首页
📁归档
⏳时光机
📫留言
🚩友链
💰资助名单
推荐
🎧音乐
🏜️ 壁纸
❤ 捐助
Search
1
【NPN/PNP三极管】放大电路饱和失真和截止失真的区别
19,008 阅读
2
论文写作中如何把word里面所有数字和字母替换为新罗马字体
10,043 阅读
3
【高数】形心计算公式讲解大全
8,726 阅读
4
【概论】一阶矩、二阶矩原点矩,中心矩区别与概念
7,414 阅读
5
Vivado-FPGA Verilog烧写固化教程
6,747 阅读
🪶微语&随笔
励志美文
我的随笔
写作办公
📡电子&通信
嵌入式&系统
通信&信息处理
编程&脚本笔记
⌨️IC&系统
FPGA&ASIC
VLSI&IC验证
EDA&虚拟机
💻电子&计算机
IP&SOC设计
机器学习
软硬件算法
登录
⌨️IC&系统(共78篇)
找到
78
篇与
⌨️IC&系统
相关的结果
- 第 3 页
2023-02-24
VLSI设计基础9-时序逻辑电路设计(一)
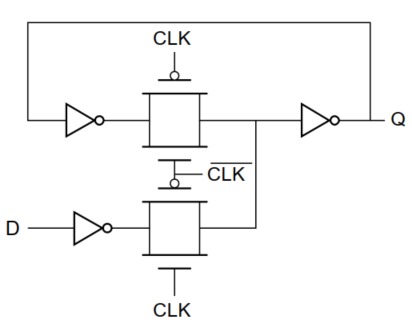
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 时序电路的相关概念1. 时序电路 2. 静态/动态存储器 3. 时序参数(重点) 4. 时序约束条件(重点) 5. 锁存器和寄存器 静态锁存器/寄存器1. 静态锁存器1. 电路图与分析 2. 时序参数分析 2. 静态寄存器——边沿触发寄存器 3. 动态锁存器/寄存器 4. 流水线和多周期路径(重点) 1. 时序电路的相关概念 1. 时序电路 框架: 时序电路=组合电路+存储电路 结果:取决于当前的输入和过去的状态。 2. 静态/动态存储器 静态存储器: 上电就保持存储状态 通过正反馈,有意将输入和输出连接 如果长时间不用可以用门控时钟关闭(起到降低功耗的作用) 图片 动态存储器: 简单而言,即传输门+反相器,如下图。 利用寄生电容存储高低电平 只能存储较短的时间(ms级别)(电容小等原因使得存储时间短) 需要周期性刷新来补偿泄露电荷(参见(9)动态门) 结构简单,有较高性能(管子少,RC小)和较低功耗(不存在静态功耗) 图片 3. 时序参数(重点) 图片 为何这么说? 因为只有当满足了建立时间,此时时钟CLK才可以翻转,即此时的数据才是输入端输入的数据 所以输入端数据的50%即为时钟的50% 图片 图片 小贴士: 建立时间tsu和保持时间thold都是针对时钟的有效沿而言的。 即,输入数据50%的时间对时钟有效沿50%的时间;对于传播延时 ,输入信号50%(即时钟信号)时间对输出信号50%时间 4. 时序约束条件(重点) 图片 1.时钟周期T 图片 2.保持时间thold 图片 5. 锁存器和寄存器 图片 静态锁存器/寄存器 1. 静态锁存器 1. 电路图与分析 以正锁存器为例,电路图如下, 图片 电路结构:以传输门为主体的二选一选择器;CLK=1,Q=D;而CLK=0,通过正反馈,输出端和输入端连接。 2. 时序参数分析 1.5中提到,分析正锁存器时,需要注意的时钟边沿是时钟的下降沿。 这是因为,在CLK=1时,Q=D,属于透明传输,即输出随输入随时变化。其信号传播路径:D-①-②-③-Q 当CLK=1->0时,锁存器将要对输入数据进行所存。因此需要考虑建立时间tsu。 如果要让数据可以正确锁存下来,需要④⑤之间的节点的电平等于③⑤之间节点的电平,即 $$ D_{(4)(5)}=D_{(3)(5)} $$2. 静态寄存器——边沿触发寄存器 边沿触发寄存器,又称主-从寄存器,由主、从两个锁存器组成 电路图与分析 图片 图片 图片 主-从寄存器,由主锁存器——负锁存器、从锁存器——正锁存器组成。 图片 时序参数分析 图片 图片 图片 寄存器复位——同步/异步 同步复位(RST=0时复位) 图片 异步复位(clr=0时复位) 图片 3. 动态锁存器/寄存器 动态锁存器 电路图: 图片 使用电容电荷表示一个逻辑信号。 但是值的保存时间有限(ms)(漏电时间),需要周期性进行刷新。 动态寄存器 电路图 图片 工作原理: 图片 时间参数分析: 图片 存在的问题 图片 图片 优化——提高噪声容限 图片 3.C2MOS寄存器 图片 图片 4. 流水线和多周期路径(重点) 流水线 电路的工作速度取决于时序电路间的组合逻辑 可以通过将复杂、延迟大的组合逻辑(如计算lg(AB))通过寄存器进行分割,提高做工效率。 需要注意时序设计。每增加一个寄存器,结果就落后一拍! 图片 多周期路径 主要是写RTL代码时需要注意。 如果一个组合逻辑计算需要多个时间周期完成,可以通过一个cnt进行移位(移位运算量小)。当满足某个条件时,寄存器en=1,输出结果。 如:某运算需要经过四个周期完成,可以声明cnt=4'b0001,每个时钟进行左移,当cnt[3]==1'b1时,en=1,输出结果。
VLSI&IC验证
# VLSI
刘航宇
3年前
0
802
2
VLSI设计基础8-动态COMS
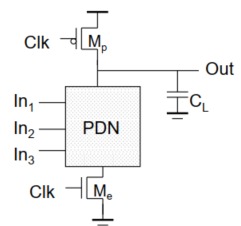
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 综述 2. 存在的问题——信号完整性问题 3. 多米诺逻辑 4. 组合多米诺逻辑 静态CMOS:稳态时,通过低阻路径连接VDD或GND 互补CMOS:上下网络互补,上拉到VDD,下拉到GND。管子数为2N 传输管逻辑:上拉网络用其他代替,有比逻辑,存在VTH。管子数为N+1 动态CMOS:依靠高阻抗上的电容存储临时的信号。管子数为N+2 图片 1. 综述 结构如下, 图片 工作方式:工作分为两个阶段 预充电:CLK=0,Mp导通,对CL充电 求值:CLK=1,MN导通,OUT和GND之间存在低阻通路。 特点: 全电压摆幅 无比逻辑(同互补CMOS,异传输管逻辑) 噪声容限低。因为out在预充电阶段已经充电到VDD,即VDS已经满足>VOV,于是只要VIN>VTH,管子就会导通。 需要预充电和求值的时钟。 较快的开关速度。原因如下, 相对互补CMOS,缺少了上拉网络的一个门,相对负载是互补CMOS,负载是动态门的CL比较小 动态门没有短路电流(同一个时刻,只能一个导通),由下拉网络提供的所有电流都用于CL电容的放电 如果IN=0,则不存在输出延时(预充电完输出即为1);如果IN=1,则需要CL放电 晶体管重复利用,减小面积(多输出多米诺) 优点: 提高速度 减小面积(多输出多米诺;N+2个管子) 没有短路功耗 没有毛刺(因为一次只能翻转一次,CL放电完只能等效下一次预充电才能回到1) 2. 存在的问题——信号完整性问题 电荷泄露 来源:与CL相连的管子存在反偏二极管和亚阈值漏电。 图片 解决办法:使用泄露晶体管 反馈形式的伪NMOS型上拉器件。 