首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,161 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,125 阅读
3
【高数】形心计算公式讲解大全
8,748 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,444 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,804 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
刘航宇(共304篇)
找到
304
篇与
刘航宇
相关的结果
- 第 6 页
2023-03-03
天线设计1-基本参数
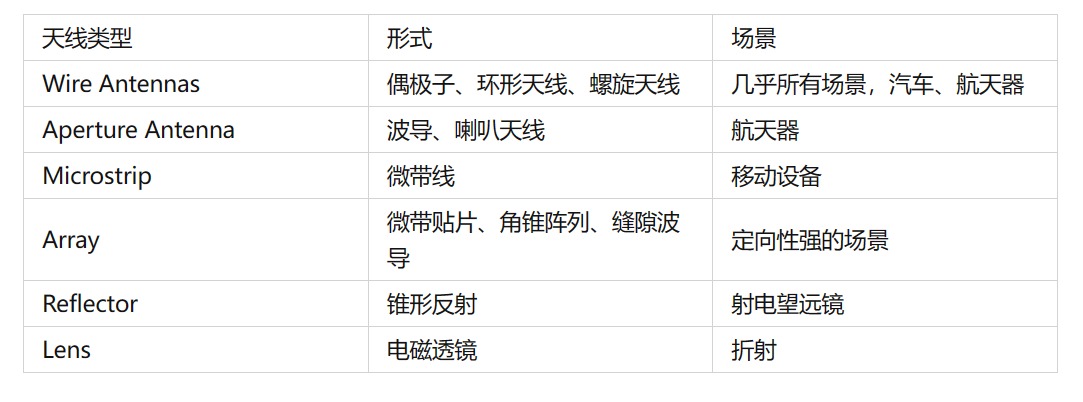
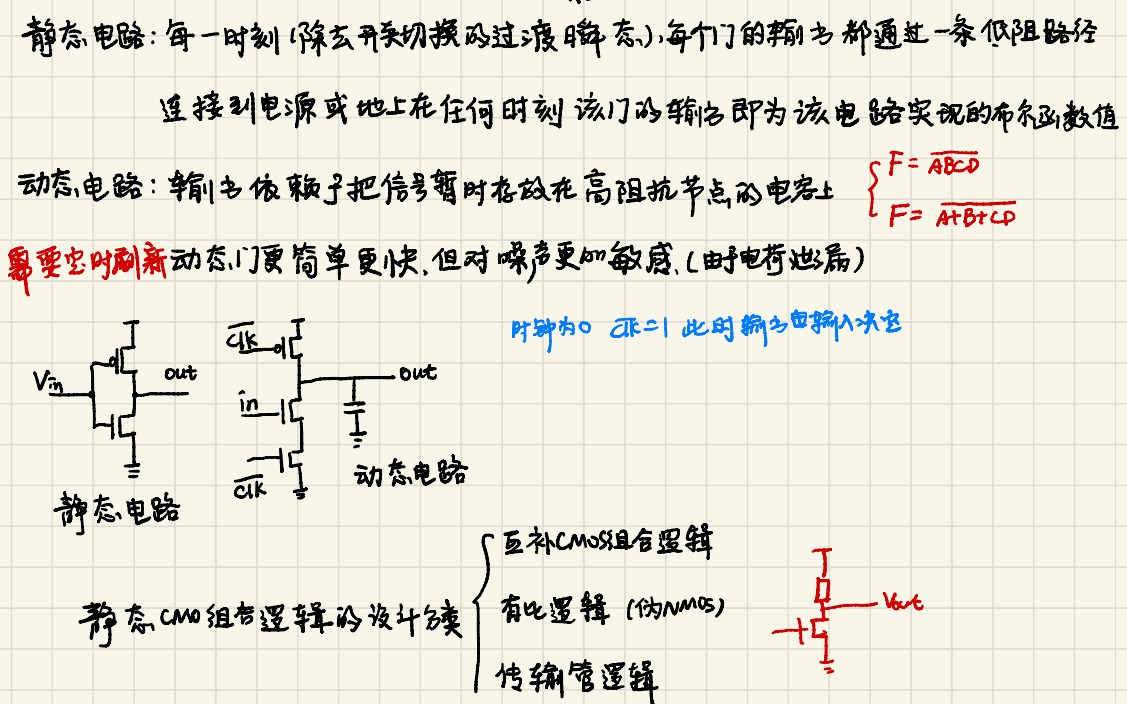
第一章 导言 天线类型 图片 辐射机理 电磁波是如何产生,并最终与天线“分离”而在自由空间中传播的呢? 我们讨论以下几种辐射源的辐射原理。 单根导线 图片 图片 这一方程表示了电流和电荷之间的关系,也是电磁辐射的基本条件:要产生电磁辐射,需要有电流或电荷的加速(或减速)。 要产生电荷的加速或减速,需要导线弯曲、不连续、或者端接。就如同水流一样,当管道宽度变化,流速发生变化,在管道宽度变化的区域,就有水流的加速/减速。 为了定性的的了解辐射机理。考虑一个脉冲源连接到一个导线,导线与GND存在RC寄生参数,到导线通电时,导体中的电子被加速;在终端的电子被减速,即反射;从而在导线的两端和导线上产生辐射场。在这个过程中,电荷加速是外部源造成的,电场使电荷运动;电荷减速,则于是由于感应场有关的力造成的,例如导线两端的电荷积累。因此激励电场引起电荷加速,而导线阻抗不连续导致辐射的产生。 传输线 图片 考虑一个电压源连接到图1.11(a)所示的两根导线上。导线间的交变电压使得电荷加速或减速,交变电场感应出交变的磁场,反之亦然,因此,从天线端产生了电磁波,并传播到自由空间中。 结论:激发电场需要电荷,单维持电场不需要。(这就类似水波的产生) 偶极子 首先我们要接受电磁场传播的速度是有限的。两个偶极子在每T/2的时间内交换位置,每个T/2时间内,电场只能传播的距离。每次偶极子交换位置时,电场的极性发生了变化,因此传播的电场变成交变电场,产生交变磁场,从而形成了脱离源的电磁波。 图片 电流在细导线上的分布 讨论天线的辐射场时,需要知道电流的分布。 图片 图片 图片 图片 分析方法 在过去,分析复杂天线问题通常用积分方程方法、几何衍射理论来求解。此类方法用于线型天线较为方便。然而当辐射系统为多个波长时,低频的方法计算效率不高,最近广为关注和应用的GTD/UTD方法,它是几何光学的拓展,通过引入衍射机制,克服了几何光学的局限性。有限差分时域是另一种在散射方面受到广泛关注的方法,现已应用到天线辐射问题。有限元是一种在解决天线问题中获得巨大成功的方法。 遇到的挑战 目前仍有许多挑战和需要解决的问题,例如单片集成MIC技术和相控阵架构依然是最具挑战的问题。复杂问题的计算电磁学。创新的天线设计。多功能、多频带、超宽带、可重构天线等。 第二章 天线的基本参数和FOM 在描述天线性能前,需要定义一些参数,一些参数可能是相互关联的。书中的许多带引号的定义来源于 IEEE Standard Definitions of Terms for Antennas [IEEE Std 145-1993.Reaffirmed 2004(R2004)] Radiation Pattern 辐射图 在天线研究中,通常用球面坐标来表示电磁场会较为方便,因此首先介绍球面坐标系 图片 图片 图片 辐射波瓣(radiation lobe):以辐射强度较弱的区域为边界,将辐射图分割成几个区域。 最大的辐射波瓣称为主瓣(major lobe),其他则为次瓣(minor lobe)。副瓣(side lobe)通常表示功率水平最高的次瓣。后瓣(back lobe)方向与主瓣方向相反的次瓣。 图片 图片 图片 各向同性、定向、全向天线 图片 其中全向天线是定向天线的特殊类型。 主平面 对于线性极化的天线,通常用其主要平面图来描述其性能,包括: 电场平面(E-plane):包含最大电场矢量与最大辐射方向的平面。 磁场平面(H-plane):包含最大磁场矢量与最大辐射方向的平面。 大多数天线的通常的做法是让至少一个电磁平面与几何平面重合。例如图2.5中,可以定义XOZ平面为电场的主平面,而XOY为磁场的主平面。 图片 图片 Field Regions 场区 天线周围空间可分成三个区域: 图片 图2.8显示了,从近场到远场时,场的形状随距离的典型变化趋势。在近场中,场更加分散,几乎均匀,只有很小的变化,随着距离到辐射近场区,图案变得圆滑,逐渐形成波瓣。在远场区,形成了类似花瓣的图案。 图片 弧度和球面度 图片 图片 波束宽度 HPBW Half power beam width 半波束宽度 FNBW First Null Beam width 第一组零点之间的宽度 方向性 定义:在给定方向上的辐射强度与各项同性源的辐射强度之比。 图片 波束立体角 波束立体角定义:假如辐射强度是恒定的,且等于最大值,流过某一个立体角的功率等于天线辐射功率,那么该立体角称为波束立体角。 图片 图片 图片 传导效率和介电效率通常很难计算,可以通过实验测量,但也很难区分出二者,因此把两项合并成传导-介电效率 极化 辐射波的极化定义为:沿着传播方向观察电场的矢量箭头,随时间变化,绘制的轨迹图。 极化可以分成线性、圆形和椭圆。如果电场的矢量始终沿着一条直线变化,则该电场称为线性极化;但一般而言,电场矢量箭头的路径通常是椭圆形,这称为椭圆极化。圆形和线性实际上是椭圆的特赦情况。 假如有一个沿着负z轴方向传播的平面波。其电场可以写成: 图片 图片 输入阻抗 图片 重要公式 图片
通信&信息处理
# 天线设计
刘航宇
3年前
0
1,538
1
AMBA--APB总线协议及Verilog实现与仿真
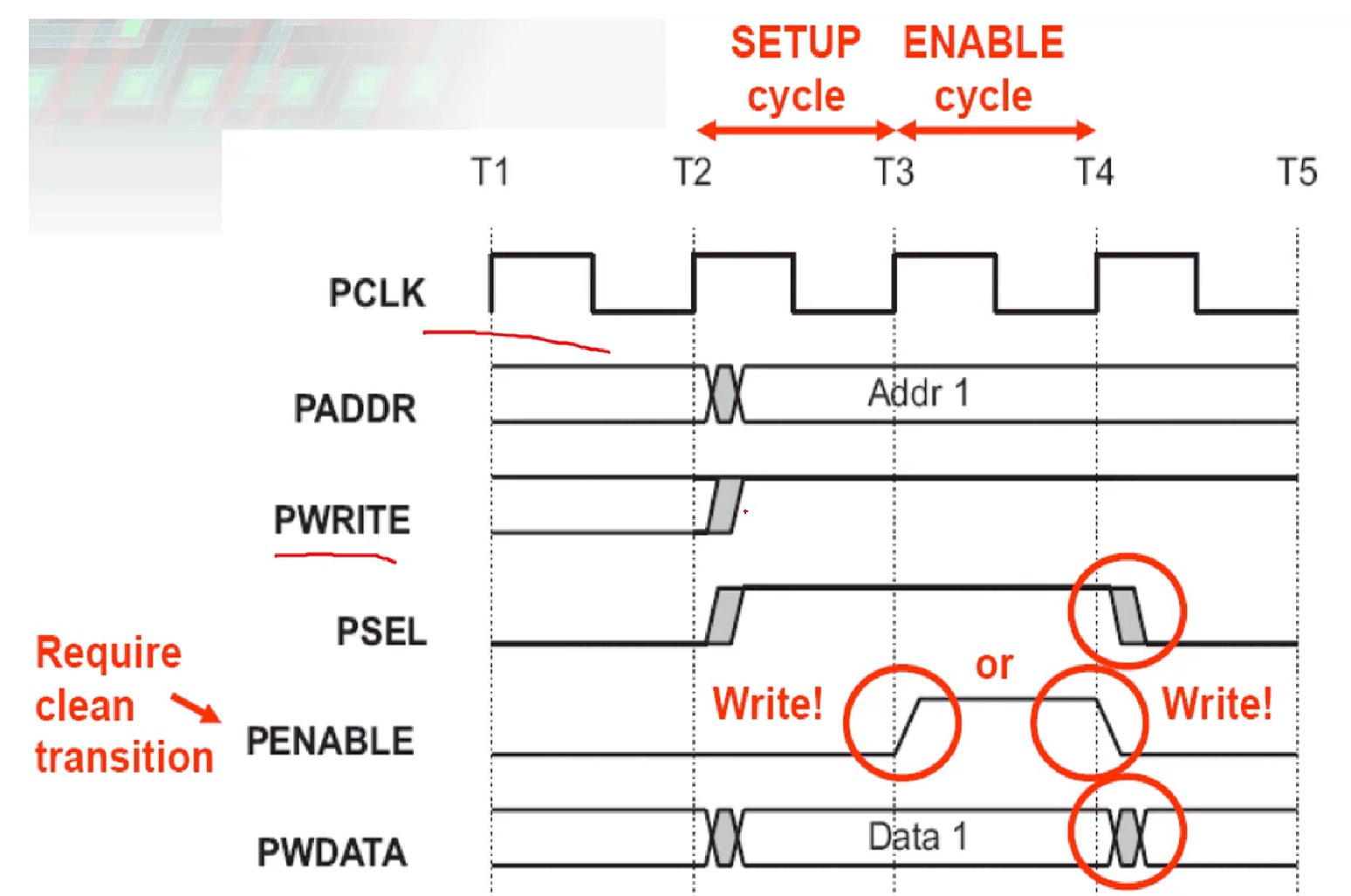
