,S3会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确 图片 3、16位超前进位加法器 (1)16位超前进位加法器电路 将4位超前进位加法器连接成如下图的16位超前进位加法器,加法器之间为并行连接,前一个4位超前进位加法器的进位输送到下一级。 图片 (2)16位超前进位加法器电路逻辑验证 在cadence中导出16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。 在sp文件中对B0,B1,B2,B3,B4,B5,B6,B7,B8,B9,B10,B11,B12,B13,B14,B15都输入5V高电平,对A1,A2,A3,A4,A5,A6,A7,A8,A9,A10,A11,A12,A13,A14,A15输入0V低电平,其中A0,C0输入脉冲信号,这样输出的结果S0,S1,S2,S3,S4,S5,S6,S7,S8,S9,S10,S11,S12,S13, S14,S15和进位信号C会跟随A0脉冲信号的变化而发生变化。由下图可知输出信号S的各个位逻辑功能正确。但是存在较大的延时,经过测量可知延时为8.294ns。 图片 4、16位超前进位加法器的优化 (1)16位超前进位加法器优化原理 由上述结果可知,由于位数增加,超前模块的复杂度也会增加,这将反过来降低加法运算的速度,同时也有较大的延时。为了解决这个问题,对于上述的宽位加法器,使用整组进位信号和,电路结构如下图,4组以上的整组进位信号和传播信号定义为: 图片 上式中每个4组的进位输出信号由进位信号表示如下: 图片 (2)16位超前进位加法器优化电路 由上述改进方法,首先对4位超前进位加法器进行修改,使其输出P,G信号,同时对16位超前进位加法器的电路进行修改,使其每一位的进位信号都可以直接计算出来,而不是依赖于上一个加法器,修改结果如下。 图片 图片 (3)16位超前进位加法器优化电路逻辑验证 在cadence中导出修改后的16位超前进位加法器的cdl文件,并编写16bit.sp文件用Hspice进行仿真验证。仿真结果如下图。经过测量可知延时为6.623ns。 图片 图片 五、版图 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,291
1
2023-01-25
Synopsys ICC简单教程
目录 一、ICC综合概述ICC输入文件 ICC输出文件 二、ICC综合流程1、逻辑库、技术库、版图库等基本参数设定 2、创建自己的Milkyway文件夹 3、布局规划floorplan 4、布局placement 5、时钟树综合CTS 6、布线routing 三、ICC注释详解 一、ICC综合概述 ICC(IC Compiler)是把门级网表转换成foundry厂可用于掩膜的版图信息的过程,它包括数据准备、布局、时钟树综合、布线等步骤。 图片 ICC输入文件 ICC输入需要两部分信息:综合数据+物理数据。 综合数据: 门级网表文件,如orca.v 约束文件,如orca.sdc 逻辑库文件,包含时序信息,如标准单元sc.db,宏单元macros.db,输入输出单元io.db等 物理数据: 技术文件,包含金属层等信息,如abc_6m.tf 线负载模型,TLU+ 物理库文件,包含版图信息,如标准单元sc.mw,宏单元macros.mw,输入输出单元io.mw等 ICC输出文件 ICC输出的是GDSII格式的版图,用于流片。 二、ICC综合流程 参考Synopsys ICC lab1的RISC_CHIP的例子,展示各个流程发生的变化。 1、逻辑库、技术库、版图库等基本参数设定 这是前期的准备工作,设定搜索路径、逻辑时序库.db、负载模型库.tluplus等。 2、创建自己的Milkyway文件夹 Milkyway是Synopsys用于保存版图所有信息的格式,创建自己的Milkyway文件夹用来保存ICC过程中的文件。 读入门级网表,所有的模块都集中在角落,需要加入后续的布局布线信息。 图片 3、布局规划floorplan 布局主要包含芯片大小的规划、IO单元的规划、宏单元的规划、电源网络的设计等。 读入.def文件,包含了整体的布局信息,这个文件需要另外经过许多操作产生: 图片 floorplan一旦确定,整个芯片的面积就定下来了,并且和整个设计的timing、布通率密切相关。 4、布局placement placement是将一个个标准单元模块放入中间区域,通过place_opt自动排布 图片 5、时钟树综合CTS 时钟树综合的主要目的是减小内部各个时钟的偏斜。时钟源必须通过一级一级的buffer才能驱动众多内部时钟,buffer采用上下延时对称的反相器。 