该晶体管为了减小功耗和尺寸,一般选用尺寸较小(电阻值大)的管子。 图片 电荷分享 来源:下拉网络中存在的节点电容CA。当A=0-》1、B=0,则原本存储在电容CL上的电荷在CL和CA之间重新分配,造成输出电压有所下降 图片 ※需要满足A=0-》1、B=0才能进行电荷分享,否则当B=1的时候,求值过程中(CLK=1),CL存储的电荷将全部被释放掉,不存在点电荷分享现象 图片 3. 多米诺逻辑 多米诺逻辑即为前文所述的串联动态门,目的就是保证预充电时,输入均为0;求值时,输入只做0→1的翻转 $$ \text { 多米诺逻辑 }=n \text { 型动态门 }+\text { 反相器 } $$图片 初始状态均为0,求值的时候根据前一级输出确定下一级输入,从而求下一级输出。 特点: 求值层层传播,如多米诺骨牌 求值阶段的时间取决于逻辑深度(因为求值时候的特性,见上) 只能实现非反向逻辑 无比逻辑 节点需要在预充电充完电,求值的过程中,输入需要特别稳定。 速度非常快(因为当上一级的输入都是0时,下一级相当于无延迟传播) 输入电容小(和互补CMOS比,只有一个管子) 4. 组合多米诺逻辑 组合多米诺逻辑,并不需要在每个动态门之后加反相器,而是借助一个复合互补CMOS门将多个动态门组合起来。 图片 eg: 图片 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
947
2
2023-02-23
VLSI设计基础7-传输管与传输门逻辑
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 传输管逻辑1. 有比逻辑 2. 传输管逻辑 3. 互补传输管逻辑(CPL) 3. 传输门逻辑 传输管逻辑 1. 有比逻辑 传输管逻辑是有比逻辑;互补CMOS是无比逻辑。 简单而言, 无比逻辑:输出的高低电平和尺寸无关。比如互补CMOS可以直接把输出电压拉到VDD或者GND 有比逻辑:输出的高低电平和尺寸有关。基本没办法直接拉到最大逻辑摆幅。 上拉网络由一个负载代替,如下三种常见的负载(电阻负载、有源负载、伪NMOS负载) 图片 图片 图片 输出端的电压摆幅和门的功能取决于NMOS和PMOS的尺寸比 对于伪NMOS管负载 优点:逻辑门减小,面积减小,只需要n+1个管子,而互补CMOS需要2n个管子 缺点: 有比逻辑,达不到最大逻辑摆幅。 可能没办法完全关断MOS管,静态功耗增加。 应用:面积要求严格,性能要求不高的场景。 2. 传输管逻辑 区别 传输管逻辑和互补CMOS有以下差别: 图片 串联 综合以上的区别,原因主要出在于输入端可以从D、G,而输出从S,从而使输出和输入之间存在VTH的压降 为了减小VTH带来的影响,传输管串联采用D-S-D-S的方式,而不采用D-S-G-S的方式 前者只有一个VTH压降,而后者有两个 如下: 图片 3. 互补传输管逻辑(CPL) 优点: 互补输入输出 每个输出节点都有一个低阻路径连接到VDD或者GND 模块化 缺点: 存在VTH,充电充不到VDD,只能充到VDD-VTH 解决方法:电平恢复、多种阈值晶体管、传输门逻辑 确定输出: 图片 图片 3. 传输门逻辑 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
1
4,172
11
VLSI设计基础6-努力概念与优化
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 总论 2. 【重点】努力2. lg(逻辑努力)和G(路径逻辑努力)--【重点】 3. b(分支努力)和B(路径分支努力) 3.【重点】【优化】 确定电路尺寸 1. 总论 不同材料工艺 CMOS、双极性、BiCMOS、GaAs、超导等材料 逻辑级优化 逻辑深度:流水线【一级变n级】 电路拓扑:逻辑电路寄存器放几个、怎么放、要不要放;重定时(主要EDA工具完成) 扇出 门的复杂性 电路优化 逻辑类型、晶体管尺寸、不同频率下的电路模型 物理优化 版图策略 布局布线 2. 【重点】努力 根据INV延时的通式, $t_p=t_{p 0} \cdot\left(1+\frac{f}{\gamma}\right)$ 推广到所有的逻辑电路中,即有 $t_p=t_{p 0} \cdot\left(p+\frac{g \cdot f}{\gamma}\right)=t_{p 0} \cdot\left(p+\frac{h}{\gamma}\right)$ 图片 p(本征延时比) 如果忽略内部节点电容,p的计算: $p=\frac{\text { 复合门的输出端本征电容 }}{I N V \text { 输出端的本征电容 }}$ 因,$C_{i n t}=a \cdot W$,于是电容值可以用W来代替。 注意,是和输出端相连的管子才参与计算 图片 图片 图片 2. lg(逻辑努力)和G(路径逻辑努力)--【重点】 定义:一个门在最坏情况下,与反相器提供相同的输出电流(即电阻相等或驱动能力相等)时,所表现的输入电容比反相器大多少倍。 小贴士: 反相器有最小的逻辑努力 随着门的复杂度增加,逻辑努力相应增加 只和门的拓扑有关,与尺寸无关 逻辑努力g的计算: 图片 图片 3. b(分支努力)和B(路径分支努力) 图片 公式:$b=\frac{C_{o n-p a t h}+C_{o f f-p a t h}}{C_{o n-p a t h}}$ 注意: 分支努力是针对与一个路径节点而言的 如果只有一条路径,没有分叉,则b=1;如果该节点两个分支的栅电容大小相等,则b=2; 图片 对于路径分支努力B $B=\prod_1^n b_i$ 对于一条路径,该路径的分支努力等于路径上所有节点的分支努力连乘。 f(电气努力)和F (路径电气努力) 图片 f又称为等效扇出,表示第j+1级管子(j+1级输入电容)相对于第j级管子(j级输入电容)的尺寸(电容值)。 $$ f=\frac{C_{e x t}}{C_g} $$图片 图片 对于一条路径,该路径的电气努力等于路径上所有门的电气努力连乘然后除以路径分支努力。 h(门努力)和 g(路径门努力) $$ h=g \cdot f $$图片 3.【重点】【优化】 确定电路尺寸 为了追求更好的性能,即最低的延时,我们希望可以调整尺寸,让组合逻辑的延时最小。 图片 推导如下: ※本征延时和路径中逻辑门的类型有关,和尺寸无关。具体推导看(3)4.3 图片 eg: 求出路径上各级门的尺寸系数S 图片 如上图电路图,可以将电路分成以下4级 图片 步骤一:确定G、B、F 图片 图片 步骤二:确定级数N 由图可知,N=4 步骤三:计算门努力h $$ h=\sqrt[N]{H}=\sqrt[4]{55.56}=2.73 $$步骤四:计算尺寸系数Si 图片 最优级数N=lnF 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