1、APB总线简介 APB:Advanced Peripheral Bus,高级外设总线,具备以下特性: (1)低功耗; (2)接口协议简单; (3)总线传输使用时钟上升沿进行,便于时序分析; (4)应用广泛,支持多种外设。 所有的APB模块均是APB从机。 2、APB信号列表 所有的APB总线信号都以字母P作为前缀,下表列出了APB信号的名称以及对信号的描述: NameWidthI/ODescriptionPCLK1bitInAPB总线时钟,所有传输只能发生在PCLK的上升沿PRESETn1bitInAPB总线复位信号,低电平有效PADDR32bitInAPB地址总线PSEL1bitInAPB从机片选信号PENABLE1bitInAPB选通信号,高电平表示APB传输的第二个周期PWRITE1bitInAPB读写控制信号,高表示写,低表示读PRDATA32bitOutAPB读数据信号,最高为32位PWDATA32bitInAPB写数据信号,最高为32位3、APB总线时序 (1)写时序 图片 写传输开始于T2时刻,在改时钟上升沿时刻,地址、写信号、PSEL、写数据信号同时发生变化,T2时钟,即传输的第一个时钟被称为SETUP周期。在下个时钟上升沿T3,PENABLE信号拉高,表示ENABLE周期,在该周期内,数据、地址以及控制信号都必须保持有效。整个写传输在这个周期结束时完成。 (2)读时序 图片 读传输开始于T2时刻,在改时钟上升沿时刻,地址、写信号、PSEL信号同时发生变化,在下个时钟上升沿T3,PENABLE信号拉高,从机必须在ENABLE周期内提供读数据,读数据信号将在T4上升沿时刻被采样。 经历2个cycle就读数据,不需要握手 4、Verilog实现 下面编写一个简单的基于APB接口的memory读写控制程序供读数据,读数据信号将在T4上升沿时刻被采样。 `timescale 1ns / 1ps module apb_sram #( parameter SIZE_IN_BYTES = 1024 ) ( //---------------------------------- // IO Declarations //---------------------------------- input PRESETn, input PCLK, input PSEL, input [31:0] PADDR, input PENABLE, input PWRITE, input [31:0] PWDATA, output reg [31:0] PRDATA ); //---------------------------------- // Local Parameter Declarations //---------------------------------- localparam A_WIDTH = clogb2(SIZE_IN_BYTES); //---------------------------------- // Variable Declarations //---------------------------------- reg [31:0] mem[0:SIZE_IN_BYTES/4-1]; wire wren; wire rden; wire [A_WIDTH-1:2] addr; //---------------------------------- // Function Declarations //---------------------------------- function integer clogb2; input [31:0] value; reg [31:0] tmp; reg [31:0] rt; begin tmp = value - 1; for (rt = 0; tmp > 0; rt = rt + 1) tmp = tmp >> 1; clogb2 = rt; end endfunction //---------------------------------- // Start of Main Code //---------------------------------- // Create read and write enable signals using APB control signals assign wren = PWRITE && PENABLE && PSEL; // Enable Period assign rden = ~PWRITE && ~PENABLE && PSEL; // Setup Period assign addr = PADDR[A_WIDTH-1:2]; // Write mem always @(posedge PCLK) begin if (wren) mem[addr] <= PWDATA; end // Read mem always @(posedge PCLK) begin if (rden) PRDATA <= mem[addr]; else PRDATA <= 'h0; end endmodule测试代码: `timescale 1ns / 1ps `ifndef CLK_FREQ `define CLK_FREQ 50000000 `endif module top_tb(); //---------------------------------- // Local Parameter Declarations //---------------------------------- parameter SIZE_IN_BYTES = 1024; localparam CLK_FREQ = `CLK_FREQ; localparam CLK_PERIOD_HALF = 1000000000/(CLK_FREQ*2); //---------------------------------- // Variable Declarations //---------------------------------- reg PRESETn = 1'b0; reg PCLK = 1'b0; reg PSEL; reg [31:0] PADDR; reg PENABLE; reg PWRITE; reg [31:0] PWDATA; wire [31:0] PRDATA; reg [31:0] reposit[0:1023]; //---------------------------------- // Start of Main Code //---------------------------------- apb_sram #( .SIZE_IN_BYTES (SIZE_IN_BYTES) ) u_apb_sram ( .PRESETn (PRESETn), .PCLK (PCLK), .PSEL (PSEL), .PADDR (PADDR), .PENABLE (PENABLE), .PWRITE (PWRITE), .PWDATA (PWDATA), .PRDATA (PRDATA) ); // generate PCLK always #CLK_PERIOD_HALF begin PCLK <= ~PCLK; end // generate PRESETn initial begin PRESETn <= 1'b0; repeat(5) @(posedge PCLK); PRESETn <= 1'b1; end // test memory initial begin PSEL = 1'b0; PADDR = ~32'h0; PENABLE = 1'b0; PWRITE = 1'b0; PWDATA = 32'hffff_ffff; wait(PRESETn == 1'b0); wait(PRESETn == 1'b1); repeat(3) @(posedge PCLK); memory_test(0, SIZE_IN_BYTES/4-1); repeat(5) @(posedge PCLK); $finish(2); end // memory test task task memory_test; // starting address input [31:0] start; // ending address, inclusive input [31:0] finish; reg [31:0] dataW; reg [31:0] dataR; integer a; integer b; integer err; begin err = 0; // read-after-write test for (a = start; a <= finish; a = a + 1) begin dataW = $random; apb_write(4*a, dataW); apb_read (4*a, dataR); if (dataR !== dataW) begin err = err + 1; $display($time,,"%m Read after Write error at A:0x%08x D:0x%x, but 0x%x expected", a, dataR, dataW); end end if (err == 0) $display($time,,"%m Read after Write 0x%x-%x test OK", start, finish); err = 0; // read_all-after-write_all test for (a = start; a <= finish; a = a + 1) begin b = a - start; reposit[b] = $random; apb_write(4*a, reposit[b]); end for (a = start; a <= finish; a = a + 1) begin b = a - start; apb_read(4*a, dataR); if (dataR !== reposit[b]) begin err = err + 1; $display($time,,"%m Read all after Write all error at A:0x%08x D:0x%x, but 0x%x expected", a, dataR, reposit[b]); end end if (err == 0) $display($time,,"%m Read all after Write all 0x%x-%x test OK", start, finish); end endtask // APB write task task apb_write; input [31:0] addr; input [31:0] data; begin @(posedge PCLK); PADDR <= #1 addr; PWRITE <= #1 1'b1; PSEL <= #1 1'b1; PWDATA <= #1 data; @(posedge PCLK); PENABLE <= #1 1'b1; @(posedge PCLK); PSEL <= #1 1'b0; PENABLE <= #1 1'b0; end endtask // APB read task task apb_read; input [31:0] addr; output [31:0] data; begin @(posedge PCLK); PADDR <= #1 addr; PWRITE <= #1 1'b0; PSEL <= #1 1'b1; @(posedge PCLK); PENABLE <= #1 1'b1; @(posedge PCLK); PSEL <= #1 1'b0; PENABLE <= #1 1'b0; data = PRDATA; // it should be blocking end endtask `ifdef VCS initial begin $fsdbDumpfile("top_tb.fsdb"); $fsdbDumpvars; end initial begin `ifdef DUMP_VPD $vcdpluson(); `endif end `endif endmodule该测试用例,主要实现了APB读和写的task,用于产生APB读写时序,对memory的测试分成连个部分,一个是每进行一次写传输后,紧接着进行同地址的读传输,让后对比读写结果一致性;另一个测试是在连续写一段地址后,再全部读出改地址段的数据,完成读操作后进行数据比对。 下面是仿真打印信息 图片 APB写传输时序的仿真波形如下: 图片 APB写传输时序的仿真波形如下: 图片
IP&SOC设计
# SOC设计
刘航宇
3年前
0
2,647
2
2023-02-27
VLSI设计基础11-运算模块之加法器
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 总论 2. 加法器1. 一位全加器(FA) 2. 【结构】设计全加器FA 3. 传输门型加法器——传统型 4. 传输门型加法器——曼切斯特FA 4. 【重要】超前进位加法器 1. 总论 在时序电路中,时序电路=组合电路+存储电路 在(9)~(11)中,已经详细介绍了存储电路(寄存器) 在本文中,将介绍组合电路中比较重要的数据通路上的电路,可以认为是在时序电路中提到的 ,即用于逻辑运算和算数运算。 在数集中,常用的数据通路组合电路有 加法器 乘法器 移位器 我们的目的,是追求以下几个方面的优化 性能 面积 功耗 如何优化: 逻辑层次优化:利用状态机、真值表等,优化布尔方程得到一个速度更快、面积更小的电路 电路层次优化:改变管子的尺寸;改变电路的拓扑连接(互补CMOS、动态CMOS等) 2. 加法器 加法器在数据通路电路中的地位类似于反相器在与或等简单逻辑电路的位置 数据通路的电路的基础是加法器 乘法器也是加法器扩展而来的 加法器是限制数据通路运算速度的元件。 1. 一位全加器(FA) 传统表达方式 定义:根据输入的二值数据、进位信号,计算得到结果和进位。 图片 图片 【注】: 异或,常见结构有: 图片 同或,结构如下(即“异或门结构2”的“非”): 图片 P、G、D函数表达 真值表如下: 图片 图片 逐位(行波)加法器 所谓逐位(行波)加法器,指的是将N个一位全加器(FN)串联在一起构成加法器。