下图是时钟树综合后的布局,内部的标准单元会重新排布: 图片 下图高亮了时钟树的内部走线 图片 6、布线routing 布线会经过全局布线(Global routing 和详细布线 (Detail Routing)两个步骤,通过route_opt完成: 图片 三、ICC注释详解 ############################################################ # 1、逻辑库、技术库等基本参数设定 ############################################################ lappend search_path ../ref/db ../ref/tlup set_app_var target_library "sc_max.db" set_app_var link_library "* sc_max.db io_max.db ram16x128_max.db" set_min_library sc_max.db -min_version sc_min.db set_min_library io_max.db -min_version io_min.db set_min_library ram16x128_max.db -min_version ram16x128_min.db # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # RISC_CHIP setup variables # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - set my_mw_lib risc_chip.mw set mw_path "../ref/mw_lib" set tech_file " ../ref/tech/cb13_6m.tf" set tlup_map "../ref/tlup/cb13_6m.map" set tlup_max "../ref/tlup/cb13_6m_max.tluplus" set tlup_min "../ref/tlup/cb13_6m_min.tluplus" set top_design "RISC_CHIP" set verilog_file "./design_data/RISC_CHIP.v" set sdc_file "./design_data/RISC_CHIP.sdc" set def_file "./design_data/RISC_CHIP.def" set ctrl_file "./scripts/opt_ctrl.tcl" set derive_pg_file "./scripts/derive_pg.tcl" set MODULE_NAME RISC_CHIP ############################################################ # 2、创建自己的Milkyway文件夹 ############################################################ file delete -force $my_mw_lib create_mw_lib $my_mw_lib -open -technology $tech_file \ -mw_reference_library "$mw_path/sc $mw_path/io $mw_path/ram16x128" #加载门级网表文件 import_designs $verilog_file \ -format verilog \ -top $top_design #加载线负载模型 set_tlu_plus_files \ -max_tluplus $tlup_max \ -min_tluplus $tlup_min \ -tech2itf_map $tlup_map #加载VDD、VSS信息 source $derive_pg_file #加载约束文件 read_sdc $sdc_file source $ctrl_file source scripts/zic_timing.tcl exec cat zic.timing remove_ideal_network [get_ports scan_en] save_mw_cel -as RISC_CHIP_data_setup ############################################################ # 3、布局规划floorplan ############################################################ # 读入布局信息并布局 read_def $def_file set_pnet_options -complete {METAL3 METAL4} save_mw_cel -as RISC_CHIP_floorplanned ############################################################ # 4、布局placement,放置基本单元 ############################################################ place_opt redirect -tee place_opt.timing {report_timing} report_congestion -grc_based -by_layer -routing_stage global save_mw_cel -as RISC_CHIP_placed ############################################################ # 5、时钟树综合clock tree synthesis ############################################################ remove_clock_uncertainty [all_clocks] set_fix_hold [all_clocks] #时钟树综合 clock_opt redirect -tee clock_opt.timing {report_timing} # 保存文件 save_mw_cel -as RISC_CHIP_cts ############################################################ # 6、布线routing ############################################################ route_opt #报告物理信息 report_design -physical save_mw_cel -as RISC_CHIP_routed ############################################################ # 7、输出文件 ############################################################ file mkdir icc_files write -format ddc -hierarchy -output icc_files/$MODULE_NAME.apr.ddc write_verilog -no_tap_cells icc_files/$MODULE_NAME.lvs.v -pg -no_core_filler_cells write_verilog -no_tap_cells icc_files/$MODULE_NAME.sim.v -no_core_filler_cellssynopsys的实验礼包 synopsys实验 下载地址:https://pan.baidu.com/s/1OQHs8jfcFEs5bSs2fm6o8A?pwd=udwm 提取码:udwm
EDA&虚拟机
# EDA&虚拟机
刘航宇
3年前
0
1,784
0
Verilog RTL级低功耗设计-门控时钟及时钟树
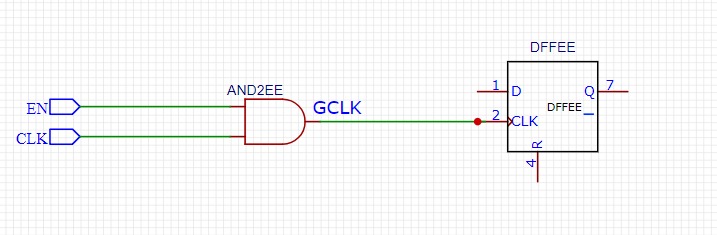
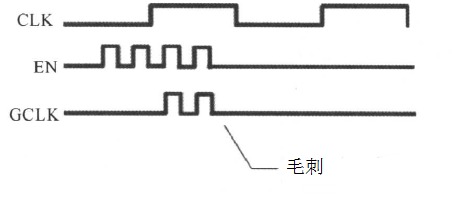
在ASIC/FGPA设计中,我们外界控制所设计的模块时候需要实现告诉他,我要给你输入信号了,你的工作了,反之你不用工作,这个就是门控时钟,就是使能信号EN,一般来说我们用EN控制CLK的产生。芯片功耗组成中,有高达40%甚至更多是由时钟树消耗掉的。这个结果的原因也很直观,因为这些时钟树在系统中具有最高的切换频率,而且有很多时钟buffer,而且为了最小化时钟延时,它们通常具有很高的驱动强度。此外,即使输入和输出保持不变,接收时钟的触发器也会消耗一定的功耗。而且这些功耗主要是动态功耗。 那么减少时钟网络的功耗消耗,最直接的办法就是如果不需要时钟的时候,就把时钟关掉。这种方法就是大家熟悉的门控时钟:clock gating。(大家电路图中看到的CG cell就是门控时钟了) 目录 1门控时钟的结构1.1与门门控 1.2 锁存门控 1.3 寄存门控 1.4 门控时钟结构选择 2 RTL中的门控时钟 附加:门控时钟的时钟树设计 3 RTL 门控时钟编码风格 后记 1门控时钟的结构 1.1与门门控 如果让我们设计一个门控时钟的电路,我们会怎么设计呢?最直接的方法,不需要时钟的时候关掉时钟,这就是与操作,我们只需要把enable和CLK进行“与”操作不就行了么,电路图如下: 图片 这种直接将控制EN信号和时钟CLK进行与操作完成门控的方式,可以完成EN为0时,时钟被关掉。但是同时带来另外一个很大的问题:毛刺 图片 如上图所示,EN是不受控制的,随时可能跳变,这样纯组合输出GCLK就完全可能会有毛刺产生。时钟信号上产生毛刺是很危险的。实际中,这种直接与门的方式基本不会被采样。 所以我们需要改进电路,为了使门控时钟不产生毛刺,我们必须对EN信号进行处理,使其在CLK的高低电平期间保持不变,或者说EN的变化就是以CLK为基准的。 1 很自然的我们会想到触发器,只要把EN用CLK寄存一下,那么输出就是以CLK为基准的; 2 其实还有一种办法是锁存器,把EN用锁存器锁存的输出,也是以CLK为基准的。 1.2 锁存门控 我们先看一下第二种电路,增加锁存器的电路如下: 图片 对应的时序如下: 图片 可以看到,只有在CLK为高的时候,GCLK才可能会输出高,这样就能消除EN带来的毛刺。这是因为D锁存器是电平触发,在clk=1时,数据通过D锁存器流到了Q;在Clk=0时,Q保持原来的值不变。 虽然达到了我们消除毛刺的目的,但是这个电路还有两个缺点: 1如果在电路中,锁存器与与门相隔很远,到达锁存器的时钟与到达与门的时钟有较大的延迟差别,则仍会出现毛刺。 2 如果在电路中,时钟使能信号距离锁存器很近,可能会不满足锁存器的建立时间,会造成锁存器输出出现亚稳态。 如下图分析所示: 图片 上述的右上图中,B点的时钟比A时钟迟到,并且Skew > delay,这种情况下,产生了毛刺。为了消除毛刺,要控制Clock Skew,使它满足Skew ENsetup 一 (D->Q),这种情况下,也产生了毛刺。为了消除毛刺,要控制Clock Skew,使它满足|Skew|< ENsetup一(D->Q)。 1.3 寄存门控 如1.1中提到的,我们还有另外的解决办法,就是用寄存器来寄存EN信号再与上CLK得到GCLK,电路图如下所示: 图片 时序如下所示: 图片 由于DFF输出会delay一个周期,所以除非CLKB上升沿提前CLKA很多,快半个周期,才会出现毛刺,而这种情况一般很难发生。