1
2,948
16
2023-02-23
VLSI设计基础5-CMOS组合逻辑门电路
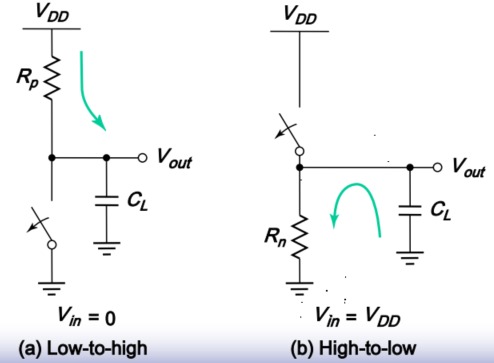
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. CMOS电路的分类 2. 静态互补CMOS设计 2. 【重点】如何确定晶体管尺寸 3. Elmore延时模型 4. 【Elmore延时】计算复合门延时——【多扇入】 5. 降低【多扇入】的电路的延时 6. 延时和【扇出】 7. 总结 1. CMOS电路的分类 静态互补CMOS电路 即常见的CMOS电路——开关模型=理想开关+有限电阻 门输出通过一个低阻连接到VCC和GND,输出为该电路实现的布尔值(0或者1) 特点如下: 高噪声容限(见(4)噪声门限)。 高输入阻抗,低输出阻抗 静态功耗可忽略(见(4)功耗) 动态CMOS集成电路 信号暂时存储在高阻抗电路节点上面的电容上——RC大 特点如下: 门电路简单、速度快 设计和制作工艺复杂 对噪声敏感 图片 2. 静态互补CMOS设计 何为互补CMOS 互补CMOS由上拉网络(PUN)和下拉网络(PDN)组成,每个输入都分配到上拉和下拉网络 如下图,以与非门为例: 图片 图片 规则 以NMOS管作为分析对象, 串与,并或 即,NMOS管串联,实现与非功能;NMOS管并联,实现或非功能。 其关系如下图: 图片 为何是非?因为互补CMOS本身脱身于反相器,故自带非逻辑。 PMOS与之对偶 图片 【静态CMOS】分析逻辑门电路 CMOS管构成的电路分析,使用开关模型——理想开关+有限电阻+电容 以两输入与非门为例,如下图 图片 注意:有节点的地方,一般都有电容。如上图两输入与非门所示,两个串联的NMOS管之间存在节点,于是存在一个电容Cint;上拉和下拉网络之间存在节点,这个节点正好是输出结果的节点,为CL 图片 2. 【重点】如何确定晶体管尺寸 图片 图片 图片 图片 图片 图片 3. Elmore延时模型 【用途】:用于大概估算具有众多电容、电阻电路的延时,适用于【RC树】 最基本的公式:$t_p=0.69 R C=0.69 \tau$ 图片 图片 图片 $\tau=R_1 C_1+R_1 C_2+\left(R_1+R_3\right) C_3+\left(R_1+R_3\right) C_4+\left(R_1+R_3+R_i\right) C_i$ 于是 图片 4. 【Elmore延时】计算复合门延时——【多扇入】 图片 图片 分析【多扇入】: 晶体管串联导致电阻增大,传播延时随着扇入数的增大而增大 一个门的无负载本征延时最坏情况下,延时约为扇入数的二次函数 实际应用中,一般扇入数不超过4 5. 降低【多扇入】的电路的延时 调整管子尺寸 ——逐级加大晶体管尺寸,即在Elmore分析中出现最多次的管子的电阻应该减小(W增大) 图片 尺寸:M1>M2>M3....>MN 重新安排输入 ——关键路径上的晶体管应该靠近输出端。 关键信号:一个门的输出信号中,在所有输入中最后到达稳定的信号。 关键路径:决定一个结构最终速度的逻辑路径称为关键路径。 原理:越靠近输出端,信号需要经过的管子少,RC延时短。 图片 1.重构逻辑结构 ——多扇入逻辑电路拆解成若干个较低扇入的逻辑电路。 前面Elmore延时模型已经知道,延时和扇入数接近平方关系增长。 于是降低扇入数,可以降低电路的整体延时。 加入buffer隔开大扇入和大扇出 图片 图片 6. 延时和【扇出】 图片 7. 总结 关于逻辑门的延时,给出如下的公式进行描述 $t_p=a_1 F_I+a_2 F_I^2+a_3 F_O$ FI表示总的等效扇入,Fo表示总的等效扇出。 可见,延时与扇入成平方关系,同扇出成线性关系
VLSI&IC验证
# VLSI
刘航宇
3年前
0
3,442
6
VLSI设计基础4-反相器
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. INV综述 2. INV的静态特性 3. 【重点】INV的动态特性——tp4. 【※重要】计算延时tp——计算、优化 5. 根据【延时】设计电路 3. 反相链的设计 6. 功耗 7. 利用【功耗】设计电路 1. INV综述 INV的数集模型 图片 由组成的图可以知道,INV是由两个CMOS管串联组成的。而CMOS的数集模型是理想开关+有限导通电阻or无限关断电阻,故INV的数集模型如下 图片 即两个电阻开关并联。 图中的CL表示晶体管的漏极电容、连线电容、扇出门的输入电容 INV的特性综述 图片 VTC(电压传输特性) 所有的工作点不是输出高电平就是输出低电平,如下图: 图片 静态CMOS反向中PMOS和NMOS的负载曲线,原点表示直流工作点 2. INV的静态特性 开关阈值(VM) 图片 图片 噪声门限 图片 图片 3. 【重点】INV的动态特性——tp 设计角度 最小的传播延时 这是厂家最希望的 满足性能的同时,做到面积最小 面积最小,意味着成本最低。这里的面积取决于W,也就是选择合适的 根据扇出设计反相器链的级数 对于时钟树、复位树等需要多扇出的、且要求tp小的,如何设计一个合理的高扇出的反相器链 输入信号的上升下降时间对传播延时的影响 计算计算CL CL =晶体管的漏极电容+连线电容+扇出门的输入电容. 图片 等效电阻Req $R_{e q}=\frac{1}{V_{D D} / 2} \int_{V_{D D} / 2}^{V_{D D}} \frac{V}{I_{D S A T(1+\lambda V)}} d V \approx \frac{3}{4} \frac{V_{D D}}{I_{D S A T}}\left(1+\frac{7}{9} \lambda V_{D D}\right)$ 4. 【※重要】计算延时tp——计算、优化 图片 图片 5. 根据【延时】设计电路 图片 图片 图片 性能最好(tp-min)的反相器 图片 图片 3. 反相链的设计 反相链结构图 图片 图片 图片 例题 图片 6. 功耗 功耗组成 动态功耗:来源于电容充放电 短路电流:当输入电压在某一个区域时,使得上下两管同时导通,从而形成短路电流。 漏电流:属于静态功耗 动态功耗 工作过程——能量分配 来源于电容充放电 图片 图片 公式 图片 短路电流引起功耗 图片 图片 图片 图片 静态功耗(漏电流) 图片 图片 7. 利用【功耗】设计电路 图片 【小贴士】:延迟最低的等效扇出系数为$f=\sqrt[N]{F}$