如下图 图片 图片 2. 【结构】设计全加器FA 互补静态CMOS结构FA 图片 图片 镜像加法器 该加法器是根据互补静态CMOS结构FA改进得到的,镜像加法器的下拉网络和互补CMOS结构FA完全相同。 电路图如图所示, 图片 图片 3. 传输门型加法器——传统型 图片 图片 4. 传输门型加法器——曼切斯特FA 静态电路 图片 图片 动态电路 图片 动态电路简单 动态电路单向工作,传输门使用NMOS管实现 该电路不需要D 曼切斯特进位链加法器 图片 图片 【逻辑】设计全加器FA 旁路进位加法器 图片 图片 延时 图片 $t_{\text {adder }}=t_{\text {setup }}+M t_{\text {carry }}+\left(\frac{N}{M}-1\right) t_{\text {bypass }}+(M-1) t_{\text {carry }}+t_{\text {sum }}$ 线性进位选择加法器 图片 图片 图片 图片 平方根进位加法器 图片 图片 图片 4. 【重要】超前进位加法器 原理 图片 图片 图片 图片 块运算 图片 图片 图片 点操作 步骤如下: 图片 图片 图片 Kogge-Stone 16位超前进位加法器 图片 图片 Brent-Kung 16位超前进位加法器 图片 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,647
5
VLSI设计基础10-时序逻辑电路设计(二)
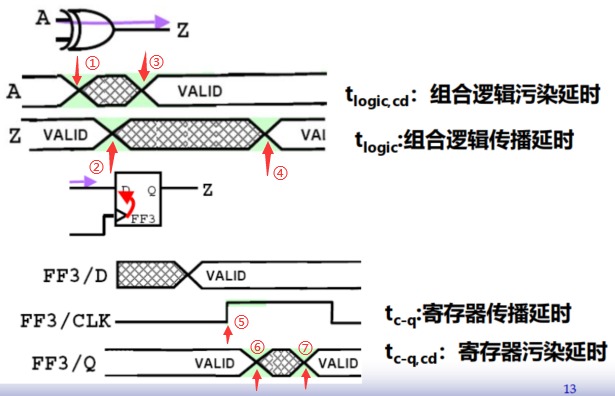
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 时序基础概念 2. 时序分析的分类4. 时序约束参数(重点) 5. 各种信号路径、时序路径 6. 时钟参数两大条件(重点) 2. 时间偏差与抖动(重点)1. 时钟偏差(Clock Skew) 2. 时钟抖动(Clock Jitter) 1. 时序基础概念 时序分析的目的 对数字系统进行时序检查,判断电路是否可以正常工作(常面临建立时间和保持时间等问题),判断电路的性能等。 常常分析电压、温度、工艺(工艺角)等参数进行分析。 2. 时序分析的分类 静态时序分析(STA) 主要研究对象:建立时间、保持时间、传播延时 常用于分析同步时序电路(源时钟和目的时钟相同) 时序分析模型: 同步时钟/异步时钟 D触发器分割组合逻辑 图片 一般不需要进行太复杂的仿真,仅需要计算就可以进行分析,运行速度快。 不依赖于激励,根据穷尽信号路径上的器件就可以进行计算 常用方法是使用查找表——①输入跳变时间②输出负载(电容)→①传播延时②输出跳变(下一级的输入跳变)。 动态时序分析(DTA) 指门级仿真 主要用于异步逻辑、多周期路径 在FPGA中,将RTL代码综合利用综合工具综合成门级网络进行仿真,其中各种门级器件的逻辑是厂家提供的。 【时钟】沿 发送沿:发送数据的源时钟活动沿 捕获沿:接收数据的目的时钟的活动沿 源时钟:用于发送数据的时钟 目的时钟:用于接受数据的时钟 小贴士:在同步电路中,源时钟和目的时钟是同一个 4. 时序约束参数(重点) 即:建立时间tsu、保持时间thold、传播延时tc-q,同时我们引入污染时间tcd 建立时间: 对于捕获沿到来之前,数据需要保持稳定的时间 间接约束了组合逻辑的最大延时 保持时间: 对于捕获沿到来之后,数据需要保持稳定的时间 间接约束了组合逻辑的最小延时 传播时间(延时): 即 最大延时 时间 捕获沿50%(数据输入沿50%【注意:数据输入沿其实就是捕获沿!!!】)到数据稳定输出(输出数据50%)的时间 根据器件不同,可以分为组合逻辑传播延时tlogic和寄存器传播延时tc-q,详细见后文。 污染时间: 可以理解为 最短延时 时间——理想状态下 从输入“扰动”到输出“扰动”的时间,下文进行解释。 根据器件不同,可以分为组合逻辑污染延时tlogic,cd和寄存器污染延时tc-q,cd,详细见后文 所谓理想状态,指的是数据没有跳变时间,即数据跳变是瞬间完成的,数据跳变的90%、50%、10%是在同一个时间。 根据以上理想状态的定义,可认为一有扰动,数据就跳变完成。 计算污染时间和传播时间 图片 现对图中四个时间进行解释: 图片 图片 5. 各种信号路径、时序路径 信号的路径主要分为三个 图片 时钟路径 源时钟路径&目的时钟路径 图片 数据路径 图片 数据起点: 对于时序逻辑电路,为某时序单元的时钟引脚 对于组合逻辑电路,为某逻辑单元的数据输入端口 数据终点: 对于组合逻辑电路、时序逻辑电路都一样,均为某单元的数据输出端口 异步路径(如异步复位) 根据路径可将分析类型分为 同步分析:时钟路径+数据路径 异步分析:时钟路径+异步路径 6. 时钟参数两大条件(重点) 周期条件 图片 保持时间条件 图片 图片 2. 时间偏差与抖动(重点) 理想时钟: 从时钟沿到各个单元的时钟端口的延时相等(即路径均匀); 同一个时刻,各个单元的时钟端的时钟相位相等。 实际时钟: 时钟偏差:各个时钟端口的时钟的周期没有改变,但是相位可能略有差别。 时钟抖动:时钟的周期存在一些差别,或长或短。 1. 时钟偏差(Clock Skew) 定义与成因 指同一个时钟域之间,时钟信号到达各个寄存器的最大时间差 产生原因: 时钟源到达各个端点的路径长度不同 各个端口的负载不同 时钟网络中插入的缓存器不等 计算【全局偏差、局部偏差】 图片 全局时钟偏差 图片 局部时钟偏差 图片 时钟偏差分类(正负) 正偏差 正偏差,即时钟延迟方向与数据流方向一致,如图所示。 图片 负偏差 正偏差,即时钟延迟方向与数据流方向相反,如图所示。 图片 利用时间偏差修补建立时间 图片 【周期T】时钟偏差对于周期的影响 前文提到,负偏差使得实际逻辑计算的时间减小,为了填补裕量,只能增加时间周期,而提高时间周期会使得电路的性能下降。 图片 2. 时钟抖动(Clock Jitter) 定义与计算 定义:芯片某一给定点上,时钟周期宽度发生变化,或缩短或变宽 计算: 图片 图片 【周期T】时钟抖动对于周期的影响 因为时钟抖动是难以预料的,在确定时钟周期的时候,我们应该考虑最坏的情况,即$T-2 t_{\text {jitter }}>t_{c-q}+t_{\text {logic }}+t_{s u}$ 即上图所示的③-④。因为这意味着周期T需要增加tjitter,性能降低 总结 图片 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,422
1
2023-02-24
VLSI设计基础9-时序逻辑电路设计(一)
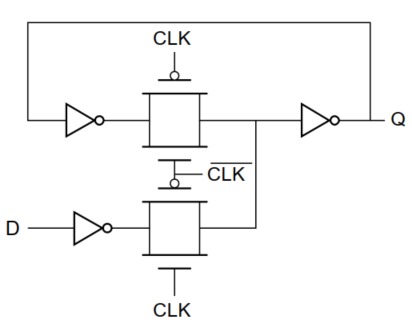