但是,这种情况CLKB比CLKA迟到,是不会出现毛刺的。 当然,如果第一个D触发器不能满足setup时间,还是有可能产生亚稳态。 1.4 门控时钟结构选择 那么到底采用哪一种门控时钟的结构呢?是锁存结构还是寄存结构呢?通过分析,我们大概会选择寄存器结构的门控时钟,这种结构比锁存器结构的问题要少,只需要满足寄存器的建立时间就不会出现问题。 那么实际中是这样么?答案恰恰相反,SOC芯片设计中使用最多的却是锁存结构的门控时钟。 原因是:在实际的SOC芯片中,要使用大量的门控时钟单元。所以通常会把门控时钟做出一个标准单元,有工艺厂商提供。那么锁存器结构中线延时带来的问题就不存在了,因为是做成一个单元,线延时是可控和不变的。而且也可以通过挑选锁存器和增加延时,总是能满足锁存器的建立时间,这样通过工艺厂预先把门控时钟做出标准单元,这些问题都解决了。 那么用寄存器结构也可以达到这种效果,为什么不用寄存器结构呢?那是因为面积!一个DFF是由两个D锁存器组成的,采样D锁存器组成门控时钟单元,可以节省一个锁存器的面积。当大量的门控时钟插入到SOC芯片中时,这个节省的面积就相当可观了。 所以,我们在工艺库中看到的标准门控时钟单元就是锁存结构了: 图片 当然,这里说的是SOC芯片中使用的标准库单元。如果是FPGA或者用RTL实现,个人认为还是用寄存器门控加上setup约束来实现比较稳妥。 门控时钟代码 always@(CLK or CLK_EN) if(!CLK) CLK_TEMP<=CLK_EN assign GCLK=CLK&CLK_TEMP2 RTL中的门控时钟 通常情况下,时钟树由大量的缓冲器和反相器组成,时钟信号为设计中翻转率最高的信号,时钟树的功耗可能高达整个设计功耗40%。 加入门控时钟电路后,由于减少了时钟树的翻转,节省了翻转功耗。同时,由于减少了寄存器时钟引脚的翻转行为,寄存器的内部功耗也减少了。采用门控时钟,可以非常有效地降低设计的功耗,一般情况下能够节省20%~60%的功耗。 那么RTL中怎么才能实现门控时钟呢?答案是不用实现。现在的综合工具比如DC会自动插入门控时钟。如下图所示: 图片 这里有两点需要注意: 插入门控时钟单元后,上面电路中的MUX就不需要了,如果数据D是多bit的(一般都是如此),插入CG后的面积可能反而会减少; 如果D是单bit信号,节省的功耗就比较少,但是如果D是一个32bit的信号,那么插入CG后节省的功耗就比较多了。 这里的决定因素就是D的位宽了,如果D的位宽很小,那么可能插入的CG面积比原来的MUX大很多,而且节省的功耗又很少,这样得不偿失。只有D位宽超过了一定的bit数后,插入CG的收益就比较大。 那么这个临界值是多少呢?不同的工艺可能不一样,但是DC给的默认值是3. 也就是说,如果D的位宽超过了3bit,那么DC就会默认插入CG,这样综合考虑就会有收益。 我们可以通过DC命令: set_clock_gating_style -minimum_bitwidth 4 来控制芯片中,对不同位宽的寄存器是否自动插入CG。一般情况都不会去修改它。 附加:门控时钟的时钟树设计 在时钟树的设计中,门控时钟单元应尽量摆放在时钟源附近,即防止在门控时钟单元的前面摆放大量的时钟缓冲器(Buffer)。 这样,在利用门控时钟电路停时钟时不仅能将该模块中的时钟停掉,也能将时钟树上的时钟缓冲器停止反转,有效地控制了时钟树上的功耗。如图11-24所示,在布局时将门控时钟电路的部件摆放在一起,并摆放在时钟源GCLK附近,停掉时钟后,整个时钟树_上的缓冲器(CTS)和时钟树驱动的模块都停止了翻转。通常的SoC设计中,门控时钟单元会被做成一个硬核或标准单元。 图片 3 RTL 门控时钟编码风格 组合逻辑中,为避免生成锁存器,好的代码风格是if语句都加上else,case语句都加上default。 时序逻辑中,为了让综合工具能够自动生成门控时钟,好的代码风格则是“若无必要,尽量不加else和default”——以减小数据翻转机会。 虽然现在综合工具可以自动插入门控时钟,但是如果编码风格不好,也不能达到自动插入CG的目的。比较下面两种RTL写法: 图片 左边的RTL代码能够成功的综合成自动插入CG的电路; 右边的RTL不能综合成插入CG的电路; 右边电路在d_valid为低时,d_out也会一直变化,其实没有真正的数据有效的指示信号,所以综合不出来插入CG的电路。 需要注意的是,有的前端设计人员,为了仿真的时候看的比较清楚,很容易会写成右边的代码,这样不仅不能在综合的时候自动插入CG来减少功耗;而且增加了d_out的翻转率,进一步增加了功耗。 在不用的时候把数据设成0并不能减少功耗,保持数据不变化才能减少toggle,降低功耗! 所以我们在RTL编写的时候一定要注意。 作为前端设计者,了解这些知识就足够了,如果想深入了解综合的控制,可以去了解 set_clock_gating_style 这个核心控制命令 后记 门控时钟是低功耗技术的一种常规方法,应用已经很成熟了,所以很多人会忽视它的存在和注意事项,也不了解它的具体时序。本文从SOC前端设计的角度详细解释了各种门控时钟的结构和RTL编码需要注意的事项,希望能对设计人员有所帮助。
FPGA&ASIC
IP&SOC设计
# ASIC/FPGA
# SOC优化技术
刘航宇
3年前
0
2,406
3
上一页
1
...
6
7
8
...
26
下一页