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,220
2
2023-02-23
VLSI设计基础3-导线与互联问题
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 1. 互连参数 2. 导线模型分布RC模型(重点) 3. 总结 互连问题1. 电容寄生效应 2. 电阻寄生效应 3. 性能——长导线延时 1. 互连参数 导线材料 金属层 多晶硅层 n+或p+扩散层 互连参数——电容 平板电容模型 边缘电容模型 互连参数——电阻 方块电阻: 图片 扩展: 芯片中的互连,一般高层的金属层一般W较大,于是电阻更小。 即W↑→R↓→功耗P↓,RC↓ 因此高层金属层,如M4、M5,常用于时钟、电源等关键信号的 布线中间层金属用作于信号线。 互连参数——电感 当频率上GHZ的时候,才会去考虑电感的作用。 2. 导线模型 模型 理想导线:一般用于较大尺寸的工艺中 集总模型 适用情况:电阻小;开关频率中低水平 内容:将一条导线上的电容集总成一个电容 集总RC模型 适用情况:电阻较大,不可忽略;开关频率中低水平 内容:将一条导线上的电容集总成一个电容,电阻集总成一个电阻 不足:当互连线太长时,该模型当变得保守 图片 分布RC模型(重点) 适用情况:互连线长;导线电阻、电容不可忽略 根据推导可知,一条导线的延时同他的长度呈现二次方关系 和集总RC模型对比 分布RC模型得到的延时是集总RC模型的1/2 适用于长互连线 图片 图片 图片 图片 传输线模型 适用情况:高频、射频、微波;互连材料好,其导线电阻保持在一定范围内。 内容:高频情况下,需要考虑电感的作用 3. 总结 图片 互连问题 寄生参数对于电路的危害: 影响信号的完整性 降低信号的性能 增加延时 增加功耗 寄生的类型——电容、电阻、电感 1. 电容寄生效应 此处讨论电容寄生主要是串扰 串扰的定义: 由相邻的信号线之间不希望有的耦合引起的干扰 小贴士: 耦合有多种,常常是电容性的耦合 串扰引起的噪声难以捕捉 串扰的危害 串扰将使得导线的延时难以预见,故产生了下文“可预见的导线延时设计” 可预见的导线设计 估计改进 方法:不断参数提取,不断仿真,不断优化 缺点:设计过程需要多次重复,时间长 备注:最常用 能动性的版图生成 布线程序考虑相邻导线的作用 缺点:主要由EDA工具完成,在如今EDA工具的要求高 备注:有吸引力;已经有一些EDA工具具备该功能 可预测的结构 方法:密集型布线结构——同层信号线使用电源线隔离,相邻层采用垂直布线。 缺点:面积和电容增加了+5%,功耗和延时增加 优点:减小了电容串扰,延时差别也下降到不超过2% 图片 克服电容串扰的方法 尽量避免浮空节点,对串扰敏感的节点,加保持器降低阻抗、 敏感节点应当很好地与全摆幅信号隔离 在满足时序约束的范围内尽可能加大上升(下降)时间 在敏感的低摆幅布线网络中采用差分信号传输方法 不要使两条信号线之间的电容太大 在两个信号之间增加屏蔽线(即加GND或VDD),使线间电容变成接地电容来消除串扰,但增加了电容负载 使用屏蔽层GND或VDD 2. 电阻寄生效应 总论 原因:芯片尺寸的减小,使得线宽减小,导线电阻增加,导线压降增加。 常考虑:电源网络设计——导线消耗了电压,使得供给门电路的电压下降 供给门电路的电压下降的危害 噪声容限降低 延时增加 降低电迁移的方法 改变金属线属性。 如合金或者Cu代替Al导线,但是成本增加。 降低温度。 降低温度可以减小电迁移发射概率。 芯片封装上面需要考虑散热问题。 增加线宽。 增加线宽可以降低平均电流密度。 缺点;增加布线资源,成本增加 优点:增加线宽不仅可以降低平均电流密度,还可以降低金属温度,间接又抑制了电迁移。 3. 性能——长导线延时 总论 原因:根据导线模型——分布RC模型,可知$t_p \propto L^2$。为了降低电路延时,提高电路的响应速度,需要降低导线寄生电阻。 降低长导线延时的方法 采用更好的互连材料。 导线:铜、合金等;绝缘材料:低介电常数的材料 ※但是,这种方法不是解决长导线延时的根本方法。 增加互连金属层的数目 管子数目增多驱动这金属层数目增多。 局部线(底层金属层做信号传输)采用高密度,全局线(高层金属层走全局信号,如时钟线、电源线) 采用更好的互连策略——对角线法 图片 采用对角线式布线(如上图),现场可较小29%,但是对于EDA工具、掩膜制作的要求高,难度大。 目前一般采用曼哈顿式布线,即横平竖直式的布线。 中间插入中继器——中继器 长的互连线中插入中继器(如inv buffer),强行减小导线长度。但是中继器也存在延时。 优化互连结构——寄存器或锁存器 方法:导线流水线——长互连线中插入寄存器或者锁存器,将导线分成K段。 优点:可以提高数据处理能力。每段导线中可以加入中继器进行进一步优化。
VLSI&IC验证
# VLSI
刘航宇
3年前
0
2,090
3
VLSI设计基础2-器件之MOS晶体管
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 MOS晶体管1. 数字电路的晶体管——最直观 2. MOS静态特性——稳定性(CMOS模电基础) 3. 数字电路手工分析模型——开关+Req 4. 【重点】MOS管的动态特性——性能(tp) 4. 寄生电阻(了解) 5.求tPHL例子(重点) MOS晶体管 1. 数字电路的晶体管——最直观 执行开关功能 非常小的寄生电容 非常高的集成度 相对简单的制造工艺 符号: 图片 2. MOS静态特性——稳定性(CMOS模电基础) 阈值电压 考虑体效应对于阈值电压的影响——偏执效应系数 图片 阈值电压与材料常数(氧化层厚度、费米电势、注入离子剂量等)有关 2.三个工作区: 截止—(亚阈值导电)—线性—饱和—(击穿) 沟长调制效应 图片 4. 速度饱和-重点 短沟道的饱和区范围更大,故常常工作在饱和区。 图片 图片 以下适用于NMOS,PMOS讨论需要取绝对值 图片 漏电流ID和VGS 长沟道,呈现平方关系 短沟道,不那么显著 3. 数字电路手工分析模型——开关+Req 常用开关模型——晶体管=开关+无穷大断开电阻Ron or 有限导通电阻Ron 【计算等效导通电阻Req】:2种方法 图片 例题与方法: 图片 图片 图片 图片 4. 