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 时序电路的相关概念1. 时序电路 2. 静态/动态存储器 3. 时序参数(重点) 4. 时序约束条件(重点) 5. 锁存器和寄存器 静态锁存器/寄存器1. 静态锁存器1. 电路图与分析 2. 时序参数分析 2. 静态寄存器——边沿触发寄存器 3. 动态锁存器/寄存器 4. 流水线和多周期路径(重点) 1. 时序电路的相关概念 1. 时序电路 框架: 时序电路=组合电路+存储电路 结果:取决于当前的输入和过去的状态。 2. 静态/动态存储器 静态存储器: 上电就保持存储状态 通过正反馈,有意将输入和输出连接 如果长时间不用可以用门控时钟关闭(起到降低功耗的作用) 图片 动态存储器: 简单而言,即传输门+反相器,如下图。 利用寄生电容存储高低电平 只能存储较短的时间(ms级别)(电容小等原因使得存储时间短) 需要周期性刷新来补偿泄露电荷(参见(9)动态门) 结构简单,有较高性能(管子少,RC小)和较低功耗(不存在静态功耗) 图片 3. 时序参数(重点) 图片 为何这么说? 因为只有当满足了建立时间,此时时钟CLK才可以翻转,即此时的数据才是输入端输入的数据 所以输入端数据的50%即为时钟的50% 图片 图片 小贴士: 建立时间tsu和保持时间thold都是针对时钟的有效沿而言的。 即,输入数据50%的时间对时钟有效沿50%的时间;对于传播延时 ,输入信号50%(即时钟信号)时间对输出信号50%时间 4. 时序约束条件(重点) 图片 1.时钟周期T 图片 2.保持时间thold 图片 5. 锁存器和寄存器 图片 静态锁存器/寄存器 1. 静态锁存器 1. 电路图与分析 以正锁存器为例,电路图如下, 图片 电路结构:以传输门为主体的二选一选择器;CLK=1,Q=D;而CLK=0,通过正反馈,输出端和输入端连接。 2. 时序参数分析 1.5中提到,分析正锁存器时,需要注意的时钟边沿是时钟的下降沿。 这是因为,在CLK=1时,Q=D,属于透明传输,即输出随输入随时变化。其信号传播路径:D-①-②-③-Q 当CLK=1->0时,锁存器将要对输入数据进行所存。因此需要考虑建立时间tsu。 如果要让数据可以正确锁存下来,需要④⑤之间的节点的电平等于③⑤之间节点的电平,即 $$ D_{(4)(5)}=D_{(3)(5)} $$2. 静态寄存器——边沿触发寄存器 边沿触发寄存器,又称主-从寄存器,由主、从两个锁存器组成 电路图与分析 图片 图片 图片 主-从寄存器,由主锁存器——负锁存器、从锁存器——正锁存器组成。 图片 时序参数分析 图片 图片 图片 寄存器复位——同步/异步 同步复位(RST=0时复位) 图片 异步复位(clr=0时复位) 图片 3. 动态锁存器/寄存器 动态锁存器 电路图: 图片 使用电容电荷表示一个逻辑信号。 但是值的保存时间有限(ms)(漏电时间),需要周期性进行刷新。 动态寄存器 电路图 图片 工作原理: 图片 时间参数分析: 图片 存在的问题 图片 图片 优化——提高噪声容限 图片 3.C2MOS寄存器 图片 图片 4. 流水线和多周期路径(重点) 流水线 电路的工作速度取决于时序电路间的组合逻辑 可以通过将复杂、延迟大的组合逻辑(如计算lg(AB))通过寄存器进行分割,提高做工效率。 需要注意时序设计。每增加一个寄存器,结果就落后一拍! 图片 多周期路径 主要是写RTL代码时需要注意。 如果一个组合逻辑计算需要多个时间周期完成,可以通过一个cnt进行移位(移位运算量小)。当满足某个条件时,寄存器en=1,输出结果。 如:某运算需要经过四个周期完成,可以声明cnt=4'b0001,每个时钟进行左移,当cnt[3]==1'b1时,en=1,输出结果。
VLSI&IC验证
# VLSI
刘航宇
3年前
0
816
2
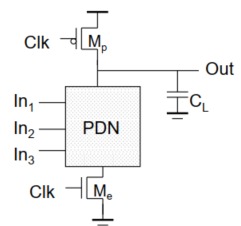
VLSI设计基础8-动态COMS
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 综述 2. 存在的问题——信号完整性问题 3. 多米诺逻辑 4. 组合多米诺逻辑 静态CMOS:稳态时,通过低阻路径连接VDD或GND 互补CMOS:上下网络互补,上拉到VDD,下拉到GND。管子数为2N 传输管逻辑:上拉网络用其他代替,有比逻辑,存在VTH。管子数为N+1 动态CMOS:依靠高阻抗上的电容存储临时的信号。管子数为N+2 图片 1. 综述 结构如下, 图片 工作方式:工作分为两个阶段 预充电:CLK=0,Mp导通,对CL充电 求值:CLK=1,MN导通,OUT和GND之间存在低阻通路。 特点: 全电压摆幅 无比逻辑(同互补CMOS,异传输管逻辑) 噪声容限低。因为out在预充电阶段已经充电到VDD,即VDS已经满足>VOV,于是只要VIN>VTH,管子就会导通。 需要预充电和求值的时钟。 较快的开关速度。原因如下, 相对互补CMOS,缺少了上拉网络的一个门,相对负载是互补CMOS,负载是动态门的CL比较小 动态门没有短路电流(同一个时刻,只能一个导通),由下拉网络提供的所有电流都用于CL电容的放电 如果IN=0,则不存在输出延时(预充电完输出即为1);如果IN=1,则需要CL放电 晶体管重复利用,减小面积(多输出多米诺) 优点: 提高速度 减小面积(多输出多米诺;N+2个管子) 没有短路功耗 没有毛刺(因为一次只能翻转一次,CL放电完只能等效下一次预充电才能回到1) 2. 存在的问题——信号完整性问题 电荷泄露 来源:与CL相连的管子存在反偏二极管和亚阈值漏电。 图片 解决办法:使用泄露晶体管 反馈形式的伪NMOS型上拉器件。 该晶体管为了减小功耗和尺寸,一般选用尺寸较小(电阻值大)的管子。 图片 电荷分享 来源:下拉网络中存在的节点电容CA。当A=0-》1、B=0,则原本存储在电容CL上的电荷在CL和CA之间重新分配,造成输出电压有所下降 图片 ※需要满足A=0-》1、B=0才能进行电荷分享,否则当B=1的时候,求值过程中(CLK=1),CL存储的电荷将全部被释放掉,不存在点电荷分享现象 图片 3. 多米诺逻辑 多米诺逻辑即为前文所述的串联动态门,目的就是保证预充电时,输入均为0;求值时,输入只做0→1的翻转 $$ \text { 多米诺逻辑 }=n \text { 型动态门 }+\text { 反相器 } $$图片 初始状态均为0,求值的时候根据前一级输出确定下一级输入,从而求下一级输出。 特点: 求值层层传播,如多米诺骨牌 求值阶段的时间取决于逻辑深度(因为求值时候的特性,见上) 只能实现非反向逻辑 无比逻辑 节点需要在预充电充完电,求值的过程中,输入需要特别稳定。 速度非常快(因为当上一级的输入都是0时,下一级相当于无延迟传播) 输入电容小(和互补CMOS比,只有一个管子) 4. 组合多米诺逻辑 组合多米诺逻辑,并不需要在每个动态门之后加反相器,而是借助一个复合互补CMOS门将多个动态门组合起来。 图片 eg: 图片 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