【重点】MOS管的动态特性——性能(tp) 电容的分类 MOS管的动态响应取决于: 本征电容: 基本的MOS结构:结构电容 沟道电荷:沟道电容 漏源反向偏置的PN结耗尽电容:结电容 注意:除了结构电容外,其他两个电容是非线性、随电压变化的 寄生电容 (连线和负载引起) 略解本征电容 简单归类: 图片 小贴士:红色框框:结构电容;灰色框框:沟道电容;蓝色框框:结电容 两个覆盖(结构)电容: $\begin{gathered}C_O=C_{G C O}+C_{G D O}=2 C_o W \\ C_{G C O}=C_{G D O}=C_{o x} x_d W=C_o W\end{gathered}$ 覆盖电容是由于源漏横向扩散到栅氧下形成的寄生电容,故而有两个——栅源之间(CGSO)和栅漏之间(CGDO) 由于这个电容是由于扩散形成的,只要器件做成之后就电容大小就确定,于是结构电容是三类电容中唯一可以确定确切大小的 图片 三个沟道电容: 沟道电容,即栅到沟道之间的电容,称为CGC,即 (Gate Channel)。其中,$C_{G C}=C_{G C B}+C_{G C S}+C_{G C D}$ 即,栅至体、栅至源、栅至漏电容。 由于和沟道有关,又因为沟道形成和工作点有关,于是三个工作点下,CGC不同。 图片 图片 两个(PN)结(耗尽层)电容: PN结电容是由于源-体和漏-体之间反向偏置造成的。 由于工艺上面,我们是在体上“挖一个坑“放漏和源,故而他们之间存在着”立体“的关系。 故而需要关注”四周立体接触“,如图所示, 图片 图片 图片 我们关注的【本征电容】有哪些 我们研究电容是为了利用$\tau=R C$计算tp的值,故而我们在意的是输入和输出通路上的电容。 图片 输入电容——栅极电容 图片 2.输出电容——漏极电容 图片 4. 寄生电阻(了解) 源漏区的串联电阻。 图片 危害: 当晶体管尺寸进一步缩小,会使结变浅、接触孔变小。使得这个影响更加显著。 当给定一个电压,由于分压作用,会使得漏极电流变小。 改善: 源漏极铺一层低电阻材料(如钨或者钛) 5.求tPHL例子(重点) 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
1,005
0
2023-02-23
VLSI设计基础1-数字IC引论:度量指标及版图基础
参考书:数字集成电路-电路、系统与设计,本文栏目对其重点进行精简化 目录 引论1. 数字设计中需解决的问题 2. 集成电路质量评价-重点 3. 数字IC基本概念-重点 4. IC全定制流程 版图基础1. CMOS版图 2. 设计规则检查 3.棍棒图 引论 1. 数字设计中需解决的问题 摩尔定律:技术突破才能推动摩尔定律 特征尺寸:28nm是传统制程和先进制程的分界点 存储器容量:存储器的容量增大,意味着功耗增大,意味着稳定性下降(发热)。如果想要实现更大容量的突破,需要寻找新技术或者新架构使功耗不能超过功耗红线 晶圆尺寸:晶圆尺寸增加,单位硅片数量增加,所需的技术越先进,最终成品芯片价格也越低 技术突破:大直径的硅片可以大大提高成品率 2. 集成电路质量评价-重点 图片 注: ① 是取决于制造工艺复杂行参数,常取值3 ②单位面积缺陷数常取值0.5~1个缺陷/cm² ③芯片成本 $=f(\text { 芯片面积 })^4$ 稳定性与功能性 噪声:电容耦合、电感耦合、地线耦合 ※※※【重点】性能——延时tp、工作频率性能常与时钟周期、时钟频率相关 重点:延时 图片 1、传播延时:输入和输入波形的50%翻转点之间的时间 如图: 定义传播时间tp为 $t_p=\frac{t_{p L H}+t_{p H L}}{2}$ 一般而言, ①TpLH和TpHL不会完全相等 ②如果要求传输延时<t,则意味着TpLH<t并且TpHL<t 图片 图片 2、上升时间tr 3、下降时间tf 功耗和能耗 取决的因素太多了。 常常有:瞬时功耗、峰值功耗(研究电源线尺寸)、平均功耗(研究冷却或者对电池的要求) 3. 数字IC基本概念-重点 电压传输特性VTC(DC传输曲线) 可接受的高电压、低电压区域:VIH和VIL定义为VTC增益=-1的点 噪声容限=min{NMH.NML} NMH=|VOH-VIH| NML=|VIL-VOL| 再生性 保证一个受干扰的信号经过若干个组合逻辑之后依旧回到一个额定电平(高或者低,不是不确定态) 抗干扰能力 方向性 6.扇入和扇出 扇入和扇出个数和一些延迟有关 4. IC全定制流程 图片 版图基础 1. CMOS版图 1、图编辑工具:virtuoso、max 2、工艺层的概念:将cmos使用中难以理解的掩膜转化为一组简单概念化的版图层 3、可伸缩的设计:将版图所有参数定义与$\lambda$,利用EDA工具使之在想要兼容的工艺间转换。如0.25转为0.18。早期的工艺中,这个缩放比例可以达到75%左右,随着如今器件尺寸的减小,该比例只有90%左右了。 不足:①由于不同工艺之间的非线性,线性缩放仅在有限尺寸范围内;②可缩放规则是保守的,结果会使得标准单元尺寸过大或者过小。 4、晶体管的尺寸由W/L指定。 给定一个工艺,最小线宽为2$\lambda$; 图片 5、在版图中,只要多晶硅穿过扩散区,就形成一个晶体管 随着工艺的发展,电源电压VDD呈现下降趋势。 2. 设计规则检查 设计规则检查工具:Calibre DRC 设定规则的目的:可以很容易的把电路的概念转换为硅上的几何关系。 Calibre的规则相当于是行业的标准了。 其规则是基于边(edge)的DRC/LVE工具,所有的计算都是基于边来计算的,其中”边“分为”内边“和”外边“ 常见的三个指令: internal:检查多边形的内边距 external:检查多边形的外边距 enclosure:检查多边形的交迭 3.棍棒图 1、要求:①将棍棒图转为管级电路图、并且写出输出表达式;②将管级电路图转化为棍棒图 2、特点: 仅用象征性的符号表示电路的拓扑结构 不需要标尺寸大小 棍棒图中棍棒的位置很重要 3、棍棒图中的串并联 以下为版图的: 串联: 图片 并联: 图片
VLSI&IC验证
# VLSI
刘航宇
3年前
0
693
2
RAM与ROM及Verilog实现
概念 RAM(random access memory)即随机存储内存,这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序。 ROM 指的是“只读存储器”,即Read-Only Memory。只读存储器(Read-Only Memory,ROM)以非破坏性读出方式工作,只能读出无法写入信息。信息一旦写入后就固定下来,即使切断电源,信息也不会丢失,所以又称为固定存储器。ROM所存数据通常是装入整机前写入的,整机工作过程中只能读出,不像随机存储器能快速方便地改写存储内容。ROM所存数据稳定 ,断电后所存数据也不会改变,并且结构较简单,使用方便,因而常用于存储各种固定程序和数据。 PROM 指的是“可编程只读存储器”既Programmable Red-Only Memory。这样的产品只允许写入一次,所以也被称为“一次可编程只读存储器”(One Time Progarmming ROM,OTP-ROM)。最初从工厂中制作完成的PROM内部并没有资料,用户可以用专用的编程器将自己的资料写入,但是这种机会只有一次,一旦写入后也无法修改。 EPROM 指的是“可擦写可编程只读存储器”,即Erasable Programmable Read-Only Memory。它的特点是具有可擦除功能,擦除后即可进行再编程,但是缺点是擦除需要使用紫外线照射一定的时间。 EEPROM 指的是“电可擦除可编程只读存储器”,即Electrically Erasable Programmable Read-Only Memory。它的最大优点是可直接用电信号擦除,也可用电信号写入。EEPROM不能取代RAM的原因是其工艺复杂, 耗费的门电路过多,且重编程时间比较长,同时其有效重编程次数也比较低。 Flash memory 指的是“闪存”,所谓“闪存”,它也是一种非易失性的内存,属于EEPROM的改进产品。它的最大特点是必须按块(Block)擦除(每个区块的大小不定,不同厂家的产品有不同的规格), 而EEPROM则可以一次只擦除一个字节(Byte)。目前“闪存”被广泛用在PC机的主板上,用来保存BIOS程序,便于进行程序的升级。其另外一大应用领域是用来作为硬盘的替代品,具有抗震、速度快、无噪声、耗电低的优点,但是将其用来取代RAM就显得不合适,因为RAM需要能够按字节改写,而Flash ROM做不到。 二、编程 1.要求: 编程实现512x8的ROM和RAM。 ROM、RAM至少应该包含的端口包括地址线、数据线、片选线、读写使能端,复位端和时钟端(其中部分信号线只适用于RAM)。 ROM、RAM和总测试模块分别包含在不同的.v文件中。 端口意义: Data: 双向数据总线,用于读写数据。它的宽度由width参数决定。 Addr: 输入地址总线,用于指定要访问的内存单元。它的宽度也由width参数决定,默认为8位。 CS: 输入芯片选择信号,用于使能或禁止模块的读写操作。当CS为1时,模块可以进行读写操作;当CS为0时,模块不响应任何操作。 RWEnable: 输入读写使能信号,用于指定模块的工作模式。当RWEnable为1时,模块处于写模式,可以将Data总线上的数据写入到Addr指定的内存单元中;当RWEnable为0时,模块处于读模式,可以将Addr指定的内存单元中的数据输出到Data总线上。 2.设计思路: 512x8的ROM和RAM,至少需要9位地址线和8位数据位。 3.RAM实现代码 //模块声明,指定模块名和端口引脚 module RAM (Data,Addr,CS,RWEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RWEnable,Reset,Clk; //输入信号,分别为芯片选择、读写使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 inout[width-1:0] Data; //双向数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_temp; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为0 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= 0; //将每个内存单元赋值为0 end //写操作条件,当RWEnable为1且CS为1时,将Data总线上的数据写入到Addr指定的内存单元中 else if((RWEnable==1'b1)&&(CS==1'b1)) begin Mem[Addr] <= Data; //将Data总线上的数据赋值给Mem[Addr] end //读操作条件,当RWEnable为0且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_temp中 else if((RWEnable==1'b0)&&(CS==1'b1)) begin Data_temp<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_temp end //其他条件,当CS为0或RWEnable为不确定值时,将Data_temp置为高阻抗状态 else begin Data_temp <= 8'bz; //将Data_temp赋值为高阻抗状态 end end //assign语句,指定Data总线与Data_temp之间的连接关系 assign Data=RWEnable?8'bz:Data_temp; //当RWEnable为1时,Data总线处于高阻抗状态;当RWEnable为0时,Data总线接收Data_temp中的数据 endmodule //模块结束测试代码如下: //模块声明,指定模块名为RAM_TS module RAM_TS; //信号和寄存器的定义,指定与RAM模块相连的端口引脚和内部变量 reg CS_t,RWEnable_t,Reset_t,Clk_t; //芯片选择、读写使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 reg [7:0] Data_temp_t; //用于暂存写入数据的寄存器,也是8位的 //initial块,指定测试RAM模块的过程,只会在仿真开始时执行一次 initial begin RWEnable_t = 1;//w //初始化读写使能信号为1,表示写模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 Data_temp_t = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 Data_temp_t=Addr_t; //将地址总线上的值赋给暂存数据,表示要写入的数据与地址相同 end #70 //延迟70个时间单位后 RWEnable_t = 0;//r //将读写使能信号置为0,表示读模式 Addr_t=0; //将地址总线置为0,表示从第一个内存单元开始读取数据 repeat(10) //重复10次以下操作 begin #5 //延迟5个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //assign语句,指定数据总线与暂存数据之间的连接关系 assign Data_t=RWEnable_t?Data_temp_t:8'bz; always #5 Clk_t=~Clk_t; //实例化一个RAM模块,并且用定义好的信号和寄存器与之相连 RAM myRAM( .Data(Data_t), //将数据总线与RAM模块的Data端口相连 .Addr(Addr_t), //将地址总线与RAM模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与RAM模块的CS端口相连 .RWEnable(RWEnable_t), //将读写使能信号与RAM模块的RWEnable端口相连 .Reset(Reset_t), //将复位信号与RAM模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与RAM模块的Clk端口相连 ); endmodule //模块结束4.RAM仿真测试: ① 数据写入操作 image.png图片 ② 数据读取操作 image.png图片 5.ROM实现代码: RDEnable: 当RDEnable为1时,模块处于读模式,将Addr指定的内存单元中的数据输出到Data总线,当RDEnable为0时,模块处于空闲模式,不对Data驱动。 