958
2
2023-02-23
VLSI设计基础7-传输管与传输门逻辑
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 传输管逻辑1. 有比逻辑 2. 传输管逻辑 3. 互补传输管逻辑(CPL) 3. 传输门逻辑 传输管逻辑 1. 有比逻辑 传输管逻辑是有比逻辑;互补CMOS是无比逻辑。 简单而言, 无比逻辑:输出的高低电平和尺寸无关。比如互补CMOS可以直接把输出电压拉到VDD或者GND 有比逻辑:输出的高低电平和尺寸有关。基本没办法直接拉到最大逻辑摆幅。 上拉网络由一个负载代替,如下三种常见的负载(电阻负载、有源负载、伪NMOS负载) 图片 图片 图片 输出端的电压摆幅和门的功能取决于NMOS和PMOS的尺寸比 对于伪NMOS管负载 优点:逻辑门减小,面积减小,只需要n+1个管子,而互补CMOS需要2n个管子 缺点: 有比逻辑,达不到最大逻辑摆幅。 可能没办法完全关断MOS管,静态功耗增加。 应用:面积要求严格,性能要求不高的场景。 2. 传输管逻辑 区别 传输管逻辑和互补CMOS有以下差别: 图片 串联 综合以上的区别,原因主要出在于输入端可以从D、G,而输出从S,从而使输出和输入之间存在VTH的压降 为了减小VTH带来的影响,传输管串联采用D-S-D-S的方式,而不采用D-S-G-S的方式 前者只有一个VTH压降,而后者有两个 如下: 图片 3. 互补传输管逻辑(CPL) 优点: 互补输入输出 每个输出节点都有一个低阻路径连接到VDD或者GND 模块化 缺点: 存在VTH,充电充不到VDD,只能充到VDD-VTH 解决方法:电平恢复、多种阈值晶体管、传输门逻辑 确定输出: 图片 图片 3. 传输门逻辑 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
1
4,218
11
VLSI设计基础6-努力概念与优化
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 总论 2. 【重点】努力2. lg(逻辑努力)和G(路径逻辑努力)--【重点】 3. b(分支努力)和B(路径分支努力) 3.【重点】【优化】 确定电路尺寸 1. 总论 不同材料工艺 CMOS、双极性、BiCMOS、GaAs、超导等材料 逻辑级优化 逻辑深度:流水线【一级变n级】 电路拓扑:逻辑电路寄存器放几个、怎么放、要不要放;重定时(主要EDA工具完成) 扇出 门的复杂性 电路优化 逻辑类型、晶体管尺寸、不同频率下的电路模型 物理优化 版图策略 布局布线 2. 【重点】努力 根据INV延时的通式, $t_p=t_{p 0} \cdot\left(1+\frac{f}{\gamma}\right)$ 推广到所有的逻辑电路中,即有 $t_p=t_{p 0} \cdot\left(p+\frac{g \cdot f}{\gamma}\right)=t_{p 0} \cdot\left(p+\frac{h}{\gamma}\right)$ 图片 p(本征延时比) 如果忽略内部节点电容,p的计算: $p=\frac{\text { 复合门的输出端本征电容 }}{I N V \text { 输出端的本征电容 }}$ 因,$C_{i n t}=a \cdot W$,于是电容值可以用W来代替。 注意,是和输出端相连的管子才参与计算 图片 图片 图片 2. lg(逻辑努力)和G(路径逻辑努力)--【重点】 定义:一个门在最坏情况下,与反相器提供相同的输出电流(即电阻相等或驱动能力相等)时,所表现的输入电容比反相器大多少倍。 小贴士: 反相器有最小的逻辑努力 随着门的复杂度增加,逻辑努力相应增加 只和门的拓扑有关,与尺寸无关 逻辑努力g的计算: 图片 图片 3. b(分支努力)和B(路径分支努力) 图片 公式:$b=\frac{C_{o n-p a t h}+C_{o f f-p a t h}}{C_{o n-p a t h}}$ 注意: 分支努力是针对与一个路径节点而言的 如果只有一条路径,没有分叉,则b=1;如果该节点两个分支的栅电容大小相等,则b=2; 图片 对于路径分支努力B $B=\prod_1^n b_i$ 对于一条路径,该路径的分支努力等于路径上所有节点的分支努力连乘。 f(电气努力)和F (路径电气努力) 图片 f又称为等效扇出,表示第j+1级管子(j+1级输入电容)相对于第j级管子(j级输入电容)的尺寸(电容值)。 $$ f=\frac{C_{e x t}}{C_g} $$图片 图片 对于一条路径,该路径的电气努力等于路径上所有门的电气努力连乘然后除以路径分支努力。 h(门努力)和 g(路径门努力) $$ h=g \cdot f $$图片 3.【重点】【优化】 确定电路尺寸 为了追求更好的性能,即最低的延时,我们希望可以调整尺寸,让组合逻辑的延时最小。 图片 推导如下: ※本征延时和路径中逻辑门的类型有关,和尺寸无关。具体推导看(3)4.3 图片 eg: 求出路径上各级门的尺寸系数S 图片 如上图电路图,可以将电路分成以下4级 图片 步骤一:确定G、B、F 图片 图片 步骤二:确定级数N 由图可知,N=4 步骤三:计算门努力h $$ h=\sqrt[N]{H}=\sqrt[4]{55.56}=2.73 $$步骤四:计算尺寸系数Si 图片 最优级数N=lnF 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
1
2,977
16
2023-02-23
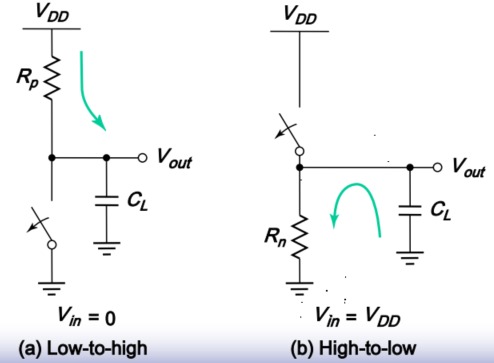
VLSI设计基础5-CMOS组合逻辑门电路
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. CMOS电路的分类 2. 静态互补CMOS设计 2. 【重点】如何确定晶体管尺寸 3. Elmore延时模型 4. 【Elmore延时】计算复合门延时——【多扇入】 5. 降低【多扇入】的电路的延时 6. 延时和【扇出】 7. 总结 1. CMOS电路的分类 静态互补CMOS电路 即常见的CMOS电路——开关模型=理想开关+有限电阻 门输出通过一个低阻连接到VCC和GND,输出为该电路实现的布尔值(0或者1) 特点如下: 高噪声容限(见(4)噪声门限)。 高输入阻抗,低输出阻抗 静态功耗可忽略(见(4)功耗) 动态CMOS集成电路 信号暂时存储在高阻抗电路节点上面的电容上——RC大 特点如下: 门电路简单、速度快 设计和制作工艺复杂 对噪声敏感 图片 2. 静态互补CMOS设计 何为互补CMOS 互补CMOS由上拉网络(PUN)和下拉网络(PDN)组成,每个输入都分配到上拉和下拉网络 如下图,以与非门为例: 图片 图片 规则 以NMOS管作为分析对象, 串与,并或 即,NMOS管串联,实现与非功能;NMOS管并联,实现或非功能。 