ROM代码如下: //模块声明,指定模块名和端口引脚 module ROM(Data,Addr,CS,RDEnable,Reset,Clk); //参数定义,指定数据总线和地址总线的宽度,以及内存单元的数量 parameter width=8,msize=512; //端口引脚的方向和位宽定义 input CS,RDEnable,Reset,Clk; //输入信号,分别为芯片选择、读使能、复位和时钟 input[width:0] Addr; //输入地址总线,宽度由width参数决定 output [width-1:0] Data; //输出数据总线,宽度由width参数决定 //内部信号和寄存器的定义 reg [width-1:0] Data_read; //用于暂存读出的数据的寄存器,宽度与Data总线相同 reg [width-1:0] Mem [msize-1:0]; //用于存储所有数据的内存数组,大小与内存单元数量相同 integer i; //用于遍历内存单元的整数变量 //always块,指定模块中所有操作的逻辑 always @(posedge Clk or posedge Reset) begin //复位条件,当Reset为1时,所有内存单元都被置为其地址值 if(Reset) begin for(i=0;i<msize;i=i+1) //用一个for循环遍历所有内存单元 Mem[i] <= i; //将每个内存单元赋值为其地址值 end //读操作条件,当RDEnable为1且CS为1时,将Addr指定的内存单元中的数据读出并暂存在Data_read中 else if((RDEnable==1'b1)&&(CS==1'b1)) begin Data_read<=Mem[Addr]; //将Mem[Addr]中的数据赋值给Data_read end //其他条件,当CS为0或RDEnable为不确定值时,将Data_read置为高阻抗状态 else Data_read <= 8'bz; //将Data_read赋值为高阻抗状态 end //assign语句,指定Data总线与Data_read之间的连接关系 assign Data=Data_read; //当RDEnable为1时,Data总线输出Data_read中的数据;当RDEnable为0时,Data总线处于高阻抗状态 endmodule //模块结束测试代码如下: //模块声明,指定模块名为R0M98_TS module R0M_TS; //信号和寄存器的定义,指定与ROM98模块相连的端口引脚和内部变量 reg CS_t,RDEnable_t,Reset_t,Clk_t; //芯片选择、读使能、复位和时钟信号,都是1位的寄存器 wire [7:0] Data_t; //数据总线,是8位的线网 reg [8:0] Addr_t; //地址总线,是9位的寄存器 //initial块,指定测试ROM98模块的过程,只会在仿真开始时执行一次 initial begin RDEnable_t = 1;//r //初始化读使能信号为1,表示读模式 Reset_t = 1; //初始化复位信号为1,表示复位模式 Clk_t = 0; //初始化时钟信号为0 Addr_t = 0; //初始化地址总线为0 // Data_read_ts = 0; //初始化暂存数据为0 CS_t=1; //初始化芯片选择信号为1,表示使能模式 #5 Reset_t=0; //延迟5个时间单位后,将复位信号置为0,表示正常工作模式 repeat(10) //重复10次以下操作 begin #10 //延迟10个时间单位后 Addr_t=Addr_t+10; //将地址总线加10,表示访问下一个内存单元 end end //always块,指定时钟信号的变化规律,每隔5个时间单位翻转一次 always #5 Clk_t=~Clk_t; //实例化一个ROM98模块,并且用定义好的信号和寄存器与之相连 ROM myROM( .Data(Data_t), //将数据总线与ROM98模块的Data端口相连 .Addr(Addr_t), //将地址总线与ROM98模块的Addr端口相连 .CS(CS_t), //将芯片选择信号与ROM98模块的CS端口相连 .RDEnable(RDEnable_t), //将读使能信号与ROM98模块的RDEnable端口相连 .Reset(Reset_t), //将复位信号与ROM98模块的Reset端口相连 .Clk(Clk_t) //将时钟信号与ROM98模块的Clk端口相连 ); endmodule //模块结束 6.ROM仿真测试: image.png图片
FPGA&ASIC
VLSI&IC验证
# 体系结构
刘航宇
3年前
0
1,104
2
2023-02-10
FPGA与数字IC设计中接口命名规范
在硬件编程中,接口命名规范也是一个良好的习惯。接口在确定模块划分后需要明确模块的端口以及模块间的数据交互。完成项目模块划分后,可以在确定端口及数据流向时参考使用。本节重点是EN与vld的区别! ` 端口信号规范 ` 信号说明clk模块工作时钟rst_n系统复位信号,低电平有效en门控时钟,请搜索本站关于门控时钟讲解,这是低功耗的设计,EN=0睡眠状态、阻断时钟输入vld数据有效标志指示信号,表示当前的 data 数据有效。注意,vld 不仅表示了数据有效,而且还表示了其有效次数。时钟收到多少个 vld=1,就表示有多少个数据有data数据总线。输入一般名称为 din,输出一般名称为 dout。类似的信号还有 addr,len 等err整个报文错误指示,在 eop=1 且 vld=1 有效时才有效sop报文起始指示信号,用于表示有效报文数据的第一个数据,当 vld=1 时此信号有效eop报文结束指示信号,用于表示有效报文数据的最后一个数据,当 vld=1 时此信号有效rdy模块准备好信号,用于模块之间控制数据发送速度。例如模块 A 发数据给模块 B,则rdy 信号由模块 B 产生,连到模块 A(该信号对于 B 是输出信号,对于 A 是输入信号);B 要确保 rdy 产生正确,当此信号为 1 时,B 一定能接收数据;A 要确保仅在 rdy=1 时才发送图片
FPGA&ASIC
# ASIC/FPGA
刘航宇
3年前
0
472
2
2023-02-09
VCS、Verdi与Makefile使用简介
前期工作 1、.fsdb文件 在使用Makefile文件前,先在测试文件中加入这样一句。 initial begin $fsdbDumpfile("tb.fsdb");//这个是产生名为tb.fsdb的文件 $fsdbDumpvars; end需要注意:对于用于仿真的testbench,需要额外建立一个 initial 块,调用产生有关 fsdb 格式的波形文件: 首先调用 fsdbDumpfile 函数,产生一个叫 .fsdb 的波形文件 然后调用 fsdbDumpvars 函数,声明需要保存那些信号的波形,括号内不加任何参数,则默认全部保存。 2、 filelist.f文件 filelist.f里存放所有需要仿真的.v文件。 创建filelist.f的方法: find -name "*.v" >filelist.f 1. Makefile作用? 编写makefile文件本质上是帮组make如何一键编译,进行批处理,makefile文件包含的规则命令使我们不需要繁琐的操作,提高了开发效率。 Makefile可以根据指定的依赖规则和文件是否有修改来执行命令。常用来编译软件源代码,只需要重新编译修改过的文件,使得编译速度大大加快。 2. Makefile应用 利用Makefile 实现简单的前端设计流程,包括VCS编译,Verdi仿真,DC综合,后续流程待补充。 目录结构 图片 #use "make" for help help: @echo "make help" @echo "make com to compile" @echo "make sim to run simulation" @echo "make clean to delete temporary files" #need to midify design name design_name = div_top fsdb_name = $(design_name).fsdb # use command "make com" to run vsc and product fsdb file com: cd RTL && vcs \ -full64 \ -f flist.f \ -debug_all \ -l com.log \ +v2k \ -P ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/novas.tab ${Verdi_HOME}/share/PLI/VCS/LINUXAMD64/pli.a # cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) #simulation:product fsdb file and sim log sim: ./RTL/simv cd RTL && ./simv -l sim.log +fsdbfile+$(fsdb_name) # use verdi to observe the waveform verdi: cd RTL && verdi \ +v2k \ -f flist.f \ -ssf $(fsdb_name) & #use fsdb file # run dc for synthesize syn: cd dc_script && dc_shell -64bit -topographical -f top_syn.tcl | tee -i syn.log #delete all files except .v and makefile clean: #rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v" | grep -v "dc_script"` make -C RTL clean make -C dc_script clean/RTL目录下MakeFile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "flist.f" | grep -v "\.v"` dc_script目录下Makefile #delete temporary files clean: rm -rf `ls | grep -v "Makefile"|grep -v "script" | grep -v ".*.tcl"` make com :调用vcs编译 make sim:调用vcs仿真 make verdi 波形,shifrt+l可刷新重新编译结果 make clean 删除所有子目录下的临时生成文件 详细命令 执行“make vcs” 编译仿真 执行“make verdi” 打开波形 verdi常用快捷键 ctrl+w: 添加信号到波形图 h: 在波形窗口显示详细的信号名(路径) File>save signal,命名*.rc,下次直接打开rc文件就行 c/t: 修改信号的颜色(t可以直接切换颜色) 在波形窗口显示状态机的名字: 在rtl窗口,tools>Extract internative FSM ,可选first stage(仅展开目前所指定的FSM state),all stage (展开所有的FSM state) 改变颜色填充波形: Tools>waveform>view options>waveformpane> paint waveform with specified color/pattern 在rtl窗口按x: 标注出信号的值 z: 缩小波形窗口 Z: 放大波形窗口 f: 全屏 l: 上一个视图 L: 重新加载设计波形或文件 n: 向前查找 N: 向后查找 ctrl+→: 向右移动半屏 ctrl+←: 向左移动半屏 双击信号波形: 跳转到rtl中信号位置,并高亮新号 b: 跳到波形图开头 e: 跳到波形图尾部 2.不使用Makefile直接执行 vcs -R -f flist.f -full64 -fsdb -l name.log verdi -f flist.f -ssf name.fsdb 图片
编程&脚本笔记
EDA&虚拟机
# EDA&虚拟机
# Makefile
刘航宇
3年前
0
1,487
2
上一页
1
2
3
4
...
7
下一页