其关系如下图: 图片 为何是非?因为互补CMOS本身脱身于反相器,故自带非逻辑。 PMOS与之对偶 图片 【静态CMOS】分析逻辑门电路 CMOS管构成的电路分析,使用开关模型——理想开关+有限电阻+电容 以两输入与非门为例,如下图 图片 注意:有节点的地方,一般都有电容。如上图两输入与非门所示,两个串联的NMOS管之间存在节点,于是存在一个电容Cint;上拉和下拉网络之间存在节点,这个节点正好是输出结果的节点,为CL 图片 2. 【重点】如何确定晶体管尺寸 图片 图片 图片 图片 图片 图片 3. Elmore延时模型 【用途】:用于大概估算具有众多电容、电阻电路的延时,适用于【RC树】 最基本的公式:$t_p=0.69 R C=0.69 \tau$ 图片 图片 图片 $\tau=R_1 C_1+R_1 C_2+\left(R_1+R_3\right) C_3+\left(R_1+R_3\right) C_4+\left(R_1+R_3+R_i\right) C_i$ 于是 图片 4. 【Elmore延时】计算复合门延时——【多扇入】 图片 图片 分析【多扇入】: 晶体管串联导致电阻增大,传播延时随着扇入数的增大而增大 一个门的无负载本征延时最坏情况下,延时约为扇入数的二次函数 实际应用中,一般扇入数不超过4 5. 降低【多扇入】的电路的延时 调整管子尺寸 ——逐级加大晶体管尺寸,即在Elmore分析中出现最多次的管子的电阻应该减小(W增大) 图片 尺寸:M1>M2>M3....>MN 重新安排输入 ——关键路径上的晶体管应该靠近输出端。 关键信号:一个门的输出信号中,在所有输入中最后到达稳定的信号。 关键路径:决定一个结构最终速度的逻辑路径称为关键路径。 原理:越靠近输出端,信号需要经过的管子少,RC延时短。 图片 1.重构逻辑结构 ——多扇入逻辑电路拆解成若干个较低扇入的逻辑电路。 前面Elmore延时模型已经知道,延时和扇入数接近平方关系增长。 于是降低扇入数,可以降低电路的整体延时。 加入buffer隔开大扇入和大扇出 图片 图片 6. 延时和【扇出】 图片 7. 总结 关于逻辑门的延时,给出如下的公式进行描述 $t_p=a_1 F_I+a_2 F_I^2+a_3 F_O$ FI表示总的等效扇入,Fo表示总的等效扇出。 可见,延时与扇入成平方关系,同扇出成线性关系
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,465
6
VLSI设计基础4-反相器
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. INV综述 2. INV的静态特性 3. 【重点】INV的动态特性——tp4. 【※重要】计算延时tp——计算、优化 5. 根据【延时】设计电路 3. 反相链的设计 6. 功耗 7. 利用【功耗】设计电路 1. INV综述 INV的数集模型 图片 由组成的图可以知道,INV是由两个CMOS管串联组成的。而CMOS的数集模型是理想开关+有限导通电阻or无限关断电阻,故INV的数集模型如下 图片 即两个电阻开关并联。 图中的CL表示晶体管的漏极电容、连线电容、扇出门的输入电容 INV的特性综述 图片 VTC(电压传输特性) 所有的工作点不是输出高电平就是输出低电平,如下图: 图片 静态CMOS反向中PMOS和NMOS的负载曲线,原点表示直流工作点 2. INV的静态特性 开关阈值(VM) 图片 图片 噪声门限 图片 图片 3. 【重点】INV的动态特性——tp 设计角度 最小的传播延时 这是厂家最希望的 满足性能的同时,做到面积最小 面积最小,意味着成本最低。这里的面积取决于W,也就是选择合适的 根据扇出设计反相器链的级数 对于时钟树、复位树等需要多扇出的、且要求tp小的,如何设计一个合理的高扇出的反相器链 输入信号的上升下降时间对传播延时的影响 计算计算CL CL =晶体管的漏极电容+连线电容+扇出门的输入电容. 图片 等效电阻Req $R_{e q}=\frac{1}{V_{D D} / 2} \int_{V_{D D} / 2}^{V_{D D}} \frac{V}{I_{D S A T(1+\lambda V)}} d V \approx \frac{3}{4} \frac{V_{D D}}{I_{D S A T}}\left(1+\frac{7}{9} \lambda V_{D D}\right)$ 4. 【※重要】计算延时tp——计算、优化 图片 图片 5. 根据【延时】设计电路 图片 图片 图片 性能最好(tp-min)的反相器 图片 图片 3. 反相链的设计 反相链结构图 图片 图片 图片 例题 图片 6. 功耗 功耗组成 动态功耗:来源于电容充放电 短路电流:当输入电压在某一个区域时,使得上下两管同时导通,从而形成短路电流。 漏电流:属于静态功耗 动态功耗 工作过程——能量分配 来源于电容充放电 图片 图片 公式 图片 短路电流引起功耗 图片 图片 图片 图片 静态功耗(漏电流) 图片 图片 7. 利用【功耗】设计电路 图片 【小贴士】:延迟最低的等效扇出系数为$f=\sqrt[N]{F}$
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,229
2
2023-02-23
VLSI设计基础3-导线与互联问题
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 互连参数 2. 导线模型分布RC模型(重点) 3. 总结 互连问题1. 电容寄生效应 2. 电阻寄生效应 3. 性能——长导线延时 1. 互连参数 导线材料 金属层 多晶硅层 n+或p+扩散层 互连参数——电容 平板电容模型 边缘电容模型 互连参数——电阻 方块电阻: 图片 扩展: 芯片中的互连,一般高层的金属层一般W较大,于是电阻更小。 即W↑→R↓→功耗P↓,RC↓ 因此高层金属层,如M4、M5,常用于时钟、电源等关键信号的 布线中间层金属用作于信号线。 互连参数——电感 当频率上GHZ的时候,才会去考虑电感的作用。 2. 导线模型 模型 理想导线:一般用于较大尺寸的工艺中 集总模型 适用情况:电阻小;开关频率中低水平 内容:将一条导线上的电容集总成一个电容 集总RC模型 适用情况:电阻较大,不可忽略;开关频率中低水平 内容:将一条导线上的电容集总成一个电容,电阻集总成一个电阻 不足:当互连线太长时,该模型当变得保守 图片 分布RC模型(重点) 适用情况:互连线长;导线电阻、电容不可忽略 根据推导可知,一条导线的延时同他的长度呈现二次方关系 和集总RC模型对比 分布RC模型得到的延时是集总RC模型的1/2 适用于长互连线 图片 图片 图片 图片 传输线模型 适用情况:高频、射频、微波;互连材料好,其导线电阻保持在一定范围内。 内容:高频情况下,需要考虑电感的作用 3. 总结 图片 互连问题 寄生参数对于电路的危害: 影响信号的完整性 降低信号的性能 增加延时 增加功耗 寄生的类型——电容、电阻、电感 1. 电容寄生效应 此处讨论电容寄生主要是串扰 串扰的定义: 由相邻的信号线之间不希望有的耦合引起的干扰 小贴士: 耦合有多种,常常是电容性的耦合 串扰引起的噪声难以捕捉 串扰的危害 串扰将使得导线的延时难以预见,故产生了下文“可预见的导线延时设计” 可预见的导线设计 估计改进 方法:不断参数提取,不断仿真,不断优化 缺点:设计过程需要多次重复,时间长 备注:最常用 能动性的版图生成 布线程序考虑相邻导线的作用 缺点:主要由EDA工具完成,在如今EDA工具的要求高 备注:有吸引力;已经有一些EDA工具具备该功能 可预测的结构 方法:密集型布线结构——同层信号线使用电源线隔离,相邻层采用垂直布线。 缺点:面积和电容增加了+5%,功耗和延时增加 优点:减小了电容串扰,延时差别也下降到不超过2% 图片 克服电容串扰的方法 尽量避免浮空节点,对串扰敏感的节点,加保持器降低阻抗、 敏感节点应当很好地与全摆幅信号隔离 在满足时序约束的范围内尽可能加大上升(下降)时间 在敏感的低摆幅布线网络中采用差分信号传输方法 不要使两条信号线之间的电容太大 在两个信号之间增加屏蔽线(即加GND或VDD),使线间电容变成接地电容来消除串扰,但增加了电容负载 使用屏蔽层GND或VDD 2. 电阻寄生效应 总论 原因:芯片尺寸的减小,使得线宽减小,导线电阻增加,导线压降增加。 常考虑:电源网络设计——导线消耗了电压,使得供给门电路的电压下降 供给门电路的电压下降的危害 噪声容限降低 延时增加 降低电迁移的方法 改变金属线属性。 如合金或者Cu代替Al导线,但是成本增加。 降低温度。 降低温度可以减小电迁移发射概率。 芯片封装上面需要考虑散热问题。 增加线宽。 增加线宽可以降低平均电流密度。 缺点;增加布线资源,成本增加 优点:增加线宽不仅可以降低平均电流密度,还可以降低金属温度,间接又抑制了电迁移。 3. 性能——长导线延时 总论 原因:根据导线模型——分布RC模型,可知$t_p \propto L^2$。为了降低电路延时,提高电路的响应速度,需要降低导线寄生电阻。 降低长导线延时的方法 采用更好的互连材料。 导线:铜、合金等;绝缘材料:低介电常数的材料 ※但是,这种方法不是解决长导线延时的根本方法。 增加互连金属层的数目 管子数目增多驱动这金属层数目增多。 局部线(底层金属层做信号传输)采用高密度,全局线(高层金属层走全局信号,如时钟线、电源线) 采用更好的互连策略——对角线法 图片 采用对角线式布线(如上图),现场可较小29%,但是对于EDA工具、掩膜制作的要求高,难度大。 目前一般采用曼哈顿式布线,即横平竖直式的布线。 中间插入中继器——中继器 长的互连线中插入中继器(如inv buffer),强行减小导线长度。但是中继器也存在延时。 优化互连结构——寄存器或锁存器 方法:导线流水线——长互连线中插入寄存器或者锁存器,将导线分成K段。 优点:可以提高数据处理能力。每段导线中可以加入中继器进行进一步优化。
VLSI&IC验证
# VLSI
刘航宇
3年前
0
2,096
3
VLSI设计基础2-器件之MOS晶体管
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 MOS晶体管1. 数字电路的晶体管——最直观 2. MOS静态特性——稳定性(CMOS模电基础) 3. 数字电路手工分析模型——开关+Req 4. 【重点】MOS管的动态特性——性能(tp) 4. 寄生电阻(了解) 5.求tPHL例子(重点) MOS晶体管 1. 数字电路的晶体管——最直观 执行开关功能 非常小的寄生电容 非常高的集成度 相对简单的制造工艺 符号: 图片 2. MOS静态特性——稳定性(CMOS模电基础) 阈值电压 考虑体效应对于阈值电压的影响——偏执效应系数 图片 阈值电压与材料常数(氧化层厚度、费米电势、注入离子剂量等)有关 2.三个工作区: 截止—(亚阈值导电)—线性—饱和—(击穿) 沟长调制效应 图片 4. 速度饱和-重点 短沟道的饱和区范围更大,故常常工作在饱和区。 图片 图片 以下适用于NMOS,PMOS讨论需要取绝对值 图片 漏电流ID和VGS 长沟道,呈现平方关系 短沟道,不那么显著 3. 数字电路手工分析模型——开关+Req 常用开关模型——晶体管=开关+无穷大断开电阻Ron or 有限导通电阻Ron 【计算等效导通电阻Req】:2种方法 图片 例题与方法: 图片 图片 图片 图片 4. 【重点】MOS管的动态特性——性能(tp) 电容的分类 MOS管的动态响应取决于: 本征电容: 基本的MOS结构:结构电容 沟道电荷:沟道电容 漏源反向偏置的PN结耗尽电容:结电容 注意:除了结构电容外,其他两个电容是非线性、随电压变化的 寄生电容 (连线和负载引起) 略解本征电容 简单归类: 图片 小贴士:红色框框:结构电容;灰色框框:沟道电容;蓝色框框:结电容 两个覆盖(结构)电容: $\begin{gathered}C_O=C_{G C O}+C_{G D O}=2 C_o W \\ C_{G C O}=C_{G D O}=C_{o x} x_d W=C_o W\end{gathered}$ 覆盖电容是由于源漏横向扩散到栅氧下形成的寄生电容,故而有两个——栅源之间(CGSO)和栅漏之间(CGDO) 由于这个电容是由于扩散形成的,只要器件做成之后就电容大小就确定,于是结构电容是三类电容中唯一可以确定确切大小的 图片 三个沟道电容: 沟道电容,即栅到沟道之间的电容,称为CGC,即 (Gate Channel)。其中,$C_{G C}=C_{G C B}+C_{G C S}+C_{G C D}$ 即,栅至体、栅至源、栅至漏电容。 由于和沟道有关,又因为沟道形成和工作点有关,于是三个工作点下,CGC不同。 图片 图片 两个(PN)结(耗尽层)电容: PN结电容是由于源-体和漏-体之间反向偏置造成的。 由于工艺上面,我们是在体上“挖一个坑“放漏和源,故而他们之间存在着”立体“的关系。 故而需要关注”四周立体接触“,如图所示, 图片 图片 图片 我们关注的【本征电容】有哪些 我们研究电容是为了利用$\tau=R C$计算tp的值,故而我们在意的是输入和输出通路上的电容。 图片 输入电容——栅极电容 图片 2.输出电容——漏极电容 图片 4. 寄生电阻(了解) 源漏区的串联电阻。 图片 危害: 当晶体管尺寸进一步缩小,会使结变浅、接触孔变小。使得这个影响更加显著。 当给定一个电压,由于分压作用,会使得漏极电流变小。 改善: 源漏极铺一层低电阻材料(如钨或者钛) 5.求tPHL例子(重点) 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,011
0
上一页
1
...
5
6
7
...
26
下一页